


自 2023 年 8 月 25 日起,我們開始注意到很多客戶遭受到一些異常大型的 HTTP 攻擊。我們的自動化 DDoS 系統偵測到這些攻擊並加以緩解。但是,沒過多久,它們就開始達到破紀錄的規模,峰值最終剛好超過每秒 2.01 億次請求。這幾乎是之前記錄在案的最大規模攻擊的 3 倍。
而更加深入後發現,攻擊者能夠利用僅由 20,000 台機器組成的 Botnet 發起此類攻擊,而如今的 Botnet 規模可達數十萬或數百萬台機器。整個 web 網路通常每秒處理 10-30 億個請求,因此使用此方法可以將整個 web 網路的請求數量等級集中在少數目標上,而其實是可以達成的。
偵測和緩解
這是一種規模空前的新型攻擊手段,但 Cloudflare 的現有保護主要能夠吸收攻擊的壓力。我們一開始就注意到一些客戶流量影響 (在第一波攻擊期間約影響 1% 的請求); 如今,我們仍在持續改善緩解方法,以阻止對任何 Cloudflare 客戶發動的攻擊,而且不會影響我們的系統。
我們注意到這些攻擊,同時也有其他兩家主流的業內廠商(Google 和 AWS)發現相同的狀況。我們竭力強化 Cloudflare 的系統,以確保現今所有客戶都能免於此新型 DDoS 攻擊方法的侵害,而且沒有任何客戶受到影響。我們還與 Googel 和 AWS 合作,協調披露受影響廠商和關鍵基礎架構提供者遭受的攻擊。
此攻擊是透過濫用 HTTP/2 通訊協定部分功能和伺服器實作詳細資料才得以發動(請參閱 CVE-2023-44487 瞭解詳細資料)。因為攻擊會濫用 HTTP/2 通訊協定中的潛在弱點,所以我們認為任何實作 HTTP/2 的廠商都會遭受攻擊。這包括每部現代 Web 伺服器。我們與 Google 和 AWS 已經將攻擊方法披露給預期將實作修補程式的 Web 伺服器廠商。在這段期間,最佳防禦就是針對任何面向 Web 的網頁或 API 伺服器使用 DDoS 緩解服務(例如 Cloudflare)。
本文將深入探討 HTTP/2 通訊協定、攻擊者用於發動這些大規模攻擊的功能,以及我們為確保所有客戶均受到保護而採取的緩解策略。我們希望在發布這些詳細資料後,其他受影響的 Web 伺服器和服務即可取得實施緩解策略所需的資訊。此外,HTTP/2 通訊協定標準團隊和未來 Web 標準制定團隊,都能進一步設計出預防此類攻擊的功能。
RST 攻擊詳細資料
HTTP 是支援 Web 的應用程式通訊協定。HTTP 語意為所有版本的 HTTP 所共用;整體架構、術語及通訊協定方面,例如請求和回應訊息、方法、狀態碼、標頭和後端項目欄位、訊息內容等等。每個 HTTP 版本將定義如何將語意轉化為「有線格式」以透過網際網路交換。例如,客戶必須將請求訊息序列化為二進位資料並進行傳送,接著伺服器會將其剖析回可處理的訊息。
