


构建支持生成式人工智能的大型语言模型(LLM)和扩散模型需要庞大的基础架构。最明显的组成部分是计算——数百到数千个 GPU,但同样关键(而且往往被忽视)的组成部分是数据存储基础设施。训练数据集的大小可以达到 TB 到 PB 的规模,这些数据需要由数千个进程并行读取。此外,在训练过程中需要经常保存模型检查点,对于 LLM 来说,每个检查点的大小可能都达到数百 GB!
为了管理存储成本和可扩展性,许多机器学习团队已经开始使用对象存储来托管其数据集和检查点。不幸的是,大多数对象存储提供商通过出口费用来将用户“锁定”在其平台上。这样一来,利用多个云提供商的 GPU 容量,或者利用其他地方更低/动态的价格变得非常困难,因为数据和模型检查点的移动成本太高。在云 GPU 稀缺、新硬件选项进入市场之际,保持灵活性比以往任何时候都更加重要。
除了高昂的出口费用之外,以对象存储为中心的机器学习训练还存在一个技术障碍。在对象存储和计算集群之间读写数据需要高吞吐量、高效利用网络带宽、确定性和弹性(能够使用不同数量的 GPU 进行训练)。构建能够正确、可靠地处理所有这些问题的训练软件并非易事!
今天,我们怀着兴奋之情,向大家展示如何结合使用 MosaicML 的工具和 Cloudflare R2 来解决以上挑战。首先,利用 MosaicML 开源的 StreamingDataset 和 Composer 库,您可以轻松地流式传输训练数据,并将模型检查点读/写回 R2。您只需要互联网连接。其次,得益于 R2 的零出口费用,您可以根据计算提供商的 GPU 可用性和价格的变化启动/停止/移动/调整作业,而无需支付任何数据传输费用。MosaicML 训练平台使得在多个云之间编排此类训练作业变得非常简单。
Cloudflare 和 MosaicML 相结合使您能够在全球任何地方、任何计算资源上训练 LLM,而且零切换成本。这意味着训练速度更快,成本更低,而且避免了供应商锁定 :)
“通过 MosaicML 训练平台,客户可以高效使用 R2 作为持久性存储后端,在任何计算提供商上训练 LLM,而且没有任何出口费用。AI 公司面临着惊人的云成本,正在寻找能够为自己提供速度和灵活性的工具,以最优惠的价格训练出最好的模型。”
– Naveen Rao,CEO 兼联合创始人,MosaicML
使用 StreamingDataset 从 R2 读取数据
要高效、确定地从 R2 读取数据,可以使用 MosaicML 的 StreamingDataset 库。首先,使用提供的 Python API 将训练数据(图像、文本、视频等任何内容)写入 '.mds' shard 文件中:
import numpy as np
from PIL import Image
from streaming import MDSWriter
# Local or remote directory in which to store the compressed output files
data_dir = 'path-to-dataset'
# A dictionary mapping input fields to their data types
columns = {
'image': 'jpeg',
'class': 'int'
}
# Shard compression, if any
compression = 'zstd'
# Save the samples as shards using MDSWriter
with MDSWriter(out=data_dir, columns=columns, compression=compression) as out:
for i in range(10000):
sample = {
'image': Image.fromarray(np.random.randint(0, 256, (32, 32, 3), np.uint8)),
'class': np.random.randint(10),
}
out.write(sample)
在数据集转换完成后,您可以将其上传到 R2。下面我们用 `awscli` 命令行工具进行演示,但您也可以使用 `wrangler ` 或任何您选择的 S3 兼容工具。StreamingDataset 库很快也将支持直接云写入 R2!
$ aws s3 cp --recursive path-to-dataset s3://my-bucket/folder --endpoint-url $S3_ENDPOINT_URL
最后,您可以将数据读取到任何具有 R2 存储桶读取权限的设备上。您可以获取单个样本,遍历整个数据集,并将其输送到标准的 PyTorch dataloader 中。
from torch.utils.data import DataLoader
from streaming import StreamingDataset
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
# Remote path where full dataset is persistently stored
remote = 's3://my-bucket/folder'
# Local working dir where dataset is cached during operation
local = '/tmp/path-to-dataset'
# Create streaming dataset
dataset = StreamingDataset(local=local, remote=remote, shuffle=True)
# Let's see what is in sample #1337...
sample = dataset[1337]
img = sample['image']
cls = sample['class']
# Create PyTorch DataLoader
dataloader = DataLoader(dataset)
StreamingDataset 库内置了高性能、具有弹性确定性、快速恢复和多 worker 支持。它还使用智能混洗和分发来确保最小化下载带宽。在各种工作负载(例如 LLMs 和扩散模型)中,我们发现从像 R2 这样的对象存储中进行训练时,没有对训练吞吐量产生影响(没有数据加载器瓶颈)。如果您想了解更多信息,请查看 StreamingDataset 公告博客!
