

简介
有许多方法可以存储您应用程序中的数据。例如,在 Cloudflare Workers 应用程序中,我们有用于键值存储的 Workers KV 和可以实时协调存储而不影响一致性的 Durable Objects。您还可以插入 Cloudflare 生态系统之外的其他工具,例如 NoSQL 和图形数据库。
但有时,您想使用 SQL。索引帮助我们快速检索数据。连接可用于描述不同表之间的复杂关系。SQL 使用声明式语言描述如何验证、创建和永久查询我们应用程序的数据。
今天发布了 D1 的公开 α 测试。我想借机分享我使用 D1 构建应用程序的经验:特别是如何入门,以及我为什么对 D1 成为 Cloudflare 上构建应用程序的许多工具之一感到兴奋。
D1 的卓越之处在于,它是向应用程序即时添加值,既不需要新的工具,也不需要离开 Cloudflare 生态系统。使用 Wrangler,我们可以对 Workers 应用程序进行本地开发;而在 Wrangler 中添加 D1 后,我们现在还可以在本地开发适当的有状态的应用程序。然后,在部署应用程序的时候,Wrangler 让我们可以访问并执行对 D1 数据库的命令,以及您的 API 本身。
我们正在构建的产品
在这篇博客文章中,我将向您讲述如何使用 D1 向静态博客网站添加评论。为此,我们将构建一个新的 D1 数据库,并建立一个允许创建和检索评论的简单 JSON API。
我之前提到过,将 D1 与应用程序本身分开(与静态网站分开的 API 和数据库),我们能够将网站的静态和动态部分相互剥离。这也简化了应用程序的部署:我们将把前端部署到 Cloudflare Pages,把 D1 支持的 API 部署到 Cloudflare Workers。
构建新的应用程序
首先,我们将在 Workers 中添加一个基本 API。创建一个新目录,并在其中创建一个新的 Wrangler 项目。
$ mkdir d1-example && d1-example
$ wrangler init
在这个示例中,我们将使用 Hono(一个 Express.js 框架)来快速构建 API。要在项目中使用 Hono,需使用 NPM 安装 Hono:
$ npm install hono
然后,我们将在 src/index.ts 将新的 Hono 应用程序初始化,并定义几个端点:GET /API/posts/:slug/comments 和 POST /get/api/:slug/comments。
