


我们在三年前发布 Bot Management 时,一开始使用了我们第一个版本的 ML 检测模型。我们使用了常见的机器人用户代理训练我们的模型,识别恶意机器人。此模型即 ML1,它只要检测请求的属性就能判断是机器人还是人类发出的请求。此后,我们引入了一组试探算法,快速、准确地过滤掉有害流量中最容易去除的部分。我们有多种试探算法和数百种具体规则,它们基于请求的特定属性,其中许多属性都很难伪造。但机器学习是我们机器人管理工具集中非常重要的组成部分。
我们一开始使用了静态模型,因为我们是从零开始的,并且我们能够使用汇总的 HTTP 分析元数据快速进行试验。该模型发布后,我们立即从早期机器人管理客户收集了反馈,找出我们的优缺点。我们发现攻击者也更加狡猾了,于是我们生成了一组新的模型功能。我们的试探算法能够准确识别各种恶意机器人,为我们提供质量高很多的标记数据。我们的模型逐渐精进,适应了跨多个请求维度不断改变的机器人行为,即使该模型之前没有针对该类型的数据训练机器人。自那以后,我们又发布了五个模型,它们接受了一些元数据培训,这些元数据是通过理解我们整个网络中的流量模式而生成。
虽然我们的模型在不断精进,流量流经 Cloudflare 的模式也在变化。Cloudflare 诞生于桌面流量占主导地位的时代,但移动流量后来居上,如今占据我们网络流量的 54% 以上。移动流量已经占据网络流量的大半江山,我们需要调整策略,才能更好地检测假冒移动应用程序的机器人。虽然桌面流量都拥有许多相似点,且不论连接到哪种源站,但每个移动应用是围绕特定用途来创建的,并使用不同的定义模式在一组不同的 API 上构建。我们意识到,我们需要构建一种对拥有移动应用程序流量的网站更有效的模型。
我们如何构建和部署模型
在深入探讨我们如何更新模型吸引移动流量并让流量不断增加之前,我们首先应该探讨,我们构建和训练模型的总体思路。
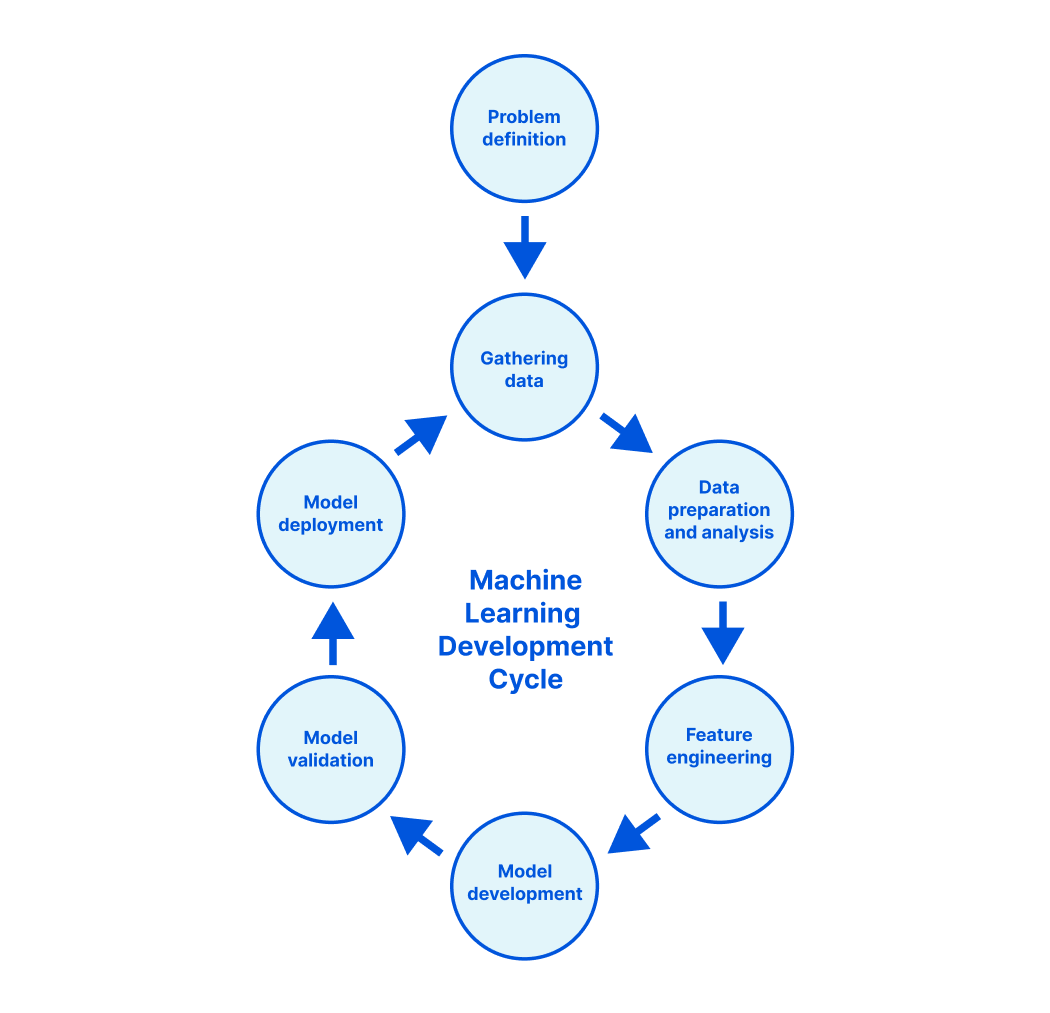
数据收集和准备
ML 模型的质量取决于训练所用的数据质量。我们可以利用网络上数量庞大、种类繁多的流量来创建训练数据集。
我们识别了明显是机器人的示例,即我们能够使用试探算法检测的示例,或者自证是机器人(例如,合法的搜索引擎爬网程序、广告机器人)的示例。
我们还可以识别明显不是机器人的示例。当机器人解决了难题或通过身份认证时,这些请求的分数就会很高。
数据分析和功能选择
从此数据集,我们可以使用 ANOVA(方差分析)f 值识别可使用的最佳功能。我们想让我们的数据集中有各种具有代表性的操作系统、浏览器、设备类型、机器人类别和指纹。我们执行了功能的统计分析,以了解这些功能在数据集内的分布情况,以及它们可能会对预测产生哪些影响。
