HTTP is the application protocol that powers the Web. It began life as the so-called HTTP/0.9 protocol in 1991, and by 1999 had evolved to HTTP/1.1, which was standardised within the IETF (Internet Engineering Task Force). HTTP/1.1 was good enough for a long time but the ever changing needs of the Web called for a better suited protocol, and HTTP/2 emerged in 2015. More recently it was announced that the IETF is intending to deliver a new version - HTTP/3. To some people this is a surprise and has caused a bit of confusion. If you don't track IETF work closely it might seem that HTTP/3 has come out of the blue. However, we can trace its origins through a lineage of experiments and evolution of Web protocols; specifically the QUIC transport protocol.
If you're not familiar with QUIC, my colleagues have done a great job of tackling different angles. John's blog describes some of the real-world annoyances of today's HTTP, Alessandro's blog tackles the nitty-gritty transport layer details, and Nick's blog covers how to get hands on with some testing. We've collected these and more at https://cloudflare-quic.com. And if that tickles your fancy, be sure to check out quiche, our own open-source implementation of the QUIC protocol written in Rust.
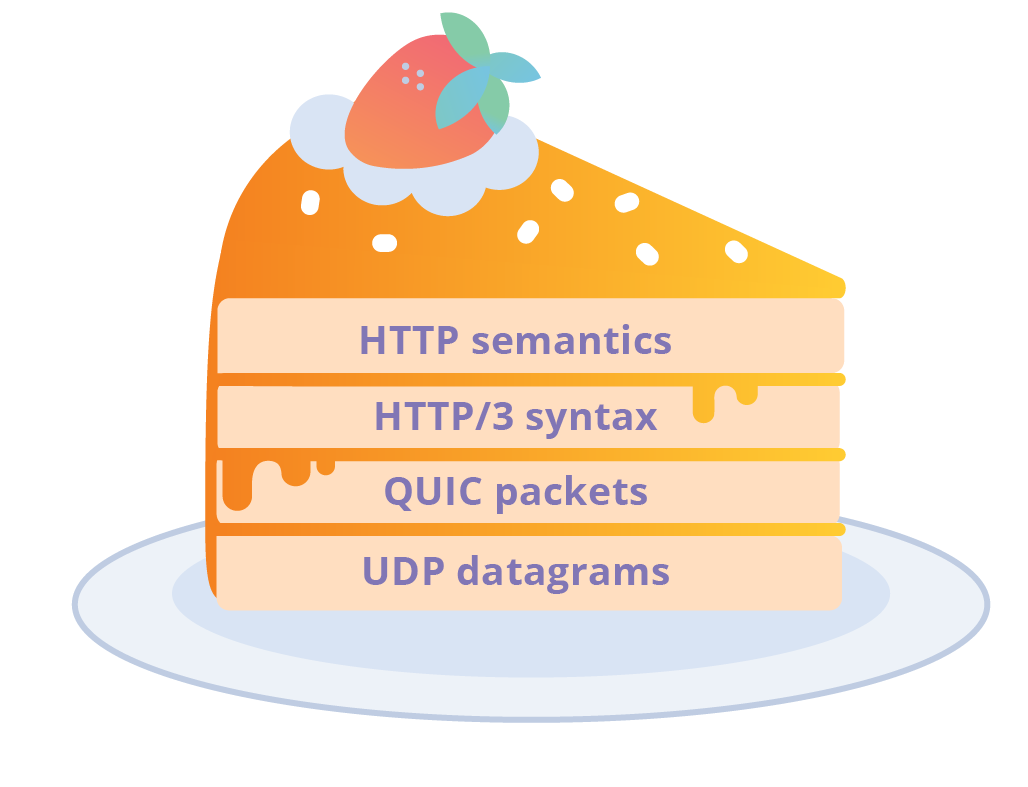
HTTP/3 is the HTTP application mapping to the QUIC transport layer. This name was made official in the recent draft version 17 (draft-ietf-quic-http-17), which was proposed in late October 2018, with discussion and rough consensus being formed during the IETF 103 meeting in Bangkok in November. HTTP/3 was previously known as HTTP over QUIC, which itself was previously known as HTTP/2 over QUIC. Before that we had HTTP/2 over gQUIC, and way back we had SPDY over gQUIC. The fact of the matter, however, is that HTTP/3 is just a new HTTP syntax that works on IETF QUIC, a UDP-based multiplexed and secure transport.
In this blog post we'll explore the history behind some of HTTP/3's previous names and present the motivation behind the most recent name change. We'll go back to the early days of HTTP and touch on all the good work that has happened along the way. If you're keen to get the full picture you can jump to the end of the article or open this highly detailed SVG version.
{kind=link}
Setting the scene
Just before we focus on HTTP, it is worth reminding ourselves that there are two protocols that share the name QUIC. As we explained previously, gQUIC is commonly used to identify Google QUIC (the original protocol), and QUIC is commonly used to represent the IETF standard-in-progress version that diverges from gQUIC.
