


今天,我們很高興地宣佈,我們已將 Mistral-7B-v0.1-instruct 新增到 Workers AI 中。Mistral 7B 是一個 73 億參數語言模型,具有許多獨特的優勢。我們將在 Mistral AI 創始人的幫助下介紹 Mistral 7B 模型的一些亮點,並利用這個機會更深入地研究「注意力」及其變體,例如多查詢注意力 (multi-query attention) 和分組查詢注意力 (grouped-query attention)。
Mistral 7B tl;dr:
Mistral 7B 是一個 73 億參數模型,在基準測試中得出了令人印象深刻的數據。該模型:
- 在所有基準測試中都優於 Llama 2 13B;
- 在許多基準測試中都優於 Llama 1 34B;
- 程式碼效能接近 CodeLlama 7B,同時仍擅長英文任務;以及
- 在 Mistral 提供的基準測試中,我們部署的聊天微調版本優於 Llama 2 13B 聊天。
下面是透過 REST API 使用串流處理的範例:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
下面是使用 Worker 指令碼的範例:
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral 利用分組查詢注意力來加快推理速度。這項最近開發的技術提高了推理速度,同時又不影響輸出品質。對於 70 億參數模型,藉助分組查詢注意力,我們使用 Mistral 每秒產生的權杖數量幾乎是 Llama 的 4 倍。
您不需要除此之外的任何資訊即可開始使用 Mistral-7B,您可以立即在 ai.cloudflare.com 上進行測試。要瞭解有關注意力和分組查詢注意力的更多資訊,請繼續閱讀!
那麼,「注意力」到底是什麼呢?
注意力的基本機制,特別是里程碑式論文「Attention Is All You Need」(注意力就是你所需要的一切)中介紹的「縮放點積注意力 (Scaled Dot-Product Attention)」,相當簡單:
我們將我們的特定注意力稱為「縮放點積注意力」。輸入由維度 d_k 的查詢和鍵以及維度 d_v 的值組成。我們使用所有鍵計算查詢的點積,將每個鍵除以 sqrt(d_k) 並套用 softmax 函數來獲取值的權重。
更具體地說,這看起來像這樣:
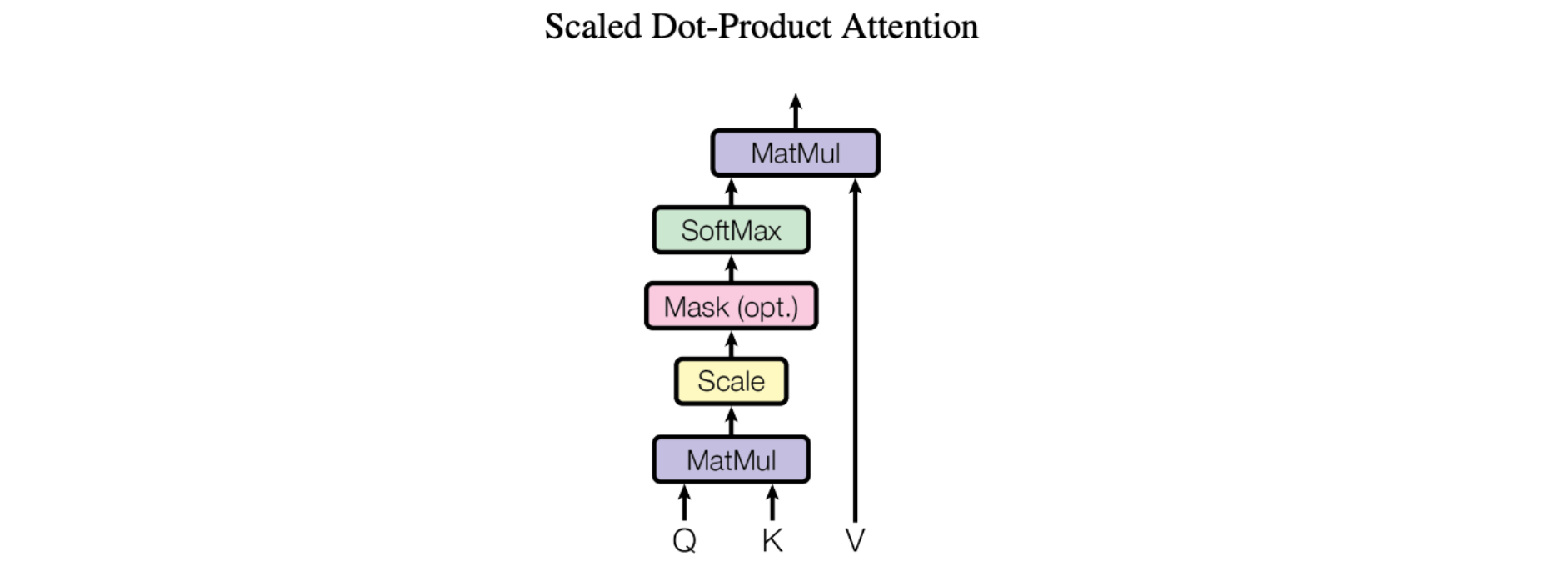
簡而言之,這使得模型能夠專注於輸入的重要部分。想像一下您正在閱讀一個句子並試圖理解它。縮放點積注意力使您能夠根據某些單詞的相關性更加關注它們。它的工作原理是計算句子中每個單詞 (K) 與查詢 (Q) 之間的相似度。然後,它透過將相似度分數除以查詢維度的平方根來縮放相似度分數。這種縮放有助於避免非常小或非常大的值。最後,使用這些縮放後的相似度分數,我們可以確定每個單詞應該受到多少關注(或者說其重要性如何)。這種注意力機制有助於模型識別關鍵資訊 (V) 並提高其理解和翻譯能力。
很簡單,對吧?為了從這個簡單的機制發展到可以編寫「Jerry 學習冒泡排序演算法的《宋飛正傳》」的人工智慧,我們需要讓它變得更加複雜。事實上,我們剛剛介紹的所有內容甚至沒有任何學習參數,這是在模型訓練期間學習的恒定值,用於自訂注意力區塊的輸出!
「Attention is All You Need」中的注意力區塊主要增加了三種類型的複雜性:
學習參數
學習參數是指在模型訓練過程中為了提高模型效能而調整的值或權重。這些參數用於控制模型內的資訊流或注意力,使其能夠專注於輸入資料的最相關部分。簡而言之,學習參數就像機器上的可調節旋鈕,可以轉動它來最佳化其操作。
垂直堆疊——分層注意力區塊
垂直分層堆疊是一種將多個注意力機制堆疊在一起的方法,每一層都建立在前一層的輸出之上。這使得模型能夠專注於不同抽象層級的輸入資料的不同部分,從而可以在某些任務上獲得更好的效能。
水準堆疊——又名多頭注意力 (Multi-Head Attention)
論文中的圖顯示了完整的多頭注意力模組。多個注意力操作是同時執行的,每個注意力操作的 Q-K-V 輸入由相同輸入資料(由一組唯一的學習參數定義)的唯一線性投影產生。這些並行的注意力區塊被稱為「注意力頭」。所有注意力頭的加權和輸出被連接成一個向量,並透過另一個參數化線性變換以獲得最終輸出。