HTTP/1.1 採用文字形式的序列化。請求和回應訊息交換為 ASCII 字元串流,透過 TCP 等可靠的傳輸層傳送,並使用下列格式(其中的 CRLF 表示斷行和換行):
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]
例如,對 https://blog.cloudflare.com/ 非常簡單的 GET 請求在網路上看起來像這樣:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
回應如下所示:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
此格式框住網路上的訊息,表示可使用單一 TCP 連線來交換多個請求和回應。但是,該格式要求完整傳送每則訊息。此外,為使請求與回應正確關聯,需要嚴格排序;表示訊息會依次交換且無法多工處理。以下是 https://blog.cloudflare.com/ 和 https://blog.cloudflare.com/page/2/ 的兩個 GET 請求:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
回應如下:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
比起這些範例,網頁需要更複雜的 HTTP 互動。造訪 Cloudflare 部落格時,您的瀏覽器會載入多個指令碼、樣式及媒體資產。如果您使用 HTTP/1.1 造訪首頁並決定瀏覽至第 2 頁,則瀏覽器可從兩個選項中任選。在第 2 頁還無法開始前,將您不再需要的頁面等待所有排入佇列的回應,或者關閉 TCP 連線並開啟新連線以取消處理中的請求。這些都不是非常實用。瀏覽器通常會管理 TCP 連線集區(每個主機最多 6 個),然後在集區上實作複雜的請求分派邏輯,藉此解決這些限制。
HTTP/2 解決了許多 HTTP/1.1 的問題。每個 HTTP 訊息會序列化為一組具有類型、長度、標誌、串流識別碼 (ID) 及負載的 HTTP/2 框架。串流 ID 明確說明了網路上的哪個位元組適用於哪個訊息,並允許安全的多工處理和並行處理。串流具有雙向特性。用戶端會使用相同 ID 來傳送框架和具有框架的伺服器回應。