使用 Composer 读取/写入模型检查点到 R2
将数据流式传输到您的训练循环中解决了一半的问题,但是如何加载/保存您的模型检查点呢?幸运的是,如果您使用像 Composer 这样的训练库,只需指向一个 R2 路径即可!
from composer import Trainer
...
# Make sure that R2 credentials and $S3_ENDPOINT_URL are set in your environment
# e.g. export S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
trainer = Trainer(
run_name='mpt-7b',
model=model,
train_dataloader=train_loader,
...
save_folder=s3://my-bucket/mpt-7b/checkpoints,
save_interval='1000ba',
# load_path=s3://my-bucket/mpt-7b-prev/checkpoints/ep0-ba100-rank0.pt,
)
Composer 使用异步上传来最小化在训练期间保存检查点时的等待时间。它还支持多 GPU 和多节点训练,而且不需要共享文件系统。这意味着您可以跳过为计算集群设置昂贵的 EFS/NFS 系统,从而每个月在公共云上节省数千美元或更多。您只需要互联网连接和适当的凭据,您的检查点就可以安全地到达 R2 存储桶,为您的私有模型提供可扩展和安全的存储。
使用 MosaicML 和 R2 在任何地方进行有效训练
使用上述工具以及 Cloudflare R2,用户可以在任何计算提供商上运行训练工作负载,享有完全的自由,而且没有任何切换成本。
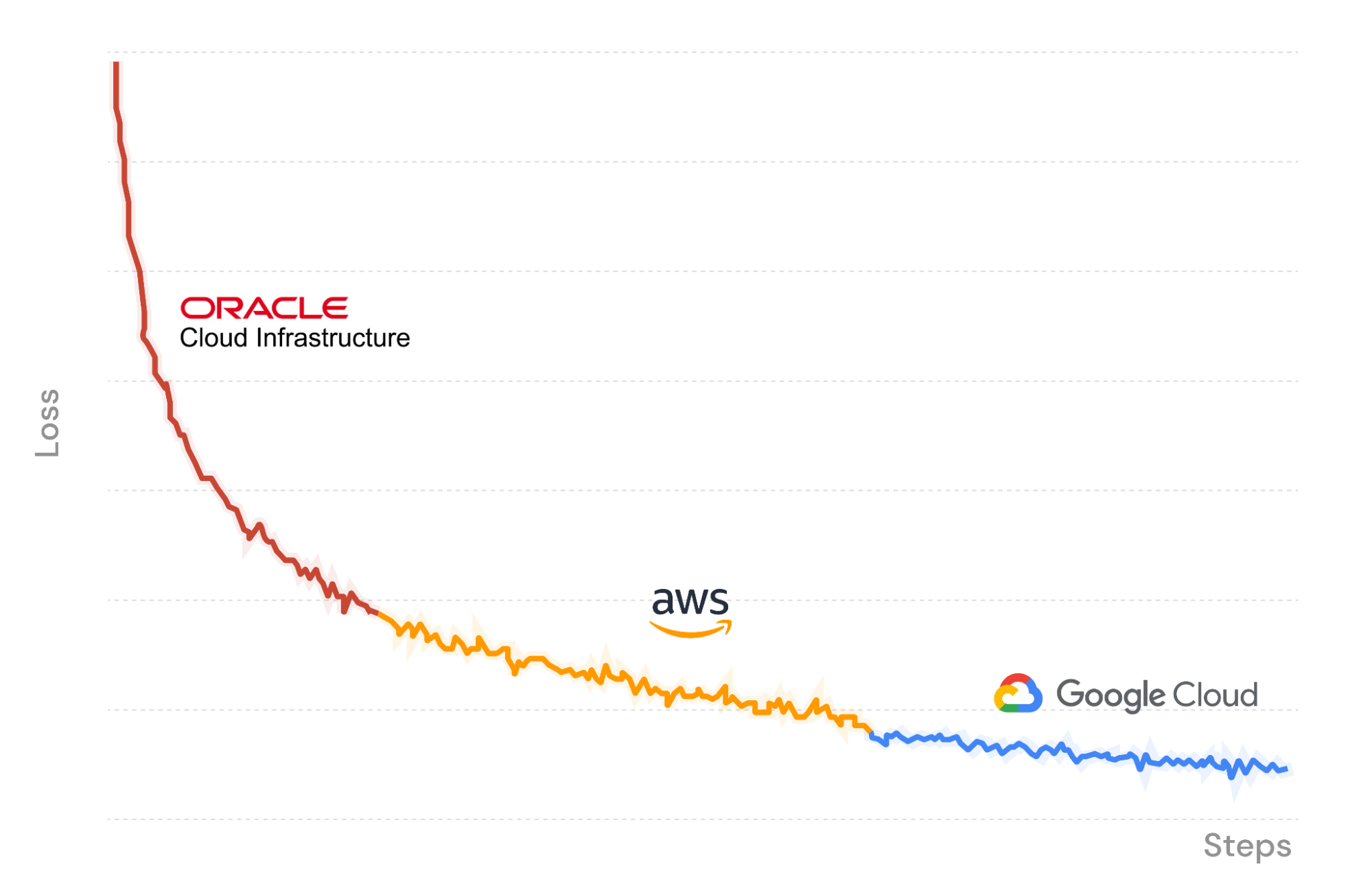
作为演示,在图 X 中,我们使用 MosaicML 训练平台在 Oracle Cloud Infrastructure 上启动一个 LLM 训练作业,数据流式传输进入并将检查点上传回 R2。在训练过程中,我们暂停了作业,并在 Amazon Web Services 上的另一套 GPU 集群上无缝恢复了作业。Composer 从 R2 中的最后一个保存的检查点加载模型权重,而流式数据加载器立即恢复到正确的批次。训练过程保持确定性。最后,我们再一次将作业迁移到 Google Cloud 上以完成运行。
当我们在三个云服务提供商上训练 LLM 时,只需要支付 GPU 计算和数据存储的成本。得益于 Cloudflare R2,我们不需要支付数据出口费用,也不必担心供应商锁定。
$ mcli get clusters
NAME PROVIDER GPU_TYPE GPUS INSTANCE NODES
mml-1 MosaicML │ a100_80gb 8 │ mosaic.a100-80sxm.1 1
│ none 0 │ cpu 1
gcp-1 GCP │ t4 - │ n1-standard-48-t4-4 -
│ a100_40gb - │ a2-highgpu-8g -
│ none 0 │ cpu 1
aws-1 AWS │ a100_40gb ≤8,16,...,32 │ p4d.24xlarge ≤4
