
Cloudflare 的 应用程序防火墙 (WAF) 可以防止针对 Web 应用程序漏洞的恶意攻击。它不断更新以提供针对最新威胁的全面覆盖,同时确保低误报率。
与所有 Cloudflare 安全产品一样,WAF 的设计不会为了安全性而牺牲性能,但总是有改进的空间。
这篇博客文章简要介绍了我们向客户推出的最新性能改进。访问我们的学习中心,了解更多关于 Web 应用程序防火墙 (WAF) 如何工作的信息。
从 PCRE 到 RE2 的过渡
回到 2019 年 7 月,WAF 从使用基于 PCRE 的正则表达式引擎转变为受 RE2 启发的正则表达式引擎,RE2 是基于确定性有限自动机 (DFA) 而不是回溯算法。此更改是由于更新添加了正则表达式而导致的中断,该正则表达式对某些 HTTP 请求进行了大量回溯,导致执行时间呈指数级增长。
迁移完成后,我们在边缘处没有看到 CPU 消耗的可测量差异,但注意到第 95 百分位和第 99 百分位的执行时间异常值下降了,这是我们预期的结果,因为 RE2 保证的执行时间与输入的大小是线性的。
由于 WAF 引擎使用一个线程池,我们还必须实现和调优线程间共享的 regex 缓存,以避免过度的内存消耗(第一个实现使用了惊人的内存)。
这些变化,以及在事后分析博文中概述的其他变化,帮助我们在边缘上提高了可靠性和安全性,并有信心进一步探索性能改进。
但是,虽然我们强调了正则表达式,但它们只是 WAF 引擎的众多功能之一。
匹配阶段
当一个 HTTP 请求到达 WAF 时,它被组织成几个逻辑部分以进行分析:方法、路径、头和主体。这些部分都存储在 Lua 变量中。如果您对 WAF 实现本身的更多细节感兴趣,可以查看这个旧的演示。
在将这些变量与特定的恶意请求签名匹配之前,需要应用一些转换。这些转换的功能范围很广泛,从简单的修改(如小写字符串)到复杂的标记器和解析器,它们试图识别某些恶意有效负载。
由于 WAF 目前使用的是 ModSecurity 语法的变体,规则可能是这样的:
SecRule REQUEST_BODY "@rx /\x00+evil" "drop, t:urlDecode, t:lowercase"它接受存储在 REQUEST_BODY 变量中的请求体,对其应用 urlDecode() 和小写()函数,然后将结果与正则表达式签名\x00+evil进行比较。
在伪代码中,我们可以表示为:
rx( "/\x00+evil", lowercase( urlDecode( REQUEST_BODY ) ) )这反过来会匹配一个请求,它的请求体包含了百分比编码的空字节,后面跟着单词 “evil”,例如:
POST /cms/admin?action=post HTTP/1.1
Host: example.com
Content-Type: text/plain; charset=utf-8
Content-Length: 16
thiSis%2F%00eVilWAF 包含数千条这样的规则,其目标是尽可能快地执行这些规则,以最小化请求所增加的延迟。更困难的是,它需要在几乎每个请求上运行大多数规则。这是因为几乎所有的 HTTP 请求都是无恶意的,并且没有匹配的规则。所以我们必须针对最坏的情况进行优化:执行所有内容!