模型构建和评估
获得数据之后,我们就可以开始训练模型。我们构建了 Airflow 支持的内部管道,使这个过程进行得更顺畅。为了训练模型,我们选择了 Catboost 库。根据我们的问题定义,我们训练了一个二元分类模型。
我们将训练数据拆分为一个训练集和一个测试集。为了选择最适合模型的超参数,我们使用 Catboost 库的网格搜索和随机搜索算法。
然后,我们使用所选超参数训练了模型。
我们逐渐开发了粒度数据集来测试我们的模型,确保我们准确检测到不同类型的机器人,但我们也想将误报率控制在最低水平。在将模型部署到任何客户流量之前,我们会执行离线监控。我们针对不同的浏览器、操作系统和设备运行了预测。然后,我们将当前训练的模型的预测与验证数据集上的生产模型进行比较。比较操作借助于通过我们 ML 管道创建的验证报告,该管道针对每个数据集包含了摘要统计数据,例如准确性、功能重要性。根据结果,要么进行迭代,要么继续进行部署。
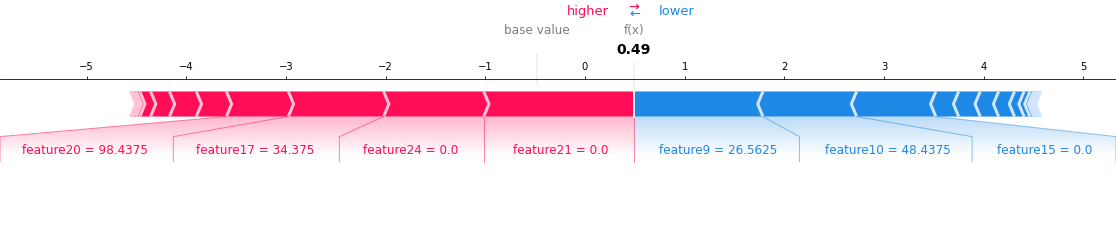
如果我们需要迭代,我们想弄清楚哪些地方有待改进。为此,我们使用了 SHAP Explainer。SHAP Explainer 是一款不错的工具,可解释模型的预测结果。我们的管道根据我们的预测结果生成了 SHAP 图表。我们对其深入研究后,了解误报或漏报情况。这有助于我们理解如何以及在哪些地方可以改进训练数据或功能,以改进预测准确性。当试验表明,我们的大多数测试数据集相比之前的模型版本有所改进时,我们会决定是否应该部署客户流量试验。
模型部署
虽然离线分析模型能精准地指示模型性能,但最好针对更多种类的流量实时验证结果。为此,我们首先在影子模式下部署每个新模型。通过影子模式,我们可以实时记录流量的得分,而不会真正影响机器人管理客户流量。这样一来,我们可以执行在线监控,即针对流量实时评估模型的性能。我们使用一组 Grafana 仪表板按不同机器人、设备、浏览器、操作系统和客户类型进行细分,并验证模型准确性提升情况。
然后,我们开始在活动模式下测试。我们能够将模型推广到不同的客户计划,并按一定比例从请求或访问者中取样。首先,我们推广到免费计划的客户,例如启用 I’m Under Attack 模式的客户。针对免费客户验证模型之后,我们逐渐过渡到超级机器人攻击模式客户。然后,我们允许想测试模型beta 版的客户加入进来,并使用该模型。如果客户对 beta 版满意,新模型将作为稳定版本正式发布。现有客户可以选择升级到该模型,默认所有新客户都能获得最新版本。
我们如何提高移动应用性能