Since its early days in the 90s, the web’s needs have changed. We've had new versions of HTTP and added user security in the shape of Transport Layer Security (TLS). We'll only touch on TLS in this post, our other blog posts are a great resource if you want to explore that area in more detail.
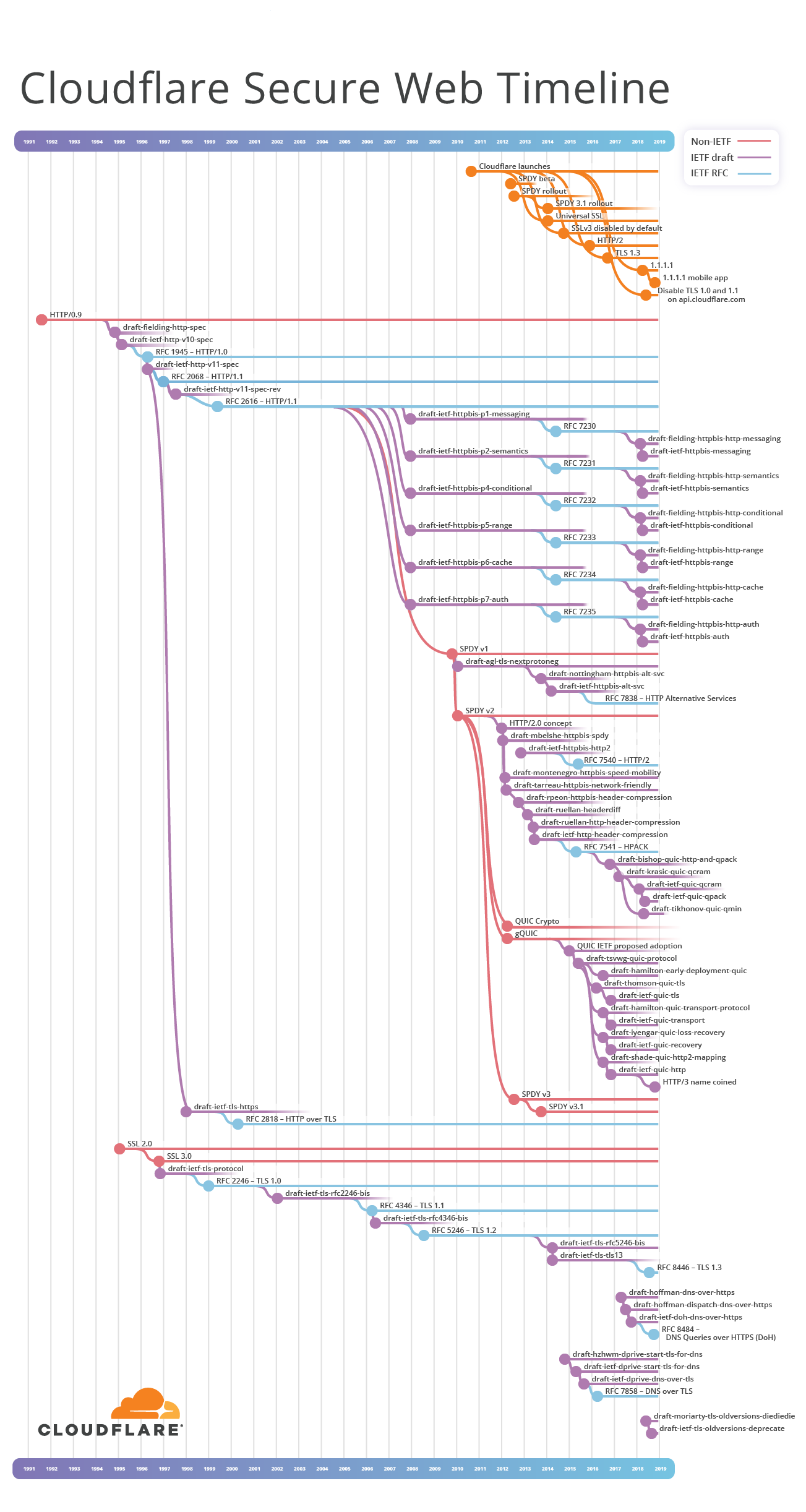
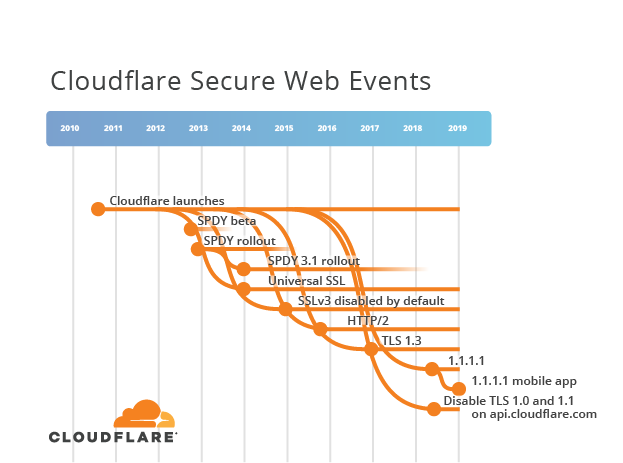
To help me explain the history of HTTP and TLS, I started to collate details of protocol specifications and dates. This information is usually presented in a textual form such as a list of bullets points stating document titles, ordered by date. However, there are branching standards, each overlapping in time and a simple list cannot express the real complexity of relationships. In HTTP, there has been parallel work that refactors core protocol definitions for easier consumption, extends the protocol for new uses, and redefines how the protocol exchanges data over the Internet for performance. When you're trying to join the dots over nearly 30 years of Internet history across different branching work streams you need a visualisation. So I made one - the Cloudflare Secure Web Timeline. (NB: Technically it is a Cladogram, but the term timeline is more widely known).
