
几年前,我们发布了 Argo 来帮助提高互联网的速度和效率。Argo 会观察网络状况,寻找互联网上最适合源服务器请求的最佳路由,以免传输过程中遭遇拥塞。
分级缓存是 Argo 的一项功能,可减少负责从源服务器请求资源的数据中心数量。启用分级缓存后,南非的请求不会直接发送到北美的源服务器,而是首先在附近的大型数据中心中查看那里是否缓存了请求的数据。分级缓存使用的数据中心数量和位置由一种称为拓扑的配置进行控制。默认情况下,我们为每个客户使用通用拓扑,它可在高速缓存命中率和延迟之间取得平衡,这种方式适合大多数用户。
今天,我们将推出“智能拓扑”。它依托 Argo 内部基础结构而构建,可以确定向源服务器提出请求的一个最佳数据中心,从而最大限度提高缓存命中率。
标准高速缓存
缓存资源的标准方法是让每个数据中心成为源服务器的反向代理。在这种方案中,任何数据中心发生未命中都会导致向源服务器请求资源。向源服务器请求资源的次数可能会与数据中心的数目一样多。
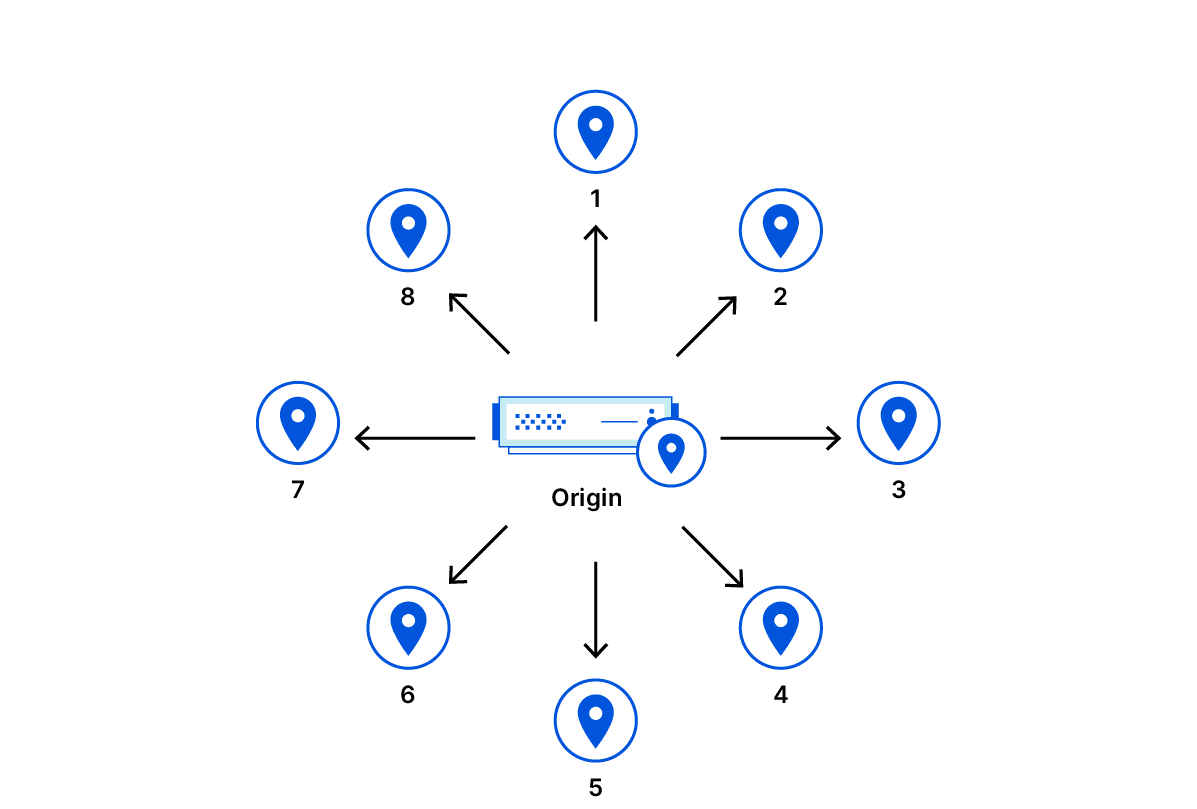
任何数据中心发生缓存未命中的情况都会导致请求被发送到源服务器,即使资源已在另外某个数据中心缓存也一样。其原因在于,数据中心完全不顾彼此的存在。
在理论上,对资源的请求必须发送到每个数据中心,缓存未命中率才能降低到最低程度。然而,将每个请求发送到每个数据中心是不切实际的。
如果资源在被请求之前就已移到距离最近的缓存中,那就可达到可能最低的缓存命中延迟,但这种预测通常并无可能。相反,一种不错的启发式方法是资源在首次缓存未命中后从距离最近的数据中心缓存中获取。
