


崩溃:截断的无效 TCP 数据包
几个月前,我们开始收到一些 flowtrackd 崩溃报告,flowtrackd 是我们的高级 TCP 保护系统,在我们的全球网络上运行。提供的栈跟踪表明,崩溃发生时,正在解析一个截断的 TCP 数据包。
最有趣的地方不是我们未能解析这个数据包。我们从互联网上收到(有意或无意)截断的畸形数据包这种情况并不罕见。这些数据包会在我们第一次解析时就被抓取出来,不会进入后续处理阶段。然而,在这个案例中,崩溃发生在我们第二次解析数据包时,表明它是在我们收到并成功完成第一次解析之后被截断的。这两次解析均从单个绿色线程调用,且引用内存中同一个数据包缓冲区,在两次解析之间我们没有尝试改变数据包。
发现此类错误可能很容易令人感到恐惧。是存在竞态条件吗?是存在内存损坏吗?这是内核错误吗?是编译器错误吗?我们计划找出这一潜在复杂问题的根本原因,确定与该错误有关的表现,创建理论来解释可能发生的情况,寻找方法来测试我们的理论或收集更多信息。
在详细讨论之前,我们首先需要一些有关 AF_XDP 和我们的设置的背景信息。
AF_XDP 概述
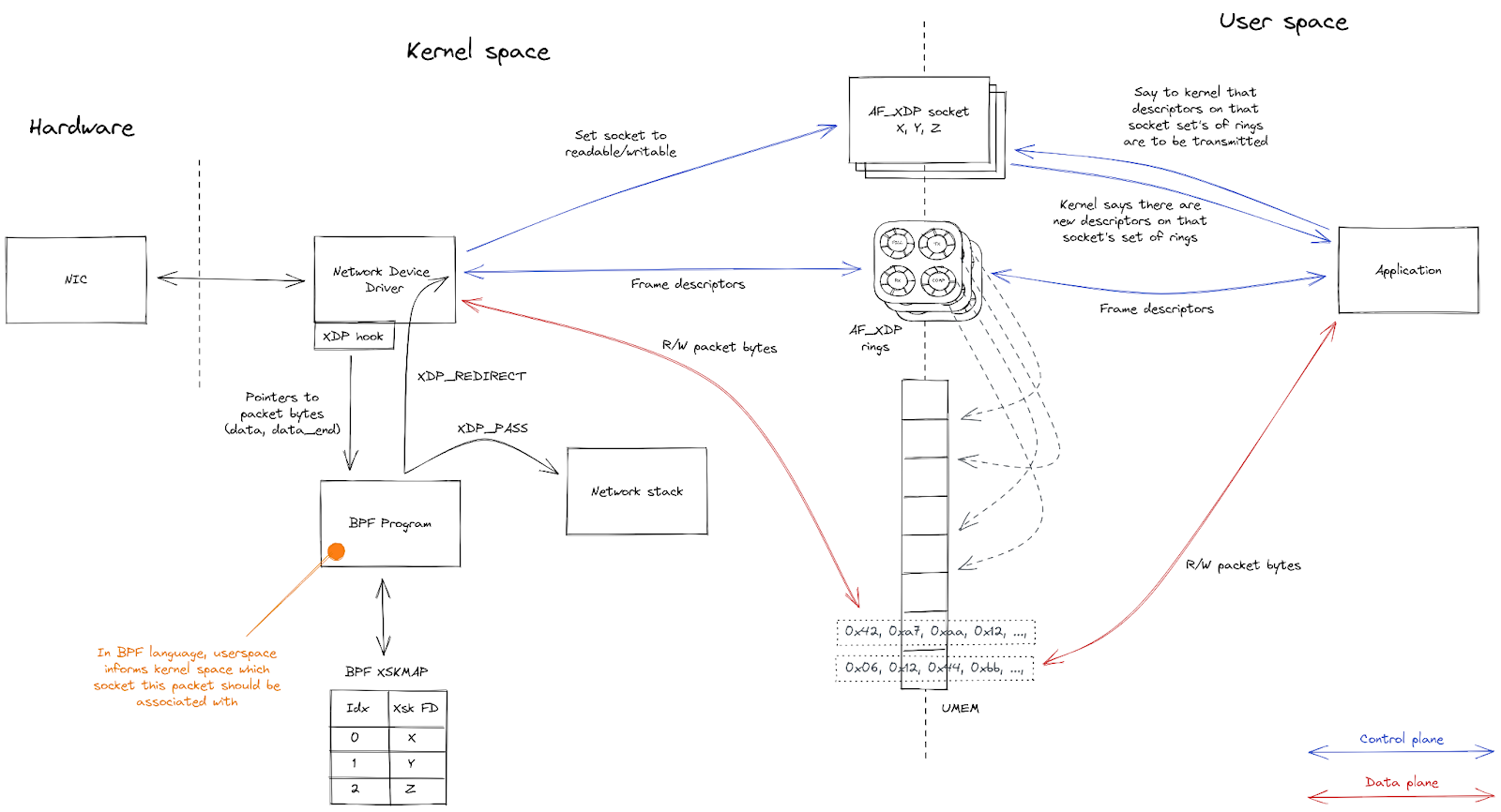
AF_XDP 是 Linux 内核中高性能、异步的用户空间网络 API。对于支持它的网络设备,AF_XDP 提供了使用内核和用户空间应用程序的共享内存缓冲区来执行极速零拷贝的数据包转发的方法。
用户空间应用程序需要设置一些组件,才能开始与使用 AF_XDP 进入网络设备的数据包交互。
首先,创建一个共享数据包缓冲区 (UMEM)。这个 UMEM 被分成大小相等的“帧”,这些“帧”被一个“描述符地址”所引用,描述符地址只是从 UMEM 开始的偏移量。
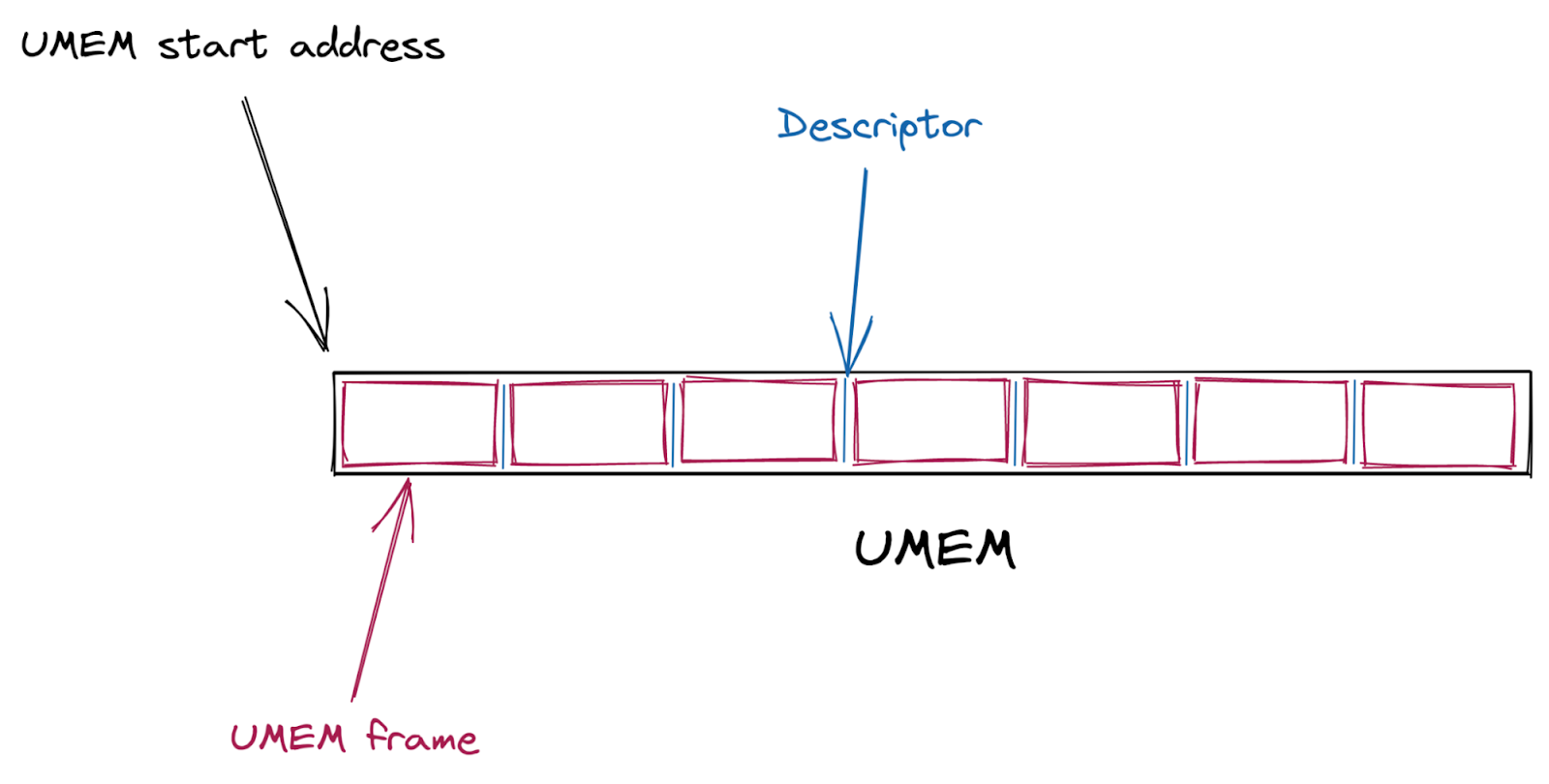
然后,创建多个 AF_XDP 套接字(XSK,网络设备上的每个硬件队列各一个),并与 UMEM 绑定。每个套接字提供四个环形缓冲区(即“队列”),用于在内核和用户空间之间来回发送描述符。
