


緊急情況:TCP 封包無效:已截斷
幾個月前,我們開始收到 flowtrackd 的一些當機報告,flowtrackd 是在我們的全球網路上執行的進階 TCP 保護系統。它所提供的堆疊追蹤指出,在剖析已截斷的 TCP 封包時發生緊急情況。
有趣之處在於,並非我們無法剖析封包。我們從網際網路中收到已截斷(無論故意與否)的格式錯誤的封包的情況並不罕見。這些封包將在我們第一次剖析它們時被擷取,並且不會進入後面的處理階段。但是,在我們的案例中,在我們第二次剖析封包時發生了緊急情況,這表明封包是在我們收到它並順利完成第一次剖析後被截斷的。這兩次剖析呼叫從單一綠色執行緒發起,參照了記憶體中同一個封包緩衝區,我們也並未嘗試在中間變動封包。
人們很容易對發現這樣的錯誤感到恐懼。是否存在競爭條件?是否存在記憶體損毀?這是核心錯誤嗎?是編譯器錯誤嗎?為了找到這個潛在複雜問題的根本原因,我們計劃識別該錯誤的相關徵兆,針對可能發生的事情建立理論,並建立一種方法來測試理論或收集更多資訊。
在深入細節之前,我們首先需要瞭解一些有關 AF_XDP 以及我們的設定的背景資訊。
AF_XDP 概觀
AF_XDP 是 Linux 核心中的高效能的非同步使用者空間網路 API。對於支援它的網路裝置,AF_XDP 提供了一種方法,可使用在核心和使用者空間應用程式之間共用的記憶體緩衝區,執行極快的零複製封包轉寄。
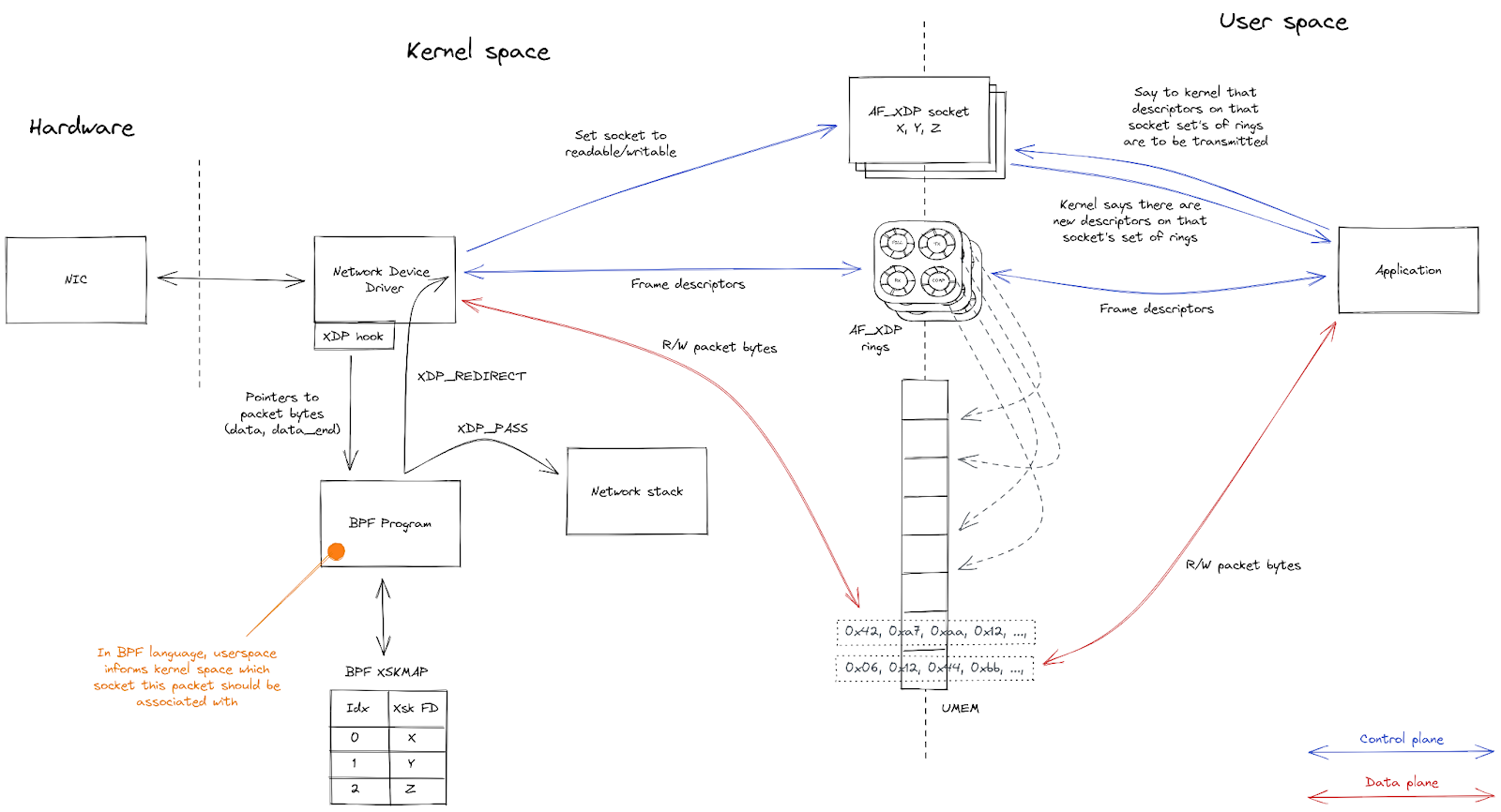
使用者空間應用程式需要設定多個元件,才能開始與使用 AF_XDP 進入網路裝置的封包互動。
首先,會建立一個共用封包緩衝區 (UMEM)。這個 UMEM 被分為相同大小的「框架」,它們由「描述元位址」參照,而該位址就是距離 UMEM 開始處的位移。
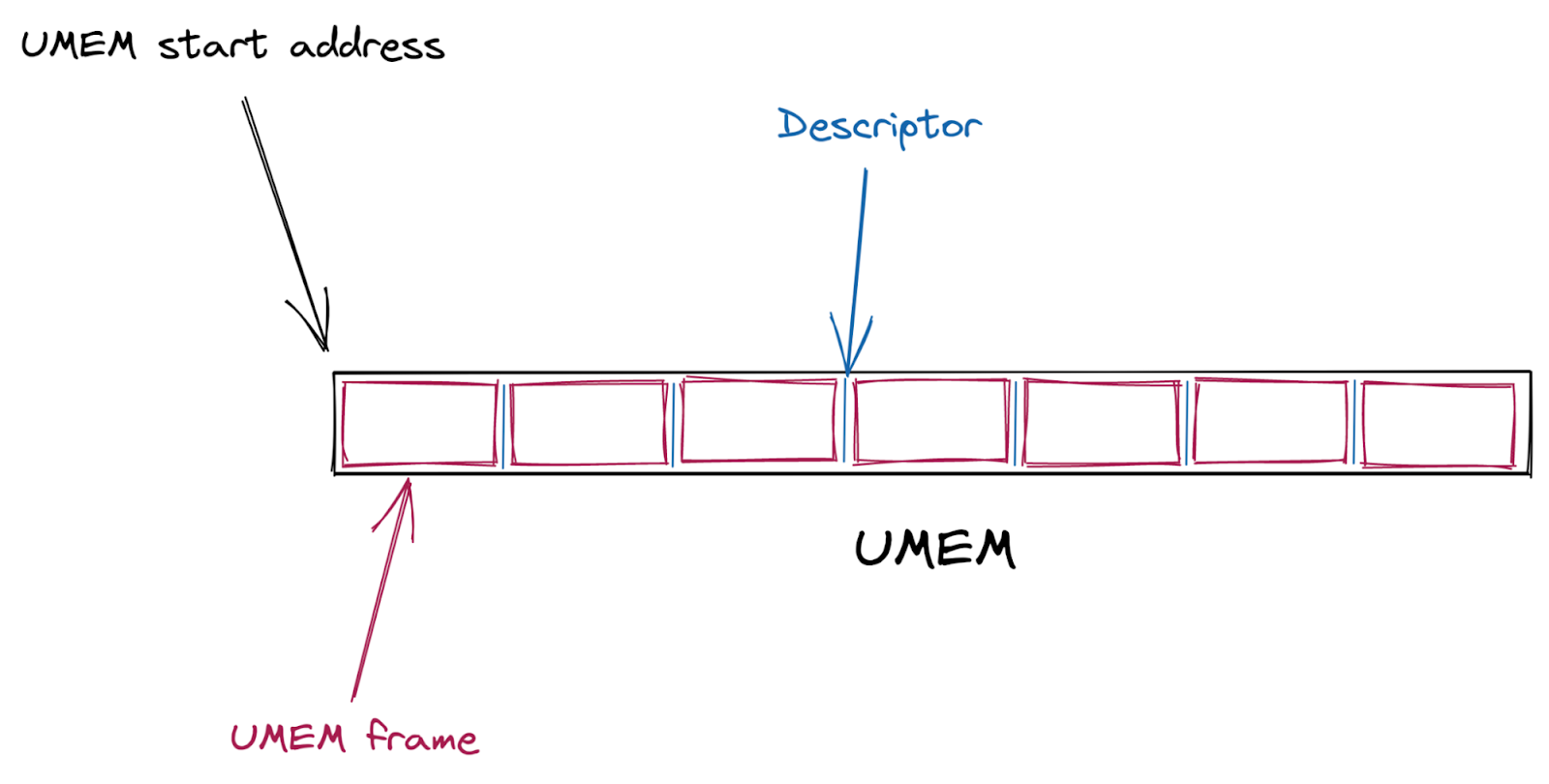