但是,必须要从某个位置复制资源,并且只有查询了每一个数据中心才能知道它在网络中的哪个位置上。
若要避免查询每一个数据中心,必须在首次缓存未命中后将资源的副本存储到一个已知位置,以便其他数据中心可以使用它。这正是分级高速缓存的作用。
分级高速缓存
分级高速缓存允许某些数据中心充当其他数据中心的缓存,使后者不再需要向源服务器提交请求,以此提高缓存命中率。使用分级缓存时,某些数据中心将成为其他数据中心的源服务器反向代理。
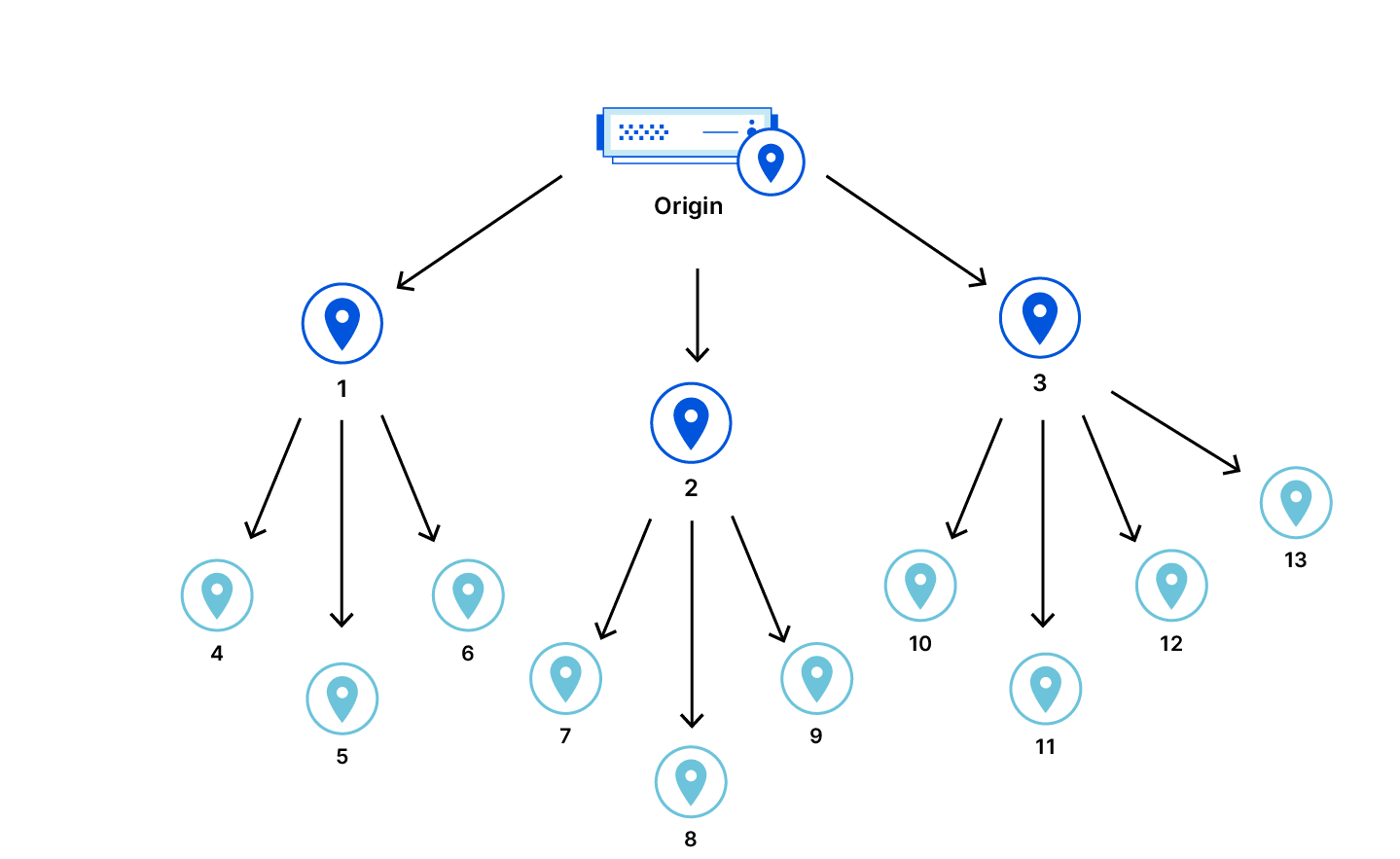
如果被代理的数据中心请求相同的资源,那么资源已经缓存在了代理数据中心中,并可从那里检索,不必再从源服务器检索了。在总体上,对源服务器的请求会变少。
自定义拓扑
在分级缓存中,拓扑描述了哪一个数据中心应充当其他数据中心的代理。
对于客户来说,设计最佳拓扑是一个挑战,需要优化和持续维护。最佳拓扑的配置基于客户私有的信息,以及仅 Cloudflare 持有的其他信息。
例如,了解延迟与缓存命中率之间的理想平衡是仅客户持有的信息,而如何以最佳方式利用互联网则是我们掌握的信息。企业客户通常设有专门的基础结构团队,他们与我们的解决方案工程师合作来手动优化和维护其分级缓存拓扑。
并非每一客户都希望个性化他们的拓扑。因此,也会有通用拓扑。
通用拓扑
通用拓扑旨在让任何源服务器(无论位置如何)达到良好的延迟和缓存效率。在缓存效率和延迟这两个约束之间取得平衡。