I have applied some artistic license when creating this, choosing to focus on the successful branches in the IETF space. Some of the things not shown include efforts in the W3 Consortium HTTP-NG working group, along with some exotic ideas that their authors are keen on explaining how to pronounce: HMURR (pronounced 'hammer') and WAKA (pronounced “wah-kah”).
In the next few sections I'll walk this timeline to explain critical chapters in the history of HTTP. To enjoy the takeaways from this post, it helps to have an appreciation of why standardisation is beneficial, and how the IETF approaches it. Therefore we'll start with a very brief overview of that topic before returning to the timeline itself. Feel free to skip the next section if you are already familiar with the IETF.
Types of Internet standard
Generally, standards define common terms of reference, scope, constraint, applicability, and other considerations. Standards exist in many shapes and sizes, and can be informal (aka de facto) or formal (agreed/published by a Standards Defining Organisation such as IETF, ISO or MPEG). Standards are used in many fields, there is even a formal British Standard for making tea - BS 6008.
The early Web used HTTP and SSL protocol definitions that were published outside the IETF, these are marked as red lines on the Secure Web Timeline. The uptake of these protocols by clients and servers made them de facto standards.
At some point, it was decided to formalise these protocols (some motivating reasons are described in a later section). Internet standards are commonly defined in the IETF, which is guided by the informal principle of "rough consensus and running code". This is grounded in experience of developing and deploying things on the Internet. This is in contrast to a "clean room" approach of trying to develop perfect protocols in a vacuum.
IETF Internet standards are commonly known as RFCs. This is a complex area to explain so I recommend reading the blog post "How to Read an RFC" by the QUIC Working Group Co-chair Mark Nottingham. A Working Group, or WG, is more or less just a mailing list.
Each year the IETF hold three meetings that provide the time and facilities for all WGs to meet in person if they wish. The agenda for these weeks can become very congested, with limited time available to discuss highly technical areas in depth. To overcome this, some WGs choose to also hold interim meetings in the months between the the general IETF meetings. This can help to maintain momentum on specification development. The QUIC WG has held several interim meetings since 2017, a full list is available on their meeting page.
These IETF meetings also provide the opportunity for other IETF-related collections of people to meet, such as the Internet Architecture Board or Internet Research Task Force. In recent years, an IETF Hackathon has been held during the weekend preceding the IETF meeting. This provides an opportunity for the community to develop running code and, importantly, to carry out interoperability testing in the same room with others. This helps to find issues in specifications that can be discussed in the following days.
For the purposes of this blog, the important thing to understand is that RFCs don't just spring into existence. Instead, they go through a process that usually starts with an IETF Internet Draft (I-D) format that is submitted for consideration of adoption. In the case where there is already a published specification, preparation of an I-D might just be a simple reformatting exercise. I-Ds have a 6 month active lifetime from the date of publish. To keep them active, new versions need to be published. In practice, there is not much consequence to letting an I-D elapse and it happens quite often. The documents continue to be hosted on the IETF document’s website for anyone that wants to read them.
I-Ds are represented on the Secure Web Timeline as purple lines. Each one has a unique name that takes the form of draft-{author name}-{working group}-{topic}-{version}. The working group field is optional, it might predict IETF WG that will work on the piece and sometimes this changes. If an I-D is adopted by the IETF, or if the I-D was initiated directly within the IETF, the name is draft-ietf-{working group}-{topic}-{version}. I-Ds may branch, merge or die on the vine. The version starts at 00 and increases by 1 each time a new draft is released. For example, the 4th draft of an I-D will have the version 03. Any time that an I-D changes name, its version resets back to 00.
It is important to note that anyone can submit an I-D to the IETF; you should not consider these as standards. But, if the IETF standardisation process of an I-D does reach consensus, and the final document passes review, we finally get an RFC. The name changes again at this stage. Each RFC gets a unique number e.g. RFC 7230. These are represented as blue lines on the Secure Web Timeline.
RFCs are immutable documents. This means that changes to the RFC require a completely new number. Changes might be done in order to incorporate fixes for errata (editorial or technical errors that were found and reported) or simply to refactor the specification to improve layout. RFCs may obsolete older versions (complete replacement), or just update them (substantively change).
All IETF documents are openly available on http://tools.ietf.org. Personally I find the IETF Datatracker a little more user friendly because it provides a visualisation of a documents progress from I-D to RFC.
