HTTP es el protocolo de aplicación que impulsa la web. Inició sus pasos conociéndose como protocolo HTTP/0.9 en 1991 y para 1999 había evolucionado a HTTP/1.1, que se estandarizó en el IETF (Internet Engineering Task Force o, en español, Grupo de Trabajo de Ingeniería de Internet). HTTP/1.1 bastó durante mucho tiempo, pero las necesidades siempre cambiantes de la web requerían un protocolo más adecuado y HTTP/2 surgió en el año 2015. Más recientemente, se anunció que el IETF tenía la intención de lanzar una nueva versión: HTTP/3. Para algunas personas ha sido una sorpresa y ha causado algo de confusión. Si no se sigue de cerca el trabajo del IETF, podría parecer que HTTP/3 ha salido de la nada. Sin embargo, podemos rastrear sus orígenes a través de una serie de experimentos y de la evolución de los protocolos web; específicamente el protocolo de transporte QUIC.
Si no conoces QUIC, mis compañeros han hecho un gran trabajo que lo aborda desde diferentes ángulos. El blog de John describe algunas complicaciones que HTTP trae hoy en la vida real; el blog de Alessandro aborda los detalles esenciales de la capa de transporte y el blog de Nick trata sobre cómo realizar algunas pruebas en la práctica. Hemos recopilado estos y más en https://cloudflare-quic.com. Y si el tema te interesa, no olvides mirar quiche, nuestra propia implementación de código abierto del protocolo QUIC escrita en Rust.
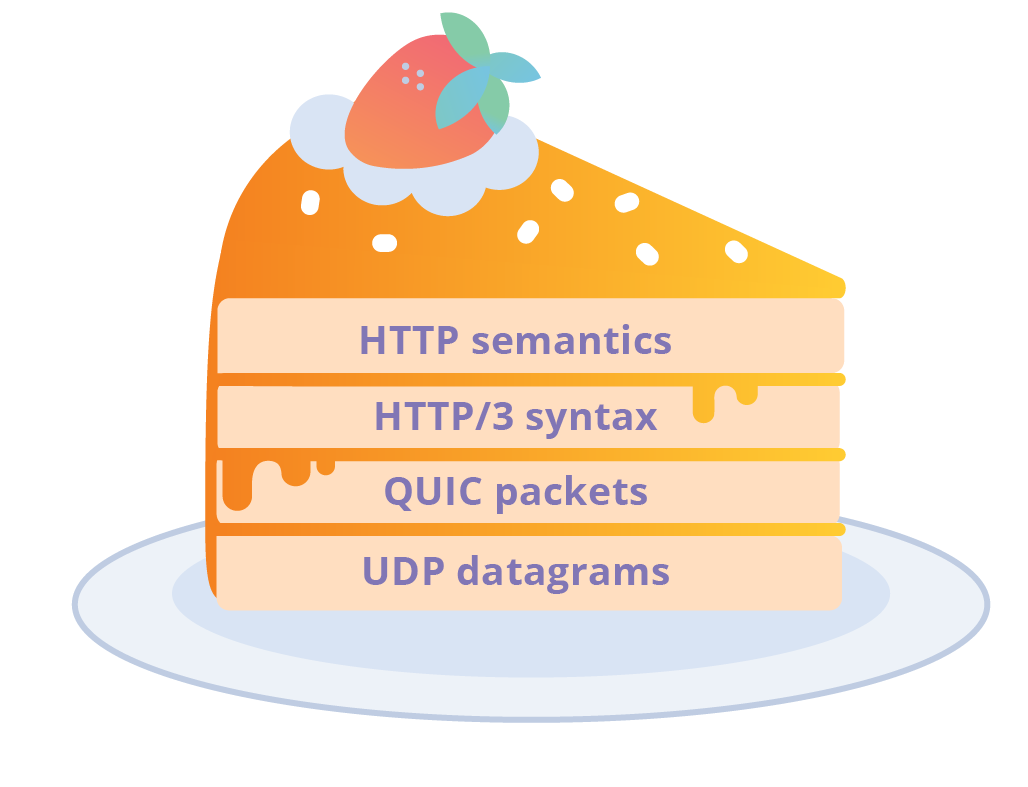
HTTP/3 es la asignación de aplicación HTTP a la capa de transporte QUIC. Este nombre se hizo oficial en la versión 17, la más reciente del borrador (draft-ietf-quic-http-17), propuesta a finales de octubre de 2018, con la discusión y consenso aproximado de la reunión 103 del IETF en Bangkok en noviembre. HTTP/3 era conocido previamente como HTTP sobre QUIC, que antes era conocido como HTTP/2 sobre QUIC. Antes de eso, tuvimos HTTP/2 sobre gQUIC y mucho antes tuvimos SPDY sobre gQUIC. La verdad, sin embargo, es que HTTP/3 es solo una nueva sintaxis HTTP que funciona en IETF QUIC, un transporte multiplexado y seguro basado en UDP.
En esta publicación del blog exploraremos la historia de algunos de los nombres anteriores de HTTP/3 y presentaremos el motivo del último cambio de nombre. Regresaremos a los inicios de HTTP y aludiremos al buen trabajo que se ha hecho en el camino. Si te interesa una visión completa de ello, puedes saltar hasta el final del artículo o abrir esta versión SVG muy detallada.
{kind=link}
Nos ponemos en situación
Antes de que nos centremos en HTTP, merece la pena recordar que hay dos protocolos que comparten el nombre QUIC. Como ya explicamos antes, gQUIC se utiliza comúnmente para identificar a Google QUIC (el protocolo original) y QUIC se utiliza comúnmente para referirse a la versión estándar en desarrollo del IETF que se desvía de gQUIC.
Desde sus inicios en los años 90, las necesidades de la web han cambiado. Hemos tenido nuevas versiones de HTTP y hemos añadido seguridad del usuario mediante la Seguridad de la capa de transporte (Transport Layer Security o TLS por sus siglas en inglés). Solo mencionaremos la TLS en este post; nuestras otras publicaciones del blog son un gran recurso si quieres profundizar en el tema.
