
最近,在布拉格Linux网络会议Netdev 0x13上,我做了一个简短的演讲,题目是“Cloudflare上的Linux”。演讲最后主要是关于BPF(柏克莱封包过滤器)的。似乎,不管问题是什么——BPF都是答案。
下面是这次演讲的稍作调整的笔录。

在Cloudflare,我们在服务器上运行Linux。我们运营两类数据中心:大型“核心”数据中心,用以处理日志,分析攻击,计算分析;以及“边缘”服务器机群,从全球180个(截至19年10月为190多个)位置交付客户内容。
在这次演讲中,我们将重点讨论“边缘”服务器。在这里,我们使用最新的Linux特性,优化性能,并深切关注DoS(拒绝服务攻击)的弹性。
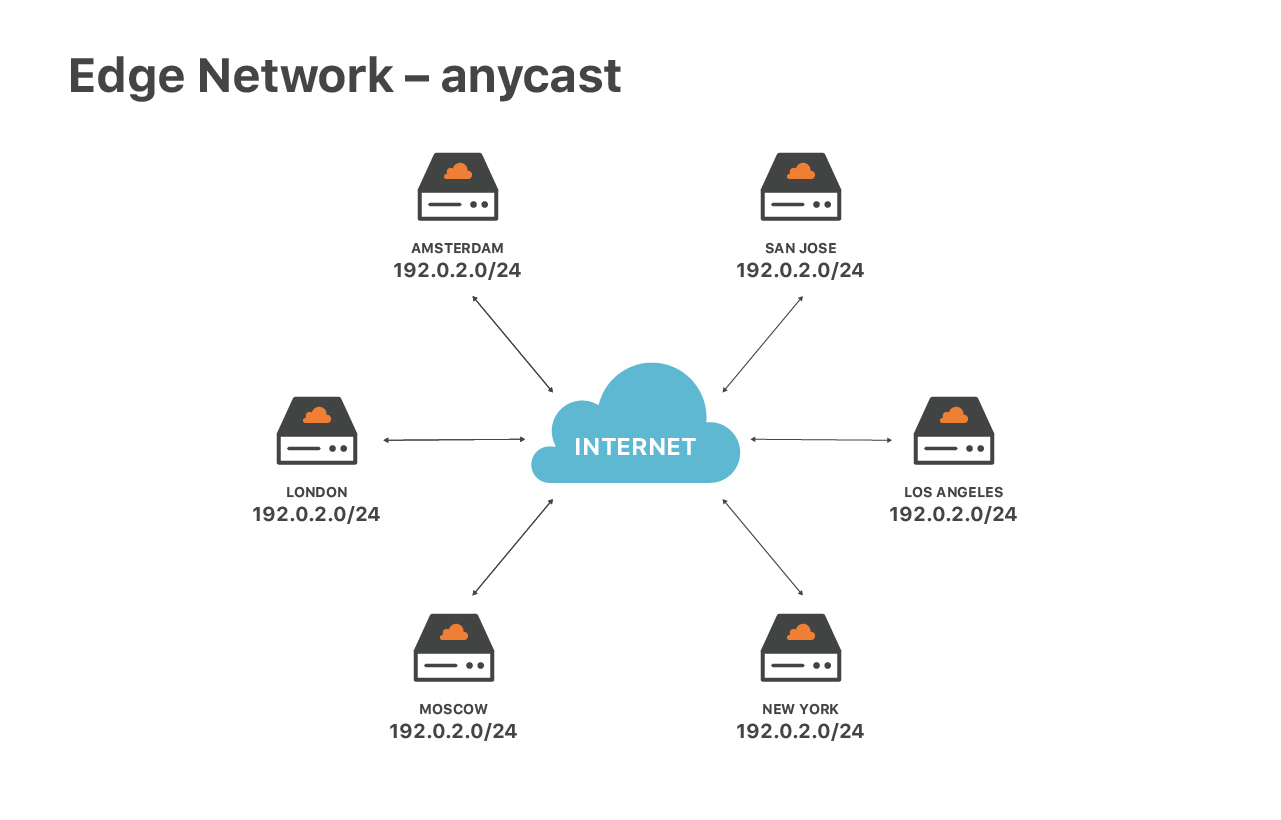
由于我们的网络配置,我们的边缘服务很特别——我们广泛使用anycast(任播)路由。任播意味着所有数据中心都公布相同的IP地址集。
这种设计有很大的优势。首先,它保证了最终用户的最佳速度。无论身处何处,您都可以到达最近的数据中心。并且,任播帮助我们分散DoS流量。在遭受攻击过程中,每个位置接收的流量仅占总流量的一小部分,因此我们可以更容易地提取和过滤掉不需要的流量。
