
多年来,我一直在探究 Linux 内核,并多次反复研究 TCP 代码。但是,最近我们在努力优化 TCP 以实现高 WAN 吞吐量并保持低延迟时,我意识到,自己对于 Linux 管理 TCP 接收缓冲区和窗口的方式有认识不足之处。深入探索之下,我发现这个话题很复杂,确实不那么浅显。
在这篇博客文章中,我准备谈一谈自己钻研 Linux 网络堆栈的过程,在这期间,我认真学习了 TCP 连接接收端的内存和窗口管理。具体来说,就是设法解答以下看似无关紧要的问题:
- TCP 接收缓冲区中可以存储多少数据?(答案令人意外)
- 能达到多快的填写速度?(答案同样令人意外!)
我们的探索专注于 TCP 连接的接收端。我们会试着摸索如何调优,实现最佳速度,而不浪费宝贵的财力。
快速上传的案例
为了以最佳方式演示接收端缓冲区管理,我们需要美观的图表!但要掌握所有数字,我们需要一点理论知识。
我们会从 TCP 流的接收端绘制图表,展示一个相当简单明了的场景:
- 客户端打开 TCP 连接。
- 客户端执行
send(),并推送尽可能多的数据。 - 服务器不会通过
recv()接收任何数据。我们预期所有数据在接收队列中保留并等待。 - 我们修复了 SO_RCVBUF,以便更好地展示。
简化的伪代码可能类似于(有本事就编写完整代码试试):
sd = socket.socket(AF_INET, SOCK_STREAM, 0)
sd.bind(('127.0.0.3', 1234))
sd.listen(32)
cd = socket.socket(AF_INET, SOCK_STREAM, 0)
cd.setsockopt(SOL_SOCKET, SO_RCVBUF, 32*1024)
cd.connect(('127.0.0.3', 1234))
ssd, _ = sd.accept()
while true:
cd.send(b'a'*128*1024)
我们希望解答如下基本问题:
- 服务器的接收缓冲区中可以容纳多少数据?我们发现,这个数量并不等同于 Linux 上的默认读取缓冲区大小,下文会具体讲到。
- 假定带宽无限,客户端填满接收缓冲区所需的最短时间(以 RTT 测量)是多少?
一点理论知识
首先,我们来确立一些通用术语。我会遵循 iproute2 包内 ss Linux 工具中使用的措辞。
