


介紹
今天,我們滿懷欣喜之情來談論 Pingora,這是我們使用 Rust 在內部構建的全新 HTTP 代理程式 ,其每天可處理超過 1 萬億個請求,能提高我們的效能,並為 Cloudflare 客戶實現眾多新功能,同時只需之前代理基礎結構三分之一的 CPU 和記憶體資源。
隨著 Cloudflare 的擴展,我們已經因發展而不再需要 NGINX。多年來,NGINX 一直備受追捧,但隨著時間的推移,其在規模上存在局限性,這意味著需要構建新的代理來實現。我們無法再獲得所需的效能,NGINX 也不具備極其複雜的環境所需的各項功能。
許多 Cloudflare 客戶和使用者將 Cloudflare 全球網路用作 HTTP 用戶端(如 Web 瀏覽器、應用程式、IoT 裝置等)與伺服器之間的代理。過去,關於瀏覽器和其他使用者代理程式如何連線至我們的網路,我們已經討論了很多,並且已經開發了許多技術並實施了新的通訊協定(請參閱 QUIC 和 HTTP2 最佳化),以使該連線網段更具效率。
如今,我們專注於同等事項的另一部分:代理傳送我們的網路與網際網路伺服器間流量的服務。此代理服務為我們的 CDN、Workers 擷取、Tunnel、Stream、R2,以及許多其他功能和產品提供支援。
我們來深入瞭解我們為什麼選擇取代舊式服務,以及如何開發 Pingora,這是我們針對 Cloudflare 的客戶使用案例和規模設計的全新系統。
為什麼要構建另一個代理
多年來,NGINX 的使用面臨局限性。對於某些局限性,我們已最佳化或解決。但其他一些則更難以克服。
架構局限性會損害效能
NGINX 工作者(處理序)架構在我們的使用案例中具有操作上的不足,這會損害效能和效率。
首先,在 NGINX 中,每個請求只能由單一工作者提供服務。這會導致所有 CPU 內核間的負載不平衡,進而減慢速度。
由於這種請求-處理序固定效應,執行 CPU 密集型或封鎖 IO 任務的請求可能會減慢其他請求的速度。正如這些部落格文章所證實的那樣,我們花費了大量時間來解決這些問題。
對於我們的使用案例而言,最關鍵的問題是連線重複使用表現較差。機器與原始伺服器建立 TCP 連線,以代理傳送 HTTP 請求。連線重複使用可透過重複使用連線集區中之前建立的連線,跳過新連線所需的 TCP 和 TLS 握手,來加速請求的 TTFB(第一個位元組接收時間)。
