
大約三年前,我們推出了 Cloudflare Waiting Room,以保護客戶的網站免受合法流量劇增的衝擊,這種流量劇增可能導致其網站癱瘓。Waiting Room 讓客戶即使在高流量時也能控制使用者體驗,將多餘的流量放置在可自訂的品牌 Waiting Room 中,並在網站上有空位時動態接納使用者。自 Waiting Room 推出以來,我們根據客戶的意見反應不斷擴展其功能,如行動應用程式支援、分析、Waiting Room 繞過規則等 。
我們很喜歡發佈新功能,並透過擴展Waiting Room 的功能為客戶解決問題。但是今天,我們想給您一個幕後的視角,讓您瞭解我們如何發展產品的核心機制,即它如何啟動流量排隊以回應流量高峰。
Waiting Room 是如何構建的以及面臨哪些挑戰?
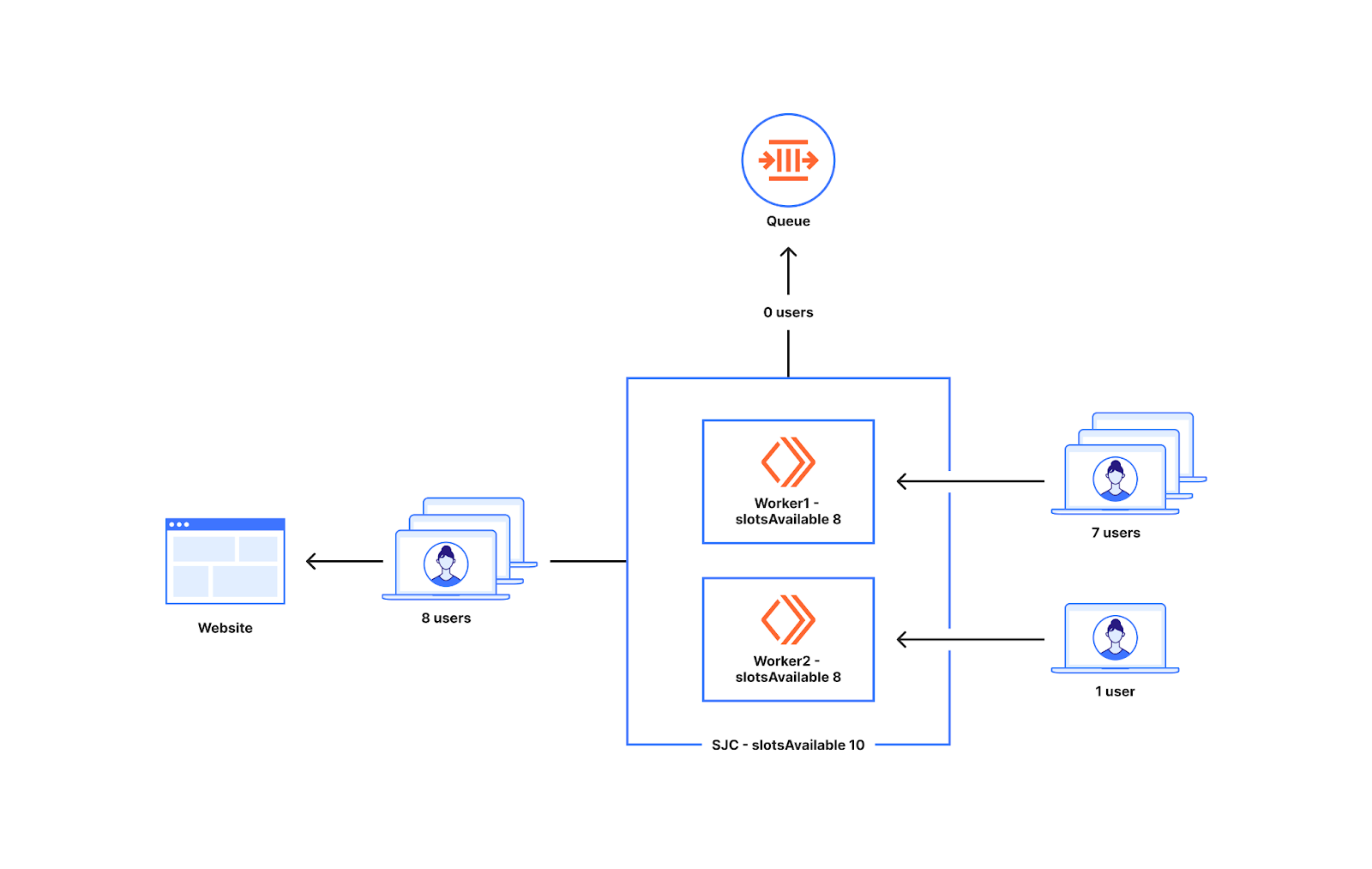
下圖顯示了 Waiting Room 在客戶網站啟用後的位置概觀。
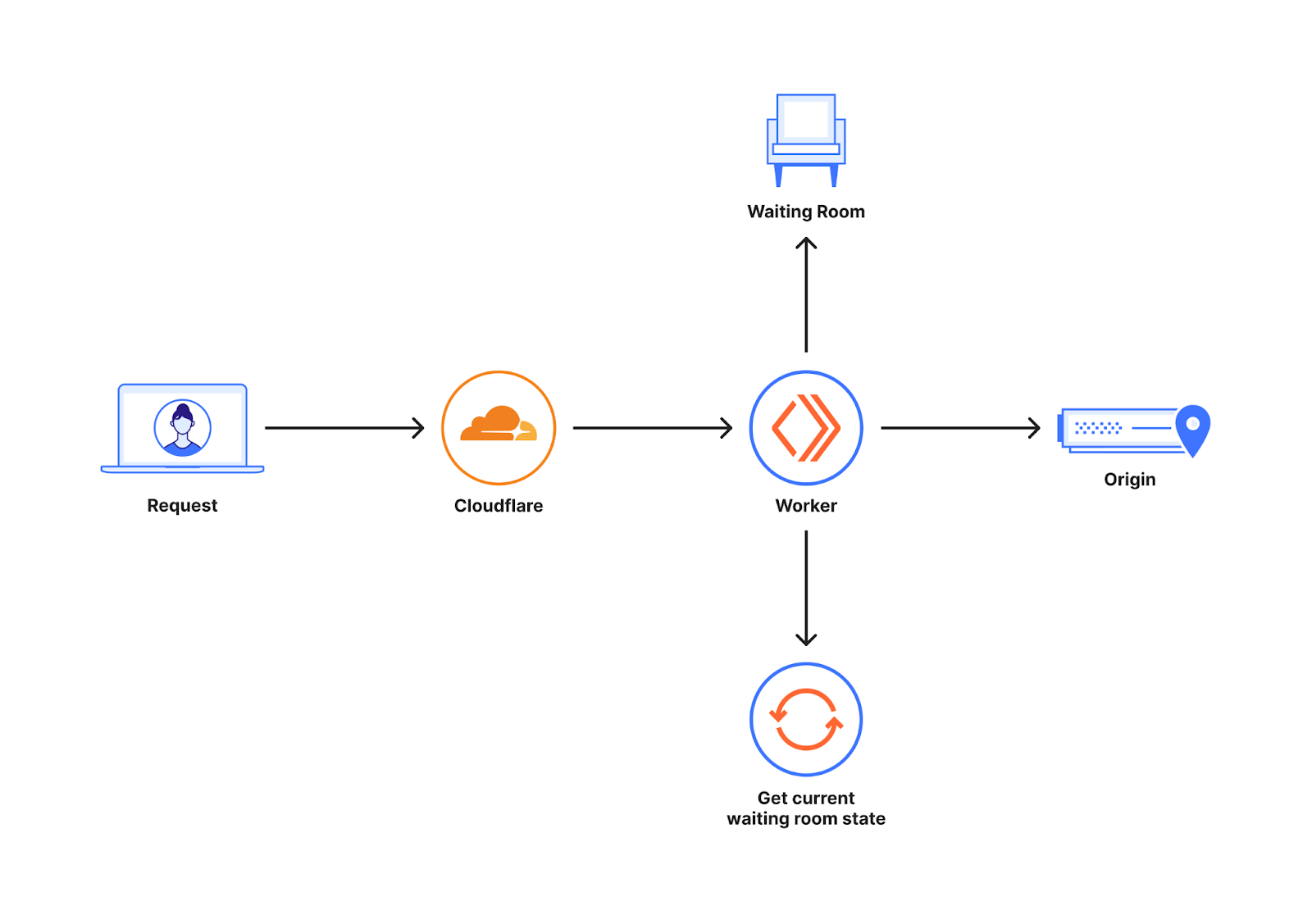
Waiting Room 建立在跨 Cloudflare 資料中心全球網路執行的 Workers 之上。對客戶網站的請求可能會轉到許多不同的 Cloudflare 資料中心。為了最佳化以減少延遲和提高效能,這些請求會被路由到地理位置最接近的資料中心。當新使用者向 Waiting Room 覆蓋的主機/路徑發出請求時,Waiting Room Worker 會決定是將使用者傳送到源站還是 Waiting Room。這一決定是利用 Waiting Room 狀態做出的,Waiting Room 狀態可提供源站上有多少使用者的資訊。
Waiting Room 的狀態會根據世界各地的流量不斷變化。這些資訊可以儲存在一個中央位置,或者最終可以在世界各地傳播變更。將這些資訊儲存在一個中心位置,會大大增加每次請求的延遲時間,因為中心位置可能離請求發出地非常遙遠。因此,每個資料中心都有自己的 Waiting Room 狀態,這是該時間點全球可用網站流量模式的快照。在讓使用者進入網站之前,我們不想等待來自世界其他地方的資訊,因為這會顯著增加請求的延遲時間。這就是我們選擇不設立中心位置,而是透過管道將流量變化最終傳播到世界各地的原因。
這個在後台匯總 Waiting Room 狀態的管道基於 Cloudflare Durable Objects 構建。2021 年,我們撰寫了一篇部落格,介紹了匯總管道的工作原理以及我們在其中採取的不同設計決策,如果您感興趣,可閱讀這篇文章。該管道可確保每個資料中心在幾秒鐘內獲得有關流量變化的最新資訊。
Waiting Room 必須根據當前看到的狀態決定是將使用者傳送到網站或還是讓他們排隊。必須在確保在正確的時間讓使用者排隊,以免客戶的網站過載。我們還必須確保不會因為誤認為出現流量高峰而讓使用者過早排隊。排隊可能會導致一些使用者放棄造訪該網站。Waiting Room 在 Cloudflare 網路中的每台伺服器上執行,該網路覆蓋 100 多個國家/地區的 300 多座城市。我們希望確保,在決定每個新使用者是直接造訪網站還是排隊時,能夠將延遲降到最低。這也正是何時排隊成為 Waiting Room 難題的原因。在本部落格中,我們將介紹如何進行這種權衡。我們的演算法不斷發展,以減少誤判,同時繼續尊重客戶設定的限制。
Waiting Room 如何決定何時讓使用者排隊