首先,存在缓冲区预算限制。ss 手册页称之为 skmem_rb,在内核中名为 sk_rcvbuf。该值通常使用 net.ipv4.tcp_rmem 设置由 Linux 自动调整机制来控制:
$ sysctl net.ipv4.tcp_rmem
net.ipv4.tcp_rmem = 4096 131072 6291456
或者,也可以使用 setsockopt(SO_RCVBUF) 对套接字进行设置。请注意,内核将提供给此 setsockopt 的值加倍了。例如,SO_RCVBUF=16384 将导致 skmem_rb=32768。此 setsockopt 允许的最大值默认仅限于微薄的 208KiB:
$ sysctl net.core.rmem_max net.core.wmem_max
net.core.rmem_max = 212992
net.core.wmem_max = 212992
前述博客文章介绍了手动缓冲区大小管理有问题的原因,通常最好依赖自动调整。
下图显示了 skmem_rb 预算的划分方式:
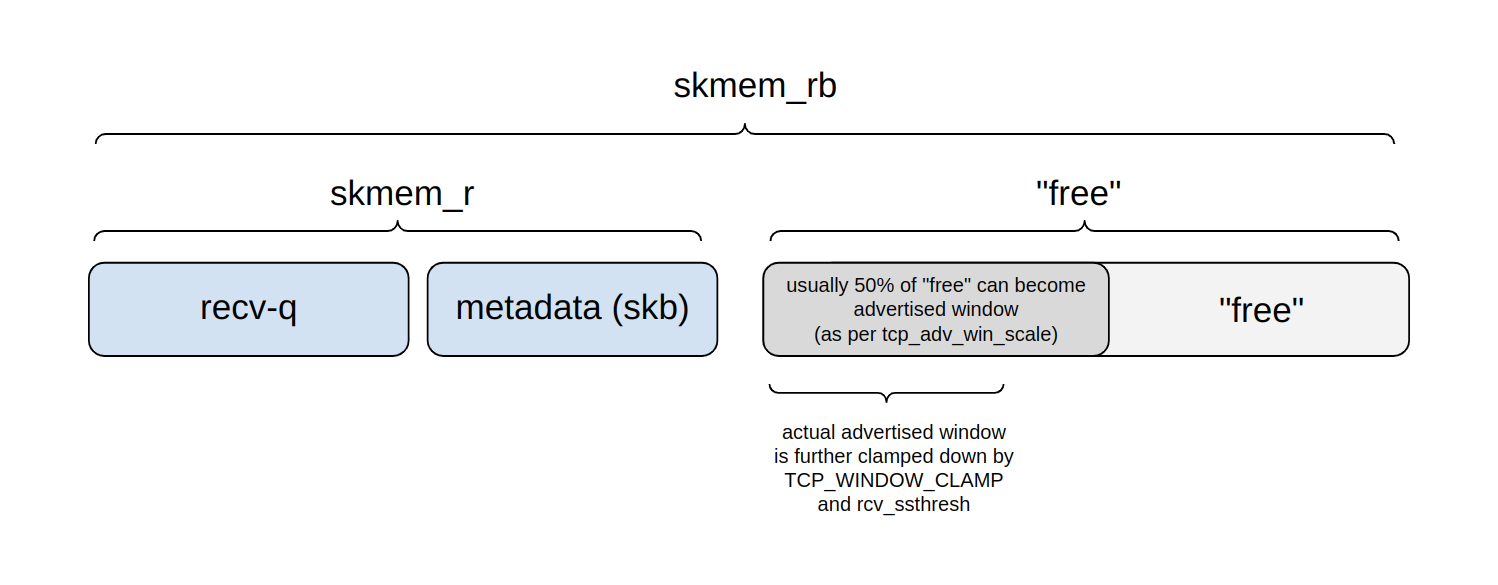
在任何给定时刻,我们可以将预算分成四个部分来考虑:
- Recv-q:等待
read()的实际应用程序字节所占用的缓冲区预算部分。 - 另一部分用于元数据处理,包括 struct sk_buff 的成本等。
- 这两个部分一起由
ss报告为 skmem_r,而内核名称是 sk_rmem_alloc。 - 剩余部分是“空闲”的,即尚未被主动使用。
- 但是,这个“空闲”区域的一部分是一个公告窗口,可能很快就会被应用程序数据占用。
- 剩余部分将用于未来的元数据处理,或者可以在未来进一步划分到公告窗口中。
窗口上限通过 tcp_adv_win_scale 设置进行配置。默认情况下,窗口设置为“空闲”空间的最多 50%。该值可以进一步通过 TCP_WINDOW_CLAMP 选项或内部 rcv_ssthresh 变量进行限制。
服务器可以接收多少数据?
我们的第一个问题是“服务器可以接收多少数据?”。缺乏经验的读者可能会认为这很简单:如果服务器将接收缓冲区设置为某个值,比如 64KiB,客户端当然就能传递 64KiB 的数据!
