


介紹
今天,2022 年 6 月 21 日,Cloudflare 遭遇了一次服務中斷事件,影響了我們 19 個資料中心的流量。很不幸的是這 19 個地點是我們最大的資料中心,承載著我們全球相當大一部分流量。此次服務中斷事件由一個長期執行專案中的一項變更引起,該專案旨在提高我們最大資料中心的復原能力,因為這些資料中心是我們基礎網路架構的關鍵部分,並處理相當大比重的 Cloudflare 流量。在這些地點的一項網路設定變更引起了在 UTC 06:27 開始的一次服務中斷事件。在 UTC 06:58,第一個資料中心重新上線;UTC 07:42,所有資料中心恢復上線並正常運作。
基於您的地理位置,您可能無法訪問,存取構建於 Cloudflare 的網站和服務。而在其他地點,Cloudflare 始終持續正常運作。
對於此次服務中斷事件,我們深感抱歉。這是我們工作上的不足,而不是由攻擊或惡意活動所導致的結果。
背景
在過去 18 個月內,Cloudflare 一直在致力於將我們的所有最大資料中心轉換為更具備援屬性的架構。在此期間,我們已將 19 個資料中心轉換為這種架構,內部稱為 Multi-Colo PoP (MCP):阿姆斯特丹、亞特蘭大、阿什本、芝加哥、法蘭克福、倫敦、洛杉磯、馬德里、曼徹斯特、邁阿密、米蘭、孟買、紐華克、大阪、聖保羅、聖荷西、新加坡、雪梨、東京。
這一新架構的關鍵部分設計為 Clos 網路,是路由的新增層級,用於建立連線網格。該網格讓我們能夠輕鬆停用和啟用資料中心內的部分內部網路,以進行維修或是處理問題。該層級由下圖中的骨幹 (spine) 表示。