然而, NGINX 連線集區會針對每個工作者。當請求登陸某個工作者時,它只能重複使用該工作者中的連線。若新增更多 NGINX 工作者進行擴展,則連線重複使用率會變得更糟,因為連線分散在所有處理序更孤立的集區中。這會導致 TTFB 速度變慢,需要維護的連線也會更多,進而消耗我們和我們客戶的資源(和資金)。
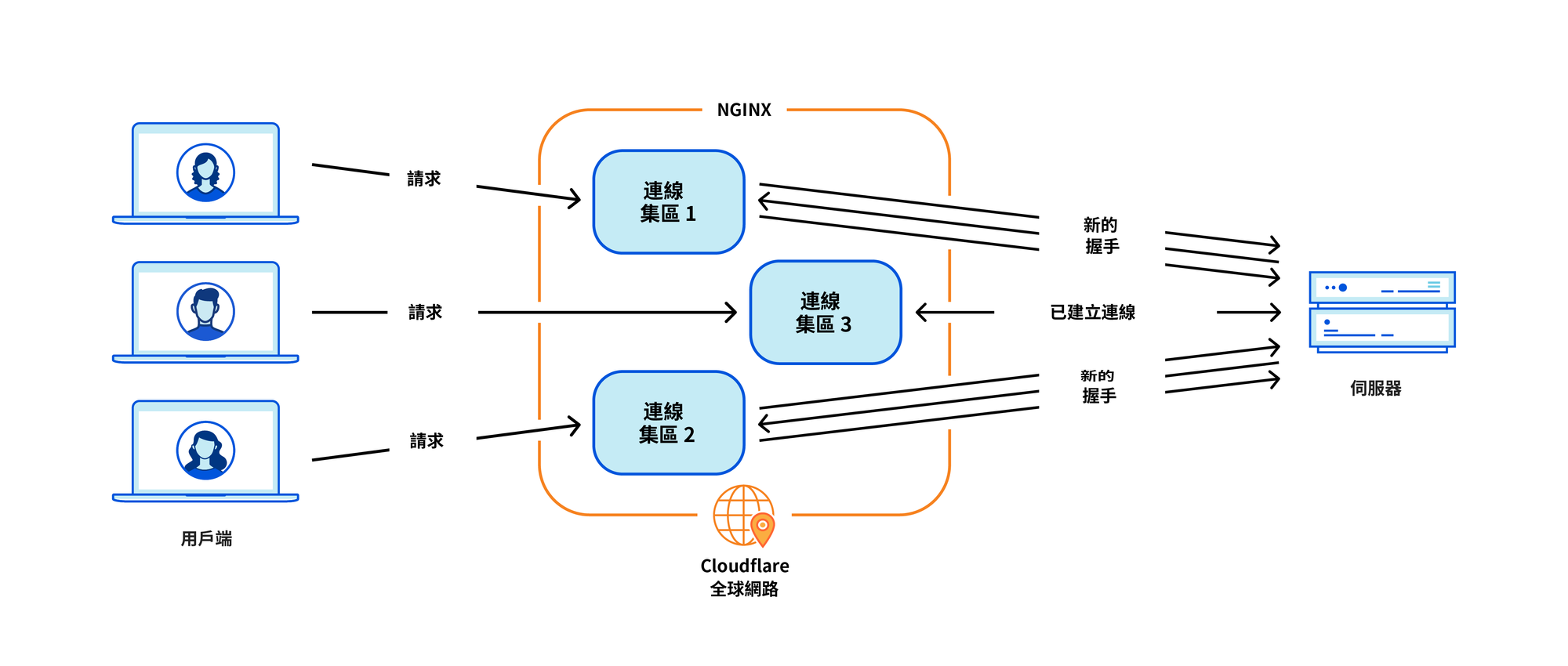
正如如過去的部落格文章中所述,我們提供了其中一些問題的因應措施。但如果能解決根本問題:工作者/處理序模型,這些問題將迎刃而解。
新增某些類型的功能困難重重
NGINX 是非常好的 Web 伺服器、負載平衡器或簡單的閘道。但 Cloudflare 所做的遠不止於此。我們曾在 NGINX 的基礎上構建需要的所有功能,這並非易事,同時盡量不與 NGINX 上游程式碼庫產生太大差異。
例如,在請求重試/容錯移轉時,我們有時希望將請求傳送至具有不同請求標頭集的不同原始伺服器。但 NGINX 不允許這樣操作。在這種情況下,我們要花費時間和精力來解決 NGINX 因應條件約束。
與此同時,我們必須使用的程式設計語言並沒有幫助緩解困難。NGINX 純粹採用 C 語言,這在設計上並非記憶體安全。使用此類第三方程式碼庫非常容易出錯。即使對於經驗豐富的工程師來說,也很容易遇到記憶體安全問題,而我們希望盡可能避免這些問題。
我們使用另一種語言 Lua 來作為 C 語言的補充。其風險更小,但效能也更低。此外, 在處理複雜的 Lua 程式碼和業務邏輯時,我們經常發現自己缺少靜態類型。
而且,NGINX 社群不太活躍,開發往往「閉門造車」。。
決定自己開闢道路
在過去幾年中,隨著我們不斷擴大客戶群和功能集,我們對三種選擇持續進行評估:
- 繼續投入 NGINX 並可能建立分支,使其 100% 符合我們的需求。我們擁有所需的專業知識,但考慮到上述架構局限性,這需要付出巨大的努力,才能以完全支援我們需求的方式重建。
- 遷移至另一個第三方代理程式碼庫。肯定有很好的專案,例如 envoy 和其他方案。但這條路徑意味著可能會在幾年內重複同樣的迴圈。
- 從頭開始構建內部平台和架構。這種選擇需要在工程工作方面進行最大的前期投資。