但实际情况远非如此。为了说明这一点,不妨暂时设置 sysctl tcp_adv_win_scale=0。这并非默认值,而且接下来我们会发现,这样设置是不正确的。采用这个设置,服务器实际上确实会将 100% 的接收缓冲区设置为公告窗口。
下面是我们的设置:
- 客户端尝试尽可能快地发送数据。
- 因为我们关注的是接收端,不必那么严格,就随意提高发送端的速度。客户端禁用了传输拥塞控制:我们将 initcwnd=10000 设置为路由选项。
- 服务器将 skmem_rb 固定设为 64KiB。
- 服务器设置了
tcp_adv_win_scale=0。
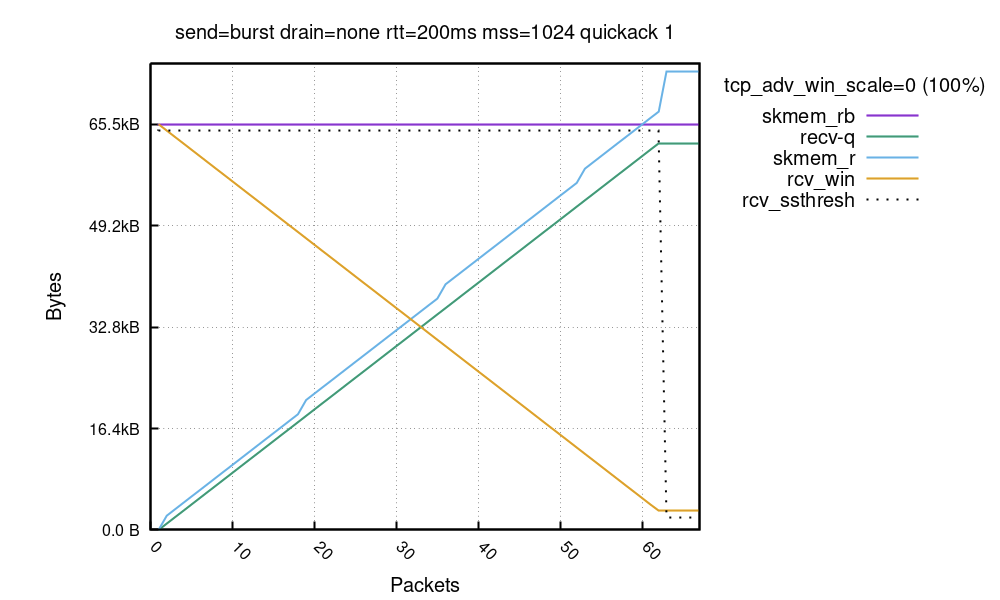
事情比较纷繁复杂,我们试着捋一捋。首先,X 轴是入口数据包数量(我们看到大约为 65)。Y 轴显示每个数据包的接收路径上所见的缓冲区大小。
- 首先,紫线是以字节为单位的缓冲区大小限值 - skmem_rb。在我们的试验中,我们调用了
setsockopt(SO_RCVBUF)=32K,skmem_rb 是该值的两倍。请注意,通过调用 SO_RCVBUF,我们禁用了 Linux 自动调整机制。 - 绿线 recv-q 表示接收套接字中可用的应用程序字节数。它会随着接收的每个数据包而线性增长。
- 接着是蓝色的 skmem_r,表示接收套接字中的已用数据和元数据开销。它就像 recv-q 一样增长,但稍快一些,因为它涵盖了内核需要处理的元数据开销。
- 橙色的 rcv_win 是公告窗口。我们从 64KiB(skmem_rb 的 100%)开始,并随着数据的到来而下降。
- 最后,虚线显示 rcv_ssthresh,暂时别管它,后面会提到。
超出预算很不好
请特别注意,最终 skmem_r 高于 skmem_rb!这个结果令人大感意外,也不能接受。采用 skmem_rb 内存预算的根本意义就是避免超出预算。下面是 ss 的显示情况:
$ ss -m
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
tcp ESTAB 62464 0 127.0.0.3:1234 127.0.0.2:1235
skmem:(r73984,rb65536,...)