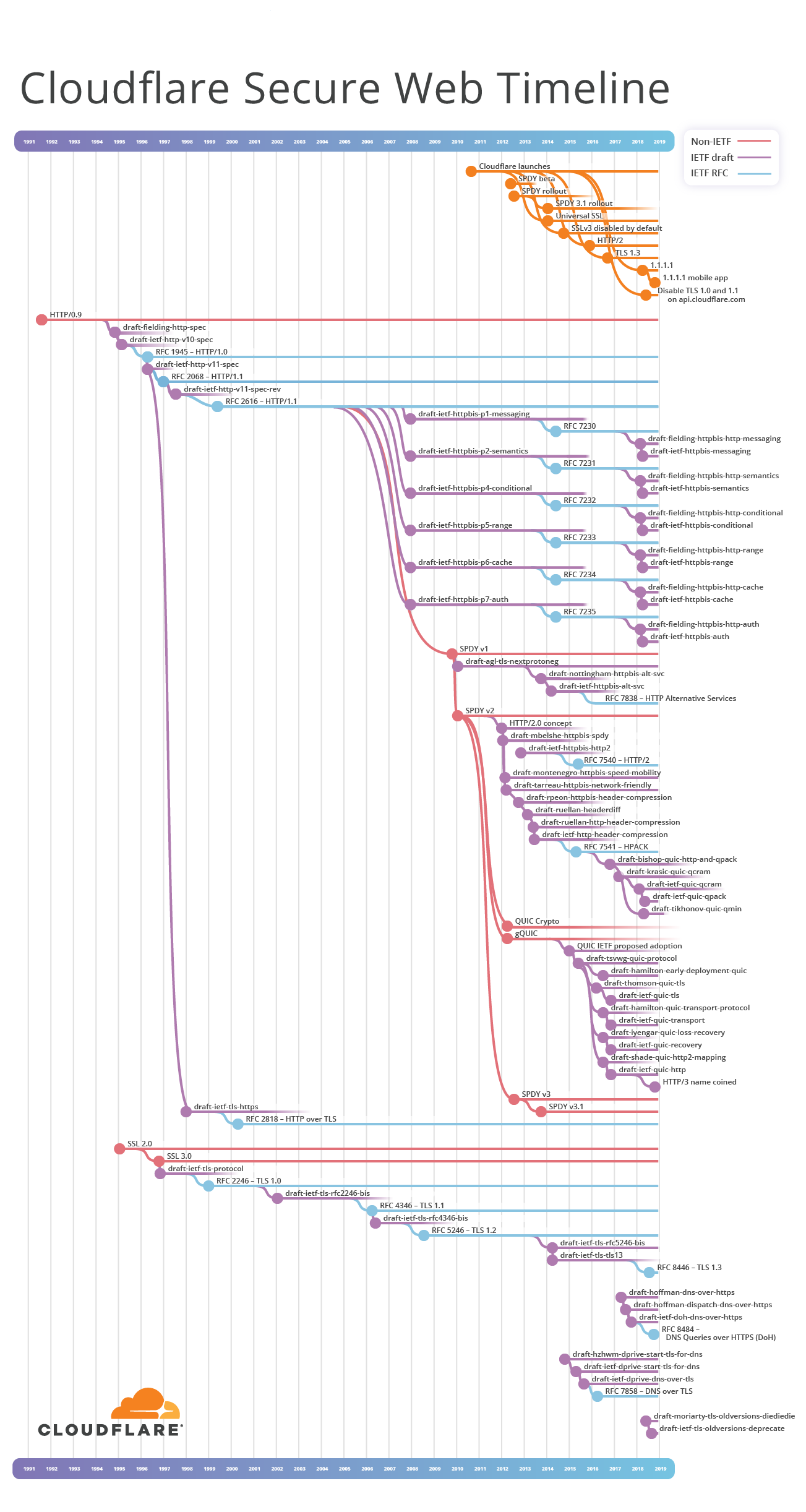
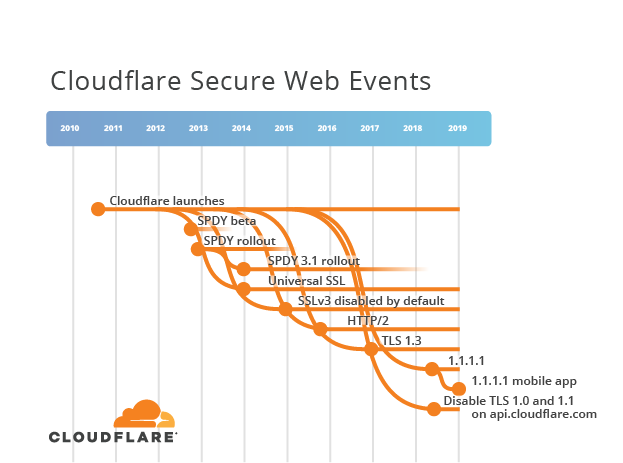
Para explicar mejor la historia de HTTP y TLS, empecé a recopilar información de las especificaciones y las fechas del protocolo. Esta información se presenta generalmente en forma textual como una lista de elementos que indican títulos de documentos, ordenados por fecha. Sin embargo, hay estándares que se ramifican, que se superponen en el tiempo, así que una simple lista no puede mostrar la verdadera complejidad de las relaciones. En HTTP, ha habido trabajo paralelo que refactoriza las definiciones básicas del protocolo para facilitar el consumo, que amplía el protocolo a nuevos usos y que redefine cómo el protocolo intercambia datos en Internet para un mayor rendimiento. Cuando se trata de unir los puntos de casi 30 años de historia de Internet a través de diferentes flujos de trabajo ramificados hace falta visualizarlos. Y eso fue lo que hice: creé la Cronología de la web segura de Cloudflare. (Nota: técnicamente es un cladograma, pero el término cronología es más conocido).
Me he tomado algunas licencias artísticas al crearla, centrándome en las ramificaciones con éxito en el espacio del IETF. Algunas de las cosas que no se muestran son la labor del Grupo de Trabajo de HTTP-NG del Consorcio W3, junto con algunas ideas extrañas cuya pronunciación les encanta explicar a sus autores: HMURR (pronunciado "hammer") y WAKA (pronunciado "waka").
