
多年來,我一直在留意 Linux 核心,並對 TCP 程式碼進行了多次研究。但最近,當我們撰寫最佳化 TCP 以實現高 WAN 輸送量並保持低延遲時,我才意識到我對 Linux 如何管理 TCP 接收緩衝區及視窗的瞭解還存在缺漏。隨著深入地挖掘,我發現這個主題非常複雜,當然也不太容易理解。
在本篇部落格貼文中,我將與大家分享我深入 Linux 網路堆疊的旅程,試著去瞭解 TCP 連線接收端的記憶體及視窗管理情況。具體來說,就是尋找一些看似很簡單的問題的答案:
- TCP 接收緩衝區中可以儲存多少資料?(不是您想的那樣)
- 多快能填滿?(這也不是您想的那樣!)
我們的探索重點是 TCP 連線的接收端。我們將試著去瞭解如何在不浪費寶貴記憶體的情况下將其調整到最佳速度。
一個快速上傳的案例
若要清楚地說明接收端緩衝區管理的情況,我們需要繪製精美的圖表!但若要掌握所有數據,我們還需要一點點理論。
我們將從 TCP 流程的接收端繪製圖表,執行一個非常簡單的情境:
- 用戶端開啟 TCP 連線。
- 用戶端執行
send(),並推送盡可能多的資料。 - 伺服器不會
recv()任何資料。我們期望所有資料都留在接收佇列中等待。 - 我們修復了 SO_RCVBUF 以便更清楚地說明。
簡化的虛擬程式碼可能看起來如下所示(如果您想要挑戰,可在此處檢視完整的程式碼):
sd = socket.socket(AF_INET, SOCK_STREAM, 0)
sd.bind(('127.0.0.3', 1234))
sd.listen(32)
cd = socket.socket(AF_INET, SOCK_STREAM, 0)
cd.setsockopt(SOL_SOCKET, SO_RCVBUF, 32*1024)
cd.connect(('127.0.0.3', 1234))
ssd, _ = sd.accept()
while true:
cd.send(b'a'*128*1024)
我們對一些基本問題很感興趣:
- 伺服器的接收緩衝區可以容納多少資料?結果表明,它與 Linux 上的預設讀取緩衝區大小並不完全相同;我們會在下文談及。
- 假設頻寬是無限的,用戶端填滿接收緩衝區最少需要多長時間(以 RTT 測量)?
一點點理論
我們先來確立一些通用術語吧。我會遵循 ss Linux 工具(來自 iproute2 套件)所使用的措辭。
