


Workers AI est notre plateforme d'inférence serverless basée sur des GPU, qui s'exécute sur le réseau mondial de Cloudflare. Elle propose un catalogue grandissant de modèles prêts à l'emploi, qui s'intègrent avec fluidité à Workers, permettant aux développeurs de créer des applications d'IA puissantes et évolutives en quelques minutes seulement. Nous avons déjà vu des développeurs accomplir des choses incroyables avec Workers AI, et nous sommes impatients de découvrir ce qu'ils créeront à mesure que nous continuons à développer la plateforme. À cette fin, nous sommes heureux d'annoncer aujourd'hui une sélection de nouvelles fonctionnalités particulièrement demandées : la diffusion en continu de réponses pour tous les grands modèles de langage (LLM) sur Workers AI, des fenêtres de contexte et de séquence plus grandes et une variante du modèle Llama-2 doté d'une précision totale.
Si vous avez déjà utilisé ChatGPT, vous connaissez les avantages qu'offre la diffusion en continu des réponses, selon laquelle les réponses sont reçues jeton par jeton. Au niveau interne, les LLM opèrent en générant des réponses séquentiellement, via un processus d'inférence répétée : le résultat intégral d'un modèle LLM est fondamentalement une séquence de centaines ou de milliers de tâches de prédiction individuelles. Par conséquent, bien qu'il ne faille que quelques millisecondes pour générer un jeton unique, la génération de la réponse intégrale demande davantage de temps, de l'ordre de quelques secondes. La bonne nouvelle est que nous pouvons commencer à afficher la réponse dès que les premiers jetons sont générés, puis ajouter chaque jeton supplémentaire jusqu'à ce que la réponse soit complète. Cette approche offre à l'utilisateur final une expérience considérablement meilleure : l'affichage progressif du texte à mesure de sa génération permet non seulement une réactivité instantanée, mais laisse également à l'utilisateur final le temps de lire et d'interpréter le texte.
À compter d'aujourd'hui, vous pouvez utiliser la diffusion en continu des réponses pour n'importe quel modèle LLM de notre catalogue, notamment le très apprécié modèle Llama-2. Voici comment cela fonctionne.
Événements transmis par le serveur : un petit bijou dans l'API de navigateur
Les événements transmis par le serveur sont faciles à utiliser, simples à mettre en œuvre côté serveur, normalisés et largement disponibles sur de nombreuses plateformes, nativement ou sous forme de polyfill. Les événements transmis par le serveur répondent au besoin très spécialisé de gestion d'un flux de mises à jour provenant du serveur, éliminant la nécessité d'exécuter le code de base qui serait autrement nécessaire au traitement du flux d'événements.
| Facile à utiliser | Streaming | Bidirectionnel | |
|---|---|---|---|
| fetch | ✅ | ||
| Événements transmis par le serveur | ✅ | ✅ | |
| Serveurs WebSocket | ✅ | ✅ |
Pour commencer à utiliser la diffusion en continu avec les modèles de génération de texte de Workers AI et les événements transmis par le serveur, définissez le paramètre « stream » dans l'entrée de la requête sur « true ». Cela modifiera le format de la réponse et l'identifiant mime-type en text/event-stream.
Voici un exemple d'utilisation de la diffusion en continu avec l'API REST :
curl -X POST \
"https://api.cloudflare.com/client/v4/accounts/<account>/ai/run/@cf/meta/llama-2-7b-chat-int8" \
-H "Authorization: Bearer <token>" \
-H "Content-Type:application/json" \
-d '{ "prompt": "where is new york?", "stream": true }'
data: {"response":"New"}
data: {"response":" York"}
data: {"response":" is"}
data: {"response":" located"}
data: {"response":" in"}
data: {"response":" the"}
...
data: [DONE]Et voici un exemple avec un script Workers :
import { Ai } from "@cloudflare/ai";
export default {
async fetch(request, env, ctx) {
const ai = new Ai(env.AI, { sessionOptions: { ctx: ctx } });
const stream = await ai.run(
"@cf/meta/llama-2-7b-chat-int8",
{ prompt: "where is new york?", stream: true }
);
return new Response(stream,
{ headers: { "content-type": "text/event-stream" } }
);
}
}Si vous souhaitez consommer le flux d'événements résultant de cette instance Workers sur une page de navigateur, le code JavaScript côté client se présentera, dans les grandes lignes, comme ceci :
const source = new EventSource("/worker-endpoint");
source.onmessage = (event) => {
if(event.data=="[DONE]") {
// SSE spec says the connection is restarted
// if we don't explicitly close it
source.close();
return;
}
const data = JSON.parse(event.data);
el.innerHTML += data.response;
}Vous pouvez utiliser ce code simple avec n'importe quelle page HTML simple, des SPA complexes utilisant React ou d'autres frameworks web.