Below is an example that shows the development of RFC 1945 - HTTP/1.0 and it is a clear source of inspiration for the Secure Web Timeline.
Interestingly, in the course of my work I found that the above visualisation is incorrect. It is missing draft-ietf-http-v10-spec-05 for some reason. Since the I-D lifetime is 6 months, there appears to be a gap before it became an RFC, whereas in reality draft 05 was still active through until August 1996.
Exploring the Secure Web Timeline
With a small appreciation of how Internet standards documents come to fruition, we can start to walk the the Secure Web Timeline. In this section are a number of excerpt diagrams that show an important part of the timeline. Each dot represents the date that a document or capability was made available. For IETF documents, draft numbers are omitted for clarity. However, if you want to see all that detail please check out the complete timeline.
HTTP began life as the so-called HTTP/0.9 protocol in 1991, and in 1994 the I-D draft-fielding-http-spec-00 was published. This was adopted by the IETF soon after, causing the name change to draft-ietf-http-v10-spec-00. The I-D went through 6 draft versions before being published as RFC 1945 - HTTP/1.0 in 1996.
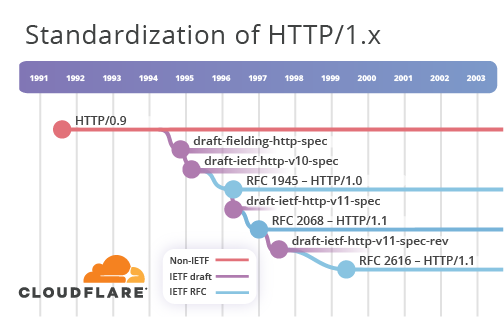
However, even before the HTTP/1.0 work completed, a separate activity started on HTTP/1.1. The I-D draft-ietf-http-v11-spec-00 was published in November 1995 and was formally published as RFC 2068 in 1997. The keen eyed will spot that the Secure Web Timeline doesn't quite capture that sequence of events, this is an unfortunate side effect of the tooling used to generate the visualisation. I tried to minimise such problems where possible.
An HTTP/1.1 revision exercise was started in mid-1997 in the form of draft-ietf-http-v11-spec-rev-00. This completed in 1999 with the publication of RFC 2616. Things went quiet in the IETF HTTP world until 2007. We'll come back to that shortly.
A History of SSL and TLS
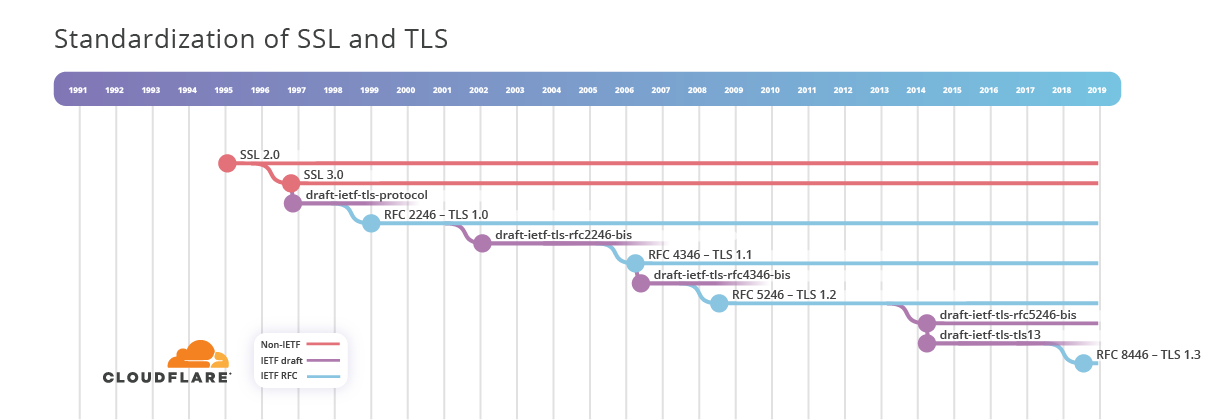
Switching tracks to SSL. We see that the SSL 2.0 specification was released sometime around 1995, and that SSL 3.0 was released in November 1996. Interestingly, SSL 3.0 is described by RFC 6101, which was released in August 2011. This sits in Historic category, which "is usually done to document ideas that were considered and discarded, or protocols that were already historic when it was decided to document them." according to the IETF. In this case it is advantageous to have an IETF-owned document that describes SSL 3.0 because it can be used as a canonical reference elsewhere.
Of more interest to us is how SSL inspired the development of TLS, which began life as draft-ietf-tls-protocol-00 in November 1996. This went through 6 draft versions and was published as RFC 2246 - TLS 1.0 at the start of 1999.
Between 1995 and 1999, the SSL and TLS protocols were used to secure HTTP communications on the Internet. This worked just fine as a de facto standard. It wasn't until January 1998 that the formal standardisation process for HTTPS was started with the publication of I-D draft-ietf-tls-https-00. That work concluded in May 2000 with the publication of RFC 2616 - HTTP over TLS.