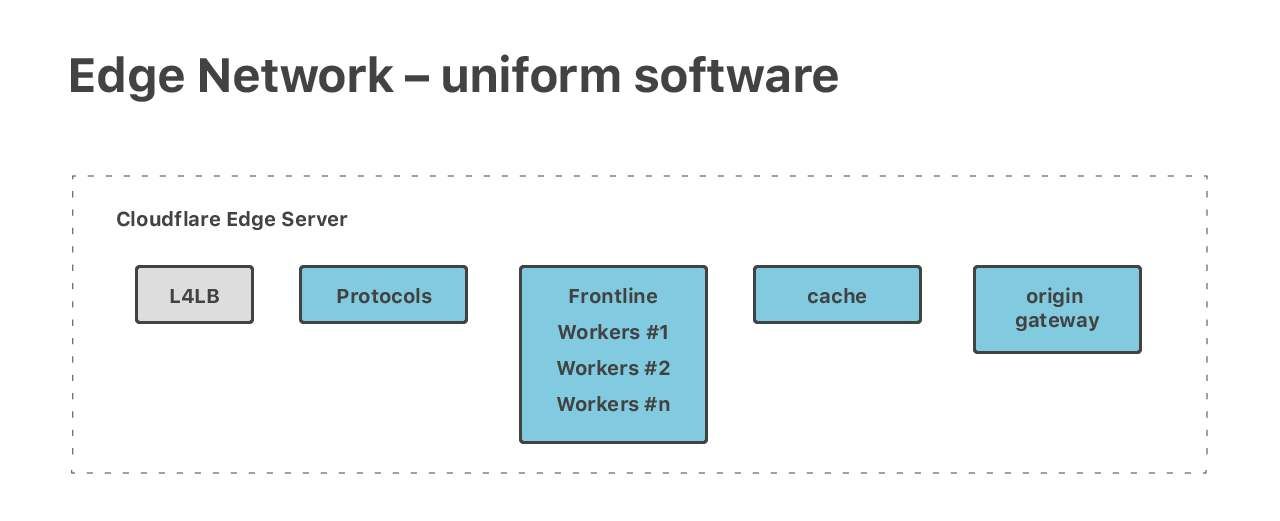
任播使我们能够在所有边缘数据中心保持统一的网络设置。我们在数据中心内部应用了相同的设计——我们的软件堆栈在边缘服务器上是统一的。每一个服务器上都运行着所有的软件。
原则上,每台机器都能处理所有的任务——我们运行着许多不同的、要求很高的任务。我们有完整的HTTP栈、神奇的Cloudflare Workers、两组DNS服务器——权威DNS和解析器,以及许多其他的面向公众的应用程序,如Spectrum和Warp。
尽管每台服务器都运行着所有的软件,但请求通常也会在堆栈的旅程中跨越许多机器。例如,在处理HTTP请求的5个阶段中,每个阶段都有不同的机器进行处理。
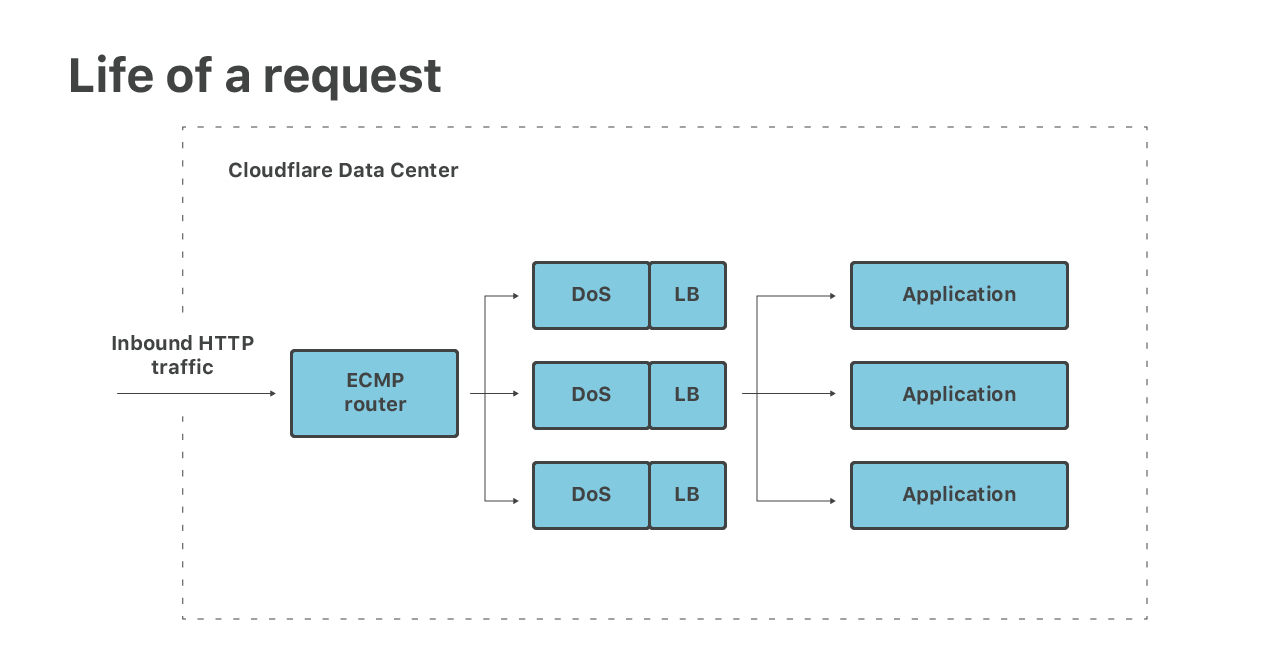
让我向您介绍入站数据包处理的早期阶段:
(1)首先,数据包到达我们的路由器。路由器执行ECMP(等价多路径路由),并将数据包转发到我们的Linux服务器上。我们使用ECMP将每个目标IP分布到至少16台机器上。这是一种基本的负载均衡技术。
(2)在服务器上,我们使用XDP eBPF接收数据包。在XDP中,我们执行两个阶段。首先,我们运行大容量的DoS缓解措施,丢弃属于非常大的第3层攻击的数据包。