接下來,會建立多個 AF_XDP 通訊端 (XSK)——網路裝置上的每個硬體佇列一個——並繫結至 UMEM。這些通訊端中的每一個都提供四個環形緩衝區(或者說「佇列」),用於在核心與使用者空間之間來回傳送描述元。
使用者空間傳送封包的方法是,獲取一個未使用的描述元並將封包複製到該描述元中(或者更確切地說,是複製到該描述元所指向的 UMEM 框架中)。它將該描述元排入 TX 佇列,以將該描述元提供給核心。一段時間後,核心會將該描述元從 TX 佇列中清除,並將其所指向的封包傳輸出網路裝置。最後,核心會將該描述元排入 COMPLETION 佇列,讓該描述元回到使用者空間,這樣,使用者空間稍後便可重複使用它來傳送另一個封包。
若要接收封包,使用者空間會將未使用的描述元排入 FILL 佇列,來為核心提供描述元。核心會將它所接收的封包複製到這些未使用的描述元中,然後將這些描述元排入 RX 佇列,以將它們提供給使用者空間。在使用者空間處理它從 RX 佇列中清除的封包後,就可以將它們排入 TX 佇列,以將其從網路裝置傳輸回來,也可以將它們排入 FILL 佇列,從而將其送回核心以供稍後重複使用。
| 佇列 | 使用者空間 | 核心空間 | 內容描述 |
|---|---|---|---|
| COMPLETION | 取用 | 產生 | 包含由核心成功傳輸之封包的描述元 |
| FILL | 產生 | 取用 | 空白且可供核心用來接收封包的描述元 |
| RX | 取用 | 產生 | 包含核心最近接收之封包的描述元 |
| TX | 產生 | 取用 | 包含可由核心傳輸之封包的描述元 |
最後,一個 BPF 程式會連結到網路裝置。它的工作是將連入封包導向至與接收封包的特定硬體佇列相關聯的 XSK。
以下是核心與使用者空間之間互動的概觀:
我們的設定
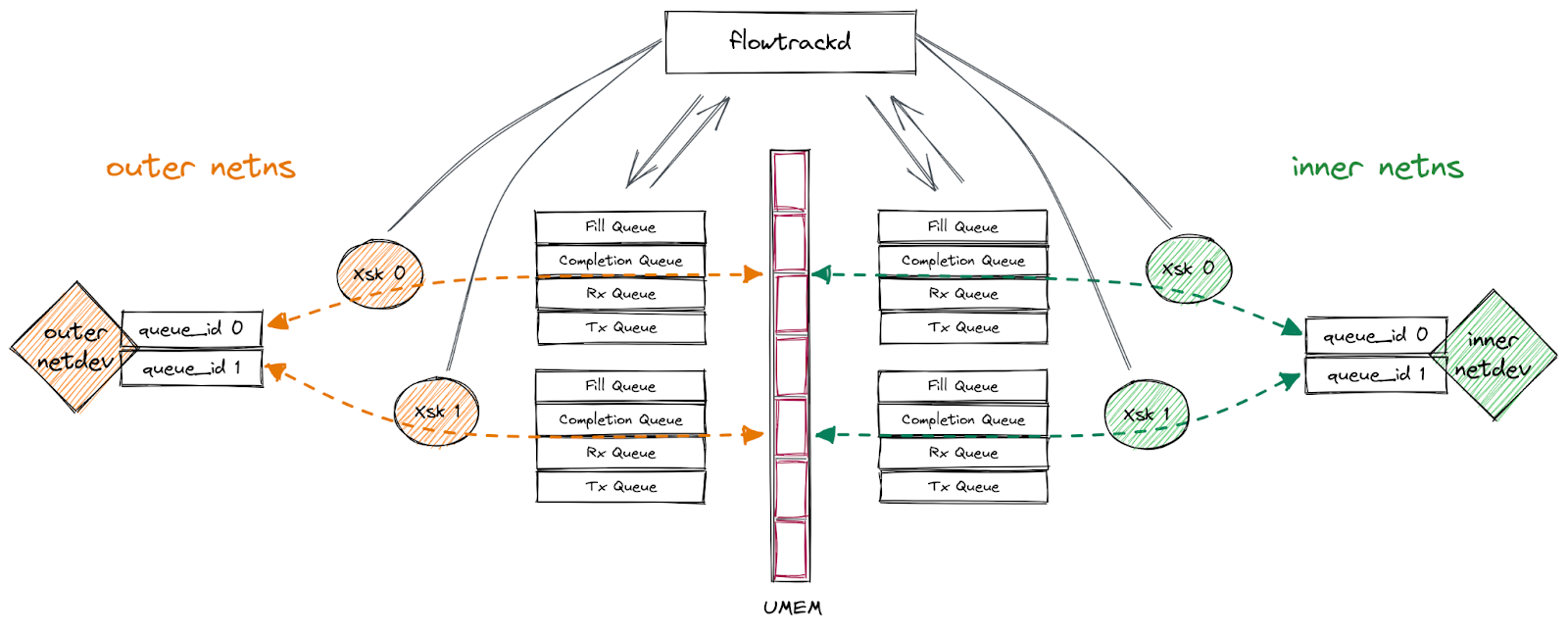