通用拓扑具有分布于世界各地的多个代理数据中心,确保导致缓存未命中的请求在到达源服务器之前不会走很长的弯路。代理数据中心数量和缓存命中率之间存在一种平衡,因为代理数据中心彼此无关。
如果某个首选代理数据中心离线,则会使用备用数据中心作为代理数据中心(如果备用数据中心处于在线状态),或者还原为如同禁用了分级缓存时的方式。
为了在一般使用情况下达到最佳平衡,通用拓扑结构会指示较小的数据中心由同一地理区域中的较大数据中心进行代理。
智能拓扑
智能代理假定源服务器在某个位置上,一旦客户拨动仪表板上的开关,它会自动将分级缓存配置为最佳状态。为了真正做到这一点,Cloudflare 需要能够判断哪个数据中心距离源服务器的延迟最短,无需让客户告诉 Cloudflare 其源服务器在哪里。
延迟确定方法
有几种方法可以确定哪个数据中心相对于源服务器具有最低的延迟。
IP Geolocation
物理距离可以用作延迟的近似值,但智能拓扑并不是以这种方式构建的,原因有二。其一,即使是最好的商用 IP 地理数据库也没有符合要求的覆盖范围和准确度。其二,即使准确度极高,物理距离依然是互联网延迟的一个值得怀疑的近似值。
探测
可以通过探测 IP 地址来准确地确定该地址的延迟。探针可以是执行 TCP 握手所需的时间。每个数据中心探测源服务器,以便直接测量延迟并找到最小值。除了涉及 Anycast 和 TCP 终止的极端例子外,我们可以假定某一 IP 地址的延迟与该 IP 地址背后源服务器的延迟相同。
拓扑选择算法