可以看到,skmem_rb 是 65536,而 skmem_r 是 73984,超出了 8448 字节!发生这种情况时,我们面临一个更大的问题。在大约第 62 个数据包处,公告窗口为 3072 字节,虽然不断在发送数据包,但接收端却无法处理它们!要验证这一点很容易,只需查看 nstat TcpExtTCPRcvQDrop 计数器:
$ nstat -az TcpExtTCPRcvQDrop
TcpExtTCPRcvQDrop 13 0.0
在我们的运行中,有 13 个数据包被丢弃。此变量计算的是由于系统范围或逐个套接字的内存压力而丢弃的数据包数量,我们发现实际发生的是第二种情况。在我们的案例中,逾越套接字内存限制后,新的数据包就无法排队进入套接字。尽管 TCP 公告窗口仍开放,还是发生了这种情况。
这就带来一个比较有意思的现象。接收端的窗口是打开的,这可能表明它有资源来处理数据。但也并非总是如此,比如在我们的例子中,它耗尽了内存预算。
发送端会认为自己遭遇了网络拥塞丢包,并运行通常的重试机制,包括指数退避。这种行为是否可取,取决于观察角度。一方面,不会丢失任何数据,发送端最终会可靠地传递所有字节。另一方面,指数退避逻辑可能导致发送端长时间停滞,从而造成明显的延迟。
问题根源很简单明了,就是 Linux 内核 skmem_rb 同时为套接字中的数据和元数据设置了内存预算。在悲观的情况下,每个数据包可能产生一个 struct sk_buff + struct skb_shared_info 的开销,这在我的系统上是 576 字节,超出了实际有效负载大小,加上由于网卡缓冲区对齐而产生的内存浪费:

现在我们明白了,Linux 不能直接将 100% 的内存预算作为公告窗口进行公告。一些预算必须保留用于元数据等。窗口大小的上限表示为“空闲”套接字预算的比例。它受 tcp_adv_win_scale 控制,其值如下:
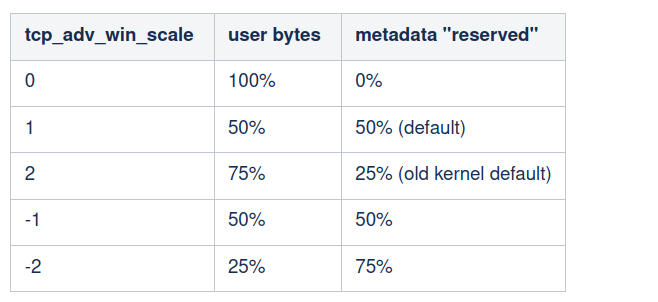
默认情况下,Linux 将公告窗口设置为不超过 50% 的剩余缓冲区空间。
即使将 50% 的空间“预留”给元数据,内核仍然很智能,会竭力减轻元数据内存占用量。为此,它可采用两种机制:
- TCP 合并 - 正常情况下,Linux 能够扔掉 struct sk_buff。具体做法可以是直接将数据链接到之前排队的数据包。不妨将其视为扩展套接字上的最后一个数据包。
- TCP 折叠 - 达到内存预算时,Linux 会运行“折叠”代码。折叠代码会对接收缓冲区进行重写和碎片整理,将其从许多小 skb 转变为少数几个非常长的分段,从而降低元数据开销。
下面扩展了我们之前的图表,展示这些机制的运行过程:
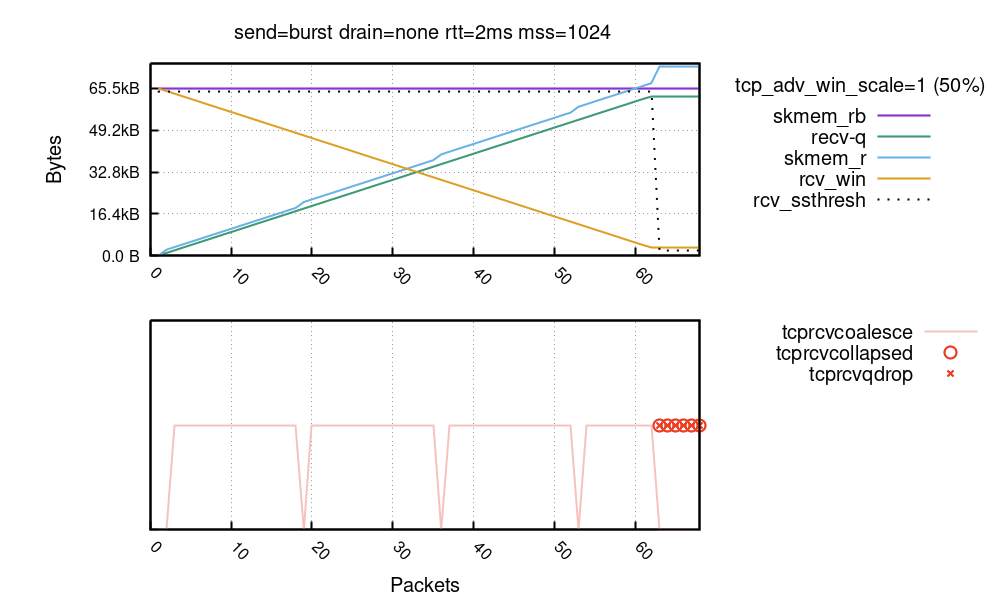
TCP 合并是非常有效的措施,始终在幕后运行。在底部图表中,开展合并的数据包以粉色线表示。可以看到,skmem_r 凸块(蓝线)很明显与缺乏合并(粉色线)有关!而 nstat TcpExtTCPRcvCoalesce 计数器很可能有助于调试合并问题。