(3)然后,同样在XDP中,我们执行第4层负载均衡。所有的非攻击包都在计算机之间重定向。这是用来解决ECMP问题的,为我们提供了精细的负载均衡,并允许我们自然而正常地关闭服务器的服务。
(4)重定向之后,数据包到达指定的机器。此时,它们被普通的Linux网络堆栈接收,通过常规的iptables防火墙,并被分派到合适的网络套接字。
(5)最后,数据包被应用程序接收。例如,HTTP连接由“协议”服务器处理,该服务器负责执行TLS加密和处理HTTP、HTTP/2和QUIC协议。
在请求处理的早期阶段,我们使用了最酷的Linux新功能。我们可以将有用的现代功能分为三类:
- DoS处理
- 负载均衡
- 套接字分配
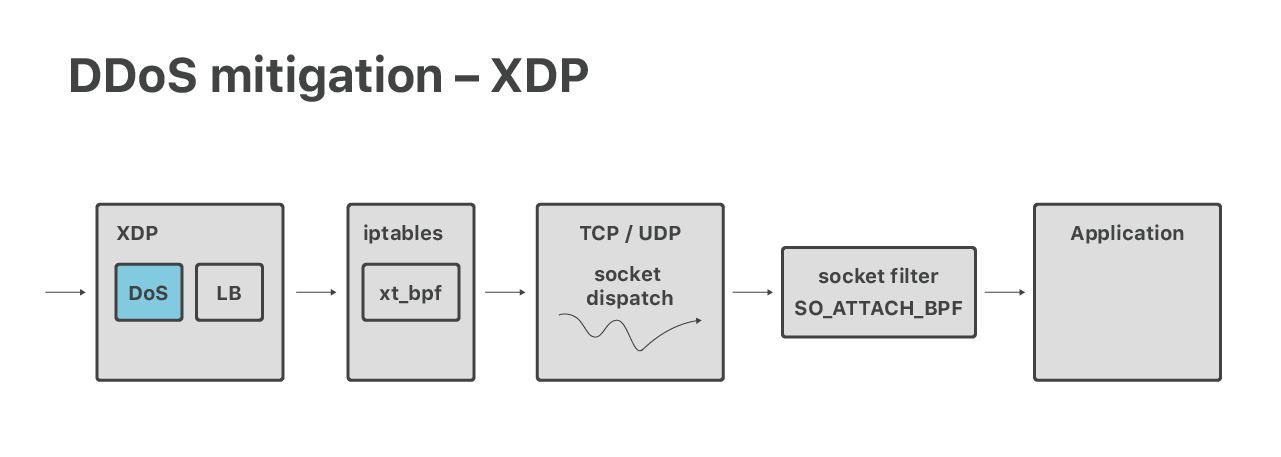
让我们更详细地讨论DoS处理。如前所述,ECMP路由之后的第一步是Linux的XDP堆栈,其中,我们运行DoS缓解措施。
从历史上看,我们对容量攻击的缓解是用经典的BPF和iptables样式的语法表示的。最近,我们对它们进行了调整,从而在XDP eBPF环境中执行,事实证明这非常困难。一起来看看我们冒险的经历吧:
- L4Drop: XDP DDoS缓解
- xdpcap: XDP数据包捕获
- Arthur Fabre的演讲:基于XDP的DoS缓解
- 实践中的XDP:将XDP集成到我们的DDoS缓解通道中 (PDF)
在这个项目中,我们遇到了许多eBPF/XDP限制。其中之一是缺乏并发原语。实现无竞争令牌桶之类的东西非常困难。后来,我们发现Facebook工程师Julia Kartseva遇到了同样的问题。在2月份,这个问题已经通过引入bpf_spin_lock helper得到了解决。
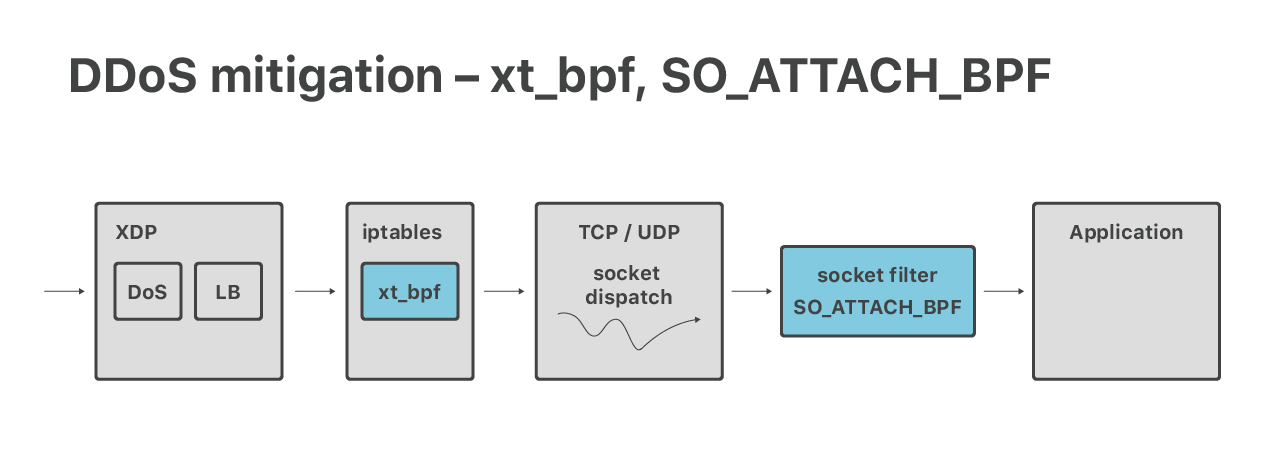
虽然我们现代的容量DoS防御是在XDP层完成的,但我们仍然依赖iptables来减轻应用层(第7层)的影响。在这里,更高级别防火墙的特性起着很大的作用:connlimit、hashlimit和ipset。我们还使用xt_bpf iptables模块在iptables中运行cBPF,从而匹配数据包有效负载。我们以前讨论过这个问题:
- 抵御不可抗力的经验教训 (PPT)
- 介绍BPF工具
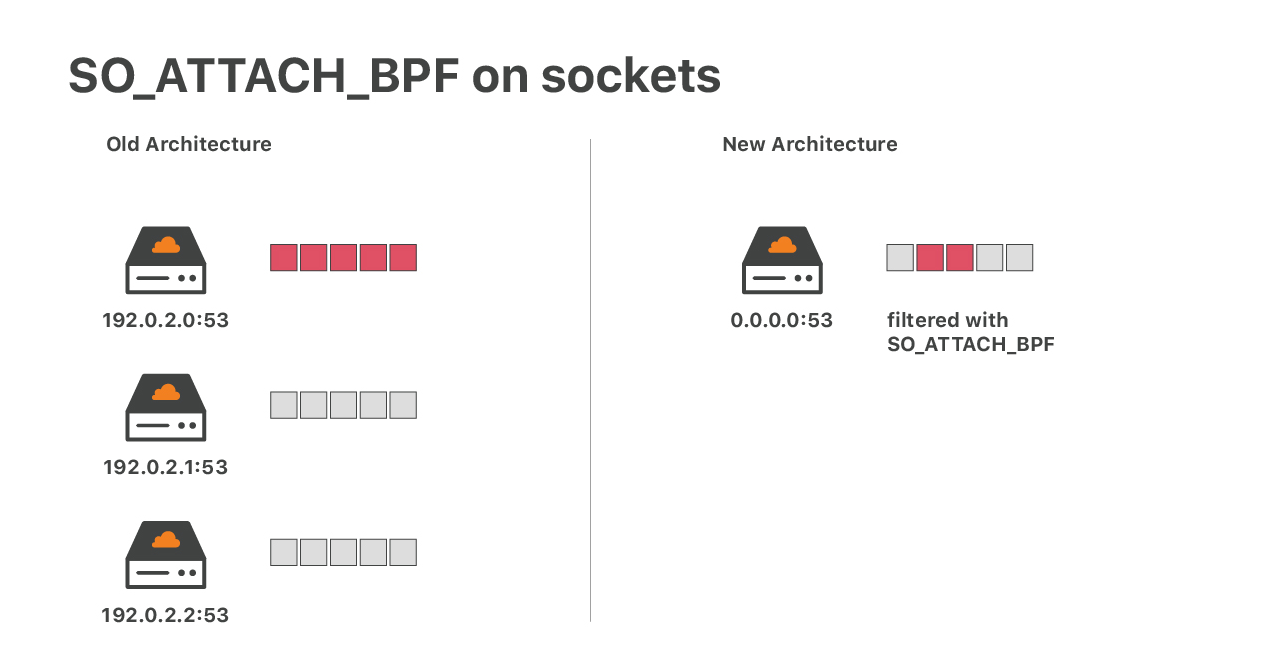