我們的應用程式在一對多佇列 veth 介面(「外部」和「內部」)上使用 AF_XDP,這兩個介面分別位於不同的網路命名空間中。我們遵循上述流程將 XSK 繫結至每個介面的佇列,將封包從一個介面轉寄到另一個介面,將封包從接收它們的介面傳送回去,或捨棄它們。此功能讓我們能夠實作雙向流量檢查來執行 DDoS 緩解邏輯。
此設定如下圖所示:
資訊收集
一開始,我們只知道我們的程式偶爾會看到似乎不可能發生的損毀。我們不知道這些損毀封包實際上是什麼樣子。它們的內容可能會顯示有關錯誤以及如何重現錯誤的更多詳細資料,因此,我們首先做的是記錄封包位元組數並捨棄該封包,而不是恐慌。然後,我們可以獲取包含封包位元組數的記錄,並建立一個 PCAP 檔案來使用 Wireshark 進行分析。分析表明,封包看起來基本正常,只是 Wireshark 的 TCP 分析器抱怨其「IPv4 總長度超過封包長度」。換言之,「總長度」IPv4 標頭欄位表示封包長度應為(例如)60 個位元組,但封包本身長度只有 56 個位元組。
長度不符
是否有可能是我們從 RX 環讀取的位元組數不正確?我們來檢查一下。
一個 XDP 描述元具有以下 C struct:
struct xdp_desc {
__u64 addr;
__u32 len;
__u32 options;
};
在這裡,len 成員會告訴我們 UMEM 框架中 addr 指向的封包的總大小。
我們與封包內容的第一次互動發生在連結到網路介面的 BPF 程式碼中。
在那裡,我們的進入點函數會獲取一個指向 xdp_md C struct 的指標,其定義如下:
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
__u32 egress_ifindex; /* txq->dev->ifindex */
};
此內容結構包含兩個指標 (as __u32),分別指向封包開始和結尾。取得封包長度可以透過從 data_end 中減去 data 來完成。
如果我們將這個值與我們從描述元中取得的值進行比較,我們肯定會發現它們是一樣的,對嗎?