用户空间发送数据包的方法:用一个未使用的描述符,并将数据包复制到该描述符中(或者说,复制到描述符所指向的 UMEM 帧中)。它通过让描述符在 TX 队列上排队,将描述符提供给内核。一段时间后,内核将描述符从 TX 队列中出列,并将其指向的数据包从网络设备中传输出去。最后,内核通过让描述符在 COMPLETION 队列上排队,将描述符返回给用户空间,用户空间此后又可以重新使用它来发送另一个数据包。
为接收数据包,用户空间通过让未使用的描述符在 FILL 队列排队,将其提供给内核。内核将收到的数据包复制到这些未使用的描述符中,然后通过让它们在 RX 队列上排队,将它们交给用户空间。用户空间将从 RX 队列中出列的数据包处理完毕后,或通过让它们在 TX 队列上排队,将它们传送回网络设备,或通过让它们在 FILL 队列上排队,将它们返回给内核,供以后重复使用。
| 队列 | 用户空间 | 内核空间 | 内容描述 |
|---|---|---|---|
| COMPLETION | 消费 | 生产 | 包含内核成功传输的数据包的描述符 |
| FILL | 生产 | 消费 | 内核用来接收数据包的空描述符 |
| RX | 消费 | 生产 | 包含内核最近收到的数据包的描述符 |
| TX | 生产 | 消费 | 包含已准备就绪、待内核传输的数据包的描述符 |
最后,一个 BPF 程序附加到了网络设备上。该程序负责将传入的数据包引导到与接收数据包的特定硬件队列相关联的任何一个 XSK。
内核与用户空间的交互概述如下:
我们的设置
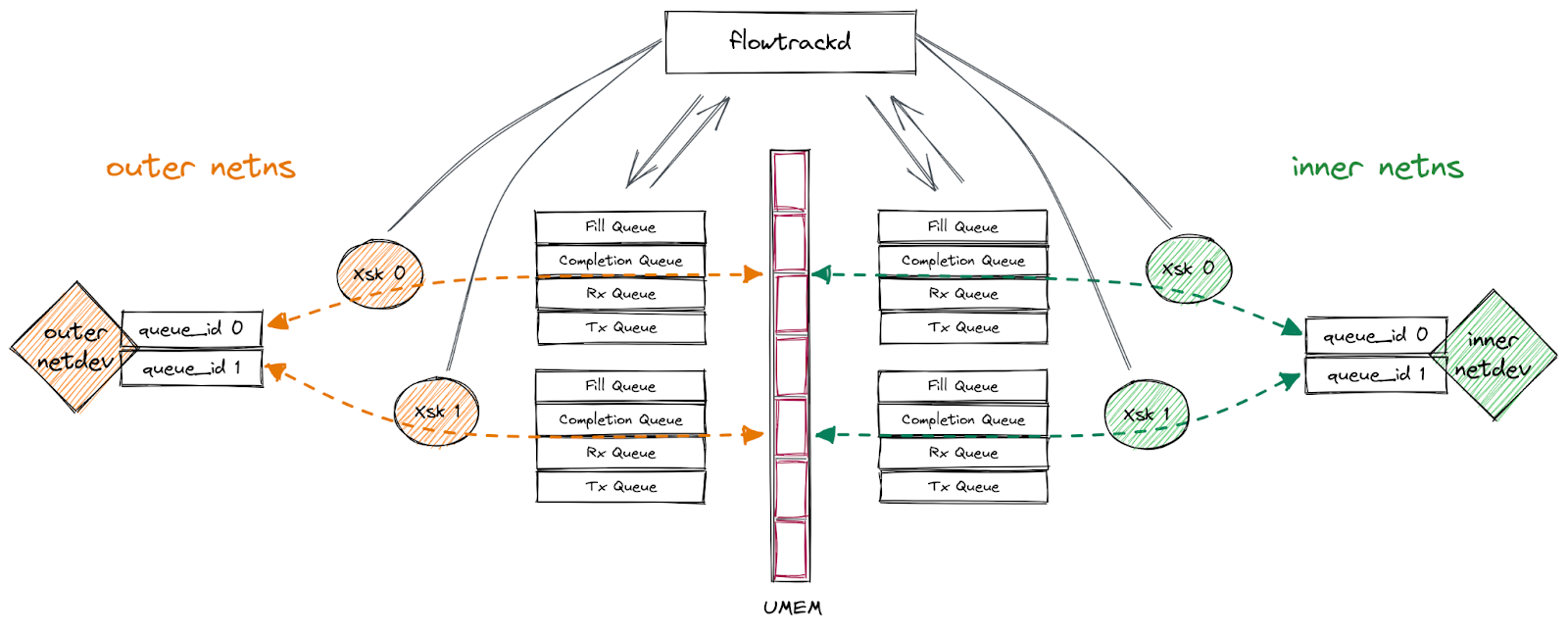
我们的应用程序在一对多队列 veth 接口(“外部”接口和“内部”接口,分别位于不同的网络命名空间)上使用 AF_XDP。我们按照上述过程为每个接口的队列绑定一个 XSK,将数据包从一个接口转发到另一个接口,将数据包从其接收接口发送回去或丢弃。凭借这一功能,我们实现了双向流量检查,可以执行 DDoS 缓解逻辑。
下图描述了这一设置:
信息收集
我们一开始只知道,我们的程序偶尔会有一些看似不可能发生的损坏。我们不知道这些受损数据包到底是什么样的。但数据包的内容可能可以揭示更多的错误细节,以及如何重现该错误,所以我们的第一步是记录数据包字节,并丢弃数据包,没有任何恐慌。然后我们可以提取包含数据包字节的日志,创建一个 PCAP 文件,使用 Wireshark 进行分析。结果显示,这些数据包看起来基本正常,只有 Wireshark 的 TCP 分析器抱怨:“IPv4 总长度超过数据包长度”。换而言之,“总长度”IPv4 标头字段说,数据包长度应该为(例如)60 字节,但数据包实际长度只有 56 字节。
长度不匹配
有没有可能是我们从 RX 环上读取的字节数不正确?我们来检查一下。
一个 XDP 描述符包含以下 C 结构体:
struct xdp_desc {
__u64 addr;
__u32 len;
__u32 options;
};
其中,len 告诉我们 UMEM 帧中 addr 所指向的数据包的总大小。
我们与数据包内容的第一次交互发生在附加到网络接口的 BPF 代码中。
在这里,我们的入口点函数得到一个指向 xdp_md C 结构体的指针,其定义如下:
struct xdp_md {
__u32 data;
__u32 data_end;
__u32 data_meta;
/* Below access go through struct xdp_rxq_info */
__u32 ingress_ifindex; /* rxq->dev->ifindex */
__u32 rx_queue_index; /* rxq->queue_index */
__u32 egress_ifindex; /* txq->dev->ifindex */
};
这个上下文结构包含两个指针 (as __u32),分别指向数据包的首尾。数据包长度可以通过从 data_end 中减去数据来计算。
如果我们把这个值与我们从描述符中得到的值进行比较,我们肯定会发现它们是一样的,对吧?