在XDP和iptables之后,我们有了最后一个内核端DoS防御层。
考虑UDP缓解失败的情况。在这种情况下,可能会有大量的数据包到达应用程序UDP套接字。这可能会使套接字溢出,导致数据包丢失。这是有问题的——好的数据包和坏的数据包都会被随意丢弃。对于DNS这样的应用程序来说,这一后果是灾难性的。在过去,为了减少危害,我们为每个IP地址运行了一个UDP套接字。无法缓解的洪水攻击是很糟糕的,但至少它没有影响到其他服务器IP地址的流量。
如今,这种架构已不再适用。我们正在运行30,000多个DNS IP,并且运行同样数量的UDP套接字是不可行的。我们现代的解决方案是运行一个带有复杂eBPF套接字过滤器的UDP套接字——使用SO_ATTACH_BPFsocket选项。我们在以前的博客文章中讨论过在网络套接字上运行eBPF:
- eBPF,套接字,跳段距离,手动编写eBPF程序集
- SOCKMAP——未来的TCP粘合
上面提到的eBPF速率限制了数据包。它将状态(数据包计数)保存在eBPF映射中。我们可以确保一个被“淹没”的IP不会影响其他流量。这种做法效果很好,尽管在进行此项目期间,我们在eBPF验证程序中发现了一个令人担忧的错误:
- eBPF无法计数?!