TCP 折叠的效力更强。Mike 对此有过详述,我在多年前也写过博客文章,那时 TCP 折叠的延迟很高,让我们吃尽了苦头。在上面的图表中,折叠显示为红圆圈。可以清楚地看到,达到套接字内存预算之后,即从数据包编号 63 开始,就进行了折叠。这里,nstat TcpExtTCPRcvCollapsed 计数器恰好适用。该值继续增长不是好现象,可能表示有恶劣的延迟激增情况,尤其是在处理较大的缓冲区时。通常,折叠应当很少运行。一位杰出的内核开发人员描述了这种悲观情况:
这也意味着,TCP 为给定分配的 rcvspace 公告了过于乐观的窗口:收到帧时,sk_rmem_alloc可能达到sk_rcvbuf限值,我们也可能过于频繁地调用tcp_collapse(),尤其是在应用程序清空接收队列太慢的情况下 [...] 这是一个主要的延迟来源。
如果内存预算在折叠后仍然被耗尽,Linux 将丢弃入口数据包。在我们的图表中,将其标记为红色的“X”。nstat TcpExtTCPRcvQDrop 计数器显示了丢弃的数据包数量。
rcv_ssthresh 预测元数据开销
一个数据包的内存开销可能远大于其中包含的实际应用程序数据量,这一点也许比较反直觉。这取决于以下几个因素:
- 网卡:一些网卡总是为每个数据包分配一整页(4096,甚至 16KiB),无论有效负载是大是小。
- 有效负载大小:数据包越短小,元数据与内容的比率越不利,因为 struct skb 会相应更大。
- 是否使用了 XDP。
- L2 头大小:以太网、VLAN Tag 标记和隧道等可能会累积得很大。
- 缓存行大小:许多内核 struct 都瞄准缓存行。在缓存行较大的系统上,它们会使用更多内存(参见 P4 或 S390X 体系结构)。
前两个因素最重要。下面的运行中,专门将发送端配置为造成高昂的元数据开销并使合并无效(设置的细节很乱):
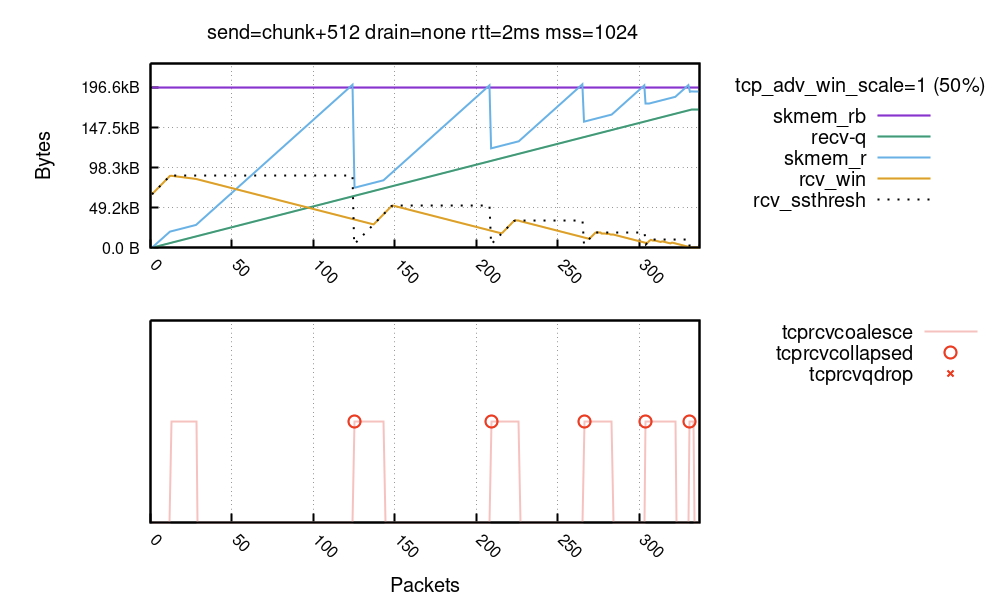
您可以看到内核多次达到 TCP 折叠,这完全不可取。每次折叠内核都很可能重写完整的接收缓冲区。这整个内核机制,从利用 tcp_adv_win_scale 为元数据预留一些空间,通过使用合并来降低每个数据包的内存开销,一直到 rcv_ssthresh 限值,其目的都是为了避免发生过于频繁达到折叠的这种情况。
内核机制往往没什么问题,TCP 折叠在实践中也很少发生。但是,我们注意到,对于特定类型的流量,情况并非如此。一个例子是 WebSocket 流量中有大量小数据包,而读取器速度很慢。有一条内核注释谈到了这种情况:
* The scheme does not work when sender sends good segments opening
* window and then starts to feed us spaghetti. But it should work
* in common situations. Otherwise, we have to rely on queue collapsing.
