

介紹
有許多方法可以在應用程式中儲存資料。例如,在 Cloudflare Workers 應用程式中,我們有用於鍵值儲存的 Workers KV,以及用於即時協調儲存的 Durable Objects,而不會影響一致性。在 Cloudflare 生態系統之外,您還可以插入其他工具,如 NoSQL 和圖形資料庫。
但有時,您需要 SQL。Index 讓我們能夠快速擷取資料。Join 讓使我們能夠描述不同表單之間的複雜關係。SQL 以聲明方式描述如何驗證、建立及高效查詢應用程式的資料。
今天,D1 發佈了公開 alpha 版,,為了表示慶祝,我希望分享使用 D1 構建應用程式的經驗:具體來說,即如何開始,以及為什麼我對 D1 加入可用於在 Cloudflare 上構建應用程式的長工具清單感到興奮。
D1 非常出色,因為它可以即時為應用程序增值,而無需新工具或在 Cloudflare 生態系統之外進行。使用 wrangler,我們可以對 Workers 應用程式進行本機開發,並且在 wrangler 中新增 D1,我們現在也可以在本機開發適當的有狀態的應用程式。然後,當需要部署應用程式時,wrangler 允許我們存取 D1 資料庫及 API 本身並對其執行命令。
我們正在構建什麼
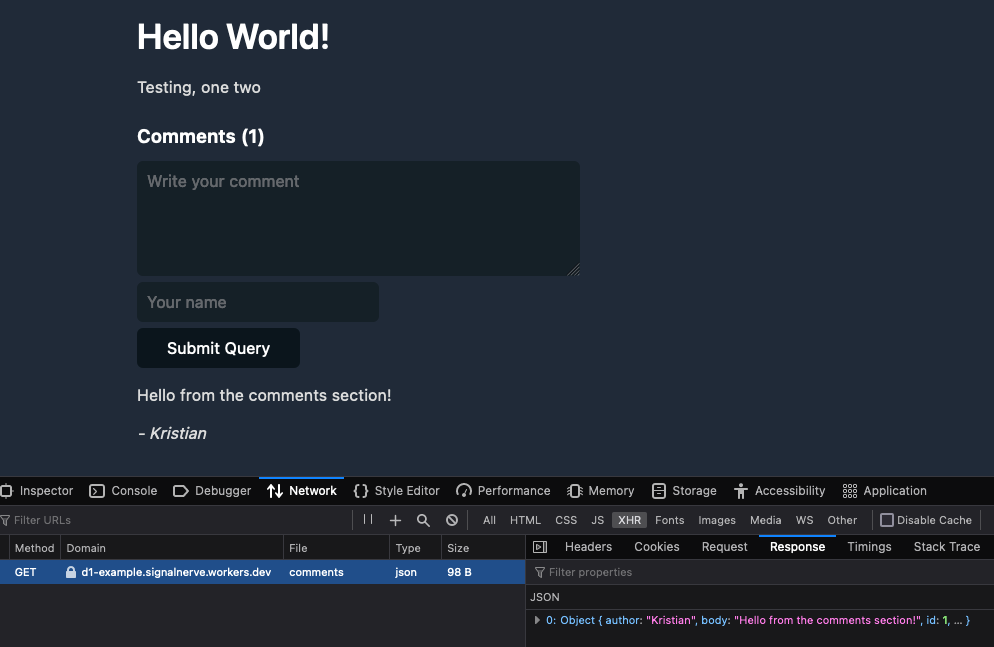
在本篇部落格文章中,我將介紹如何使用 D1 來為靜態部落格網站新增評論。為此,我們將建構一個新的 D1 資料庫,並建置一個簡單的 JSON API 來建立和擷取評論。
正如我所提到的,將 D1 與應用程式本身(與靜態網站保持分離的 API 和資料庫)分開,我們將能夠將網站的靜態和動態部分相互分離。它還使部署我們的應用程式變得更加容易:我們將前端部署到 Cloudflare Pages,並將 D1 驅動的 API 部署到Cloudflare Workers。
構建新應用程式
首先,我們將在 Workers 中新增一個基本的 API。建立新目錄,並在其中建立新的 wrangler 專案:
$ mkdir d1-example && d1-example
$ wrangler init
在此範例中,我們將使用 Hono,一種 Express.js 式框架,以快速構建我們的 API。要在此專案中使用 Hono,請使用 NPM 安裝它:
$ npm install hono
然後,在 src/index.ts 中,我們將初始化一個新的 Hono 應用程式,並定義一些端點 - GET /API/posts/:slug/comments 和 POST /get/api/:slug/comments。
import { Hono } from 'hono'
import { cors } from 'hono/cors'
const app = new Hono()
app.get('/api/posts/:slug/comments', async c => {
// do something
})
app.post('/api/posts/:slug/comments', async c => {
// do something
})
export default app
現在,我們將建立一個 D1 資料庫。在 Wrangler 2 中,支援 wrangler d1 子命令,它允許您直接從命令行建立和查詢 D1 資料庫。因此,例如,我們可以使用單個命令建立一個新資料庫:
$ wrangler d1 create d1-example