在 HTTP/2 中,https://blog.cloudflare.com 的 GET 請求會跨 Stream ID 1 交換,其中用戶端傳送一個 HEADERS 框架,伺服器則回應一個 HEADERS 框架,接著是一個或多個 DATA 框架。用戶端請求一律使用奇數的 Stream ID,因此後續請求會使用 Stream ID 3、5 等等。回應可以是任何順序,而且不同串流的框架可以交錯。
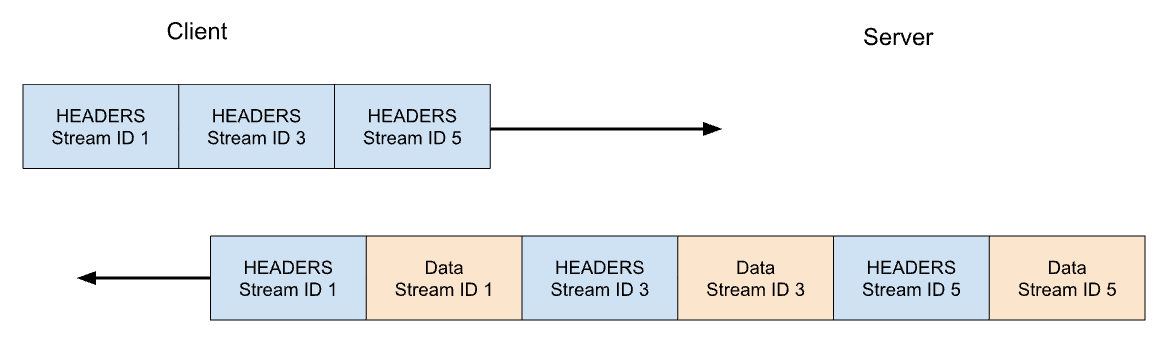
Stream 多工處理和並行處理是 HTTP/2 的強大功能。它們可更有效地使用單一 TCP 連線。HTTP/2 將資源最佳化,特別是搭配優先順序時擷取的資源。另一方面,與 HTTP/1.1 相比,讓用戶端輕鬆啟動大量平行工作,可能會增加伺服器資源的尖峰需求。這是阻斷服務的明顯手段。
為建立一些防護機制,HTTP/2 提供最大作用中並行串流的概念。SETTINGS_MAX_CONCURRENT_STREAMS 參數允許伺服器宣告其並行處理限制。例如,如果伺服器指出 100 的限制,則任何時間都只會有 100 個作用中請求。如果用戶端嘗試開啟超過此限制的串流,則須由使用 RST_STREAM 框架的伺服器拒絕。串流拒絕不會影響連線上的其他處理中串流。
實際情況會更複雜一點。串流具有生命週期。以下是 HTTP/2 串流狀態機器的圖表。用戶端和伺服器會管理自己的串流狀態檢視。HEADERS、DATA 及 RST_STREAM 框架會在傳送或接收時觸發轉換。雖然串流狀態可獨立檢視,但已完成同步。
HEADERS 和 DATA 框架包括 END_STREAM 標誌,在設定為數值 1 (true) 時,可觸發狀態轉換。

讓我們利用無訊息內容的 GET 請求範例來逐步解決此狀況。用戶端會在具有 END_STREAM 標誌的 HEADERS 框架設定為 1 時傳送請求。用戶端首先會將串流狀態從閒置轉換為開啟狀態,然後立即轉換為半關閉狀態。用戶端半關閉狀態表示無法再傳送 HEADERS 或 DATA,只會傳送 WINDOW_UPDATE、PRIORITY 或 RST_STREAM 框架,但是可接收任何框架。
伺服器接收並剖析 HEADERS 框架後,即會將串流狀態從閒置轉換為開啟及半關閉,以便與用戶端相符。伺服器半關閉狀態表示可傳送任何框架,但只會接收 WINDOW_UPDATE、PRIORITY 或 RST_STREAM 框架。
GET 回應包含訊息內容,因此伺服器傳送 HEADERS 時 END_STREAM 標誌設定為 0,傳送 DATA 時 END_STREAM 標誌設定為 1。DATA 框架會在伺服器上觸發從半關閉到關閉的串流轉換。當用戶端接收時,也會轉換為關閉。串流關閉後,無法傳送或接收任何框架。
