
我們骨幹網路 (backbone network) 的某項設定錯誤導致網際網路設備和 Cloudflare 服務今天 (7/17) 故障了 27 分鐘。我們發現整個網路的流量下降了大約 50%。鑑於我們的主幹架構,這次故障沒有影響到整個 Cloudflare 網路,而是僅限於局部。
故障的原因是:在處理從紐瓦克到芝加哥的一段骨幹網的不相關問題時,我們的網路工程團隊更新了亞特蘭大一台路由的設定,以期緩解擁塞。該設定包含一項錯誤,導致我們骨幹網上的所有流量都被傳送到亞特蘭大。這很快導致亞特蘭大路由不堪重負,使得連結至骨幹網的 Cloudflare 網路位置出現故障。
受影響的位置包括聖荷西、達拉斯、西雅圖、洛杉磯、芝加哥、華盛頓、里奇蒙、紐瓦克、亞特蘭大、倫敦、阿姆斯特丹、法蘭克福、巴黎、斯德哥爾摩、莫斯科、聖彼得堡、聖保羅、庫里奇巴和阿雷格里港。其他位置繼續正常運作。
為避免疑義,故作此解釋:這不是由任何類型的攻擊或破壞造成的。
我們對此故障深感抱歉,並且已經對骨幹網設定進行了全域更改,以防止故障再次發生。
Cloudflare 骨幹網
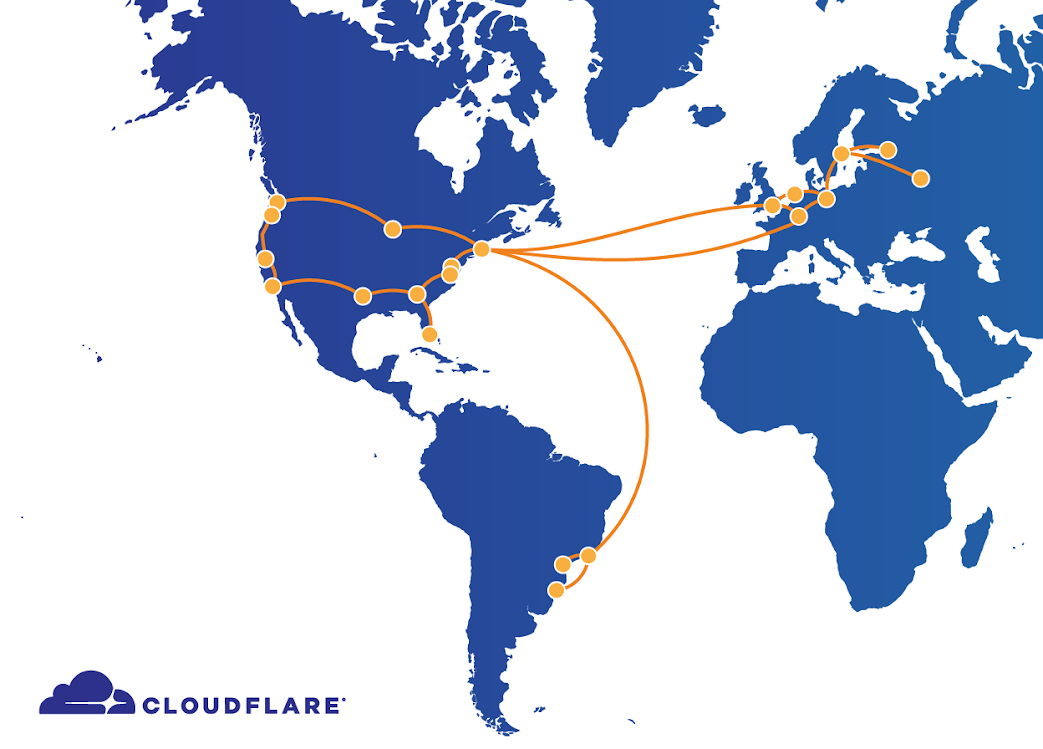
Cloudflare 營運著我們全球多處資料中心之間的骨幹網。骨幹網是我們資料中心之間的一系列專用線路,我們使用這些線路在它們之間建立更快、更可靠的路徑。這些連結讓我們能在不同的資料中心之間傳輸流量,而無需透過公共網際網路。
例如:我們用它來造訪位於紐約的網站來源伺服器,透過我們的專用骨幹網將請求傳送到加州的聖荷西,甚至法蘭克福或聖保羅。這種避免公共網際網路的額外方案可以實現品質更高的服務,因為專用網路可以用來避開網際網路擁塞點。有了骨幹網,我們對於控制路由網際網路請求和流量的位置和方式方面優於公共網際網路。
時間表
所有時間均為格林威治時間 (UTC)。
首先,紐瓦克和芝加哥之間的骨幹網線路出現問題,導致亞特蘭大和華盛頓之間發生骨幹網擁塞。