我们可以使用 BPF 辅助函数 bpf_xdp_adjust_meta()(因为 veth 驱动程序支持该函数)来声明一个元数据空间,让其占有我们计算的数据包缓冲区长度。我们的使用方式与该内核示例代码的使用方式相同。
在生产中部署新代码后,我们在日志中看到了以下内容:
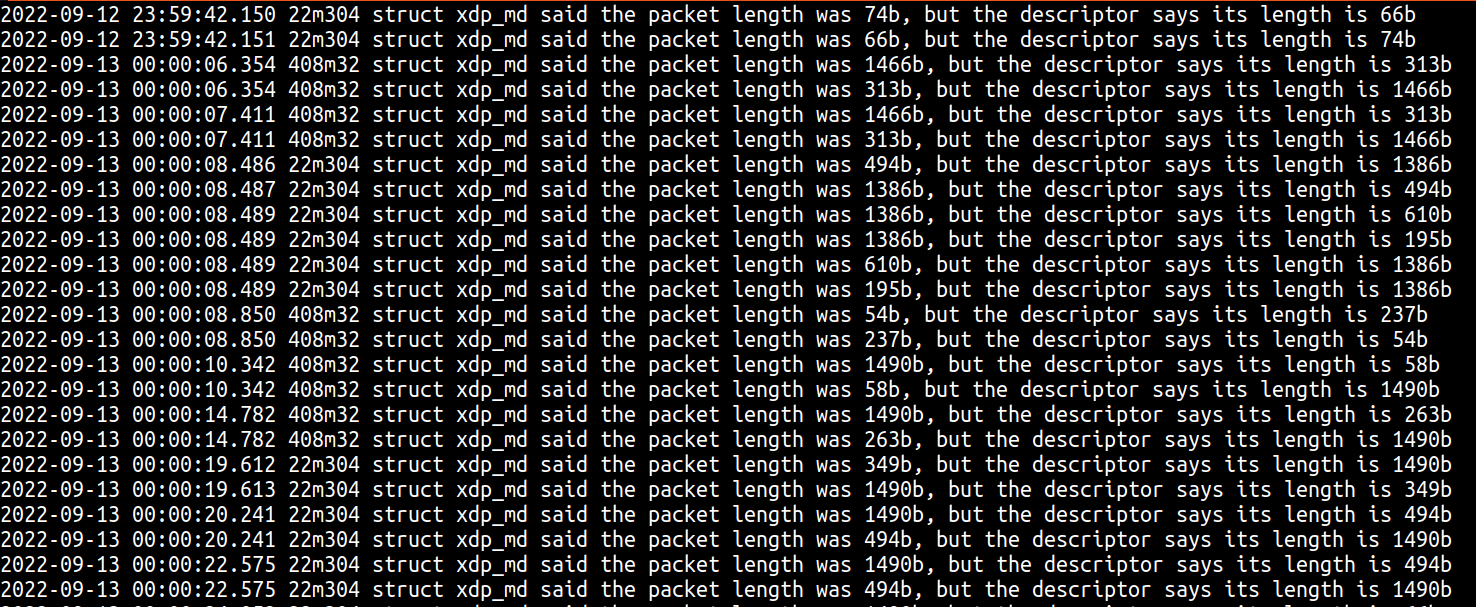
其中可以看到三条有趣的信息:
- 在 XDP 中第一次看到的数据包长度与描述符中的长度不一致,这印证了我们的推理。
- 我们已经从截断数据包错误中观察到,有时描述符的长度比实际数据包的长度要短,但输出结果显示,有时描述符的长度可能比实际数据包的长度要长。
- 这类情况似乎通常是“成对”出现,XDP 的长度和描述符的长度会在数据包之间互换。
两个数据包和一个缓冲区?
看到 XDP 和描述符的长度“成对”互换,这也许是第一个顿悟时刻。这两个不同数据包是否写入了同一个缓冲区?这也说明,我们有一个关键信息(即描述符地址)没有添加到调试输出中!我们借此机会输出了数据包字节等额外信息,并在路径的多个位置输出,以查看有没有随时间发生任何变化。
这些调试输出显示的真正关键信息是,不仅每个互换的“对”共享一个描述符地址,而且几乎单台服务器的每个受损数据包也总是使用同一个描述符地址。这里您可以看到 49750 个受损数据包,它们全都使用 69837056 这一描述符地址:
$ cat flowtrackd.service-2022-11-03.log | grep 87m237 | grep -o -E 'desc_addr: [[:digit:]]+' | sort | uniq -c
49750 desc_addr: 69837056
这是第二个顿悟时刻。我们不只是试图将两个数据包复制到同一个缓冲区,而且总是复制到同一个缓冲区。也许问题在于这个描述符已插入 AF_XDP 环中两次了?我们通过更新我们的消费者代码来测试该理论,测试从 RX 环中读取的一批描述符中是否有同一描述符出现了两次。这并不能保证环中没有两次出现同一描述符,因为不能保证这两个相同描述符会出现在同一个读取批次中,不过我们很幸运,确实在一次读取中发现同一描述符出现了两次,证明问题就是出在这里。事后来看,Linux 内核 AF_XDP 文档中指出了这一问题:
问:我的数据包有时会受损。出了什么问题?
