

目前,Cloudflare Radar 在服務中斷中心中發佈了觀察到的網際網路中斷清單(可能包括部分或完全服務中斷)。只要我們能夠透過檢查 ISP 的狀態更新和相關發佈,或者查找與電纜切斷、政府命令、停電或自然災害相關的新聞報導,找到與觀察到的流量下降相關聯的背景資訊,我們就會記錄這些中斷。
然而,我們觀察到的中斷情況要多於我們目前在服務中斷中心報告的情況,因為在有些情況下,儘管我們仍然能夠透過外部資料來源(如 Georgia Tech 的 IODA)進行驗證,但我們無法找到任何資訊來源為我們觀察到的情況提供可能的原因。這一整理過程需要人工作業,並由內部工具提供支援,使我們能夠分析流量並自動偵測異常,從而觸發工作流程,找到相關的根本原因。雖然 Cloudflare Radar 服務中斷中心是一個寶貴的資源,但其中一個主要缺點是我們沒有報告所有的中斷情況,而且當前的整理流程並不像我們希望的那樣及時,因為我們仍需要找到背景情況。
正如我們今天在相關部落格文章中宣佈的那樣,Cloudflare Radar 將發佈有關國家/地區和自發系統 (AS) 的異常流量事件。這些事件與上面提到的事件相同,它們觸發了我們用於驗證和確認中斷的內部工作流程。(請注意,這裡的「異常流量事件」與流量下降相關,而不是意外的流量暴增。)除了將流量異常資訊新增到服務中斷中心外,我們還推出了使用者可以在位置或網路(自發系統)層級訂閱通知的功能:每當偵測到新的異常事件,或服務中斷表格中新增了新的項目,都會收到通知。有關如何訂閱的更多詳細資訊,請參閱相關部落格文章。
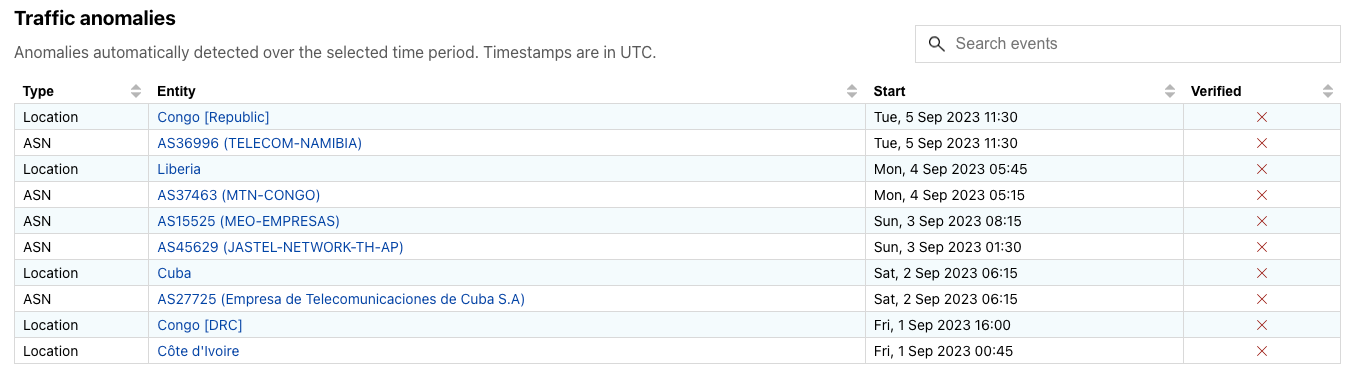
每個偵測到的異常的當前狀態將顯示在服務中斷中心頁面上新的「流量異常」表格中:
- 自動偵測到異常時,其初始狀態為
未驗證 - 嘗試驗證「未驗證」項目後:
- 如果我們能確認異常情況出現在多個內部資料來源中,以及出現在外部資料來源中,我們將把狀態變更為「已驗證」。如果我們找到了相關的背景資訊,我們也將建立一個服務中斷項目。
- 如果無法透過多個資料來源確認,我們將把狀態變更為「誤判」。這將把它從「流量異常」表格中移除。(如果已傳送通知,但該異常不再顯示在 Radar 中,則表示我們已將其標記為「誤判」)。
