

Cloudflare 采取各种措施,确保能够防止基础设施所有层级的故障。其中包括 Kafka,我们在关键工作流中使用这个系统,例如发送时间敏感的电子邮件和警报。
在保持我们利用 Kafka 的应用使用健康并始终正常运行方面,我们学到了很多。众所周知,应用运行状况检查很难实现:是什么决定应用是否健康?我们如何保持服务始终正常运行?
这些可通过多种方式实现。我们将讨论一种方法,它允许我们显著减少不健康的应用相关事件,且要求更少人工干预。
Kafka 在 Cloudflare
Cloudflare 大量采用 Kafka。由于 Kafka 的异步特性和可靠性,我们使用它来解耦服务。它允许不同的团队有效地工作,而不会相互依赖。有关其他 Cloudflare 团队如何使用 Kafka,详见这篇文章。
Kafka 用于发送和接收消息。消息代表某种事件,例如信用卡支付,或在平台中创建的新用户的详细信息。这些消息可以用多种方式表示:JSON、Protobuf、Avro 等等。
Kafka 以主题形式组织消息。主题是事件的有序日志,其中每条消息都用累进偏移量标记。当由外部系统写入一个事件时,它将被追加到该主题的末尾。默认情况下,这些事件不会从主题中删除(可以应用保留)。
