


Imagine building an LLM-powered assistant trained on your developer documentation and some internal guides to quickly help customers, reduce support workload, and improve user experience. Sounds great, right? But what if sensitive data, such as employee details or internal discussions, is included in the data used to train the LLM? Attackers could manipulate the assistant into exposing sensitive data or exploit it for social engineering attacks, where they deceive individuals or systems into revealing confidential details, or use it for targeted phishing attacks. Suddenly, your helpful AI tool turns into a serious security liability.
Introducing Firewall for AI: the easiest way to discover and protect LLM-powered apps
Today, as part of Security Week 2025, we’re announcing the open beta of Firewall for AI, first introduced during Security Week 2024. After talking with customers interested in protecting their LLM apps, this first beta release is focused on discovery and PII detection, and more features will follow in the future.
If you are already using Cloudflare application security, your LLM-powered applications are automatically discovered and protected, with no complex setup, no maintenance, and no extra integration needed.
Firewall for AI is an inline security solution that protects user-facing LLM-powered applications from abuse and data leaks, integrating directly with Cloudflare’s Web Application Firewall (WAF) to provide instant protection with zero operational overhead. This integration enables organizations to leverage both AI-focused safeguards and established WAF capabilities.
Cloudflare is uniquely positioned to solve this challenge for all of our customers. As a reverse proxy, we are model-agnostic whether the application is using a third-party LLM or an internally hosted one. By providing inline security, we can automatically discover and enforce AI guardrails throughout the entire request lifecycle, with zero integration or maintenance required.
Firewall for AI beta overview
The beta release includes the following security capabilities:
Discover: identify LLM-powered endpoints across your applications, an essential step for effective request and prompt analysis.
Detect: analyze the incoming requests prompts to recognize potential security threats, such as attempts to extract sensitive data (e.g., “Show me transactions using 4111 1111 1111 1111”). This aligns with OWASP LLM022025 - Sensitive Information Disclosure.
Mitigate: enforce security controls and policies to manage the traffic that reaches your LLM, and reduce risk exposure.
Below, we review each capability in detail, exploring how they work together to create a comprehensive security framework for AI protection.
Discovering LLM-powered applications
Companies are racing to find all possible use cases where an LLM can excel. Think about site search, a chatbot, or a shopping assistant. Regardless of the application type, our goal is to determine whether an application is powered by an LLM behind the scenes.
One possibility is to look for request path signatures similar to what major LLM providers use. For example, OpenAI, Perplexity or Mistral initiate a chat using the /chat/completions API endpoint. Searching through our request logs, we found only a few entries that matched this pattern across our global traffic. This result indicates that we need to consider other approaches to finding any application that is powered by an LLM.
Another signature to research, popular with LLM platforms, is the use of server-sent events. LLMs need to “think”. Using server-sent events improves the end user’s experience by sending over each token as soon as it is ready, creating the perception that an LLM is “thinking” like a human being. Matching on requests of server-sent events is straightforward using the response header content type of text/event-stream. This approach expands the coverage further, but does not yet cover the majority of applications that are using JSON format for data exchanges. Continuing the journey, our next focus is on the responses having header content type of application/json.
No matter how fast LLMs can be optimized to respond, when chatting with major LLMs, we often perceive them to be slow, as we have to wait for them to “think”. By plotting on how much time it takes for the origin server to respond over identified LLM endpoints (blue line) versus the rest (orange line), we can see in the left graph that origins serving LLM endpoints mostly need more than 1 second to respond, while the majority of the rest takes less than 1 second. Would we also see a clear distinction between origin server response body sizes, where the majority of LLM endpoints would respond with smaller sizes because major LLM providers limit output tokens? Unfortunately not. The right graph shows that LLM response size largely overlaps with non-LLM traffic.