為了解決這個問題,工作人員在亞特蘭大進行了設定變更。此變更導致在 21:12 發生故障。工作人員立即查明故障原因,停用了亞特蘭大路由,流量在 21:39 開始正常流動。
不久之後,我們在一個處理記錄和指標的核心資料中心發現了擁塞,導致丟失一些記錄。在此期間,邊緣網路繼續正常運作。
- 20:25:EWR 和 ORD 之間的骨幹網線路遺失
- 20:25:ATL 和 IAD 之間的骨幹網擁塞
- 21:12 至 21:39:ATL 從骨幹網中吸引流量
- 21:39 至 21:47:ATL 從骨幹網斷開,服務恢復
- 21:47 至 22:10:核心擁塞導致一些記錄丟失,邊緣網路繼續運作
- 22:10:全面恢復,包括記錄和指標
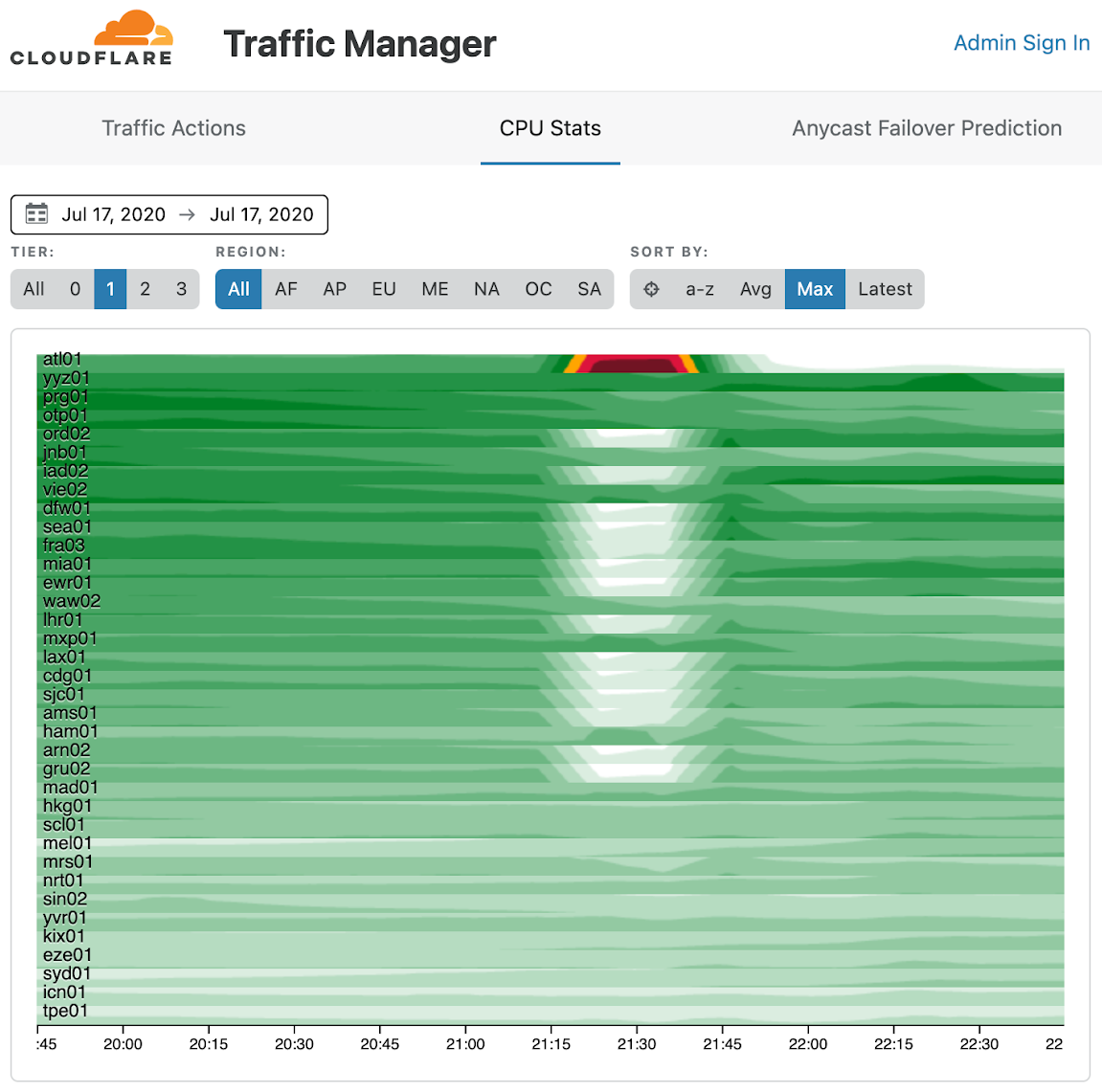
這是關於 Cloudflare 內部流量管理工具影響的檢視畫面。頂端的紅色和橙色區域顯示亞特蘭大的 CPU 利用率達到過載,白色區域則顯示受影響的資料中心的 CPU 利用率降至接近零,因為它們不再處理流量。這就是故障期間的情況。
其他未受影響的資料中心在故障期間的 CPU 利用率沒有發生變化。事實表明,在這些資料中心發生故障期間,綠色不會改變。
狀況描述以及我們的措施
由於亞特蘭大發生骨幹網擁塞,該團隊決定移除亞特蘭大的部分骨幹網流量。這原本一行的命令修改,本應將亞特蘭大的路由從主幹網中移除,但結果反而泄露了所有的 BGP 路由至主幹網。
{master}[edit]
atl01# show | compare
[edit policy-options policy-statement 6-BBONE-OUT term 6-SITE-LOCAL from]
! inactive: prefix-list 6-SITE-LOCAL { ... }
完整術語 (term) 看起來是這樣的:
from {
prefix-list 6-SITE-LOCAL;