En las siguiente secciones recorreré esta cronología para explicar capítulos importantes de la historia de HTTP. Para disfrutar de las lecciones de este post, conviene saber apreciar los beneficios de la estandarización y cómo la aborda el IETF. Por lo tanto, comenzaremos con un breve resumen de este tema antes de regresar a la cronología. No dudes en saltar a la próxima sección si ya conoces el IETF.
Tipos de estándares de Internet
Generalmente, los estándares definen términos comunes de referencia, alcance, restricciones, aplicabilidad y otras consideraciones. Existen estándares de muchas formas y tamaños, que puede ser informales (también conocidos como de facto) o formales (acordados/publicados por un organismo de normalización de estándares como IETF, ISO o MPEG). Los estándares se utilizan en muchas áreas, incluso hay un estándar británico formal para preparar té: BS 6008.
La web inicialmente utilizaba las definiciones de protocolo HTTP y SSL que fueron publicadas fuera del IETF y se marcan como líneas rojas en la Cronología de la web segura. La adopción de estos protocolos por parte de clientes y servidores los convirtió en estándares de facto.
En algún momento, se decidió formalizar estos protocolos (algunas de las razones para ello se describen en una sección posterior). Los estándares de Internet se definen comúnmente en el IETF, que se guía por el principio informal de "consenso aproximado y código en ejecución". Este se basa en la experiencia de desarrollar y desplegar cosas en Internet. Contrasta además con el enfoque de "sala limpia", que trata de desarrollar protocolos perfectos de forma aislada.
Los estándares de Internet del IETF se conocen comúnmente como RFC (Request for Comments o, en español, Petición de comentarios). Es algo complejo de explicar, por lo que recomiendo leer la publicación del blog "Cómo leer una RFC" del copresidente del Grupo de trabajo de QUIC Mark Nottingham. Un Grupo de trabajo es más o menos una lista de correo.
Cada año, el IETF celebrar tres reuniones donde se pone a disposición de los Grupos de trabajo el momento y el lugar para conocerse en persona si así lo desean. La agenda para esas semanas puede estar muy llena, con escaso tiempo disponible para discutir en profundidad las áreas muy técnicas. Para compensar eso, algunos Grupos de trabajo realizan también reuniones intermedias además de las reuniones generales del IETF. Así se contribuye a mantener el impulso en el desarrollo de especificaciones. El Grupo de Trabajo de QUIC ha celebrado varias reuniones intermedias desde 2017. Se puede acceder a la lista completa en su página de reuniones.
Estas reuniones del IETF también son oportunidades para que otras agrupaciones de personas relacionadas con el IETF se reúnan, como el Consejo de arquitectura de Internet o el Grupo de trabajo de investigación de Internet. En los últimos años, se ha celebrado un Hackathon del IETF el fin de semana anterior a la reunión del IETF. Con ello, se da una oportunidad para que la comunidad desarrolle código en ejecución y, también importante, para que se realicen pruebas de interoperabilidad en la misma sala con otras personas. Eso permite encontrar problemas en especificaciones, que pueden discutirse los días siguientes.
Para los propósitos de este blog, lo que conviene entender es que las RFC no salen de la nada. Mejor dicho, pasan por un proceso que generalmente comienza con un borrador de Internet (Internet Draft o I-D) del IETF que se considera para su adopción. En casos donde ya hay una especificación publicada, la preparación de un borrador de Internet podría ser un simple ejercicio de reformateo. Los borradores de Internet están activos seis meses a partir de la fecha de publicación. Para mantenerlos activos, deben publicarse nuevas versiones. En la práctica, no sucede nada si se deja que un borrador de Internet se pase, pues ocurre muy a menudo. Los documentos continúan alojados en el sitio web de documentos del IETF para que cualquiera pueda leerlos.
Los borradores de Internet aparecen en la Cronología de la web segura representados como líneas violetas. Cada uno tiene un único nombre formado por proyecto-{nombre de autor}-{grupo de trabajo}-{tema}-{versión}. El campo del Grupo de trabajo es opcional, puede predecir el grupo del IETF que trabajará en el borrador y a veces puede cambiar. Si un borrador de Internet es aprobado por el IETF, o si el borrador se inició directamente en el IETF, el nombre es draft-ietf-{grupo de trabajo}-{tema}-{versión}. Los borradores de Internet pueden ramificarse, fusionarse o caer en saco roto. La versión empieza con 00 y aumenta en 1 cada vez que se lanza un nuevo borrador. Por ejemplo, la cuarta versión de un borrador de Internet será la versión 03. Cada vez que se cambia el nombre de un borrador de Internet, su versión se reinicia con 00.
Es importante tener en cuenta que cualquier persona puede presentar un borrador de Internet para el IETF; estos no deben considerarse como normas. Sin embargo, si el proceso de estandarización de un borrador de Internet por parte del IETF no llega a un consenso y el documento final pasa a revisión, finalmente se llega a una RFC. El nombre se cambia de nuevo en esta etapa. Cada RFC tiene un número exclusivo, por ejemplo, RFC 7230. Estos se representan mediante líneas azules en la Cronología de la web segura.
Las RFC son documentos inmutables. Por ello, los cambios en una RFC requieren un número completamente nuevo. Se podrían hacer cambios para incorporar correcciones de erratas (errores editoriales o técnicos que se encontraron y registraron) o simplemente para refactorizar la especificación para mejorar el diseño. Las RFC pueden dejar obsoletas versiones anteriores (sustitución completa), o simplemente actualizarlas (cambiarlas sustancialmente).
Todos los documentos del IETF están disponibles al público en http://tools.ietf.org. Personalmente, me parece que el Rastreador de datos del IETF es un poco más intuitivo, ya que permite visualizar el avance de los documentos, desde el borrador de Internet hasta la RFC.
A continuación hay un ejemplo que muestra el desarrollo de la RFC 1945-HTTP/1.0 y es una clara fuente de inspiración de la Cronología de la web segura.
