
大约三年前,我们推出了 Cloudflare Waiting Room,以保护客户的网站免受合法流量剧增的冲击,这种流量剧增可能导致其网站瘫痪。Waiting Room 让客户即使在高流量时也能控制用户体验,将多余的流量放置在可定制的品牌 Waiting Room 中,并在网站上有空位时动态接纳用户。自 Waiting Room 推出以来,我们根据客户的反馈不断扩展其功能,如移动应用支持、分析、Waiting Room 绕过规则等 。
我们很喜欢发布新功能,并通过扩展Waiting Room 的功能为客户解决问题。但今天,我们想给您一个幕后的视角,让您了解我们如何发展产品的核心机制,即它如何启动流量队列以响应流量高峰。
Waiting Room 是如何建成的以及面临哪些挑战?
下图显示了 Waiting Room 在客户网站启用后的位置概览。
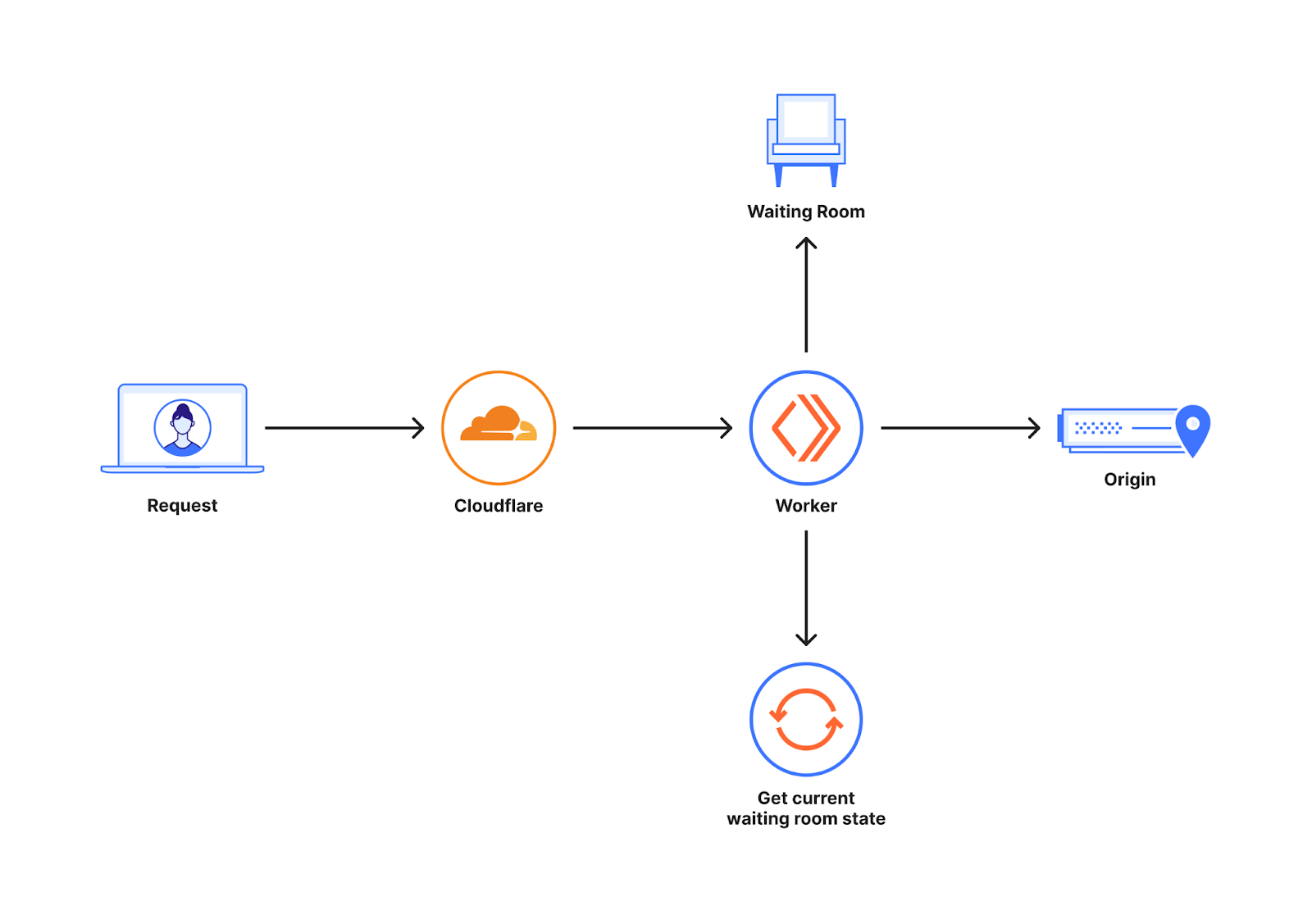
Waiting Room 建立在跨 Cloudflare 数据中心全球网络运行的 Workers 之上。对客户网站的请求可能会转到许多不同的 Cloudflare 数据中心。为了优化以减少延迟和提高性能,这些请求会被路由到地理位置最接近的数据中心。当新用户向 Waiting Room 覆盖的主机/路径发出请求时,Waiting Room Worker 会决定是将用户发送到源站还是 Waiting Room。这一决定是利用 Waiting Room 状态做出的,Waiting Room 状态可提供源站上有多少用户的信息。
Waiting Room 的状态会根据世界各地的流量不断变化。这些信息可以存储在一个中央位置,或者最终可以在世界各地传播更改。将这些信息存储在一个中心位置,会大大增加每次请求的延迟时间,因为中心位置可能离请求发出地非常遥远。因此,每个数据中心都有自己的 Waiting Room 状态,这是该时间点全球可用网站流量模式的快照。在让用户进入网站之前,我们不想等待来自世界其他地方的信息,因为这会显著增加请求的延迟时间。这就是我们选择不设立中心位置,而是通过管道将流量变化最终传播到世界各地的原因。
这个在后台汇总 Waiting Room 状态的管道基于 Cloudflare Durable Objects 构建。2021 年,我们撰写了一篇博客,介绍了汇总管道的工作原理以及我们在其中采取的不同设计决策,如果您感兴趣,可阅读这篇文章。该管道可确保每个数据中心在几秒钟内获得有关流量变化的最新信息。
Waiting Room 必须根据当前看到的状态决定是将用户发送到网站或还是让他们排队。必须在确保在正确的时间让用户排队,以免客户的网站超载。我们还必须确保不会因为误认为出现流量高峰而让用户过早排队。排队可能会导致一些用户放弃访问该网站。Waiting Room 在 Cloudflare 网络中的每台服务器上运行,该网络覆盖 100 多个国家/地区的 300 多个城市。我们希望确保,在决定每个新用户是直接访问网站还是排队时,能够将延迟降到最低。这也正是何时排队成为 Waiting Room 难题的原因。在本博客中,我们将介绍如何进行这种权衡。我们的算法不断发展,以减少误报,同时继续尊重客户设定的限制。
Waiting Room 如何决定何时让用户排队
决定 Waiting Room 何时开始排队的最重要因素是您配置流量设置的方式。配置 Waiting Room 时,您将设置两个流量限制:活跃用户总数和每分钟新用户数。活跃用户总数是您希望在 Waiting Room 覆盖的页面上允许多少并发用户数的目标阈值。每分钟新用户数定义了每分钟用户涌入网站的最大速率的目标阈值。这两个值中任何一个的急剧上升都可能导致排队。影响我们计算活跃用户总数的另一个配置是会话持续时间。由于请求是向 Waiting Room 覆盖的任何页面发出的,因此用户在会话持续时间分钟内被视为处于活动状态。