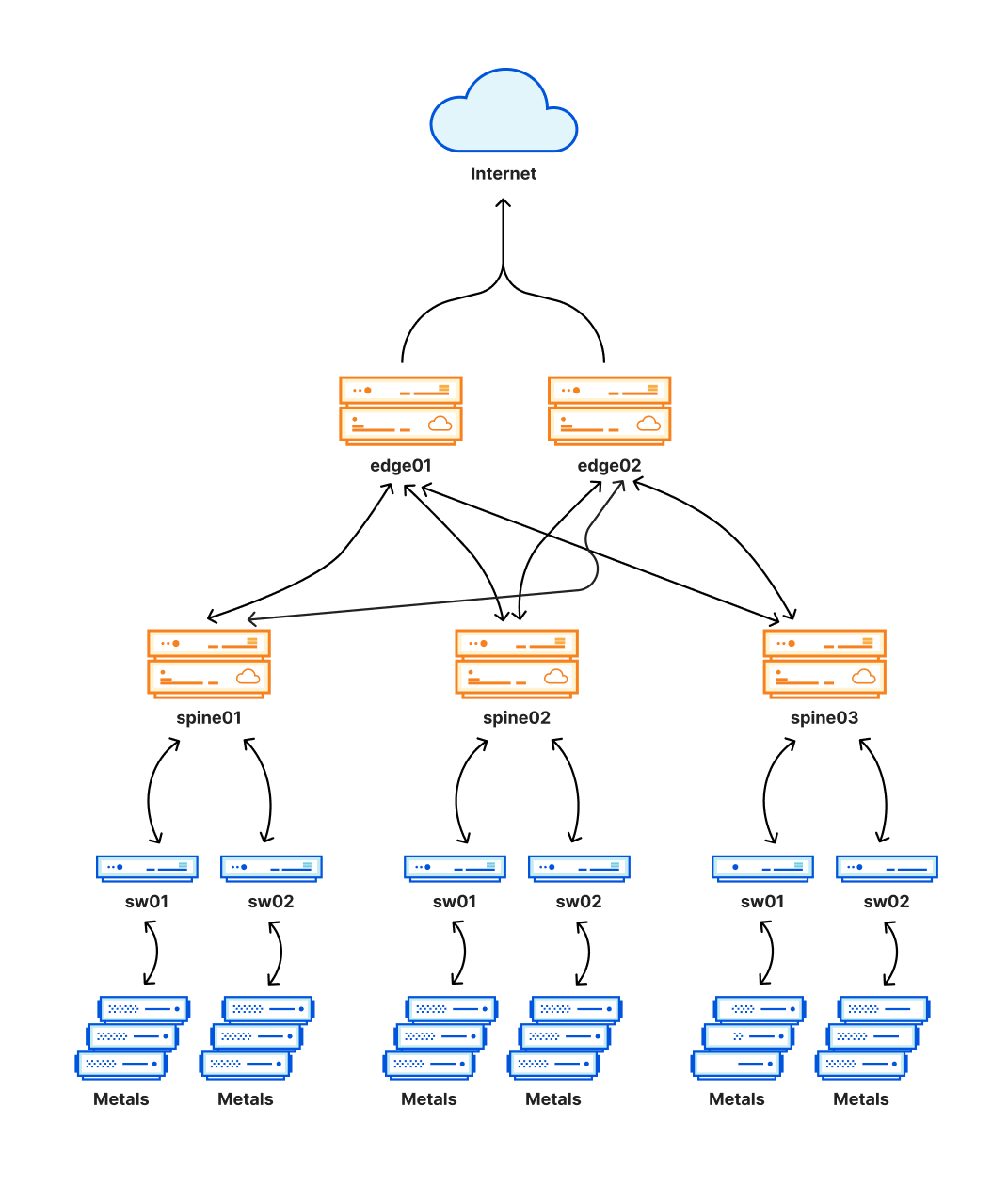
此全新架構為我們提供了重要的可靠性改進 (reliability improvements),以及讓我們能夠在這些地點進行維護工作而無需中斷客戶流量。由於這些地點還承載相當大比重的 Cloudflare 流量,此處發生的任何問題都可能有非常廣泛的影響,很不幸,今天就發生了這樣的事件。
事件時間表(UTC)和影響
Cloudflare 采用 BGP 作爲其維持網路聯通性的通訊協定。作為該通訊協定的一部分,操作員會定義原則 (policies),以決定是否通告網絡前綴 Prefixes 給相鄰網路亦或者是否接受相鄰網路通告的 prefixes。
這些原則 (policies) 將擁有單獨的組件,按順序進行評估。最終結果是某個特定前綴 (prefixes) 將被通告或不被通告。原則中的變更可能使得之前被通告的某個前綴不再被通告,在這種情況下,該前綴將被撤回,這些 IP 位址將將失去其在網路上的連通性。
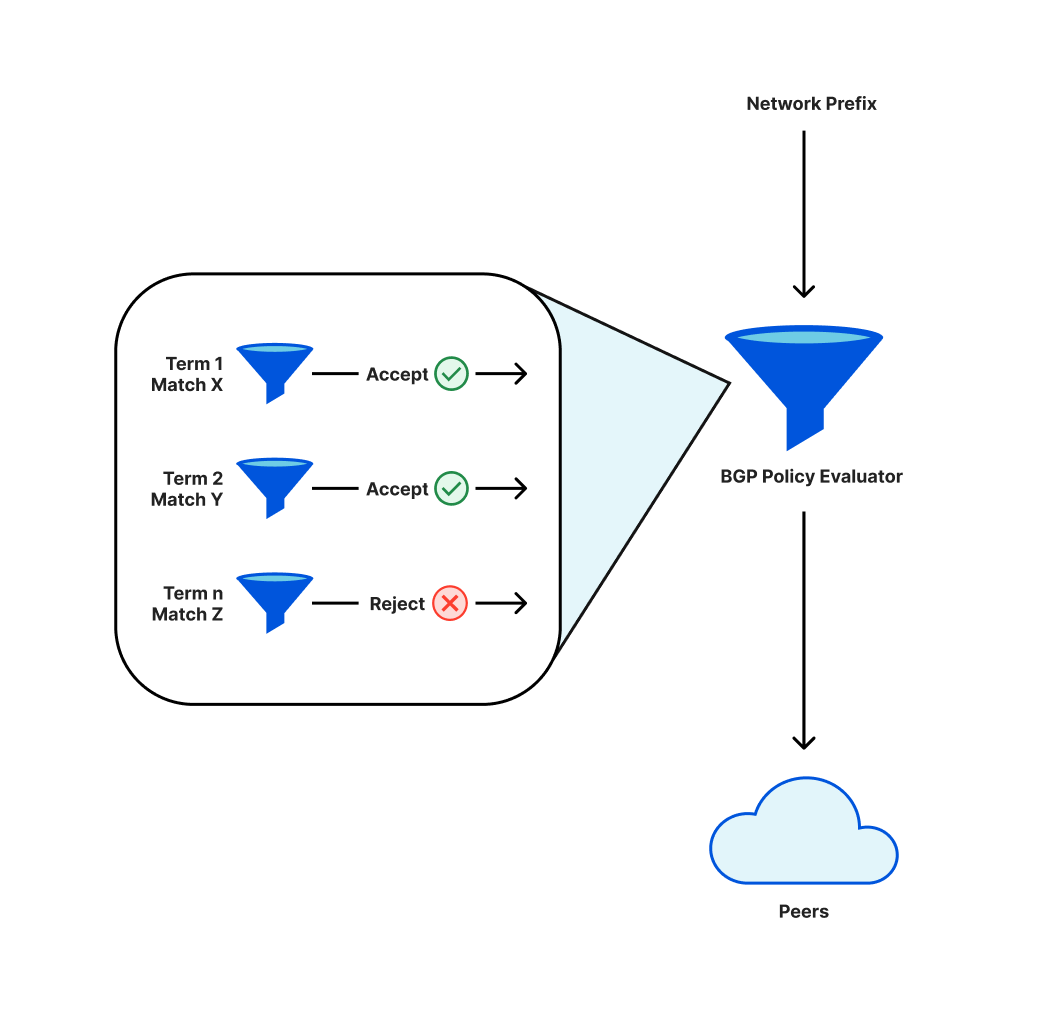
在對我們的前綴通告原則 (prefix advertisement policies) 進行變更時,term 的重新排序導致我們撤回一個關鍵的前綴。
由於該撤回,Cloudflare 工程師在連線受影響的地點以還原有問題的變更時遭遇額外的困難。我們擁有處理此類事件的備用程序,並使用這些程序控制受影響的地點。