有了最新的模型,我们开始使用上述训练过程,专门提高移动应用流量的性能。要训练模型,我们就需要标注的数据:一组我们已手动注释为“机器人”或“人类”流量的 HTTP 请求。我们从上述各种来源收集这些标注的数据,但有个问题始终困扰者我们,如何找到适合移动应用程序的“人类”流量的数据集。客户能够解析浏览器质询或 CAPTCHA 的情况,就是一个绝佳的“良性”流量示例。遗憾的是,这也限制了我们数据集内能拥有的良性流量种类,因为许多“良性”流量无法解析 CAPTCHA,比如一部分移动应用流量。大多数 CAPTCHA 解决方案依赖 HTML + JavaScript 等 Web 技术,并意图通过 Web 浏览器执行和渲染。另一方面,原生移动应用可能无法正确渲染 CAPTCHA,因此大多数原生移动应用流量从未进入这些数据集。
这意味着,相较于“人类”流量在整个互联网上的普遍程度,来自原生移动应用程序的“人类”流量通常在我们的训练数据中不够有代表性。这进而导致我们的模型在原生移动应用流量上的性能比浏览器流量更差。为了改进这一情况,我们开始寻找更好的数据集。
我们利用了各种技术,来识别我们可以自信地标注为合法原生移动应用流量的那部分请求。我们在移动操作系统以及流行库和框架的开源代码中仔细搜查,确定合法移动应用流量的行为应该是什么样的。我们还与一些客户合作,找出了特定域才有的流量模式,以区分合法移动应用流量和其他类型的流量。
在进行大量测试、反馈和迭代之后,我们得到了多个新的数据集,将其包含到模型训练过程中,极大地提高了移动应用流量的性能。
移动性能的改进
利用来自已验证的移动应用流量的额外数据,我们的最新模型可以理解我们针对移动应用流量所发现的独特模式和信号,从而识别源自这种类型的流量的有效用户请求。本月,我们向一组精选的 beta 版客户发布了最新的机器学习模型,该模型使用我们新识别的有效移动请求数据集进行训练。结果比较乐观。
在一个案例中,一家送餐公司的 Android 流量误报率降至 0.0%。这可能听起来难以置信,但这就是训练可信数据的成果。
在另一个案例中,一家主流的 Web3 平台取得了类似的成绩。之前的模型针对边缘案例应用程序流量呈现出 28.7% 到 40.7% 不等的误报率。我们最新模型的误报率已接近 0.0%。以上只是两个例子,类似的示例比比皆是,因此,希望保护移动应用的客户越来越多地采用了 ML。如果您尚未通过机器人管理保护移动应用,请立即前往 Cloudflare 仪表板,看看新模型能够为您自己的流量带来什么。我们将机器人分析免费发放给所有客户,您马上就能看到机器人在您的移动应用上做些什么,如果发现您想阻止机器人做什么,可以开启机器人管理。如果您的移动应用是由 API 驱动的(大部分移动应用都是这种情况),您还可能需要看一看我们的新 API Gateway。