Curiosamente, a lo largo de mi trabajo me di cuenta de que el diagrama anterior es incorrecto. Falta draft-ietf-http-v10-spec-05 por alguna razón. Puesto que la duración de un borrador de Internet es de 6 meses, parece que hay un lapso antes de que se convierta en una RFC, mientras que en realidad el borrador 05 siguió activo hasta agosto de 1996.
Explorar la Cronología de la web segura
Tras esta pequeña apreciación de cómo los documentos de los estándares de Internet llegan a buen término, podemos comenzar a recorrer la Cronología de la web segura. En esta sección hay una serie de extractos de diagramas que muestran una parte importante de la cronología. Cada punto representa la fecha cuando un documento o capacidad empezó a estar disponible. En los documentos del IETF, los números del borrador se omiten para mayor claridad. Sin embargo, si quieres ver todos los datos, mira la Cronología completa.
Cuando empezó HTTP en 1991, se conocía como protocolo HTTP/0.9 y en 1994 se publicó el borrador de Internet draft-fielding-http-spec-00. Este fue aprobado por el IETF poco después, lo que provocó el cambio de nombre a draft-ietf-http-v10-spec-00. Hubo seis versiones del borrador de Internet antes de que se publicara como RFC 1945-HTTP/1.0 en 1996.
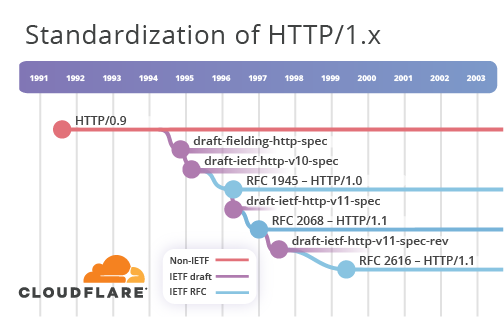
Sin embargo, incluso antes de que el trabajo del HTTP/1.0 concluyera, se inició la actividad para el HTTP/1.1. separadamente. El borrador de Internet draft-ietf-http-v11-spec-00 se publicó en noviembre de 1995 y se publicó formalmente como RFC 2068 en 1997. Los más atentos se darán cuenta de que la Cronología de la web segura no recoge completamente la secuencia de eventos; es un desafortunado efecto secundario de las herramientas usadas para generar el diagrama. He tratado de minimizar estos problemas cuando era posible.
Un ejercicio de revisión de HTTP/1.1 se inició a mediados de 1997 en el draft-ietf-http-v11-spec-rev-00. Terminó en 1999 con la publicación de la RFC 2616. Las cosas se calmaron en el mundo del HTTP del IETF hasta 2007. Volveremos a eso más adelante.
Una historia de SSL y TLS
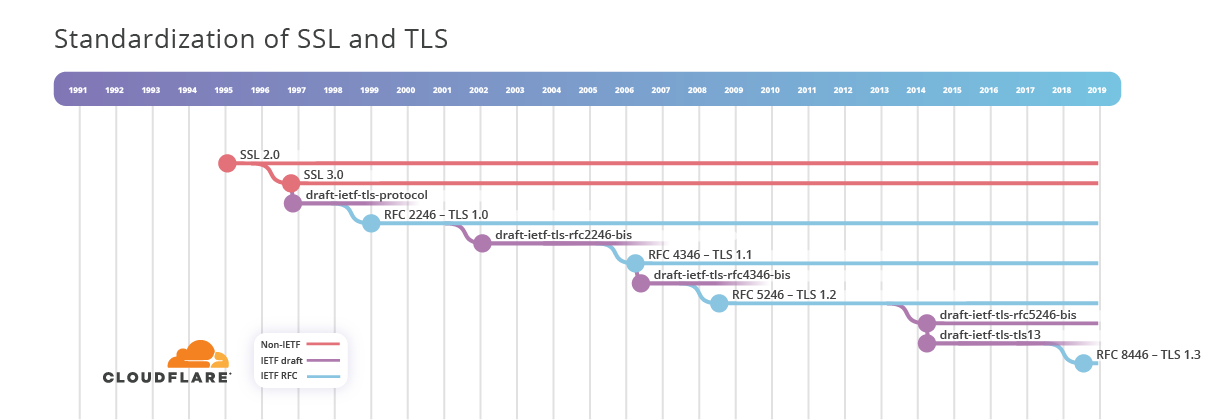
Cambiamos ahora a SSL. Vemos que la especificación de SSL 2.0 se lanzó en algún momento de 1995 y SSL 3.0 se lanzó en noviembre de 1996. Curiosamente, SSL 3.0 se describe en la RFC 6101, publicada en agosto de 2011. Se encuentra en la categoría Histórico, que "normalmente se usa para ideas de documentos que fueron considerados y descartados, o protocolos que ya eran históricos cuando se decidió documentarlos", según el IETF. En este caso, conviene tener un documento propio del IETF que describa SSL 3.0, porque puede utilizarse como referencia canónica en otros lugares.
Para nosotros, tiene más interés cómo SSL inspiró el desarrollo de TLS, que vio la luz como draft-ietf-tls-protocol-00 en noviembre de 1996. Se hicieron 6 versiones y se publicó como RFC 2246-TLS 1.0 a principios de 1999.
Entre 1995 y 1999, se utilizaron los protocolos SSL y TLS para asegurar comunicaciones HTTP en Internet. Funcionó bien como estándar de facto. No fue hasta enero de 1998 cuando el proceso de normalización formal para HTTPS se inició con la publicación del borrador de Internet draft-ietf-tls-https-00. El trabajo concluyó en mayo de 2000 con la publicación de la RFC 2616-HTTP sobre TLS.
TLS continuó evolucionando entre 2000 y 2007, con la estandarización de TLS 1.1 y 1.2. Hubo un lapso de 7 años hasta que comenzó el trabajo de la siguiente versión de TLS, que se aprobó como draft-ietf-tls-tls13-00 en abril del de 2014 y, después de 28 borradores, se completó con la RFC 8446-TLS 1.3 en agosto de 2018.