下图来自我们为客户提供的一个内部监控工具,显示了客户两天内的流量模式。该客户将其每分钟新用户数和活跃用户总数限制分别设置为 200 和 200。
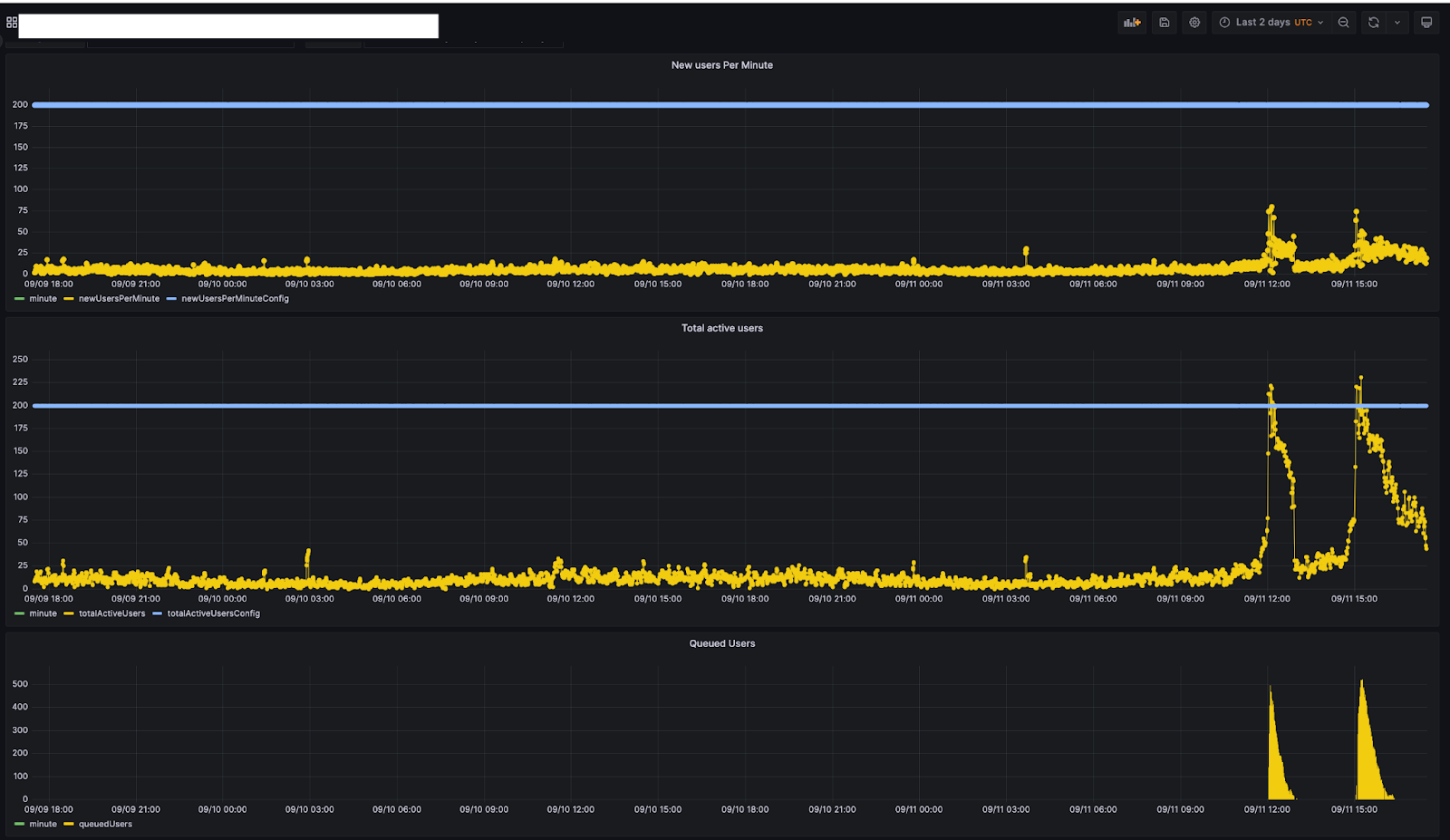
如果查看他们的流量,会发现用户在 9 月 11 日 11:45 左右排队。当时,活跃用户总数约为 200 人左右。随着活跃用户总数逐渐下降(12:30 左右),排队用户逐渐减少到 0。9 月 11 日 15:00 左右,活跃用户总数达到 200 时,再次开始排队。此时让用户排队,确保了访问该网站的流量在客户设置的限制范围内。
一旦用户获得网站访问权,我们就会向他们提供一个加密的 cookie,表明他们已经获得访问权限。cookie 的内容可能如下所示。
{
"bucketId": "Mon, 11 Sep 2023 11:45:00 GMT",
"lastCheckInTime": "Mon, 11 Sep 2023 11:45:54 GMT",
"acceptedAt": "Mon, 11 Sep 2023 11:45:54 GMT"
}
cookie 就像一张门票,表明 Waiting Room 的入口。bucketId 表明该用户属于哪个用户集群。acceptedAt 时间和 lastCheckInTime 表明最后一次与 Workers 交互的时间。当我们将其与客户在配置 Waiting Room 时设置的会话持续时间值进行比较时,该信息可以表明门票是否能够有效打开入口。如果 cookie 有效,我们会让用户通过,以确保网站上的用户继续能够浏览网站。如果 cookie 无效,我们会创建一个新的 cookie,将用户视为新用户,如果网站上发生排队,他们会排到队列的后面。在下一节中,我们会介绍如何决定让这些用户进行排队。
为了进一步理解这一点,让我们来看看Waiting Room 状态的内容。对于我们上面讨论的客户,在 "Mon, 11 Sep 2023 11:45:54 GMT" 时,状态可能如下所示。
{
"activeUsers": 50,
}
如上所述,客户配置的每分钟新用户数和活跃用户总数分别为 200 和 200。
因此,该状态表明,还有空间留给新用户,因为只有 50 个活跃用户,而活跃用户可以达到 200 个。因此,还可以再容纳 150 个用户。假设这 50 个用户分别来自圣何塞(20 个用户)和伦敦(30 个用户)这两个数据中心。我们还跟踪全球范围内活跃的 Worker 数量以及计算状态的数据中心的活跃 Worker 数量。圣何塞可能计算得出下面的状态密钥。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
试想一下,在 "Mon, 11 Sep 2023 11:45:54 GMT" 这个时间,我们收到一个请求,前往圣何塞数据中心的 Waiting Room。
要查看到达圣何塞的用户是否能前往源站,我们首先要查看过去一分钟的流量历史记录,以了解当时的流量分布情况。这是因为很多网站在世界的某些地方很受欢迎。很多网站的流量往往来自相同的数据中心。