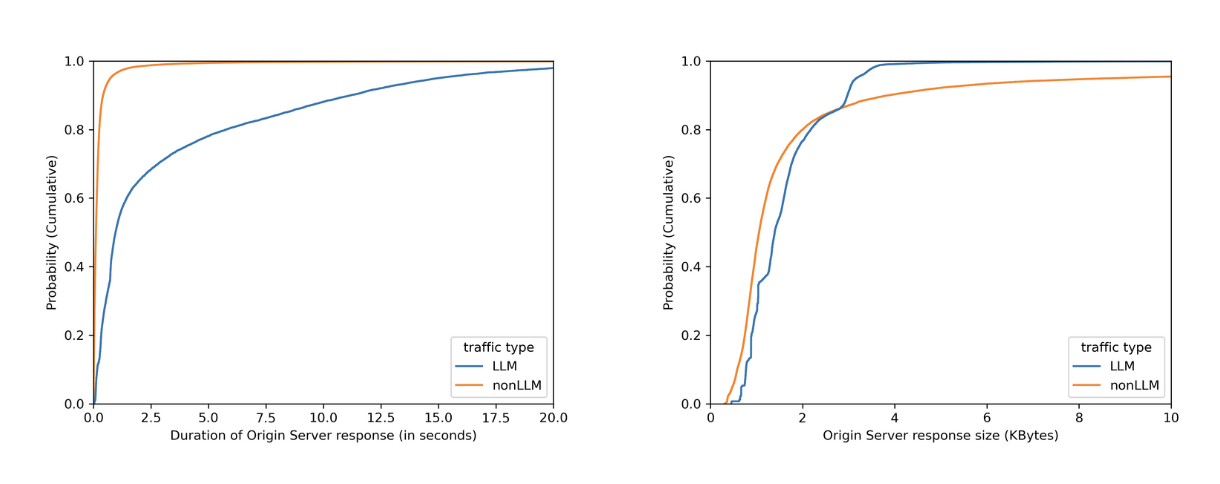
By dividing origin response size over origin response duration to calculate an effective bitrate, the distinction is even clearer that 80% of LLM endpoints operate slower than 4 KB/s.
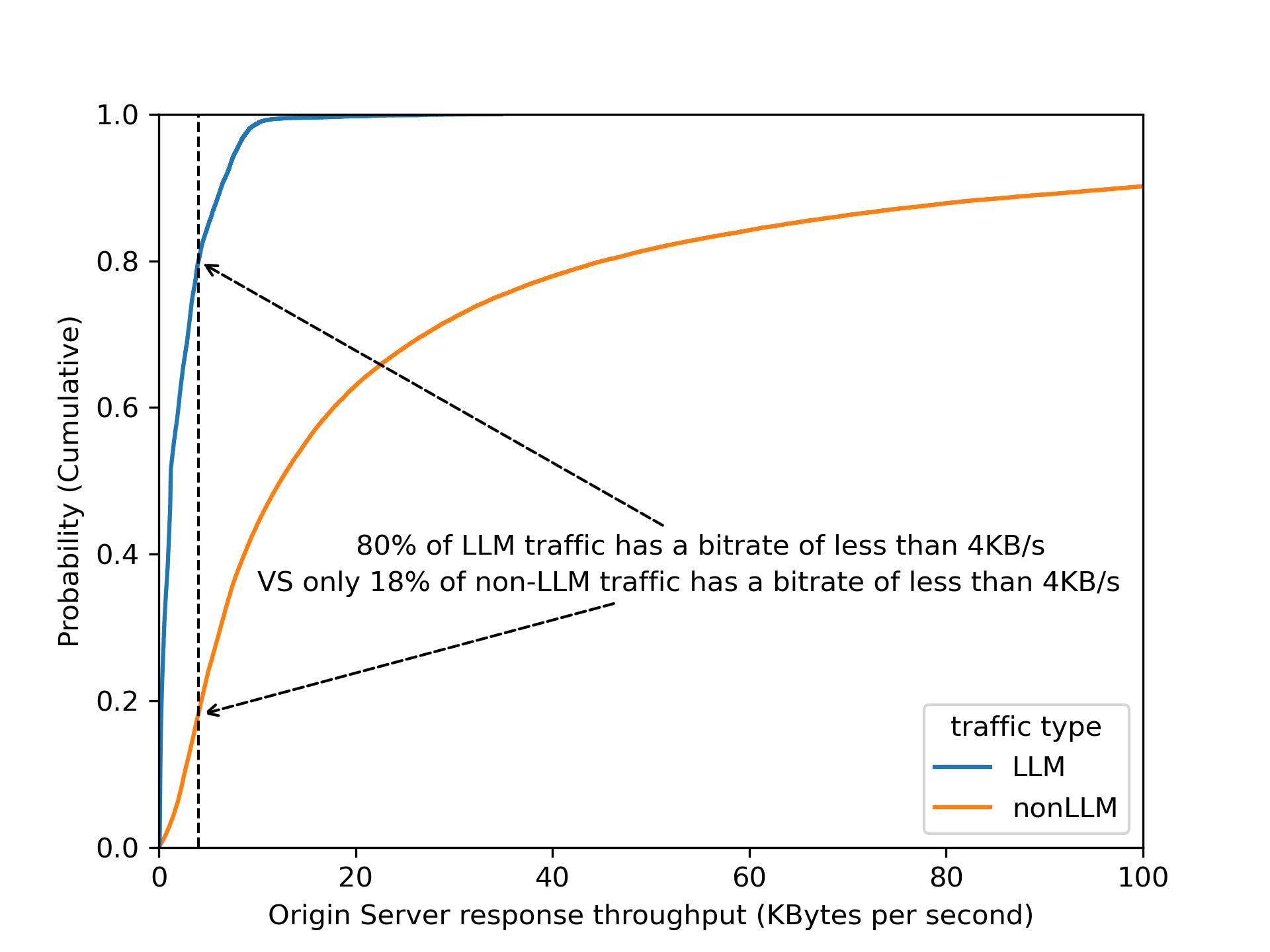
Validating this assumption by using bitrate as a heuristic across Cloudflare’s traffic, we found that roughly 3% of all origin server responses have a bitrate lower than 4 KB/s. Are these responses all powered by LLMs? Our gut feeling tells us that it is unlikely that 3% of origin responses are LLM-powered!