Proceso de estandarización de Internet
Después de haberle echado un vistazo a la cronología, espero que tengas una idea de cómo funciona el IETF. Una generalización de la manera en que los estándares de Internet toman forma es que los investigadores o ingenieros diseñan protocolos experimentales que se adaptan a su caso de uso específico. Experimentan con los protocolos, en público o en privado, a diversos niveles de escala. Los datos contribuyen a identificar mejoras o problemas. El trabajo puede publicarse para explicar el experimento, obtener más valoraciones o tratar de encontrar más implementadores. Si el trabajo inicial se asume por parte de otros, puede convertirse en estándar de facto; finalmente puede haber suficiente impulso para que haya opción de estandarización formal.
El estado de un protocolo puede ser una consideración importante para las organizaciones que estarían planteándose implementarlo, desplegarlo o usarlo de alguna manera. Un proceso de estandarización formal puede hacer un estándar de facto más atractivo porque tiende a dar estabilidad. La administración y la guía las proporciona una organización, como el IETF, que refleja experiencias muy diferentes. Sin embargo, cabe destacar que no todos los estándares formales tienen éxito.
El proceso de creación de un estándar final es casi tan importante como el propio estándar. Tomar una idea inicial y fomentar la contribución de personas con conocimientos, experiencia y casos de uso más amplios puede contribuir a producir algo que sea de más utilidad para una población más extensa. Sin embargo, el proceso de estandarización no siempre es fácil. Hay trampas y obstáculos. A veces el proceso toma tanto tiempo que el resultado ya no es relevante.
Cada organización de definición de estándares tiende a tener su propio proceso orientado alrededor de su campo y sus participantes. Explicar todos los detalles del funcionamiento del IETF va más allá del alcance de este blog. La página "Cómo trabajamos" del IETF es un excelente punto de partida que trata muchos aspectos. Como de costumbre, la mejor manera de hacerse una idea es implicarse personalmente. Es tan fácil como unirse a una lista de correo o participar en la discusión de un repositorio de GitHub pertinente.
Código en ejecución de Cloudflare
Cloudflare se enorgullece de haber adoptado tempranamente protocolos nuevos y cambiantes. Tenemos un largo historial de adopción de nuevos estándares, como HTTP/2. También probamos funciones experimentales o aún no definitivas, como TLS 1.3 y SPDY.
En relación con el proceso de estandarización del IETF, desplegar código en ejecución en redes reales a través de un conjunto diverso de sitios web nos ayuda a entender cómo funcionará el protocolo en la práctica. Combinamos nuestros conocimientos actuales con información experimental para ayudar a mejorar el código en ejecución y, si es necesario, las respuestas a problemas o las mejoras del Grupo de trabajo que está estandarizando un protocolo.
Probar cosas nuevas no es la única prioridad. Una parte de ser innovadores consiste en saber cuándo es el momento de avanzar y poner innovaciones anteriores en perspectiva. A veces, eso se relaciona con protocolos orientados a la seguridad, por ejemplo, el SSLv3 de Cloudflare desactivado por defectodebido a la vulnerabilidad de POODLE. En otros casos, los protocolos se reemplazan por otros más avanzados tecnológicamente; Cloudflare dejó en desuso SPDY en favor de HTTP/2.
La introducción y el abandono de los protocolos correspondientes se representa en la Cronología de la web segura con líneas naranjas. Las líneas punteadas verticales ayudan a correlacionar los eventos de Cloudflare con los documentos relevantes del IETF. Por ejemplo, Cloudflare introdujo soporte TLS 1.3 en septiembre de 2016, mientras que el documento final, RFC 8446, se publicó casi dos años después, en agosto de 2018.
Refactorizar en HTTPbis
HTTP/1.1 es un protocolo muy acertado y la Cronología muestra que no hubo mucha actividad en el IETF después de 1999. Sin embargo, la verdad es que los años de uso activo proporcionaron la experiencia de implementación que desveló problemas latentes en la RFC 2616, que causaban algunos problemas de interoperabilidad. Además, el protocolo se extendió a otras RFC, como la 2817 y la 2818. Se decidió en 2007 impulsar una nueva actividad para mejorar la especificación del protocolo HTTP. Se llamó HTTPbis ("bis" en latín significa "dos", "dos veces" o "repetición") y tomó la forma de un nuevo Grupo de trabajo. El cuadro original es bastante claro en su descripción de los problemas que se intentaban resolver.
En definitiva, HTTPbis optó por refactorizar la RFC 2616. Incorporaría correcciones de erratas e incluiría algunos elementos de otras especificaciones que habían sido publicadas mientras tanto. Se decidió dividir el documento en partes. Esto dio lugar a 6 borradores de Internet publicados en diciembre de 2007:
- draft-ietf-httpbis-p1-messaging
- draft-ietf-httpbis-p2-semantics
- draft-ietf-httpbis-p4-conditional
- draft-ietf-httpbis-p5-range
- draft-ietf-httpbis-p6-cache
- draft-ietf-httpbis-p7-auth
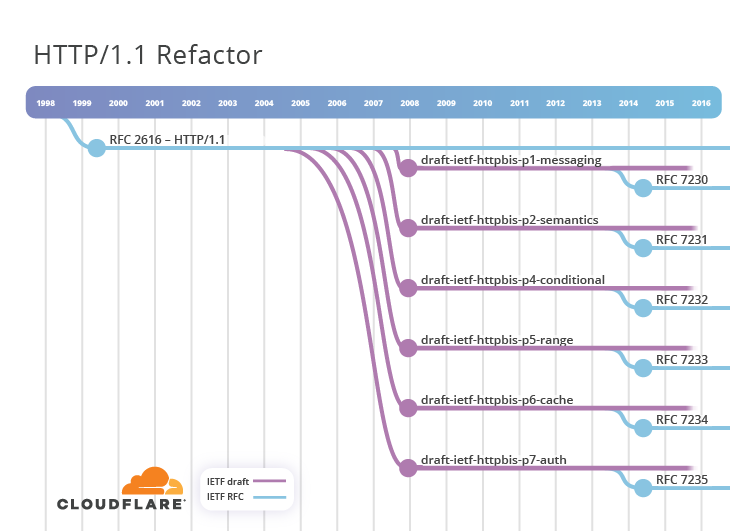
El diagrama muestra cómo este trabajo avanzó a lo largo de un prolongado proceso de redacción de 7 años, con 27 versiones publicadas, antes de la estandarización final. En junio de 2014, se lanzó la llamada serie RFC 723x (donde la x iba de 0 a 5). El presidente del Grupo de trabajo de HTTPbis celebró este logro con la aclamación: "la RFC2616 ha muerto". Si no estaba ya claro, estos nuevos documentos dejaban obsoletas las antiguas RFC 2616.