TLS continued to evolve between 2000 and 2007, with the standardisation of TLS 1.1 and 1.2. There was a gap of 7 years until work began on the next version of TLS, which was adopted as draft-ietf-tls-tls13-00 in April 2014 and, after 28 drafts, completed as RFC 8446 - TLS 1.3 in August 2018.
Internet standardisation process
After taking a small look at the timeline, I hope you can build a sense of how the IETF works. One generalisation for the way that Internet standards take shape is that researchers or engineers design experimental protocols that suit their specific use case. They experiment with protocols, in public or private, at various levels of scale. The data helps to identify improvements or issues. The work may be published to explain the experiment, to gather wider input or to help find other implementers. Take up of this early work by others may make it a de facto standard; eventually there may be sufficient momentum that formal standardisation becomes an option.
The status of a protocol can be an important consideration for organisations that may be thinking about implementing, deploying or in some way using it. A formal standardisation process can make a de facto standard more attractive because it tends to provide stability. The stewardship and guidance is provided by an organisation, such as the IETF, that reflects a wider range of experiences. However, it is worth highlighting that not all all formal standards succeed.
The process of creating a final standard is almost as important as the standard itself. Taking an initial idea and inviting contribution from people with wider knowledge, experience and use cases can to help produce something that will be of more use to a wider population. However, the standardisation process is not always easy. There are pitfalls and hurdles. Sometimes the process takes so long that the output is no longer relevant.
Each Standards Defining Organisation tends to have its own process that is geared around its field and participants. Explaining all of the details about how the IETF works is well beyond the scope of this blog. The IETF's "How we work" page is an excellent starting point that covers many aspects. The best method to forming understanding, as usual, is to get involved yourself. This can be as easy as joining an email list or adding to discussion on a relevant GitHub repository.
Cloudflare's running code
Cloudflare is proud to be early an adopter of new and evolving protocols. We have a long record of adopting new standards early, such as HTTP/2. We also test features that are experimental or yet to be final, like TLS 1.3 and SPDY.
In relation to the IETF standardisation process, deploying this running code on real networks across a diverse body of websites helps us understand how well the protocol will work in practice. We combine our existing expertise with experimental information to help improve the running code and, where it makes sense, feedback issues or improvements to the WG that is standardising a protocol.
Testing new things is not the only priority. Part of being an innovator is knowing when it is time to move forward and put older innovations in the rear view mirror. Sometimes this relates to security-oriented protocols, for example, Cloudflare disabled SSLv3 by default due of the POODLE vulnerability. In other cases, protocols become superseded by a more technologically advanced one; Cloudflare deprecated SPDY support in favour of HTTP/2.
The introduction and deprecation of relevant protocols are represented on the Secure Web Timeline as orange lines. Dotted vertical lines help correlate Cloudflare events to relevant IETF documents. For example, Cloudflare introduced TLS 1.3 support in September 2016, with the final document, RFC 8446, being published almost two years later in August 2018.
Refactoring in HTTPbis
HTTP/1.1 is a very successful protocol and the timeline shows that there wasn't much activity in the IETF after 1999. However, the true reflection is that years of active use gave implementation experience that unearthed latent issues with RFC 2616, which caused some interoperability issues. Furthermore, the protocol was extended by other RFCs like 2817 and 2818. It was decided in 2007 to kickstart a new activity to improve the HTTP protocol specification. This was called HTTPbis (where "bis" stems from Latin meaning "two", "twice" or "repeat") and it took the form of a new Working Group. The original charter does a good job of describing the problems that were trying to be solved.
In short, HTTPbis decided to refactor RFC 2616. It would incorporate errata fixes and buy in some aspects of other specifications that had been published in the meantime. It was decided to split the document up into parts. This resulted in 6 I-Ds published in December 2007:
- draft-ietf-httpbis-p1-messaging
- draft-ietf-httpbis-p2-semantics
- draft-ietf-httpbis-p4-conditional
- draft-ietf-httpbis-p5-range
- draft-ietf-httpbis-p6-cache
- draft-ietf-httpbis-p7-auth
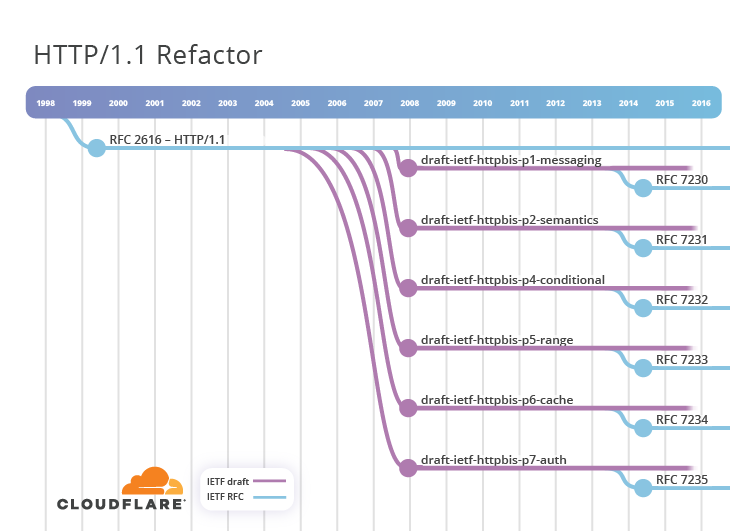
The diagram shows how this work progressed through a lengthy drafting process of 7 years, with 27 draft versions being released, before final standardisation. In June 2014, the so-called RFC 723x series was released (where x ranges from 0 to 5). The Chair of the HTTPbis WG celebrated this achievement with the acclimation "RFC2616 is Dead". If it wasn't clear, these new documents obsoleted the older RFC 2616.