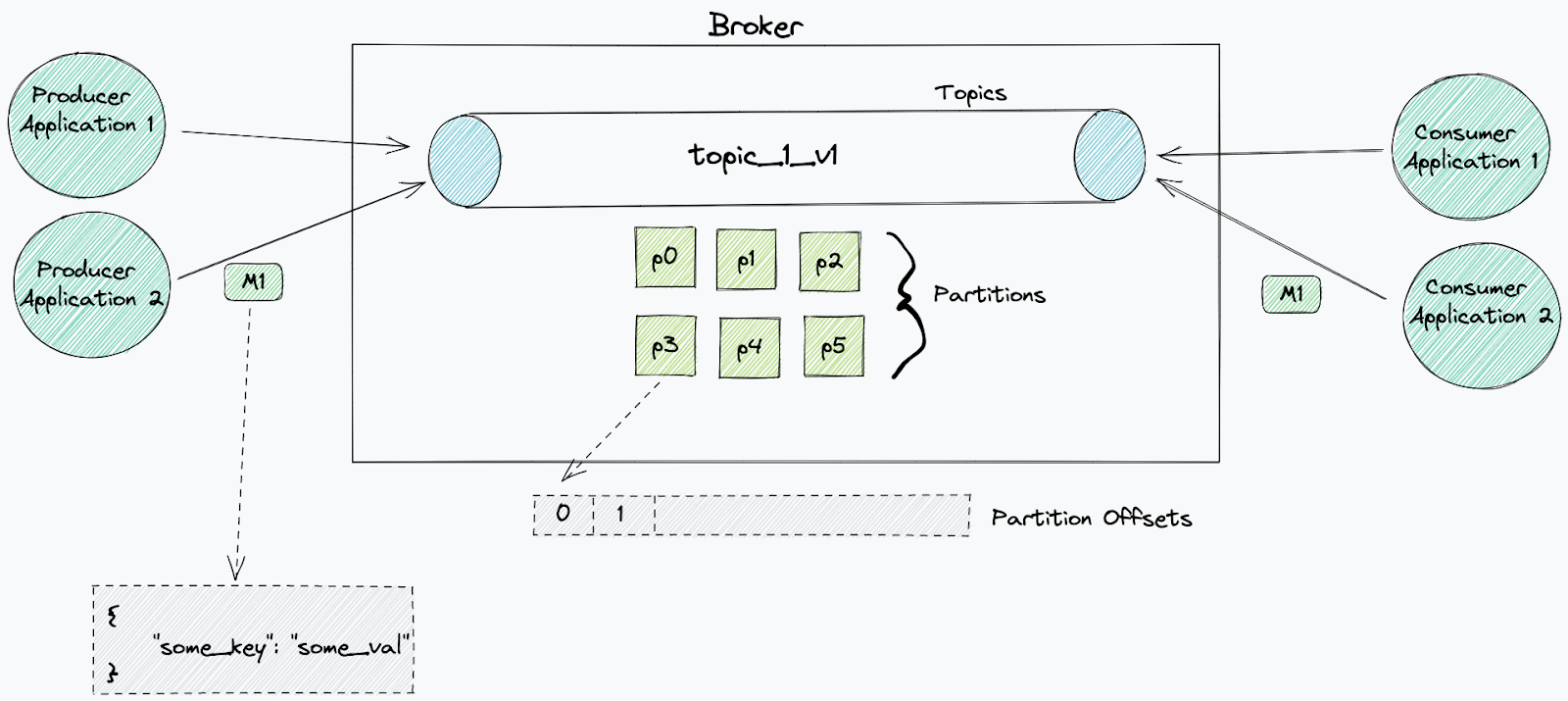
主题作为日志文件存储在磁盘上,大小有限。分区是一种系统方法,用于将一个主题日志文件分解为多个日志,每个日志可以托管在单独的服务器上,从而支持扩展主题。
主题由 Kafka 集群中的代理节点管理。它们负责向分区写入新事件,支持读取,并在它们之间复制分区。
消息可以由单个消费者或协调的消费者组消费。
消费者使用唯一的 id (消费者 id),这个 id 允许代理将它们识别为消费特定主题的应用。
每个主题都可以被无限数量的消费者阅读,只要他们使用不同的 id。每个消费者可以根据需要重播相同的消息。
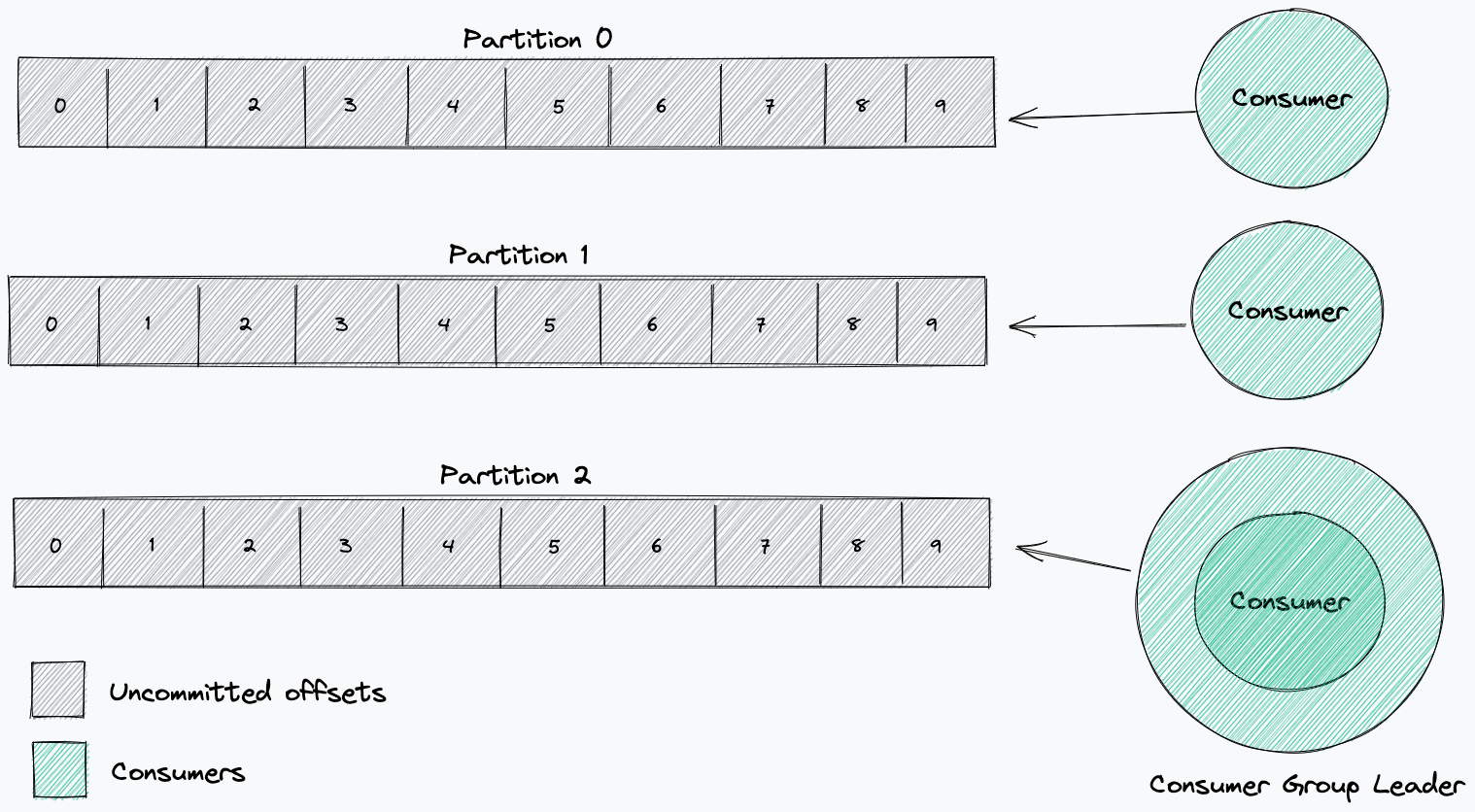
当使用者开始从一个主题消费时,它将从每个分区的选定偏移量开始处理所有消息。通过消费者组,分区可在组中的每个消费者之间划分。这一划分由消费者组领导者决定。这个领导者将接收关于组中其他消费者的信息,并决定哪些消费者将从哪个分区接收消息(分区策略)。
消费者提交的偏移量可以证明消费者是否按预期工作。提交已处理的偏移量是使用者及其消费者组向代理报告它们已处理特定消息的方式。