首先是緩衝區預算限制。ss 手冊頁稱之為 skmem_rb,在核心中,稱之為 sk_rcvbuf。此值通常由 Linux 自動調整機制使用 net.ipv4.tcp_rmem 設定進行控制:
$ sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 131072 6291456
或者,也可以在通訊端使用 setsockopt(SO_RCVBUF) 手動設定。請注意,核心會將提供給該 setsockopt 的值加倍。例如,SO_RCVBUF=16384 會導致 skmem_rb=32768。預設情况下,會將此 setsockopt 允許的最大值限制為僅 208KiB:
$ sysctl net.core.rmem_max net.core.wmem_max
net.core.rmem_max = 212992
net.core.wmem_max = 212992
前面提到的部落格貼文討論了為什麼手動緩衝區大小管理有問題——通常最好依賴自動調整。
下面的圖表顯示了 skmem_rb 預算是如何劃分的:
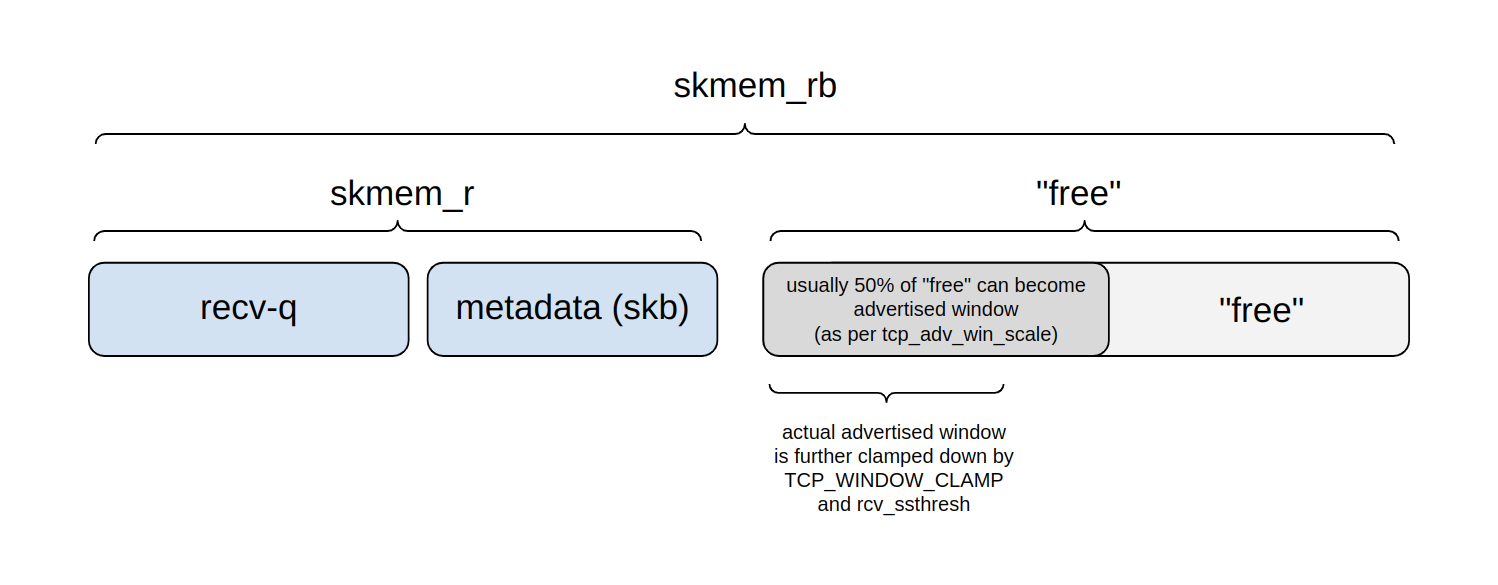
在任何時刻,我們都可以將預算劃分為四個部分:
- Recv-q:緩衝區預算中由等待
read()的實際應用程式位元組所佔用的一部分。 - 另一部分由中繼資料處理使用——struct sk_buff 以及諸如此類的成本。
ss將這兩個部分合在一起,報告為 skmem_r——核心名稱為 sk_rmem_alloc。- 剩餘部分為「可用」,也就是說:它還沒有被使用。
- 然而,在這個「可用」區域中,有一部分是通告視窗——它可能很快就會被應用程式資料佔滿。
- 其餘部分將用於未來的中繼資料處理,也可能會在將來進一步劃分為通告視窗。
該視窗的上限由 tcp_adv_win_scale 設定進行配置。預設情况下,最多可將該視窗設定為「可用」空間的 50%。透過 TCP_WINDOW_CLAMP 選項或內部 rcv_ssthresh 變數可以進一步固定該值。
一台伺服器可以接收多少資料?
我們的第一個問題是「一台伺服器可以接收多少資料?」。天真的讀者可能會認為這很簡單:如果伺服器將接收緩衝區設定為 64KiB,則用戶端肯定能够傳遞 64KiB 的資料!