- 我們也可以手動新增「已驗證」狀態的項目。如果我們觀察到流量的明顯下降並已經過驗證,但下降幅度不足以讓演算法擷取到,就可能出現這種情況。
網際網路流量一覽
在 Cloudflare,我們擁有多個內部資料來源,可以讓我們深入瞭解特定實體的流量情況。我們根據 IP 位址地理位置(對於位置)和 IP 位址配置(對於 AS)來識別實體,並且可以分析來自不同來源的流量,例如 DNS、HTTP、NetFlow 和網路錯誤記錄 (NEL)。下圖中使用的所有訊號都來自這些資料來源之一,在這篇部落格文章中,我們將其視為單變數時間序列問題——在當前的演算法中,我們使用多個訊號只是為了增加備援並以更高的置信度識別異常。在下面的討論中,我們有意選擇各種範例,以涵蓋廣泛的潛在網際網路流量場景。
1. 理想情況下,澳大利亞 (AU) 的訊號類似於下面所示的模式:穩定的週模式,有輕微的正趨勢,這意味著趨勢平均值隨著時間的推移而上升(我們看到來自澳大利亞使用者的流量隨著時間的推移而增加)。
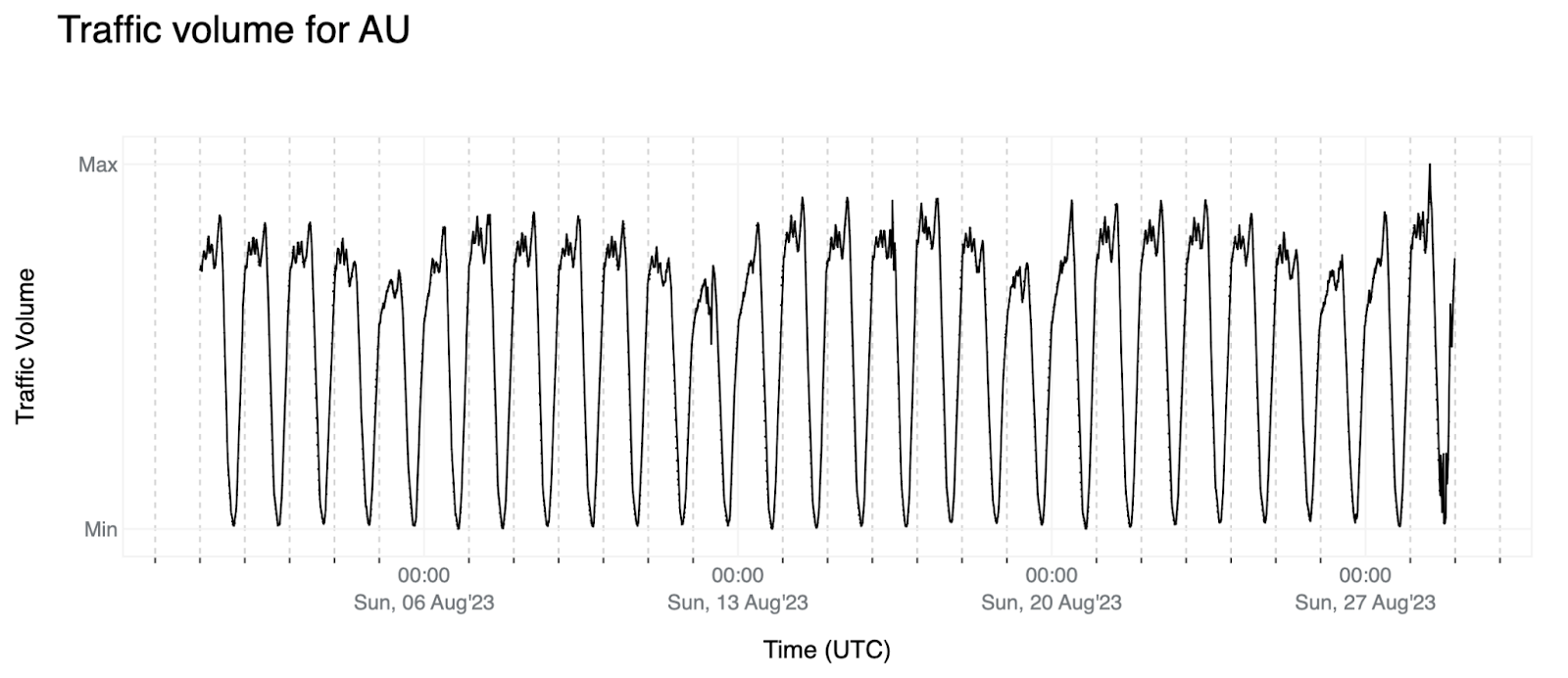
當我們執行時間序列分解時,可以清楚地看到這些陳述,這使我們能夠將時間序列分解為其組成部分,以更好地理解和分析其底層模式。使用 Seasonal-Trend decomposition using LOESS (STL) 假設一個每週模式並分解澳大利亞的流量,我們得到以下結果:
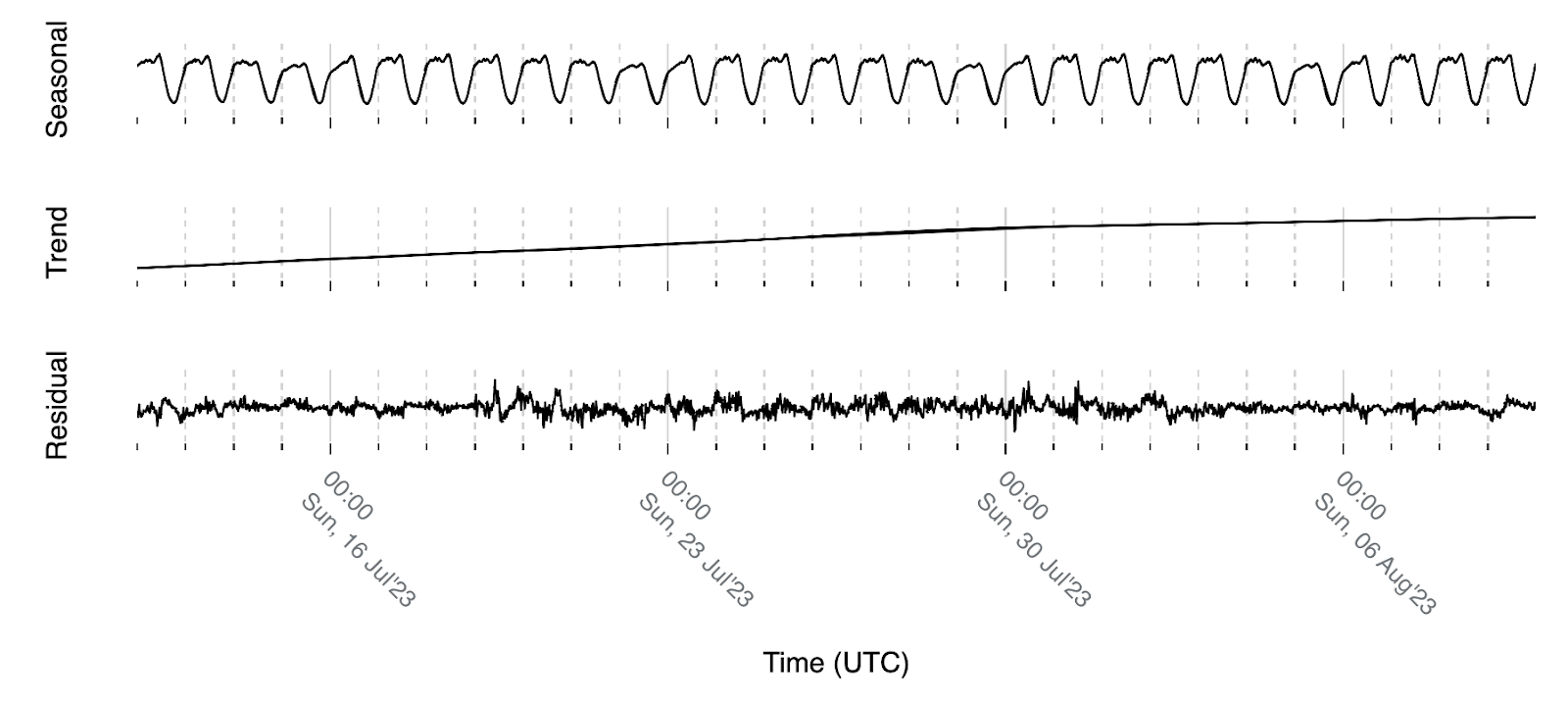
我們所說的每週模式是指訊號的季節性部分,由於我們關注的是人類網際網路流量,這是一個預計會觀察到的訊號。如上圖所示,與訊號水準相比,趨勢分量預計會緩慢移動,殘差部分理想情況下類似於白色雜訊,這意味著訊號中所有現有的模式都由季節和趨勢分量表示。
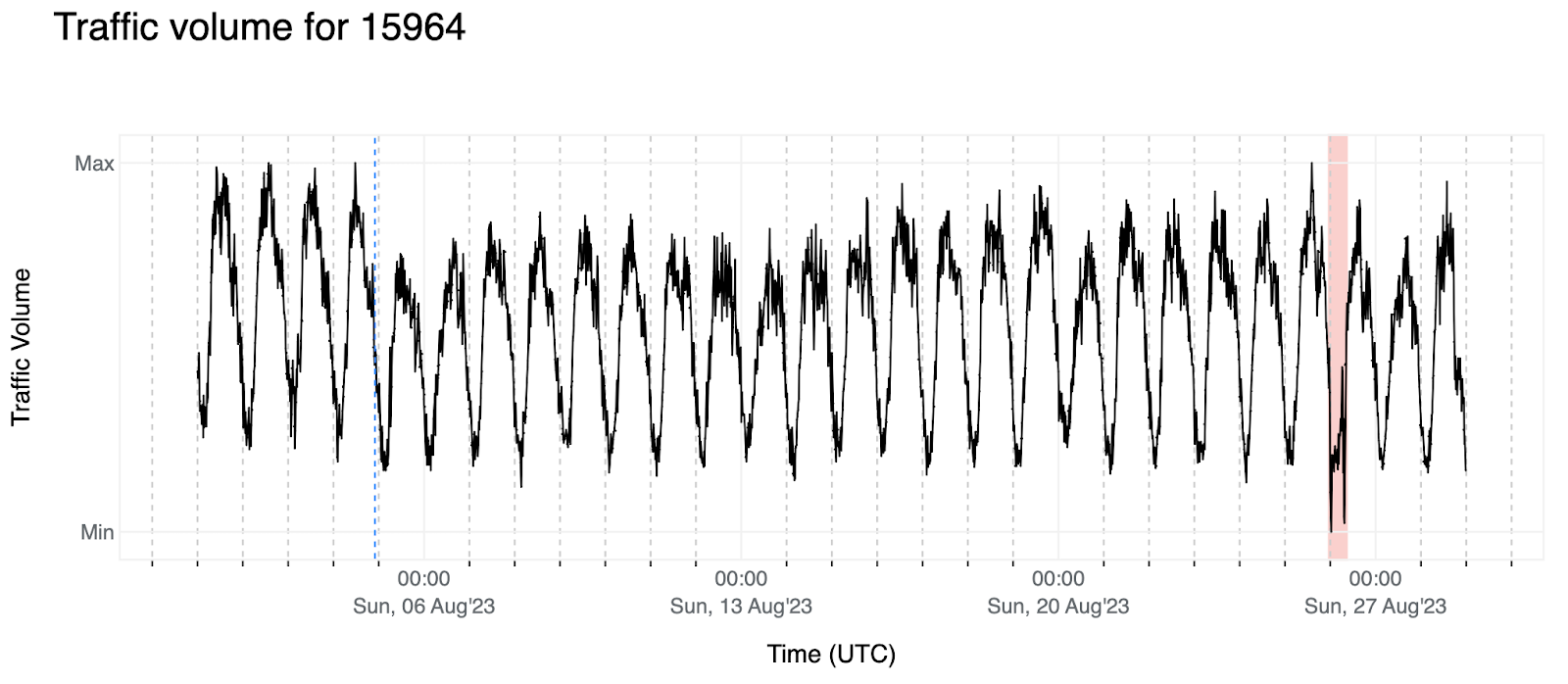
2. 下面我們列出了 AS15964 (CAMNET-AS) 的流量,該流量似乎更多的是每日模式,而不是每週。