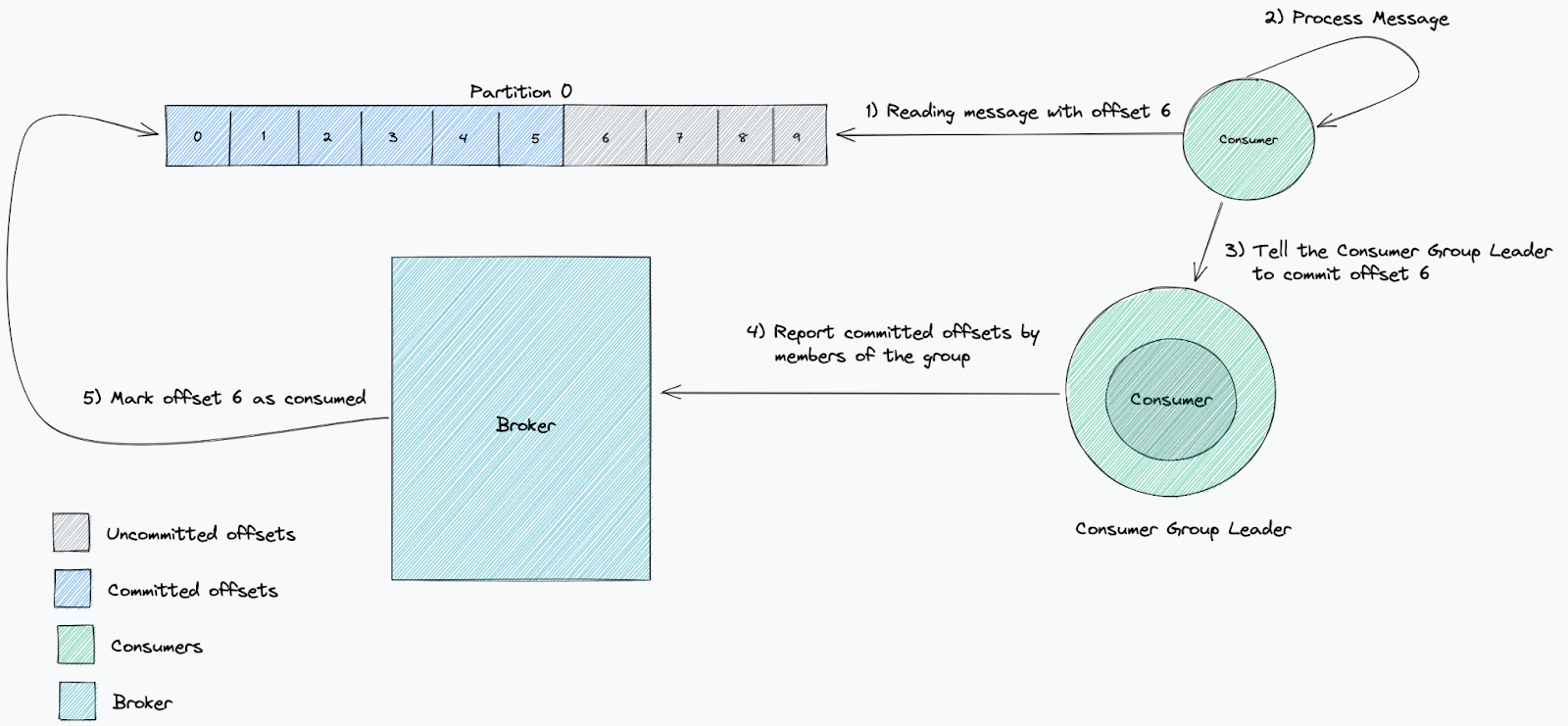
衡量消费者处理速度是否足够快的一个标准是滞后(lag)。我们用它来衡量我们落后最新消息的程度。这将跟踪消息写入主题和从主题读取消息之间的时间间隔。当一项服务滞后时,意味着消费的速度比新消息产生的速度慢。
由于 Cloudflare 的规模,消息速率往往非常高,大量请求是时间敏感的,因此监控这一点至关重要。
Cloudflare 使用 Kafka 的应用作为 Kubernetes 上的微服务部署。
Kubernetes 应用的运行状况检查
Kubernetes 使用探针 (probe) 来了解某一项服务是否正常运行,并准备好接收流量以开始运行。当一个存活探针失败且重试次数被超过时,Kubernete 将重新启动该服务。
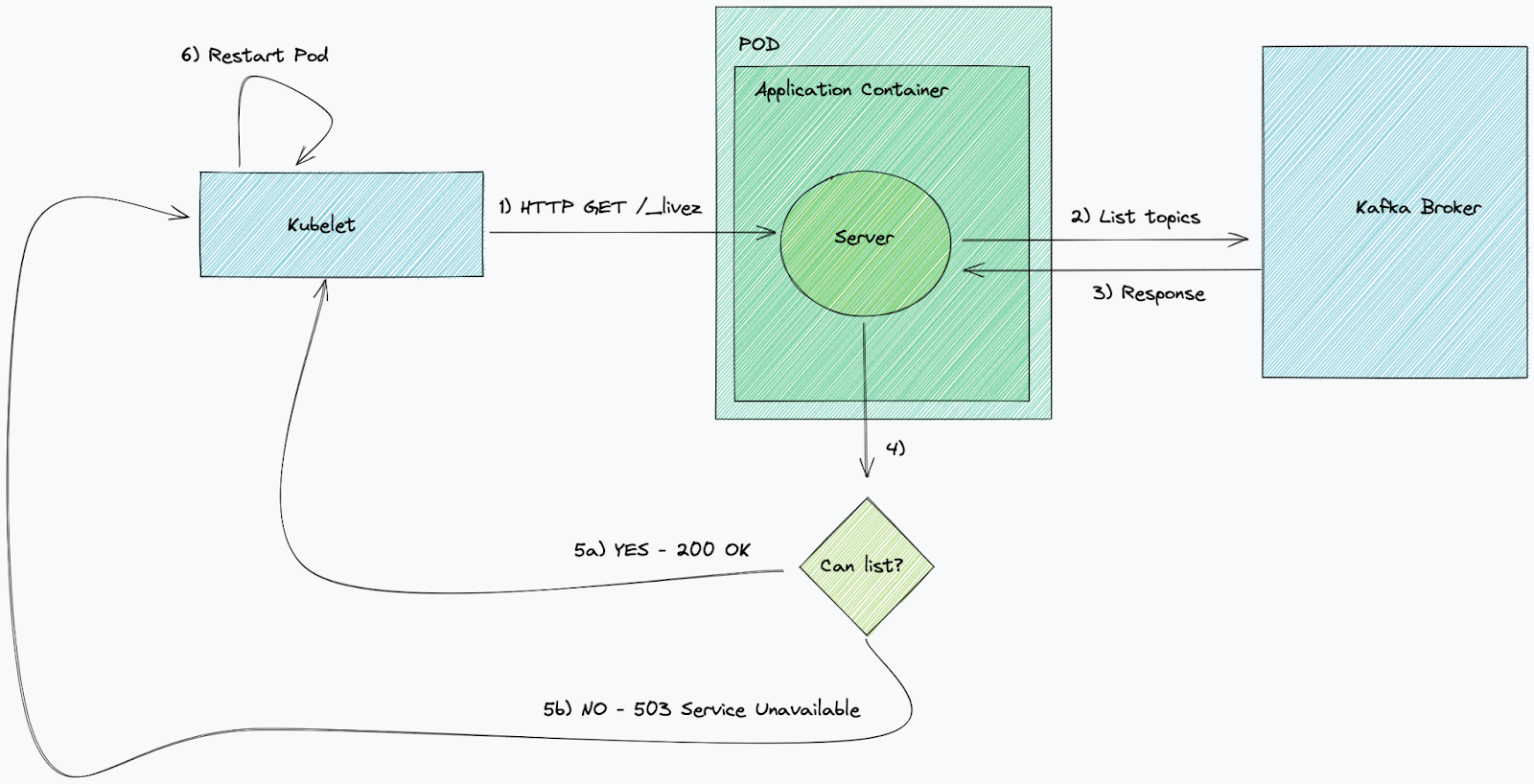
当一个就绪探针失败且重试次数被超过时,它将停止向目标 pod 发送 HTTP 流量。对 Kafka 应用而言,这是不相关的,因为它们不运行 http 服务器。为此,我们仅介绍存活检查。