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
现在我们将创建一个 D1 数据库。Wrangler 2 支持 wrangler d1 子命令,可以直接从命令行创建和查询 D1 数据库。例如,我们可以使用单个命令创建一个新的数据库。
$ wrangler d1 create d1-example
利用我们创建的数据库,我们可以提取数据库名称 ID,并将其与 wrangler.toml(Wrangler 的配置文件)内的绑定关联起来。绑定让我们可以在代码中使用一个简单的变量名来访问各种 Cloudflare 资源,例如 D1 数据库、KV 命名空间和 R2 存储桶。下面,我们将创建绑定 DB,并用它来表示我们的新数据库:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
请注意,这个指令(即 [[d1_databases]] 字段)目前需要使用 Wrangler 的 beta 版本。您可以使用命令 npm install -D wrangler/beta 为您的项目安装该版本。
在我们的 wrangler.toml 中配置数据库后,我们便可从命令行和 Workers 函数中与之互动。
首先,您可以使用 wrangler d1 execute 直接发布 SQL 命令。
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
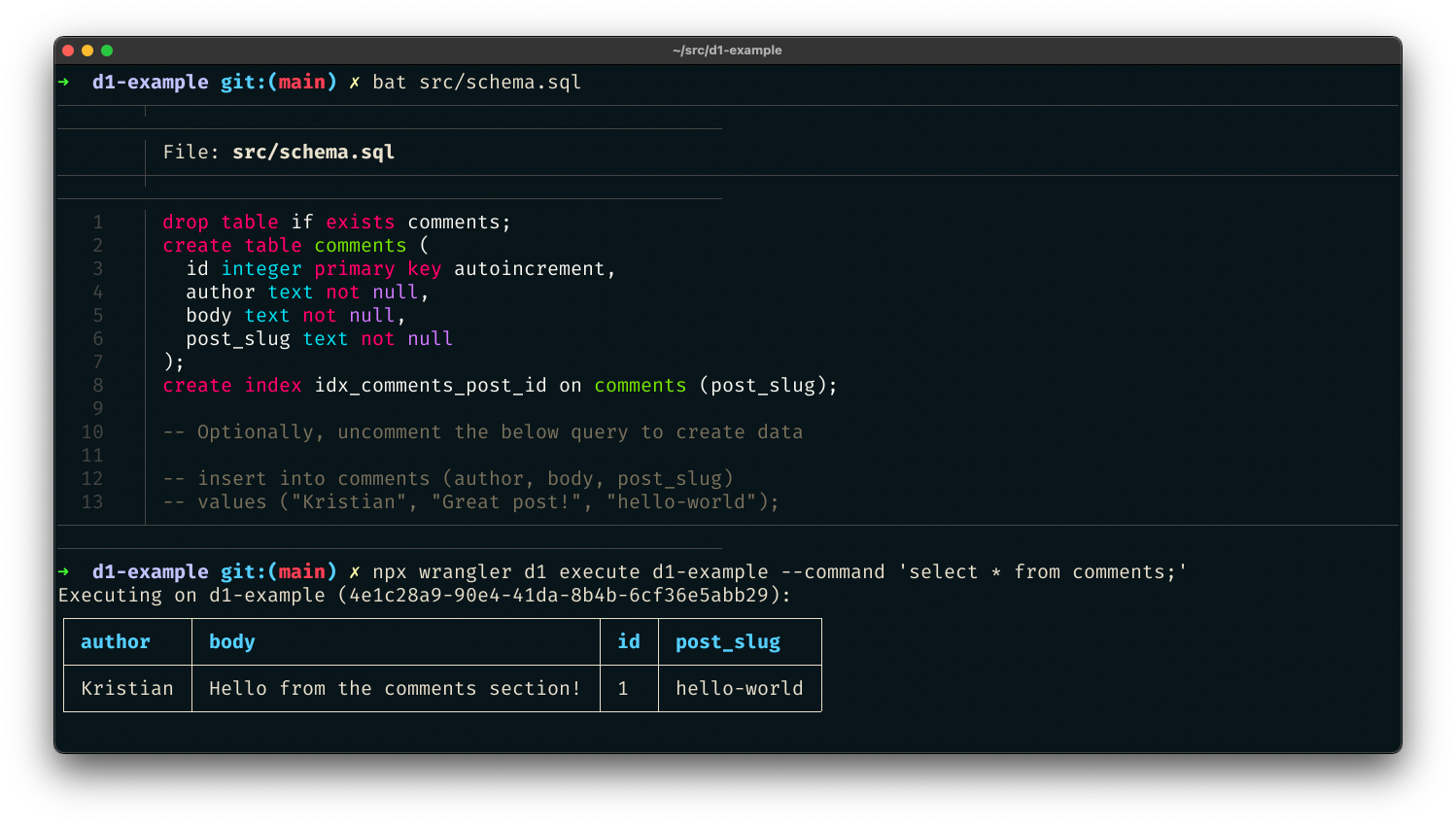
您也可以传递一个 SQL 文件——非常适合在单个命令中进行初始数据种子设定。创建 src/schema.sql,为我们的项目创建一个新的 comments 表。
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
创建文件后,通过向 D1 数据库传递标志 --file,对其执行模式文件。
$ wrangler d1 execute d1-example --file src/schema.sql
