


Workers AI 是我们的无服务器 GPU 驱动的推理平台,在 Cloudflare 的全球网络之上运行。它提供了越来越多的现成模型目录,这些模型可以使用 Workers 无缝运行,并使开发人员能够在几分钟内构建强大且可扩展的 AI 应用程序。我们已经看到开发人员使用 Workers AI 构建出了惊人的作品,随着我们继续扩展平台,我们迫不及待地想看到他们的最新成果。为此,今天我们很高兴地宣布推出一些饱受期待的新功能:Workers AI 上所有大型语言模型 (LLM) 的流式响应、更长的背景信息和序列窗口以及全精度 Llama-2 模型变体 。
如果您以前使用过 ChatGPT,那么您就会熟悉响应流的好处,其中响应按令牌逐个流动。LLM 的内部工作方式是使用重复推理过程按顺序生成响应,LLM 模型的完整输出本质上是数百或数千个单独预测任务的序列。因此,生成一个令牌只需要几毫秒,而生成完整的响应则需要更长的时间,大约需要几秒钟。好消息是,我们可以在生成第一个令牌后立即开始显示响应,并追加每一个额外的令牌,直到响应完成。这将为最终用户带来更好的体验——随着文本的生成逐步显示文本,不仅能提供即时响应,还能让最终用户有时间阅读和解释文本。
截至今天,您可以对我们目录中的任何 LLM 模型使用响应流,包括非常流行的 Llama-2 模型。下面是它的工作原理。