对消费者进行的经典 Kafka 存活探针检查与代理之间的连接状态。最佳实践通常是使这些检查保持简单,并执行一些基本操作——例如,在本例中的列出主题。如果由于任何原因,检查始终失败,例如代理返回 TLS 错误,Kubernetes 将终止服务并启动相同服务的新 pod,从而强制建立新连接。简单的 Kafka 存活检查可以很好地了解与代理的连接是否不健康。
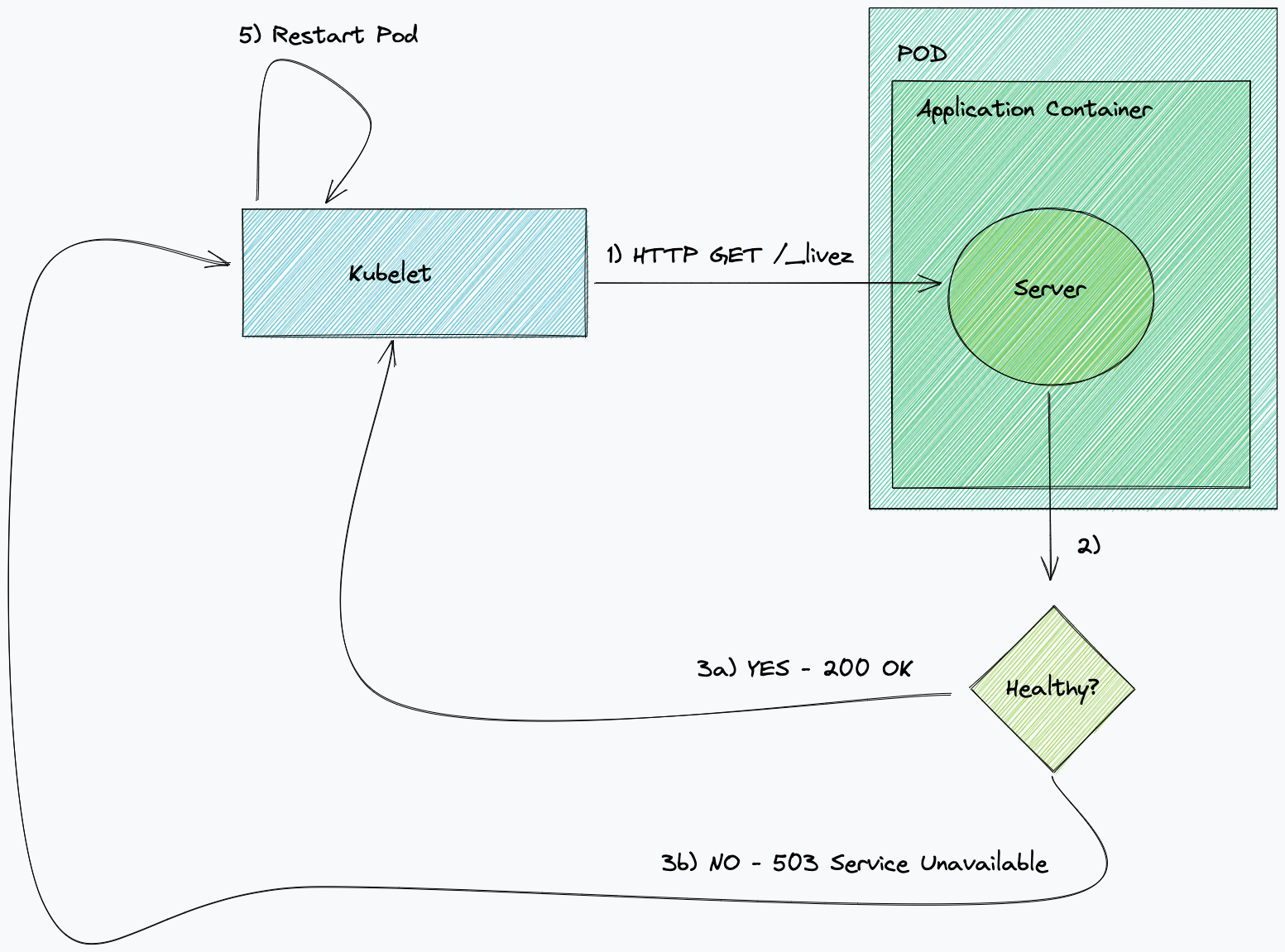
Kafka 运行状况检查的问题
由于 Cloudflare 的规模,我们的许多 Kafka 主题被划分为多个分区(在某些情况下可能多达数百个!)而且在许多情况下,我们消费的服务的副本计数并不一定符合 Kafka 主题上的分区数。这可能意味着在许多情况下,这种简单的运行状况检查方法是不足够的。
对于消费 Kafka 主题的微服务而言,如果它们在消息发布到主题时定期消费和提交偏移量,就表明其运行正常。当这样的服务没有按照预期提交偏移量时,意味着消费者处于不良状态,并将开始积累滞后。我们经常采取的一种方法是手动终止并重新启动 Kubernetes 中的服务,这将导致重新连接和重新平衡。