但事實並非如此。為了說明這一點,請允許我暫時設定 sysctl tcp_adv_win_scale=0。這並不是預設值,而且我們之後會學到,這樣做是錯誤的。透過此設定,伺服器確實會將 100% 的接收緩衝區設定為通告視窗。
下面是我們的設定:
- 用戶端嘗試以盡可能快的速度傳送。
- 由於我們對接收端很感興趣,因此可以稍微作弊一下,任意加快傳送者的速度。用戶端停用了傳輸壅塞控制:我們將 initcwnd=10000 設定為路由選項。
- 伺服器有一個固定的 skmem_rb,設定為 64KiB。
- 伺服器設定了
tcp_adv_win_scale=0。
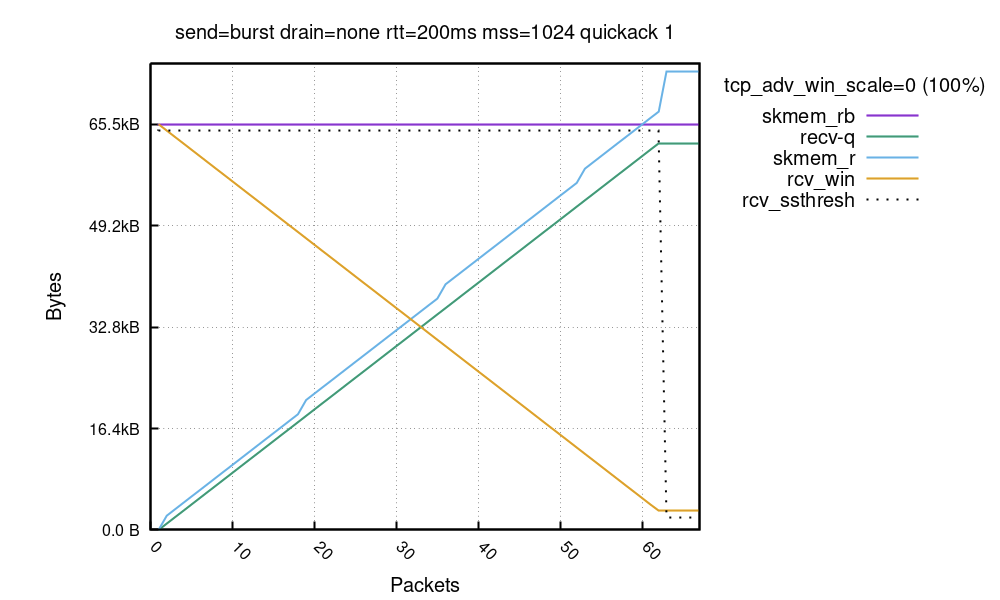
這裡包含了太多內容!讓我們試著去理解吧。首先,X 軸是輸入封包數量(我們看到大約是 65 個)。Y 軸顯示在每個封包的接收路徑上看到的緩衝區大小。
- 首先,紫色線是緩衝區大小限制(以位元組為單位)——skmem_rb。在實驗中,我們呼叫了
setsockopt(SO_RCVBUF)=32K且 skmem_rb 使該值加倍。注意,透過呼叫 SO_RCVBUF,我們停用了 Linux 自動調整機制。 - 綠色線 recv-q 是接收通訊端中可用的應用程式位元組數。它會隨著每個接收到的封包以線性方式增長。
- 然後是藍色的 skmem_r,它是接收通訊端中使用的資料 + 中繼資料成本。其增長方式與 recv-q 類似,但更快一點,因為它包含核心需要處理的中繼資料的成本。
- 橙色線 rcv_win 是一個通告視窗。這條線從 64KiB(100% 的 skmem_rb)開始,然後隨著資料的到來而下降。
- 最後,虛線顯示 rcv_ssthresh,這個並不重要,我們會在下文談及。
超出預算可不是什麼好事
我們必須要注意的是,實驗完成後,skmem_r 高於 skmem_rb!這個結果相當意外,也是我們不希望看到的。skmem_rb 記憶體預算的關鍵就是,不要超過它。下面是 ss 的呈現方式:
$ ss -m
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 62464 0 127.0.0.3:1234 127.0.0.2:1235
skmem:(r73984,rb65536,...)
如您所見,skmem_rb 為 65536,skmem_r 為 73984,超出了 8448 個位元組!當這種情況發生時,我們會面臨更大的問題。在傳送大約第 62 個封包時,我們有一個 3072 個位元組的通告視窗,但在封包傳送過程中,接收者無法處理它們!透過檢查 nstat TcpExtTCPRcvQDrop 計數器即可輕鬆驗證這一點:
$ nstat -az TcpExtTCPRcvQDrop
TcpExtTCPRcvQDrop 13 0.0