決定 Waiting Room 何時開始排隊的最重要因素是您配置流量設定的方式。設定 Waiting Room 時,您將設定兩個流量限制:作用中使用者總數和每分鐘新使用者數。作用中使用者總數是您希望在 Waiting Room 覆蓋的頁面上允許多少同時使用者數的目標閾值。每分鐘新使用者數定義了每分鐘使用者湧入網站的最大速率的目標閾值。這兩個值中任何一個的急劇上升都可能導致排隊。影響我們計算作用中使用者總數的另一個設定是工作階段持續時間。由於請求是向 Waiting Room 覆蓋的任何頁面發出的,因此使用者在工作階段持續時間分鐘內被視為處於作用中狀態。
下圖來自我們為客戶提供的一個內部監控工具,顯示了客戶兩天內的流量模式。該客戶將其每分鐘新使用者數和作用中使用者總數限制分別設定為 200 和 200。
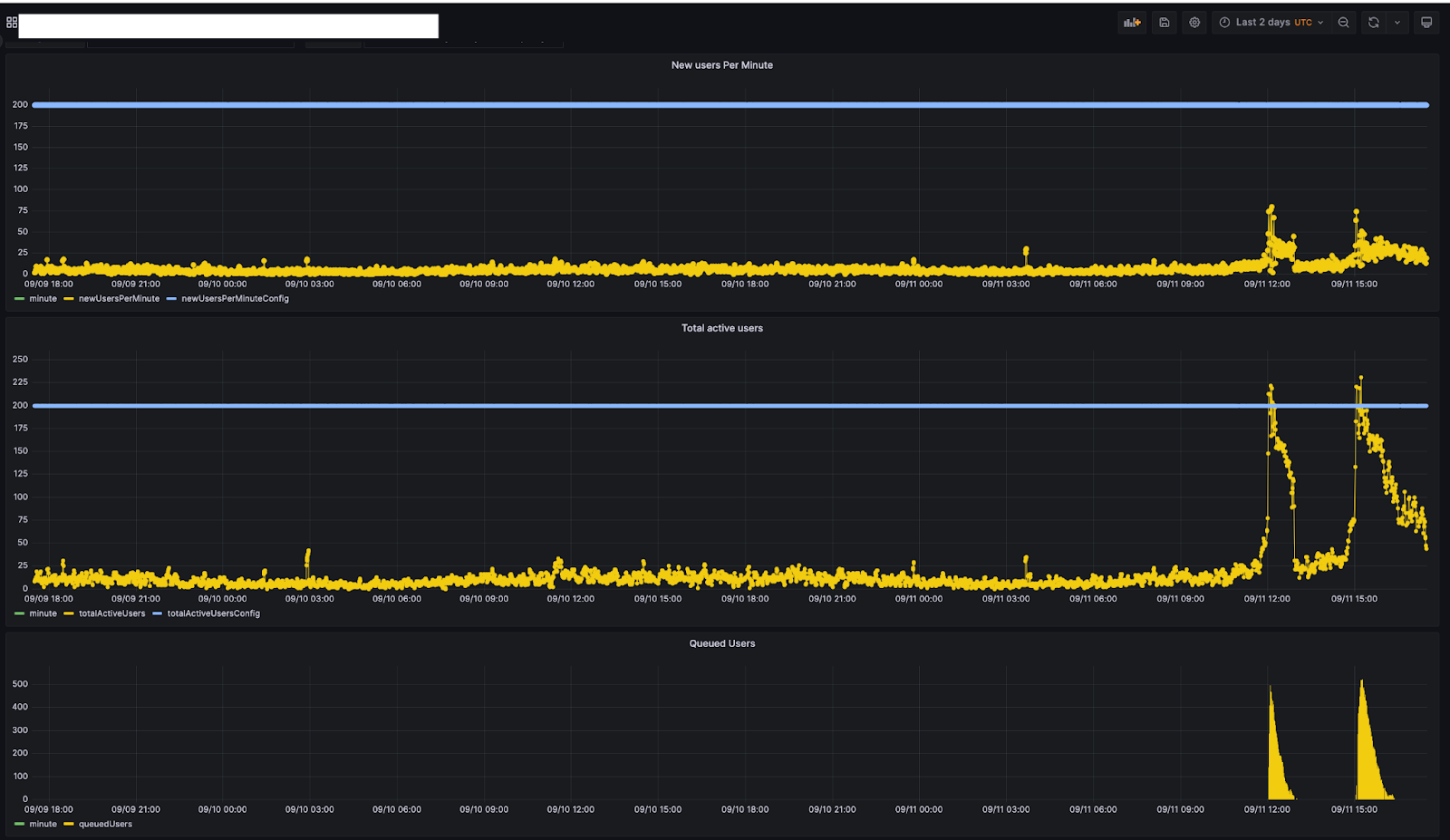
如果查看他們的流量,會發現使用者在 9 月 11 日 11:45 左右排隊。當時,作用中使用者總數約為 200 人左右。隨著作用中使用者總數逐漸下降(12:30 左右),排隊使用者逐漸減少到 0。9 月 11 日 15:00 左右,作用中使用者總數達到 200 時,再次開始排隊。此時讓使用者排隊,確保了造訪該網站的流量在客戶設定的限制範圍內。
一旦使用者獲得網站存取權限,我們就會向他們提供一個加密的 cookie,表明他們已經獲得存取權限。cookie 的內容可能如下所示。
{
"bucketId": "Mon, 11 Sep 2023 11:45:00 GMT",
"lastCheckInTime": "Mon, 11 Sep 2023 11:45:54 GMT",
"acceptedAt": "Mon, 11 Sep 2023 11:45:54 GMT"
}
cookie 就像一張門票,表明 Waiting Room 的入口。bucketId 表明該使用者屬於哪個使用者叢集。acceptedAt 時間和 lastCheckInTime 表明最後一次與 Workers 互動的時間。當我們將其與客戶在配置 Waiting Room 時設定的工作階段持續時間值進行比較時,該資訊可以表明門票是否能夠有效打開入口。如果 cookie 有效,我們會讓使用者通過,以確保網站上的使用者繼續能夠瀏覽網站。如果 cookie 無效,我們會建立一個新的 cookie,將使用者視為新使用者,如果網站上發生排隊,他們會排到佇列的後面。在下一節中,我們會介紹如何決定讓這些使用者進行排隊。
為了進一步理解這一點,讓我們來看看Waiting Room 狀態的內容。對於我們上面討論的客戶,在 "Mon, 11 Sep 2023 11:45:54 GMT" 時,狀態可能如下所示。
{
"activeUsers": 50,
}
如上所述,客戶設定的每分鐘新使用者數和作用中使用者總數分別為 200 和 200。
因此,該狀態表明,還有空間留給新使用者,因為只有 50 個作用中使用者,而作用中使用者可以達到 200 個。因此,還可以再允許 150 個使用者進入。假設這 50 個使用者分別來自聖約瑟(20 個使用者)和倫敦(30 個使用者)這兩個資料中心。我們還追蹤全球範圍內作用中的 Worker 數量以及計算狀態的資料中心的作用中 Worker 數量。聖約瑟可能計算得出下面的狀態金鑰。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
試想一下,在 "Mon, 11 Sep 2023 11:45:54 GMT" 這個時間,我們收到一個請求,前往聖約瑟資料中心的 Waiting Room。
要查看到達聖約瑟的使用者是否能前往源站,我們首先要查看過去一分鐘的流量歷程記錄,以瞭解當時的流量分佈情況。 這是因為很多網站在世界的某些地方很受歡迎。很多網站的流量往往來自相同的資料中心。