当消费者加入或离开消费者组时,将触发重新平衡,消费者组领导者必须重新分配哪些消费者将从哪些分区读取。
当重新平衡发生时,每个消费者都被通知停止消费。一些消费者可能会被收回分配给它们的分区,并重新分配给另一个消费者。我们注意到这种情况发生在我们的库实现中;如果使用者不确认此指令,它将无限期地等待从不再分配给它的分区消费新消息,最终导致死锁。通常需要手动重新启动故障的客户端应用程序来恢复处理。
智能运行状况检查
当我们看到消费者报告“健康”但不进行任何工作时,我们就会想到,也许我们在运行状况中把注意力放在错误的地方上了。仅仅因为服务连接到 Kafka 代理并可以从主题中读取,并不意味着消费者正在积极地处理消息。
因此,我们意识到应该专注于消息摄取,使用偏移量来确保向前进展。
PagerDuty 方式
PagerDuty 就这个问题写了一篇精彩的博客文章,在我们考虑自己的解决方案时提供了灵感。
他们的方法使用当前(最新)偏移量和提交的偏移量。当前偏移量表示发送到主题的最后一条消息,而提交的偏移量是由消费者处理的最后一条消息。
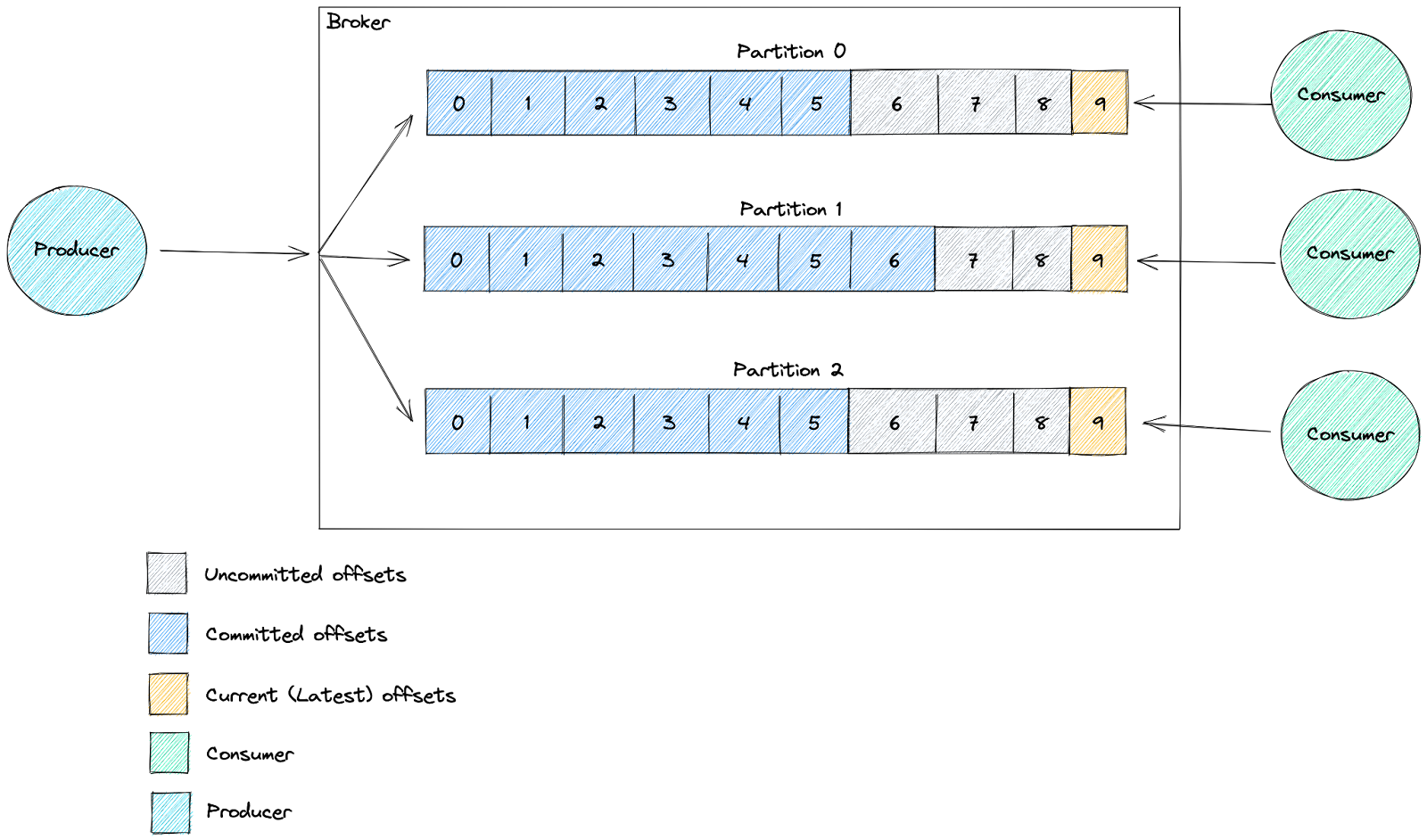