將此生命週期套用回並行處理背景後,HTTP/2 指出:
處於「開啟」狀態或「半關閉」狀態的串流會計入允許端點開啟的最大串流數。這些狀態中的串流會計入在 SETTINGS_MAX_CONCURRENT_STREAMS 設定中宣告的限制。
理論上,並行處理限制很實用。但還是有阻礙其效率的實際因素,我們稍後將在部落格中介紹。
HTTP/2 請求取消
之前,我們介紹了處理中請求的用戶端取消。與 HTTP/1.1 相比,HTTP/2 支援這項作業的方式更有效率。不需要斷開整個連線,用戶端即可傳送單一串流的 RST_STREAM 框架。這會指示伺服器停止處理請求和中止回應,進而釋放伺服器資源及避免浪費頻寬。
我們來考量一下先前 3 個請求範例。這次用戶端在所有 HEADERS 傳送完畢後取消了串流 1 上的請求。伺服器則會在準備提供回應前剖析此 RST_STREAM 框架,轉而僅回應串流 3 和 5:
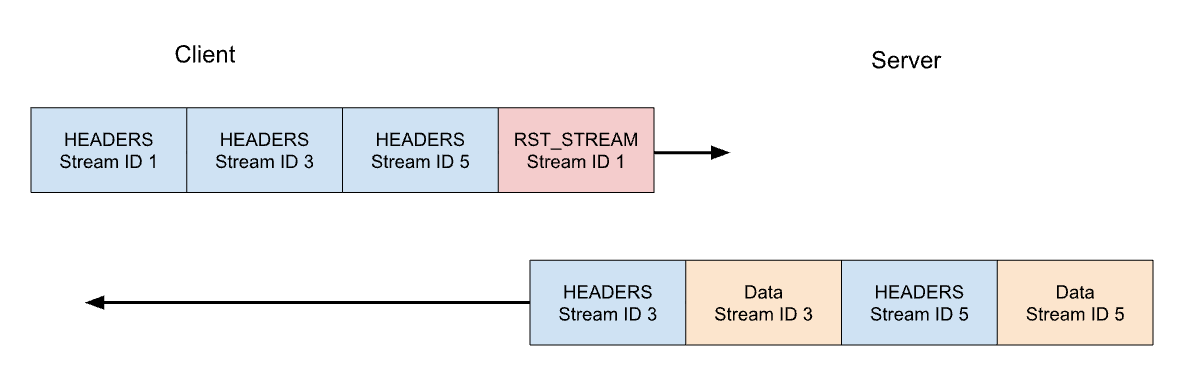
請求取消是實用的功能。例如,捲動具有多張影像的網頁時,Web 瀏覽器可以取消檢視區以外的影像,表示影像進入該區後的載入速度更快。比起 HTTP/1.1,HTTP/2 讓這個行為變得更有效率。
取消的請求串流會在整個串流生命週期中轉換。用戶端的 HEADERS 在 END_STREAM 標誌設定為 1 時,狀態會從閒置轉換到開啟和半關閉,然後 RST_STREAM 會立即產生半關閉到關閉的轉換。

回想一下,只有開啟或半開放狀態的串流會造成串流並行處理限制。當用戶端取消串流時,才能在其位置中開啟另一個串流,而且可以立即傳送另一個請求。這是 CVE-2023-44487 得以運作的關鍵。
導致阻斷服務的快速重設
HTTP/2 請求取消可能被濫用來快速重設無數串流。當 HTTP/2 伺服器處理用戶端傳送之 RST_STREAM 框架及斷開狀態的速度夠快時,此類快速重設就不會造成問題。當整理作業有任何種類的延遲或延滯時,問題就會開始突然出現。用戶端可能會處理太多因工作積壓而累積的請求,導致伺服器上的資源過度消耗。
常見的 HTTP 部署架構是在其他元件前執行 HTTP/2 Proxy 或負載平衡器。用戶端請求到達時即會快速分派,而且實際工作在其他位置以非同步活動完成。這可讓 Proxy 非常高效地處理用戶端流量。但是,此關注點分離會讓 Proxy 難以整理進行中的工作。因此,這些部署更有可能遇到快速重設造成的問題。