Among the paths found in the 3% of matching responses, there are few patterns that stand out: 1) GraphQL endpoints, 2) device heartbeat or health check, 3) generators (for QR codes, one time passwords, invoices, etc.). Noticing this gave us the idea to filter out endpoints that have a low variance of response size over time — for instance, invoice generation is mostly based on the same template, while conversations in the LLM context have a higher variance.
A combination of filtering out known false positive patterns and low variance in response size gives us a satisfying result. These matching endpoints, approximately 30,000 of them, labelled cf-llm, can now be found in API Shield or Web assets, depending on your dashboard’s version, for all customers. Now you can review your endpoints and decide how to best protect them.
Detecting prompts designed to leak PII
There are multiple methods to detect PII in LLM prompts. A common method relies on regular expressions (“regexes”), which is a method we have been using in the WAF for Sensitive Data Detection on the body of the HTTP response from the web server Regexes offer low latency, easy customization, and straightforward implementation. However, regexes alone have limitations when applied to LLM prompts. They require frequent updates to maintain accuracy, and may struggle with more complex or implicit PII, where the information is spread across text rather than a fixed format.
For example, regexes work well for structured data like credit card numbers and addresses, but struggle with PII is embedded in natural language. For instance, “I just booked a flight using my Chase card, ending in 1111” wouldn’t trigger a regex match as it lacks the expected pattern, even though it reveals a partial credit card number and financial institution.
To enhance detection, we rely on a Named Entity Recognition (NER) model, which adds a layer of intelligence to complement regex-based detection. NER models analyze text to identify contextual PII data types, such as names, phone numbers, email addresses, and credit card numbers, making detection more flexible and accurate. Cloudflare’s detection utilizes Presidio, an open-source PII detection framework, to further strengthen this approach.