在過去幾年中,我們每個季度都會評估每一種選擇。沒有顯而易見的公式來判斷哪種選擇最好。幾年來,我們不斷走阻力最小的路徑,繼續增強 NGINX。然而,在某些時候,構建專屬代理的投資報酬率似乎很值得。我們呼籲從頭開始構建代理,並開始設計我們夢想中的代理應用程式。
Pingora 專案
設計決策
為了讓代理能夠針對每秒數百萬個請求,快速、高效、安全地提供服務,我們首先必須做出一些重要的設計決策。
我們選擇 Rust 作為該專案的語言,因為它能夠以記憶體安全的方式,來執行 C 語言可執行的操作,而不會影響效能。
雖然有一些絕佳的現成第三方 HTTP 程式庫,如 hyper,但我們選擇構建自己的專屬程式庫,因為我們希望最大限度地提高處理 HTTP 流量的靈活性,並確保可以按照自己的節奏來進行創新。
在 Cloudflare,我們需要處理整個網際網路上的流量。還需要支援種種稀奇古怪、不符合 RFC 的 HTTP 流量。這是 HTTP 社群和 Web 中常見的困境,即如何在嚴格遵循 HTTP 規範的同時,適應潛在舊式用戶端或伺服器廣泛生態系統的細微差別,這兩者之間存在矛盾。選擇哪一方面都可能十分棘手。
在 RFC 9110 中,HTTP 狀態代碼被定義為一個三位整數,通常應在 100 至 599 的區間。Hyper 就是這樣一種實作。不過,許多伺服器也支援使用介於 599 和 999 之間的狀態代碼。https://github.com/hyperium/http/issues/144這種衝突曾引發過激烈的爭論。雖然 hyper 團隊最終接受了這一變更,但他們也有充分的理由拒絕此類要求,而這只是我們需要支援的眾多不合規行為的冰山一角。
為了滿足 Cloudflare 在 HTTP 生態系統中佔主導地位的要求,我們需要一個強大、寬鬆、可定製的 HTTP 程式庫,以適應網際網路上的狂野法則,並支援種種不合規的使用案例。保證這一點的最佳方法是實作內部代理。
下一項設計決策圍繞工作負載排程系統。我們選擇了多執行緒,而非多處理序,以便輕鬆共用資源,尤其是連線集區。我們還決定,需要用竊取機制來避免上述某些類別的效能問題。事實證明,Tokio 非同步執行時間非常符合我們的需求。