通过确保最新的偏移量正在改变(接收新消息)和提交的偏移量也在改变(处理新消息),从而确认消费者正在向前移动。
因此,我们想到的解决方案如下:
- 如果不能读取当前偏移量,则存活探针失败。
- 如果不能读取提交偏移量,则存活探针失败。
- 如果提交偏移量==当前偏移量,存活探针通过。
- 如果自上次运行运行状况检查以来提交的偏移量的值没有更改,则存活探针失败。
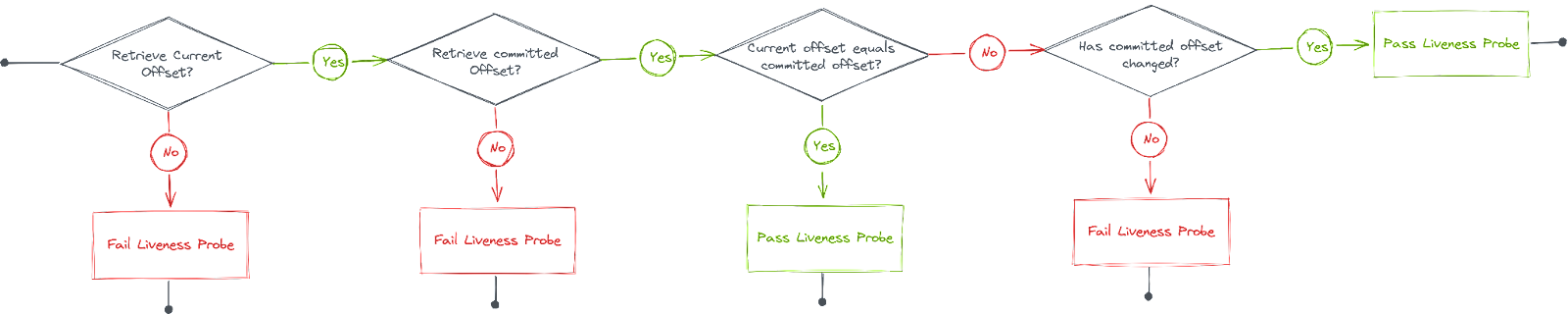
为了测量提交的偏移量是否在发生变化,我们需要存储前一次运行的值,我们使用分区号为键的内存映射来实现这一点。这意味着我们服务的每个实例仅拥有当前正在从中消费的分区的视图,并将为每个分区进行运行状况检查。
问题
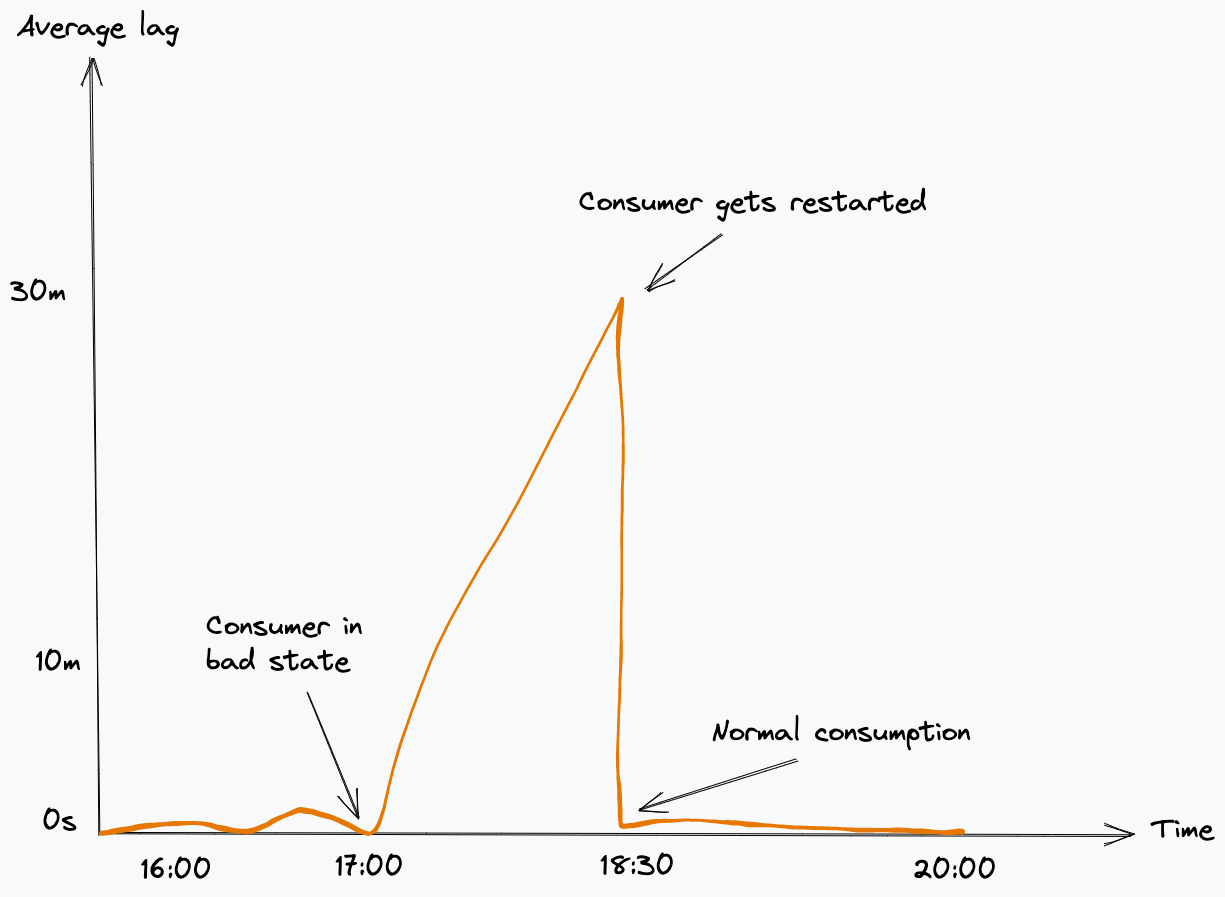
当我们第一次推出智能运行状况检查时,发布后不久就开始注意到级联失败。在初步调查之后,我们意识到,这种情况发生在出现重新平衡时。它最初会影响一个副本,然后很快导致其他副本报告为不健康。