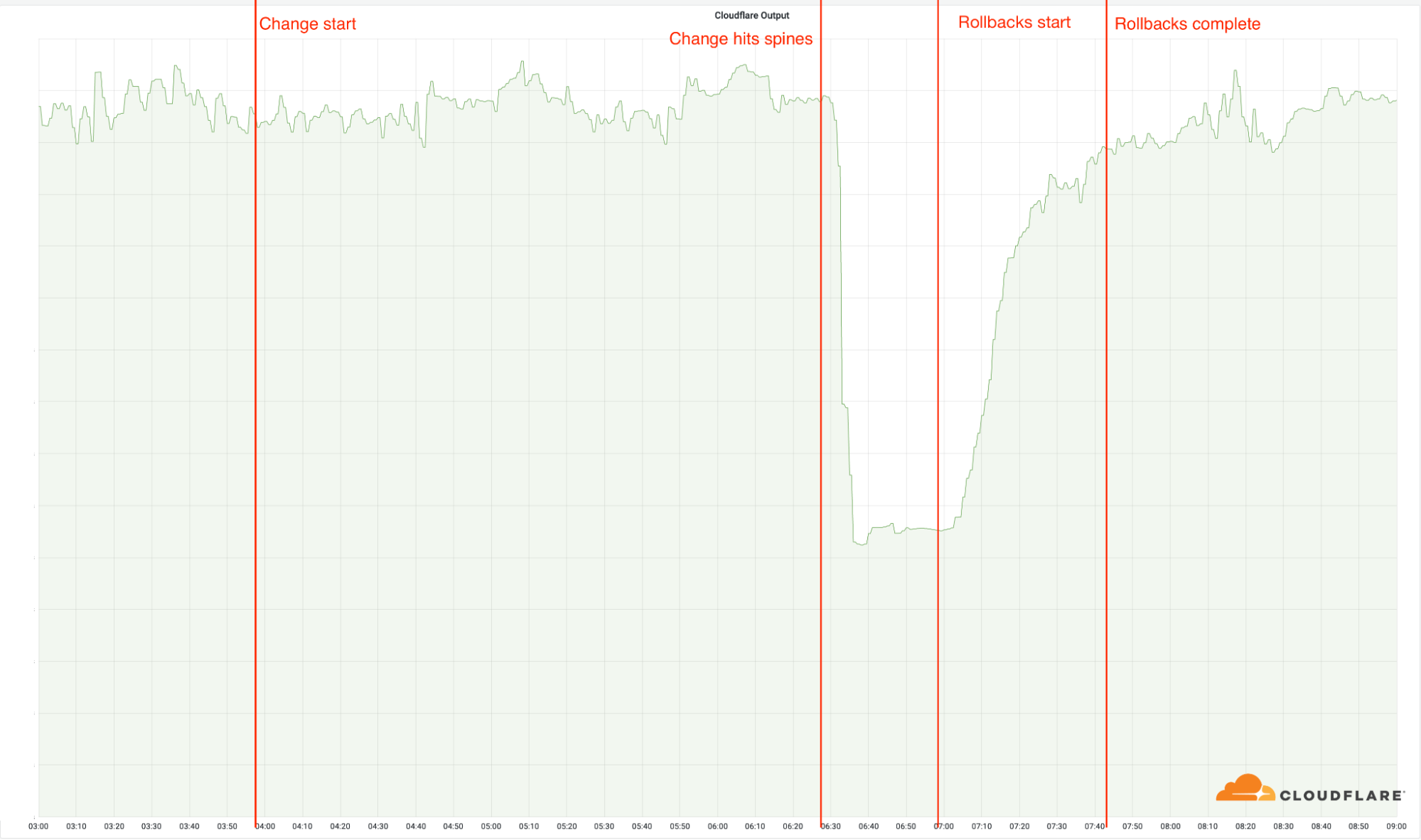
03:56:我們開始將變更部署到第一個資料中心。此時所有地點都尚未受到該變更影響,因為舊的架構仍被使用當中。
06:17:該變更部署到最忙碌的節點,但這不是使用新架構的地點。
06:27:新架構的部署到達我們最忙碌的節點,且變更已部署到骨幹。這是事件開始的時間,該事件迅速使這 19 個地點離線。
06:32:正式宣佈發生事故。
06:51:對一個路由器進行第一次變更,以驗證可能的根本原因。
06:58:找到並瞭解根本原因。開始著手還原 (revert) 有問題的變更。
07:42:最後的還原工作完成。這一時間有所延誤,因為網路工程師互相檢查彼此的變更,還原前面的一些還原工作,導致問題偶爾再次出現。
08:00:事件結束。
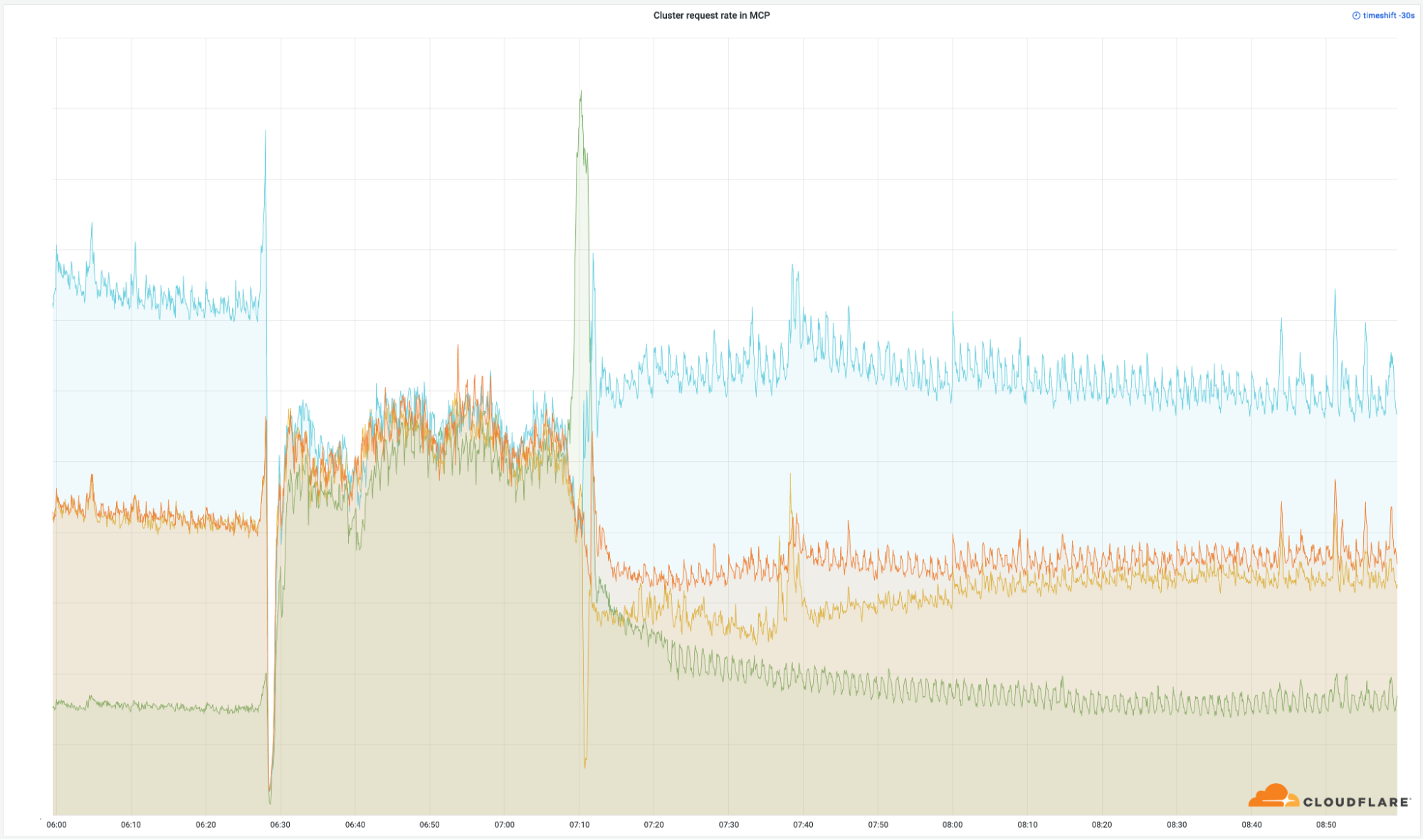
從我們在全球範圍內傳回的成功請求數量中可以清楚地看出這些資料中心的重要性:
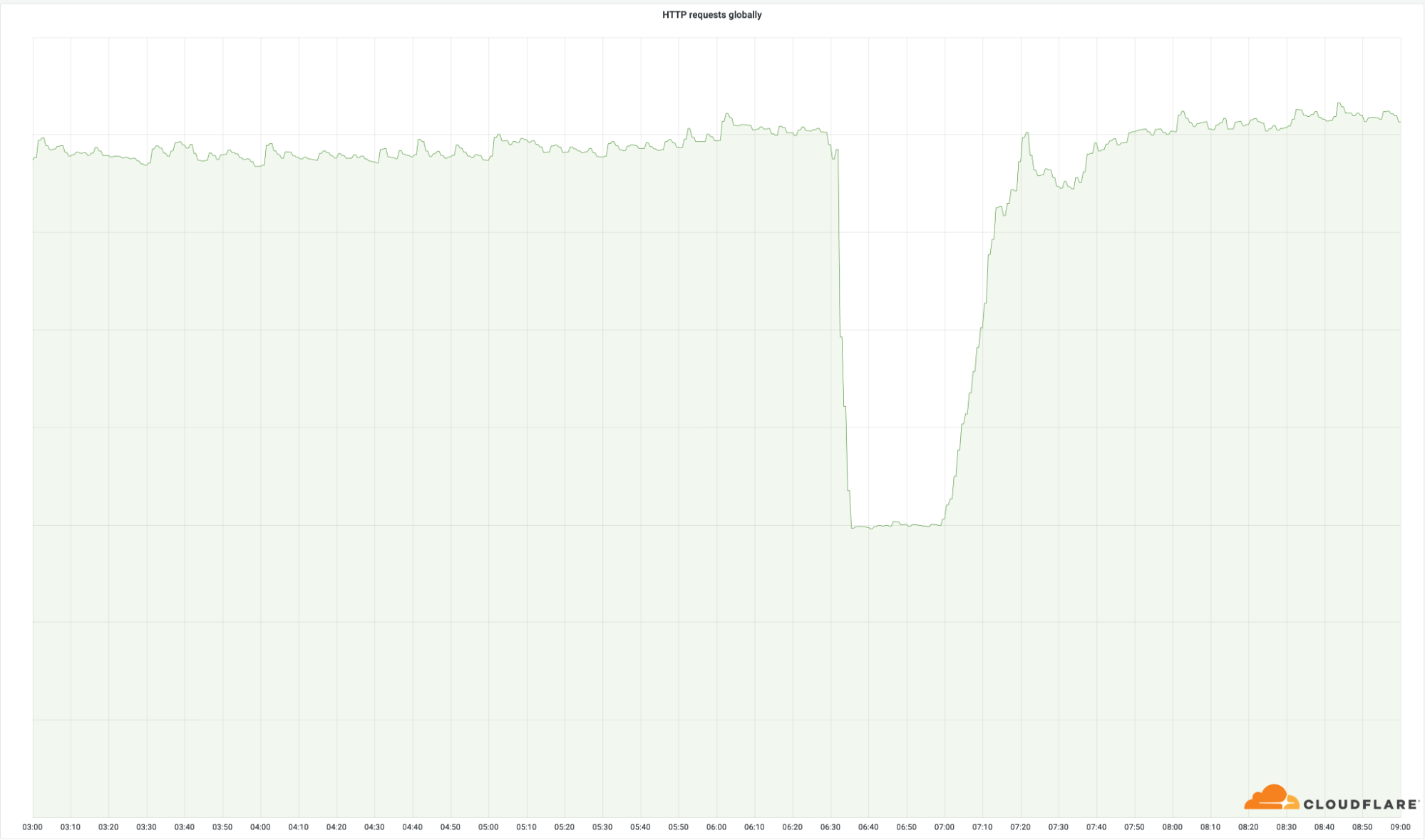
儘管這些節點僅佔我們總體網路的一小部分 (4%),但影響了我們總請求的 50%。在我們的輸出頻寬中也可以看出這一點:
報錯發生 (error) 的技術說明及其發生的原因