我們還觀察到,訊號值在前四天后出現了偏移(藍色虛線),紅色背景顯示了一次服務中斷,除了在我們的資料和其他網際網路資料提供者的資料中看到了這次服務中斷外,我們沒有找到任何相關報告——我們的目的是開發一種演算法,在遇到這種或類似模式時觸發事件。
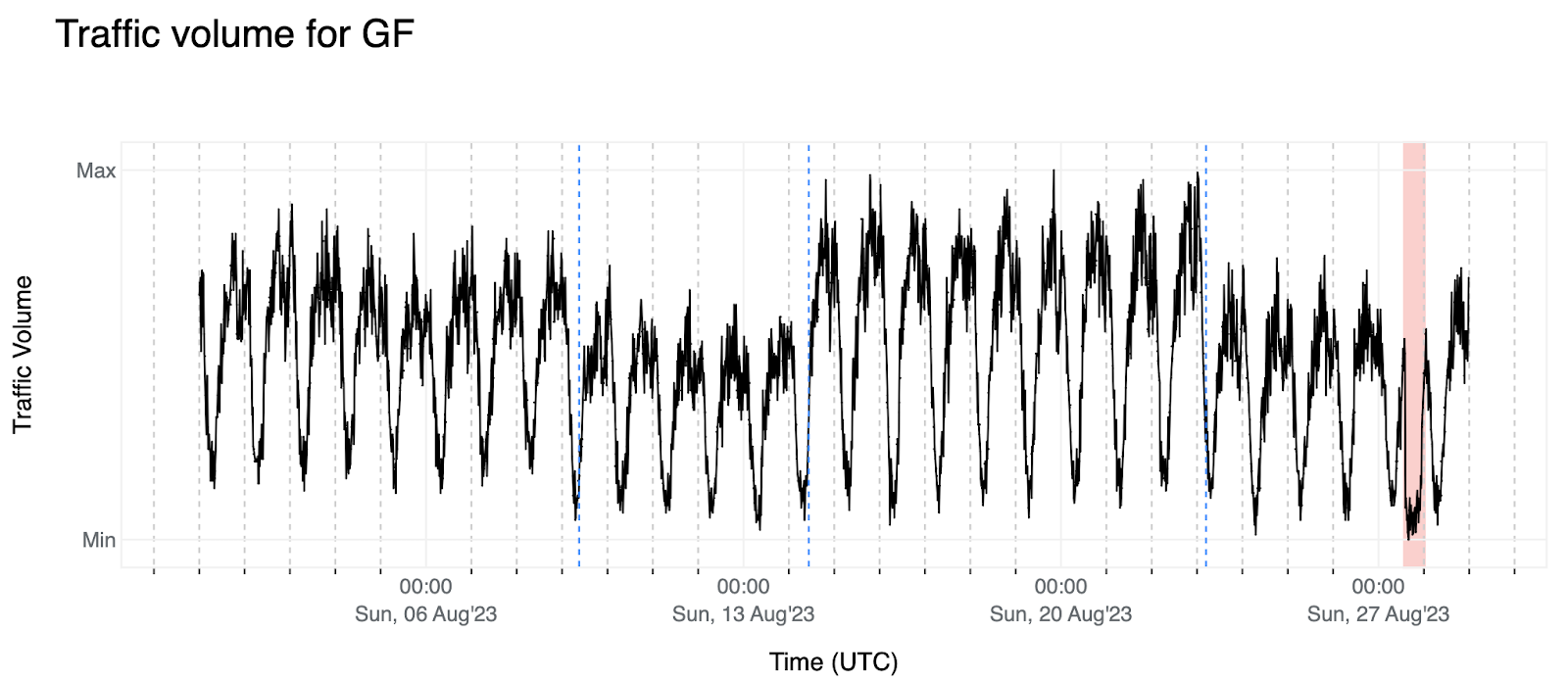
3. 下面是法屬圭亞那 (GF) 的類似範例。我們觀察到一些資料偏移(8 月 9 日至 23 日)、幅度變化(8 月 15 日至 23 日之間),以及我們在 Cloudflare Radar 中觀察到的另一次服務中斷,對於此次中斷,我們獲得了相關背景資訊。
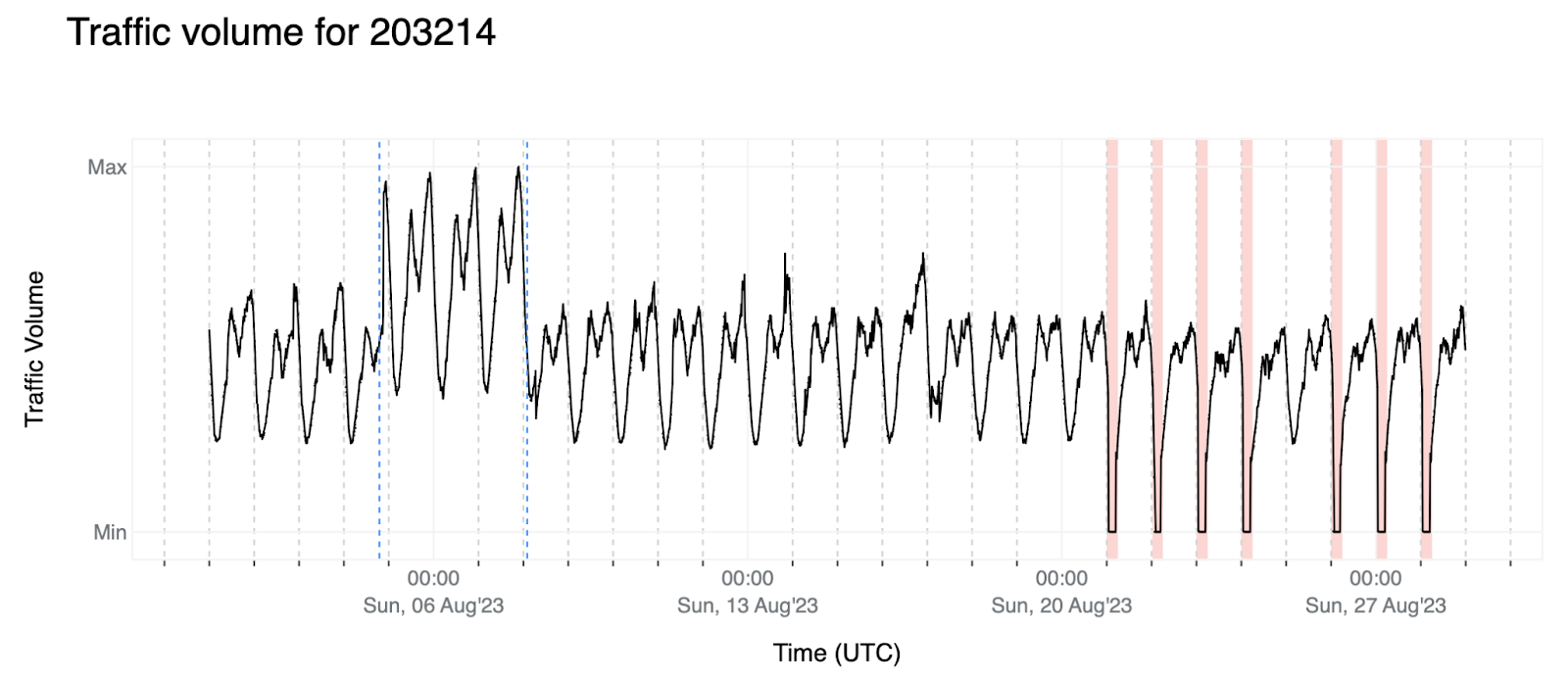
4. 另一個範例是 AS203214 (HulumTele) 的幾次計劃中斷,我們也獲得了相關背景資訊。這些異常是最容易偵測到的,因為流量值僅會在發生服務中斷時出現(不會被誤認為是正常流量),但這也帶來了另一個挑戰:如果我們的計畫只是檢查每週模式,由於這些政府指令的中斷以相同的頻率發生,在某些時候,演算法會將其視為預期流量。
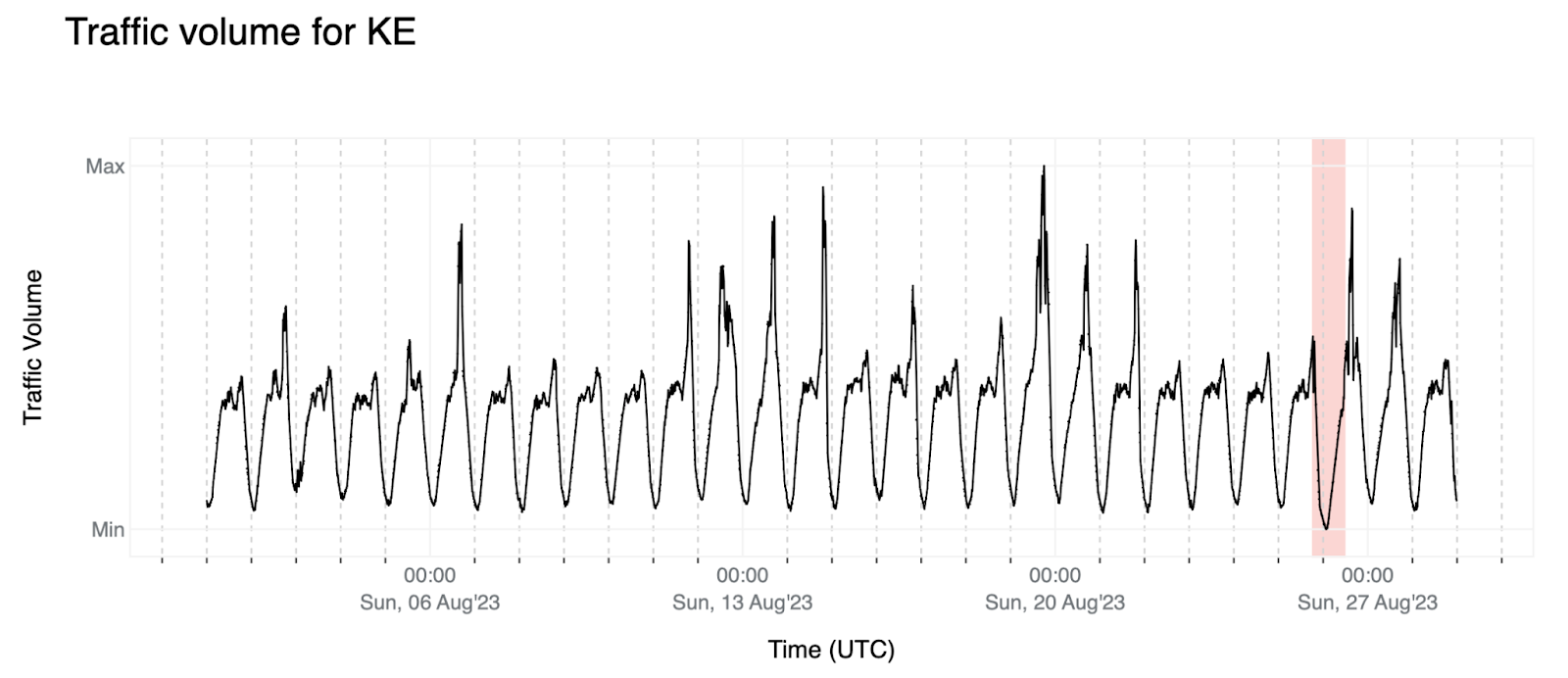
5. 肯亞的這次服務中斷可以看作與上述事件類似:流量下降到幾乎看不見。我們還觀察到資料中存在一些不遵循任何特定模式的向上峰值(可能是異常值),我們應該根據我們用於建模時間序列的方法來清理這些峰值。
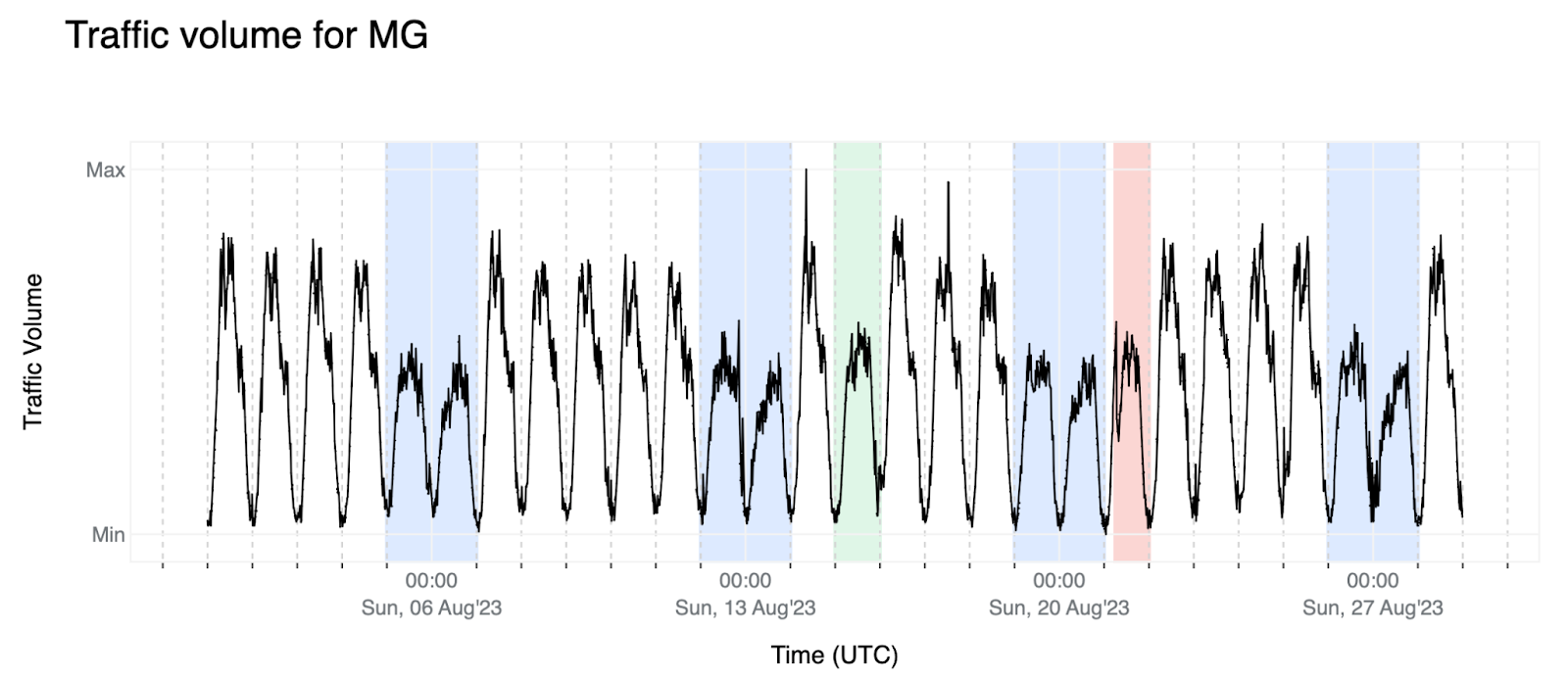
6. 最後,下面是本文中全篇將使用的資料,作為我們如何解決此問題的範例。對於馬達加斯加 (MG),我們觀察到明顯的週末模式(藍色背景)。還有一個節日(聖母蒙召升天節),以綠色背景突出顯示,以及一次服務中斷,以紅色背景突出顯示。在此範例中,週末、節日和服務中斷的流量似乎都大致相同。幸運的是,這次服務中斷顯示出了它自己的資訊,即本來打算像正常工作日一樣上升,但隨後卻突然下降——我們將在後文中更詳細地介紹這一點。
