

自 Cloudflare 成立之初,我們就一直依靠 ML 和 AI 來提供 Web 應用程式防火牆 (WAF) 等核心服務。在這個過程中,我們學到了很多關於大規模執行 AI 部署的經驗,以及所有必要的工具和流程。我們最近推出了 Workers AI,幫助提取出許多推理方法,讓開發人員只需幾行程式碼就能輕鬆利用強大的模型。在本篇文章中,我們將探討我們在 ML 等式的另一面——訓練方面學到的一些經驗。
Cloudflare 擁有豐富的模型訓練經驗,並利用它們來改進我們的產品。不斷發展的 ML 模型推動了 WAF Attack Score,有助於保護我們的客戶免受惡意負載的侵害。另一個不斷發展的模型為傀儡程式管理產品提供支援,以擷取和防止傀儡程式對我們客戶的攻擊。資料科學增強了我們的客戶支援。我們構建機器學習來識別我們全球網路上的威脅。最重要的是,Cloudflare 正在我們的網路中以前所未有的規模提供機器學習。
這些產品以及其他許多產品都將 ML 模型(包括實驗、培訓和部署)提升到了 Cloudflare 的重要位置。為了幫助我們的團隊繼續高效創新,我們的 MLOps 團隊與 Cloudflare 的資料科學家合作實施了以下最佳做法。
Notebooks
給定使用案例和資料,許多資料科學家/AI 科學家的第一步是建立一個用於探索資料、特徵工程和模型實驗的環境。Jupyter Notebooks 是滿足這些要求的常用工具。這些環境提供了一個簡單的遠端 Python 環境,可以在瀏覽器中執行或連接到本機程式碼編輯器。為了使 Notebook 具有可擴展性並開放協作,我們在 Kubernetes 上部署了 JupyterHub。藉助 JupyterHub,我們可以管理資料科學家團隊的資源,並確保他們獲得合適的開發環境。每個團隊都可以透過預先安裝庫和設定使用者環境來定制自己的環境,以滿足特定需求,甚至單個專案的需求。
這一 Notebook 空間也在不斷發展。開放原始碼專案還包括更多的功能,例如:
- nbdev:用於改善 Notebook 使用體驗的 Python 封裝
- Kubeflow:用於機器學習的 kubernetes 原生 CNCF 專案
- depoyKF:任何 Kubernetes 叢集上的 ML 平台,提供集中設定、就地升級,並支援 Kubeflow、Airflow 和 MLflow 等領先的 ML 和資料工具
GitOps
我們的目標是為資料科學家和 AI 科學家提供一個易於使用的平台,以便快速開發和測試機器學習模型。因此,我們在 Cloudflare 的 MLOps 平台上採用 GitOps 作為持續交付策略並進行基礎架構管理。GitOps 是一種軟體發展方法,它利用分散式版本控制系統 Git 作為定義和管理基礎架構、應用程式設定和部署流程的單一來源。其目的是以聲明和可稽核的方式,自動化和簡化應用程式與基礎架構的部署和管理。GitOps 非常符合自動化和協作的原則,這些原則對機器學習 (ML) 工作流程至關重要。GitOps 利用 Git 存放庫作為聲明式基礎架構和應用程式代碼的真實來源。
資料科學家需要定義基礎架構和應用程式的所需狀態。這通常需要大量的自訂工作,但有了 ArgoCD 和模型範本,只需一個簡單的 pull 請求就能新增新的應用程式。Helm 圖表和 Kustomize 均受支援,可以針對不同的環境和作業進行設定。藉助 ArgoCD,聲明式 GitOps 將啟動持續交付流程。ArgoCD 將持續檢查基礎架構和應用程式的所需狀態,以確保它們與 Git 存放庫同步。