查看 "Mon, 11 Sep 2023 11:44:00 GMT" 这一分钟的流量历史记录,我们可以看到当时圣何塞的 200 个用户中,有 20 个用户前往该网站 (10%)。对于当前时间 "Mon, 11 Sep 2023 11:45:54 GMT",我们按照过去一分钟流量历史记录的相同比例分配网站可用的名额。因此,我们可以从圣何塞发送 150 个可用名额的 10%,即 15 个用户。我们还知道,有三个活跃的 Worker,因为 "dataCenterWorkersActive" 为 3。
数据中心可用的名额数量在数据中心的 Worker 之间平均分配。因此,圣何塞的每个 Worker 都可以向该网站发送 15/3 的用户。如果接收流量的 Worker 在当前分钟内未向源站发送任何用户,则它们最多可以发送五个用户 (15/3)。
同时 ("Mon, 11 Sep 2023 11:45:54 GMT"),假设有一个请求发送到德里的数据中心。德里数据中心的 Worker 检查了流量历史记录,发现没有为其分配名额。对于这样的流量,我们保留了 Anywhere 名额,因为我们距离所设置的限制确实还有很多的空间。
{
"activeUsers":50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Anywhere 名额在全球所有活跃 Worker 之间分配,相当于世界各地的任何 Worker 都可以分享这块蛋糕。剩余 150 个名额的 75%,即 113 个。
状态密钥还跟踪在世界各地产生的 Worker 数量 (globalWorkersActive)。分配的 Anywhere 名额将分配给世界上所有活跃的 Worker(如果有)。当我们查看 Waiting Room 状态时,globalWorkersActive 为 10。因此,每个活跃 Worker 最多可以发送 113/10,即大约 11 个用户。因此,在 Mon, 11 Sep 2023 11:45:00 GMT 这一分钟内到达 Worker 的前 11 位用户将被允许进入源站。后面的用户需要排队。之前讨论过的圣何塞会在 Mon, 11 Sep 2023 11:45:00 GMT 这一分钟额外保留 5 个名额,确保我们可以允许来自圣何塞的 Worker 最多 16 (5 + 11) 个用户访问该网站。
在 Worker 级别排队可能会导致用户在数据中心可用名额用完之前排队
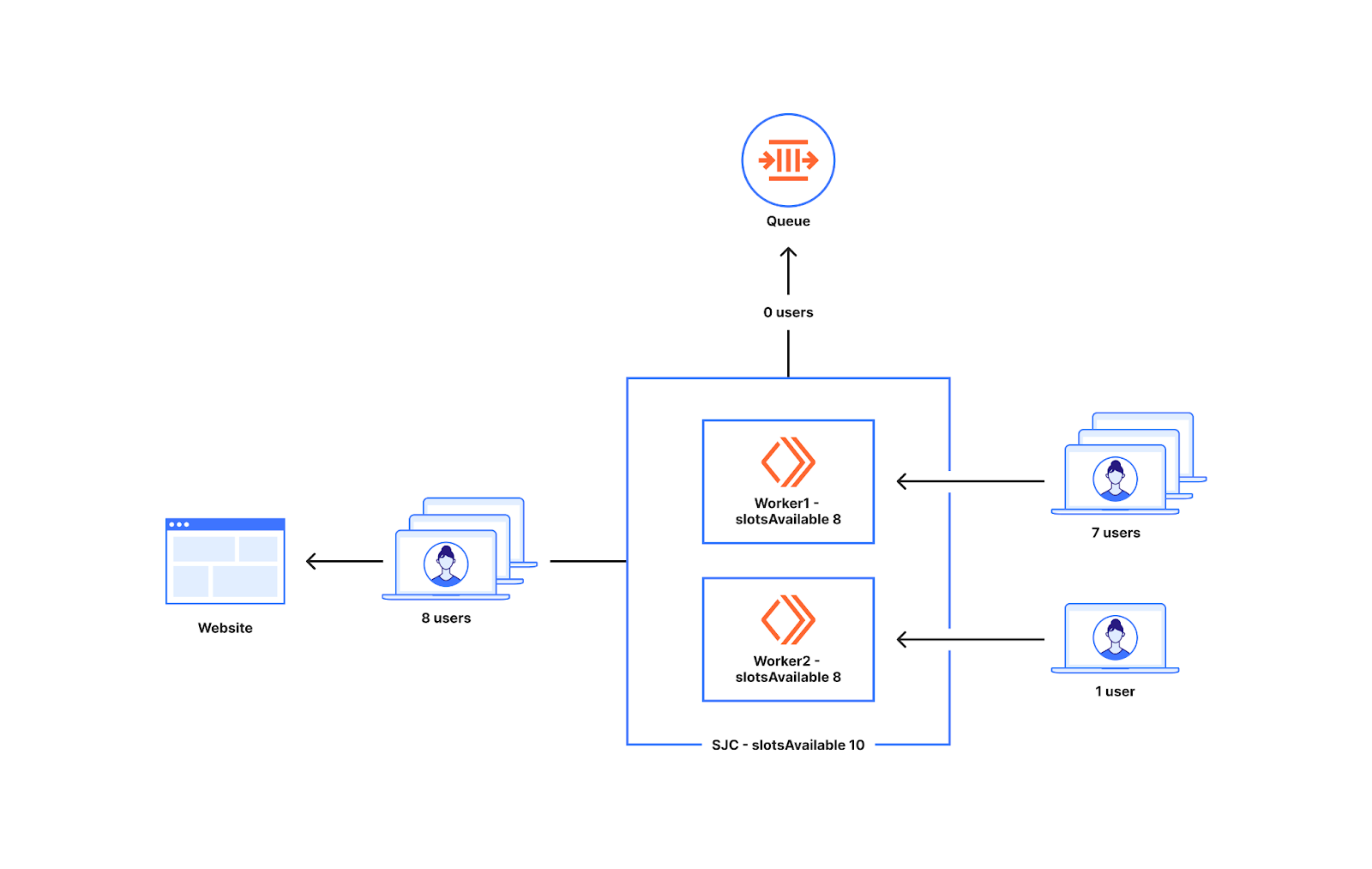
从上面的例子可以看出,我们是在 Worker 级别决定是否排队的。前往世界各地 Worker 的新用户数量可能并不相同。为了了解两个 Worker 的流量分布不均匀时会发生什么情况,让我们看看下图。
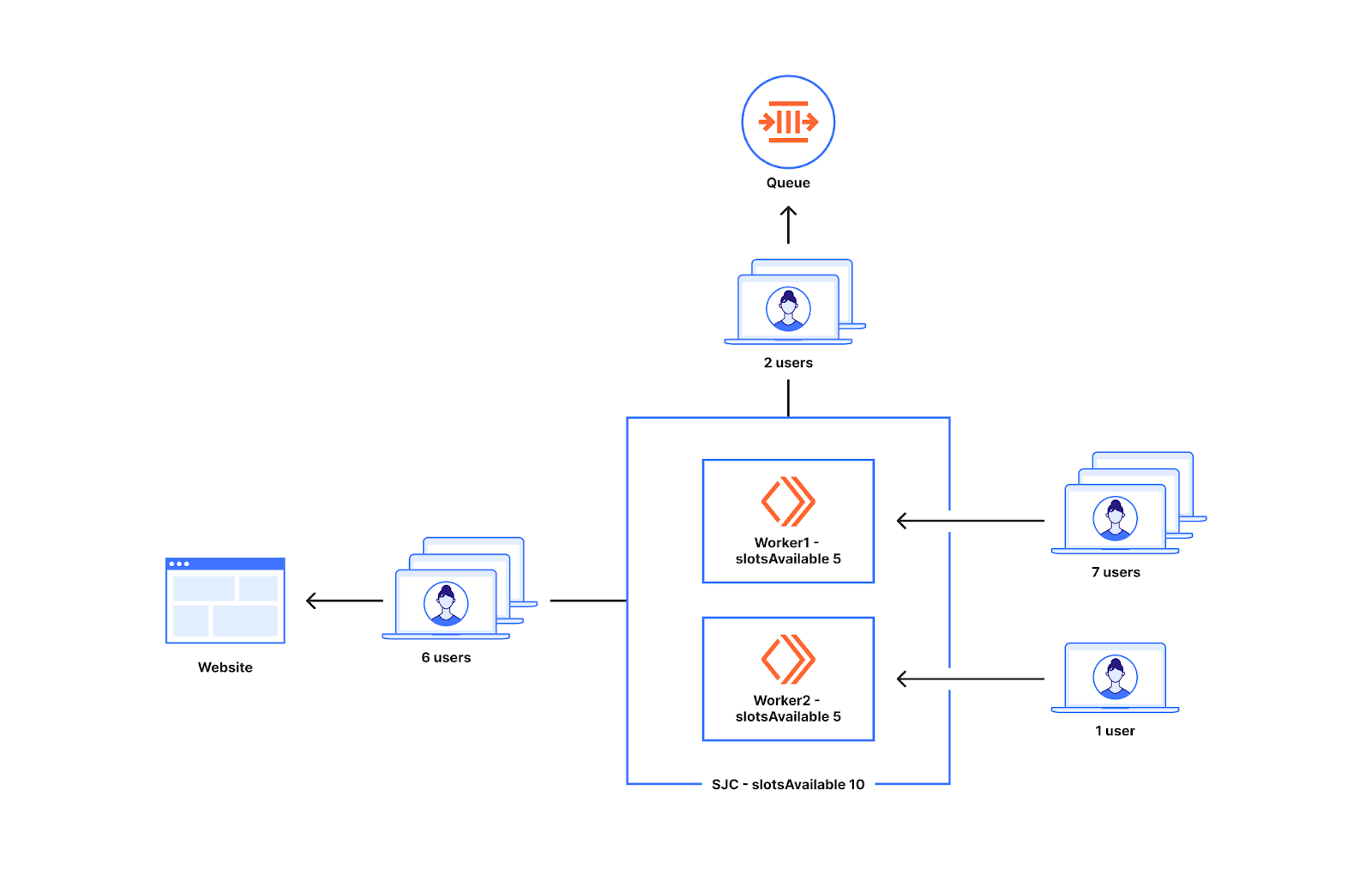
想象一下,圣何塞数据中心的可用名额有十个。有两个 Worker 在圣何塞运行。七个用户前往 worker1,一个用户前往 worker2。在这种情况下,worker1 会让七个用户中的五个进入网站,其中两个人会排队,因为 worker1 只有五个可用名额。前往 worker2 的一个用户也可以转到源站。因此,实际上可以从圣何塞数据中心发送十个用户,但在只出现了八个用户时,我们却让两个用户进行了排队。
这种方式虽然在 Worker 之间平均分配了名额,但也导致在达到 Waiting Room 配置的流量限制之前进行排队,通常在所设置限制的 20-30% 范围内。我们接下来将讨论这种方法的优点。我们已经对这种方法进行了修改,以降低在 20-30% 范围之外出现排队的频率,以在尽可能接近限制时再开始排队,同时仍然确保 Waiting Room 做好应对高峰的准备。本博客稍后将介绍我们如何通过更新分配和计算名额的方式来实现这一目标。
由 Worker 做出这些决定有什么好处?