在我們不斷努力對基礎結構設定進行標準化的過程中,我們推出了一項變更,以標準化我們附加到所通告的前綴子網的 BGP 社群。具體來說,我們在向 site-local 前綴新增資訊社群 (informational communities)。這些前綴允許我們的計算節點相互通訊,以及連線到客戶原點。作為 Cloudflare 變更程序的一部分,建立了一個變更請求 (CR) 工單,其中包括變更的試執行以及逐步推出程序。在它被允許發佈之前,它還經過了多位工程師的同儕審查。不幸的是,在此次案例中,這些步驟還不夠細緻,未能在變更到達我們的所有骨幹之前找出錯誤。
在其中一個路由器上,變更看起來是像以下這樣:
[edit policy-options policy-statement 4-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 4-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-COGENT-TRANSIT-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
[edit policy-options policy-statement 6-PUBLIC-PEER-ANYCAST-OUT term ADV-SITELOCAL then]
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add TLL01;
+ community add EUROPE;
這是無害的,只是向這些首碼通告新增一些額外資訊。在骨幹上的變更如下所示:
[edit policy-options policy-statement AGGREGATES-OUT]
term 6-DISABLED_PREFIXES { ... }
! term 6-ADV-TRAFFIC-PREDICTOR { ... }
! term 4-ADV-TRAFFIC-PREDICTOR { ... }
! term ADV-FREE { ... }
! term ADV-PRO { ... }
! term ADV-BIZ { ... }
! term ADV-ENT { ... }
! term ADV-DNS { ... }
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
[edit policy-options policy-statement AGGREGATES-OUT term 4-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
[edit policy-options policy-statement AGGREGATES-OUT term 6-ADV-SITE-LOCALS then]
community delete NO-EXPORT { ... }
+ community add STATIC-ROUTE;
+ community add SITE-LOCAL-ROUTE;
+ community add AMS07;
+ community add EUROPE;