我们只用了几个命令就创建了一个 SQL 数据库,并种入初始数据。现在我们可以给 Workers 函数添加一个路由,从该数据库获取数据。根据我们的 wrangler.toml 配置,现可通过 DB 绑定访问 D1 数据库。在我们的代码中,我们可以使用绑定来编写并执行 SQL 语句,例如,检索评论:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
在这个函数中,我们接受了一个 slug URL 查询参数,并设置了一个新的 SQL 语句——我们选择了有一个与查询参数匹配的 post_slug 值的所有评论。然后我们可以把它作为一个简单的 JSON 响应返回。
目前,我们已经构建了对数据的只读访问权限。当然,向 SQL “插入”值也是可能实现的。那么,我们来定义另一个函数,即通过向端点发送 POST 请求来创建新评论:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
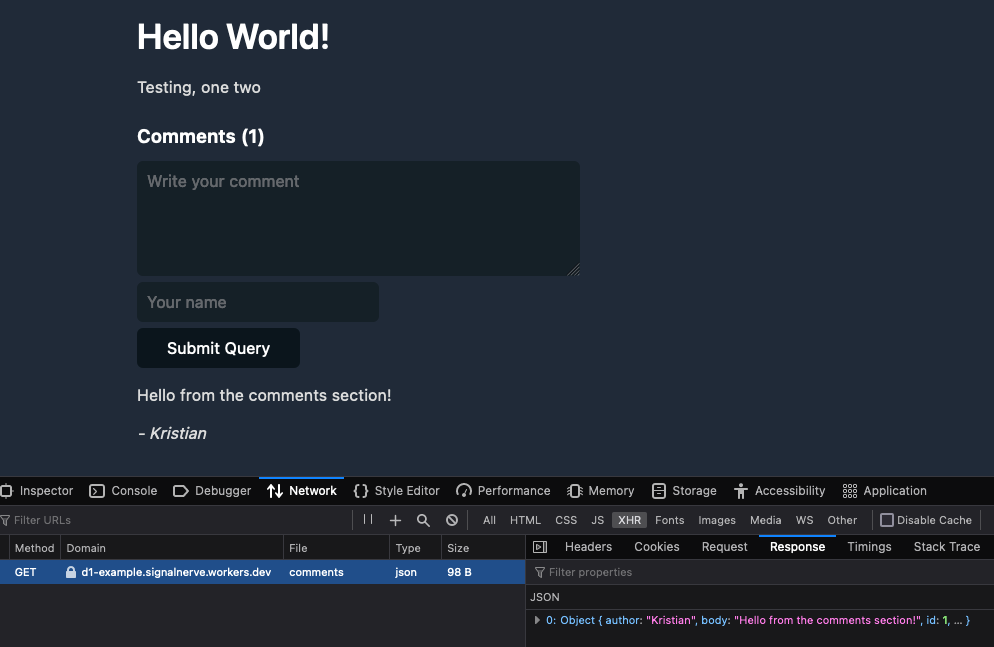
在这个示例中,我们构建了一个评论 API 来支持博客。如需查看这个 D1 驱动的评论 API 的源代码,请访问 cloudflare/templates/worker-d1-api。
总结
D1 最令人振奋的优势之一是,有机会利用动态关系型数据增强现有应用程序或网站。作为曾经的 Ruby on Rails 开发人员,面对 JavaScript 和无服务器开发工具的世界,我最怀念该框架的一点是,能够快速启动完整的数据驱动的应用程序,而不需要成为管理数据库基础设施的专家。利用 D1 及其基于 SQL 的数据的简单入口,我们可以构建真正的数据驱动的应用程序,而不会影响性能或开发人员的体验。
这一转变源于过去几年中使用 Hugo 或 Gatsby 等工具的静态网站的出现。使用 Hugo 等静态网站生成器构建的博客可提供不可思议的性能,只需几秒钟即可构建小型资产。
但是,如果把 WordPress 等工具换成静态网站生成器,您就失去了向您的网站添加动态信息的机会。许多开发人员通过增加构建流程的复杂性来解决这个问题:在构建过程中,获取和检索数据并使用这些数据生成页面。
增加构建流程的复杂性试图解决应用程序缺乏动态性的问题,但它仍然不是真正的动态应用程序。这样的应用程序并不能在创建时检索和显示新数据,而是在数据发生变化时重新构建和部署,因此看起来像实时动态呈现数据。您的应用程序可以保持静态,而动态数据的呈现将在地理上靠近网站的用户,可通过富有表现力的可查询 API 访问。