上面的例子谈到了圣何塞和德里的 Worker 如何决定是否让用户直达源站。在 Worker 级别做出决定的优势在于,我们可以在不给请求增加任何明显延迟的情况下做出决定。这是因为,在做出决定时,我们无需离开数据中心来获取有关 Waiting Room 的信息,因为我们始终知道数据中心的当前可用状态。当 Worker 中的名额用完时,就开始排队。由于没有增加额外的延迟,客户可以始终开启 Waiting Room,而不必担心用户会受到额外延迟的影响。
Waiting Room 的首要任务是确保客户的网站始终保持正常运行,即使面对突如其来的巨大流量也不例外。为此,Waiting Room 优先考虑保持在接近或低于客户为该房间所设置之流量限制的位置,这一点至关重要。当全球的一个数据中心(例如圣何塞)出现峰值时,数据中心的当地状态将需要几秒钟才能到达德里。
在 Worker 之间划分名额可确保在利用稍微过时的数据工作时不会导致严重超出总体限制。例如,在圣何塞数据中心,activeUsers 值可能为 26,而在发生峰值的另一个数据中心,这个值可能为 100。在这个时候,从德里发送更多的用户可能不会超出总体限制太多,因为他们在德里只拥有一部分名额。因此,在达到总体限制之前排队是设计的一部分,可以确保满足总体限制。在下一节中,我们将介绍我们实施的方法,以在尽可能接近限制时排队,又不会增加超出流量限制的风险。
当流量相对于 Waiting Room 限制还较低时分配更多名额
我们要解决的第一种情况是当流量距离限制较远时开始排队。虽然这种情况很少见,并且对于排队的最终用户来说通常会持续一个刷新间隔(20 秒),但这是我们更新排队算法时的首要任务。为了解决这个问题,在分配名额时,我们会考虑利用率(距离流量限制有多远),并在流量确实距离限制较远时分配更多名额。这样做的目的是防止在距离限制较远时出现排队的情况,同时还能在源站用户增多时重新调整每个 Worker 可用的名额。
为了理解这一点,让我们回顾一下两个 Worker 的流量不均匀分配的示例。跟我们前面讨论过的情况一样,有下面两个 Worker。在这种情况下,利用率很低 (10%)。这意味着我们离限制还很远。因此,分配的名额数 (8) 更接近圣何塞数据中心的可用名额数 (10)。从下图中可以看出,在修改名额分配后,前往任一 Worker 的全部八个用户都能访问网站,因为我们在利用率较低的情况下为每个 Worker 提供了更多的名额。
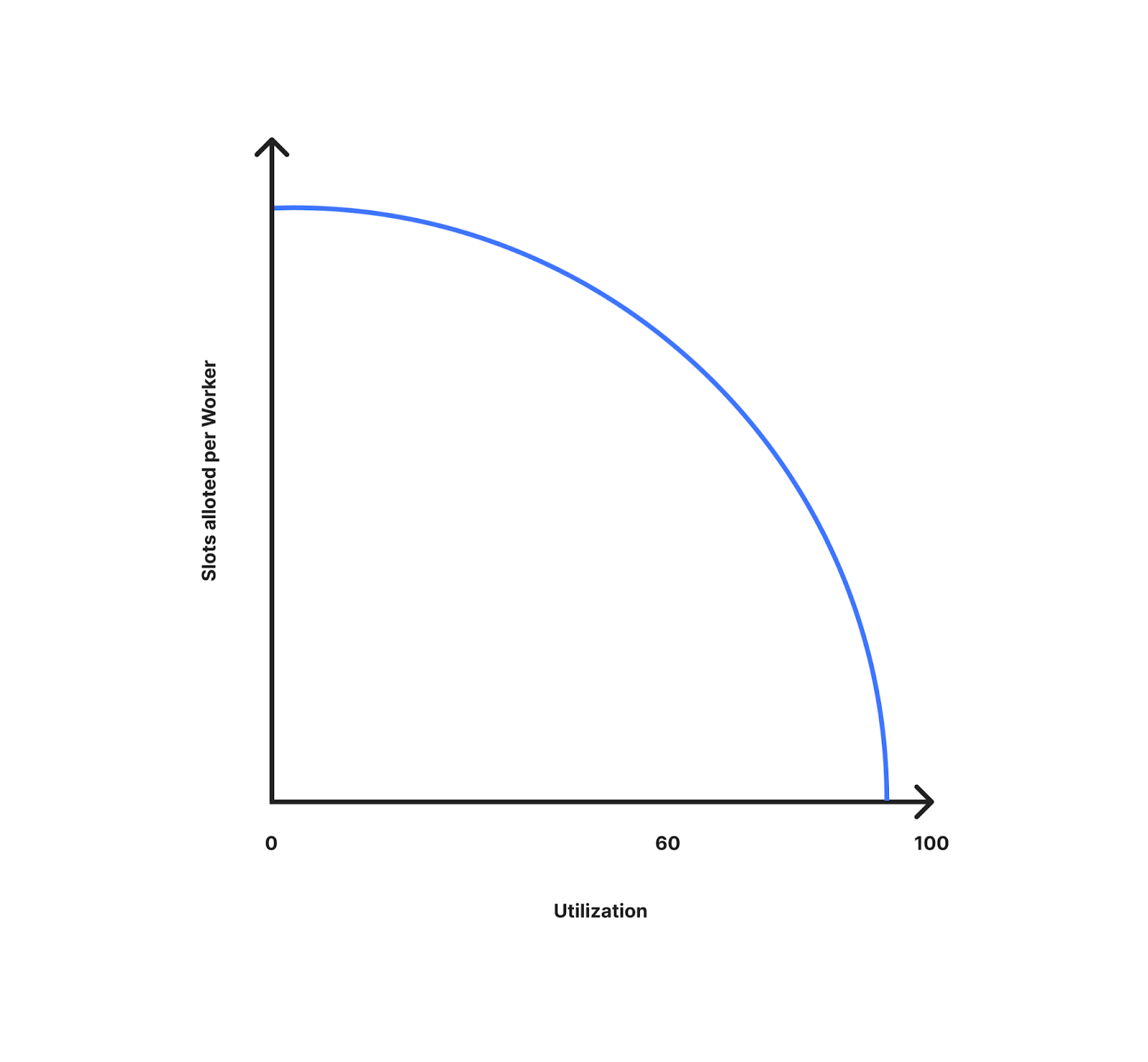
下图显示了每个 Worker 分配的名额如何随利用率(离限制有多远)的变化而变化。如图所示,在利用率较低的情况下,我们为每个 Worker 分配了更多名额。随着利用率的提高,每个 Worker 分配的名额也在减少,因为它越来越接近限制,我们可以更好地为流量高峰做好准备。当利用率为 10% 时,每个 Worker 所获得的名额将接近数据中心的可用名额。当利用率接近 100% 时,它就接近于可用名额除以数据中心的 Worker 数量。
如何在低利用率时获得更多名额?