拓扑选择算法的目标是最大限度减少缓存未命中和延迟。拓扑选择一个代理数据中心,以最大限度提高缓存命中率。选择的代理数据中心应当靠近源服务器,从而使代理数据中心的缓存未命中延迟不差于关闭分级缓存时的情况。
这一选择最终应该要稳定下来。稳定性很重要,因为每次选择改变时,代理数据中心的缓存未命中有可能会导致新代理数据中心出现缓存未命中。容量也很重要,因为当数据中心脱机时,它可能会导致大量缓存未命中。为确保有效使用网络,尽可能降低源服务器的延迟非常重要。
数据中心选择算法非常像是各个源服务器的最快数据中心排行榜。随着数据的收集,更快的数据中心可能会淘汰掉给定源服务器的排行榜上的其他数据中心。这场竞赛基于 24 小时延迟时间中值,每小时比一次。仅一部分被认为足够大的数据中心才允许参加比赛。
最终,代理数据中心选择会稳定下来。随着时间推移,数据中心会针对各个源服务器生成竞赛记录,并在需要时替换掉排行榜上竞争力较弱的记录。因此,排行榜上任何源服务器的延迟都只会单调降低。现实世界中总会存在物理限制,因此理想的数据中心最终将创造出难以超越的记录。
同样,排行榜实际上同时含有延迟最低的数据中心和延迟第二低的数据中心。如果首选数据中心脱机以进行维护,那么延迟第二低的数据中心将充当备用。
Anycast 网络
我们测量的是源站 IP 地址的延迟,也假设它代表源服务器的延迟,但在某些情况下这种假设可能会不成立。除了 Cloudflare 外,另外几家云提供商也使用 Anycast 技术来提供其服务。