我猜在UDP套接字上运行eBPF并不如往常般简单。
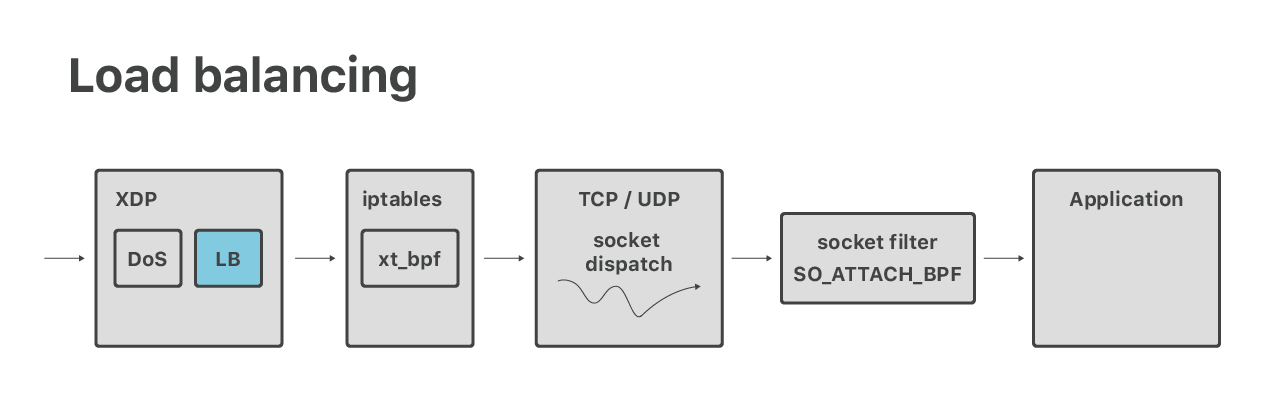
除了DoS,在XDP中我们还运行了第4层负载均衡器层。这是一个新项目,我们还没作过多的谈论。无需深入探讨:在某些情况下,我们需要从XDP执行套接字查找。
这个问题相对简单——我们的代码需要查找从数据包中提取的5元组的“套接字”内核结构。这通常很简单——可以借助bpf_sk_lookup helper。不出所料的是,这里出现了一些复杂情况。其中有个问题是,当启用SYN cookie时,无法验证接收到的ACK包是否是三方握手的有效部分。我的同事Lorenz Bauer正在为这个特殊情况提供额外支持。
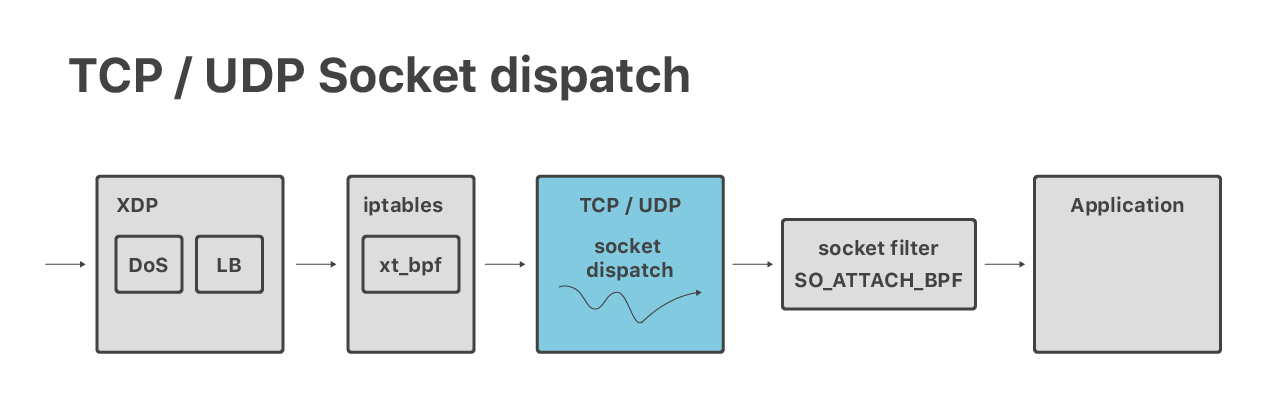
经过DoS和负载均衡层之后,数据包将被传递到通常的Linux TCP / UDP堆栈上。在这里,我们进行套接字分配——例如,将进入端口53的数据包传递到属于我们的DNS服务器的套接字上。
我们尽力使用原始Linux功能,但是当您在服务器上使用数千个IP地址时,事情会变得复杂。
使用“AnyIP”技巧使Linux能够正确地路由数据包是相对比较容易的。但确保数据包被分发到正确的应用程序则是另一回事。不幸的是,标准的Linux套接字分派逻辑不够灵活,不能满足我们的需要。对于TCP/80这样的流行端口,我们希望在多个应用程序之间共享端口,每个应用程序在不同的IP范围内处理它。Linux不支持此功能。您可以在特定的IP或所有(使用0.0.0.0)的IP地址上调用bind()。