當 Cloudflare 的反向 Proxy 處理傳入的 HTTP/2 用戶端流量時,它們會將連線通訊端的資料複製到依序緩衝資料的緩衝區和程序。讀取每個請求時(HEADERS 和 DATA 框架),即會分派至上游服務。讀取 RST_STREAM 框架時,即會卸除請求的本機狀態並通知上游已取消該請求。重複該程序直到消耗掉整個緩衝區。但是,此邏輯可能被濫用:當惡意用戶端在連線初期開始傳送大型請求和重設鏈時,我們的伺服器會迫不急待讀取所有內容並在上游伺服器上建立壓力,直到能夠處理任何新的傳入請求為止。
特別強調一點,串流並行處理無法自行緩解快速重設。用戶端可以處理請求以建立高請求率,無論伺服器的 SETTINGS_MAX_CONCURRENT_STREAMS 選定值為何。
Rapid Reset 詳細分析
以下範例為使用嘗試提出共計 1,000 個請求的概念驗證用戶端來重現的 Rapid Reset。我使用了現成伺服器且沒有任何緩解措施;在測試環境中接聽連接埠 443。已使用 Wireshark 詳細分析流量並經過篩選,且為了清楚起見,僅顯示 HTTP/2 流量。下載該 pcap 以遵循。

由於框架太多,有點難看到。我們可以透過 Wireshark 統計資料 > HTTP2 工具取得快速摘要:
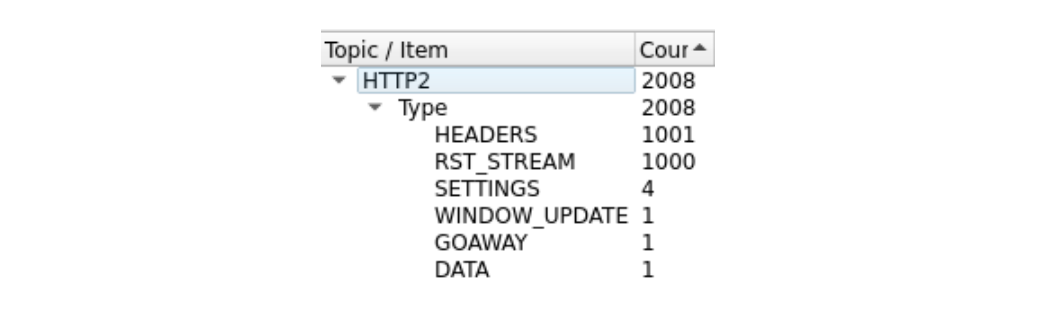
在封包 14 中,此追蹤的第一個框架為伺服器的 SETTINGS 框架,其宣告 100 的串流並行處理上限。在封包 15 中,用戶端會傳送一些控制框架並開始提出快速重設的請求。第一個 HEADERS 框架長度為 26 個位元組,所有後續的 HEADERS 則只有 9 個位元組。名稱為 HPACK 的壓縮技術造成了這項大小差異。封包 15 共包含 525 個請求,並往上至串流 1051。
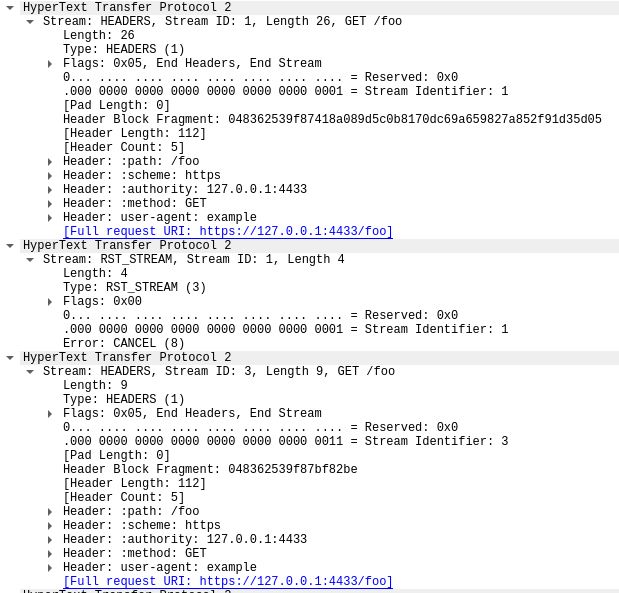
有趣的是,串流 1051 的 RST_STREAM 不適合封包 15,所以我們在封包 16 看到了 404 回應的伺服器回應。接著在封包 17 中,用戶端的確傳送了 RST_STREAM,然後繼續傳送剩餘的 475 個請求。
請注意,雖然伺服器宣告了 100 個並行串流,用戶端傳送的封包還傳送了數量更多的 HEADERS 框架。用戶端不必等待任何從伺服器傳回的流量,唯一限制為可傳送的封包大小。此追蹤沒有任何伺服器 RST_STREAM 框架,表明伺服器並未觀察到並行的串流違規事件。
對客戶的影響
如上所述,取消請求時即會通知上游服務,而且可能在浪費太多資源前中止請求。這是此次攻擊的情況,其中大多數的惡意請求從未轉傳至原始伺服器。但是,這些攻擊的龐大規模並未造成一些影響。