在 Anycast 中,多台机器可能会共享一个 IP 地址,不管是从哪里连入互联网;而且,互联网通常会将发往该地址的数据包路由到距离最近的机器。如果使用 Anycast 网络代理源服务器,则源服务器 IP 地址的表观延迟实际上是 Anycast 网络边缘的延迟,而不是源服务器的延迟。源服务器的实际延迟无法通过探测来确定。
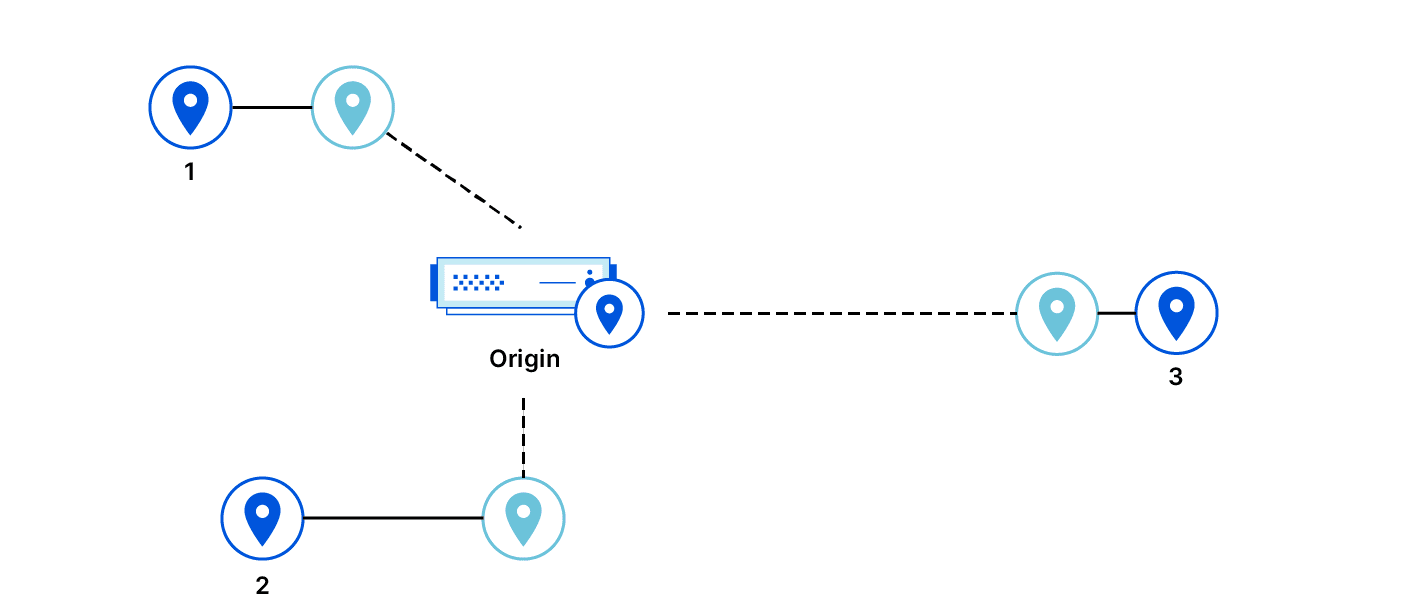
如果这些延迟不能代表数据中心与源服务器之间的实际延迟,那么算法就无法选出一个最佳代理数据中心。选择错误的数据中心会给对源服务器的请求的延迟造成不利影响,而且代价可能会很高。
例如,某个云提供商提供一个 IP 地址,该地址实际上路由到全球多个数据中心。一旦数据包进入网络,便会通过私有基础结构路由到正确的目的地。到此 Anycast IP 地址延迟最低的数据中心甚至可能位于和实际源服务器不同的大陆上。因此,表观延迟实际上不能被视为衡量源服务器延迟的可信尺度。
数据中心选择算法假设源服务器位于单个地理位置,并且可以对其进行探测来确定各个数据中心的延迟。此类网络破坏了这些假设中的一个或两个,因此必须开发一种手段来检测它们。首先,假定 IP 出现在单个地理位置上,并且没有被此类网络代理。源服务器的延迟受到光线穿过光纤的速度的限制。尽管任何数据中心与源服务器的距离是未知的,但 Cloudflare 知道数据中心之间的距离。
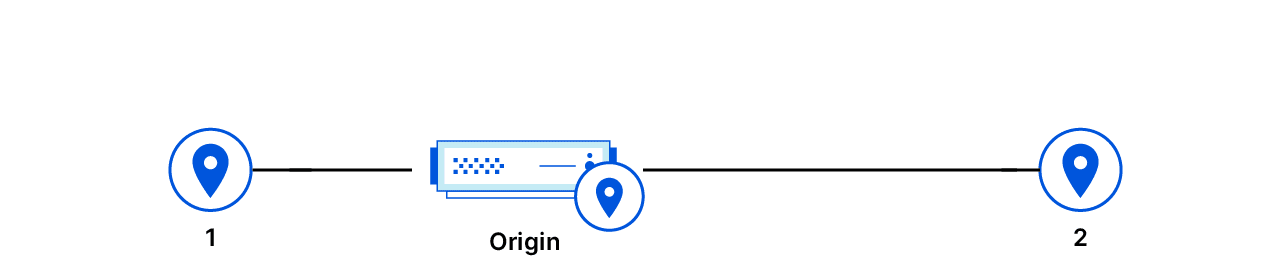