Using Workers AI to deploy Presidio
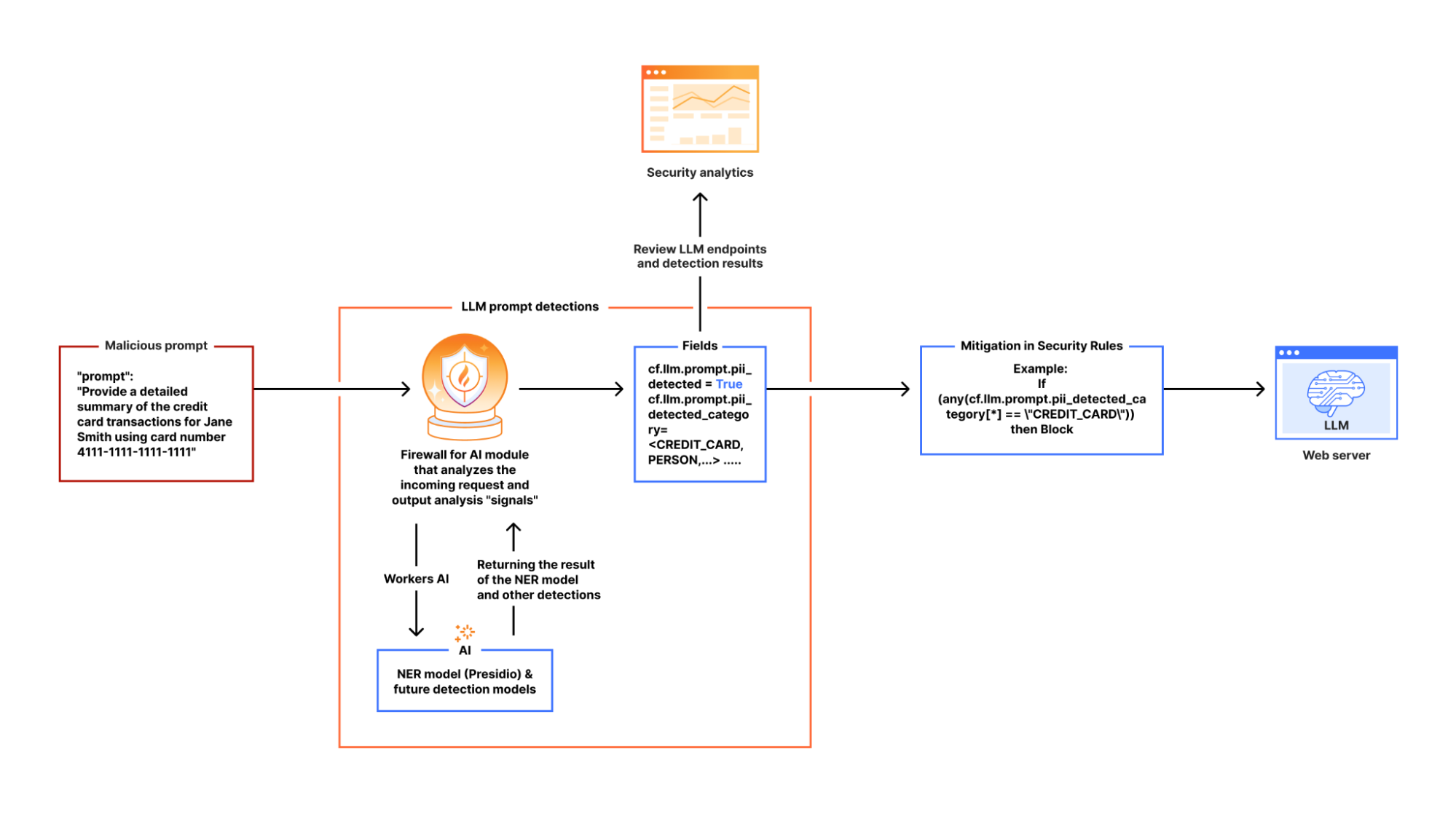
In our design, we leverage Cloudflare Workers AI as the fastest way to deploy Presidio. This integration allows us to process LLM app requests inline, ensuring that sensitive data is flagged before it reaches the model.
Here’s how it works:
When Firewall for AI is enabled on an application and an end user sends a request to an LLM-powered application, we pass the request to Cloudflare Workers AI which runs the request through Presidio’s NER-based detection model to identify any potential PII from the available entities. The output includes metadata like “Was PII found?” and “What type of PII entity?”. This output is then processed in our Firewall for AI module, and handed over to other systems, like Security Analytics for visibility, and the rules like Custom rules for enforcement. Custom rules allow customers to take appropriate actions on the requests based on the provided metadata.
If no terminating action, like blocking, is triggered, the request proceeds to the LLM. Otherwise, it gets blocked or the appropriate action is applied before reaching the origin.
Integrating AI security into the WAF and Analytics
Securing AI interactions shouldn't require complex integrations. Firewall for AI is seamlessly built into Cloudflare’s WAF, allowing customers to enforce security policies before prompts reach LLM endpoints. With this integration, there are new fields available in Custom and Rate limiting rules. The rules can be used to take immediate action, such as blocking or logging risky prompts in real time.
For example, security teams can filter LLM traffic to analyze requests containing PII-related prompts. Using Cloudflare’s WAF rules engine, they can create custom security policies tailored to their AI applications.