首先,隨著傳入請求率達到前所未有的峰值,我們收到了用戶端所發現 502 錯誤數量漸增的報告。這發生在我們受影響程度最大的資料中心,目前正努力處理所有請求。雖然我們的網路旨在處理大型攻擊,這項特殊漏洞還是暴露了我們基礎架構中的弱點。我們來進一步探討細節,並將重點放在傳入請求到達我們其中一個資料中心時如何受到處理:
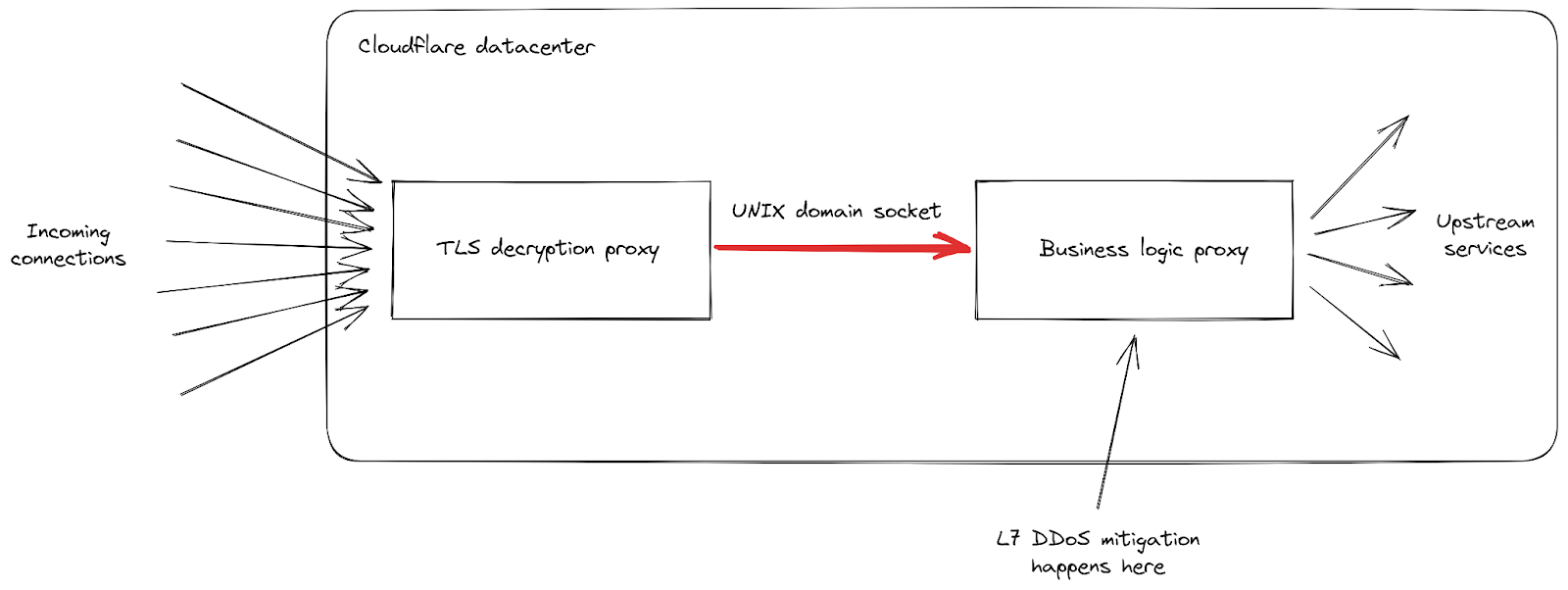
我們可以看到基礎架構由責任不同的各種 Proxy 伺服器組成。特別是,當用戶端連線至 Cloudflare 以傳送 HTTPS 流量時,會先到達我們的 TLS 解密 Proxy:可解密 TLS 流量、處理 HTTP 1、2 或 3 流量,然後將其轉傳至「商務邏輯」Proxy。這會負責為每個客戶載入所有設定,然後將請求正確路由至其他上游服務;在我們案例中更重要的是,這也會負責安全功能。此時會處理 L7 攻擊緩解。
此攻擊手段的問題是,它有辦法非常快速地在每一次連線中傳送大量請求。每個請求都必須轉傳至商務邏輯 Proxy,我們才有機會加以封鎖。隨著請求輸送量變得比我們的 Proxy 容量還要高,連線這兩項服務的管道在部分伺服器中都達到了其飽和程度。
此情況發生時,TLS Proxy 即無法再連線至它的上游 Proxy,因此在大多數嚴重攻擊期間,有些用戶端會看到裸機的「502 錯誤的閘道」錯誤。請務必注意,截至今日為止,我們的商務邏輯 Proxy 也會發出用於建立 HTTP 分析的記錄。後果就是 Cloudflare 儀表板鐘看不到這些錯誤。我們的內部儀表板顯示第一波攻擊期間約有 1% 請求受到影響,並在 8 月 29 日最嚴重的一次期間,達到幾秒約 12% 的峰值。下列圖表顯示此情況發生期間的兩小時內,這些錯誤的比率:

如本文稍後詳述的內容,我們在接下來幾天內努力將這個數字大幅減少。得益於我們堆疊中的變更及緩解措施,顯著減少了這些攻擊的規模,這個數字在今日實際上是零。

499 錯誤及 HTTP/2 串流並行處理的挑戰
部分客戶回報的另一個症狀為 499 錯誤有所增加。此情況的原因有點不同,而且與本文稍早詳述之 HTTP/2 連線中的串流並行處理上限相關。
HTTP/2 設定在連線開始時使用 SETTINGS 框架交換。在沒有接收明確參數的情況下,則適用於預設值。在用戶端建立 HTTP/2 連線後,即可等待伺服器的 SETTINGS(緩慢),或者假設預設值並開始提出請求(快速)。對於 SETTINGS_MAX_CONCURRENT_STREAMS,預設值其實沒有限制(串流 ID 使用 31 位元數的空格且請求使用奇數,因此實際限制為 1,073,741,824 次)。