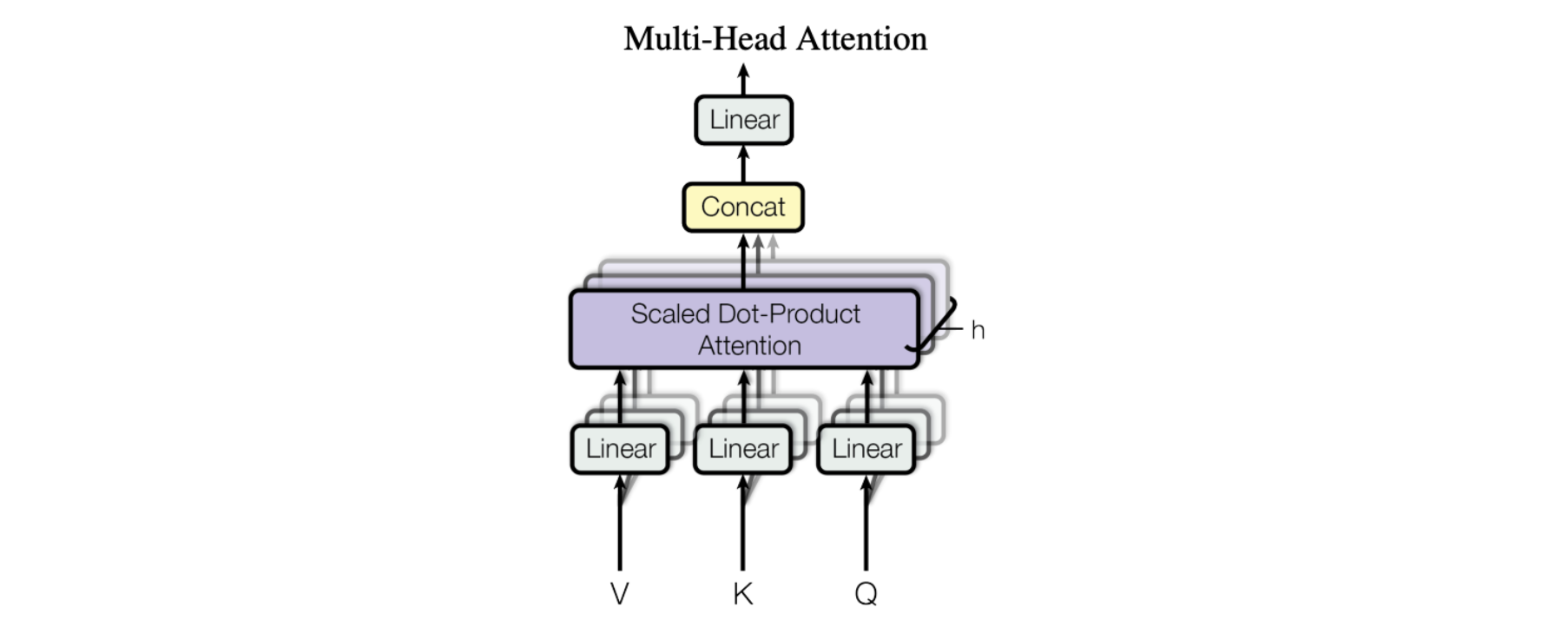
這種機制允許模型同時關注輸入資料的不同部分。想像一下,您正在嘗試理解一條複雜的資訊,例如一個句子或一個段落。為了理解它,您需要同時注意它的不同部分。例如,您可能需要同時注意句子的主語、動詞和賓語,才能理解句子的含義。多頭注意力的工作原理與此類似。它允許模型透過使用多個注意力「頭」同時關注輸入資料的不同部分。每個注意力頭關注輸入資料的不同方面,所有注意力頭的輸出組合起來產生模型的最終輸出。
注意力的類型
近年來開發的大型語言模型使用三種常見的注意力區塊排列:多頭注意力、分組查詢注意力和多查詢注意力。它們的不同之處在于相對于查詢向量數量的 K 和 V 向量的數量。多頭注意力使用與 Q 向量相同數量的 K 和 V 向量,在下表中用「N」表示。多查詢注意力僅使用單個 K 和 V 向量。分組查詢注意力是 Mistral 7B 模型中使用的類型,它將 Q 向量均勻地分成每個包含「G」向量的群組,然後為每個群組使用單個 K 和 V 向量,總共 N 個向量,除以 G 組 K 和 V 向量。這裡簡單總結了這些差異,我們將在下面深入探討這些差異的含義。
|
鍵/值區塊數 |
品質 |
記憶體使用量 |
|
|
多頭注意力 (MHA) |
N |
最佳 |
最多 |
|
分組查詢注意力 (GQA) |
N / G |
更佳 |
較少 |
|
多查詢注意力 (MQA) |
1 |
良性 |
最少 |
注意力類型摘要
這張圖有助於說明三種類型之間的區別:
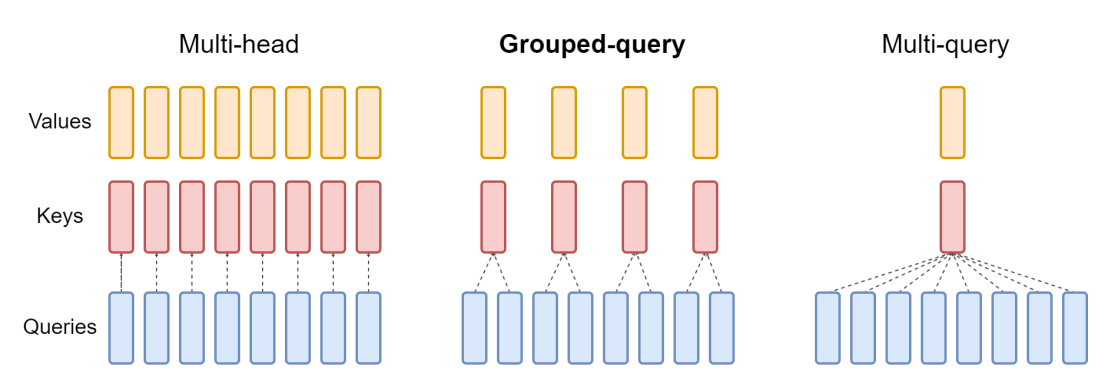
多查詢注意力
2019 年 Google 的論文「Fast Transformer Decoding: One Write-Head is All You Need」(快速 Transformer 解碼:一個寫頭即可滿足您的需求)描述了多查詢注意力。這個理念是,不像上面的多頭注意力那樣為注意力機制中的每個 Q 向量建立單獨的 K 和 V 項目,而是僅將單個 K 和 V 向量用於整個 Q 向量集。因此,多個查詢組合成一個單一的注意力機制。在論文中,這是在翻譯任務上進行基準測試的,並且在基準任務上表現出與多頭注意力相同的效能。