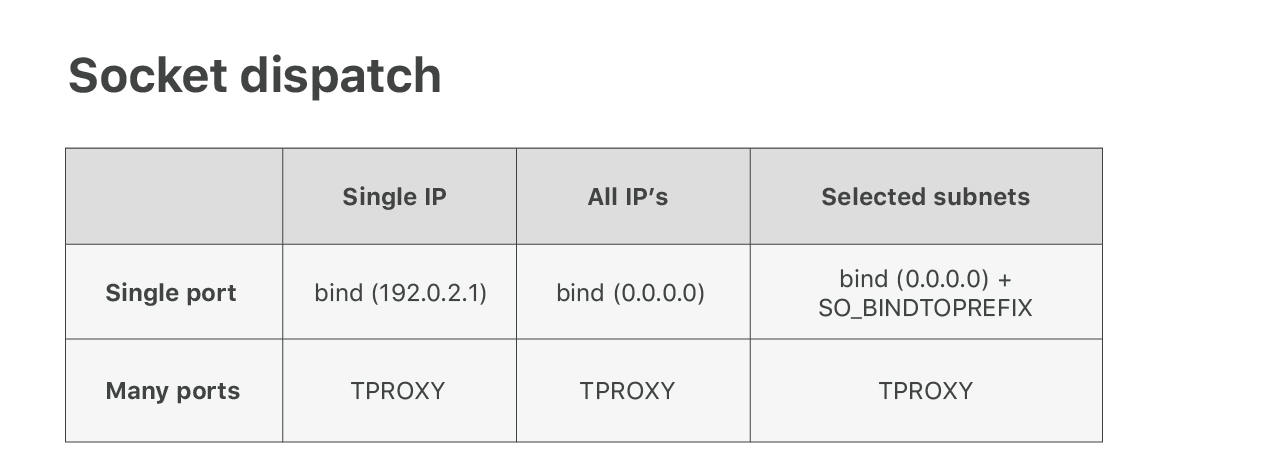
为了解决这个问题,我们开发了一个自定义内核补丁,其中添加了一个SO_BINDTOPREFIXsocket选项。顾名思义——它允许我们在选定的IP前缀上调用bind()。这解决了多个应用程序共享流行端口(如53或80)的问题。
然后我们遇到另一个问题。对于我们的Spectrum产品,我们需要监听所有总共65535个端口。运行这么多监听套接字不是一个好主意(请参阅我们过去的战争故事博客),因此我们不得不寻找另一种方法。经过一些实验,我们学会了使用一个鲜有人知的iptables模块——TPROXY——来达到这个目的。点击这里进行阅读:
这个设置起到了作用,但我们不喜欢额外的防火墙规则。我们正在努力正确地解决这个问题——实际上我们扩展了套接字调度逻辑。您猜对了——我们希望利用eBPF扩展套接字分派逻辑。敬请期待我们的一些补丁。

然后还有一种使用eBPF改进应用程序的方法。最近,我们对使用SOCKMAP进行TCP粘合很感兴趣:
这项技术在改善我们许多软件堆栈的尾部延迟方面具有巨大潜力。当前的SOCKMAP实施尚未准备好完全发挥其作用,但它的潜力是巨大的。
同样,新的TCP-BPF又名BPF_SOCK_OPS挂载为检查TCP流的性能参数提供了一种很好的方法。此功能对我们的性能表现团队非常有用。

一些Linux特性没有很好地发展成熟,我们需要解决它们。例如,我们正在突破网络指标的限制。不要误解我的意思——网络指标非常棒,但遗憾的是它们不够精细。像TcpExtListenDrops和TcpExtListenOverflows之类的事物被称为全局计数器,而我们需要在每个应用程序的基础上了解它。