¿Qué tiene esto que ver con HTTP/3?
Mientras que el IETF estaba ocupado trabajando en la serie 723x de la RFC, el mundo no se paró. La gente continuó mejorando, ampliando y experimentando con HTTP en Internet. Entre ellos se encontraba Google, que había comenzado a experimentar con algo llamado SPDY (pronunciado "speedy"). Este protocolo se promocionó como una mejora del rendimiento de la navegación web, un caso de uso principal de HTTP. A finales de 2009 se anunció SPDY v1, y fue seguido rápidamente por SPDY v2 en 2010.
Quiero evitar entrar en los detalles técnicos de SPDY. Dejaremos el tema para otro día. Lo importante es entender que SPDY tomó los paradigmas básicos de HTTP y modificó ligeramente el formato de intercambio para obtener mejoras. En retrospectiva, podemos ver que HTTP ha delimitado claramente la semántica y la sintaxis. La semántica describe el concepto de los intercambios de solicitud y respuesta incluyendo métodos, códigos de estado, campos de encabezado (metadatos) y cuerpos (carga). La sintaxis describe cómo asignar la semántica a los bytes en la conexión.
HTTP/0.9, 1.0 y 1.1 comparten mucha semántica. También comparten la sintaxis en forma de cadenas de caracteres que se envían mediante conexiones TCP. SPDY tomó la semántica de HTTP/1.1 y cambió la sintaxis de cadenas a binario. Este es un tema muy interesante, pero hoy no nos enredaremos más en él.
Los experimentos de Google con SPDY mostraron que el cambio de la sintaxis HTTP prometía y que convenía mantener la semántica existente de HTTP. Por ejemplo, mantener el formato de URL al utilizar https:// evitaba muchos problemas que podrían haber afectado a la adopción.
Después de haber visto algunos de los resultados positivos, el IETF decidió que era tiempo de considerar cómo podría ser HTTP/2.0. Las diapositivas de la sesión de HTTPbis celebrada durante la reunión 83 del IETF en marzo de 2012 muestra los requisitos, objetivos y mediciones del éxito que se establecieron. También se afirma claramente que "HTTP/2.0 solo indica que el formato de transferencia no es compatible con el de HTTP/1.x".
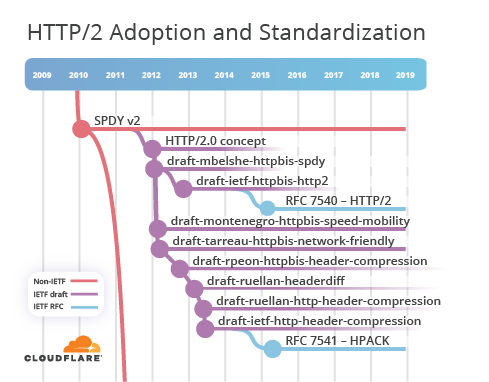
Durante esa reunión, se invitó a la comunidad a compartir propuestas. Los borradores de Internet que se sometieron a examen incluían draft-mbelshe-httpbis-spdy-00, draft-montenegro-httpbis-speed-mobility-00 y draft-tarreau-httpbis-network-friendly-00. En definitiva, se aprobó el borrador SPDY y en noviembre de 2012 se inició draft-ietf-httpbis-http2-00. Después de 18 borradores a lo largo de un período de 2 años, RFC 7540-HTTP/2 se publicó en el año 2015. Durante este período de especificación, la sintaxis precisa de HTTP/2 divergió lo suficiente para hacer HTTP/2 y SPDY incompatibles.
Estos años fueron un período de mucha actividad en el trabajo relacionado con el HTTP en el IETF, con la refactorización de HTTP/1.1 y la estandarización de HTTP/2 llevándose a cabo en paralelo. Eso contrasta claramente con los muchos años de silencio de la primera década del 2000. Consulta la cronología completa para apreciar realmente la cantidad de trabajo que se llevó a cabo.
Aunque HTTP/2 estaba en proceso de estandarización, todavía había beneficios que obtener al utilizar y experimentar con SPDY. Cloudflare introdujo soporte para SPDY en agosto de 2012 y solamente lo dejó en desuso en febrero de 2018, cuando nuestras estadísticas demostraron que menos del 4 % de los clientes de web continuaban queriendo SPDY. Mientras tanto, introdujimos soporte para HTTP/2 en diciembre de 2015, no mucho tiempo después de que se publicara la RFC, cuando nuestro análisis indicó que una proporción significativa de clientes de web podría beneficiarse de ello.
El soporte de los clientes de web de los protocolos SPDY y HTTP/2 dio preferencia a la opción segura de usar TLS. La introducción de Universal SSL en septiembre de 2014 ayudó a asegurar que todos los sitios web registrados en Cloudflare pudieran beneficiarse de estos nuevos protocolos cuando los introdujimos.
gQUIC
Google continuó experimentando entre 2012 y 2015; lanzó SPDY v3 y v3.1. También comenzó a trabajar en gQUIC (que se pronunciaba entonces "quick") y la especificación pública inicial estuvo disponible a principios de 2012.