为了帮助缓解这个问题,对许多规则执行的第一个匹配步骤之一是预过滤。通过检查请求是否包含某些字节或字符串集,我们可能会跳过相当多的表达式。
在前面的例子中,快速检查 NULL 字节(在正则表达式中由\ x00 表示),如果没有找到,我们可以完全跳过该规则:
contains( "\x00", REQUEST_BODY )
and
rx( "/\x00+evil", lowercase( urlDecode( REQUEST_BODY ) ) )由于大多数请求不匹配任何规则,而且这些检查执行起来很快,所以总体上我们不会通过添加它们来执行更多的操作。
还可以使用其他步骤来扫描和组合多个正则表达式,以避免执行规则表达式。和往常一样,做更少的工作通常是使系统更快的最简单的方法。
记忆有关
这就给我们带来了记忆化——缓存函数调用的输出,以便在以后的调用中重用。
假设我们有以下表达式:
1. rx( "\x00+evil", lowercase( url_decode( body ) ) )
2. rx( "\x00+EVIL", remove_spaces( url_decode( body ) ) )
3. rx( "\x00+evil", lowercase( url_decode( headers ) ) )
4. streq( "\x00evil", lowercase( url_decode( body ) ) )在这种情况下,我们可以重用嵌套的函数调用的结果 (1) (4) 他们是相同的。通过保存中间结果我们也能够利用的结果 url_decode(body) 从 (1) 和 (2) 和 (4) 中使用它。有时也可以交换顺序函数应用于提高缓存,尽管在这种情况下,我们会得到不同的结果。
该系统的简单实现可以是一个散列表,每个条目都以函数名和参数作为键,其输出作为值。