在我們的執行中,捨棄了 13 個封包。此變數會計算由於系統範圍或每個通訊端記憶體壓力而捨棄的封包數,在這裡,我們遇到的是後一種情況。在我們的案例中,在超過通訊端記憶體限制後不久,就會阻止新封包加入通訊端佇列。即使 TCP 通告視窗仍然開啟,也會發生這種情況。
這會產生一種非常有趣的情况。接收者的視窗是開啟的,這可能表明它有資源來處理資料。但情况卻並非總是如此,就像在我們的範例中,發生了記憶體預算耗盡的情況。
傳送者會認為它遇到了網路壅塞封包遺失,並會執行通常的重試機制,包括指數輪詢。這種行為可能會被視為預期,也可能被視為非預期,這取決於您如何看待它。一方面,資料不會遺失,並且傳送者最終會可靠地傳遞所有位元組。另一方面,指數輪詢邏輯可能會使傳送者長時間停止,從而導致明顯的延遲。
問題的根源很簡單——Linux 核心 skmem_rb 為存放於通訊端內的資料及中繼資料設定了記憶體預算。在悲觀的情况下,每個封包可能會產生的成本為 struct sk_buff + struct skb_shared_info,在我的系統上為 576 個位元組,超出了實際負載大小,再加上網路卡緩衝區調整造成的記憶體浪費:

我們現在知道,Linux 不能將 100% 的記憶體預算通告為通告視窗。必須為中繼資料等保留一些預算。視窗大小的上限表示為「可用」通訊端預算的一部分。它由 tcp_adv_win_scale 控制,可能使用以下值:
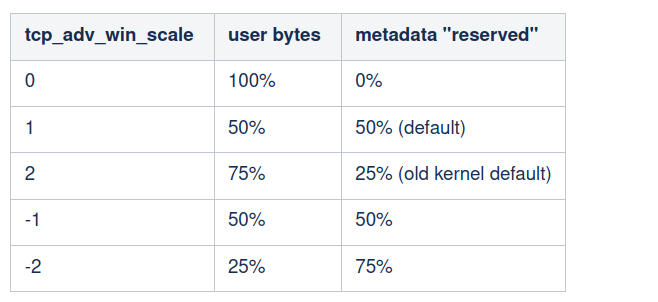
預設情况下,Linux 將通告視窗設定為剩餘緩衝區空間的最多 50%。
即使為中繼資料「保留」了 50% 的空間,核心也非常智慧,會努力减少中繼資料記憶體使用量。對此,它有兩種機制:
- TCP 聯合——在主邏輯上,Linux 能够捨棄 struct sk_buff。只需將資料連結至先前加入佇列的封包就可以了。您可以將其想像為正在延伸通訊端上的最後一個封包.
- TCP 摺疊——當達到記憶體預算時,Linux 會執行「摺疊」程式碼。摺疊將來自許多小型 skb 的接收緩衝區重新撰寫並重組為幾個非常長的區段,從而降低中繼資料成本。
這是上一張圖表的延伸,顯示了正在運作的這些機制:
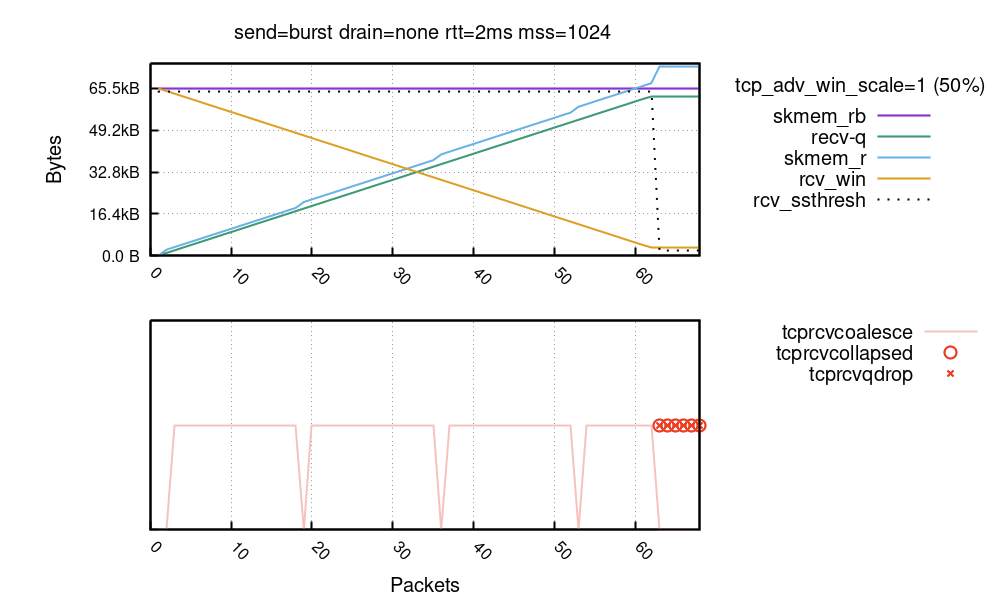
TCP 聯合是一種非常有效的措施,始終在幕後作業。在底部圖表中,接合聯合處的封包數用粉色線表示。您會看到 skmem_r 小高峰(藍色線)與聯合(粉色線)的缺失明顯相關。nstat TcpExtTCPRcvCoalesce 計數器可能有助於偵錯聯合問題。