規格建議伺服器提供的串流不少於 100 個。用戶端一般偏向速度,所以請勿等待伺服器設定,其中會產生一些競爭條件。用戶端會在伺服器可能挑選的限制上賭一把;如果它們選錯,請求即會遭到拒絕且必須重試一次。要賭 1,073,741,824 個串流的話,有點愚蠢。取而代之的是,很多用戶端決定限制自身發出 100 個並行串流,並希望伺服器遵循規格建議。如果伺服器挑選的數字為 100 以下,表示用戶端賭輸,然後會重設串流。
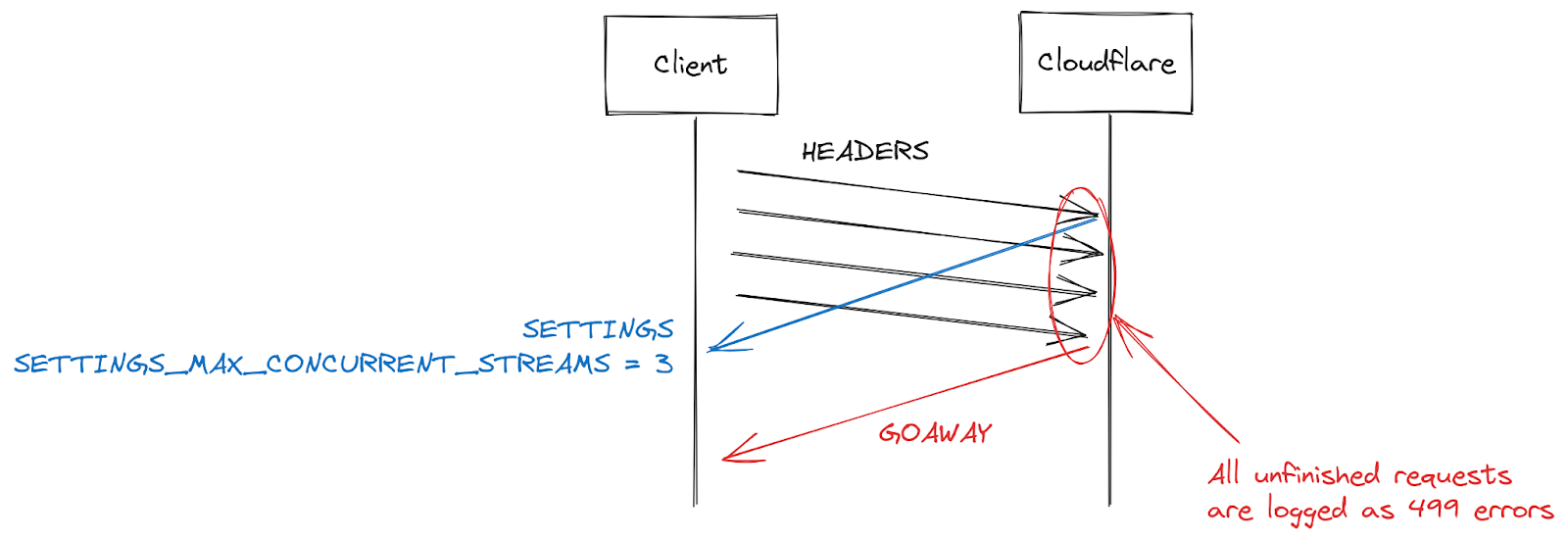
伺服器可能將串流重設為超出並行處理限制的原因有很多。HTTP/2 很嚴格且在出現剖析或邏輯錯誤時要求串流關閉。在 2019 年,Cloudflare 制度了多項緩解措施以回應 HTTP/2 DoS 漏洞。那些漏洞有很多是因用戶端行為不當造成,並導致伺服器重設串流。若要壓制此類用戶端,計算連線期間的伺服器重設數目是非常有效的策略,還可以在超出部分閾值時,關閉具有 GOAWAY 框架的連線。合法用戶端可能會出現一或兩個連線錯誤,此為合理情況。如果用戶端出現太多錯誤,則可能處於損壞或惡意狀態,關閉連線可解決這兩種情況。
在回應 CVE-2023-44487 啟用的 DoS 攻擊時,Cloudflare 將串流並行處理上限減少至 64。進行此變更前,我們並不清楚用戶端不會等待 SETTINGS,而是假設並行處理為 100。有些網頁(例如影像庫)的確會讓瀏覽器在連線初期立即傳送 100 個請求。遺憾的是,36 個超出我們限制的串流全都需要重設,因而觸發我們的計算緩解措施。這表示我們關閉了合法用戶端上的連線,導致完整頁面載入失敗。在我們意識到此互通性問題時,我們就立即將串流並行處理上限變更 100。
Cloudflare 端採取的行動
在 2019 年,我們發現多項 DoS 漏洞與 HTTP/2 實作相關。Cloudflare 在回應中發展並部署了一系列偵測和緩解措施。CVE-2023-44487 是 HTTP/2 漏洞的不同表現。但是,為緩解此問題,我們能夠擴展現有保護以監控用戶端傳送的 RST_STREAM 框架,並且在連線受到濫用時將其關閉。RST_STREAM 在合法用戶端使用上不會受到影響。
除了直接修復之外,我們對伺服器的 HTTP/2 框架處理和請求分派代碼實作了多項改善。此外,商務邏輯伺服器收到了佇列和排程改善,可減少不不要的工作並改善取消的回應能力。這些可共同降低各種潛在濫用模式的影響,並且在飽和前為伺服器提供更多處理請求的空間。
提早緩解攻擊