本节将深入探讨帮助我们实现这一目标的数学知识。如果您对这些细节不感兴趣,请前往阅读“超额配置的风险”部分。
为了进一步理解这一点,让我们回顾一下前面的示例:请求到达德里数据中心。activeUsers 值为 50,因此利用率为 50/200,约为 25%。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
我们的想法是利用率水平较低时分配更多名额。这可以确保当流量远离限制时,客户不会看到意外的排队行为。根据当地状态密钥,在 Mon, 11 Sep 2023 11:45:54 GMT 时,德里的请求利用率为 25%。
为了在利用率较低时分配更多可用名额,我们添加了一个 workerMultiplier,它与利用率成比例地移动。利用率较低时,乘数较低,利用率较高时,乘数接近于 1。
workerMultiplier = (utilization)^curveFactor
adaptedWorkerCount = actualWorkerCount * workerMultiplier
utilization - 您距离限制有多远。
curveFactor - curveFactor 是一个可以调整的指数,它决定了我们在 Worker 数量较少的情况下分配额外预算的积极程度。为了理解这一点,让我们看一下 y = x 和 y = x^2 在值 0 和 1 之间的关系图。
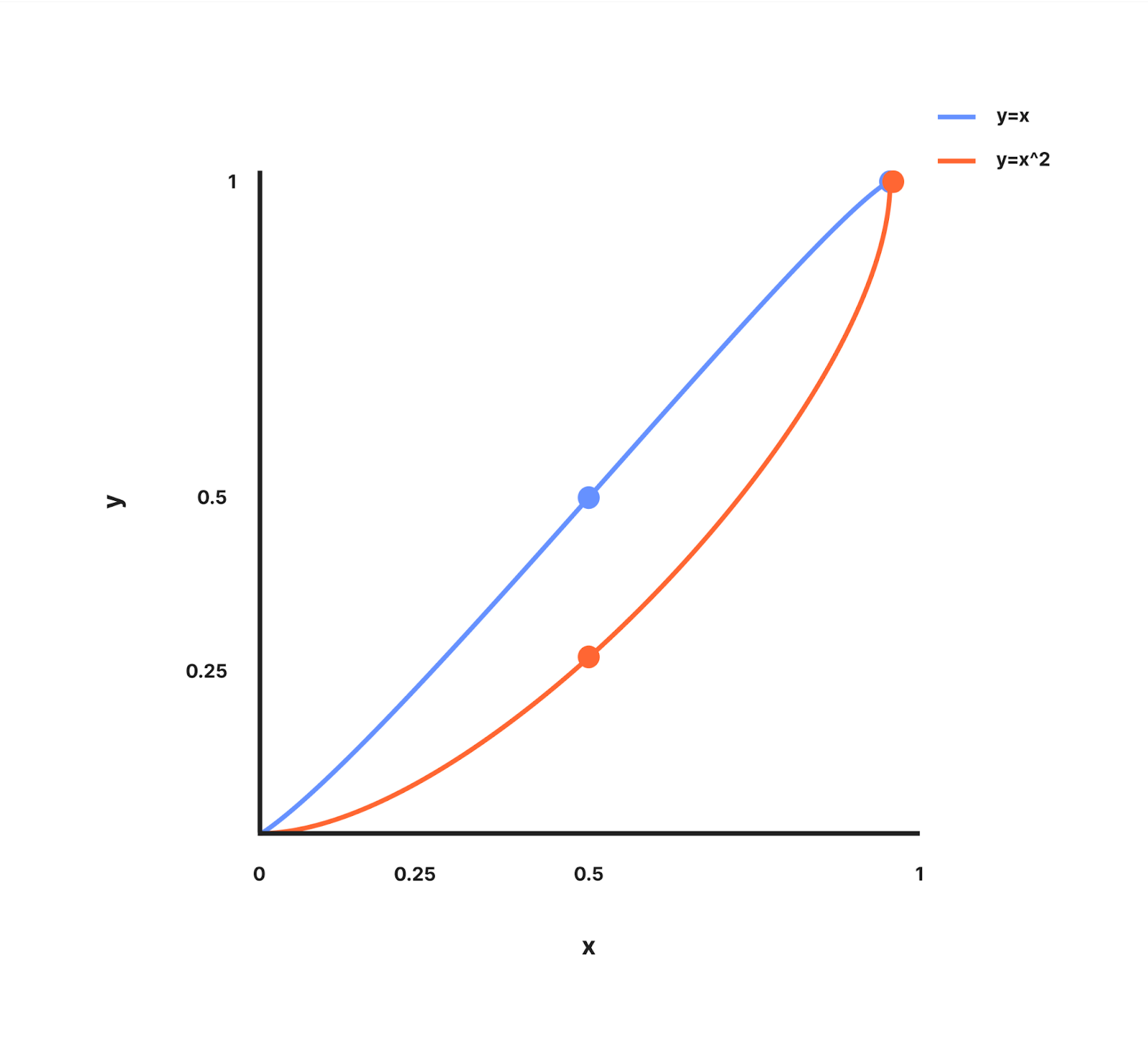
y=x 的图形是一条经过 (0, 0) 和 (1, 1) 的直线。
y=x^2 的图形是一条曲线,其中当 x < 1 时,y 的增长速度慢于 x,并且经过 (0, 0) 和 (1, 1)
利用曲线工作原理的概念,我们推导出了workerCountMultiplier 的公式,其中y=workerCountMultiplier,x=utilization,curveFactor 是可以调整的幂,它决定了我们在 Worker 数量较少的情况下分配额外预算的积极程度。当 curveFactor 为 1 时,workerMultiplier 等于利用率。
让我们回到之前讨论的例子,看看曲线因子的值是多少。根据当地状态密钥,在 Mon, 11 Sep 2023 11:45:54 GMT 时,德里的请求利用率为 25%。Anywhere 名额在全球所有活跃 Worker 之间划分,因为世界各地的任何 Worker 都可以分享这块蛋糕,即剩余 150 个名额的 75% (113)。
当我们查看 Waiting Room 状态时,globalWorkersActive 为 10。在这种情况下,我们不会将 113 个名额除以 10,而是除以调整后的 Worker 数,即 globalWorkersActive * workerMultiplier。如果 curveFactor 为 1,则 workerMultiplier 等于 25% 或 0.25 的利用率。
因此,有效 workerCount = 10 * 0.25 = 2.5
这样,每个活跃 Worker 最多可以发送 113/2.5,即大约 45 个用户。在 Mon, 11 Sep 2023 11:45:00 GMT 这一分钟内到达 Worker 的前 45 个用户将被允许进入源站,后面的用户则需要排队。