最初的想法是減少執行模型推理時存取的記憶體總大小。從那時起,隨著廣義模型的出現和參數數量的增長,所需的 GPU 記憶體往往成為多查詢注意力的瓶頸,因為它在三種注意力類型中所需的加速器記憶體最少。然而,隨著模型規模和通用性的增長,多查詢注意力的效能相對於多頭注意力有所下降。
分組查詢注意力
其中最新的(也是 Mistral 使用的)是分組查詢注意力,這在 2023 年 5 月在 arxiv.org 上發佈的論文「GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints」(GQA:從多頭檢查點訓練通用多查詢 Transformer 模型)中進行了介紹。多組查詢注意力結合了兩者的優點:多頭注意力的品質與多查詢注意力的速度和低記憶體使用量。不是使用一組 K 和 V 向量,也不是每個 Q 向量使用一組,而是每個 Q 向量使用 1 組 K 和 V 向量的固定比例,從而減少記憶體使用量,同時在許多任務上保持高效能。
通常,為生產任務選擇模型不僅僅是選擇可用的最佳模型,因為我們必須考慮效能、記憶體使用、批量大小和可用硬體(或雲端成本)之間的權衡。瞭解這三種注意力方式可以協助指導這些決策,並瞭解我們何時可以根據具體情況選擇特定模型。
進入 Mistral——立即試用
作為第一個利用分組查詢注意力並將其與滑動視窗注意力相結合的大型語言模型,Mistral 似乎已經達到了最佳狀態——它具有低延遲、高輸送量的特點,而且即使與更大的模型 (13B) 相比,它在基準測試中也表現得非常好。所有這一切都表明,它的尺寸與功能都達到了巔峰,我們非常高興今天能夠透過 Workers AI 將其提供給所有開發人員。
請前往我們的開發人員文件以開始使用。如果您需要幫助、想要提供意見反應或想要分享您正在構建的內容,請進入我們的開發人員 Discord!
Workers AI 團隊也在擴大和招聘;如果您對人工智慧工程充滿熱情,並希望幫助我們構建和發展我們的全球無伺服器 GPU 驅動的推理平台,請查看我們的職位頁面,瞭解空缺職位。