


今天,我们很高兴地宣布,我们已将 Mistral-7B-v0.1-instruct 添加到 Workers AI 中。Mistral 7B 是一个 73 亿参数语言模型,具有许多独特的优势。我们将在 Mistral AI 创始人的帮助下介绍 Mistral 7B 模型的一些亮点,并利用这个机会更深入地研究“注意力”及其变体,例如多查询注意力 (multi-query attention) 和分组查询注意力 (grouped-query attention)。
Mistral 7B tl;dr:
Mistral 7B 是一个 73 亿参数模型,在基准测试中得出了令人印象深刻的数据。该模型:
- 在所有基准测试中都优于 Llama 2 13B;
- 在许多基准测试中都优于 Llama 1 34B;
- 代码性能接近 CodeLlama 7B,同时仍擅长英语任务;以及
- 在 Mistral 提供的基准测试中,我们部署的聊天微调版本优于 Llama 2 13B 聊天。
下面是通过 REST API 使用流式传输的示例:
curl -X POST \
“https://api.cloudflare.com/client/v4/accounts/{account-id}/ai/run/@cf/mistral/mistral-7b-instruct-v0.1” \
-H “Authorization: Bearer {api-token}” \
-H “Content-Type:application/json” \
-d '{ “prompt”: “What is grouped query attention”, “stream”: true }'
API Response: { response: “Grouped query attention is a technique used in natural language processing (NLP) and machine learning to improve the performance of models…” }
下面是使用 Worker 脚本的示例:
import { Ai } from '@cloudflare/ai';
export default {
async fetch(request, env) {
const ai = new Ai(env.AI);
const stream = await ai.run('@cf/mistral/mistral-7b-instruct-v0.1', {