What does any of this have to do with HTTP/3?
While the IETF was busy working on the RFC 723x series the world didn't stop. People continued to enhance, extend and experiment with HTTP on the Internet. Among them were Google, who had started to experiment with something called SPDY (pronounced speedy). This protocol was touted as improving the performance of web browsing, a principle use case for HTTP. At the end of 2009 SPDY v1 was announced, and it was quickly followed by SPDY v2 in 2010.
I want to avoid going into the technical details of SPDY. That's a topic for another day. What is important, is to understand that SPDY took the core paradigms of HTTP and modified the interchange format slightly in order to gain improvements. With hindsight, we can see that HTTP has clearly delimited semantics and syntax. Semantics describe the concept of request and response exchanges including: methods, status codes, header fields (metadata) and bodies (payload). Syntax describe how to map semantics to bytes on the wire.
HTTP/0.9, 1.0 and 1.1 share many semantics. They also share syntax in the form of character strings that are sent over TCP connections. SPDY took HTTP/1.1 semantics and changed the syntax from strings to binary. This is a really interesting topic but we will go no further down that rabbit hole today.
Google's experiments with SPDY showed that there was promise in changing HTTP syntax, and value in keeping the existing HTTP semantics. For example, keeping the format of URLs to use https:// avoided many problems that could have affected adoption.
Having seen some of the positive outcomes, the IETF decided it was time to consider what HTTP/2.0 might look like. The slides from the HTTPbis session held during IETF 83 in March 2012 show the requirements, goals and measures of success that were set out. It is also clearly states that "HTTP/2.0 only signifies that the wire format isn't compatible with that of HTTP/1.x".
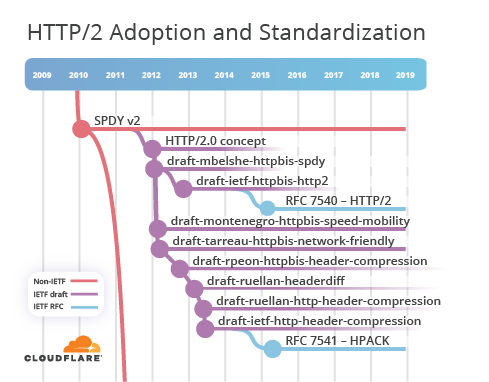
During that meeting the community was invited to share proposals. I-Ds that were submitted for consideration included draft-mbelshe-httpbis-spdy-00, draft-montenegro-httpbis-speed-mobility-00 and draft-tarreau-httpbis-network-friendly-00. Ultimately, the SPDY draft was adopted and in November 2012 work began on draft-ietf-httpbis-http2-00. After 18 drafts across a period of just over 2 years, RFC 7540 - HTTP/2 was published in 2015. During this specification period, the precise syntax of HTTP/2 diverged just enough to make HTTP/2 and SPDY incompatible.
These years were a very busy period for the HTTP-related work at the IETF, with the HTTP/1.1 refactor and HTTP/2 standardisation taking place in parallel. This is in stark contrast to the many years of quiet in the early 2000s. Be sure to check out the full timeline to really appreciate the amount of work that took place.
Although HTTP/2 was in the process of being standardised, there was still benefit to be had from using and experimenting with SPDY. Cloudflare introduced support for SPDY in August 2012 and only deprecated it in February 2018 when our statistics showed that less than 4% of Web clients continued to want SPDY. Meanwhile, we introduced HTTP/2 support in December 2015, not long after the RFC was published, when our analysis indicated that a meaningful proportion of Web clients could take advantage of it.
Web client support of the SPDY and HTTP/2 protocols preferred the secure option of using TLS. The introduction of Universal SSL in September 2014 helped ensure that all websites signed up to Cloudflare were able to take advantage of these new protocols as we introduced them.
gQUIC
Google continued to experiment between 2012 and 2015 they released SPDY v3 and v3.1. They also started working on gQUIC (pronounced, at the time, as quick) and the initial public specification was made available in early 2012.