使用我們建立的資料庫,我們可以獲取資料庫名稱 ID 並將其與 wrangler 的設定檔 wrangler.toml 內部的繫結相關聯。繫結將允許我們在程式碼中使用簡單的變數名稱存取 Cloudflare 資源,例如 D1 資料庫、KV 命名空間和 R2 儲存桶。下面,我們將建立繫結 DB 並使用它來表示我們的新資料庫:
[[ d1_databases ]]
binding = "DB" # i.e. available in your Worker on env.DB
database_name = "d1-example"
database_id = "4e1c28a9-90e4-41da-8b4b-6cf36e5abb29"
請注意,此指令,即 [[d1_databases]] 欄位當前需要 wrangler 的測試版。您可以使用命令 npm install -D wrangler/beta 為您的專案安裝它。
在我們的 wrangler.toml 中設定資料庫,我們可以從命令行和 Workers 函數中開始與它互動。
首先,您可以使用 wrangler d1 execute 發出直接 SQL 命令:
$ wrangler d1 execute d1-example --command "SELECT name FROM sqlite_schema WHERE type ='table'"
Executing on d1-example:
┌─────────────────┐
│ name │
├─────────────────┤
│ sqlite_sequence │
└─────────────────┘
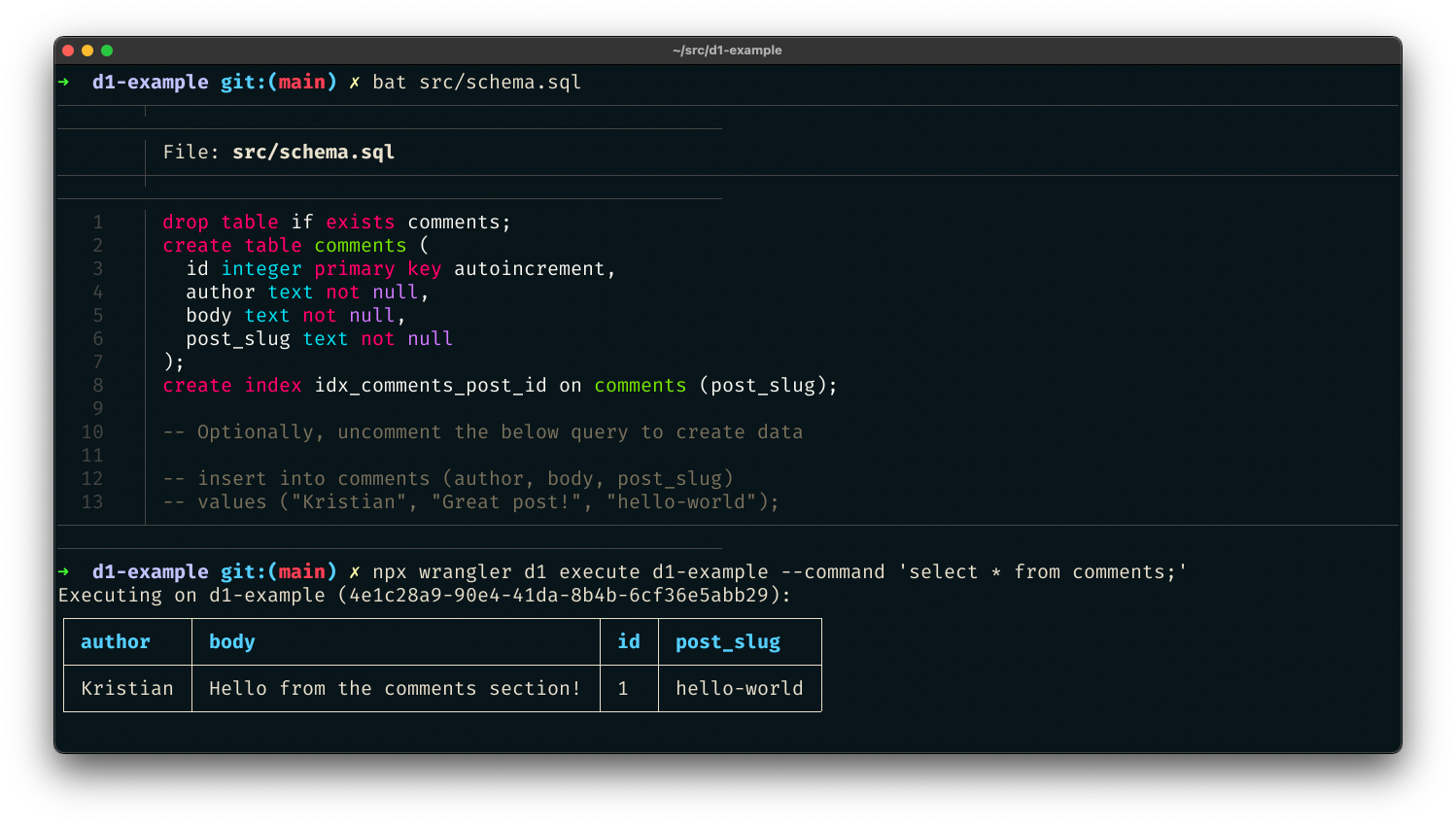
您還可以傳遞 SQL 檔案 - 非常適合在單個命令中進行初始資料種子設定。建立 src/schema.sql,這將為我們的專案建立一個新的 comments 表:
drop table if exists comments;
create table comments (
id integer primary key autoincrement,
author text not null,
body text not null,
post_slug text not null
);
create index idx_comments_post_id on comments (post_slug);
-- Optionally, uncomment the below query to create data
-- insert into comments (author, body, post_slug)
-- values ("Kristian", "Great post!", "hello-world");
建立檔案後,透過傳遞帶有標誌的模式檔案,針對 D1 資料庫執行模式檔案 --file:
$ wrangler d1 execute d1-example --file src/schema.sql
我們只用幾個命令即建立了一個 SQL 資料庫,並使用初始資料為其設定了種子。現在,我們可以向 Workers 函新增一個路由,以從該資料庫中擷取資料。基於我們的 wrangler.toml 設定,現在可以透 DB 繫結來存取 D1 資料庫。在我們的程式碼中,我們可以使用繫結來準備 SQL 語句並執行它們,例如,擷取註釋:
app.get('/api/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { results } = await c.env.DB.prepare(`
select * from comments where post_slug = ?
`).bind(slug).all()
return c.json(results)
})
在此函數中,我們接受了一個 slug URL 查詢參數並設定了一個新的 SQL 語句,在該語句中,我們選擇具有與查詢參數相符的 post_slug 值的所有註釋。然後,我們可以將其作為簡單的 JSON 回應返回。
到目前為止,我們已經建立了對資料的唯讀存取。但是,當然,向 SQL 「插入」值也是可能的。因此,讓我們定義另一個函數,以允許 POST 到端點以建立新註釋:
app.post('/API/posts/:slug/comments', async c => {
const { slug } = c.req.param()
const { author, body } = await c.req.json<Comment>()
if (!author) return c.text("Missing author value for new comment")
if (!body) return c.text("Missing body value for new comment")
const { success } = await c.env.DB.prepare(`
insert into comments (author, body, post_slug) values (?, ?, ?)
`).bind(author, body, slug).run()
if (success) {
c.status(201)
return c.text("Created")
} else {
c.status(500)
return c.text("Something went wrong")
}
})
在此範例中,我們建立了一個註釋 API 來為部落格提供支援。要查看此 D1 驅動的註釋 API 的原始程式碼,可以存取 cloudflare/templates/worker-d1-api。
結論
D1 最令人興奮的一點是有機會使用動態關係資料來增強現有應用程式或網站。作為一名前 Ruby on Rails 開發人員,在 JavaScript 和無伺服器開發工具領域,我最懷念的莫過於能夠快速啟動完整的資料驅動應用程式,而無需成為管理資料庫基礎結構的專家。藉由 D1 及其可輕鬆存取基於 SQL 的資料的功能,我們可以構建真正的資料驅動型應用程式,而不會影響效能或開發人員體驗。
這種轉變與過去幾年使用 Hugo 或 Gatsby 等工具的靜態站點的出現非常吻合。使用諸如 Hugo 的靜態站點產生成器構建的部落格具有令人難以置信的效能,可以在幾秒鐘內以較小的資產大小進行構建。
但是,透過將 WordPress 之類的工具換成靜態站點產生,您將失去向站點新增動態資訊的機會。許多開發人員透過增加構建過程的複雜性、獲取和擷取資料,及使用該資料來產生頁面作為構建過程的一部分來解決此問題。
增加構建過程的複雜性以嘗試解決應用程式中缺乏動態的問題,但它仍然不是真正的動態。應用程式無法在建立新資料時擷取和顯示新資料,而是在資料變更時重新產生和重新部署,使其看起來像是資料的即時動態表示形式。您的應用程式可以保持靜態,且動態資料將在地理位置上靠近您站點的使用者,可透過可查詢和可表達的 API 進行存取。