查看 "Mon, 11 Sep 2023 11:44:00 GMT" 這一分鐘的流量歷程記錄,我們可以看到當時聖約瑟的 200 個使用者中,有 20 個使用者前往該網站 (10%)。對於當前時間 "Mon, 11 Sep 2023 11:45:54 GMT",我們按照過去一分鐘流量歷程記錄的相同比例分配網站可用的名額。因此,我們可以從聖約瑟傳送 150 個可用名額的 10%,即 15 個使用者。我們還知道,有三個作用中的 Worker,因為 "dataCenterWorkersActive" 為 3。
資料中心可用的名額數量在資料中心的 Worker 之間平均分配。因此,聖約瑟的每個 Worker 都可以向該網站傳送 15/3 的使用者。如果接收流量的 Worker 在當前分鐘內未向源站傳送任何使用者,則它們最多可以傳送五個使用者 (15/3)。
同時 ("Mon, 11 Sep 2023 11:45:54 GMT"),假設有一個請求傳送到德里的資料中心。德里資料中心的 Worker 檢查了流量歷程記錄,發現沒有為其分配名額。對於這樣的流量,我們保留了 Anywhere 名額,因為我們距離所設定的限制確實還很遠。
{
"activeUsers":50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Anywhere 名額在全球所有作用中 Worker 之間劃分,相當於世界各地的任何 Worker 都可以分享這塊蛋糕。剩餘 150 個名額的 75%,即 113 個。
狀態金鑰還追蹤在世界各地產生的 Worker 數量 (globalWorkersActive)。分配的 Anywhere 名額將劃分給世界上所有作用中的 Worker(如果有)。當我們查看 Waiting Room 狀態時,globalWorkersActive 為 10。因此,每個作用中 Worker 最多可以傳送 113/10,即大約 11 個使用者。因此,在 Mon, 11 Sep 2023 11:45:00 GMT 這一分鐘內到達 Worker 的前 11 位使用者將被允許進入源站。後面的使用者需要排隊。之前討論過的聖約瑟會在 Mon, 11 Sep 2023 11:45:00 GMT 這一分鐘額外保留 5 個名額,確保我們可以允許來自聖約瑟的 Worker 最多 16 (5 + 11) 個使用者造訪該網站。
在 Worker 層級排隊可能會導致使用者在資料中心可用名額用完之前排隊
從上面的範例可以看出,我們是在 Worker 層級決定是否排隊的。前往世界各地 Worker 的新使用者數量可能並不相同。為了瞭解兩個 Worker 的流量分佈不均勻時會發生什麼情況,讓我們看看下圖。
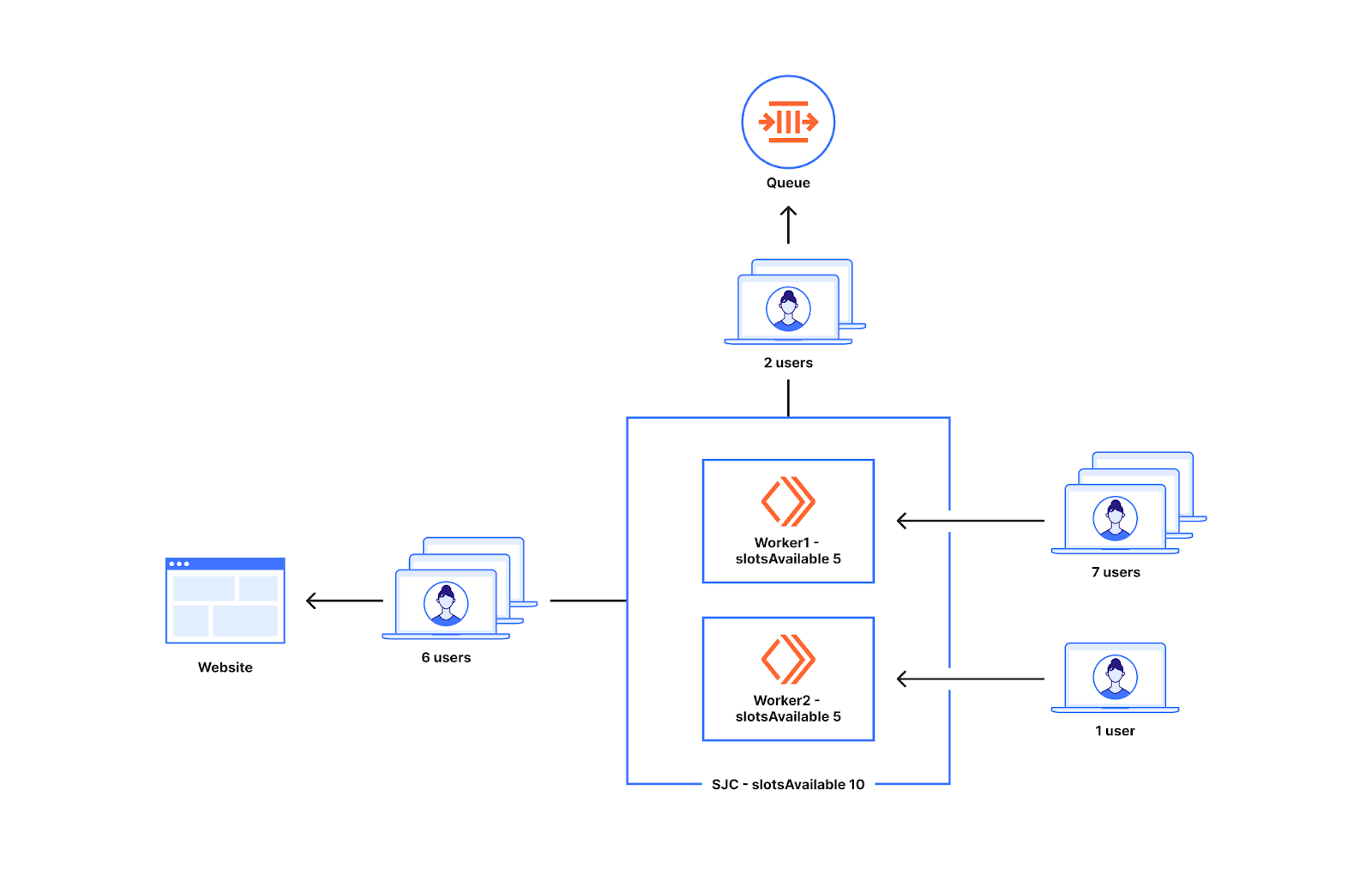
想像一下,聖約瑟資料中心的可用名額有十個。有兩個 Worker 在聖約瑟執行。七個使用者前往 worker1,一個使用者前往 worker2。在這種情況下,worker1 會讓七個使用者中的五個進入網站,其中兩個人會排隊,因為 worker1 只有五個可用名額。前往 worker2 的一個使用者也可以前往源站。因此,實際上可以從聖約瑟資料中心傳送十個使用者,但在只出現了八個使用者時,我們卻讓兩個使用者進行了排隊。
這種方式雖然在 Worker 之間平均分配了名額,但也導致在達到 Waiting Room 設定的流量限制之前進行排隊,通常在所設定限制的 20-30% 範圍內。我們接下來將討論這種方法的優點。 我們已經對這種方法進行了修改,以降低在 20-30% 範圍之外出現排隊的頻率,以在盡可能接近限制時再開始排隊,同時仍然確保 Waiting Room 做好應對高峰的準備。本部落格稍後將介紹我們如何透過更新配置和計算名額的方式來實現這一目標。
由 Worker 做出這些決定有什麼好處?