}
then {
local-preference 200;
community add SITE-LOCAL-ROUTE;
community add ATL01;
community add NORTH-AMERICA;
accept;
}
該術語設定了本機喜好設定 (local-preference),新增了一些社群 (community),接受了相符前置詞清單 (prefix-list) 的路由。本機喜好設定是 iBGP 工作階段的傳遞屬性 (這將被傳輸到下一個 BGP 對等體 (BGP peer))。
正確的變更方式應該是停用該術語,而不是前置詞清單。
透過移除前置詞清單狀態 (prefix-list condition),可指示路由將其所有 BGP 路由傳送到所有其他骨幹網路由,local-preference 設定增加到 200。但不幸的是,當時邊緣路由從我們的計算節點收到的本機路由的 local-preference 設定僅為 100。隨著本機喜好設定越來越高,本機計算節點的所有流量轉而流向亞特蘭大計算節點。
隨著路由的發出,亞特蘭大開始從骨幹網中吸引流量。
我們的變更措施如下:
- 在我們的骨幹網 BGP 工作階段中引入 maximum-prefix 限制——這將關閉亞特蘭大的骨幹網,但我們網路的建置可在沒有骨幹網的情況下正常運作。此變更將於 7 月 20 日 (週一) 部署。
- 變更本機伺服器路由的 BGP local-preference 設定。此變更將可防止單一位置以類似的方式吸引其他位置的流量。此變更已在故障發生後部署。
結論
我們的骨幹網之前從未發生過故障,故障發生後,我們的團隊迅速做出反應,幫助受影響的位置恢復了服務,但所有受到影響的人員都歷經艱辛。對於我們的客戶以及所有在故障期間無法使用網際網路設備的使用者,我們深感抱歉。
我們已經對骨幹網設定進行了變更,以確保這種情況不會再次發生,我們將在週一 (7/20) 繼續進行變更。