Cloudflare 已配備可有效緩解非常大型攻擊的系統,而且是更經濟實惠的方法。其中一項稱為「IP Jail」。對於巨流量攻擊,此系統會收集參與攻擊的用戶端 IP,並阻止它們連線至受到攻擊的財產,無論是 IP 層級或位於我們的 TLS Proxy 中。但是,此系統需要幾秒才能充分發揮效果;在珍貴的幾秒之間,原始伺服器已受到保護,但我們的基礎架構還是需要吸收所有 HTTP 請求。由於這種新的殭屍網路實際上沒有啟動期間,因此我們能夠抵禦攻擊,以免造成問題。
為實現此目標,我們擴展了 IP Jail 系統以保護整個基礎架構:只要 IP「受到監禁」,不僅無法連線至受到攻擊的財產,我們還會在一段期間內禁止相應 IP 使用 HTTP/2 連線至 Cloudflare 上的其他網域。由於使用 HTTP/1.x 時無法濫用此類通訊協定,這限制了攻擊者執行大型攻擊的能力,而任何共用相同 IP 的合法用戶端在此期間內只會看到非常小幅度的效能降低。基於 IP 的緩解措施是非常遲鈍的工具;這就是為什麼我們在大規模採用並儘量設法避免誤判時必須極度謹慎。此外,殭屍網路中特定 IP 的生命週期通常很短,所以任何長期緩解措施有可能弊大於利。下圖顯示我們所見證攻擊中 IP 流失的情況:
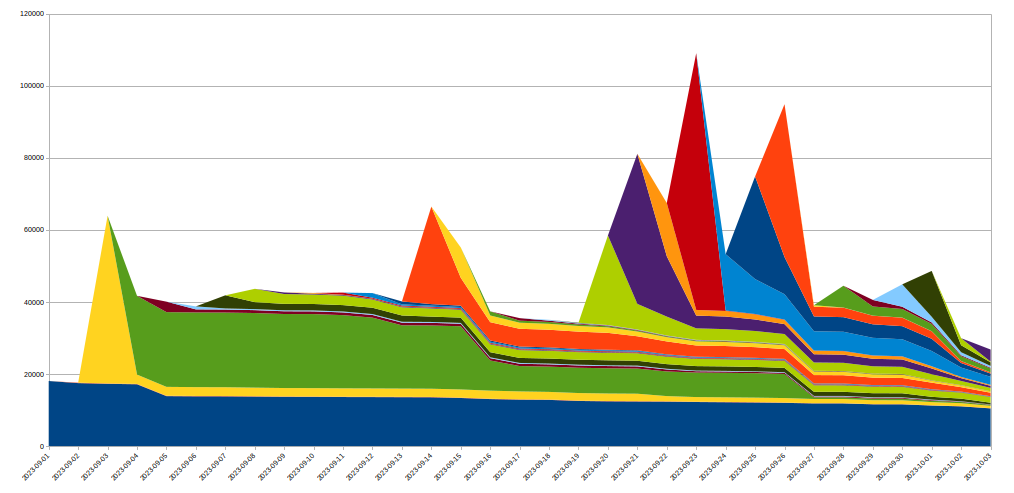
如我們所見,很多在特定日期發現的新 IP 隨後都消失得非常快。
由於所有動作都發生在 HTTPS 管道開始處的 TLS Proxy 中,因此相較於常規的第 7 層緩解系統,這節省了大量資源。我們還可更加順暢地處理這些攻擊,目前由這些殭屍網路造成的隨機 502 錯誤數目已降至零。
可觀察性改善
我們做出變更的另一方面是可觀察性。向用戶端傳回錯誤卻未顯示於客戶分析中,令人很不滿意。幸運的是,早在近期的攻擊之前,這些系統的檢修專案已在進行中。最終讓我們基礎架構中的每項服務記錄自己的資料,而不是依賴商務邏輯 Proxy 整合並發出記錄資料。此事件強調了這項工作的重要性,而且我們正在加倍投入心力。
我們也在發展更好的連線層級記錄功能,以便更快速地找出此類通訊協定濫用,進而改善我們的 DDoS 緩解能力。
結論
雖然這是最新一次破紀錄的攻擊,但我們知道不只如此。隨著攻擊變得越來越複雜,Cloudflare 只有堅持不懈地主動識別新的威脅,同時為全球網路部署對策,才能讓我們數百萬名客戶獲得即時和自動的保護。
Cloudflare 自 2017 年起向我們所有客戶提供了免費、非計量且無限制的 DDoS 保護。此外,我們還有一系列額外的安全功能,符合所有規模的組織需求。如果您不確定自己是否受到保護或想瞭解如何受到保護,請聯絡我們。