其中一些函数是昂贵的,缓存结果可以显著节省成本。为了给人一种重要性的感觉,我们修改了一个规则,以确保记忆能够发生,它的执行时间减少了大约 95%:
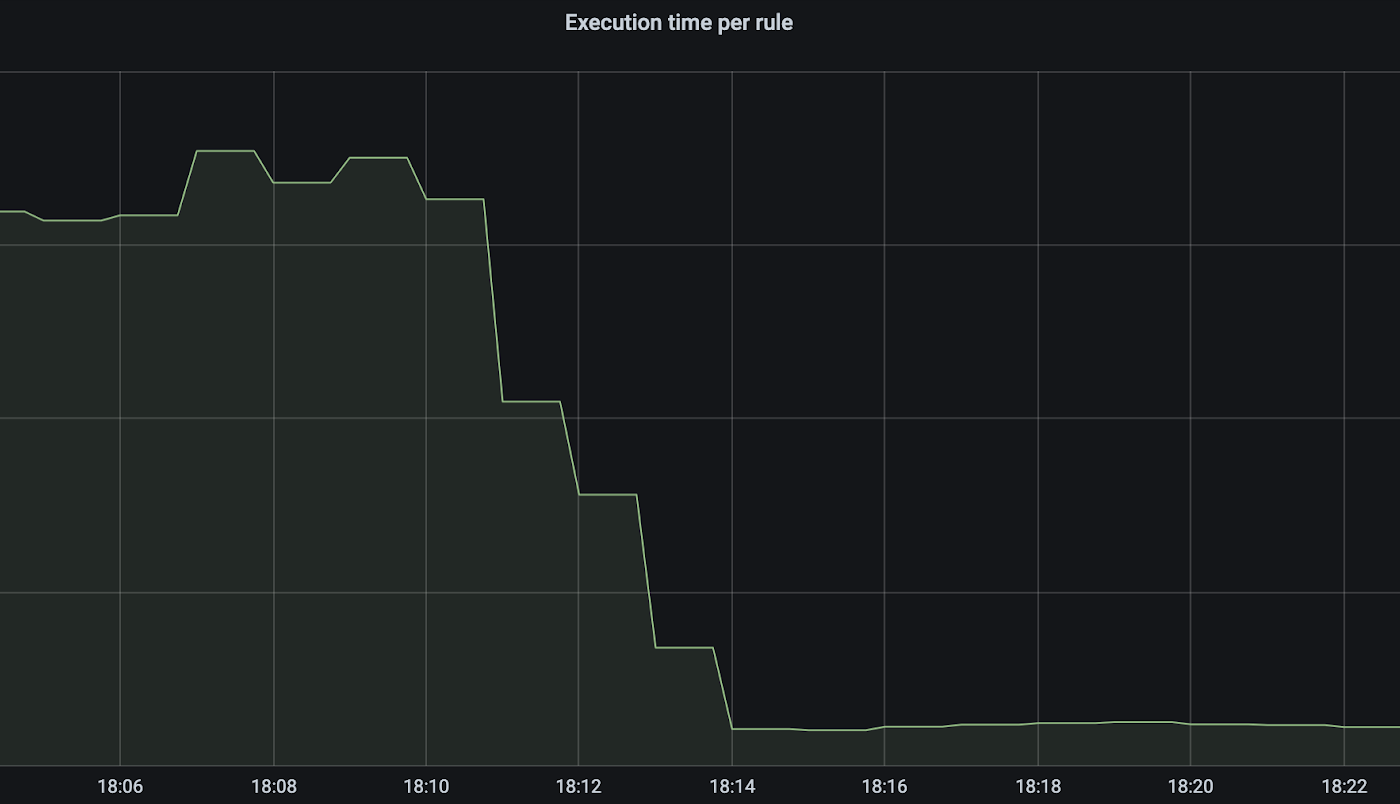
WAF 引擎实现了记忆,规则利用了这一点,但总有增加缓存命中的空间。
重写规则和结果
Cloudflare 定期向托管规则集发布更新和新规则。然而,随着规则的增加和新函数的实现,记忆缓存命中率有下降的趋势。
为了改进这一点,我们首先使用一些性能指标来研究需要花费大量时间的规则:
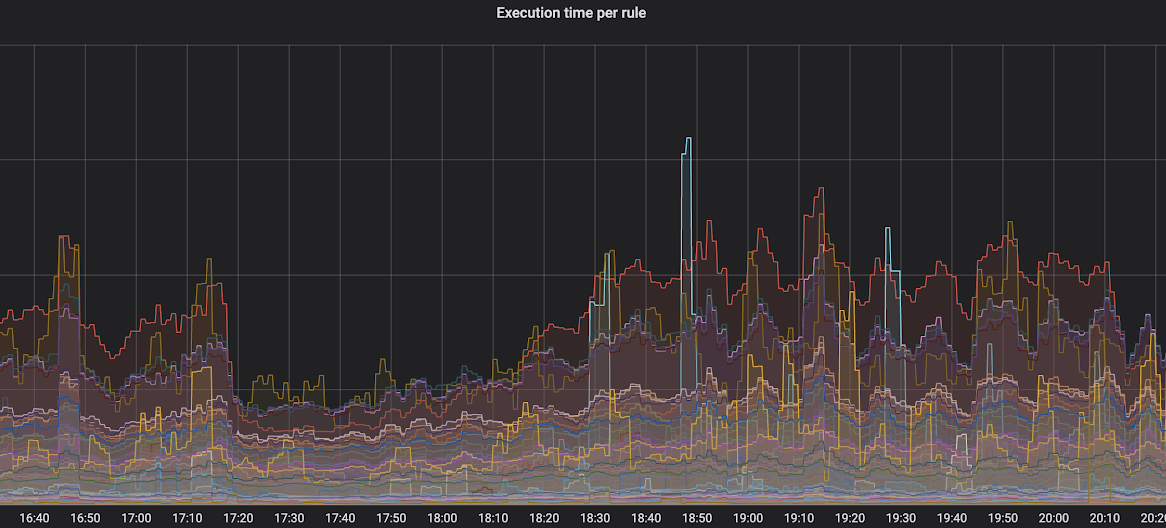
有了这些,我们就可以将它们与缓存未命中的数据进行交叉引用( 输出用 […] 截断 ):
$ ./parse.py --profile
Hit Ratio:
-------------
0.5608
Hot entries:
-------------
[urlDecode, replaceComments, REQUEST_URI, REQUEST_HEADERS, ARGS_POST]
[urlDecode, REQUEST_URI]
[urlDecode, htmlEntityDecode, jsDecode, replaceNulls, removeWhitespace, REQUEST_URI, REQUEST_HEADERS]
[urlDecode, lowercase, REQUEST_FILENAME]
[urlDecode, REQUEST_FILENAME]
[urlDecode, lowercase, replaceComments, compressWhitespace, ARGS, REQUEST_FILENAME]
[urlDecode, replaceNulls, removeWhitespace, REQUEST_URI, REQUEST_HEADERS, ARGS_POST]
[...]