因此,在利用率较低时(流量离限制较远时),每个 Worker 都会获得更多名额。但是,如果将名额总和相加,则超过总体限制的可能性就更大。
超额配置的风险
在距离限制较远时提供更多名额的方法,可以减少在流量远未达到限制时出现排队的可能性。然而,在利用率水平较低时,如果世界各地一起发生流量高峰,可能会导致超过预期的用户数进入源站。下图显示了这种情况,而这可能出现问题。如您所见,数据中心可用的名额有十个。在我们之前讨论过的利用率为 10% 的情况下,每个 Worker 可以拥有八个名额。如果一个 Worker 中有八个用户,另一个 Worker 中有七个用户,那么就会在数据中心的最大可用名额只有十个的情况下,向该网站发送了十五个用户。
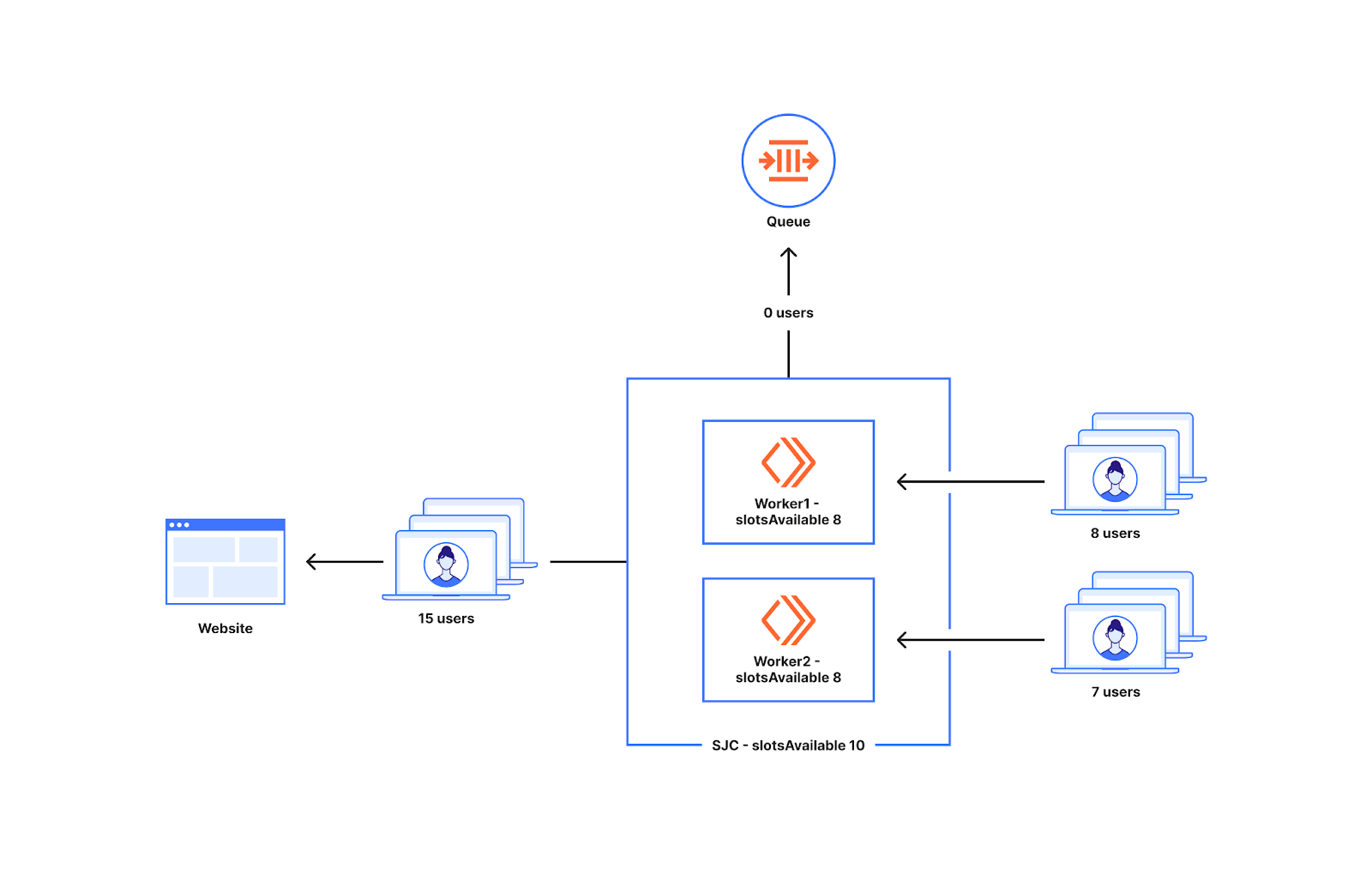
由于我们的客户和流量类型多种多样,因此我们能够看到出现这种问题的情况。从低利用率水平突然进入流量高峰可能会导致超出全局限制。这是因为我们在距离限制较远时超额配置,这增加了显着超出流量限制的风险。我们需要实施一种更安全的方法,既不会导致超出限制,同时还可以减少当流量距离限制较远时出现排队的可能性。
退一步思考我们的方法,我们的一个假设是,数据中心的流量与数据中心的 Worker 数量直接相关。实际上,我们发现,并非所有客户都是如此。即使流量与 Worker 数量相关,但前往数据中心内 Worker 的新用户可能与 Worker 数量并不相关。这是因为我们分配的名额是给新用户的,但数据中心的流量既包括已经访问网站的用户,也包括试图访问网站的新用户。
在下一节中,我们将讨论一种不使用Worker 计数,而是让 Worker 与数据中心内其他 Worker 进行通信的方法。为此,我们推出了一项新服务,即 Durable Object 计数器。
通过引入数据中心计数器,减少划分名额的次数
从上面的示例中,我们可以看到,Worker 级别的超额配置可能会导致使用的名额数量多于分配给数据中心的名额数量。如果我们不在流量水平较低时超额配置,就有可能在用户达到配置限制之前就出现排队的情况,这一点我们在前面已经讨论过。因此,必须有一种解决方案能够同时解决这两个问题。
超额配置的目的是,当到达一群 Worker 的新用户数量不均衡时,Worker 不会很快用完名额。如果数据中心的两个 Worker 之间有办法进行通信,我们就不需要根据 Worker 的数量,在数据中心内的 Worker 之间划分名额。为了实现这种通信,我们引入了计数器。计数器是一组小型 Durable Object 实例,为数据中心的一组 Worker 进行计数。
要了解它如何帮助避免使用 Worker 计数,请看下图。下面有两个 Worker 在与数据中心计数器对话。就像我们之前讨论的那样,Worker 根据 Waiting Room 状态让用户前往网站。通过的用户数量存储在 Worker 的内存中。引入计数器后,通过的用户数量可以存储在数据中心计数器中。每当有新用户向 Worker 发出请求时,Worker 就会与计数器对话,以了解计数器的当前值。在下面的示例中,当 Worker 收到第一个新请求时,收到的计数器值是 9。在数据中心有 10 个可用名额的情况下,这意味着该用户可以访问网站。如果下一个 Worker 收到一个新用户并在其后发出请求,它将得到计数器值 10,并根据该 Worker 的可用名额,让该用户排队。