我們可以使用 BPF helper 函數 bpf_xdp_adjust_meta()(因為 veth 驅動程序支援它)來宣告一個中繼資料空間,該空間將保存我們計算的封包緩衝區長度。我們使用它的方式與此核心範例程式碼如出一轍。
在生產環境中部署新程式碼之後,我們在記錄檔中看到了下列幾行:
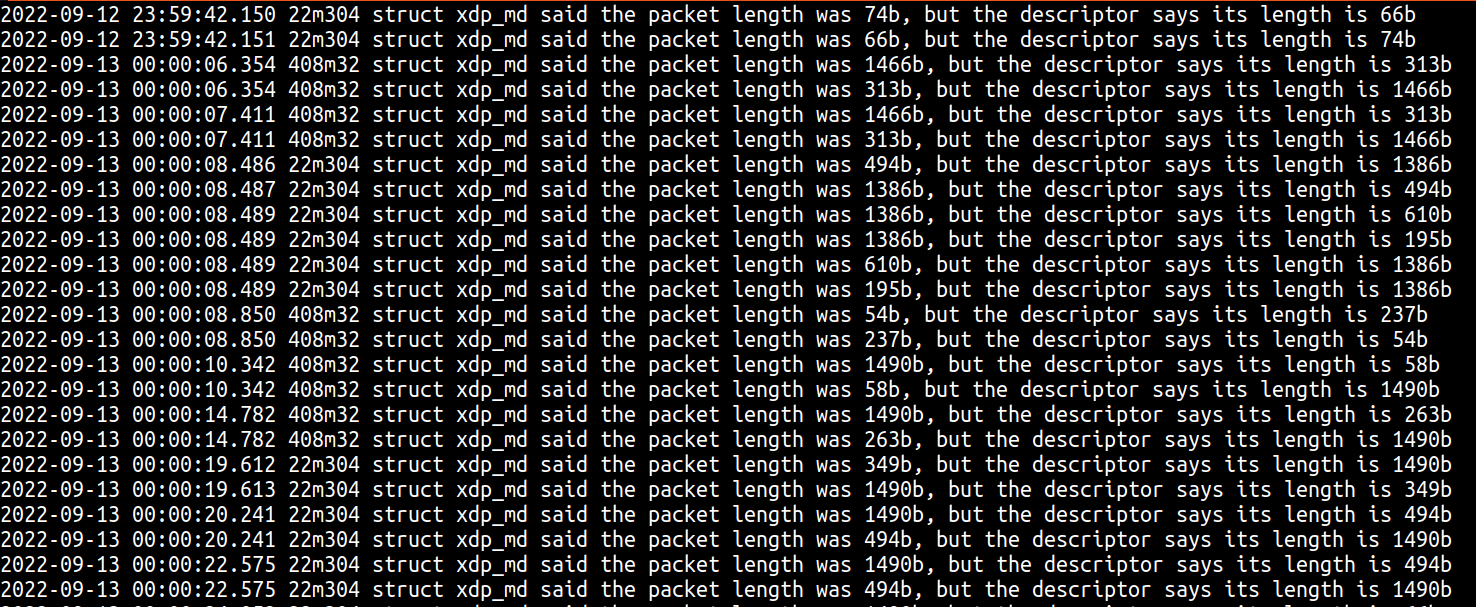
在這裡,您會看到三件有趣的事情:
- 正如我們的理論推測,第一次在 XDP 中看到的封包的長度與描述元中顯示的長度不符。
- 我們已經從截斷的封包緊急情況中觀察到,有時描述元長度比實際封包長度短,但是列印顯示有時描述元長度可能大於實際封包位元組數。
- 這些情況通常「成對」出現,其中 XDP 長度和描述元長度會在封包之間交換。
兩個封包和一個緩衝區?
看到 XDP 和描述元長度「成對」交換可能是第一個靈光一現。這兩個不同的封包是否被寫入到同一個緩衝區?這也說明,我們未將一條關鍵資訊(即描述元位址)加入偵錯列印!我們藉此機會列印其他資訊(如封包位元組數),並在路徑中的多個位置列印,看看隨著時間的推移是否有任何變化。
這些偵錯列印所顯示的真正的關鍵資訊是,不僅每個「成對」交換共用一個描述元位址,而且單一伺服器上幾乎每個損毀封包都始終使用同一個描述元位址。在這裡,您可以看到 49750 個損毀封包全都使用描述元位址 69837056:
$ cat flowtrackd.service-2022-11-03.log | grep 87m237 | grep -o -E 'desc_addr: [[:digit:]]+' | sort | uniq -c
49750 desc_addr: 69837056
這是第二個靈光一現。我們不僅試圖將兩個封包複製到相同的緩衝區,而且始終是同一個緩衝區。也許問題在於我們已經將這個描述元插入 AF_XDP 環兩次了?我們透過更新取用者代碼測試了這個理論,以測試在從 RX 環讀取的一批描述元中,是否有相同的描述元出現了兩次。這並不能保證該描述元未在環中出現兩次,因為不能保證這兩個描述元會出現在同一個讀取批次中,不過,我們很幸運,確實在單次讀取中擷取到了相同的描述元兩次,證明這就是問題所在。事後看來,Linux 核心 AF_XDP 文件已經指出了這個問題:
問:我的封包有時會損毀。哪裡出錯了?