prompt: 'What is grouped query attention',
stream: true
});
return Response.json(stream, { headers: { “content-type”: “text/event-stream” } });
}
}
Mistral 利用分组查询注意力来加快推理速度。这项最近开发的技术提高了推理速度,同时又不影响输出质量。对于 70 亿参数模型,借助分组查询注意力,我们使用 Mistral 每秒生成的令牌数量几乎是 Llama 的 4 倍。
您不需要除此之外的任何信息即可开始使用 Mistral-7B,您可以立即在 ai.cloudflare.com 上进行测试。要了解有关注意力和分组查询注意力的更多信息,请继续阅读!
那么,“注意力”到底是什么呢?
注意力的基本机制,特别是里程碑式论文“Attention Is All You Need”(注意力就是你所需要的一切)中介绍的“缩放点积注意力 (Scaled Dot-Product Attention)”,相当简单:
我们将我们的特定注意力称为“缩放点积注意力”。输入由维度 d_k 的查询和键以及维度 d_v 的值组成。我们使用所有键计算查询的点积,将每个键除以 sqrt(d_k) 并应用 softmax 函数来获取值的权重。
更具体地说,是像这样:
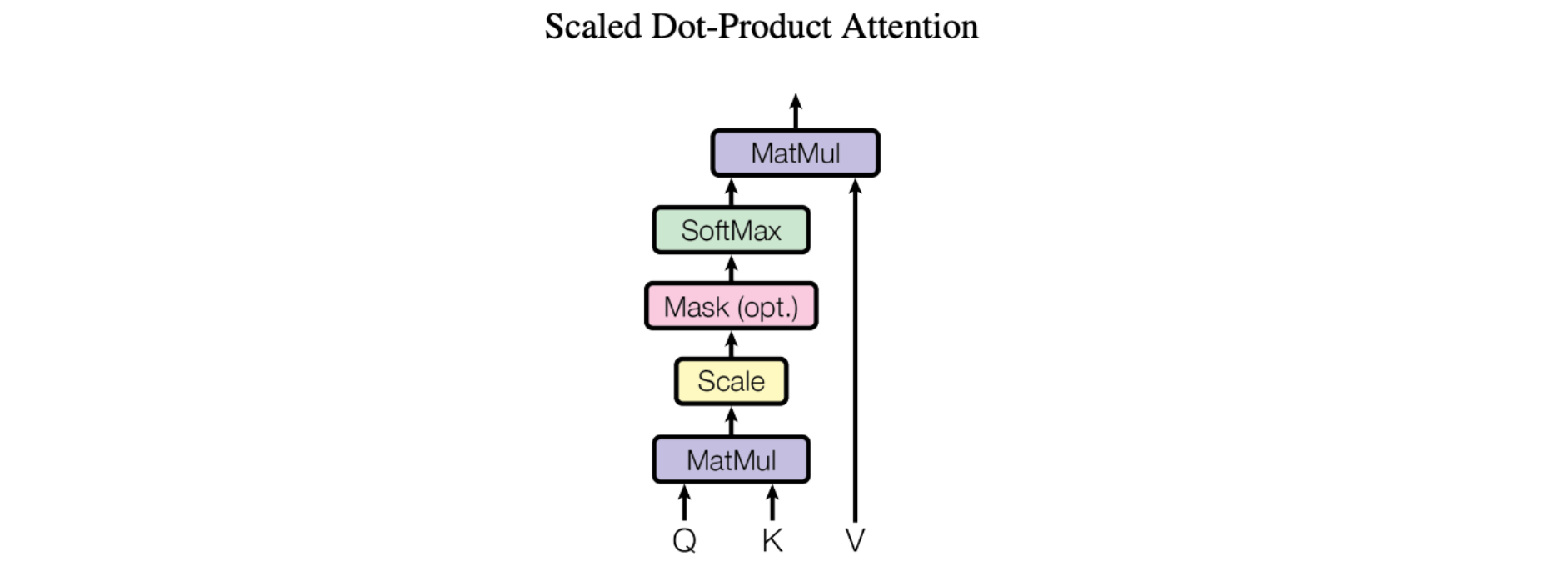
简而言之,这使得模型能够专注于输入的重要部分。想象一下您正在阅读一个句子并试图理解它。缩放点积注意力使您能够根据某些单词的相关性更加关注它们。它的工作原理是计算句子中每个单词 (K) 与查询 (Q) 之间的相似度。然后,它通过将相似度分数除以查询维度的平方根来缩放相似度分数。这种缩放有助于避免非常小或非常大的值。最后,使用这些缩放后的相似度分数,我们可以确定每个单词应该受到多少关注(或者说其重要性如何)。这种注意力机制有助于模型识别关键信息 (V) 并提高其理解和翻译能力。
很简单,对吧?为了从这个简单的机制发展到可以编写“Jerry 学习冒泡排序算法的《宋飞正传》”的人工智能,我们需要让它变得更加复杂。事实上,我们刚刚介绍的所有内容甚至没有任何学习参数,这是在模型训练期间学习的恒定值,用于自定义注意力块的输出!
“Attention is All You Need”中的注意力块主要增加了三种类型的复杂性:
学习参数