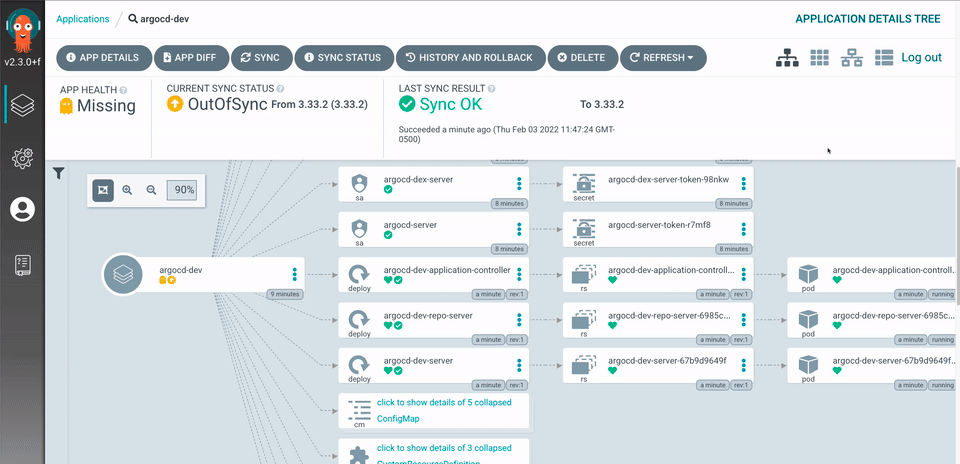
未來,我們計劃將我們的平台(包括 Jupyterhub)遷移到 Kubeflow,這是一個基於 Kubernetes 的機器學習工作流程平台,可簡化 Notebook 和端對端管道的開發、部署和管理。最好使用新專案 deployKF 進行部署,該專案允許跨 Kubeflow 可用的多個元件以及超出 Kubeflow 的其他元件進行分散式設定管理。
範本
是否使用正確的工具和結構啟動專案可能決定專案是成功還是停滯。在 Cloudflare 中,我們策劃了一系列模型範本,它們是帶有範例模型的生產就緒資料科學存放庫。這些模型範本在生產過程中進行部署,以持續確保它們成為未來專案的穩定基礎。要啟動一個新專案,只需要一個 Makefile 命令即可在使用者選擇的 git 專案中構建一個新的 CICD 專案。這些範本公用程式封裝與我們的 Jupyter Notebooks 中使用的公用程式封裝以及與 R2/S3/GCS 貯體、D1/Postgres/Bigquery/Clickhouse 資料庫的連線相同。資料科學家可以使用這些範本充滿信心地立即啟動新專案。這些範本尚未公開,但我們的團隊計劃在未來將其開放原始碼。
1. 訓練範本
我們的模型訓練範本為構建任何模型提供了堅實的基礎。我們對其進行了設定,可協助從任何資料來源擷取、轉換和載入資料 (ETL)。該範本包括用於特徵工程的 helper 函數、使用模型中繼資料追蹤實驗以及透過有向無環圖 (DAG) 選擇協調流程以生產模型管道。每個協調流程都可以設定為使用 Airflow 或 Argo Workflows。
2. 批量推理範本
批量和微批量推理可以對處理效率產生重大影響。我們的批量推理模型範本用於排程模型以獲得一致的結果,並且可以設定為使用 Airflow 或 Argo Workflows。
3. 串流推理範本
該範本使我們的團隊可以輕鬆部署即時推理。該範本使用 FastAPI 針對 Kubernetes 進行了定制(作為微服務),允許我們的團隊在容器中使用熟悉的 Python 執行推理。該微服務已經內建了 Swagger 的 REST 互動式文件,並與 terraform 中的 Cloudflare Access 驗證權杖整合。
4. 可解釋性範本
我們的可解釋性模型範本會旋轉儀表板來闡明模型類型和實驗。能夠理解時間視窗 F1 分數、特徵和資料隨時間的漂移等關鍵值非常重要。Streamlit 和 Bokeh 等工具有助於實現這一目標。
協調流程
將資料科學組織成一致的管道涉及大量資料和多個模型版本。輸入有向無環圖 (DAG),這是一種強大的流程圖協調範例,它將從資料到模型、模型到推理的步驟編織在一起。執行 DAG 管道有許多獨特的方法,但我們發現資料科學團隊的偏好是第一位的。每個團隊根據自己的使用案例和經驗都有不同的方法。
Apache Airflow——標準 DAG 編寫器
Apache Airflow 是基於 DAG(有向無環圖)的協調方法的標準。憑藉龐大的社群和廣泛的外掛程式支援,Airflow 擅長處理不同的工作流程。與多個系統整合的靈活性以及用於任務監控的 Web 型 UI 使其成為協調複雜任務序列的流行選擇。Airflow 可用於執行任何資料或機器學習工作流程。