Las versiones tempranas del gQUIC hacían uso de la forma SPDY v3 de sintaxis HTTP. Esta elección era lógica porque HTTP/2 todavía no estaba terminado. La sintaxis binaria SPDY se empaquetaba en paquetes QUIC que podían enviarse en datagramas UDP. Era una salida del transporte TCP del que tradicionalmente había dependido HTTP. Uniendo todo esto, teníamos lo siguiente:
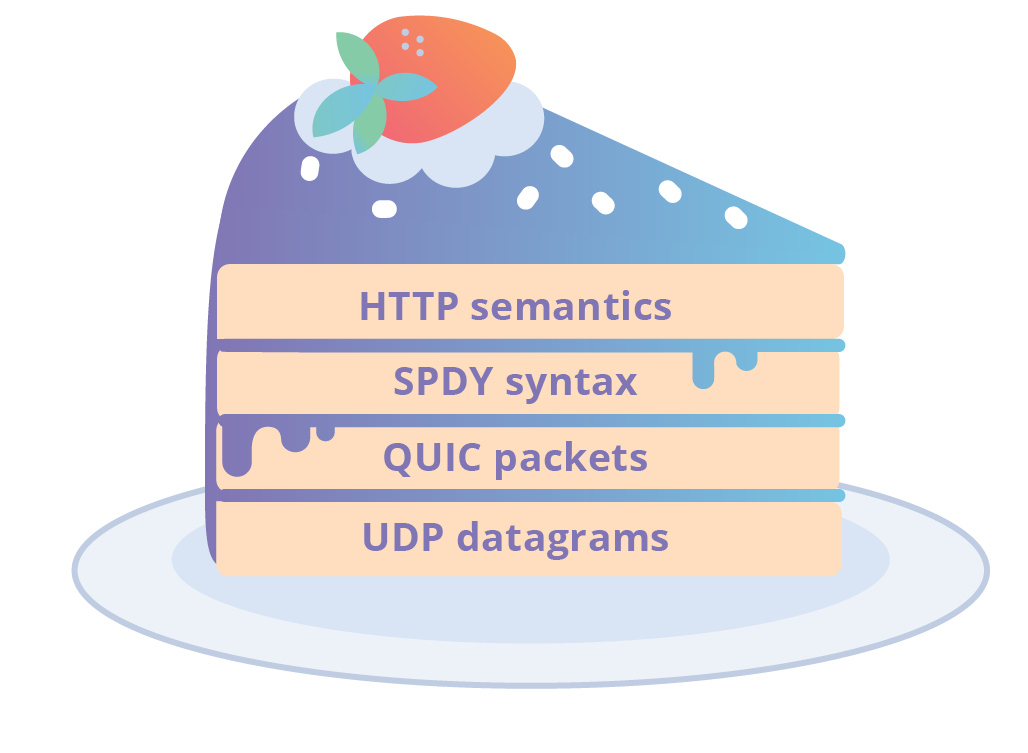
gQUIC usaba trucos ingeniosos para lograr rendimiento. Uno de ellos fue romper la clara estratificación entre la aplicación y el transporte. En la práctica, esto significaba que gQUIC solamente era compatible con HTTP. Hasta el punto que gQUIC, entonces denominado "QUIC", era sinónimo de la próxima versión candidata a HTTP. A pesar de los cambios de QUIC en los últimos años, que revisaremos en breve, hoy en día, la gente entiende hoy que el término QUIC significa esa variante inicial solo de HTTP. Lamentablemente, esto suele llevar a confusión cuando se habla del protocolo.
gQUIC continuó experimentando y finalmente cambió a una sintaxis mucho más cercana a HTTP/2. Era tan cercana que, de hecho, la mayoría de la gente simplemente la llamaba "HTTP/2 sobre QUIC". Sin embargo, debido a las limitaciones técnicas, había algunas diferencias muy sutiles. Un ejemplo se relaciona con cómo los encabezados HTTP se serializaron e intercambiaron. Es una diferencia menor, pero en la práctica significa que HTTP/2 sobre gQUIC era incompatible con el HTTP/2 del IETF.
Por último, pero no menos importante, siempre debemos considerar las cuestiones de seguridad de los protocolos de Internet. gQUIC optó por no utilizar TLS para proporcionar seguridad. En cambio, Google desarrolló un enfoque diferente denominado QUIC Crypto. Uno de los aspectos interesantes de este fue un nuevo método para acelerar los protocolos de enlace de seguridad. Un cliente que previamente había establecido una sesión segura con un servidor podía reutilizar la información para un protocolo de enlace "de ida y vuelta en tiempo cero", o 0-RTT (0 round-trip time en inglés). El 0-RTT se incorporó después a TLS 1.3.
¿Ya podrías explicar lo que es HTTP/3?
Casi.
Ya debes haber comprendido cómo funciona la estandarización y gQUIC no es muy diferente. Había bastante interés en que las especificaciones de Google se redactaran en formato de borrador de Internet. En junio de 2015 se envió draft-tsvwg-quic-protocol-00, titulado "QUIC: un transporte seguro y fiable basado en UDP para HTTP/2". Ten en cuenta mi anterior afirmación de que la sintaxis era casi la de HTTP/2.
Google anunció que se celebraría un Bar BoF en el IETF 93 en Praga. Quienes tengan curiosidad sobre qué es un "Bar BoF" pueden consultar RFC 6771. Pista: BoF significa pájaros de igual plumaje (birds of a feather en inglés).
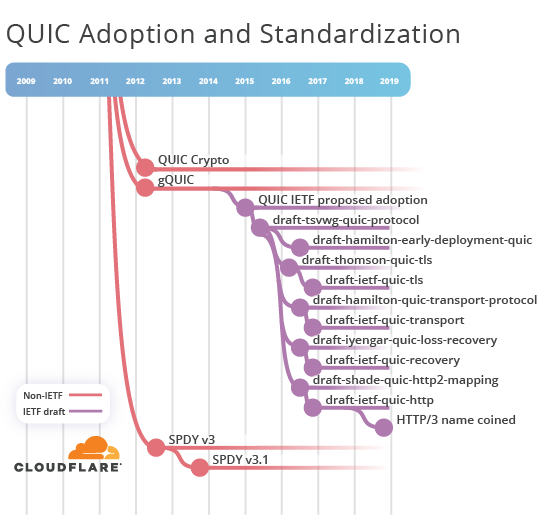
El resultado de este compromiso con el IETF era, en resumen, que QUIC parecía ofrecer muchas ventajas en la capa de transporte y que debía disociarse de HTTP. La separación clara entre las capas debía reintroducirse. Además, se prefería regresar a un enlace de seguridad basado en TLS (que no estaba tan mal, ya que TLS 1.3 estaba en marcha en esta etapa y ya incorporaba enlaces de seguridad de 0-RTT).