Server-sent events:浏览器 API 中的宝藏
Server-sent events 易于使用、易于在服务器端实施、合乎标准,并且可在许多平台上原生或作为填充程序广泛使用。Server-sent events 填补了处理来自服务器的更新流的空白,处理事件流原本所需的样板代码如今已不再需要。
| 易于使用 | 流传输 | 双向 | |
|---|---|---|---|
| fetch | ✅ | ||
| Server-sent events | ✅ | ✅ | |
| Websockets | ✅ | ✅ |
要开始在WorkersAI的文本生成模型上通过 server-sentevents 使用流式传输,请在请求输入中将“stream”参数设置为true。这会将响应格式和 mime-type 更改为 text/event-stream。
下面是通过 REST API 使用流式传输的示例:
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]下面是使用 Worker 脚本的示例:
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}如果您想在浏览器页面中使用此 Worker 的输出事件流,则客户端 JavaScript 类似于:
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}您可以将此简单的代码与任何简单的 HTML 页面、使用 React 或其他 Web 框架的复杂 SPA 结合使用。
这为用户创造了更具交互性的体验,现在,随着响应的增量创建,用户会看到页面更新,而不是看到一个旋转画面,等待整个响应序列生成。尝试在 ai.cloudflare.com 上进行流式传输。
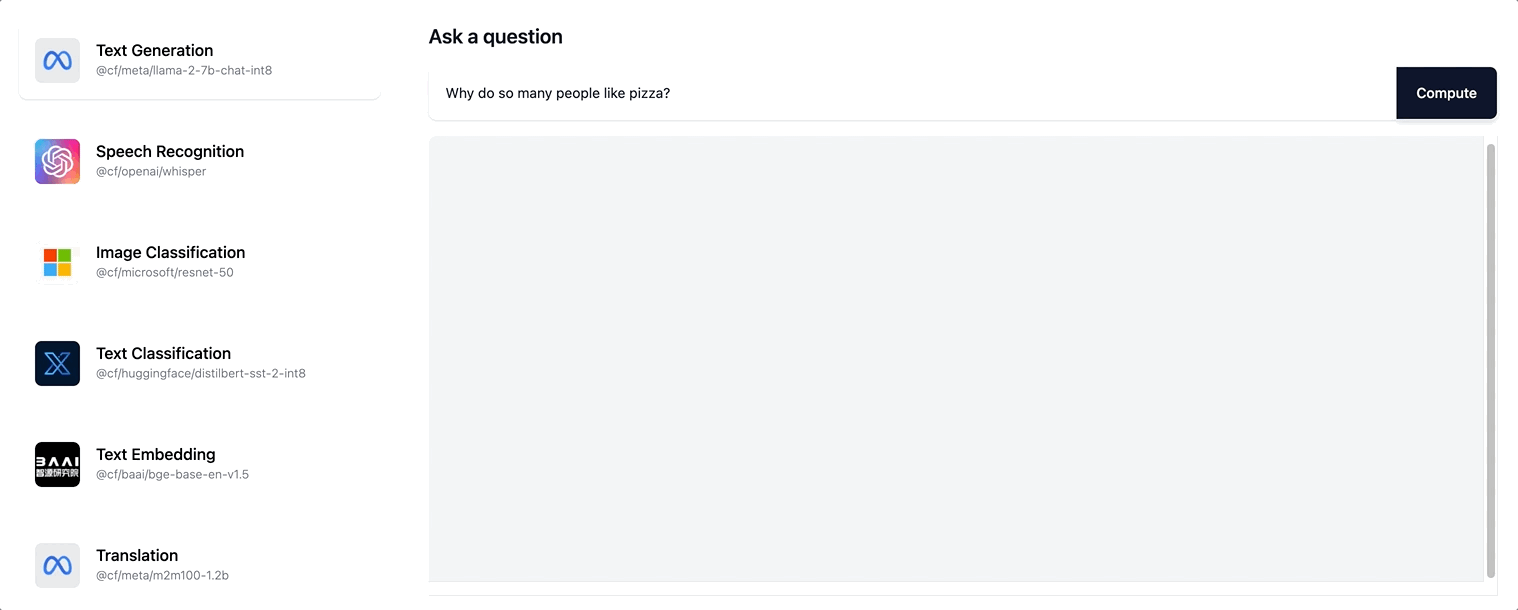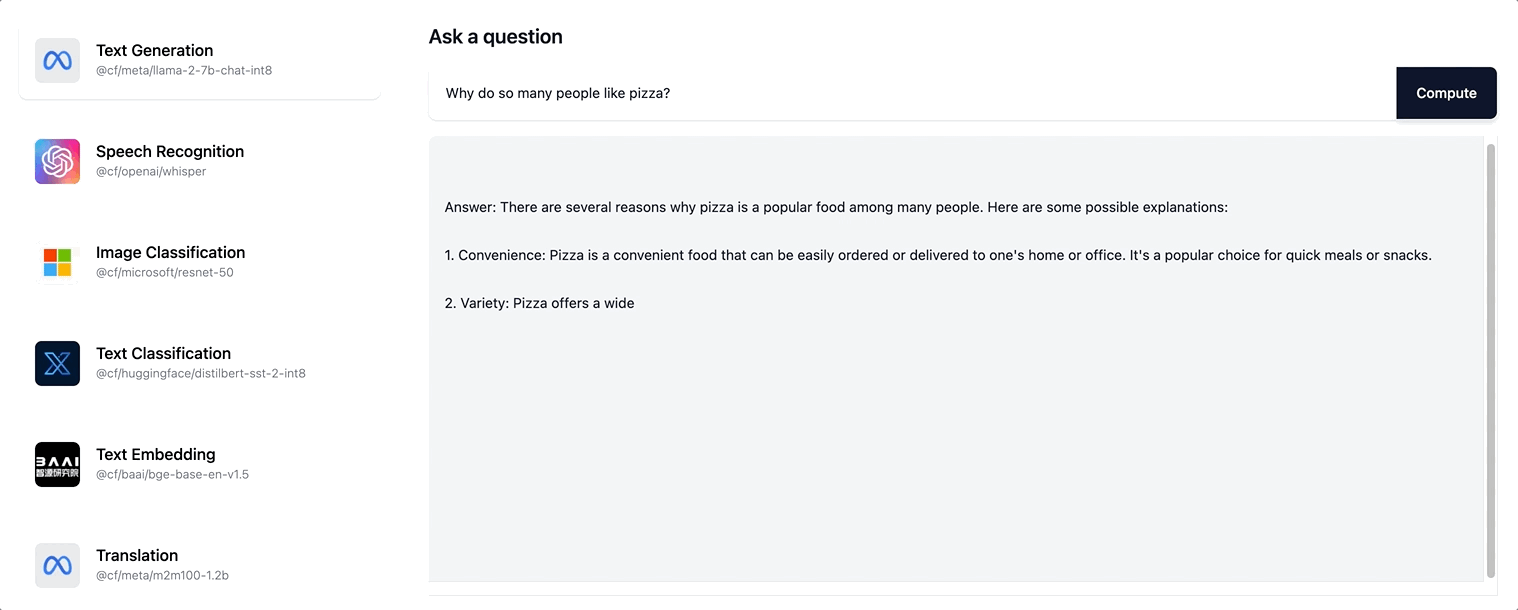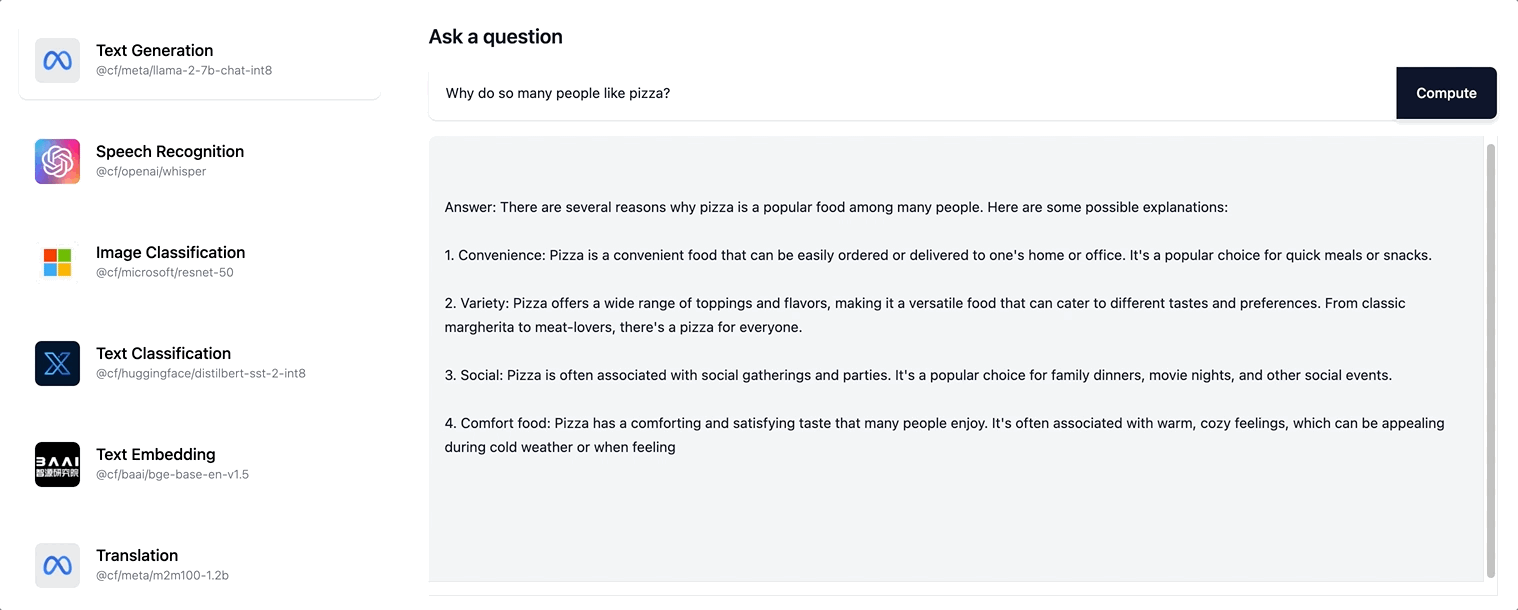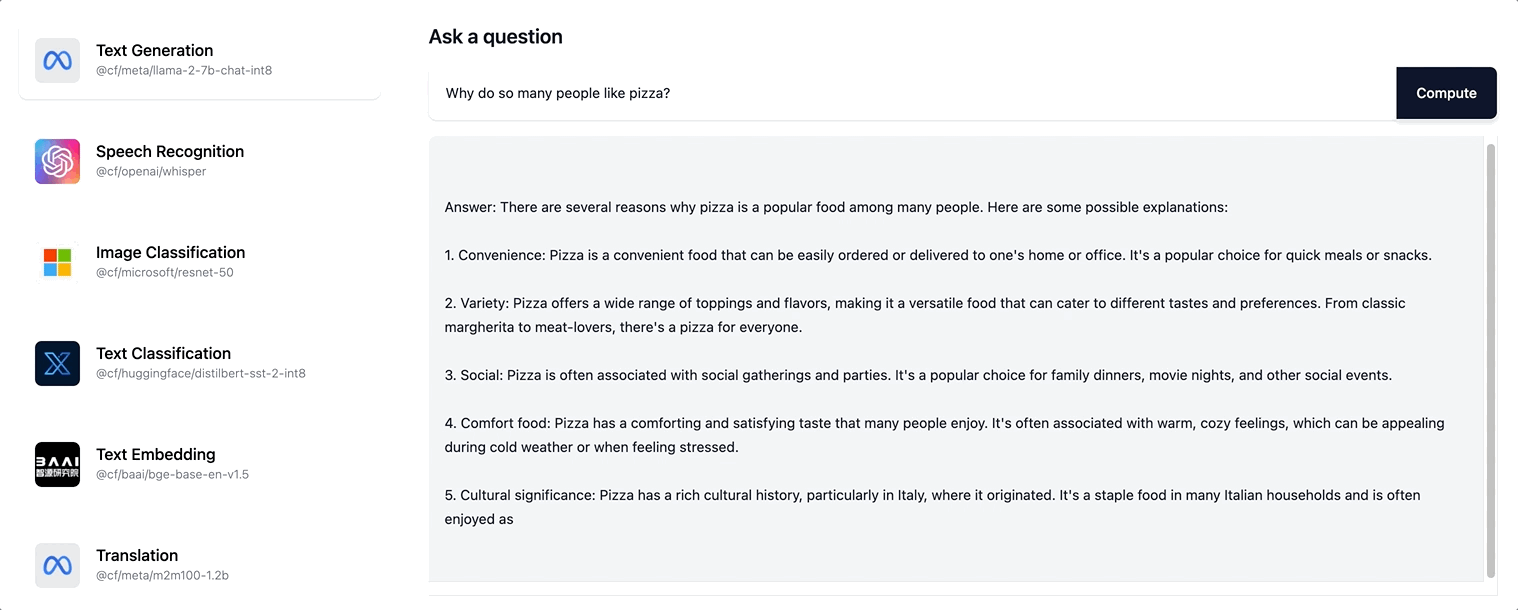
Workers AI 支持 Llama-2 模型以及我们未来添加到目录中的任何 LLM 模型的流式文本响应。
但这还不是全部。
更高的精度以及更长的背景信息和序列长度
Workers AI 推出后,我们从社区听到的另一个最重要的请求是在我们的 Llama-2 模型中提供更长的问题和答案。在 LLM 术语中,这意味着更高的背景信息长度(模型在进行预测之前作为输入的令牌数量)和更高的序列长度(模型在响应中生成的令牌数量)。
我们听取了建议,并结合流式传输,今天我们在目录中添加了更高的 16 位全精度 Llama-2 变体,并增加了现有 8 位版本的背景信息和序列长度。
| 模型 | 背景信息长度(输入) | 序列长度(输出) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048(之前为 768) | 1800(之前为 256) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
流式传输、更高的精度以及更长的背景信息和序列长度可提供更好的用户体验,并使用 Workers AI 中的大型语言模型启用新的、更丰富的应用程序。
查看 Workers AI 开发人员文档以获取更多信息和选项。如果您对 Workers AI 有任何疑问或反馈,请在 Cloudflare 社区和 Cloudflare Discord 中与我们联系。
如果您对机器学习和无服务器 AI 感兴趣,Cloudflare Workers AI 团队正在构建一个全球规模的平台和工具,让我们的客户能够在我们的网络之上运行快速、低延迟的推理任务。请查看我们的职位页面,了解工作机会。