请注意,rcv_ssthresh 线在 TCP 折叠时下降。此变量是公告窗口的内部限值。下降行为实际上表示内核是这么判断的:且住,数据包开销预测失误了,下次有机会时,得打开一个更小的窗口。内核会公告更小的窗口,并且会更加仔细,所有这一切都是为了避免折叠。
正常运行 - 持续更新的窗口
最后,下面是连接正常运行产生的图表。这里,我们使用了默认值 tcp_adv_win_wcale=1 (50%):
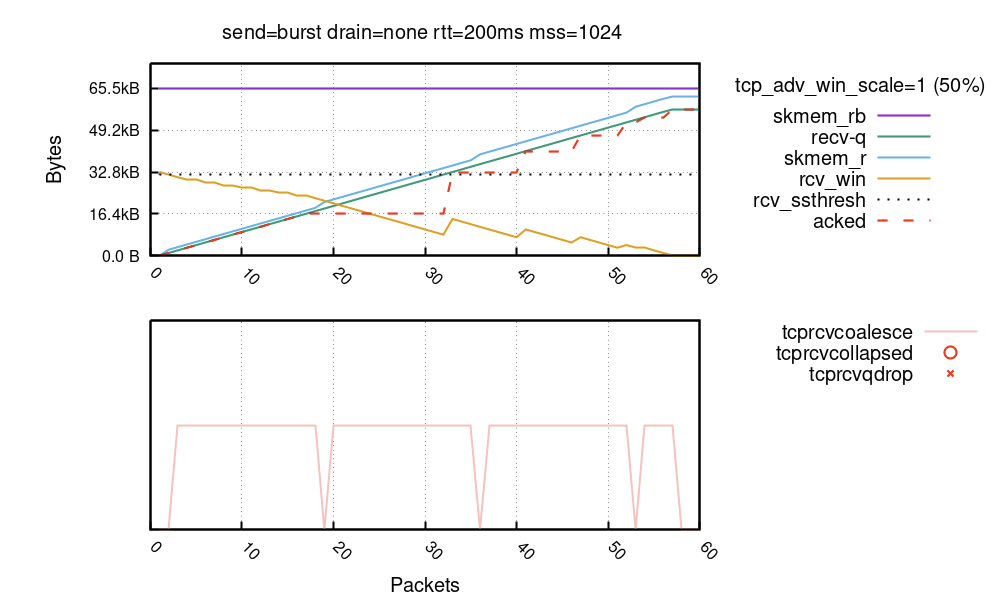
在连接早期,可以看到 rcv_win 会随着每个接收的数据包持续更新。这样做是合理的:虽然 rcv_ssthresh 和 tcp_adv_win_scale 将公告窗口限制为绝不超过 32KiB,但只要有足够空间,窗口就能顺畅滑动。在第 18 个数据包处,接收端停止更新窗口并稍等片刻。在第 32 个数据包处,接收端判定仍有一些空间,并再次更新窗口,以此类推。在流的末尾,套接字有 56KiB 的数据。这 56KiB 的数据是在滑动窗口内接收的,最高达到 32KiB。
rcv_win 的锯齿模式由延迟 ACK(也称为 QUICKACK)启用。您可以看到 “acked” 字节带有红色虚线。由于 ACK 可能被延迟,接收端会等待片刻,然后更新窗口。如果您希望线条流畅,可以使用 quickack 1 逐个路由的参数,但不推荐这样做,因为会导致许多小的 ACK 数据包在网络中传输。
在正常的连接中,我们预期大部分数据包会合并,并且绝不会达到折叠/下降代码路径。
大型接收窗口 - rcv_ssthresh
对于通过高延迟链路(BDP 很大的情况)进行的大带宽传输,设置非常宽的公告窗口很有利。但是,Linux 完全打开大型接收窗口需要一些时间:
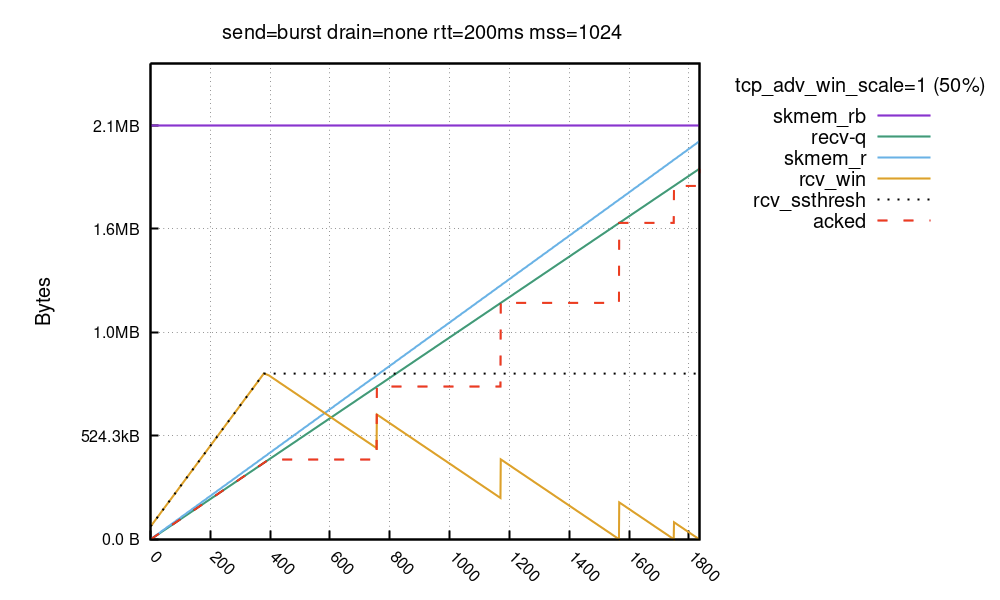