上面的範例談到了聖約瑟和德里的 Worker 如何決定是否讓使用者直達源站。在 Worker 層級做出決定的優勢在於,我們可以在不給請求增加任何明顯延遲的情況下做出決定。這是因為,在做出決定時,我們無需離開資料中心來獲取有關 Waiting Room 的資訊,因為我們始終知道資料中心的當前可用狀態。當 Worker 中的名額用完時,就開始排隊。由於沒有增加額外的延遲,客戶可以始終開啟 Waiting Room,而不必擔心使用者會受到額外延遲的影響。
Waiting Room 的首要任務是確保客戶的網站始終保持正常執行,即使面對突如其來的巨大流量也不例外。為此,Waiting Room 優先考慮保持在接近或低於客戶為該房間所設定之流量限制的位置,這一點至關重要。當全球的一個資料中心(例如聖約瑟)出現峰值時,資料中心的當地狀態將需要幾秒鐘才能到達德里。
在 Worker 之間劃分名額可確保在利用稍微過時的資料工作時不會導致嚴重超出總體限制。例如,在聖約瑟資料中心,activeUsers 值可能為 26,而在發生峰值的另一個資料中心,這個值可能為 100。在這個時候,從德里傳送更多的使用者可能不會超出總體限制太多,因為他們在德里只擁有一部分名額。因此,在達到總體限制之前排隊是設計的一部分,可以確保滿足總體限制。在下一節中,我們將介紹我們實施的方法,以在盡可能接近限制時排隊,又不會增加超出流量限制的風險。
當流量相對於 Waiting Room 限制還較低時分配更多名額
我們要解決的第一種情況是當流量距離限制較遠時開始排隊。雖然這種情況很少見,並且對於排隊的最終使用者來說通常會持續一個重新整理間隔(20 秒),但這是我們更新排隊演算法時的首要任務。為了解決這個問題,在分配名額時,我們會考慮使用率(距離流量限制有多遠),並在流量確實距離限制較遠時分配更多名額。這樣做的目的是防止在距離限制較遠時出現排隊的情況,同時還能在源站使用者增多時重新調整每個 Worker 可用的名額。
為了理解這一點,讓我們回顧一下兩個 Worker 的流量不均勻分配的范例。跟我們前面討論過的情況一樣,有下面兩個 Worker。在這種情況下,使用率很低 (10%)。 這意味著我們離限制還很遠。因此,分配的名額數 (8) 更接近聖約瑟資料中心的可用名額數 (10)。 從下圖中可以看出,在修改名額分配後,前往任一 Worker 的全部八個使用者都能造訪網站,因為我們在使用率較低的情況下為每個 Worker 提供了更多的名額。
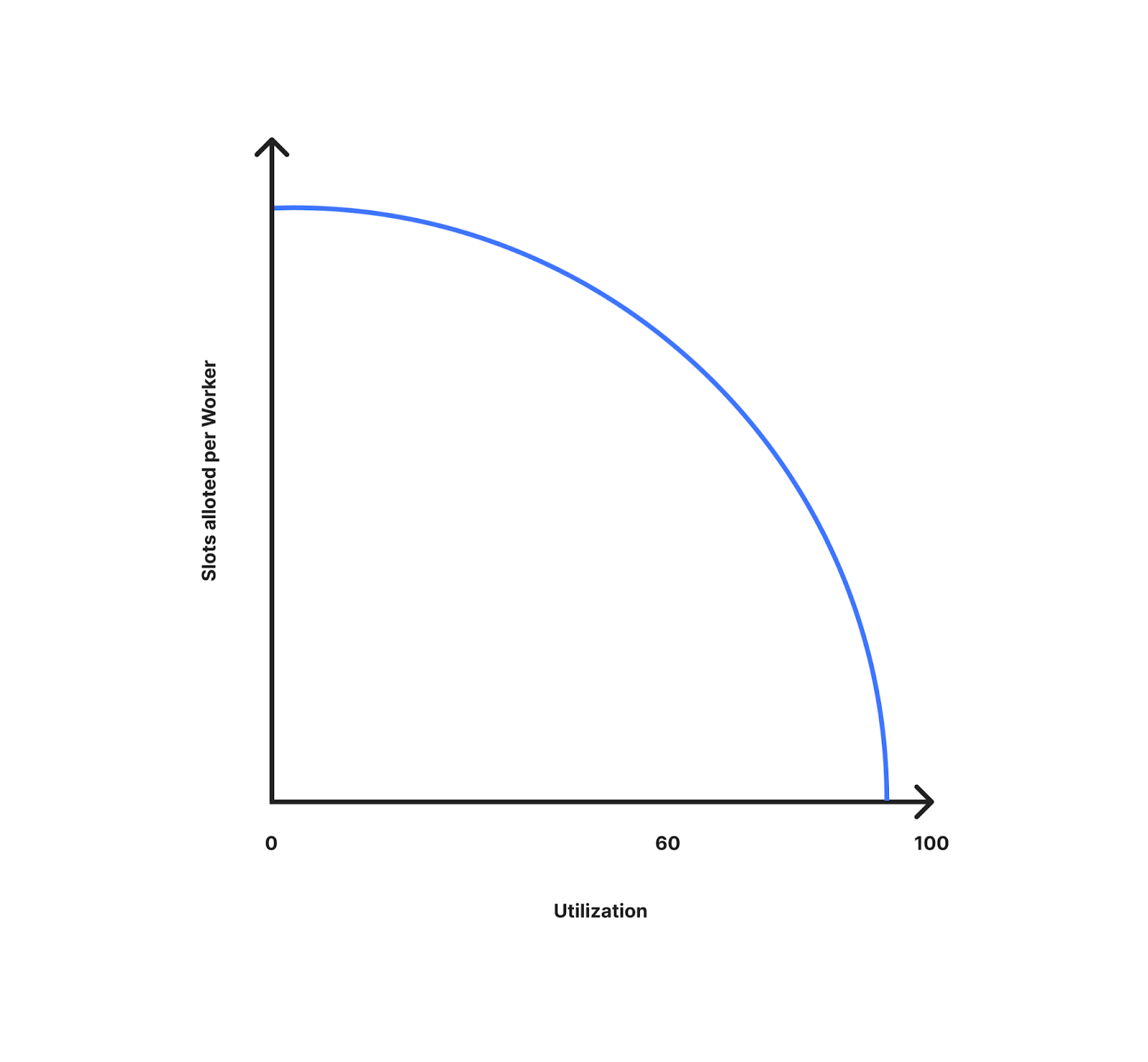
下圖顯示了每個 Worker 配置的名額如何隨使用率(離限制有多遠)的變化而變化。如圖所示,在使用率較低的情況下,我們為每個 Worker 配置了更多名額。隨著使用率的提高,每個 Worker 配置的名額也在減少,因為它越來越接近限制,我們可以更好地為流量高峰做好準備。當使用率為 10% 時,每個 Worker 所獲得的名額將接近資料中心的可用名額。當使用率接近 100% 時,它就接近於可用名額除以資料中心的 Worker 數量。
如何在低使用率時獲得更多名額?