答:必须注意,不能将 UMEM 中的同一缓冲区同时插入多个环中。例如,如果您将同一缓冲区同时插入 FILL 环和 TX 环,NIC 可能会在发送数据的同时将数据接收到缓冲区。这将导致有些数据包受损。将同一缓冲区插入属于不同队列 ID 或与 XDP_SHARED_UMEM 标记绑定的不同 netdev 的 FILL 环时也会发生同样的情况。
我们现在明白了为什么会有受损数据包,但是我们仍不明白,一个描述符怎么会在 AF_XDP 环中出现两次。我很想把这个问题归咎于内核错误,但是,正如文档中指出,这更有可能是因为我们在应用程序中将描述符两次插入环中。此外,这列入了 AF_XDP 的常见问答中,我们必须有足够的证据可证明这是由内核错误而非用户错误造成的,然后再向内核邮件列表报告。
跟踪描述符转换
审查我们的应用程序代码时,没有发现任何明显的位置让我们可能将同一个描述符地址两次插入 FILL 或 TX 环中。然而,我们确实知道描述符通过一组已知状态进行转换,而我们可以使用一个状态机来跟踪这些转换。下图显示了所有可能的有效转换。
例如,描述符从 RX 环到 FILL 环或 TX 环都是完全有效的转换。但描述符从 FILL 环到 COMP 环则是无效转换。
为了测试描述符转换的有效性,我们添加了代码来跟踪它们在各环中的存在。得到以下一些日志消息:
Nov 16 23:49:01 fuzzer4 flowtrackd[45807]: thread 'flowtrackd-ZrBh' panicked at 'descriptor 26476800 transitioned from Fill to Tx'
Nov 17 02:09:01 fuzzer4 flowtrackd[45926]: thread 'flowtrackd-Ay0i' panicked at 'descriptor 18422016 transitioned from Comp to Rx'
Nov 29 10:52:08 fuzzer4 flowtrackd[83849]: thread 'flowtrackd-5UYF' panicked at 'descriptor 3154176 transitioned from Tx to Rx'
第一个输出结果显示,一个描述符被插入 FILL 环,并直接转换到 TX 环上,没有先从 RX 环中读取。这似乎暗示我们的应用程序中有一个错误,也许表明我们的应用程序复制了该描述符,将一个副本放在 FILL 环中,另一个副本放在 TX 环中。
第二个无效转换发生在描述符从 COMP 环移动到 RX 环时,没有先插入 FILL 环。这似乎暗示存在内核错误,也许表明内核复制了一个描述符,分别插入 COMP 环和 RX 环中。
第三个无效转换是从 TX 环到 RX 环时,没有先经过 FILL 或 COMP 环。这似乎是前面 COMP 向 RX 转换的扩展案例,再次暗示可能存在内核错误。
我们对这个结果感到困惑,因此仔细检查了我们的跟踪代码,并试图寻找任何可能的途径:我们的应用程序如何能复制一个描述符,并将它们分别插入 FILL 和 TX 环中。由于没有发现错误,我们认为我们需要收集更多信息。
将 ftrace 作为“飞行记录器”使用
虽然使用状态机来捕捉无效的描述符转换能够捕捉到这些情况,但它仍然缺乏一些重要的细节,而这些细节可能有助于跟踪到导致错误的终极原因。我们仍然不知道这个错误是属于内核问题还是应用程序问题。令人困惑的是,转换状态似乎表明两者都有问题。
为了收集更多信息,我们非常希望能够跟踪一个描述符的历史记录。由于我们使用的是一个共享 UMEM,描述符理论上可以在接口和接收队列之间转换。此外,我们的应用程序使用单个绿色线程来处理每个 XSK,所以按 XSK、CPU 和线程来跟踪描述符转换可能会比较有趣。要实现这一目标,有一个简单但不可扩展的方法,即仅输出每个转换点的这些信息。当然,对于需要每秒处理数百万个数据包的生产环境来说,这并不是一个可行的方案。所产生的数据量和输出这些信息的开销两方面都行不通。
至此,我们一直都在生产系统中仔细排查这一问题。这是个非常罕见的问题,即使在我们的大型生产部署中,有些生产机器可能也需要一天的时间才会开始显示这个问题。如果我们确实想探索更多资源密集型调试技术,我们需要看看能否在测试环境中重现这一问题。为此,我们创建了 10 个虚拟机,使用 iperf 持续测试我们的应用程序。幸运的是,利用该设置,我们能够每天重现一次这个问题,我们有了更多的自由去尝试一些更加资源密集型的调试技术。
即使使用虚拟机,还是无法扩展到输出每次描述符转换的日志,但您真的需要看到每次转换吗?理论上而言,最有趣的事件就是错误发生之前的那个事件。我们可以构建一个这样的工具——内部保存最后 N 个事件的日志,只在错误发生时转储日志。就像飞机上使用黑匣子(飞行记录器)跟踪飞机坠毁前的事件。幸运的是,我们并不需要构建这种工具,因为我们可以使用 Linux 内核的 ftrace 功能,它的一些额外功能可能有助于我们最终跟踪到导致错误的原因。
ftrace 是一项内核功能,通过内部保存一组每个 CPU 环形缓冲区的跟踪事件来运行。存储在环形缓冲区中的每个事件都有时间戳,并包含一些关于事件发生时的上下文、CPU 以及当时正在运行的进程或线程的额外信息。由于这些事件存储在每个 CPU 环形缓冲区,存储满了之后,新的事件将覆盖最旧的事件,因此 CPU 上只留下最近的事件的日志。我们高效地获得了想要的飞行记录器,我们需要做的就只是将我们的事件添加到 ftrace 环形缓冲区,并在错误发生时禁用跟踪。