Un año después, en 2016, se presentó un nuevo conjunto de borradores de Internet:
- draft-hamilton-quic-transport-protocol-00
- draft-thomson-quic-tls-00
- draft-iyengar-quic-loss-recovery-00
- draft-shade-quic-http2-mapping-00
Aquí es donde aparece otra fuente de confusión sobre HTTP y QUIC. draft-shade-quic-http2-mapping-00 se titula "La semántica de HTTP/2 utilizando el protocolo de transporte QUIC" y se describe como "una asignación de la semántica de HTTP/2 sobre QUIC". Sin embargo, es un nombre poco apropiado. HTTP/2 cambiaba la sintaxis pero mantenía la semántica. Además, "HTTP/2 sobre gQUIC" tampoco fue nunca una descripción precisa de la sintaxis, por las razones que mencioné anteriormente. No pierdas esto de vista.
Esta versión de QUIC del IETF iba a ser un protocolo de transporte completamente nuevo. Sería un proyecto muy amplio, y antes de meterse de lleno en tales compromisos, al IETF le gusta medir el interés real de sus miembros. Para ello, se llevó a cabo un encuentro formal de BoF en la reunión del IETF 96 en Berlín, en el año 2016. Tuve la suerte de participar en la sesión en persona y las diapositivas no le hacen justicia. Cientos de personas asistieron a la reunión, como se ve en la foto de Adam Roach. Al final de la sesión se llegó a un consenso; QUIC se adoptaría y normalizaría en el IETF.
El primer borrador de Internet de QUIC del IETF para la asignación de HTTP a QUIC, draft-ietf-quic-http-00, usó el enfoque de Ronseal y simplificó su nombre a "HTTP sobre QUIC". Por desgracia, no se terminó el trabajo completamente y el término HTTP/2 aparecía por todo el texto. Mike Bishop, el nuevo editor de borradores de Internet, se dio cuenta y comenzó a corregir las referencias incorrectas a HTTP/2. En el borrador 01, la descripción se cambió a "una asignación de la semántica de HTTP sobre QUIC".
Poco a poco, con el tiempo y las versiones, el uso del término "HTTP/2" disminuyó y las instancias se convirtieron en meras referencias a partes de la RFC 7540. Si avanzamos dos años hasta octubre de 2018, el borrador de Internet está ahora en la versión 16. Si bien HTTP sobre QUIC guarda parecido con HTTP/2, finalmente es una sintaxis HTTP independiente y compatible que no retrocede. Sin embargo, para quienes no siguen muy de cerca el desarrollo del IETF (un porcentaje muy muy grande de población de la Tierra), el nombre del documento no recoge esta diferencia. Uno de los propósitos principales de la estandarización es facilitar la comunicación y la interoperabilidad. Sin embargo, algo tan simple como un nombre puede contribuir significativamente a la confusión en la comunidad.
Recordemos lo dicho en el 2012, "HTTP/2.0 solo significa que el formato de transferencia no es compatible con el de HTTP/1.x". El IETF había seguido esa pista inicial. Después de mucha deliberación antes y durante la reunión del IETF 103, se llegó a un consenso para cambiar el nombre "HTTP sobre QUIC" a HTTP/3. El mundo está ahora mejor ubicado y podemos pasar a debates más importantes.
¡Pero las RFC 7230 y 7231 no confirman tu definición de la semántica y la sintaxis!
A veces los títulos de los documentos pueden ser confusos. Los documentos HTTP actuales que describen la sintaxis y la semántica son:
- RFC 7230 - Protocolo de transferencia de hipertexto (HTTP/1.1): sintaxis de mensaje y enrutamiento
- RFC 7231 - Protocolo de transferencia de hipertexto (HTTP/1.1): semántica y contenido
Existe la posibilidad de que se interpreten equivocadamente estos nombres y creo que la semántica fundamental de HTTP es específica para las versiones de HTTP, como HTTP/1.1. Sin embargo, es un efecto secundario involuntario del árbol genealógico de HTTP. La buena noticia es que el Grupo de trabajo de HTTPbis está tratando de solucionar esto. Algunos valientes miembros están realizando otra ronda de revisión del documento. Como dijo Roy Fielding: "¡Una vez más!". Este trabajo está en marcha ahora mismo y se conoce como la actividad principal de HTTP (también puedes haber oído de ello con el apodo de HTTPtre o HTTPter; es difícil poner nombre a ciertas cosas). Así, se condensarán los seis borradores en tres:
- Semántica de HTTP (draft-ietf-httpbis-semantics)
- Caché de HTTP (draft-ietf-httpbis-caching)
- Sintaxis de mensaje y enrutamiento de HTTP/1.1 (draft-ietf-httpbis-messaging)
Bajo esta nueva estructura, se hace más evidente que HTTP/2 y HTTP/3 son definiciones de sintaxis para la semántica común de HTTP. Eso no significa que no tengan sus propias características más allá de la sintaxis, pero ayudará a enmarcar la a discusión en el futuro.
Tirando de todo, juntos
Esta entrada de blog ha dado un repaso superficial al proceso de estandarización de HTTP en el IETF en las últimas tres décadas. Sin entrar en muchos detalles técnicos, he intentado explicar cómo hemos llegado a HTTP/3 hoy. Si te has saltado las partes del centro y quieres un resumen, aquí lo tienes: HTTP/3 es solo una nueva sintaxis HTTP que funciona en QUIC del IETF, un transporte multiplexado y seguro bastado en UDP. Hay muchas áreas técnicas interesantes para continuar explorando, pero habrá que esperar a otro día.
A lo largo de esta publicación, hemos explorado capítulos importantes en el desarrollo de HTTP y TLS de manera aislada. Cerramos el blog añadiéndolos todos a la Cronología de la web segura completa, presentada abajo. Puedes usarla para investigar la historia en detalle a tu manera. Y para súper detectives, no olvidéis consultar la versión completa que incluye los números de los borradores.