總之,在這裡,我們查看了約 700 個執行個體(這是我們目前自動偵測異常的實體數量)中的 6 個執行個體,我們看到了廣泛的可變性。這意味著,為了有效地對時間序列進行建模,我們必須在建模之前執行大量的預先處理步驟。這些步驟包括移除異常值,偵測短期和長期資料偏移並重新調整,以及偵測方差、平均值或幅度的變化。時間也是預先處理中的一個因素,因為我們還需要提前知道何時會有活動/節假日(這會導致流量下降)、何時套用夏令時調整(這會導致資料時間轉移),並能夠為每個執行個體套用本地時區,包括處理有多個時區的地點和跨時區共用的 AS 流量。
更為棘手的是,其中一些步驟甚至無法以接近即時的方式進行(例如:我們只能在觀察新模式一段時間後才能說發生了季節性變化)。考慮到前面提到的挑戰,我們選擇了一種將基本預先處理和統計相結合的演算法。這種方法符合我們對資料特徵的預期,易於解釋,允許我們控制誤判率,並確保快速執行,同時減少對前面討論的許多預先處理步驟的需求。
在上文中,我們注意到我們在啟動時偵測到了大約 700 個實體(地點和自發系統)的異常。這顯然不能代表所有國家/地區和網路,而這一數字也有其充分的理由。正如我們在這篇文章中討論的那樣,我們需要看到來自特定實體的足夠多的流量(有足夠強的訊號),才能建立相關模型並隨後偵測到異常。對於一些較小或人口稀少的國家/地區來說,流量訊號的強度根本不夠,而對於許多自發系統來說,我們幾乎看不到來自它們的流量,這同樣導致訊號太弱而無法發揮作用。我們最初將重點放在流量訊號足夠強和/或可能出現流量異常的地點,以及主要或值得注意的自發系統——這些自發系統在一個地點的人口中佔有相當大的比例,和/或已知過去曾受到流量異常的影響。
偵測異常
我們解決這個問題的方法是建立一個預測,即根據我們在歷史資料中看到的情況,建立一組與我們的預期相對應的資料點。這將在「建立預測」一節中解釋。我們將這一預測與我們實際觀測到的情況進行比較,如果我們觀測到的情況與我們的預期大相徑庭,我們就稱之為異常。在這裡,由於我們關注的是流量下降,因此異常始終是指流量低於預測/預期的情況。這種比較將在「預測與實際流量的比較」一節中詳細闡述。
為了計算預測,我們需要滿足以下業務要求:
- 我們主要關注與人類活動有關的流量。
- 異常情況發現得越及時,就越有用。這需要考慮到資料擷取和資料處理時間等限制因素,但一旦資料可用,我們就應該能夠使用最新的資料點,並偵測其是否異常。