答:必須注意不要同時將 UMEM 中的相同緩衝區送入多個環。例如,如果您同時將相同的緩衝區送入 FILL 環和 TX 環,則 NIC 可能會在傳送資料的同時接收資料到緩衝區中。這將導致某些封包損毀。如果將相同的緩衝區送入屬於不同佇列 ID 或與 XDP_SHARED_UMEM 旗標繫結的不同 netdev 的 FILL 環中,也會發生同樣的情況。
現在,我們明白了為什麼會有損毀封包,但我們仍然不明白,一個描述元為什麼會在 AF_XDP 環中出現兩次。我很想把這歸咎於核心錯誤,但正如文件所指出的那樣,這更有可能是我們在應用程式中將描述元兩次置於環中。此外,由於這個問題已列入 AF_XDP 的常見問題集,因此在向核心郵件清單報告之前,我們必須有足夠的證據可以證明這是由核心錯誤而不是使用者錯誤引起的。
追蹤描述元轉換
審核我們的應用程式程式碼時,並未發現任何明顯的位置讓我們可能將同一個描述元位址插入 FILL 或 TX 環兩次。然而,我們確實知道描述元透過一組已知狀態進行轉換,而且我們可以使用一個狀態機器來追蹤這些轉換。下圖顯示了所有可能的有效轉換:
例如,描述元從 RX 環轉到 FILL 環或 TX 環是完全有效的轉換。另一方面,描述元從 FILL 環轉到 COMP 環則是無效的轉換。
為了測試描述元轉換的有效性,我們添加了程式碼來追蹤它們在環中的成員資格。這會產生一些記錄訊息,如下所示:
Nov 16 23:49:01 fuzzer4 flowtrackd[45807]: thread 'flowtrackd-ZrBh' panicked at 'descriptor 26476800 transitioned from Fill to Tx'
Nov 17 02:09:01 fuzzer4 flowtrackd[45926]: thread 'flowtrackd-Ay0i' panicked at 'descriptor 18422016 transitioned from Comp to Rx'
Nov 29 10:52:08 fuzzer4 flowtrackd[83849]: thread 'flowtrackd-5UYF' panicked at 'descriptor 3154176 transitioned from Tx to Rx'
第一次列印顯示,一個描述元被置於 FILL 環上,並直接轉換到 TX 環,而無需先從 RX 環中讀取。這似乎暗示了我們的應用程式中有錯誤,可能表明應用程式複製了描述元,將一個複本放在 FILL 環中,將另一個複本放在 TX 環中。
第二個無效轉換發生在描述元從 COMP 環移動到 RX 環時,沒有先置於 FILL 環上。這似乎暗示了存在核心錯誤,可能表明核心複製了一個描述元並將其同時置於 COMP 環和 RX 環中。
第三個無效轉換是從 TX 環到 RX 環時,沒有先通過 FILL 環或 COMP 環。這似乎是前面的 COMP 向 RX 轉換的擴展案例,再次暗示可能存在核心錯誤。
我們對結果感到困惑,因此仔細檢查了追蹤代碼,並試圖搞清楚,應用程式如何能夠複製一個描述元並將其同時置於 FILL 環和 TX 環中。由於沒有發現任何錯誤,我們認為我們需要收集更多的資訊。
使用 ftrace 作為「飛行記錄器」
雖然使用狀態機器來擷取無效描述元轉換能夠發現這些情況,但它仍然缺少很多重要的細節,而這些細節可能有助於找到錯誤的最終原因。我們仍然不知道該錯誤是核心問題還是應用程式問題。令人困惑的是,轉換狀態似乎表明二者都有問題。
為了收集更多資訊,在理想情況下,我們希望能夠追蹤描述元的歷程記錄。由於我們使用共用的 UMEM,理論上,一個描述元可以在介面之間以及接收佇列之間進行轉換。此外,我們的應用程式使用單一綠色執行緒來處理每個 XSK,因此使用 XSK、CPU 和執行緒來追蹤這些描述元轉換可能會很有趣。若要實現這一點,有一個非常簡單的方法,即在每個轉換點列印這些資訊,但這個方法無法擴展。當然,對於一個需要能夠每秒處理數百萬個封包的生產環境而言,這個選項並不可行。無論是產生的資料量,還是列印該資訊的開銷,都行不通。
到目前為止,我們一直在生產環境系統中對這個問題進行仔細偵錯。這個問題極其罕見,即使在大型生產環境部署中,某些生產環境電腦也可能需要一天的時間才能開始顯示問題。如果我們確實想探索更多耗用大量資源的偵錯技術,我們必須看看是否可以在測試環境中重現此問題。為此,我們建立了 10 個虛擬機,它們使用 iperf 連續對應用程式進行負載測試。幸運的是,在這種設定下,我們能夠重現這個問題,大約每天一次,這讓我們能夠更自由地去嘗試更多的耗用大量資源的偵錯技術。
即使使用虛擬機,也仍然無法擴展到列印每次描述元轉換的記錄,但是您真的需要查看每次轉換嗎?從理論上講,最有趣的事件就是在錯誤之前發生的那個事件。我們可以構建一個工具,在內部保留最後 N 個事件的日誌,並且只在錯誤發生時傾印該日誌。就像飛機上使用黑匣子(飛行記錄器)來追蹤墜機前的事件一樣。幸運的是,我們並不需要構建這個功能,而是可以使用 Linux 核心的 ftrace 功能,它的一些額外功能可以幫助我們最終找到這個錯誤的原因。
ftrace 是一個核心功能,其運作方式是在內部保存一組每個 CPU 環形緩衝區的追蹤事件。儲存在環形緩衝區中的每個事件都會加上時間戳記,並包含一些有關事件發生位置、CPU 以及事件發生時正在執行的處理序或執行緒的其他資訊。由於這些事件儲存在每個 CPU 環形緩衝區中,因此在環已滿後,新事件將覆寫最舊的事件,並在該 CPU 上留下最新事件的日誌。實際上,我們有了我們想要的飛行記錄器,我們需要做的就是將事件新增至 ftrace 環形緩衝區,並在錯誤發生時停用追蹤。