在此运行中,将 skmem_rb 设置为 2MiB。与之前的运行不同的是,缓冲区预算很大,并且接收窗口并未从 50% 的 skmem_rb 开始!而是从 64KiB 开始,并线性增长。Linux 需要一些时间才能将接收窗口增加到完整大小,在本例中大约为 800KiB。窗口受 rcv_ssthresh 限制。此变量开始于 64KiB,然后以每个数据包对应两个完整 MSS 数据包的速度增长,这样总大小 (truesize) 与有效负载大小的比率就能达到“良好”状态。
Eric Dumazet 介绍了这种行为:
堆栈对于 RWIN 增加比较保守,它想接收数据包来大致了解 skb->len/skb->truesize 比率,以便将内存预算转换为 RWIN。
有些驱动程序必须分配 16K 的缓冲区(甚至是 32K 的缓冲区),才刚好够保存一个分段(有效负载小于 1500 字节),而另一些驱动程序则能够更高效地打包内存。
这种缓慢打开窗口的行为是固定的,无法在 vanilla 内核中配置。我们准备了内核补丁,允许一开始使用更高的 rcv_ssthresh,具体基于逐个路由的选项 initrwnd:
$ ip route change local 127.0.0.0/8 dev lo initrwnd 1000
部署补丁和路由更改后,缓冲区如下所示:
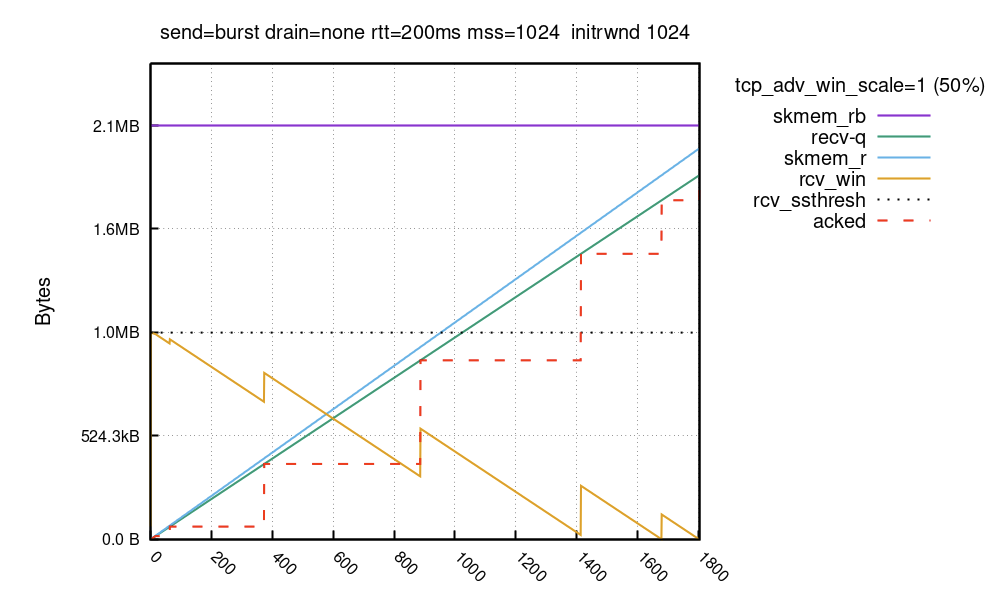
公告窗口在 TCP 握手期间仅限于 64KiB,但启用我们的内核补丁后,它此后很快会在第一个 ACK 数据包中增加到 1MiB。在两次运行中,填满接收缓冲区大约需要 1800 个数据包,但所用时间不同。在第一次运行中,发送端只能将 64KiB 推送到第二个 RTT 的线路中。在第二次运行中,可以立即推送完整 1MiB 的数据。
对于大部分用户来说,这种激进式窗口打开方式其实都没有必要。这种方式只有在以下情况下才有用:
- 您要通过高延迟链路进行高带宽的 TCP 传输。