- 低假陽性 (FP) 率比高真陽性 (TP) 率更重要。作為一個內部工具,這不一定正確,但作為一個公開可見的通知服務,我們希望以不報告某些異常情況為代價來限制虛假項目項目。
選擇要觀察的實體
除了上面給出的範例之外,資料的品質很大程度上取決於資料量,這意味著根據我們正在考慮的實體(位置/AS),我們具有不同層級的資料品質。舉一個極端的例子,我們沒有足夠的來自南極洲的資料來可靠地偵測服務中斷情況。下面是我們用來選擇哪些實體有資格被觀察的流程。
對於 AS,由於我們主要對代表人類活動的網際網路流量感興趣,因此我們使用 APNIC 提供的使用者估計數量。然後,我們透過匯總該位置中每個 AS 的使用者數量來計算每個位置的使用者總數,然後計算該位置的 AS 的使用者百分比(這一數字也由 APNIC 表格中「國家/地區百分比」欄提供)。我們篩選掉該位置使用者數量少於 1% 的 AS。葡萄牙的清單如下:AS15525 (MEO-EMPRESAS) 被排除在外,因為它的使用者數量不到葡萄牙網際網路使用者總數(估計值)的 1%。
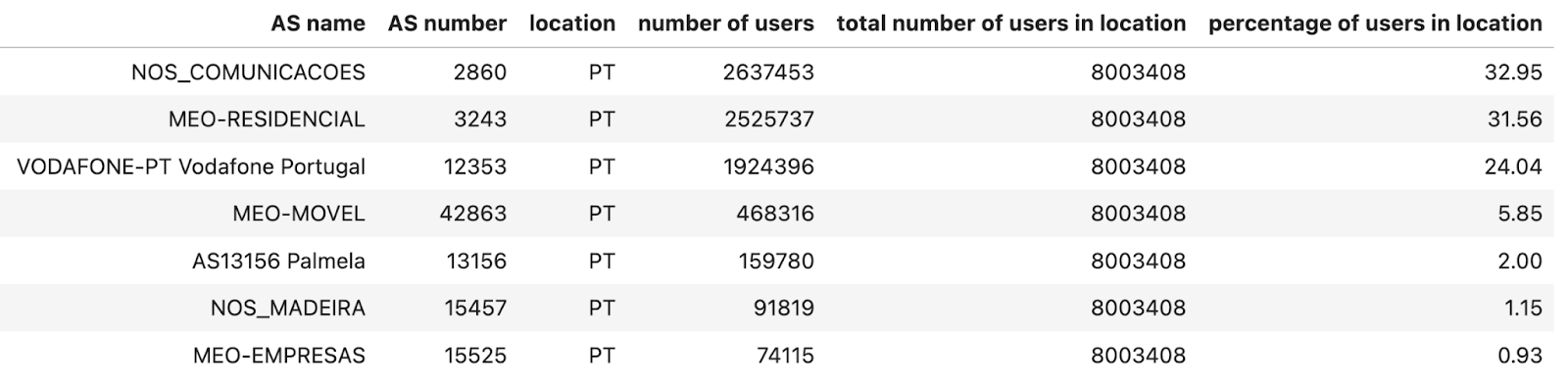
此時,我們有一個 AS 子集和一組位置(我們不會先驗地排除任何位置,因為我們希望覆蓋盡可能多的位置),但我們必須根據資料的品質縮小範圍,以便能夠可靠地自動偵測異常。在測試了多個指標並對結果進行視覺化分析後,我們得出的結論是,穩定訊號的最佳預測因素與資料量有關,因此我們移除了不滿足兩週內每日唯一 IP 最低數量標準的實體——該閾值基於直觀檢查。
建立預測
為了及時偵測異常,我們決定採用每十五分鐘聚合一次的流量,並預測一小時的資料(四個資料點/十五分鐘的資料塊),與實際資料進行比較。
選定要偵測異常的實體後,方法就非常簡單了:
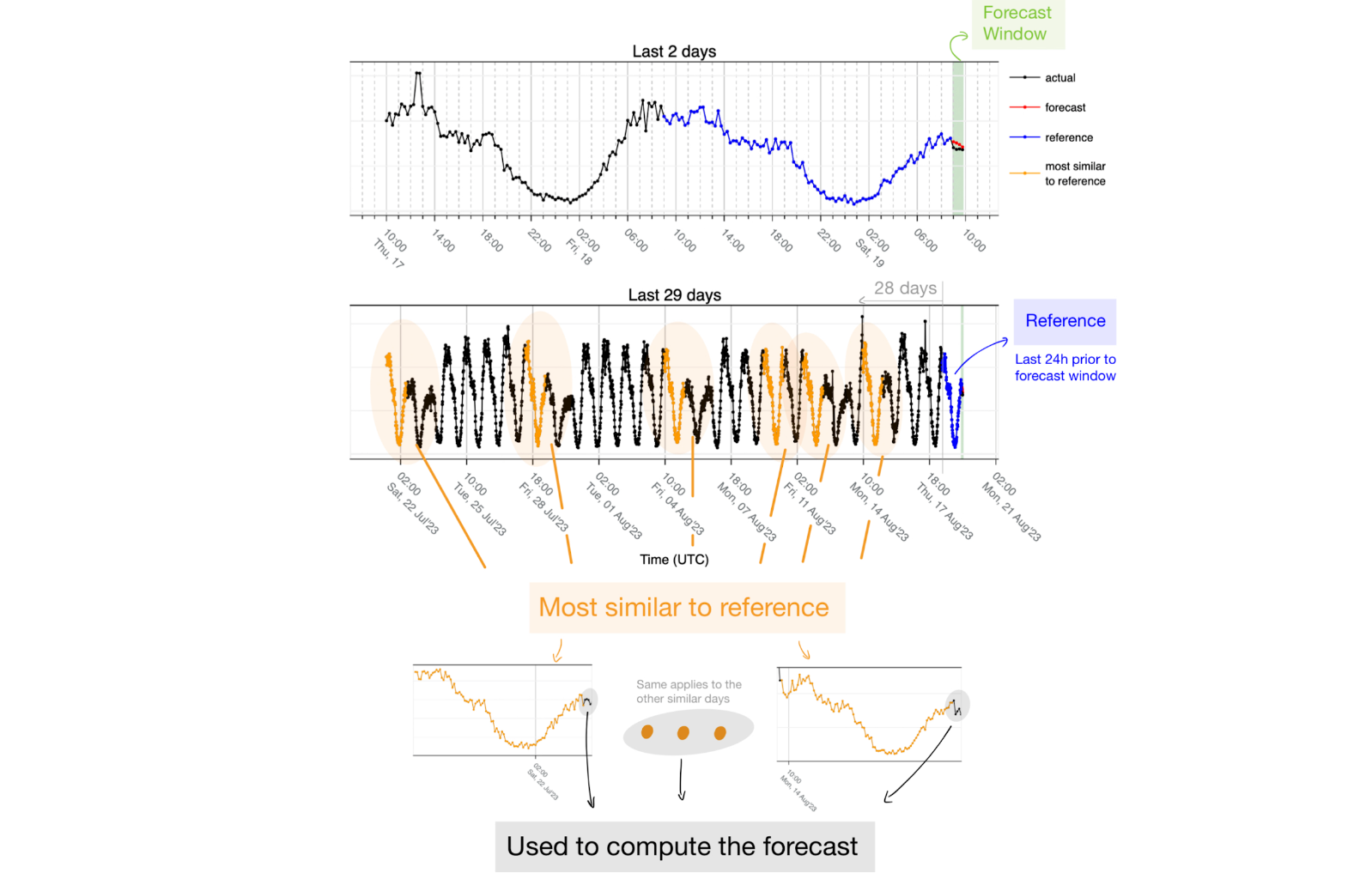
1. 我們查看預測時間段之前的最後 24 小時,並使用該時間間隔作為參照物。我們的假設是,過去 24 小時將包含有關後續走勢的資訊。在下圖中,過去 24 小時(藍色)對應的是從週五過渡到週六的資料。透過使用歐幾裡德距離,我們得到了與該參照物(橙色)最相似的六個匹配——這六個匹配中的四個對應於從週五到週六的其他過渡。它還擷取了週一(2023 年 8 月 14 日)到週二的假期,我們還看到了一個與參照物最不相似的匹配,即從週三到週四的正常工作日。擷取到一個不能正確代表參照物的資料應該不成問題,因為預測結果是與參照物最相似的 24 小時的中位數,因此,這一天的資料最終會被捨棄。