我们观察到,由于我们在存储了内存中之前提交的偏移量,当重新平衡发生时,服务可能会被重新分配到不同的分区。当这种情况发生时,它意味着我们的服务错误地假设该分区的提交偏移量没有改变(因为这个特定的副本不再更新最新的值),因此它将开始报告服务不健康。失败存活探针将导致它重新启动,从而触发 Kafka 中的另一次重新平衡,导致其他副本面临同样的问题。
解决方案
为了解决这个问题,我们需要确保每个副本只跟踪它当时正在使用的分区的偏移量。幸运的是,我们内部使用的 Shopify Sarama 库具有观察重新平衡何时发生的功能。这意味着我们可以使用它来重建偏移量的内存映射,使其只包含相关的分区值。
这是通过从会话上下文通道接收信号来处理的:
for {
select {
case message, ok := <-claim.Messages(): // <-- Message received
// Store latest received offset in-memory
offsetMap[message.Partition] = message.Offset
// Handle message
handleMessage(ctx, message)
// Commit message offset
session.MarkMessage(message, "")
case <-session.Context().Done(): // <-- Rebalance happened
// Remove rebalanced partition from in-memory map
delete(offsetMap, claim.Partition())
}
}
验证这个解决方案很简单,我们只需要触发一次重新平衡。为了测试这在所有可能的场景下都能工作,为一个从多个分区消费的服务生成单个副本,然后继续扩大副本的数量,直到它与分区数量匹配,然后缩减到单个副本。通过以上做法,我们验证了运行状况检查可以安全地处理被分配的新分区,以及被删除的分区。
要点
Kubernetes 中的探针设置非常容易,可以成为一个强大的工具,以确保应用程序按预期运行。实现良好的探针通常是工程师被召唤去解决琐碎问题(有时是在工作时间之外)与服务自我修复的区别。
然而,如果没有适当的想法,“愚蠢”的运行状况检查也会导致一种错误的安全感,即使服务并没有正常运行,也会以为如此。我们从中学到的一件事是,更多地考虑服务的具体行为,并确定在每个实例中不健康意味着什么,而非仅仅确保依赖的服务是连接的。