The early versions of gQUIC made use of the SPDY v3 form of HTTP syntax. This choice made sense because HTTP/2 was not yet finished. The SPDY binary syntax was packaged into QUIC packets that could sent in UDP datagrams. This was a departure from the TCP transport that HTTP traditionally relied on. When stacked up all together this looked like:
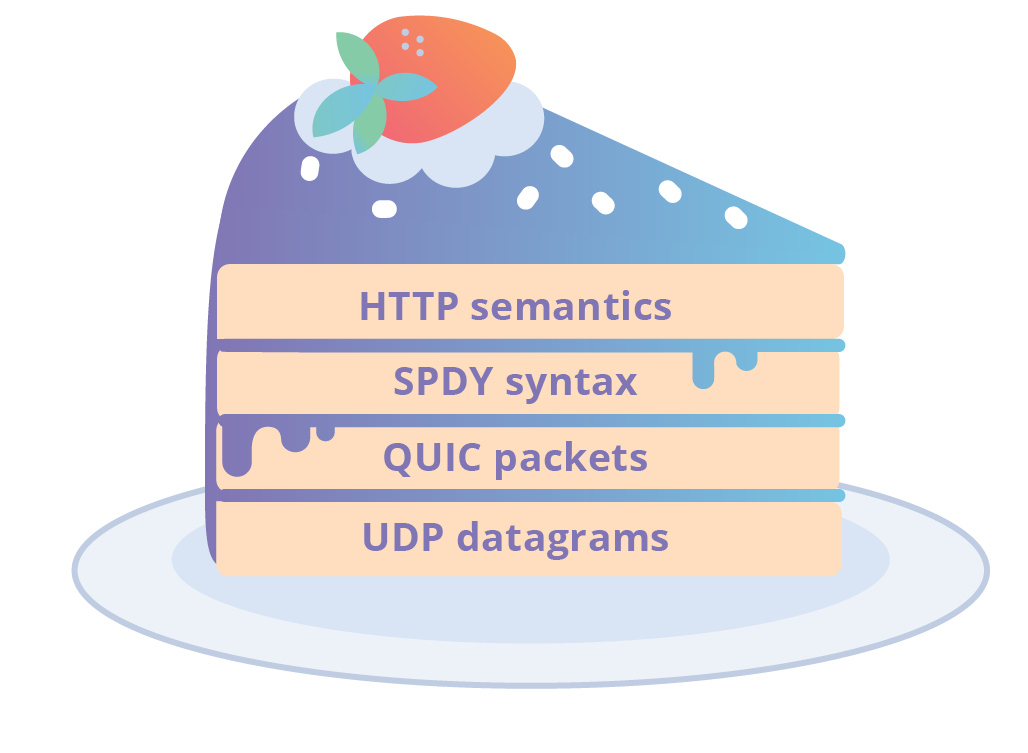
gQUIC used clever tricks to achieve performance. One of these was to break the clear layering between application and transport. What this meant in practice was that gQUIC only ever supported HTTP. So much so that gQUIC, termed "QUIC" at the time, was synonymous with being the next candidate version of HTTP. Despite the continued changes to QUIC over the last few years, which we'll touch on momentarily, to this day, the term QUIC is understood by people to mean that initial HTTP-only variant. Unfortunately this is a regular source of confusion when discussing the protocol.
gQUIC continued to experiment and eventually switched over to a syntax much closer to HTTP/2. So close in fact that most people simply called it "HTTP/2 over QUIC". However, because of technical constraints there were some very subtle differences. One example relates to how the HTTP headers were serialized and exchanged. It is a minor difference but in effect means that HTTP/2 over gQUIC was incompatible with the IETF's HTTP/2.
Last but not least, we always need to consider the security aspects of Internet protocols. gQUIC opted not to use TLS to provide security. Instead Google developed a different approach called QUIC Crypto. One of the interesting aspects of this was a new method for speeding up security handshakes. A client that had previously established a secure session with a server could reuse information to do a "zero round-trip time", or 0-RTT, handshake. 0-RTT was later incorporated into TLS 1.3.
Are we at the point where you can tell me what HTTP/3 is yet?
Almost.
By now you should be familiar with how standardisation works and gQUIC is not much different. There was sufficient interest that the Google specifications were written up in I-D format. In June 2015 draft-tsvwg-quic-protocol-00, entitled "QUIC: A UDP-based Secure and Reliable Transport for HTTP/2" was submitted. Keep in mind my earlier statement that the syntax was almost-HTTP/2.
Google announced that a Bar BoF would be held at IETF 93 in Prague. For those curious about what a "Bar BoF" is, please consult RFC 6771. Hint: BoF stands for Birds of a Feather.
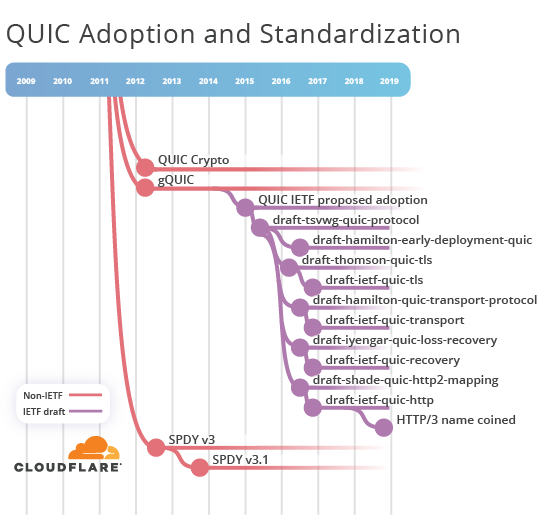
The outcome of this engagement with the IETF was, in a nutshell, that QUIC seemed to offer many advantages at the transport layer and that it should be decoupled from HTTP. The clear separation between layers should be re-introduced. Furthermore, there was a preference for returning back to a TLS-based handshake (which wasn't so bad since TLS 1.3 was underway at this stage, and it was incorporating 0-RTT handshakes).