│ none 0 │ cpu 1
oci-1 OCI │ a100_40gb 8,16,...,64 │ oci.bm.gpu.b4.8 ≤8
│ none 0 │ cpu 1
$ mcli create secret s3 --name r2-creds --config-file path/to/config --credentials-file path/to/credentials
✔ Created s3 secret: r2-creds
$ mcli create secret env S3_ENDPOINT_URL="https://[uid].r2.cloudflarestorage.com"
✔ Created environment secret: s3-endpoint-url
$ mcli run -f mpt-125m-r2.yaml --follow
✔ Run mpt-125m-r2-X2k3Uq started
i Following run logs. Press Ctrl+C to quit.
Cloning into 'llm-foundry'...
使用 MCLI 命令行工具管理计算集群、密钥和提交作业。
### mpt-125m-r2.yaml ###
# set up secrets once with `mcli create secret ...`
# and they will be present in the environment in any subsequent run
integrations:
- integration_type: git_repo
git_repo: mosaicml/llm-foundry
git_branch: main
pip_install: -e .[gpu]
image: mosaicml/pytorch:1.13.1_cu117-python3.10-ubuntu20.04
command: |
cd llm-foundry/scripts
composer train/train.py train/yamls/mpt/125m.yaml \
data_remote=s3://bucket/path-to-data \
max_duration=100ba \
save_folder=s3://checkpoints/mpt-125m \
save_interval=20ba
run_name: mpt-125m-r2
gpu_num: 8
gpu_type: a100_40gb
cluster: oci-1 # can be any compute cluster!
一个 MCLI 指定运行名称、Docker 镜像、一组命令以及要用于运行的计算集群。
立即开始使用!
MosaicML 平台是一个非常有用的工具,帮助将您的训练提升到一个新的水平。本文探讨了 Cloudflare R2 如何让您能够在任何或所有计算提供商上使用自己的数据训练模型。通过消除数据出口费用,R2 存储成为 MosaicML训练一个极具成本效益的补充,提供最大的自主权和控制。结合这两个工具,您可以随时在云服务提供商之间切换,以适应组织需求随时间的变化。
如果希望进一步了解如何使用 MosaicML 在自己的数据上训练定制的最先进人工智能模型,请访问这里或联系我们。