最後,我們希望該專案直觀且對開發人員友好。我們構建的並非最終產品,而應當是可擴展的平台,允許在其上構建更多功能。我們決定實作一個類似於 NGINX/OpenResty、基於「請求生命週期」事件的可程式設計介面。例如,「請求篩選條件」階段允許開發人員在收到請求標頭時執行程式碼,進而修改或拒絕請求。透過這種設計,我們就能清晰地將業務邏輯和一般代理邏輯分開。之前使用 NGINX 的開發人員也能輕鬆轉向 Pingora 並迅速提高工作效率。
Pingora 在生產中速度更快
我們快進到現在。Pingora 在處理幾乎所有需要與原始伺服器互動的 HTTP 請求(例如,快取未命中的情況),並且我們在此期間收集了大量效能資料。
首先,我們來看看 Pingora 如何加速客戶流量。Pingora 上的總體流量顯示,TTFB 中位數減少了 5 毫秒,第 95 百分位減少了 80 毫秒。這並不是因為我們執行程式碼的速度更快。畢竟舊式服務也能處理亞毫秒級的請求。
成本節省源自我們的新架構,它可以跨所有執行緒間共用連線。這意味著連線重複使用率提升,進而在 TCP 和 TLS 握手上所花費的時間相應地縮短。
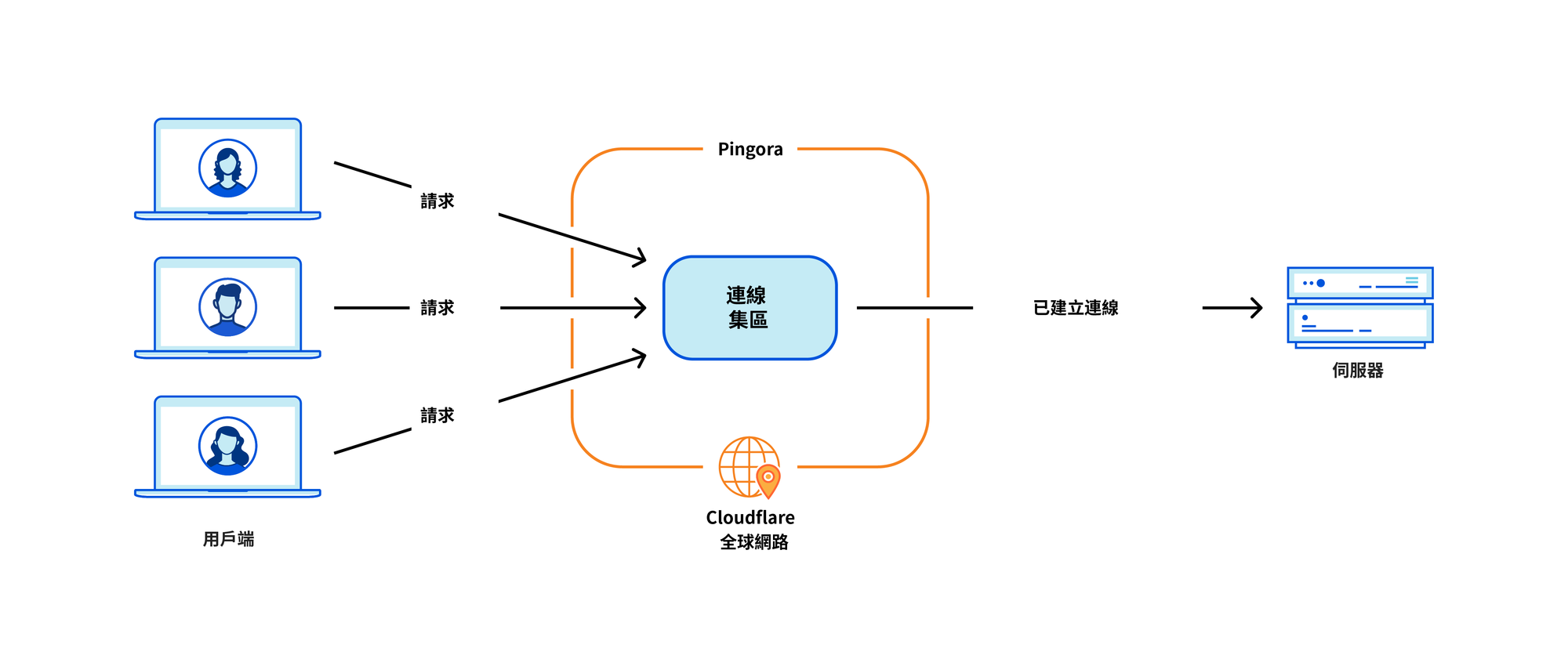
相較於舊服務,Pingora 將所有客戶的每秒新連線用量降低至三分之一。針對其中一個主要客戶,其連線重複使用率從 87.1% 提高至 99.92%,從而將與其原本的新連線數減少了 160倍。以下數據可直觀地呈現這種變化︰轉向 Pingora 之後,我們每天能夠為客戶和使用者節省 434 年的握手時間。
更多功能
有了工程師熟悉的開發人員友好型介面,又消除了之前的條件約束,這讓我們能夠更快地開發出更多功能。憑藉新通訊協定等核心功能,我們可以為客戶提供更多產品構建區塊。
例如,我們能夠在無重大障礙的情況下,向 Pingora 新增 HTTP/2 上游支援。這讓我們很快就能為客戶提供 gRPC。要將這項功能新增至 NGINX,不僅涉及的工程量更大,並且可能無法實現。
最近,我們發佈了 Cache Reserve,Pingora 在其中使用 R2 儲存作為快取層。隨著我們向 Pingora 新增更多功能,我們能夠提供各種開創性的新產品。
更有效率
在生產環境中,面對同等流量的負載,相較於舊服務,Pingora 的 CPU 消耗量減少了約 70%,記憶體消耗量減少了 67%。成本節省源自以下幾大因素。