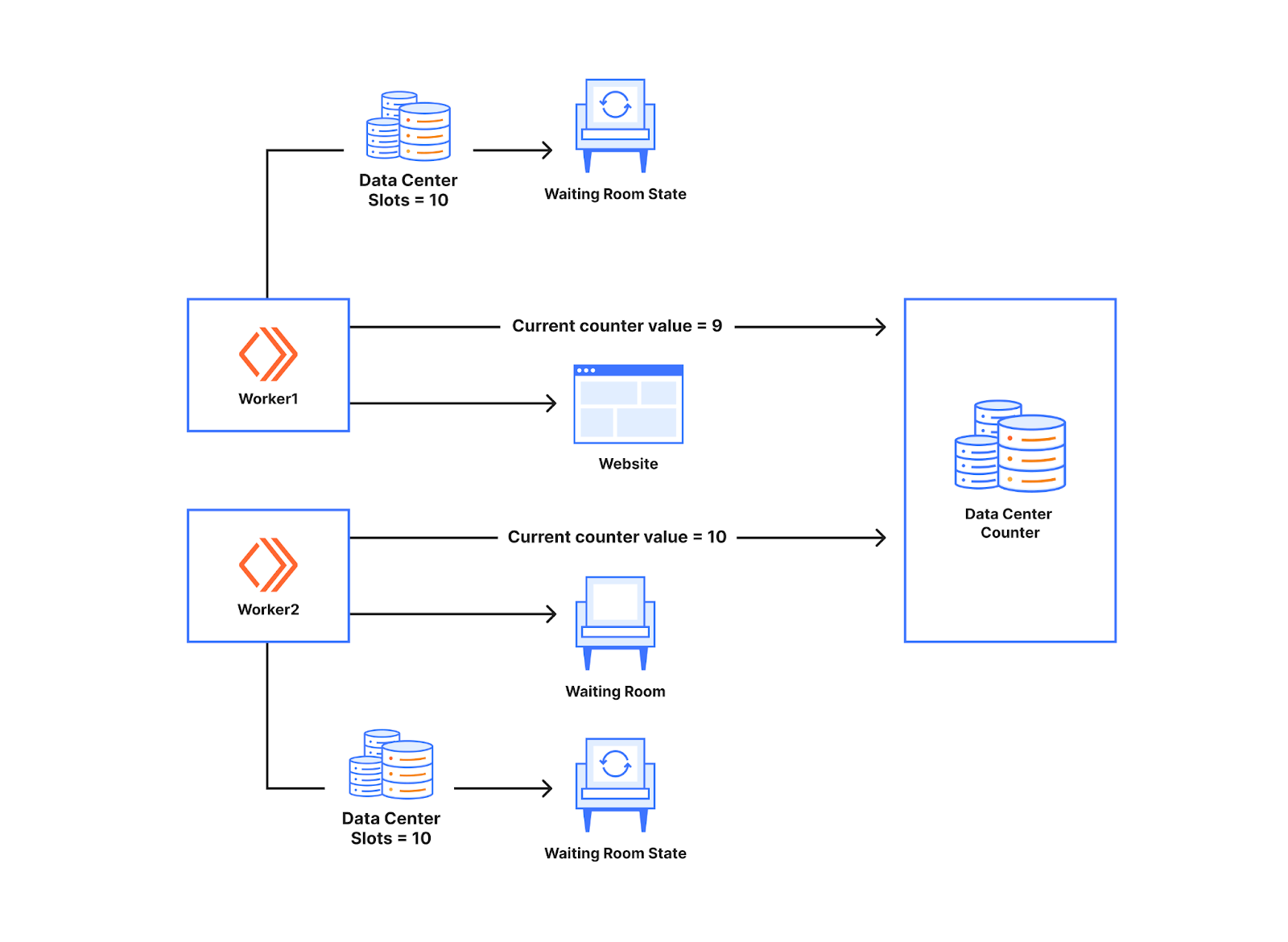
数据中心计数器充当 Waiting Room 中 Worker 的同步点。从本质上讲,这使得 Worker 能够相互对话,但无需真正直接相互对话。这与售票处的工作原理类似。每当一个 Worker 让某人进入时,他们都会向计数器索取门票,因此另一个向计数器索取门票的 Worker 将不会获得相同的票号。如果票值有效,新用户就可以访问该网站。因此,当不同的 Worker 处出现不同数量的新用户时,我们不会为一个 Worker 超额分配或分配不足的名额,因为使用的名额数量是由数据中心的计数器计算的。
下图显示了当数量不等的新用户到达 Worker 处时的行为,一个 Worker 有七个新用户,另一个 Worker 有一个新用户。下图中出现在 Worker 处的全部八个用户都会访问该网站,因为数据中心的可用名额为十个,而现在低于十个。
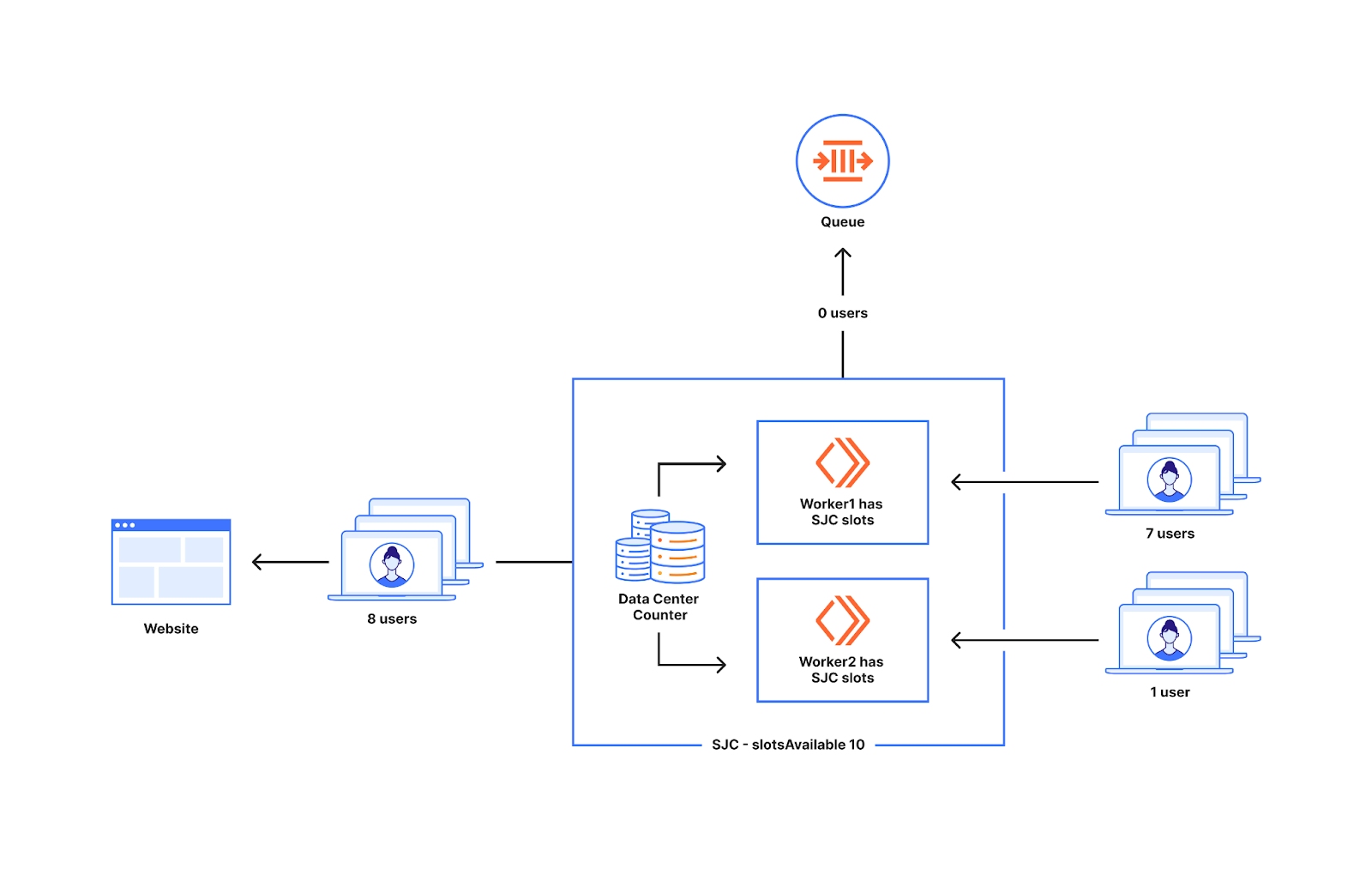
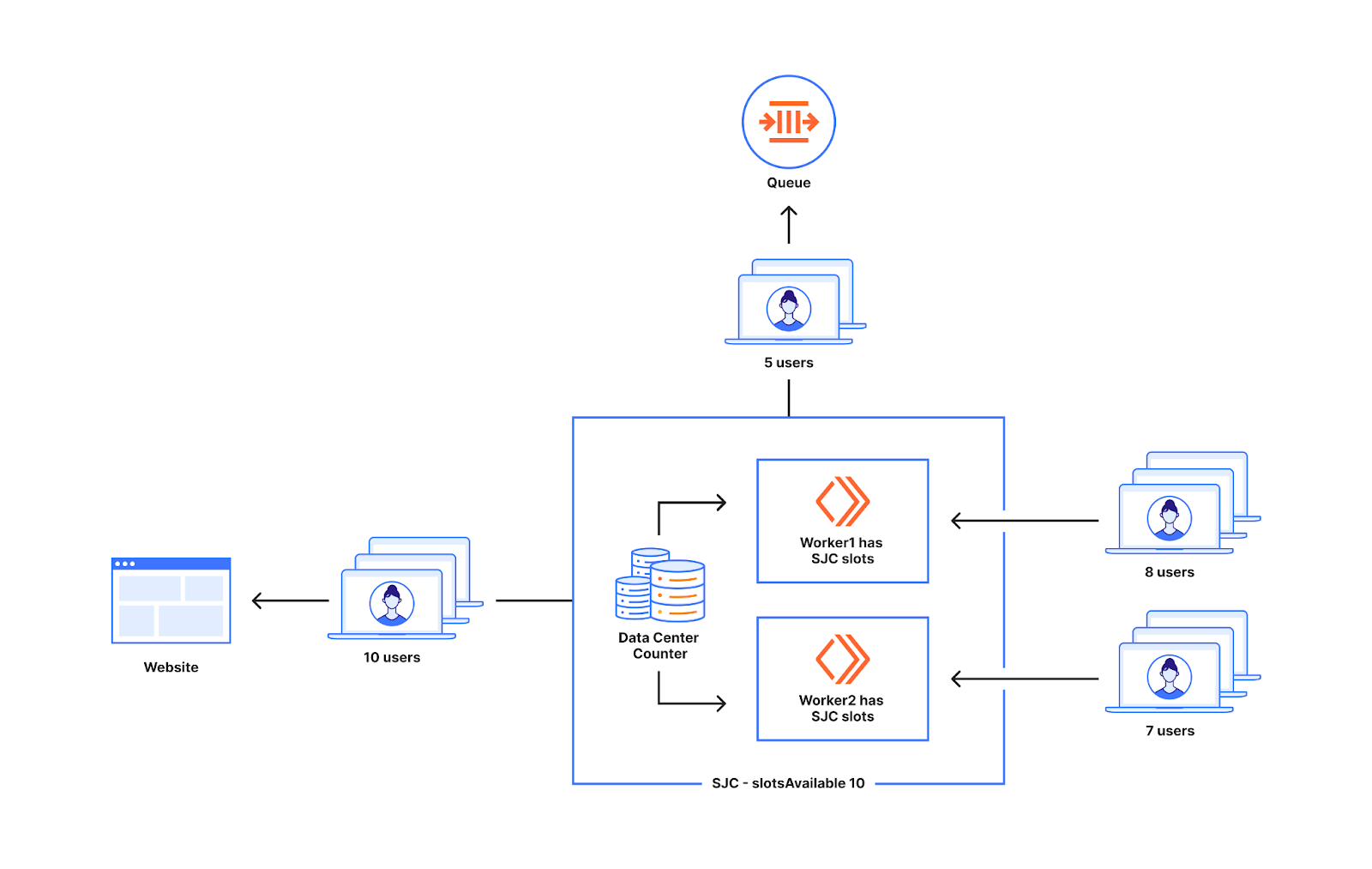
这也不会导致过多的用户被发送到网站,因为当计数器值等于数据中心的可用名额时,我们不会再发送额外的用户。在下图中出现在 Worker 处的十五个用户中,有十个将访问该网站,另外五个将排队,这正是我们所期望的。
在利用率较低的情况下,也不存在超额配置的风险,因为计数器可以帮助 Worker 相互通信
为了进一步理解这一点,让我们看一下前面谈到的例子,看看它是如何与实际的 Waiting Room 状态配合使用的。
客户的 Waiting Room 状态如下。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
目标是不在 Worker 之间划分名额,这样我们就不需要使用状态提供的信息。在 Mon, 11 Sep 2023 11:45:54 GMT 时,请求到达圣何塞。因此,我们可以从圣何塞发送 150 个可用名额的 10%,即 15 个。
每有一个新用户到达数据中心,圣何塞的 Durable Object 计数器就会不断返回当前的计数器值。返回 Worker 后,数值将递增 1。因此,前往 Worker 的前 15 个新用户会得到一个唯一的计数器值。如果针对一个用户收到的值小于 15,这个用户就可以使用数据中心的名额。
一旦数据中心的可用名额用完,用户就可以使用分配给 Anywhere 数据中心的名额,因为这些名额没有为任何特定数据中心保留。当圣何塞的 Worker 收到显示为 15 的计数器值时,它就会意识到不能再使用圣何塞的名额访问网站。
Anywhere 名额可供全球所有活跃 Worker 使用,即剩余 150 个名额中的 75% (113)。Anywhere 名额由一个 Durable Object 处理,来自不同数据中心的 Worker 在想要使用 Anywhere 名额时可以与该 Durable Object 进行对话。即使有 128 (113 + 15) 个用户最终前往该客户的同一 Worker,我们也不会让其进行排队。这提高了 Waiting Room 处理前往世界各地 Worker 的新用户数量不均的能力,进而帮助客户在接近所配置限制时才安排用户排队。
为什么计数器对我们很有效?