本節將深入探討協助我們實現這一目標的數學知識。如果您對這些細節不感興趣,請前往閱讀「超額佈建的風險」部分。
為了進一步理解這一點,讓我們回顧一下前面的範例:請求到達德里資料中心。activeUsers 值為 50,因此使用率為 50/200,約為 25%。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
我們的想法是使用率水準較低時配置更多名額。這可以確保當流量遠離限制時,客戶不會看到意外的排隊行為。根據當地狀態金鑰,在 Mon, 11 Sep 2023 11:45:54 GMT 時,德里的請求使用率為 25%。
為了在使用率較低時配置更多可用名額,我們新增了一個 workerMultiplier,它與使用率成比例地移動。使用率較低時,乘數較低,使用率較高時,乘數接近於 1。
workerMultiplier = (utilization)^curveFactor
adaptedWorkerCount = actualWorkerCount * workerMultiplier
utilization - 您距離限制有多遠。
curveFactor - curveFactor 是一個可以調整的指數,它決定了我們在 Worker 數量較少的情況下分配額外預算的積極程度。為了理解這一點,讓我們看一下 y = x 和 y = x^2 在值 0 和 1 之間的關係圖。
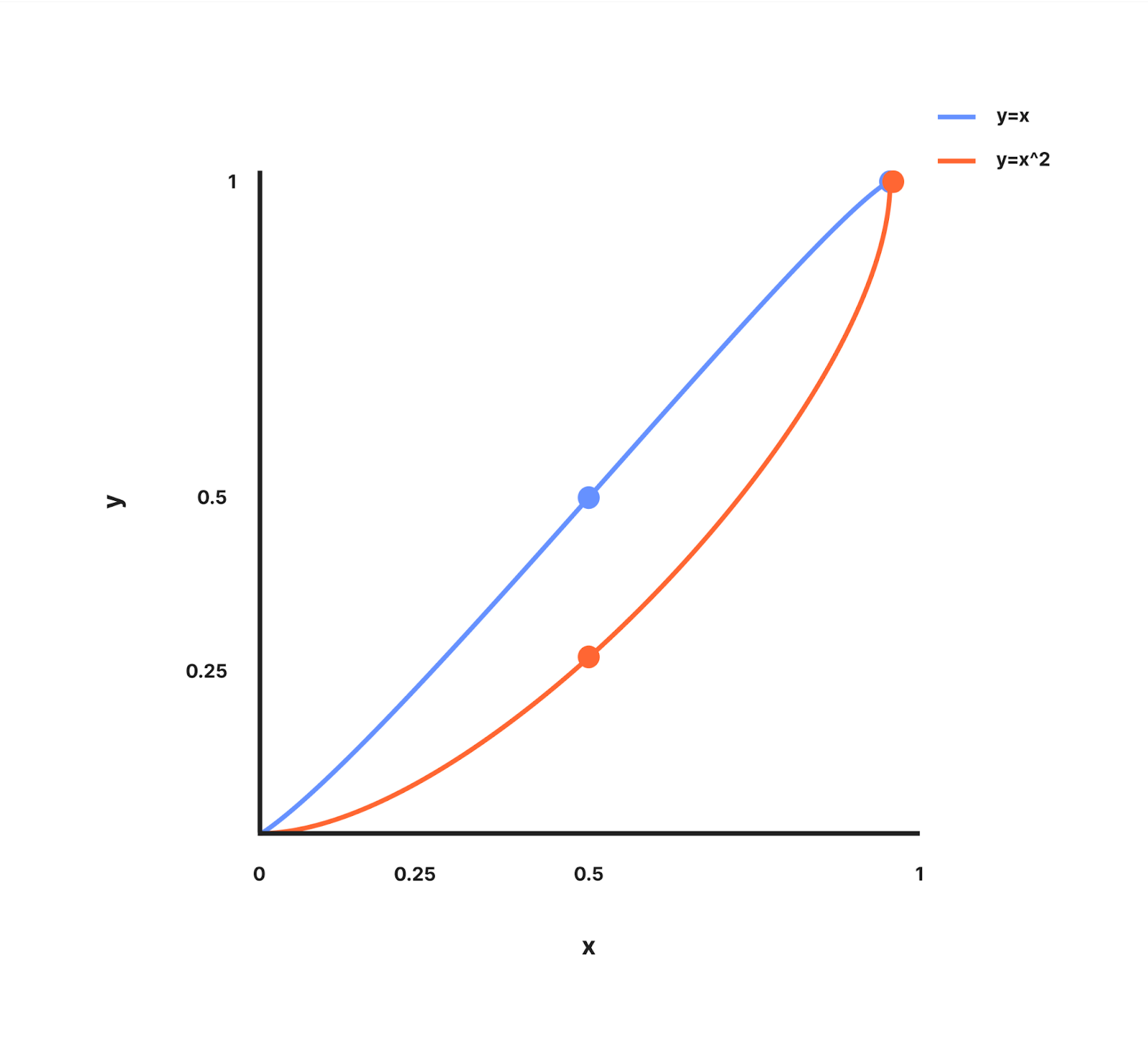
y=x 的圖形是一條經過 (0, 0) 和 (1, 1) 的直線。
y=x^2 的圖形是一條曲線,其中當 x < 1 時,y 的增長速度慢於 x,並且經過 (0, 0) 和 (1, 1)
利用曲線工作原理的概念,我們推導出了workerCountMultiplier 的公式,其中y=workerCountMultiplier,x=utilization,curveFactor 是可以調整的冪,它決定了我們在 Worker 數量較少的情況下分配額外預算的積極程度。當 curveFactor 為 1 時,workerMultiplier 等於使用率。
讓我們回到之前討論的範例,看看曲線因數的值是多少。根據當地狀態金鑰,在 Mon, 11 Sep 2023 11:45:54 GMT 時,德里的請求使用率為 25%。Anywhere 名額在全球所有作用中 Worker 之間劃分,因為世界各地的任何 Worker 都可以分享這塊蛋糕,即剩餘 150 個名額的 75% (113)。
當我們查看 Waiting Room 狀態時,globalWorkersActive 為 10。在這種情況下,我們不會將 113 個名額除以 10,而是除以調整後的 Worker 數,即 globalWorkersActive * workerMultiplier。如果 curveFactor 為 1,則 workerMultiplier 等於 25% 或 0.25 的使用率。
因此,有效 workerCount = 10 * 0.25 = 2.5
這樣,每個作用中 Worker 最多可以傳送 113/2.5,即大約 45 個使用者。在 Mon, 11 Sep 2023 11:45:00 GMT 這一分鐘內到達 Worker 的前 45 個使用者將被允許進入源站,後面的使用者則需要排隊。