Candidates:
-------------
100152A - replace t:removeWhitespace with t:compressWhitespace,t:removeWhitespace
100214 - replace t:lowercase with (?i)
100215 - replace t:lowercase with (?i)
100300 - consider REQUEST_URI over REQUEST_FILENAME
100137D - invert order of t:replaceNulls,t:lowercase
[...]在确定了 40 多个规则后,我们重新编写了它们,以充分利用记忆的优势,并在可能的情况下添加了预过滤检查。这些变化中的许多并不是很明显,这就是为什么我们也在创建工具来帮助分析师创建更有效的规则。这也有助于确保它们按照团队设置的延迟预算运行。
这一变化导致缓存命中率从 56% 增加到 74% ,这至关重要,其中包括最昂贵的转换。
最重要的是,我们还观察到 WAF 在 Cloudflare 边缘处理和分析 HTTP 请求的平均时间急剧减少了 40%。
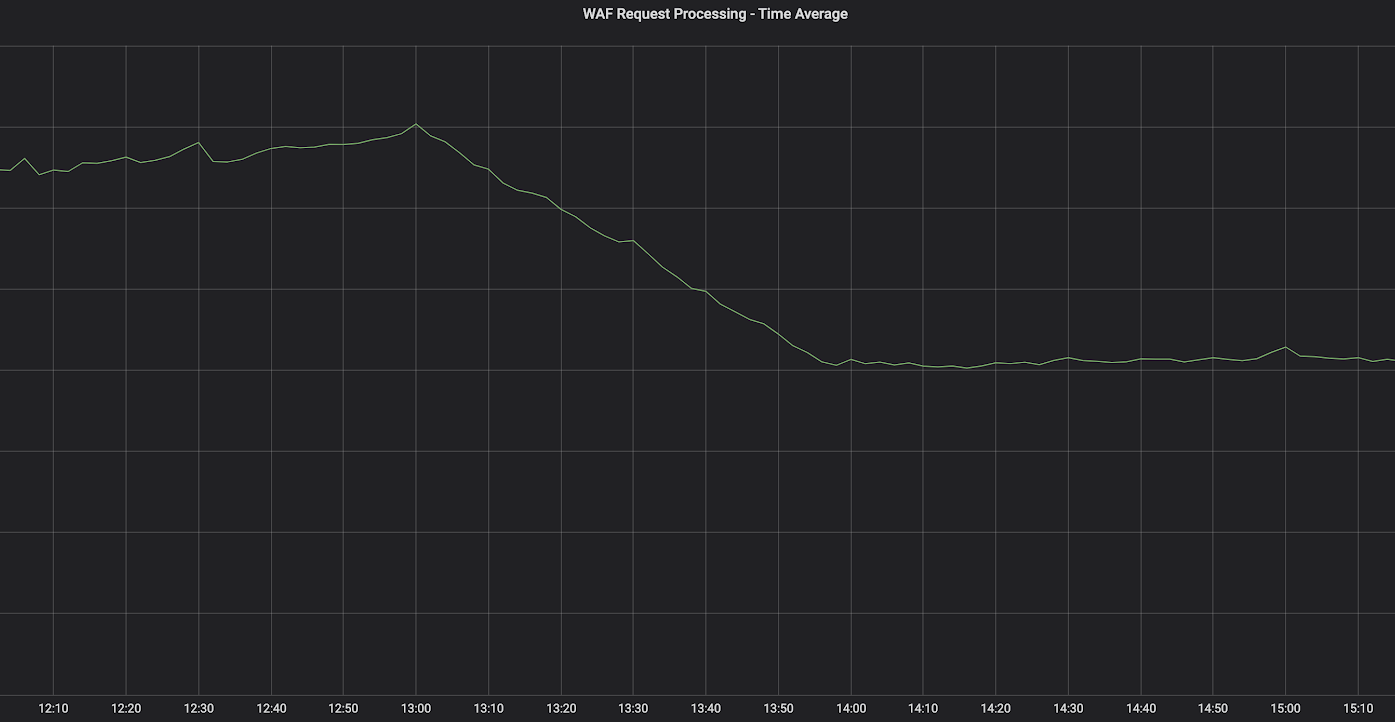
在第 95 百分位和第 99 百分位也观察到类似的下降。
最后,我们看到 CPU 消耗下降了大约 4.3% 。
下一个步骤
虽然这些年来 Lua WAF 一直很好地服务于我们,但我们目前正在将其移植到使用同样的引擎支持防火墙规则的地方。它基于我们的开源 wirefilter 执行引擎,该引擎使用了 Wireshark® 启发的过滤语法。除了允许更灵活的过滤表达式外,它还提供了更好的性能和安全性。
然而,在迁移到新引擎时,我们在这篇博文中所描述的规则优化并没有丢失,因为这些更改并不特定于当前 Lua 引擎的实现。当我们例行地对防火墙堆栈进行分析、基准测试和复杂的优化时,有时仅仅是相对简单的更改就可以产生惊人的巨大影响。