此 diff 在初看之下,可能會讓人覺得此變更是相同的,但不幸的是,事實並非如此。如果我們著重看一下 diff 的 1 個部分,原因可能就會變得很明顯:
! term REJECT-THE-REST { ... }
! term 4-ADV-SITE-LOCALS { ... }
! term 6-ADV-SITE-LOCALS { ... }
在此 diff 格式中,term 前面的感嘆號表示 term 的重新排序。在此案例中,多個 term 向上移動,兩個 term 新增至底部。具體來說,4-ADV-SITE-LOCALS term 從頂部移至底部。該 term 現在在 REJECT-THE-REST term 後方,從名字中可以看出,該 term 是明確拒絕:
term REJECT-THE-REST {
then reject;
}
由於該 term 現在在 site-local term 之前,我們立即停止通告我們的 site-local 前綴,移除對所有受影響資料中心的直接存取,以及移除我們的伺服器存取源站的能力。
除了無法聯絡源站之外,移除這些 site-local 前綴還導致我們的內部負載平衡系統 Multimog(我們的 Unimog 負載平衡器的一種變體)停止工作,因為無法再在我們 MCP 中的伺服器之間轉送請求。這意指在 MCP 中較小的運算叢集接收到的流量與我們最大的叢集相同,導致較小的運算叢集過載。
補救措施和後續步驟