TCP 摺疊更加重要。Mike 對其進行了全面的介紹,幾年前我寫了一篇部落格貼文,當時 TCP 摺疊的延遲給我們帶來了沉重的打擊。在上圖中,摺疊顯示為紅色圓圈。我們清楚地看到,摺疊在達到通訊端記憶體預算後,即從封包數量 63 開始接合。nstat TcpExtTCPRcvCollapsed 計數器與此相關。此值增長並不是什麼好迹象,可能表示發生令人不悅的延遲激增——尤其是在處理大量緩衝區時。通常情况下,執行摺疊的機會應該是非常少的。一位著名的核心開發人員描述了這種悲觀的局面:
這也意味著 tcp 為指定的已配置 rcvspace 通告了一個過於樂觀的視窗:當收到幀時,sk_rmem_alloc可能達到sk_rcvbuf限制,而且我們呼叫tcp_collapse()太過頻繁,尤其是在應用程式清空其接收佇列的速度太慢時 [...] 這是延遲的一個主要來源。
如果摺疊後記憶體預算仍然耗盡,Linux 將捨棄輸入封包。在我們的圖表中,將其標記為紅色的「X」。nstat TcpExtTCPRcvQDrop 計數器會顯示已捨棄封包的計數。
rcv_ssthresh 會預測中繼資料成本
也許沒想到的是,封包的記憶體成本可能遠遠大於其中包含的實際應用程式資料量。這取決於很多因素:
- 網路卡:有些網路卡總是為每個封包分配一整頁(4096,甚至 16KiB),無論負載有多小或多大。
- 負載大小:較短的封包將具有較差的中繼資料與內容比率,因為 struct skb 會相對較大。
- 是否正在使用 XDP。
- L2 標頭大小:像乙太網路、vlan 標記及通道這些都可能增加大小。
- 快取行大小:許多核心結構都會向著快取行對齊。在具有大量快取行的系統上,它們使用的記憶體會更多(請參閱 P4 或 S390X 架構)。
前兩個因素是最重要的。在下面的執行中,傳送者經過特別設定以使中繼資料成本不佳且聯合無效(設定的詳細資料非常混亂):
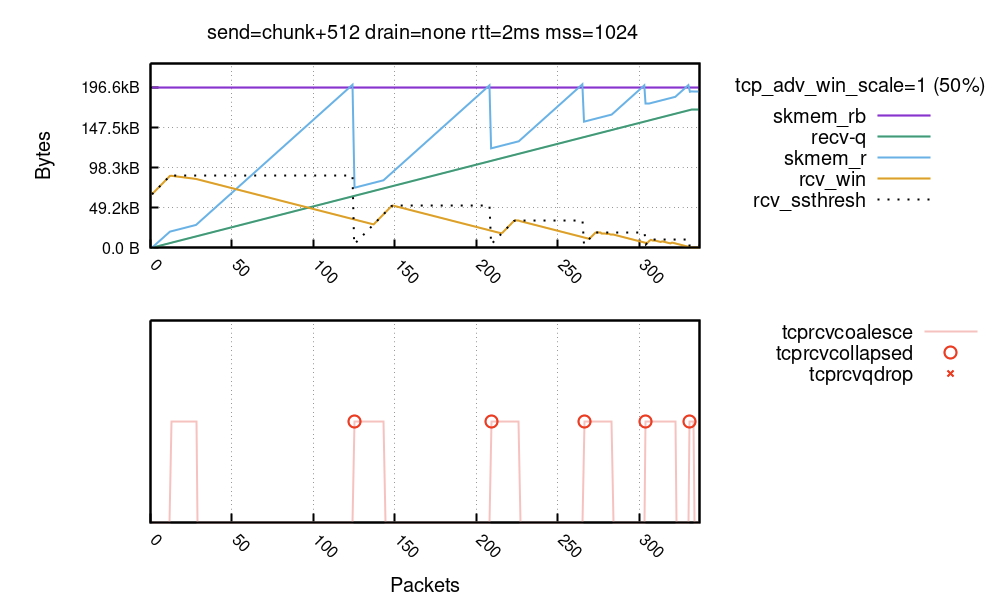
您可以看到核心多次達到 TCP 摺疊,這是絕對不希望出現的情況。每次摺疊核心都有可能重新撰寫完整的接收緩衝區。從使用 tcp_adv_win_scale 為中繼資料保留一些空間,經由使用聯合降低每個封包的記憶體成本,一直到 rcv_ssthresh 限制,整個核心機制的存在就是為了避免這種頻繁達到摺疊的情况。
核心機制在大多數情況下運作良好,TCP 摺疊在實踐中很少發生。然而,我們注意到,對於某些類型的流量,情况則並非如此。其中一個範例就是 Websocket 流量,其中包含大量的小封包以及一個速度較慢的讀取器。有一條核心評論談到了這種情況:
* The scheme does not work when sender sends good segments opening
* window and then starts to feed us spaghetti. But it should work
* in common situations. Otherwise, we have to rely on queue collapsing.