当我们构建 Waiting Room 时,我们希望在 Worker 级别自行决定是否进入网站,而不是在请求进入网站时与其他服务对话。我们这样做是为了避免增加用户请求的延迟。通过在 Durable Object 计数器上引入同步点,我们偏离了这一点,引入了对 Durable Object 计数器的调用。
不过,数据中心的 Durable Object 仍在同一数据中心内。这将导致最小的额外延迟,通常小于 10 毫秒。对于处理 Anywhere 数据中心的 Durable Object 的调用,Worker 可能需要跨越海洋和长途。在这种情况下,延迟可能会达到 60 或 70 毫秒。下面显示的第 95 百分位数值较高,因为调用会转到更远的数据中心。
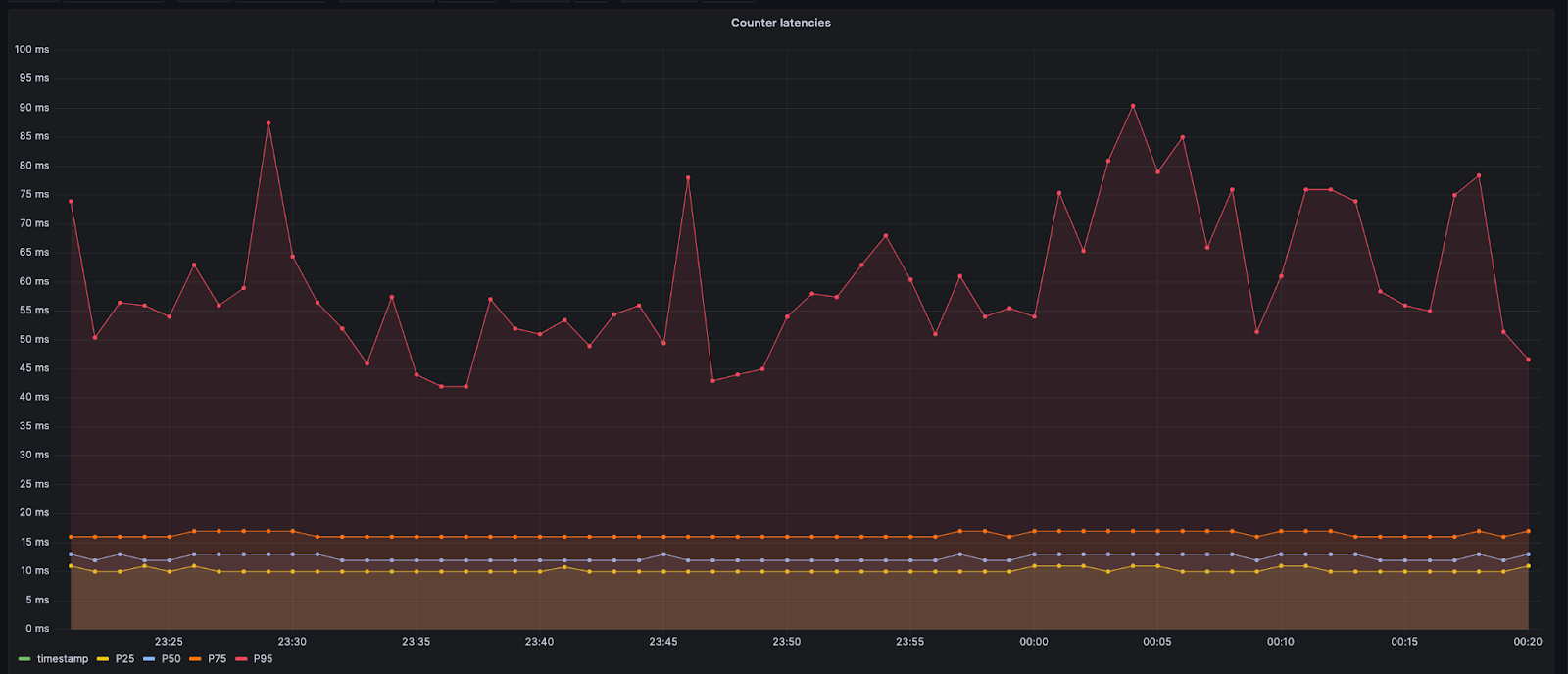
添加计数器的设计决定会给访问网站的新用户增加一点额外的延迟。我们认为这种权衡是可以接受的,因为这样可以减少在达到限制前排队的用户数量。此外,只有在新用户尝试进入网站时才需要计数器。一旦新用户到达源站,他们就可以直接从 Worker 处获得进入权限,因为可以在客户附带的 cookie 中找到进入证明,我们可以根据该证明让他们进入。
计数器实际上是一种简单的服务,只进行简单的计数,不做其他任何事情。这样,计数器占用的内存和 CPU 空间就非常小。此外,我们还在全球范围内设立了大量计数器,处理一部分 Worker 之间的协调工作,这有助于计数器成功处理来自 Worker 的同步要求负载。这些因素加在一起,使计数器成为我们使用案例中的一个可行解决方案。
摘要
在设计 Waiting Room 时,我们的首要考量是确保客户的网站保持正常运行,无论合法流量的数量或增长情况如何。Waiting Room 在 Cloudflare 网络中的每台服务器上运行,该网络覆盖 100 多个国家的 300 多座城市。我们希望确保在最短时间内为每一个新用户做出决定,是去网站还是去排队。这是一个困难的决定,因为在数据中心排队太早可能会导致我们排队的时间早于客户设置的限制。而排队太晚又会导致我们超出客户设置的限制。
我们最初采用的方法是在 Worker 之间平均分配名额,有时排队时间过早,但在尊重客户设置的限制方面做得很好。我们的后面一个方法是在低利用率(与客户限制相比较低的流量水平)时提供更多名额,这很好地解决了在远早于客户所设限制时排队的情况,因为每个 Worker 都有更多的名额可以使用。但正如我们所看到的,当流量在一段低利用率时期后突然激增时,我们更容易超出限制。
有了计数器,我们就可以避免按 Worker 数量来划分名额,从而获得两全其美的效果。利用计数器,我们能够确保根据客户设置的限制,不会过早或过晚排队。这样做的代价是,新用户的每个请求都会有一点延迟,但我们发现这种延迟可以忽略不计,而且比提前排队获得更好的用户体验。
我们不断改进我们的方法,以确保我们总是在正确的时间让用户排队,以及最重要的是——保护您的网站。随着越来越多的客户使用 Waiting Room,我们对不同类型的流量有了更多的了解,这有助于产品更好地服务于每个人。