相較於舊的 Lua 程式碼,我們的 Rust 程式碼執行效率更高。最重要的是,二者在架構上也存在效率差異。例如,在 NGINX/OpenResty 中,當 Lua 程式碼想要存取 HTTP 標頭時,必須從 NGINX C 結構中讀取、分配一個 Lua 字串,然後將其複製到 Lua 字串。之後,Lua 還必須對新字串進行垃圾回收。而 Pingora 能直接執行字串存取。
多執行緒模型也讓跨請求共用資料變得更加高效。NGINX 雖然也提供記憶體共用,但由於實作局限性,每次共用記憶體存取都必須使用互斥鎖,而且只能將字串和數字放入共用記憶體中。在 Pingora 中,大多數共用項都能透過原子引用計數器後的共用引用直接存取。
如上所述,實現 CPU 節省的另一個重要因素是建立更少的新連線。Pingora 可透過已建立的連線來傳送和接收資料,不會造成高昂 TLS 握手成本。
更安全
快速、安全地發佈功能絕非易事,在我們這樣龐大的規模下更是困難重重。在分散式環境中每秒要處理數百萬個請求,很難預測可能會發生的每種極端情況。模糊測試和分析的緩解作用也有限。Rust 的記憶體安全語義保護挺身而出,在保護我們免受未定義行為影響的同時,也讓我們堅信自己的服務將會正常運作。
有了這些保證,我們可以更多地關注服務變更將如何與其他服務或客戶來源互動。我們還能以更快的節奏開發功能,而不會因記憶體安全和難以診斷的崩潰而受到拖累。
當崩潰確實發生時,工程師需要花時間診斷崩潰如何發生,以及導致崩潰的原因。自 Pingora 運作以來,我們已處理數百萬億個請求,但還沒有遇到過源於服務代碼的崩潰問題。
實際上,Pingora 崩潰非常罕見,每次出現的問題都跟 Pingora 自身沒什麼關係。最近,我們在服務崩潰後不久發現了一個內核錯誤。我們還在幾部機器上發現了硬體問題,而在過去,要排除由軟體引起的罕見記憶體錯誤,即使進行重大偵錯也無法實現。
結論
總而言之,我們已構建了一個更快、更高效和更通用的內部代理,並將其作為我們目前和未來產品的平台。
我們將重新將視線更多地集中到技術細節,包括我們面臨的問題、我們運用的最佳化、我們從構建 Pingora 中學到的經驗教訓,以及將其推廣到網際網路的重要部分。我們還將帶著開放原始碼方案再次回歸。
Pingora 是我們重寫系統的最新嘗試,但絕不會是最後一次。它也只是我們系統重新架構的其中一個構建區塊。有興趣加入我們協助打造更完善的網際網路嗎? 我們的工程團隊正在招賢納士。