About a year later, in 2016, a new set of I-Ds were submitted:
- draft-hamilton-quic-transport-protocol-00
- draft-thomson-quic-tls-00
- draft-iyengar-quic-loss-recovery-00
- draft-shade-quic-http2-mapping-00
Here's where another source of confusion about HTTP and QUIC enters the fray. draft-shade-quic-http2-mapping-00 is entitled "HTTP/2 Semantics Using The QUIC Transport Protocol" and it describes itself as "a mapping of HTTP/2 semantics over QUIC". However, this is a misnomer. HTTP/2 was about changing syntax while maintaining semantics. Furthermore, "HTTP/2 over gQUIC" was never an accurate description of the syntax either, for the reasons I outlined earlier. Hold that thought.
This IETF version of QUIC was to be an entirely new transport protocol. That's a large undertaking and before diving head-first into such commitments, the IETF likes to gauge actual interest from its members. To do this, a formal Birds of a Feather meeting was held at the IETF 96 meeting in Berlin in 2016. I was lucky enough to attend the session in person and the slides don't give it justice. The meeting was attended by hundreds, as shown by Adam Roach's photograph. At the end of the session consensus was reached; QUIC would be adopted and standardised at the IETF.
The first IETF QUIC I-D for mapping HTTP to QUIC, draft-ietf-quic-http-00, took the Ronseal approach and simplified its name to "HTTP over QUIC". Unfortunately, it didn't finish the job completely and there were many instances of the term HTTP/2 throughout the body. Mike Bishop, the I-Ds new editor, identified this and started to fix the HTTP/2 misnomer. In the 01 draft, the description changed to "a mapping of HTTP semantics over QUIC".
Gradually, over time and versions, the use of the term "HTTP/2" decreased and the instances became mere references to parts of RFC 7540. Roll forward two years to October 2018 and the I-D is now at version 16. While HTTP over QUIC bares similarity to HTTP/2 it ultimately is an independent, non-backwards compatible HTTP syntax. However, to those that don't track IETF development very closely (a very very large percentage of the Earth's population), the document name doesn't capture this difference. One of the main points of standardisation is to aid communication and interoperability. Yet a simple thing like naming is a major contributor to confusion in the community.
Recall what was said in 2012, "HTTP/2.0 only signifies that the wire format isn't compatible with that of HTTP/1.x". The IETF followed that existing cue. After much deliberation in the lead up to, and during, IETF 103, consensus was reached to rename "HTTP over QUIC" to HTTP/3. The world is now in a better place and we can move on to more important debates.
But RFC 7230 and 7231 disagree with your definition of semantics and syntax!
Sometimes document titles can be confusing. The present HTTP documents that describe syntax and semantics are:
- RFC 7230 - Hypertext Transfer Protocol (HTTP/1.1): Message Syntax and Routing
- RFC 7231 - Hypertext Transfer Protocol (HTTP/1.1): Semantics and Content
It is possible to read too much into these names and believe that fundamental HTTP semantics are specific for versions of HTTP i.e. HTTP/1.1. However, this is an unintended side effect of the HTTP family tree. The good news is that the HTTPbis Working Group are trying to address this. Some brave members are going through another round of document revision, as Roy Fielding put it, "one more time!". This work is underway right now and is known as the HTTP Core activity (you may also have heard of this under the moniker HTTPtre or HTTPter; naming things is hard). This will condense the six drafts down to three:
- HTTP Semantics (draft-ietf-httpbis-semantics)
- HTTP Caching (draft-ietf-httpbis-caching)
- HTTP/1.1 Message Syntax and Routing (draft-ietf-httpbis-messaging)
Under this new structure, it becomes more evident that HTTP/2 and HTTP/3 are syntax definitions for the common HTTP semantics. This doesn't mean they don't have their own features beyond syntax but it should help frame discussion going forward.
Pulling it all together
This blog post has taken a shallow look at the standardisation process for HTTP in the IETF across the last three decades. Without touching on many technical details, I've tried to explain how we have ended up with HTTP/3 today. If you skipped the good bits in the middle and are looking for a one liner here it is: HTTP/3 is just a new HTTP syntax that works on IETF QUIC, a UDP-based multiplexed and secure transport. There are many interesting technical areas to explore further but that will have to wait for another day.
In the course of this post, we explored important chapters in the development of HTTP and TLS but did so in isolation. We close out the blog by pulling them all together into the complete Secure Web Timeline presented below. You can use this to investigate the detailed history at your own comfort. And for the super sleuths, be sure to check out the full version including draft numbers.