因此,在使用率較低時(流量離限制較遠時),每個 Worker 都會獲得更多名額。但是,如果將名額總和相加,則超過總體限制的可能性就更大。
超額佈建的風險
在距離限制較遠時提供更多名額的方法,可以減少在流量遠未達到限制時出現排隊的可能性。然而,在使用率水準較低時,如果世界各地一起發生流量高峰,可能會導致超過預期的使用者數進入源站。下圖顯示了這種情況,而這可能出現問題。如您所見,資料中心可用的名額有十個。在我們之前討論過的使用率為 10% 的情況下,每個 Worker 可以擁有八個名額。如果一個 Worker 中有八個使用者,另一個 Worker 中有七個使用者,那麼就會在資料中心的最大可用名額只有十個的情況下,向該網站傳送了十五個使用者。
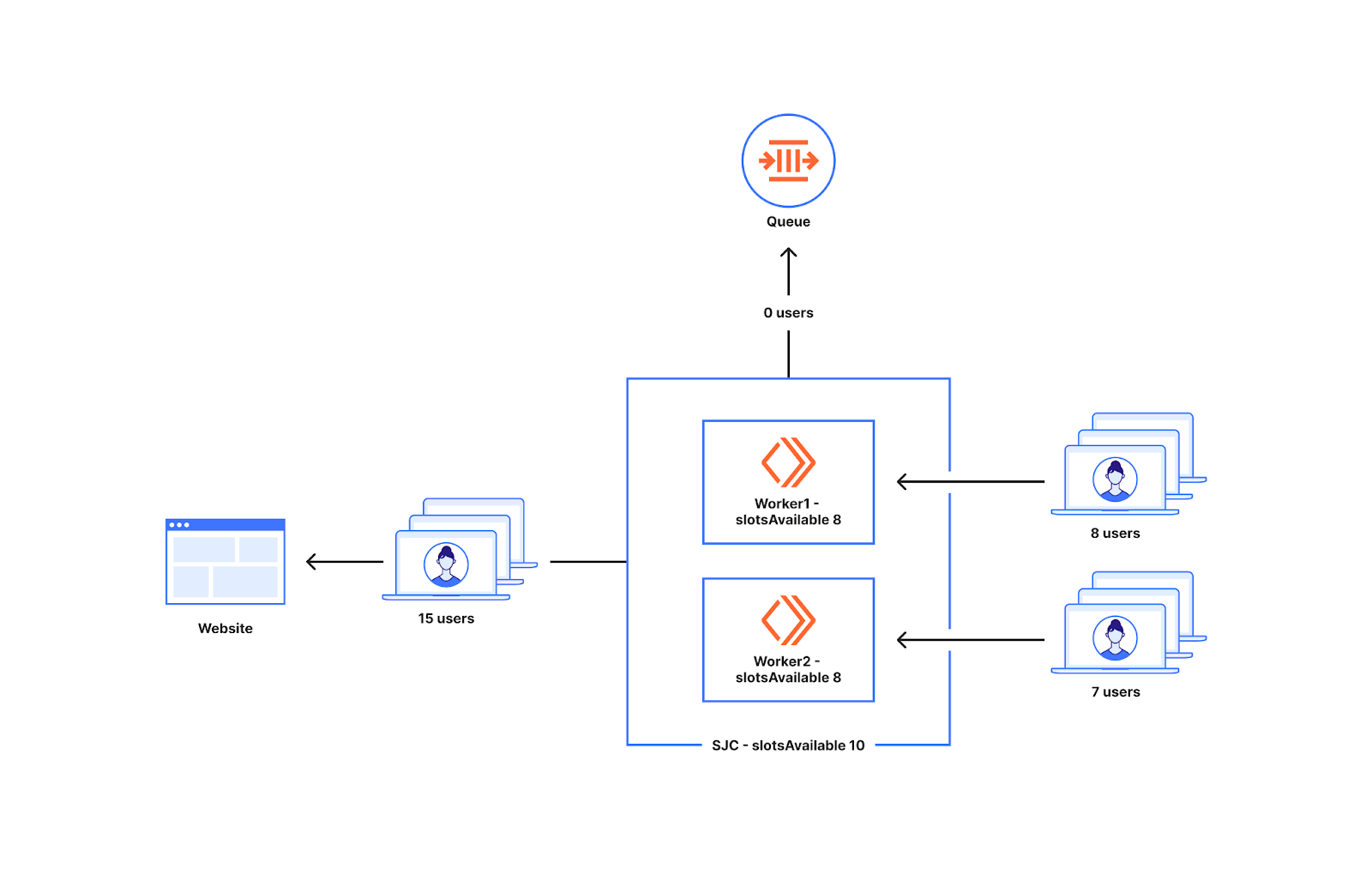
由於我們的客戶和流量類型多種多樣,因此我們能夠看到出現這種問題的情況。從低使用率水準突然進入流量高峰可能會導致超出全域限制。這是因為我們在距離限制較遠時超額佈建,這增加了顯著超出流量限制的風險。我們需要實施一種更安全的方法,既不會導致超出限制,同時還可以減少當流量距離限制較遠時出現排隊的可能性。
退一步思考我們的方法,我們的一個假設是,資料中心的流量與資料中心的 Worker 數量直接相關。實際上,我們發現,並非所有客戶都是如此。即使流量與 Worker 數量相關,但前往資料中心內 Worker 的新使用者可能與 Worker 數量並不相關。這是因為我們分配的名額是給新使用者的,但資料中心的流量既包括已經造訪網站的使用者,也包括試圖造訪網站的新使用者。
在下一節中,我們將討論一種不使用Worker 計數,而是讓 Worker 與資料中心內其他 Worker 進行通訊的方法。為此,我們推出了一項新服務,即 Durable Object 計數器。
透過引入資料中心計數器,減少劃分名額的次數
從上面的範例中,我們可以看到,Worker 層級的超額佈建可能會導致使用的名額數量多於配置給資料中心的名額數量。如果我們不在流量水準較低時超額佈建,就有可能在使用者達到所設定限制之前就出現排隊的情況,這一點我們在前面已經討論過。因此,必須有一種解決方案能夠同時解決這兩個問題。
超額佈建的目的是,當到達一群 Worker 的新使用者數量不均衡時,Worker 不會很快用完名額。如果資料中心的兩個 Worker 之間有辦法進行通訊,我們就不需要根據 Worker 的數量,在資料中心內的 Worker 之間劃分名額。為了實現這種通訊,我們引入了計數器。計數器是一組小型 Durable Object 執行個體,為資料中心的一組 Worker 進行計數。
要瞭解它如何幫助避免使用 Worker 計數,請看下圖。下面有兩個 Worker 在與資料中心計數器對話。就像我們之前討論的那樣,Worker 根據 Waiting Room 狀態讓使用者前往網站。通過的使用者數量儲存在 Worker 的記憶體中。引入計數器後,通過的使用者數量可以儲存在資料中心計數器中。每當有新使用者向 Worker 發出請求時,Worker 就會與計數器對話,以瞭解計數器的當前值。在下面的範例中,當 Worker 收到第一個新請求時,收到的計數器值是 9。在資料中心有 10 個可用名額的情況下,這意味著該使用者可以造訪網站。如果下一個 Worker 收到一個新使用者並在其後發出請求,它將得到計數器值 10,並根據該 Worker 的可用名額,讓該使用者排隊。