ftrace 是使用 debugfs 文件系统中的虚拟文件来控制的。可以通过写入 1 或 0 来启用或禁用跟踪:
/sys/kernel/debug/tracing/tracing_on
我们可以更新我们的应用程序,将我们的消息写入 trace_marker 文件,即可将我们的事件插入跟踪环形缓冲区:
/sys/kernel/debug/tracing/trace_marker
最后,在我们重现了这个错误,且我们的应用程序已禁用跟踪功能之后,我们可以通过读取跟踪文件将所有环形缓冲区的内容提取到单个跟踪文件中:
/sys/kernel/debug/tracing/trace
值得注意的是,将消息写入 trace_marker 虚拟文件仍然需要进行系统调用,并将您的消息复制到环形缓冲区。这仍然会增加开销,而在我们的案例中,我们每个数据包都要记录多个输出结果,可能是一笔不小的开销。此外,ftrace 是一项覆盖整个系统的内核跟踪功能,所以您可能需要调整虚拟文件的权限,或者以适当的权限运行应用程序。
当然,使用 ftrace 来协助排查该问题还有一大优势。如前所述,我们可以使用 trace_marker 文件将我们自己的应用程序消息记录到 ftrace 中,但 ftrace 本质上是一项内核跟踪功能。这意味着,我们可以额外使用 ftrace 来记录内核端有关 AF_XDP 数据包处理的事件。有几种方法来实现这一点,但在这个案例中,我们使用的是 kprobes,这样我们就可以瞄准非常具体的代码行,并输出一些变量。kprobes 可以直接在 ftrace 中创建,但我发现在 Linux 中,使用 perf 工具的“perf probe”命令来创建会更加简单。使用“-L”和“-V”参数,您可发现可以探测到一个函数的哪些行,可以在这些探测点查看哪些变量。最后,您可以使用“-a”参数来添加探测器。例如,检查了内核代码之后,我们在 XSK 的接收路径中插入以下探测器:
perf probe -a '__xsk_rcv_zc:7 addr len xs xs->pool->fq xs->dev'
这将探测 __xsk_rcv_zc() 的第 7 行并输出描述符地址、数据包长度、XSK 地址、填充队列地址和网络设备地址。为了说明情况,从 perf probe 命令看到的 __xsk_rcv_zc()如下:
$ perf probe -L __xsk_rcv_zc
0 static int __xsk_rcv_zc(struct xdp_sock *xs, struct xdp_buff *xdp, u32 len)
{
struct xdp_buff_xsk *xskb = container_of(xdp, struct xdp_buff_xsk, xdp);
u64 addr;
int err;
addr = xp_get_handle(xskb);
7 err = xskq_prod_reserve_desc(xs->rx, addr, len);
8 if (err) {
xs->rx_queue_full++;
return err;
}
在我们的案例中,第 7 行是对 xskq_prod_reserve_desc() 的调用。在此时的代码中,内核已经从 FILL 队列中移除了一个描述符,并将一个数据包复制到该描述符中。对 xsk_prod_reserve_desc() 的调用将确保 RX 队列中有空间,以及是否有空间将该描述符添加到 RX 队列。需要注意的是,虽然 xskq_prod_reserve_desc() 会把描述符插入 RX 队列中,但它不会更新 RX 环的生产者指针,也不会通知 XSK 数据包已准备就绪,等待读取,因为内核会尝试批量处理这些操作。
同样,我们想在内核端的传输路径上放置一个探测器,最终放置了以下探测器:
perf probe -a 'xp_raw_get_data:0 addr'
这个代码中没什么有趣的内容可以展示,但是这个探测器放置的位置是:描述符已经从 TX 队列中移除,但尚未插入 COMPLETION 队列。
对于这两个探测器,如果将探测器放置在描述符从 XSK 队列中添加或删除的最早位置,并尽可能多输出这些位置的信息,那该多好。然而,在实践中,可以放置 kprobe 的位置和这些位置的可用变量限制了可以看到的内容。
创建探测器之后,我们还需要能够在 ftrace 中看到它们。这可以通过以下方式来实现:
echo 1 > /sys/kernel/debug/tracing/events/probe/__xsk_rcv_zc_L7/enableecho 1 > /sys/kernel/debug/tracing/events/probe/xp_raw_get_data/enable
由于我们的应用程序更新之后,可以跟踪每次描述符转换,并在发生无效转换时停止跟踪,我们准备再次进行测试。
跟踪描述符状态还不够