我們對於可用性 (availability) 極其重視,然而此事故造成了廣泛的衝擊。我們已經確定了幾個需要改進的領域,並將繼續努力發現可能導致事件重演的任何其他漏洞。
下面是我們立即採取的措施:
流程:雖然 MCP 計畫旨在提高可用性,但我們更新這些資料中心的工作流程中出現的脫節問題最終導致對 MCP 地點的更廣泛影響。雖然我們確實為此變更使用了交錯程序 (stagger procedure),但交錯原則直到最後一步才包括 MCP 資料中心。變更程序 (Change procedures) 和自動化需要包括特定於 MCP 的測試和部署程序,才能確保不會出現意外後果。
架構:不正確的路由器設定阻止正確的路由被宣佈到我們的邊緣 (Edge),阻止流量正確地流向我們的基礎結構。最終,將重新設計導致錯誤路由通告 (routing advertisement) 的原則聲明 (Policy statement),以防止無預期的錯誤排序。
自動化:我們的自動化套件中有幾個機會可以緩解此事件的部分或全部影響。首先,我們將專注於自動化改進,為網路設定的推出執行改進的交錯原則,並提供自動化的「提交-確認」回復。前者的增強會顯著降低整體影響,後者會大幅縮短事件期間的解決時間。
結論
儘管 Cloudflare 已對我們的 MCP 設計進行大量投資來改善服務可用性,但這次令人痛苦的事件表明,我們顯然遠未達到客戶的期望。對於我們的客戶以及在服務中斷期間所有無法存取網際網路設備的使用者,我們深感抱歉。我們已經開始著手進行上述變更,並將繼續努力確保這種情況不會再次發生。