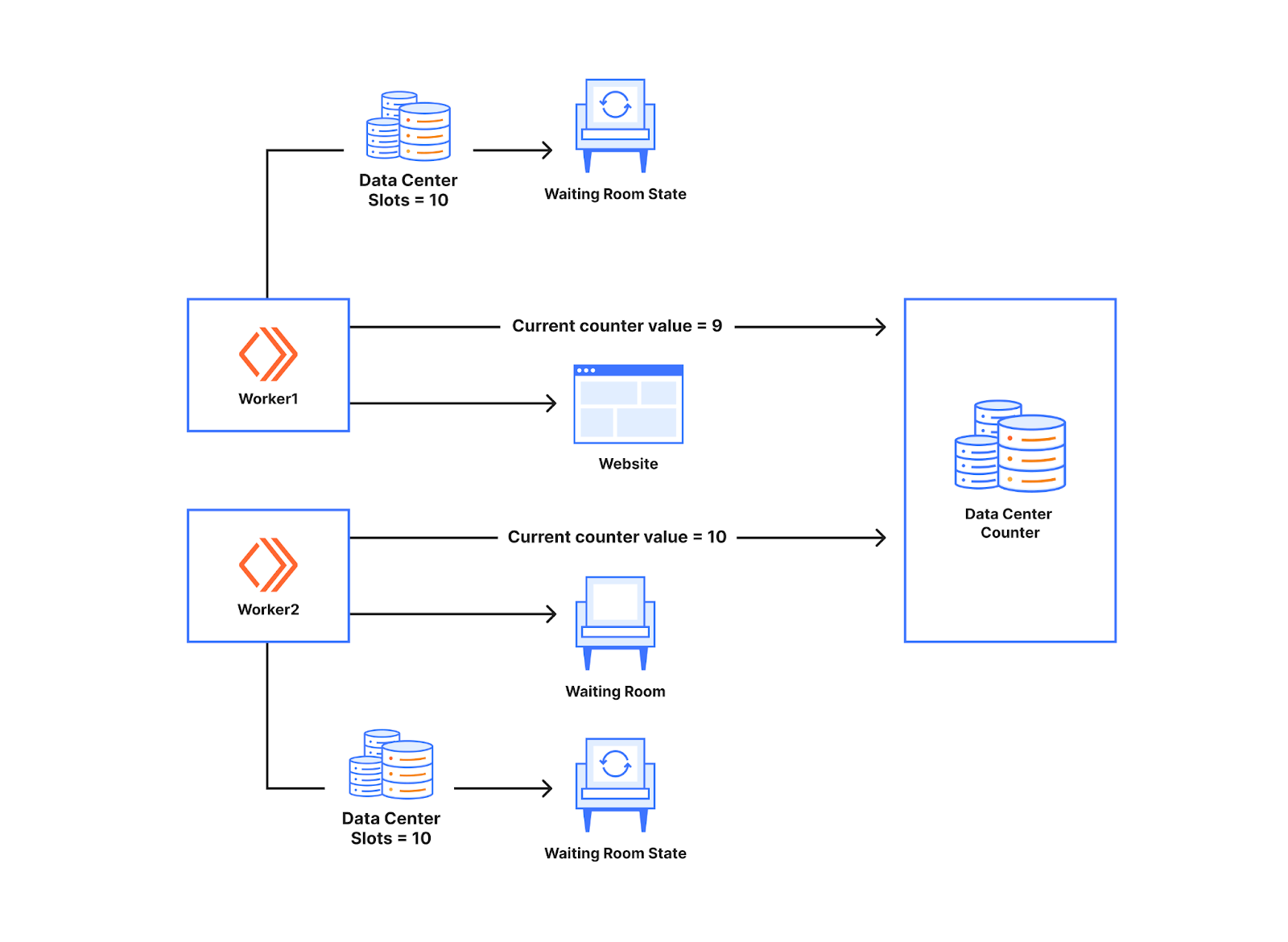
資料中心計數器充當 Waiting Room 中 Worker 的同步點。從本質上講,這使得 Worker 能夠相互對話,但無需真正直接相互對話。這與售票處的工作原理類似。每當一個 Worker 讓某人進入時,他們都會向計數器索取門票,因此另一個向計數器索取門票的 Worker 將不會獲得相同的票號。如果票值有效,新使用者就可以造訪該網站。因此,當不同的 Worker 處出現不同數量的新使用者時,我們不會為一個 Worker 超額配置或配置不足的名額,因為使用的名額數量是由資料中心的計數器計算的。
下圖顯示了當數量不等的新使用者到達 Worker 處時的行為,一個 Worker 有七個新使用者,另一個 Worker 有一個新使用者。下圖中出現在 Worker 處的全部八個使用者都會造訪該網站,因為資料中心的可用名額為十個,而現在低於十個。
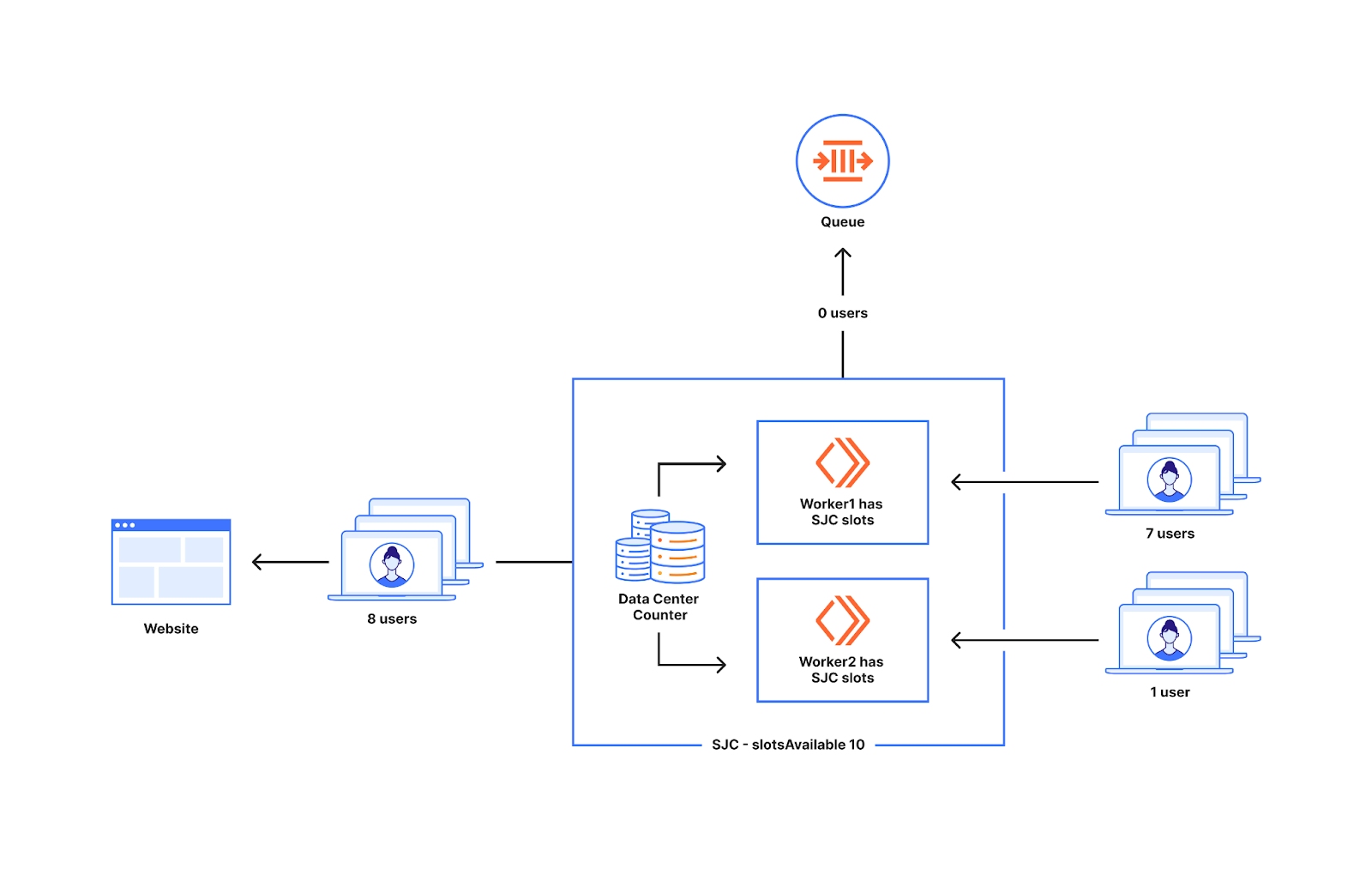
這也不會導致過多的使用者被傳送到網站,因為當計數器值等於資料中心的可用名額時,我們不會再傳送額外的使用者。在下圖中出現在 Worker 處的十五個使用者中,有十個將造訪該網站,另外五個將排隊,這正是我們所期望的。
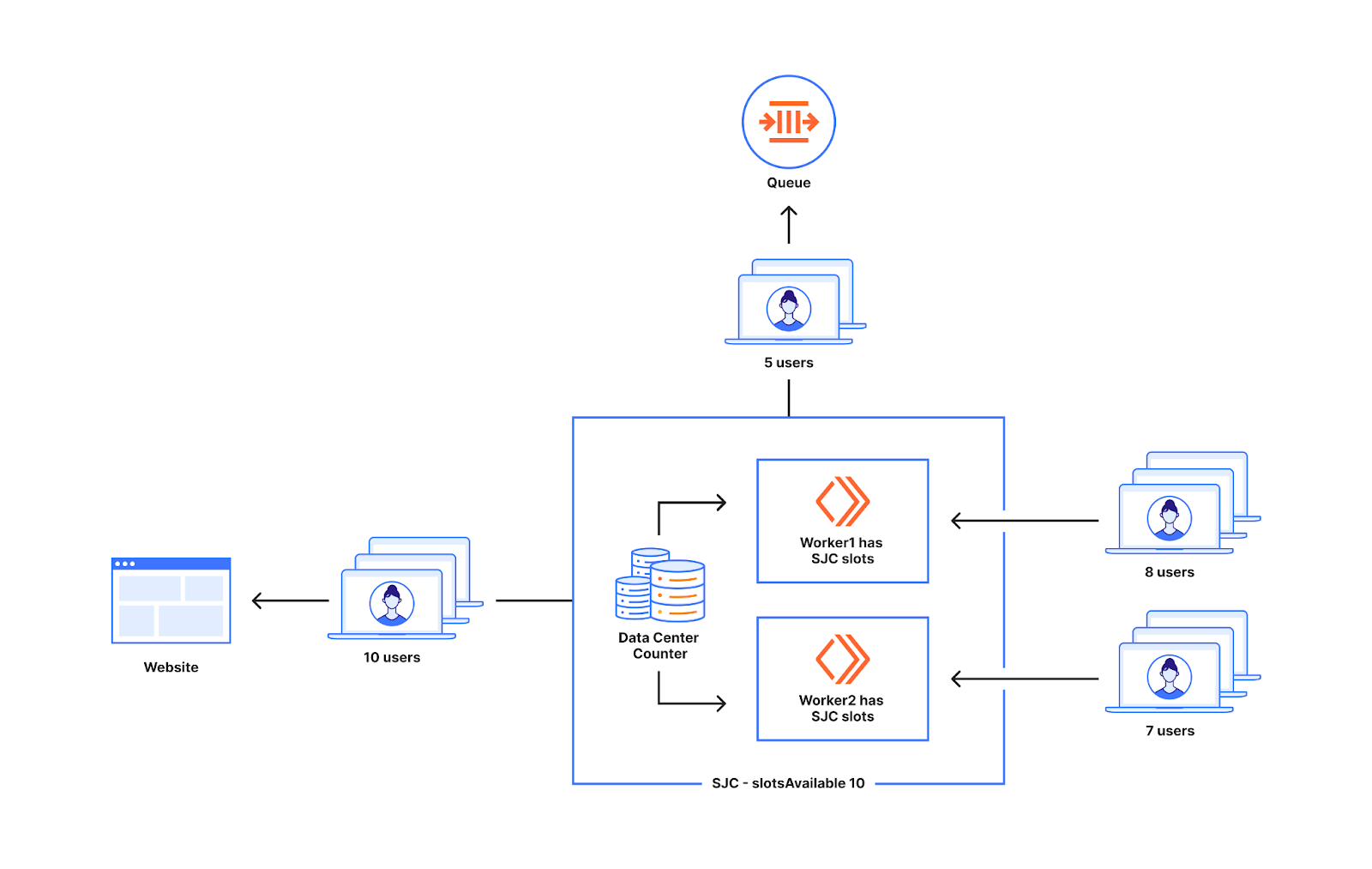
在使用率較低的情況下,也不存在超額佈建的風險,因為計數器可以幫助 Worker 相互通訊
為了進一步理解這一點,讓我們看一下前面談到的範例,看看它是如何與實際的 Waiting Room 狀態配合使用的。
客戶的 Waiting Room 狀態如下。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
目標是不在 Worker 之間劃分名額,這樣我們就不需要使用狀態提供的資訊。在 Mon, 11 Sep 2023 11:45:54 GMT 時,請求到達聖約瑟。因此,我們可以從聖約瑟傳送 150 個可用名額的 10%,即 15 個。
每有一個新使用者到達資料中心,聖約瑟的 Durable Object 計數器就會不斷返回當前的計數器值。返回 Worker 後,數值將遞增 1。因此,前往 Worker 的前 15 個新使用者會得到一個唯一的計數器值。如果針對一個使用者收到的值小於 15,這個使用者就可以使用資料中心的名額。
一旦資料中心的可用名額用完,使用者就可以使用配置給 Anywhere 資料中心的名額,因為這些名額沒有為任何特定資料中心保留。當聖約瑟的 Worker 收到顯示為 15 的計數器值時,它就會意識到不能再使用聖約瑟的名額造訪網站。
Anywhere 名額可供全球所有作用中 Worker 使用,即剩餘 150 個名額中的 75% (113)。Anywhere 名額由一個 Durable Object 處理,來自不同資料中心的 Worker 在想要使用 Anywhere 名額時可以與該 Durable Object 進行對話。即使有 128 (113 + 15) 個使用者最終前往該客戶的同一 Worker,我們也不會讓其進行排隊。這提高了 Waiting Room 處理前往世界各地 Worker 的新使用者數量不均的能力,進而協助客戶在接近所設定限制時才安排使用者排隊。
為什麼計數器對我們很有效?