学习参数是指在模型训练过程中为了提高模型性能而调整的值或权重。这些参数用于控制模型内的信息流或注意力,使其能够专注于输入数据的最相关部分。简而言之,学习参数就像机器上的可调节旋钮,可以转动它来优化其操作。
垂直堆叠——分层注意力块
垂直分层堆叠是一种将多个注意力机制堆叠在一起的方法,每一层都建立在前一层的输出之上。这使得模型能够专注于不同抽象级别的输入数据的不同部分,从而可以在某些任务上获得更好的性能。
水平堆叠——又名多头注意力 (Multi-Head Attention)
论文中的图显示了完整的多头注意力模块。多个注意力操作是并行执行的,每个注意力操作的 Q-K-V 输入是由相同输入数据(由一组唯一的学习参数定义)的唯一线性投影生成的。这些并行的注意力块被称为“注意力头”。所有注意力头的加权和输出被连接成一个向量,并通过另一个参数化线性变换以获得最终输出。
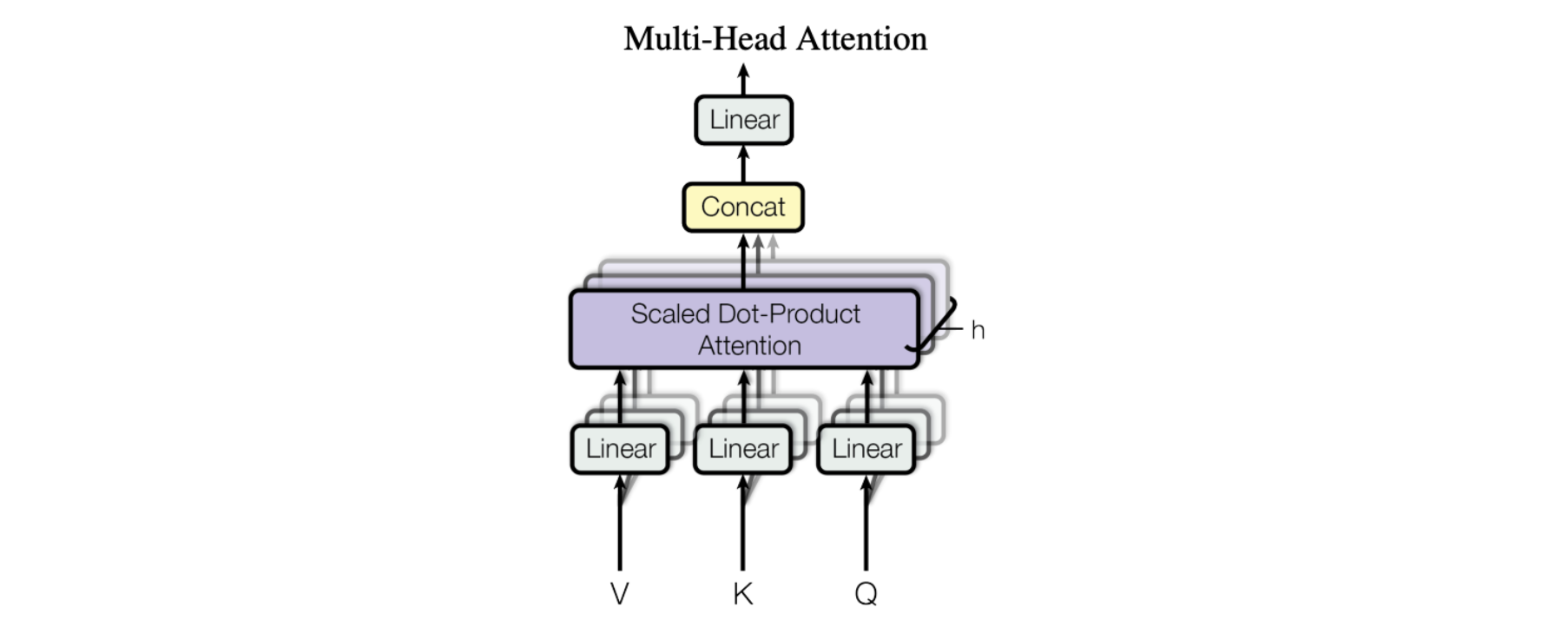
这种机制允许模型同时关注输入数据的不同部分。想象一下,您正在尝试理解一条复杂的信息,例如一个句子或一个段落。为了理解它,您需要同时注意它的不同部分。例如,您可能需要同时注意句子的主语、动词和宾语,才能理解句子的含义。多头注意力的工作原理与此类似。它允许模型通过使用多个注意力“头”同时关注输入数据的不同部分。每个注意力头关注输入数据的不同方面,所有注意力头的输出组合起来产生模型的最终输出。
注意力的类型
近年来开发的大型语言模型使用三种常见的注意力块排列:多头注意力、分组查询注意力和多查询注意力。它们的不同之处在于相对于查询向量数量的 K 和 V 向量的数量。多头注意力使用与 Q 向量相同数量的 K 和 V 向量,在下表中用“N”表示。多查询注意力仅使用单个 K 和 V 向量。分组查询注意力是 Mistral 7B 模型中使用的类型,它将 Q 向量均匀地分成每个包含“G”向量的组,然后为每个组使用单个 K 和 V 向量,总共 N 个向量,除以 G 组 K 和 V 向量。这里简单总结了这些差异,我们将在下面深入探讨这些差异的含义。
|
键/值块数量 |
质量 |
内存使用情况 |
|
|
多头注意力 (MHA) |
N |
最佳 |
大多数 |
|
分组查询注意力 (GQA) |
N / G |
更好 |
更少 |
|
多查询注意力 (MQA) |
1 |
良性 |
最少 |
注意力类型概述
这张图有助于说明三种类型之间的区别:
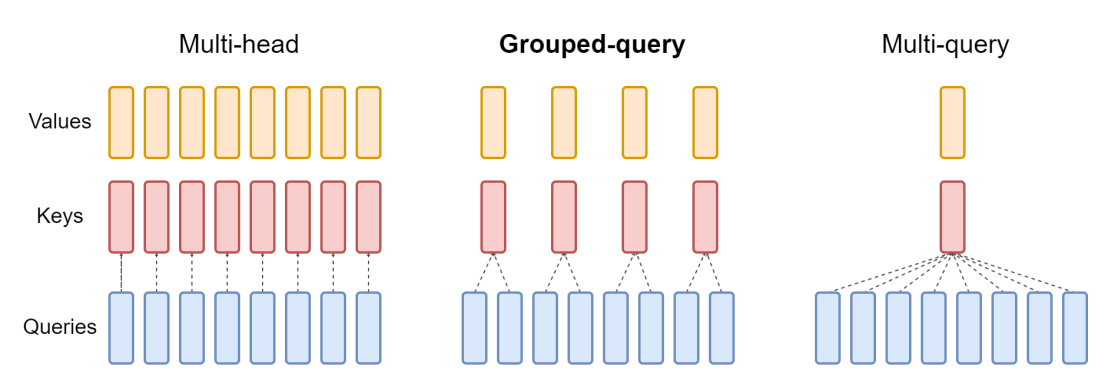
多查询注意力