- 您 NIC 的元数据和缓冲区对齐开销合理、可预测。
- 在流开始之后,您的应用程序立即做好准备,可发送大量数据。
- 发送端配置了大型
initcwnd。
您竭力想削减每个可能的 RTT。
在我们的系统上,我们确实有这样的流,但按理说,这可能不是常见的场景。在现实世界,您的大部分 TCP 连接会接入最接近的 CDN 入网点,它会离得非常近。
总结
在本博客文章中,我们讨论了看似简单的 TCP 发送端填满接收套接字的情况。我们试图解决两个问题:利用我们的独立设置,可以发送多少数据,速度有多快?
利用 net.ipv4.tcp_rmem 的默认设置,Linux 最初会为接收数据和元数据设置 128KiB 的内存预算。在我的系统上,给定完整大小的数据包,就能够最终接受大约 113KiB 的应用程序数据。
然后,我们展示了接收窗口并未立即完全打开。Linux 使接收窗口保持较小,因为它会试图预测元数据开销并避免超出内存预算,进而达到 TCP 折叠。默认情况下,利用 net.ipv4.tcp_adv_win_scale=1,公告窗口的上限是“空闲”内存的 50%。rcv_ssthresh 一开始使用 64KiB,并线性增长到该限值。
在我的系统上,填满 128KiB 接收缓冲区用了五个窗口更新,总共六个 RTT。在第一个批次中,发送端发送了大约 64KiB 的数据(别忘了,我们之前修改了 initcwnd 限值),然后发送端用越来越小的批次来填满,直至接收窗口完全关闭。
我希望本博客文章可带来帮助,能够很好地解释 Linux 上缓冲区大小和公告窗口之间的关系。此外,还介绍了常常被误解的 rcv_ssthresh,后者限制了公告窗口,以便管理内存预算,并预测元数据难以预测的开销。
您需要知道的是,QUIC 中也采用了类似的机制。但是,QUIC/H3 库仍不够成熟,目前还不具备足够多的复杂而神秘的开关。一如既往地,我们的 GitHub 中提供了关于如何重现图表的代码和说明。