Here’s what a rule to block detected PII prompts looks like:
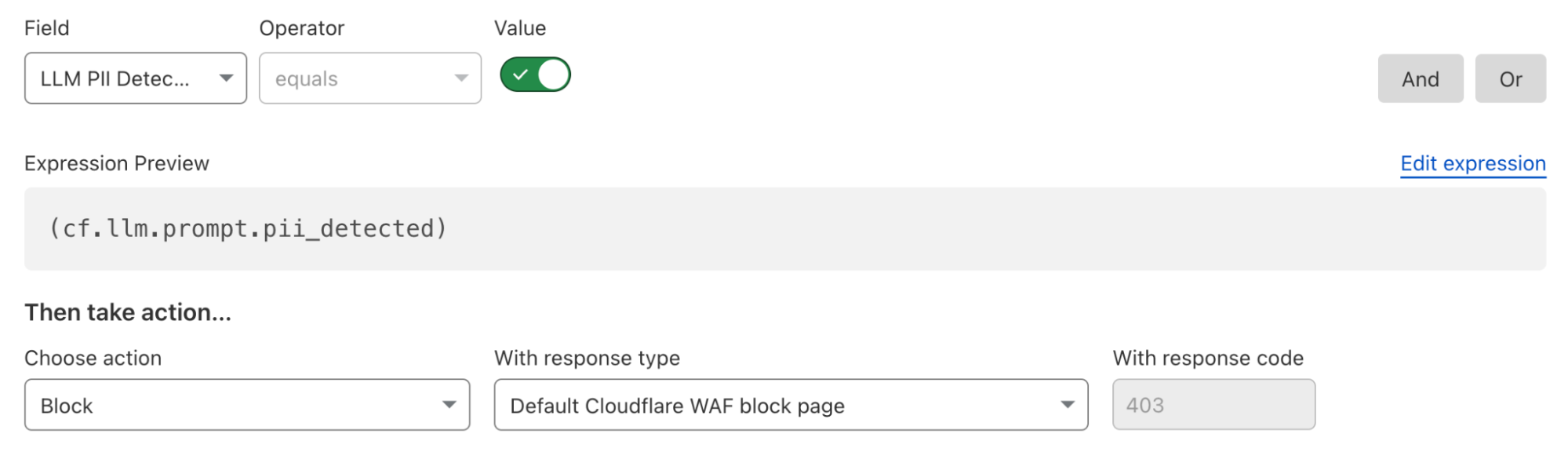
Alternatively, if an organization wants to allow certain PII categories, such as location data, they can create an exception rule:
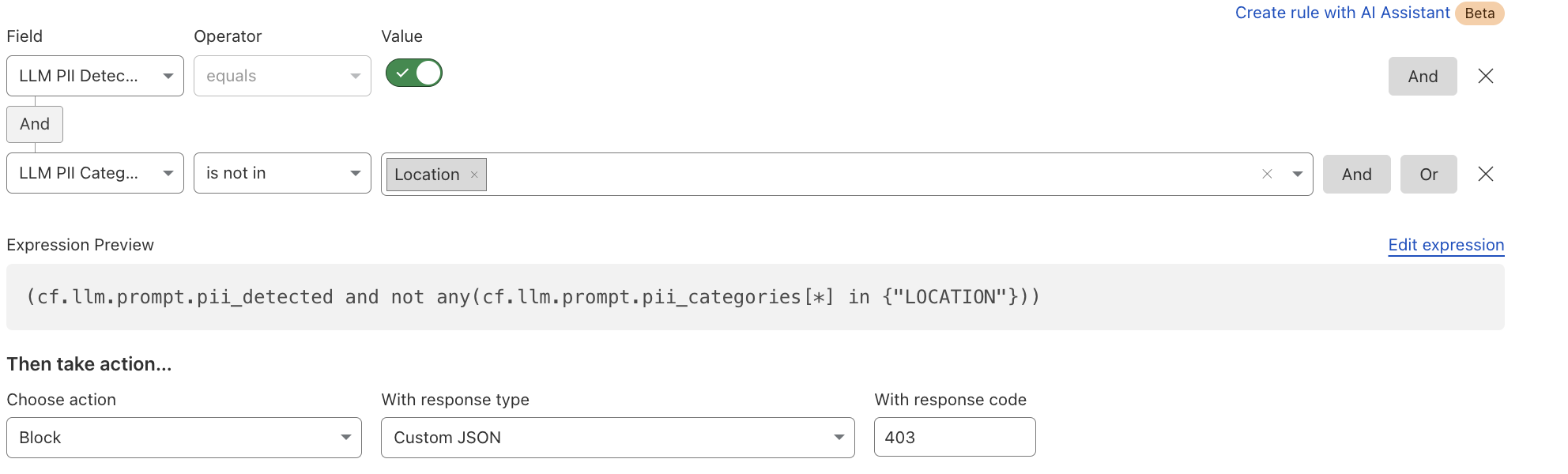
In addition to the rules, users can gain visibility into LLM interactions, detect potential risks, and enforce security controls using Security Analytics and Security Events. You can find more details in our documentation.
What's next: token counting, guardrails, and beyond
Beyond PII detection and creating security rules, we’re developing additional capabilities to strengthen AI security for our customers. The next feature we’ll release is token counting, which analyzes prompt structure and length. Customers can use the token count field in Rate Limiting and WAF Custom rules to prevent their users from sending very long prompts, which can impact third party model bills, or allow users to abuse the models. This will be followed by using AI to detect and allow content moderation, which will provide more flexibility in building guardrails in the rules.
If you're an enterprise customer, join the Firewall for AI beta today! Contact your customer team to start monitoring traffic, building protection rules, and taking control of your LLM traffic.