遗憾的是,我们对“飞行记录器”的初步测试并没有立即获得任何新信息。它主要只是证实了我们已知的事情,即最终我们有同一描述符出现了两次,原因不明。它还强调了这一事实:捕获无效的描述符转换并不意味着发现了重复描述符出现的最早时间点。例如,假设我们有描述符 A 和重复描述符 A'。如果它们都已存在于 FILL 队列中,则以下转换完全有效:
RX A -> FILL ARX A’ -> FILL A’
这可能会循环发生许多次,才会最终发生无效转换,即这两个描述符出现在同一批次或队列之间。
相反,我们需要重新思考我们的方法。我们知道,内核从 FILL 队列中移除描述符,填充并将其插入 RX 队列。这意味着,对于任何给定 XSK 来说,描述符插入 FILL 队列的顺序应该与它们从 RX 队列移出的顺序一致。如果一个描述符在此内核 RX 路径中曾经复制过,我们应该会看到,重复描述符出现的顺序不对。考虑到这一点,我们更新了我们的应用程序,使用一个双端队列独立跟踪 FILL 队列的顺序。当我们的应用程序将描述符插入 FILL 队列时,我们也将描述符地址插入了跟踪队列的尾部,当我们接收数据包时,会从跟踪队列的头部弹出描述符地址,确保地址相符。如有任何不符,我们就再次记录到 trace_marker 并停止 ftrace。
下面是我们捕获的第一次跟踪结束,更新的代码跟踪 FILL 到 RX 队列的顺序。添加颜色是为了提高可读性:
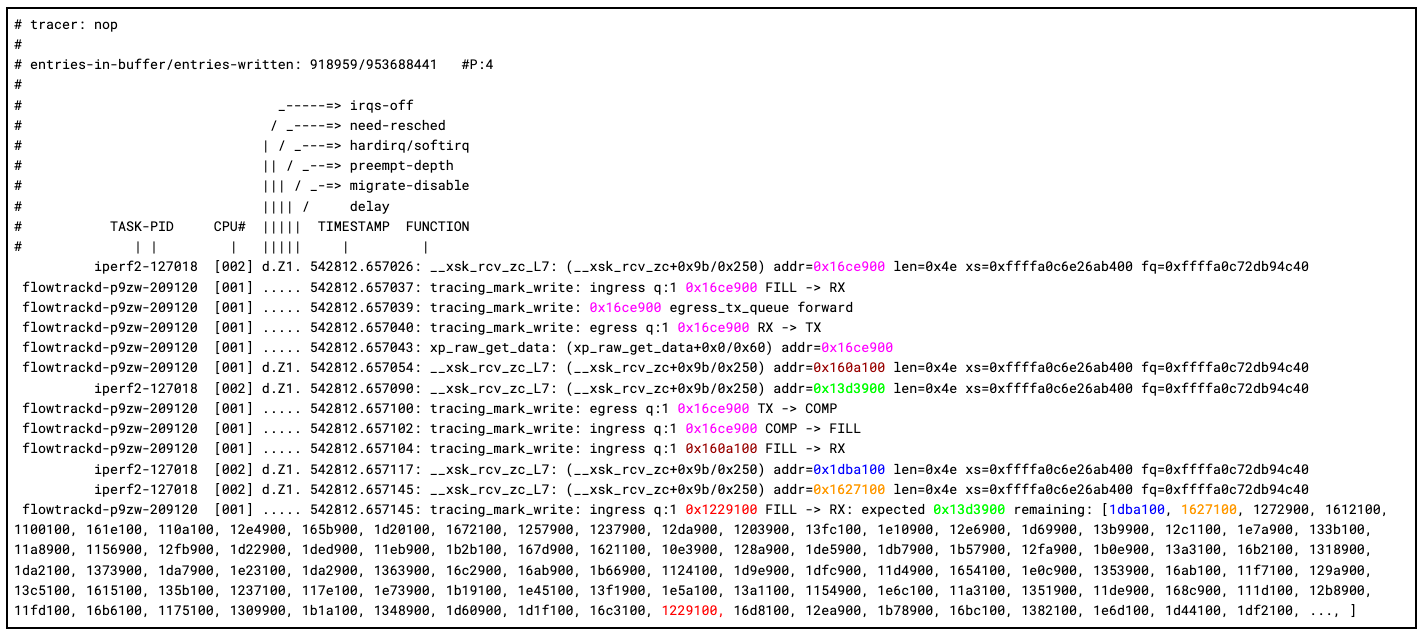
您可以发现,我们的 ftrace 飞行记录器的功能强大。例如,我们可以完整跟踪描述符 0x16ce900 的整个周期:描述符先被内核接收、被我们的应用程序接收、通过添加到 TX 队列来转发数据包、内核传输,最后我们的应用程序接收完成并将描述符返回 FILL 队列。
在内核接收到的下两个数据包中,跟踪开始变得有趣。我们可以看到 0x160a100 首先被内核接收,然后被我们的应用程序接收。然而,在内核接收 0x13d3900 时出错了,因为我们的应用程序接收到的是 0x1229100。跟踪的最后一页显示了我们的描述符顺序跟踪结果。我们可以看到,内核端似乎与我们预期的下一个描述符和下两个描述符相符,但出乎意料的是,我们看到 0x1229100 突然出现了。我们确实认为这个描述符是在 FILL 队列中,但它在队列中的位置要靠后很多。另一个潜在有趣的细节是,在 0x160a100 和 0x13d3900 之间,内核的软中断从 CPU 1 切换到了 CPU 2。
还记得吗?我们的 __xsk_rcv_zc_L7 kprobe 放置在对xskq_prod_reserve_desc() 的调用上,后者将描述符添加到 RX 队列。下面我们可以检查这个函数,看看是否有任何线索表明我们的应用程序接收的描述符地址与我们认为内核本应插入的地址不同。
static inline int xskq_prod_reserve_desc(struct xsk_queue *q,
u64 addr, u32 len)
{
struct xdp_rxtx_ring *ring = (struct xdp_rxtx_ring *)q->ring;
u32 idx;
if (xskq_prod_is_full(q))
return -ENOBUFS;
/* A, matches D */
idx = q->cached_prod++ & q->ring_mask;
ring->desc[idx].addr = addr;
ring->desc[idx].len = len;
return 0;
}
现在您可以看到,在我们更新描述符地址与长度之前,首先增加了队列的 cached_prod 指针。顾名思义,cached_prod 指针并不是实际的生产者指针,这意味着在某些时候,必须调用 xsk_flush(),cached_prod 指针和 prod 指针才能同步,才能真正将新接收的描述符暴露在用户模式下。也许存在一个竞态条件,即 xsk_flush() 在 cached_prod 指针更新之后,但在环中的实际描述符地址更新之前被调用?如果发生了这种情况,我们的应用程序会从 RX 队列的插槽中看到旧的描述符地址,并导致我们“复制”该描述符。
我们可以通过再做两项更改来测试我们的理论。首先,我们可以更新我们的应用程序,在我们收到一个数据包后,向每个 RX 队列插槽写回一个已知的“中毒”描述符地址。在我们的案例中,我们选择将 0xdeadbeefdeadbeef 作为我们已知的无效地址,只要我们接收回 RX 队列中的该值,我们就知道发生了竞态条件,暴露了一个未初始化的描述符。我们可以做的第二项更改是在 xsk_flush() 上添加 kprobe,看看我们能否在跟踪中实际捕获竞态条件。
perf probe -a 'xsk_flush:0 xs'

现在,我们似乎有了确凿的证据。如我们所料,我们可以看到 xsk_flush() 在 CPU 0 上被调用,而 CPU 2 上正在发生软中断。冲洗之后,我们的应用程序看到预期的 0xff0900 从 CPU 0 上的软中断填入,然后是 0xdeadbeefdeadbeef ,即我们未初始化的“中毒”描述符地址。
现在我们有证据表明是按以下操作顺序发生:
CPU 2 CPU 0
----------------------------------- --------------------------------