- 為了使這種方法發揮作用,我們使用了兩個重要參數:
- 我們考慮的是最近 28 天(加上參照日等於 29 天)。這樣,我們就能確保每週的季節性至少能看到 4 次,控制了趨勢隨時間變化而變化的風險,並為我們需要處理的資料量設定了上限。從上面的範例來看,第一天是與參照相似度最高的一天,因為它對應著從週五到週六的過渡。
- 另一個參數是最相似天數。我們使用六天是基於經驗知識:考慮到每週的季節性,當使用六天時,我們預計最多有四天與同一工作日相吻合,然後還有兩天可能完全不同。由於我們使用中位數來建立預測,因此大多數天數仍然是 4 天,這些額外的天數最終沒有被用作參照。另一種情況是節假日,例如下面的範例:
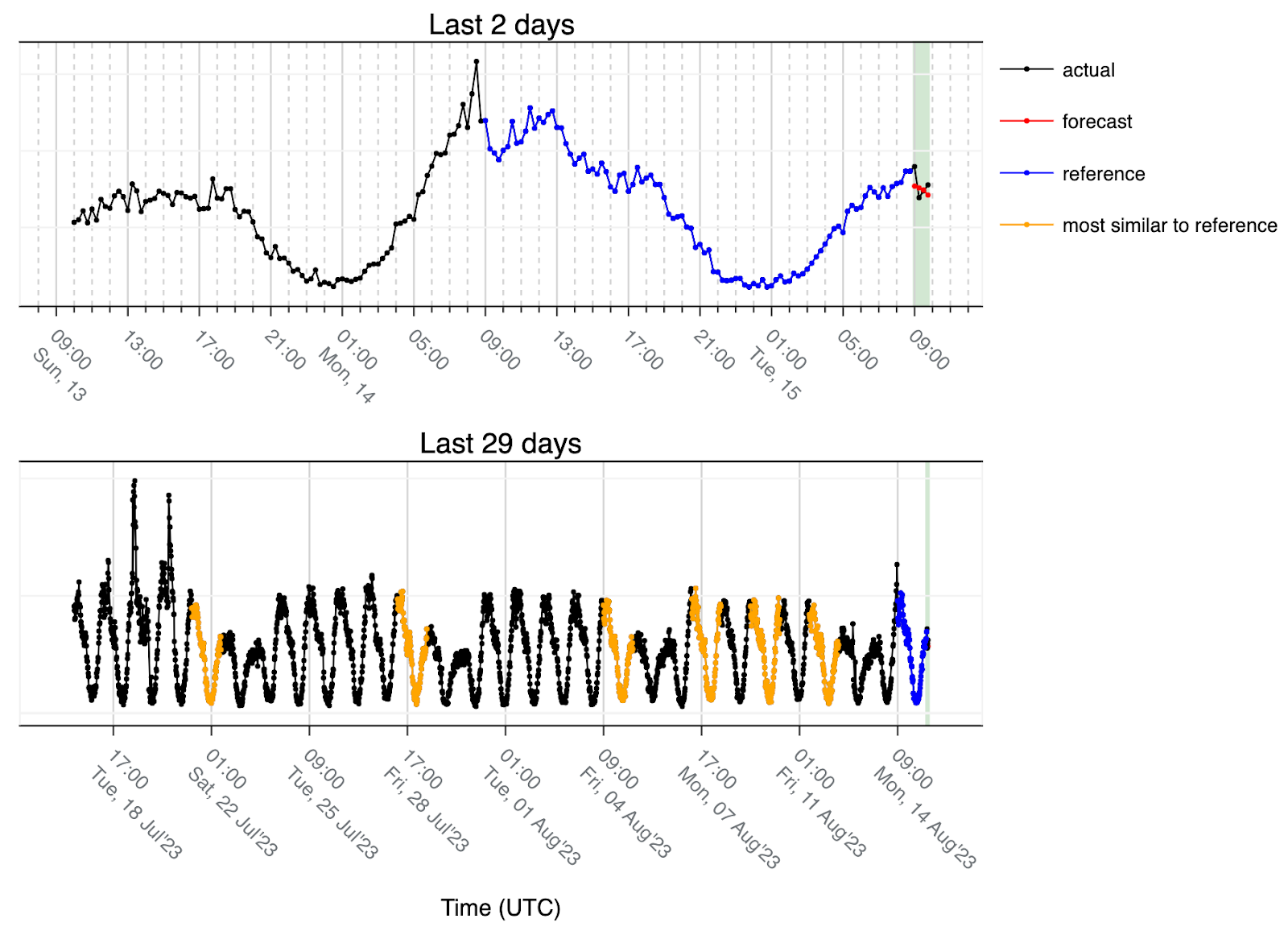
在這種情況下,位於一個星期中間的節日就像是從週五到週六的過渡。由於我們使用的是最近 28 天的資料,而節日從週二開始,因此我們只能看到三個匹配的過渡(橙色),然後是另外三個正常工作日,因為在時間序列的其他地方沒有發現這種模式,這些是最接近的匹配。這就是為什麼在計算偶數值的中位數時,我們使用下四分位數(這意味著我們將資料舍入到較低值),並將結果作為預測值。這也使我們能夠更加保守,並在真陽性/假陽性的權衡中發揮作用。
最後,讓我們看看服務中斷的範例:
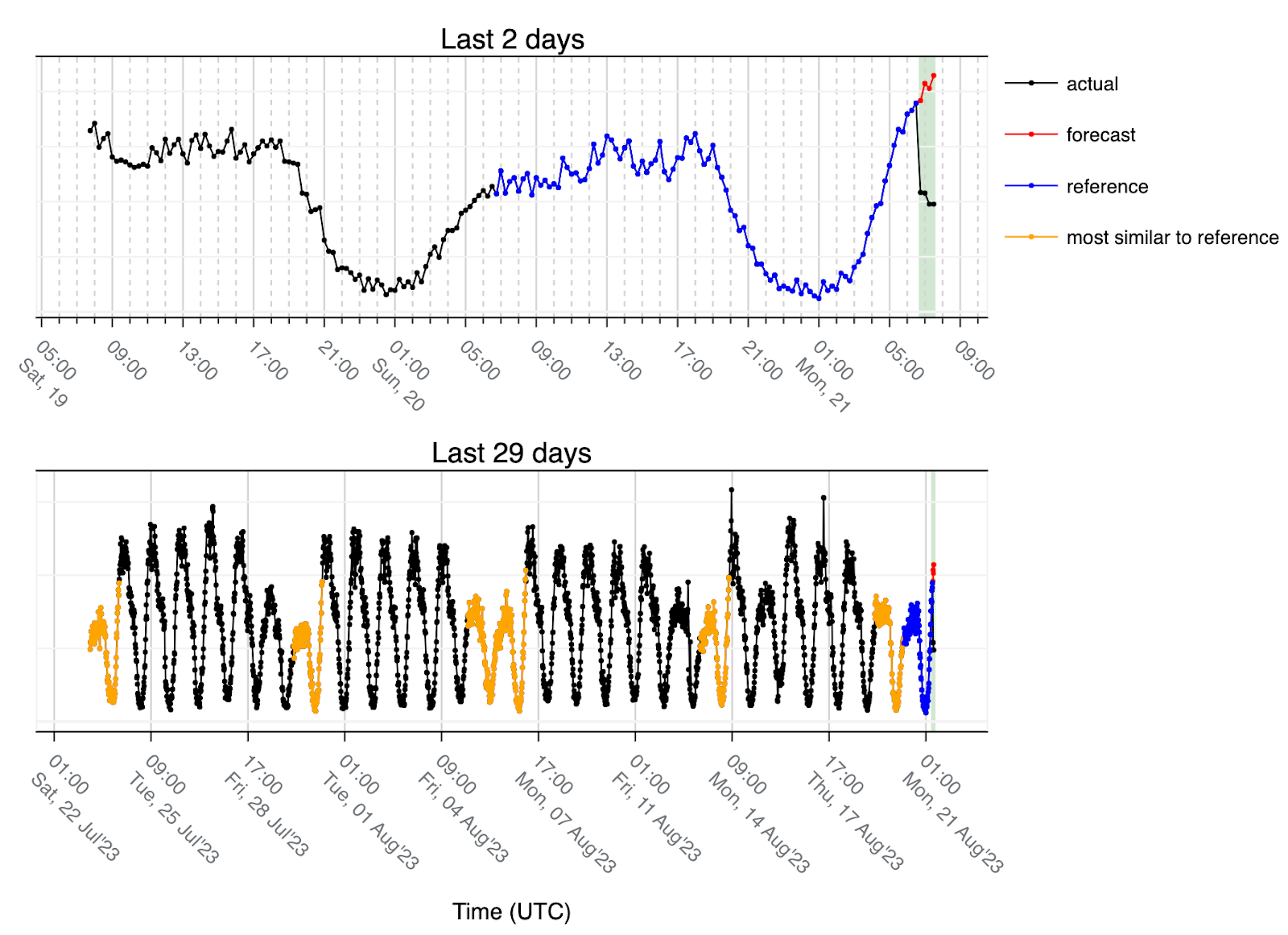
在這種情況下,匹配總是與低流量相關,因為最後 24 小時(參照)對應于從週日到週一的過渡,並且由於流量低,最低歐幾裡得距離(最相似的 24 小時)要麼是週六(兩次),要麼是週日(四次)。因此,預測值是我們期望在正常星期一看到的情況,這就是預測(紅色)呈上升趨勢的原因,但由於發生了服務中斷,實際流量(黑色)遠低於預測。