請注意,rcv_ssthresh 線在 TCP 摺疊時下降。此變數是通告視窗的內部限制。透過捨棄它,核心實際上是說:等等,我預測錯了封包成本,下次若有機會,我會開啟一個更小的視窗。核心會通告一個更小的視窗,並會更加謹慎——所有這些動作都是為了避免摺疊。
正常執行——持續更新的視窗
最後,下面是一個正常執行連線的圖表。在這裡,我們使用預設值 tcp_adv_win_wcale=1 (50%):
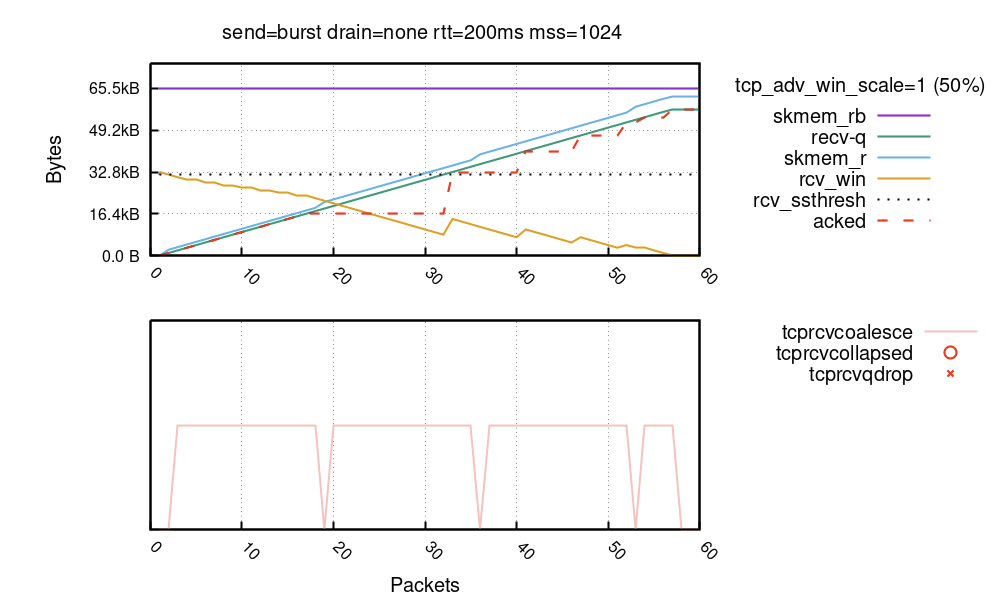
在連線的早期,您可以看到 rcv_win 隨著每個接收到的封包不斷更新。這是正常的情況:雖然 rcv_ssthresh 及 tcp_adv_win_scale 限制通告視窗絕不超過 32KiB ,但只要有足够的空間,視窗就會滑動自如。在第 18 個封包處,接收者停止更新視窗並稍等片刻。在第 32 個封包處,接收者判定仍有一些空間並再次更新視窗,以此類推。在流程的結尾處,通訊端有 56KiB 的資料。這 56KiB 的資料是透過滑動視窗接收的,最多可達到 32KiB。
rcv_win 的鋸片模式由延遲的 ACK(也稱為 QUICKACK)啟用。您會看到「acked」位元組以紅色虛線顯示。由於 ACK 可能會延遲,接收者會稍等片刻,然後再更新視窗。如果您希望線條流暢,則可以對每個路由參數使用 quickack 1,但不建議這樣做,因為這會導致許多較小的 ACK 封包在網路中傳輸。
在正常連線中,我們期望大多數封包進行聯合,且永遠不會走上摺疊/捨棄程式碼的道路。
大型接收視窗——rcv_ssthresh
對於透過較長延遲連結的大頻寬傳輸(BDP 較大的情况),有一個非常寬的通告視窗是很有益的。但是,Linux 需要一段時間才能完全開啟大型接收視窗:
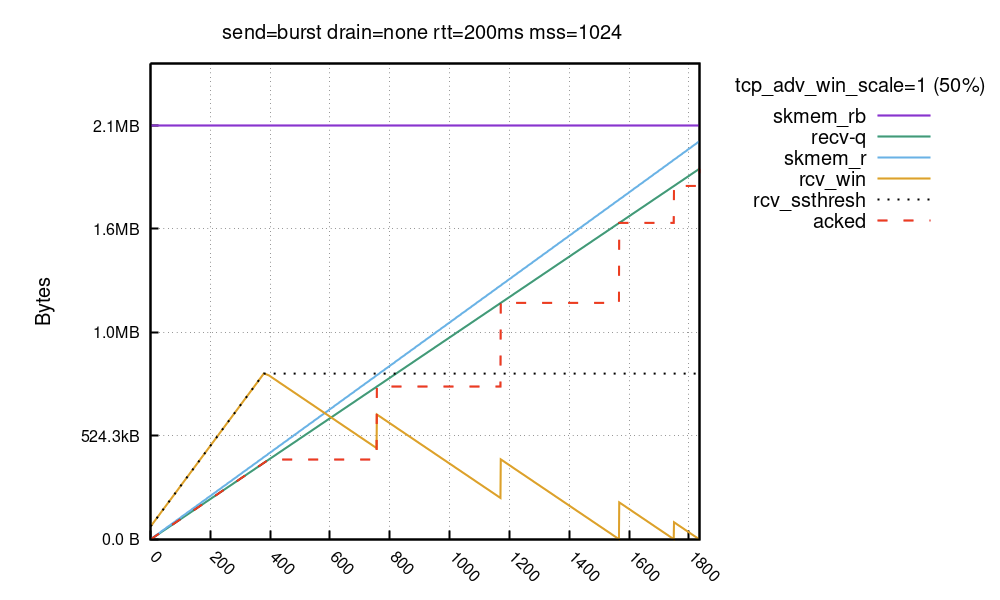