ftrace 是使用 debugfs 檔案系統中的虛擬檔案控制的。我們可以啟用和停用追蹤,方法是將 1 或 0 寫入:
/sys/kernel/debug/tracing/tracing_on
我們可以更新應用程式以將我們自己的事件插入到追蹤環形緩衝區中,方法是將訊息寫入 trace_marker 檔案:
/sys/kernel/debug/tracing/trace_marker
最後,在我們重現了錯誤並且我們的應用程式停用了追蹤之後,我們可以將所有環形緩衝區的內容擷取到單一追蹤檔案中,方法是讀取追蹤檔案:
/sys/kernel/debug/tracing/trace
值得注意的是,將訊息寫入 trace _marker 虛擬檔案仍然涉及發起系統呼叫並將訊息複製到環形緩衝區中。這可能仍然會增加開銷,在我們的案例中,我們會每個封包記錄多次列印,因此,開銷可能會很龐大。此外,ftrace 是全系統的核心追蹤功能,因此您可能需要調整虛擬檔案的權限,或是以適當的權限執行應用程式。
當然,使用 ftrace 來幫助偵測這個問題還有一個很大的優勢。如上所示,我們可以使用 trace_marker 檔案將自己的應用程式訊息記錄到 ftrace,但究其本質,ftrace 是一項核心追蹤功能。這意味著我們還可以使用 ftrace 來記錄 AF_XDP 封包處理的核心端的事件。有幾種方法可以做到這一點,但是就我們的目的而言,我們使用 kprobe,這樣我們就可以選取非常具體的程式碼行作為目標並列印一些變數。kprobe 可以直接在 ftrace 中建立,但是我發現使用 Linux 中 perf 工具的「perf probe」命令建立它們更容易。使用「-L」和「-V」引數,您可以找到可以探查函數的哪些行,以及可以在這些探查點查看哪些變數。最後,您可以使用「-a」引數新增探查。例如,在檢查核心程式碼之後,我們在 XSK 的接收路徑中插入以下探查:
perf probe -a '__xsk_rcv_zc:7 addr len xs xs->pool->fq xs->dev'
這將探查 __xsk_rcv_zc() 的第 7 行,並列印描述元位址、封包長度、XSK 位址、fill 佇列位址和網路裝置位址。對於內容,以下是 __xsk_rcv_zc() 在 perf probe 命令中的樣子:
$ perf probe -L __xsk_rcv_zc
0 static int __xsk_rcv_zc(struct xdp_sock *xs, struct xdp_buff *xdp, u32 len)
{
struct xdp_buff_xsk *xskb = container_of(xdp, struct xdp_buff_xsk, xdp);
u64 addr;
int err;
addr = xp_get_handle(xskb);
7 err = xskq_prod_reserve_desc(xs->rx, addr, len);
8 if (err) {
xs->rx_queue_full++;
return err;
}
在我們的案例中,第 7 行是對 xskq_prod_reserve_desc() 的呼叫。在程式碼中的這一點,核心已經從 FILL 佇列中移除描述元,並將封包複製到了該描述元中。呼叫 xsk_prod_reserve_desc() 將確保 RX 佇列中有空間,如果有空間,則會將該描述元新增至 RX 佇列。請務必注意,雖然 xskq_prod_reserve_desc() 會將描述元置於 RX 佇列中,但它不會更新 RX 環的產生者指標,也不會通知 XSK 封包已準備好讀取,因為核心會嘗試對這些作業進行批次處理。
同樣,我們想要在核心端的傳輸路徑中放置探查,最後放置了下列探查:
perf probe -a 'xp_raw_get_data:0 addr'
在程式碼中沒有什麼有趣的內容可以展示,但是這個探查被置於描述元已從 TX 佇列中移除但尚未置入 COMPLETION 佇列的位置。
在這兩次探查中,若是將探查置於描述元從 XSK 佇列中新增或移除的最早位置,並盡可能多地列印這些位置的資訊,那該多好。然而,實際上,可以放置 kprobe 的位置以及這些位置上可用的變數會限制可以看到的內容。
建立探查後,我們仍然需要能夠在 ftrace 中看到它們。這可以透過以下方式來完成:
echo 1 > /sys/kernel/debug/tracing/events/probe/__xsk_rcv_zc_L7/enableecho 1 > /sys/kernel/debug/tracing/events/probe/xp_raw_get_data/enable
由於我們的應用程式更新後,能夠追蹤每個描述元的轉換並在發生無效轉換時停止追蹤,我們準備再次進行測試。
追蹤描述元狀態還不夠
遺憾的是,我們並未從對「飛行記錄器」的初步測試中立即獲得什麼新資訊。相反,它主要證實了我們已經知道的事情,即不知何故,最終會有同一個描述元出現兩次。它還強調了一個事實:擷取無效描述元轉換並不意味著您已經擷取到重複描述元最早出現的時間點。例如,假設我們有描述元 A 和重複項 A'。如果這些都已經存在於 FILL 佇列中,則下列轉換完全有效:
RX A -> FILL ARX A’ -> FILL A’