想象一下,将源服务器比作旅途上的一个休息站。那么,可以计算源服务器与任何两个数据中心的一对理论上可能的最低可观察延迟。我们拥有来自这两个数据中心和源服务器的延迟探测数据,因此可以检查观察到的延迟是否低于可能的延迟。
最初的假设是,源站 IP 地址标识位于某一位置的源服务器,并且该 IP 地址的延迟就是源服务器的延迟。如果观察到的延迟比理想值快,那么该假设显然是错误的。当最初假设不成立时,智能拓扑将回退为通用拓扑。为了更确定一些,我们对世界各地的多个数据中心检查此约束,只要存在一个物理上不可行的观察结果,就会发生回退。
纵观全局
启用智能拓扑后,许多 Cloudflare 系统将协同工作,确保最终使用正确的数据中心来向源服务器请求资源。
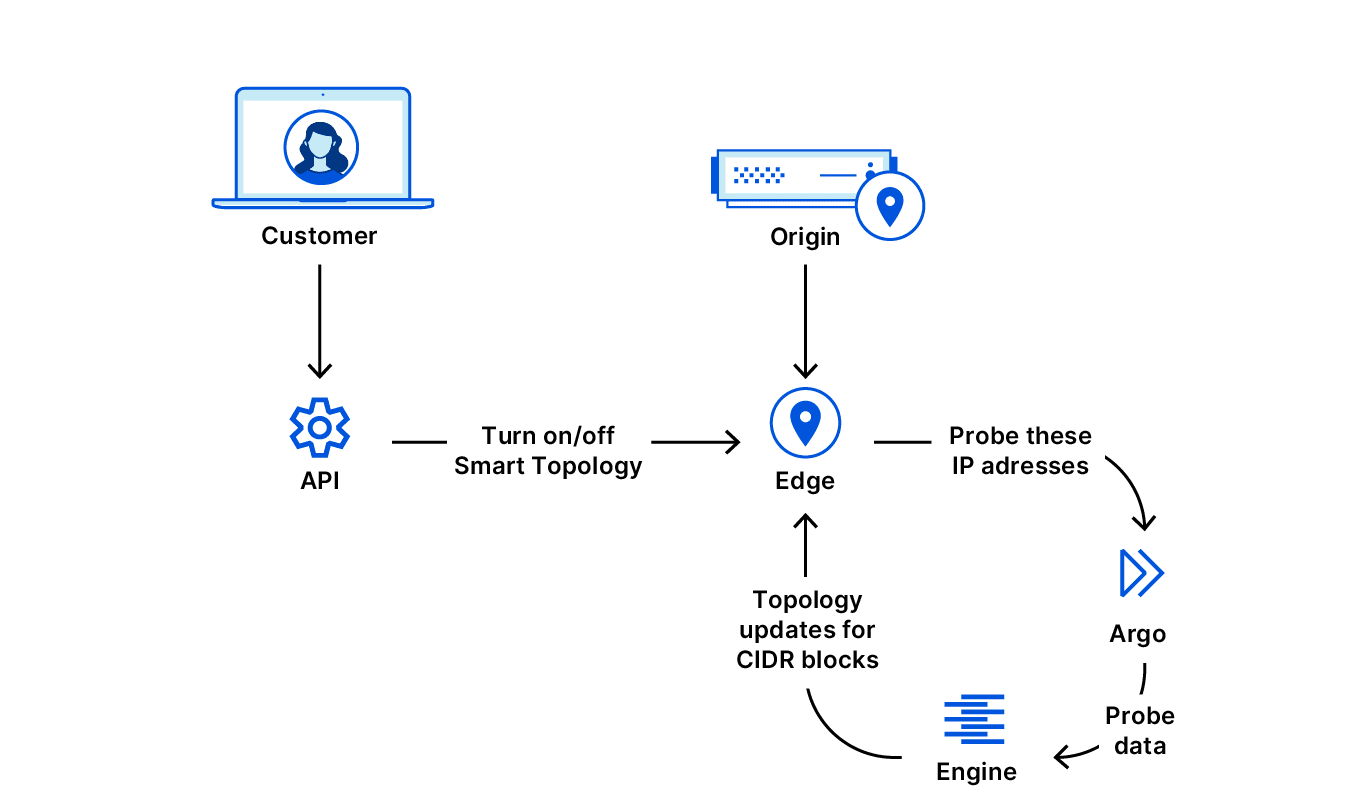
客户启用分级缓存智能拓扑后,从源站的角度看,可能会出现几种情况。如果代理数据中心被分配了包含源站 IP 的 CIDR 块,则首选或备用数据中心将用于从源服务器请求资源。否则,通用拓扑将被用于确定要使用哪些代理数据中心从源服务器提取资源。代理数据中心的选择时间会随着其到源站的延迟不断更新而减少。
总结
这项技术的开发为实现领先的技术并打造有影响力的产品创造了许多机会。这并不是孤立完成的。我们使用了 Cloudflare 已经建设的基础设施,而且我们在运用现有发展的基础上继续提高,以取得更大的进步。构建这一框架也为日后的进步打开大门;例如,未来可以探索不同的方法来选择理想的代理数据中心,即使是源服务器位于 Anycast 网络后方并隐藏了源服务器的真实延迟。