Argo Workflows——Kubernetes 原生的輝煌
Argo Workflows 專為 Kubernetes 構建,採用容器生態系統來協調工作流程。它擁有基於 YAML 的直觀工作流程定義,並且擅長執行基於微服務的工作流程。與 Kubernetes 的整合可實現可擴展性、可靠性和原生容器支援,使其非常適合深深植根於 Kubernetes 生態系統的組織。Argo Workflows 還可用於執行任何資料或機器學習工作流程。
Kubeflow 管道——一個工作流程平台
Kubeflow Pipelines 是一種更具體的方法,專為協調機器學習工作流程而定制。「KFP」旨在滿足 ML 領域中資料準備、模型訓練和部署的獨特需求。作為 Kubeflow 生態系統的整合元件,它簡化了 ML 工作流程,重點關注協作、再使用性和版本控制。它與 Kubernetes 的相容性確保了無縫整合和高效協調。
Temporal——具狀態工作流程推動者
Temporal 的立場是強調長期執行、具狀態工作流程的協調。這個相對較新的領域在管理彈性、事件驅動的應用程式、保留工作流程狀態以及實現高效的故障復原方面表現出色。獨特的賣點在於它能夠管理複雜、具狀態的工作流程,提供持久且容錯的協調解決方案。
在協調領域,選擇最終取決於團隊和使用案例。這些都是開放原始碼專案,因此唯一的限制是對不同風格工作的支援,我們發現這是值得投資的。
硬體
實現最佳效能需要瞭解工作負載和底層用例,以便為團隊提供有效的硬體。目標是協助資料科學家並在支援和利用之間取得平衡。每個工作負載都是不同的,因此針對 GPU 和 CPU 的功能微調每個使用案例以找到適合該工作的完美工具非常重要。對於核心資料中心工作負載和邊緣推理,GPU 提高了速度和效率,這是我們業務的核心。Prometheus 提供可觀察性和指標,指標使我們能夠追蹤協調以最佳化效能、最大限度地提高硬體使用率,並在 Kubernetes 原生體驗中進行操作。
採用
採用通常是 MLops 之旅中最具挑戰性的步驟之一。在開始構建之前,瞭解不同的團隊及其資料科學方法非常重要。在 Cloudflare,這個過程幾年前就開始了,當時每個團隊都分別啟動了自己的機器學習解決方案。隨著這些解決方案的發展,我們遇到了在整個公司範圍內開展工作以防止不同團隊之間的工作相互分離的共同挑戰。此外,還有其他團隊具有機器學習潛力,但團隊內不具備資料科學專業知識。這為 MLops 提供了介入的機會——既可以幫助簡化和標準化每個團隊所採用的 ML 流程,也可以向資料科學團隊引入潛在的新專案,以啟動構思和探索過程。
在有能力的情況下,當我們能夠幫助啟動專案並塑造成功的管道時,我們就獲得了最大的成功。提供共用的元件,例如 Notebook、協調、資料版本控制 (DVC)、特征工程 (Feast) 和模型版本控制 (MLflow),讓團隊能夠直接協作。
未來展望
毫無疑問,資料科學正在發展我們的業務和我們客戶的業務。我們透過模型改進我們自己的產品,並構建了 AI 基礎架構,可以幫助我們保護應用程式和使用 AI 構建的應用程式。我們可以利用網路的力量為我們和我們的客戶提供 AI。我們與機器學習巨頭合作,使資料科學界更容易從資料中提供真正的價值。
行動號召:加入 Cloudflare 社群,將現代軟體做法和工具引入資料科學。請關注 Cloudflare 的更多資料科學。幫助我們安全地利用資料來協助構建更好的網際網路。