這種轉換可能會在多個週期內發生,最終才發生無效轉換,即兩個描述元在同一批次中或在佇列之間同時出現。
相反,我們需要重新思考我們的方法。我們知道核心會從 FILL 佇列中移除描述元、填滿它們,然後將它們置於 RX 佇列中。這意味著對於任何給定的 XSK,將描述元插入 FILL 佇列的順序應與它們從 RX 佇列中移除的順序相符。如果曾在此核心 RX 路徑中複製某個描述元,我們應該看到重複的描述元出現失序。考慮到這一點,我們更新了應用程式,以使用雙端佇列獨立追蹤 FILL 佇列的順序。當我們的應用程式將描述元置入 FILL 佇列時,我們也將描述元位址推送至追蹤佇列的尾部,當我們收到封包時,我們會從追蹤佇列的頭部快顯描述元位址,並確保位址相符。如果不符,我們可以再次記錄到 trace_marker 並停止 ftrace。
以下是我們使用更新的程式碼追蹤 FILL 到 RX 佇列的順序時,擷取的第一次追蹤的結尾。我們添加了顏色以提高可讀性:
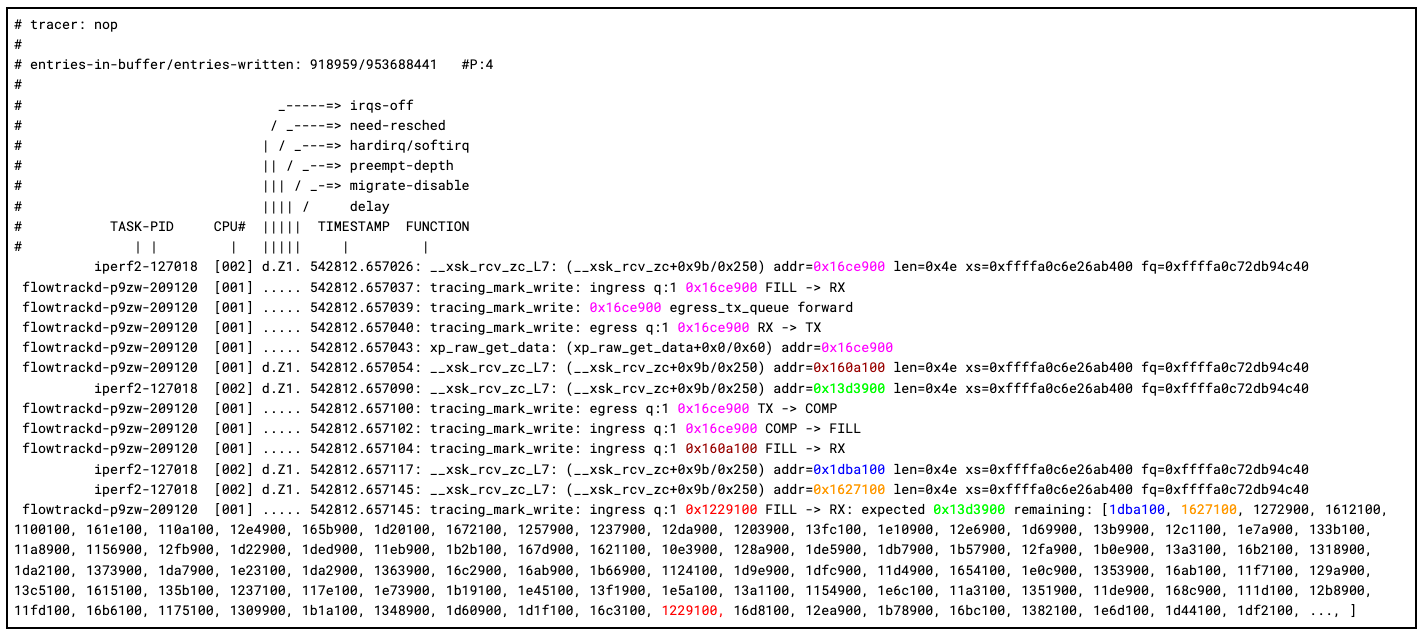
在這裡,您可以看到我們的 ftrace 飛行記錄器的功能非常強大。例如,我們可以追蹤描述元 0x16ce900 的完整週期,它先在核心中接收、由應用程式接收、然後透過新增至 TX 佇列轉寄封包、核心傳輸,最後應用程式接收完成並將描述元放回 FILL 佇列中。
對核心接收的下兩個封包進行追蹤時,事情開始變得有趣起來。我們可以看到 0x160a100 先在核心中接收,然後由應用程式接收。但是,當核心收到 0x13d3900 而應用程式收到 0x1229100 時,就出錯了。追踪的最後一次列印顯示了我們的描述元順序追蹤的結果。我們可以看到,核心端似乎與我們的下一個預期描述元和下兩個描述元相符,但出乎意料的是,我們看到 0x1229100 突然出現了。我們確實認為該描述元存在於 FILL 佇列中,但它在佇列中的位置要靠後很多。另一個潛在有趣的細節是,在 0x160a100 和 0x13d3900 之間,核心的 softirq 從 CPU 1 切換到了 CPU 2。
不知您是否還記得,我們的 __xsk_rcv_zc_L7 kprobe 被置於對 xskq_prod_reserve_desc() 的呼叫上,而後者會將描述元添加到 RX 佇列中。下面我們可以檢查一下該函數,看看是否有什麼線索可以表明,應用程式所接收的描述元位址與我們認為應該由核心插入的描述元位址不同。
static inline int xskq_prod_reserve_desc(struct xsk_queue *q,
u64 addr, u32 len)
{
struct xdp_rxtx_ring *ring = (struct xdp_rxtx_ring *)q->ring;
u32 idx;
if (xskq_prod_is_full(q))
return -ENOBUFS;
/* A, matches D */
idx = q->cached_prod++ & q->ring_mask;
ring->desc[idx].addr = addr;
ring->desc[idx].len = len;
return 0;
}
在這裡,您可以看到在我們更新描述元位址址和長度之前,先遞增了佇列的 cached_prod 指標。顧名思義,cached_prod 指標並不是實際的產生者指標,這意味著在某個時候,必須呼叫 xsk_flush() 來同步 cached_prod 指標和 prod 指標,才能實際將新接收的描述元向使用者模式公開。也許存在這樣一個競爭條件:呼叫 xsk_flush() 應在更新 cached_prod 指標之後,但在環中更新實際描述元位址之前?如果發生這種情況,我們的應用程式會從 RX 佇列的該插槽中看到舊的描述元位址,並導致我們「複製」該描述元。
我們可以再做兩項變更來測試我們的理論。首先,我們可以更新應用程式,在收到封包後,將已知的「污染」描述元位址寫回到每個 RX 佇列插槽。在這種情況下,我們選擇 0xdeadbeefdeadbeef 作為我們已知的無效位址,如果我們從 RX 佇列中收到這個值,我們就知道競爭已經發生並公開了一個未初始化的描述元。我們可以做的第二項變更是在 xsk_flush() 上新增一個 kprobe,看看我們能否在追蹤中實際擷取競爭。
perf probe -a 'xsk_flush:0 xs'

到這裡,我們似乎有了確鑿的罪證。正如我們預測的那樣,我們可以看到在 CPU 0 上呼叫 xsk_flush() ,而 CPU 2 上正在進行 softirq。排清後,我們的應用程式會看到預期的 0xff0900 從 CPU 0 上的 softirq 填入,然後是 0xdeadbeefdeadbeef ,這是我們污染的未初始化的描述元位址。
我們現在有證據表明正在發生以下作業順序:
CPU 2 CPU 0
----------------------------------- --------------------------------
__xsk_rcv_zc(struct xdp_sock *xs): xsk_flush(struct xdp_sock *xs):
idx = xs->rx->cached_prod++ & xs->rx->ring_mask;
// Flush the cached pointer as the new head pointer of
// the RX ring.