在本次執行中,skmem_rb 設定為 2MiB。與以前的執行相反,緩衝區預算很大,並且接收視窗不是從 skmem_rb 的 50% 開始的!而是從 64KiB 開始並呈線性增長。Linux 需要一段時間才能將接收視窗提升到完整大小——在這種情況下約為 800KiB。視窗由 rcv_ssthresh 固定。此變數從 64KiB 開始,然後以每個封包兩個完整 MSS 封包的速率增長,且每個封包的總大小 (truesize) 與負載大小之比為「良好」。
Eric Dumazet 提到過這種行為:
堆疊對於 RWIN 增長非常保守,它希望接收封包,以瞭解 skb->len/skb->truesize 比率,從而將記憶體預算轉換為 RWIN。
一些驅動程式不得不配置 16K 的緩衝區(甚至 32K 的緩衝區),只是為了保留一個區段(小於 1500 位元組的負載),而其他驅動程式則能够更有效地封裝記憶體。
這種緩慢開啟視窗的行為是固定的,無法在 vanilla 核心中設定。我們準備了一個核心修補程式,允許以更高的 rcv_ssthresh 開始,其基於每個路由選項 initrwnd:
$ ip route change local 127.0.0.0/8 dev lo initrwnd 1000
部署修補程式及路由變更後,緩衝區的外觀如下所示:
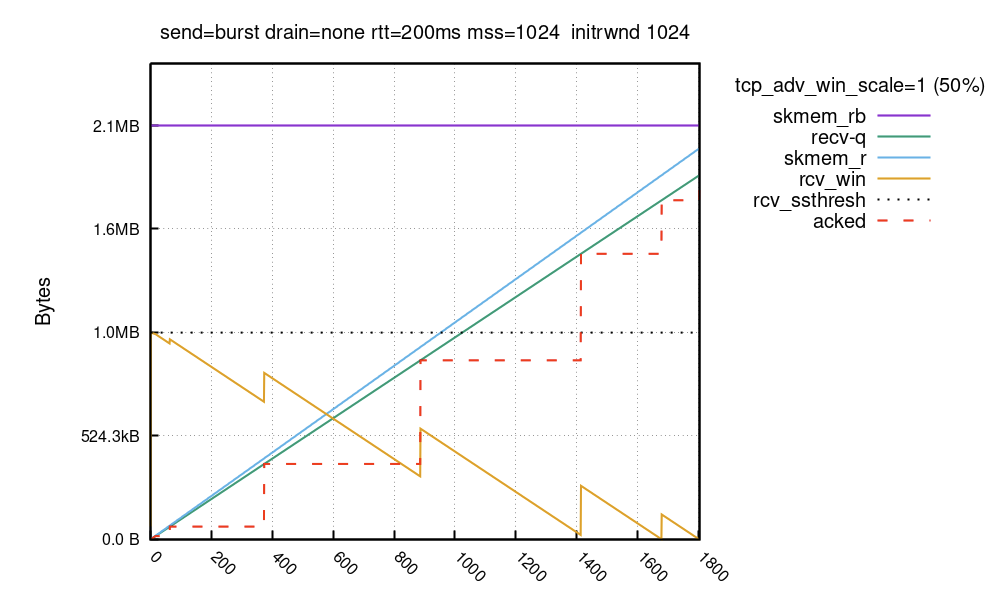
在 TCP 握手期間,通告視窗限制為 64KiB,但在啟用核心修補程式後,在隨後的第一個 ACK 封包中,該視窗迅速增長至 1MiB。在兩次執行中,填滿接收緩衝區所用的封包均為大約 1800 個,但所用時間不同。在第一次執行中,傳送者在第二個 RTT 中只能將 64KiB 推送到線上。在第二次執行中,它可以立即推送完整的 1MiB 資料。
對於大多數使用者來說,這種積極的視窗開啟技巧並不是真正必要的。僅在下列情况中有用:
- 您要透過較長延遲連結進行高頻寬 TCP 傳輸。
- NIC 的中繼資料 + 緩衝區調整成本是合理且可預測的。