2019 年 Google 的论文“Fast Transformer Decoding: One Write-Head is All You Need”(快速 Transformer 解码:一个写头即可满足您的需求)描述了多查询注意力。这个理念是,不像上面的多头注意力那样为注意力机制中的每个 Q 向量创建单独的 K 和 V 条目,而是仅将单个 K 和 V 向量用于整个 Q 向量集。因此,多个查询组合成一个单一的注意力机制。在论文中,这是在翻译任务上进行基准测试的,并且在基准任务上表现出与多头注意力相同的性能。
最初的想法是减少执行模型推理时访问的内存总大小。从那时起,随着广义模型的出现和参数数量的增长,所需的 GPU 内存往往成为多查询注意力的瓶颈,因为它在三种注意力类型中所需的加速器内存最少。然而,随着模型规模和通用性的增长,多查询注意力的性能相对于多头注意力有所下降。
分组查询注意力
其中最新的(也是 Mistral 使用的)是分组查询注意力,这在 2023 年 5 月在 arxiv.org 上发布的论文“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”(GQA:从多头检查点训练通用多查询 Transformer 模型)中进行了介绍。多组查询注意力结合了两者的优点:多头注意力的质量与多查询注意力的速度和低内存使用量。不是使用一组 K 和 V 向量,也不是每个 Q 向量使用一组,而是每个 Q 向量使用 1 组 K 和 V 向量的固定比例,从而减少内存使用量,同时在许多任务上保持高性能。
通常,为生产任务选择模型不仅仅是选择可用的最佳模型,因为我们必须考虑性能、内存使用、批量大小和可用硬件(或云成本)之间的权衡。了解这三种注意力方式可以帮助指导这些决策,并了解我们何时可以根据具体情况选择特定模型。
进入 Mistral——立即试用
作为第一个利用分组查询注意力并将其与滑动窗口注意力相结合的大型语言模型,Mistral 似乎已经达到了最佳状态——它具有低延迟、高吞吐量的特点,而且即使与更大的模型 (13B) 相比,它在基准测试中也表现得非常好。所有这一切都表明,它的尺寸与功能都达到了巅峰,我们非常高兴今天能够通过 Workers AI 将其提供给所有开发人员。
请前往我们的开发人员文档以开始使用。如果您需要帮助、想要提供反馈或想要分享您正在构建的内容,请进入我们的开发人员 Discord!
Workers AI 团队也在扩大和招聘;如果您对人工智能工程充满热情,并希望帮助我们构建和发展我们的全球无服务器 GPU 驱动的推理平台,请查看我们的职位页面,了解空缺职位。