當我們構建 Waiting Room 時,我們希望在 Worker 層級自行決定是否進入網站,而不是在請求進入網站時與其他服務對話。我們這樣做是為了避免增加使用者請求的延遲。透過在 Durable Object 計數器上引入同步點,我們偏離了這一點,引入了對 Durable Object 計數器的呼叫。
不過,資料中心的 Durable Object 仍在同一資料中心內。這將導致最小的額外延遲,通常小於 10 毫秒。對於處理 Anywhere 資料中心的 Durable Object 的呼叫,Worker 可能需要跨越海洋和長途。在這種情況下,延遲可能會達到 60 或 70 毫秒。下面顯示的第 95 百分位數值較高,因為呼叫會轉到更遠的資料中心。
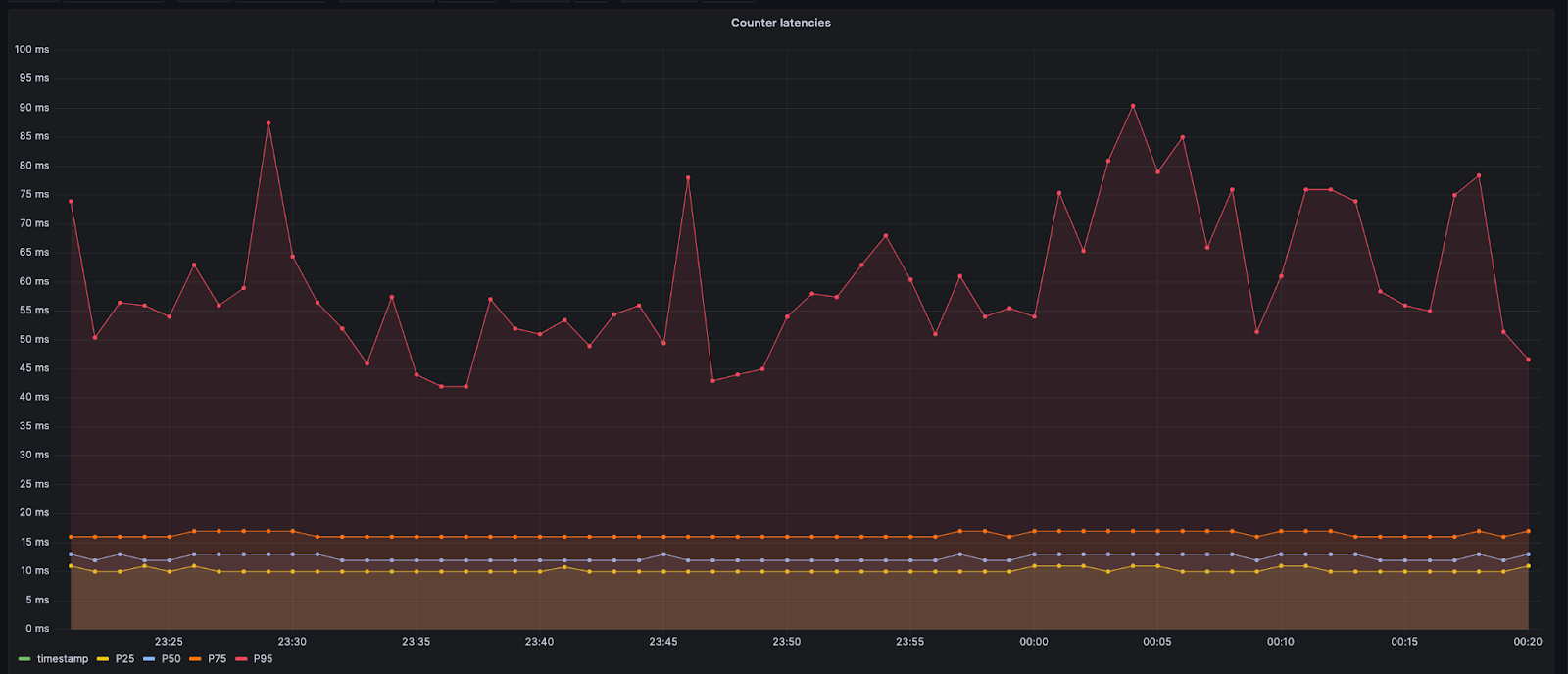
新增計數器的設計決定會給造訪網站的新使用者增加一點額外的延遲。我們認為這種權衡是可以接受的,因為這樣可以減少在達到限制前排隊的使用者數量。此外,只有在新使用者嘗試進入網站時才需要計數器。一旦新使用者到達源站,他們就可以直接從 Worker 處獲得進入許可權,因為可以在客戶附帶的 cookie 中找到進入證明,我們可以根據該證明讓他們進入。
計數器實際上是一種簡單的服務,只進行簡單的計數,不做其他任何事情。這樣,計數器佔用的記憶體和 CPU 空間就非常小。此外,我們還在全球範圍內設立了大量計數器,處理一部分 Worker 之間的協調工作,這有助於計數器成功處理來自 Worker 的同步要求負載。這些因素加在一起,使計數器成為我們使用案例中的一個可行解決方案。
概述
在設計 Waiting Room 時,我們的首要考量是確保客戶的網站保持正常執行,無論合法流量的數量或增長情況如何。Waiting Room 在 Cloudflare 網路中的每台伺服器上執行,該網路覆蓋 100 多個國家的 300 多座城市。我們希望確保在最短時間內為每一個新使用者做出決定,是去網站還是去排隊。這是一個艱難的決定,因為在資料中心排隊太早可能會導致我們排隊的時間早于客戶設定的限制。而排隊太晚又會導致我們超出客戶設定的限制。
我們最初採用的方法是在 Worker 之間平均分配名額,有時排隊時間過早,但在尊重客戶設定的限制方面做得很好。我們的後面一個方法是在低使用率(與客戶限制相比較低的流量水準)時提供更多名額,這很好地解決了在遠早于客戶所設限制時排隊的情況,因為每個 Worker 都有更多的名額可以使用。但正如我們所看到的,當流量在一段低使用率時期後突然激增時,我們更容易超出限制。
有了計數器,我們就可以避免按 Worker 數量來劃分名額,從而獲得兩全其美的效果。利用計數器,我們能夠確保根據客戶設定的限制,不會過早或過晚排隊。這樣做的代價是,新使用者的每個請求都會有一點延遲,但我們發現這種延遲可以忽略不計,而且比提前排隊獲得更好的使用者體驗。
我們不斷改進我們的方法,以確保我們總是在正確的時間讓使用者排隊,以及最重要的是——保護您的網站。隨著越來越多的客戶使用 Waiting Room,我們對不同類型的流量有了更多的瞭解,這有助於產品更好地服務於每個人。