- 流程啟動後,應用程式立即準備好傳送大量資料。
- 傳送者設定了較大的
initcwnd。
您想除去每一個可能的 RTT。
在我們的系統中,確實有這樣的流程,但可以說,這種情況可能並不常見。在現實生活中,大多數 TCP 連線都會前往最近的 CDN 服務提供點,距離非常近。
總結
在本篇部落格貼文中,我們討論了一個看似簡單的案例,此案例關於 TCP 傳送者填滿接收通訊端。我們試圖解决兩個問題:使用我們的獨立設定,可以傳送多少資料,以及傳送速度有多快?
在預設設定為 net.ipv4.tcp_rmem 的情况下,Linux 最初為接收資料及中繼資料設定了 128KiB 的記憶體預算。在我的系統上,如果是完整大小的封包,它最終能够接受大約 113KiB 的應用程式資料。
然後,我們證明了接收視窗不會立即完全開啟。Linux 保持較小的接收視窗,因為它試圖預測中繼資料成本並避免超出記憶體預算,從而導致 TCP 摺疊。預設情况下,net.ipv4.tcp_adv_win_scale=1,通告視窗的上限為「可用」記憶體的 50%。rcv_ssthresh 從 64KiB 開始,並線性增長到該極限。
在我的系統上,填滿 128KiB 的接收緩衝區花費了五次視窗更新——總共六個 RTT。在第一批中,傳送者傳送了約 64KiB 的資料(請記住,我們突破了 initcwnd 限制),然後傳送者用越來越小的批次將其填滿,直到接收視窗完全關閉。
希望這篇部落格貼文清晰地說明了 Linux 上緩衝區大小和通告視窗之間的關係,且能夠對大家有所幫助。此外,本文還描述了經常被誤解的 rcv_ssthresh,它會對通告視窗進行限制,以便管理記憶體預算並預測中繼資料的不可預測成本。
如果您想瞭解,在 QUIC 中也有類似的機制在運作。但 QUIC/H3 程式庫還很年輕,沒有那麼多複雜和神秘的切換。一如既往,我們的 GitHub 上提供了有關如何重製圖表的程式碼和說明。