我们的解决方案是使用eBPF探针直接从内核中抽取数字。我的同事Ivan Babrou编写了一个名为“ebpf_exporter”的Prometheus指标导出器,以便进行此操作。了解更多请继续阅读:
使用“ebpf_exporter”,我们可以生成所有形式的详细指标。它非常强大,并在许多情况下极大地帮助了我们。
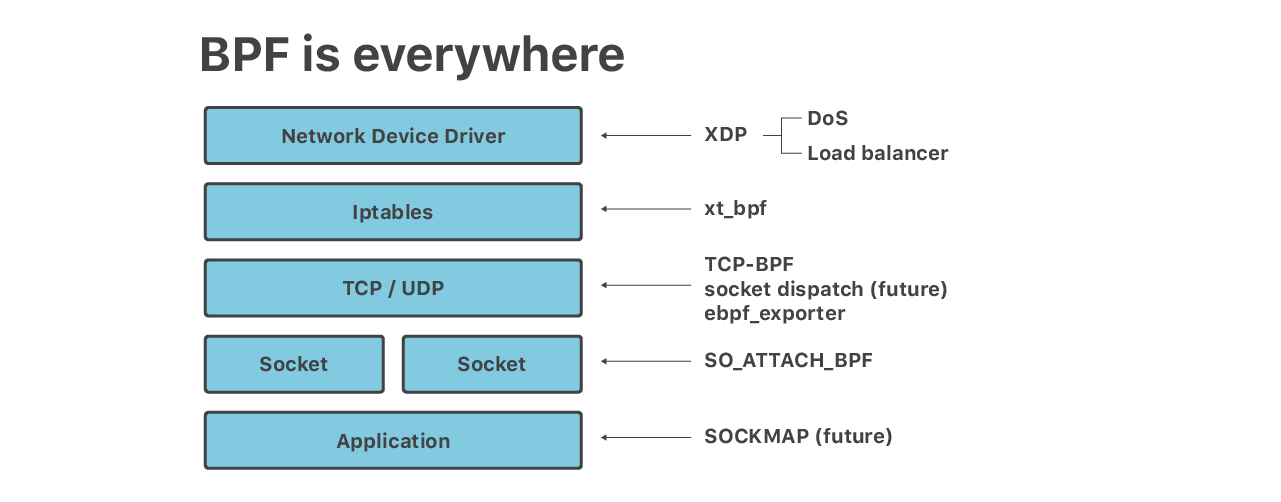
在本次演讲中,我们讨论了在边缘服务器上运行的6层BPF:
- 正在XDP eBPF上运行的批量DoS缓解措施
- 用于应用层攻击的Iptables xt_bpf cBPF
- 用于UDP套接字速率限制的SO_ATTACH_BPF
- 在XDP上运行的负载均衡器
- 用于运行应用帮助进程的eBPF,例如用于TCP套接字粘合的SOCKMAP和用于TCP测量的TCP-BPF
- 用于获取精细指标的“ebpf_exporter”
我们才刚刚开始!很快,我们将在基于eBPF的套接字调度、在Linux TC(流量控制)层上运行的eBPF以及与控制组eBPF挂载的更多集成上完成更多的工作。然后,我们的SRE团队将维护不断增长的BCC脚本列表,这些脚本对于调试非常有用。
感觉就像Linux停止了开发新的API一样,所有的新特性都要通过eBPF挂载和帮助进程来实现。这很好,并且具有强大的优势。升级eBPF程序比重新编译内核模块更容易、更安全。如果没有eBPF,那么像TCP-BPF之类展现大量性能跟踪数据的东西可能是无法实现的。
有的人说:“软件正在占据世界”,但我想说:“BPF正在占据软件”。