__xsk_rcv_zc(struct xdp_sock *xs): xsk_flush(struct xdp_sock *xs):
idx = xs->rx->cached_prod++ & xs->rx->ring_mask;
// Flush the cached pointer as the new head pointer of
// the RX ring.
smp_store_release(&xs->rx->ring->producer, xs->rx->cached_prod);
// Notify user-side that new descriptors have been produced to
// the RX ring.
sock_def_readable(&xs->sk);
// flowtrackd reads a descriptor "too soon" where the addr
// and/or len fields have not yet been updated.
xs->rx->ring->desc[idx].addr = addr;
xs->rx->ring->desc[idx].len = len;
AF_XDP 文档指出:“所有的环都是单生产者/单消费者,所以,用户空间的应用程序需要显式同步多个正在对其进行读/写的进程/线程。”显式同步要求也必须适用于内核端。一个套接字的 RX 环上的两项操作如何能同时运行?
在 Linux 上,一种名为 NAPI 的机制可以在每次网络接口接收数据包时防止发生 CPU 中断。它指示网络驱动程序在很短的时间间隔内处理一定数量的数据包。对于 veth 驱动程序,这个轮询函数称为 veth_poll,并被注册为支持 XDP 的网络设备每个队列的函数处理程序。一个符合 NAPI 标准的网络驱动程序可保证,与 NAPI 上下文绑定的数据包 (struct napi_struct *napi) 不会在多个处理器上同时处理。在我们的案例中,设备的每个队列都有一个 NAPI 上下文,即每个 AF_XDP 套接字及其关联的一组环形缓冲区(RX、TX、FILL、COMPLETION)。
static int veth_poll(struct napi_struct *napi, int budget)
{
struct veth_rq *rq =
container_of(napi, struct veth_rq, xdp_napi);
struct veth_stats stats = {};
struct veth_xdp_tx_bq bq;
int done;
bq.count = 0;
xdp_set_return_frame_no_direct();
done = veth_xdp_rcv(rq, budget, &bq, &stats);
if (done < budget && napi_complete_done(napi, done)) {
/* Write rx_notify_masked before reading ptr_ring */
smp_store_mb(rq->rx_notify_masked, false);
if (unlikely(!__ptr_ring_empty(&rq->xdp_ring))) {
if (napi_schedule_prep(&rq->xdp_napi)) {
WRITE_ONCE(rq->rx_notify_masked, true);
__napi_schedule(&rq->xdp_napi);
}
}
}
if (stats.xdp_tx > 0)
veth_xdp_flush(rq, &bq);
if (stats.xdp_redirect > 0)
xdp_do_flush();
xdp_clear_return_frame_no_direct();
return done;
}
veth_xdp_rcv() 处理与预算变量设置相同数量的数据包,将 NAPI 处理标记为完成,有可能重新安排一次 NAPI 轮询,然后调用 xdp_do_flush(),破坏上述 NAPI 保证。调用 napi_complete_done() 之后,任何 CPU 都可以在之前调用的所有冲洗操作完成之前,自由执行 veth_poll() 函数,允许 RX 环上出现竞态条件。
可以在发出 NAPI 轮询完成信号之前,完成所有数据包处理来修复该竞态条件。补丁以及促进修复的内核邮件列表的讨论请点击此处:[PATCH] veth:修复 AF_XDP 暴露旧的或未初始化的描述符导致的竞态条件。补丁最近已在上游合并。
总结
我们发现并修复了 Linux 虚拟以太网 (veth) 驱动程序中的一个竞态条件,该竞态条件破坏了支持 AF_XDP 的设备的数据包。
这个问题很难发现(也很难重现),但逻辑迭代引导我们一路找到 Linux 内核的内部,我们终于发现有几行代码没有按照正确的顺序执行。
我们终于跟踪到了潜在复杂的错误的根源,采用严密的方法、了解正确的调试工具至关重要。
修复这一错误于我们有重要意义,因为虽然 TCP 的设计是为了在偶尔丢包时恢复数据,但随机丢弃合法数据包略微延迟了我们网络上的现有连接和数据传输。
有兴趣深入研究其他内核调试过程吗?请访问我们的博客,阅读更多内容!