與其他幾種建模方法一樣,這種方法也適用於常規的季節性模式,而且在節假日和其他移動事件(如每年不在同一天舉行的慶典活動)中也能發揮作用,無需主動新增相關資訊。儘管如此,在某些用例下,特別是當資料有偏移時,還是會出現失敗。這也是我們使用多種資料來源來減少演算法受資料偽造影響的原因之一。
下面我們舉例說明演算法隨時間變化的情況。
將預測與實際流量進行比較
獲得預測和實際流量後,我們將採取以下步驟。
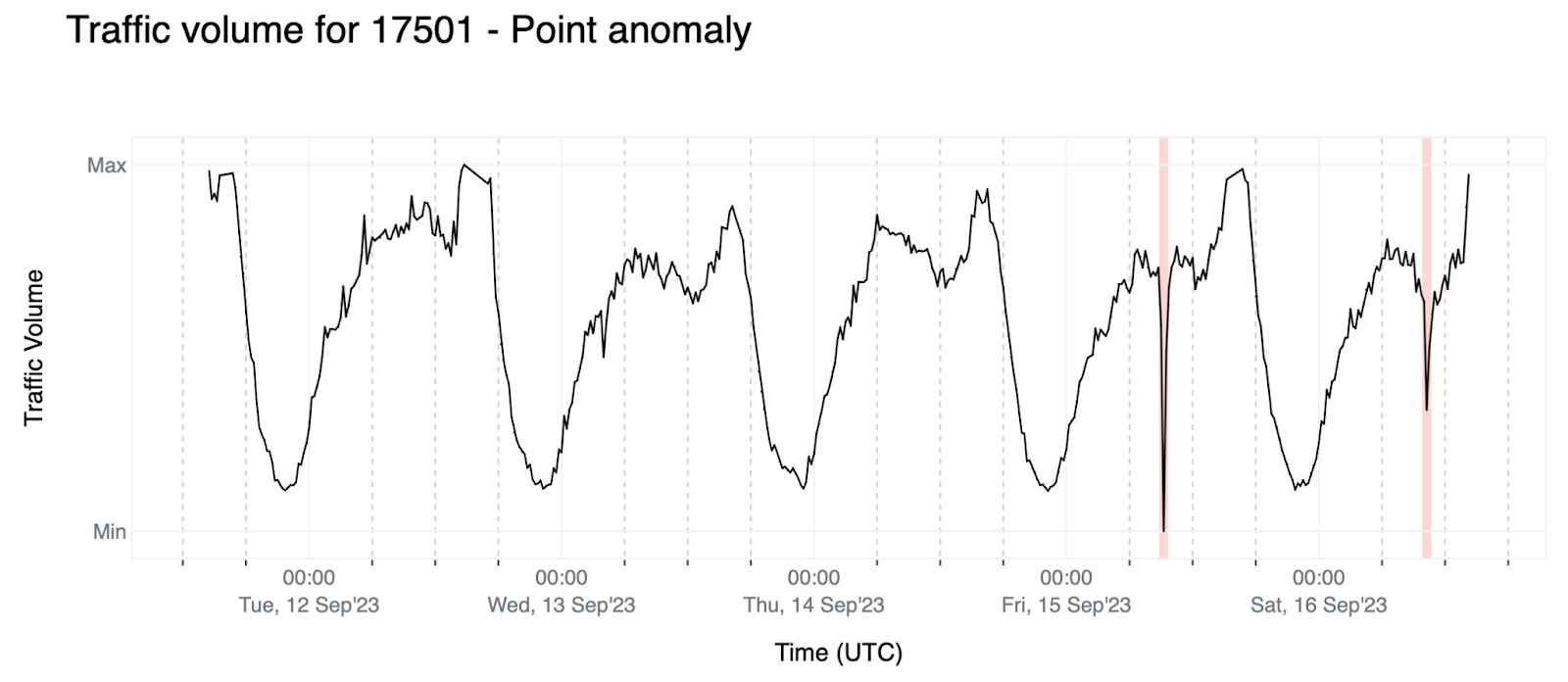
我們計算相對變化,衡量一個值相對於另一個值的變化程度。由於我們是根據流量下降來偵測異常情況,因此實際流量總是低於預測值。
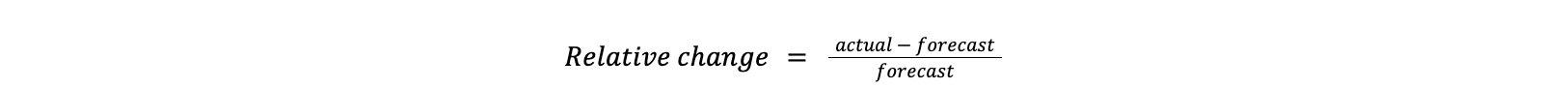
計算此指標後,我們套用以下規則:
- 實際值與預測值之間的差值必須至少為訊號幅度的 10%。這個幅度是使用所選資料的第 95 個百分位數和第 5 個百分位數之差計算得出的。這樣做的目的是避免出現流量較低的情況(尤其是在一天中的非高峰時段),以及微小的實際流量變化對應於較大的相對變化的情況(因為預測值也較低)。舉個例子:
- 預測值 100 Gbps 與實際值 80 Gbps 相比,相對變化為 -0.20 (-20%)。
- 如果預測值為 20 Mbps,而實際值為 10 Mbps,則總流量的下降幅度要比前一個範例小得多,但相對變化為 -0.50 (50%)。
- 然後,我們有兩條規則來偵測相當低的流量:
- 持續異常:在整個預測時間段中(所有四個資料點),相對變化都低於給定的閾值 α。這樣,我們就能發現延續時間較長的較弱異常(相對變化較小)。
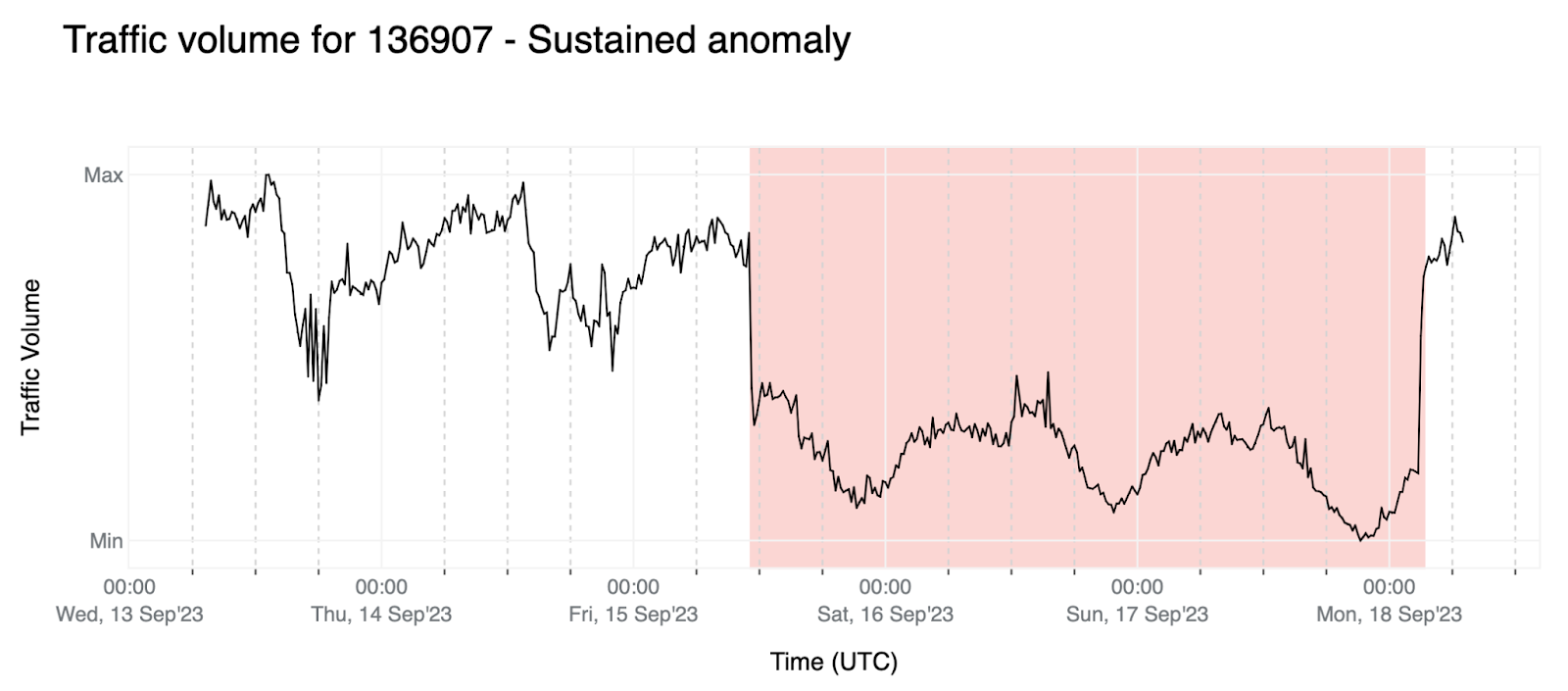
- 點異常:預測時間段最後一個資料點的相對變化低於給定閾值 β(其中 β < α——這些閾值為負;例如,β 和 α 可能分別為 -0.6 和 -0.4)。在這種情況下,我們需要 β< α 來避免因資料的隨機性而觸發異常,但仍能偵測到突然和短暫的流量下降。
- α 和 β 的值是根據經驗選擇的,目的是最大限度地提高偵測率,同時將誤判率保持在可接受的水準。
關閉異常事件
雖然我們要傳達的最重要資訊是異常開始的時間,但出於兩個主要原因,偵測網際網路流量何時恢復正常也至關重要:
- 我們需要有作用中異常的概念,這意味著我們偵測到了異常,而這一異常仍在持續。這樣,當異常仍在作用中時,我們就可以停止考慮新的參照資料。考慮這些資料會影響參照值和 24 小時內最相似資料集的選擇。
- 一旦流量恢復正常,瞭解了異常的持續時間,我們就可以將這些資料點標記為異常值並進行替換,這樣我們就不會最終將其作為參照或作為參照的最佳匹配。雖然我們使用中位數來計算預測值,而且在大多數情況下,這足以解決異常資料的問題,但在某些情況下,例如用作範例四的 AS203214 (HulumTele),由於經常在一天的同一時間發生服務中斷,這將使異常資料在幾天後成為預期資料。
每當偵測到異常時,我們都會保持相同的參照,直到資料恢復正常,否則我們的參照就會開始包含異常資料。為了確定流量何時恢復正常,我們使用比 α 更低的閾值,並給它設定一個時間段(目前為四小時),在該時間段內不出現異常,它才會關閉。這是為了避免出現流量下降後又恢復正常並再次下降的情況。在這種情況下,我們希望偵測單個異常並將其聚合以避免傳送多個通知,並且就語義而言,它很可能與同一異常相關。
結論
網際網路流量資料通常是可預測的,這在理論上允許我們建立一個非常簡單的異常偵測演算法來偵測網際網路中斷。然而,由於時間序列的異質性取決於我們觀察的實體(位置或 AS),以及資料中人工痕跡的存在,如果我們想要即時追蹤,還需要大量的背景資訊,這給我們帶來了一些挑戰。在這裡,我們舉例說明了這一問題的挑戰性所在,並解釋了我們是如何解決這一問題以克服大部分障礙的。事實證明,這種方法可以非常有效地偵測流量異常,同時保持較低的誤判率,這也是我們的工作重點之一。由於這是一種靜態閾值方法,其缺點之一是我們無法偵測到不像範例那樣大幅度的異常。
我們將繼續努力,增加更多的實體並改進演算法,以便能夠覆蓋更廣泛的異常情況。
造訪 Cloudflare Radar,瞭解有關(網際網路中斷、路由問題、網際網路流量趨勢、攻擊、網際網路品質等)的更多見解。在社交媒體上關注我們:@CloudflareRadar (Twitter)、cloudflare.social/@radar (Mastodon) 和 radar.cloudflare.com (Bluesky),或透過電子郵件聯絡我們。