smp_store_release(&xs->rx->ring->producer, xs->rx->cached_prod);
// Notify user-side that new descriptors have been produced to
// the RX ring.
sock_def_readable(&xs->sk);
// flowtrackd reads a descriptor "too soon" where the addr
// and/or len fields have not yet been updated.
xs->rx->ring->desc[idx].addr = addr;
xs->rx->ring->desc[idx].len = len;
AF_XDP 文件指出:「所有環都是單一產生者/單一取用者,因此使用者空間應用程式需要明確同步多個處理序/執行緒正在讀取/寫入它們。」明確的同步要求也必須適用於核心端。一個通訊端的 RX 環上的兩項作業如何能夠同時執行?
在 Linux 上,稱為 NAPI 的機制可防止每次網路介面接收封包時發生 CPU 插斷。它指示網路驅動程式頻繁地處理一定數量的封包。對於 veth 驅動程式,輪詢函數被稱為 veth_poll,並註冊為啟用 XDP 的網路裝置的每個佇列的函數處理常式。NAPI 相容的網路驅動程式可保證處理與 NAPI 內容 (struct napi_struct *napi) 繫結的封包不會同時在多個處理器上進行。在我們的案例中,裝置的每個佇列都存在一個 NAPI 內容,這意味著每個 AF_XDP 通訊端及其關聯的一組環形緩衝區(RX、TX、FILL、COMPLETION)。
static int veth_poll(struct napi_struct *napi, int budget)
{
struct veth_rq *rq =
container_of(napi, struct veth_rq, xdp_napi);
struct veth_stats stats = {};
struct veth_xdp_tx_bq bq;
int done;
bq.count = 0;
xdp_set_return_frame_no_direct();
done = veth_xdp_rcv(rq, budget, &bq, &stats);
if (done < budget && napi_complete_done(napi, done)) {
/* Write rx_notify_masked before reading ptr_ring */
smp_store_mb(rq->rx_notify_masked, false);
if (unlikely(!__ptr_ring_empty(&rq->xdp_ring))) {
if (napi_schedule_prep(&rq->xdp_napi)) {
WRITE_ONCE(rq->rx_notify_masked, true);
__napi_schedule(&rq->xdp_napi);
}
}
}
if (stats.xdp_tx > 0)
veth_xdp_flush(rq, &bq);
if (stats.xdp_redirect > 0)
xdp_do_flush();
xdp_clear_return_frame_no_direct();
return done;
}
veth_xdp_rcv() 會處理預算變數所設定的封包數量,將 NAPI 處理標記為完成,可能會重新排程 NAPI 輪詢,然後,呼叫 xdp_do_flush(),從而打破了上述 NAPI 保證。在呼叫 napi_complete_done() 之後,任何 CPU 都可以在前一個呼叫的所有排清作業完成之前隨意執行 veth_poll() 函數,從而允許在 RX 環上進行競爭。
在發出 NAPI 輪詢完成訊號之前,可以透過完成所有封包處理來修復該競爭條件。有關修補程式以及對促進修復的核心郵件清單的討論,請參閱:[PATCH] veth:修復 AF_XDP 公開舊的或未初始化的描述元導致的競爭條件。修補程式最近已在上游合併。
結論
我們在 Linux 虛擬乙太網路 (veth) 驅動程式中發現並修復了一個競爭條件,該競爭條件會損毀啟用 AF_XDP 的裝置的封包!
這個問題很難找到(並重現),但邏輯反覆將我們一路引向 Linux 核心的內部,在那裡,我們看到有幾行程式碼沒有以正確的順序執行。
若要找到潛在複雜錯誤的根本原因,採取嚴格的方法以及掌握有關正確偵錯工具的知識至關重要。
修復這個錯誤對我們來說非常重要,因為雖然 TCP 旨在從偶爾的封包捨棄中復原,但隨機捨棄合法的封包略微增加了在我們網路中建立連線和傳輸資料的延遲。
對深入探討其他核心偵錯過程感興趣嗎?請閱讀我們的部落格,瞭解更多內容!