Cette approche permet de créer une expérience beaucoup plus interactive pour l'utilisateur, qui voit maintenant la page être actualisée au fur et à mesure de la création de la réponse, au lieu de devoir attendre que la séquence complète de réponses soit générée. Vous pouvez tester la diffusion en continu à l'adresse ai.cloudflare.com.
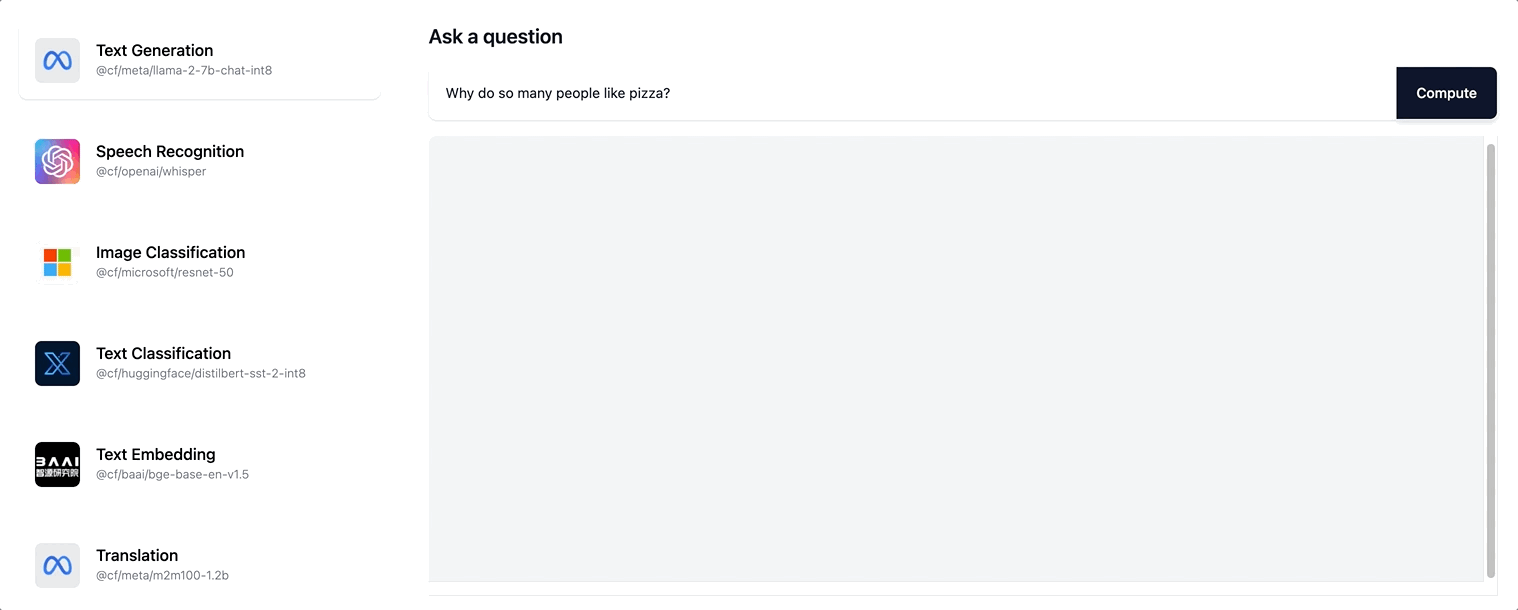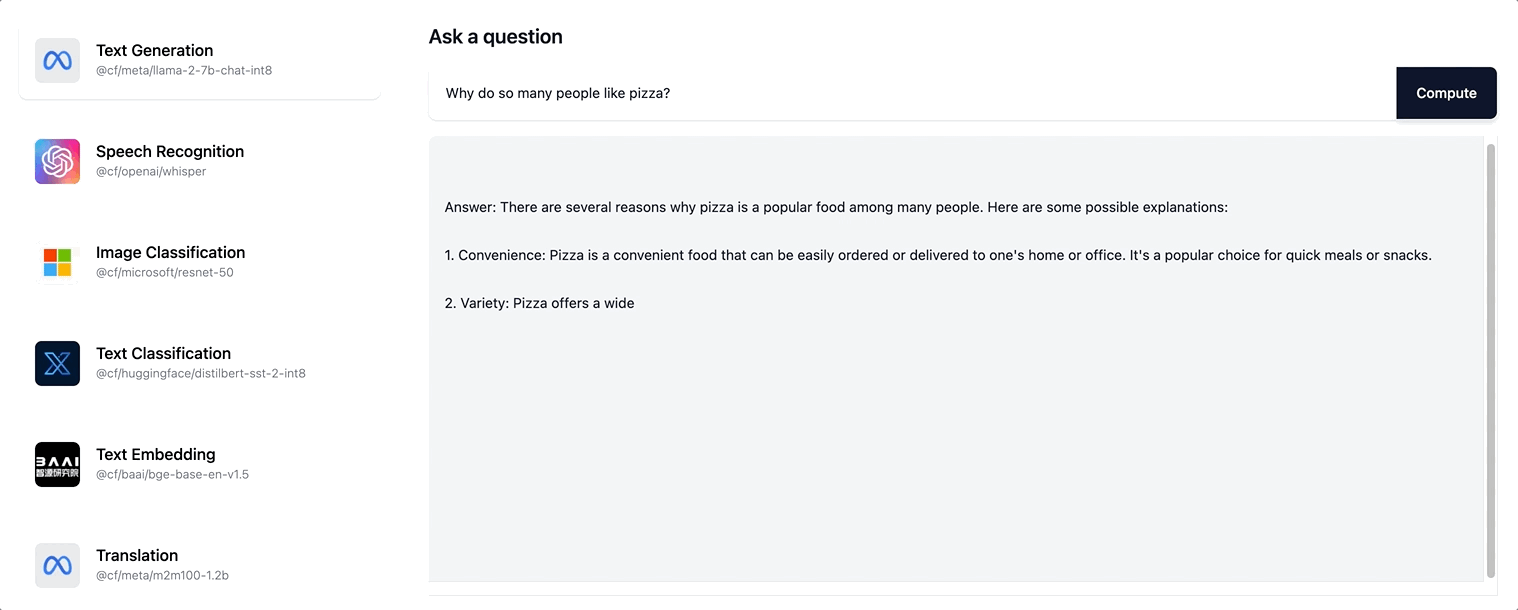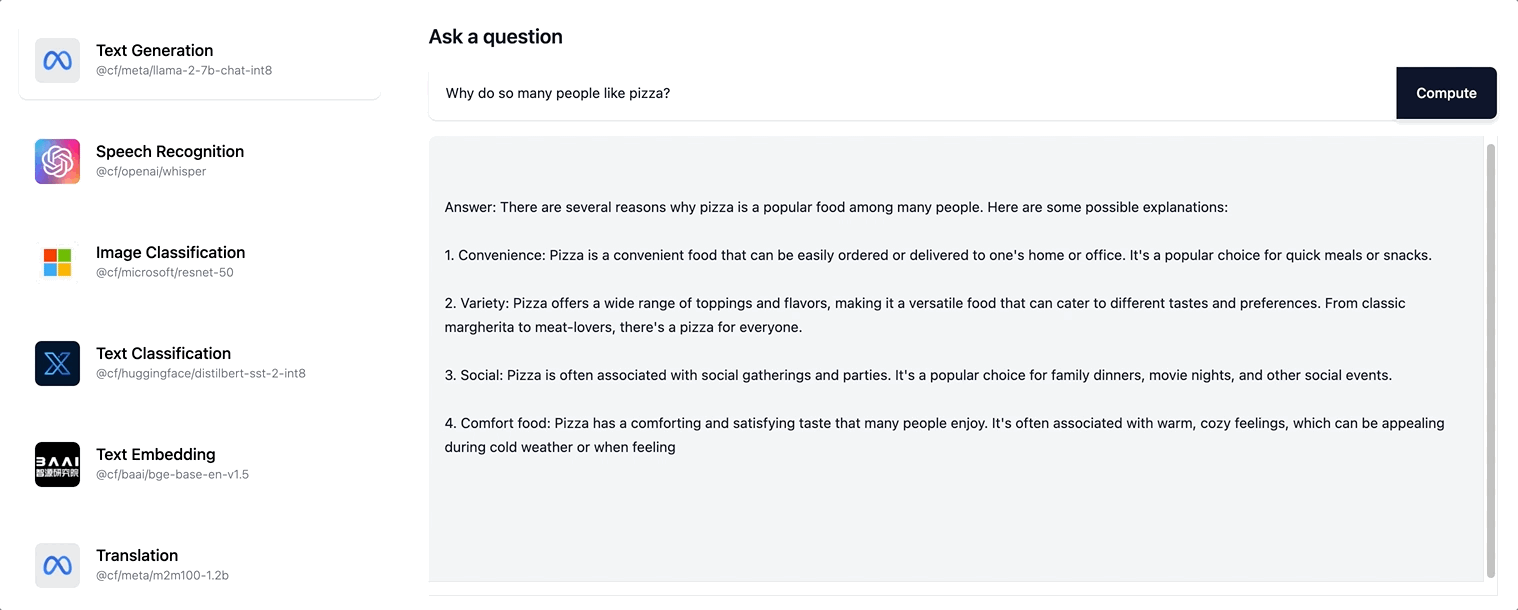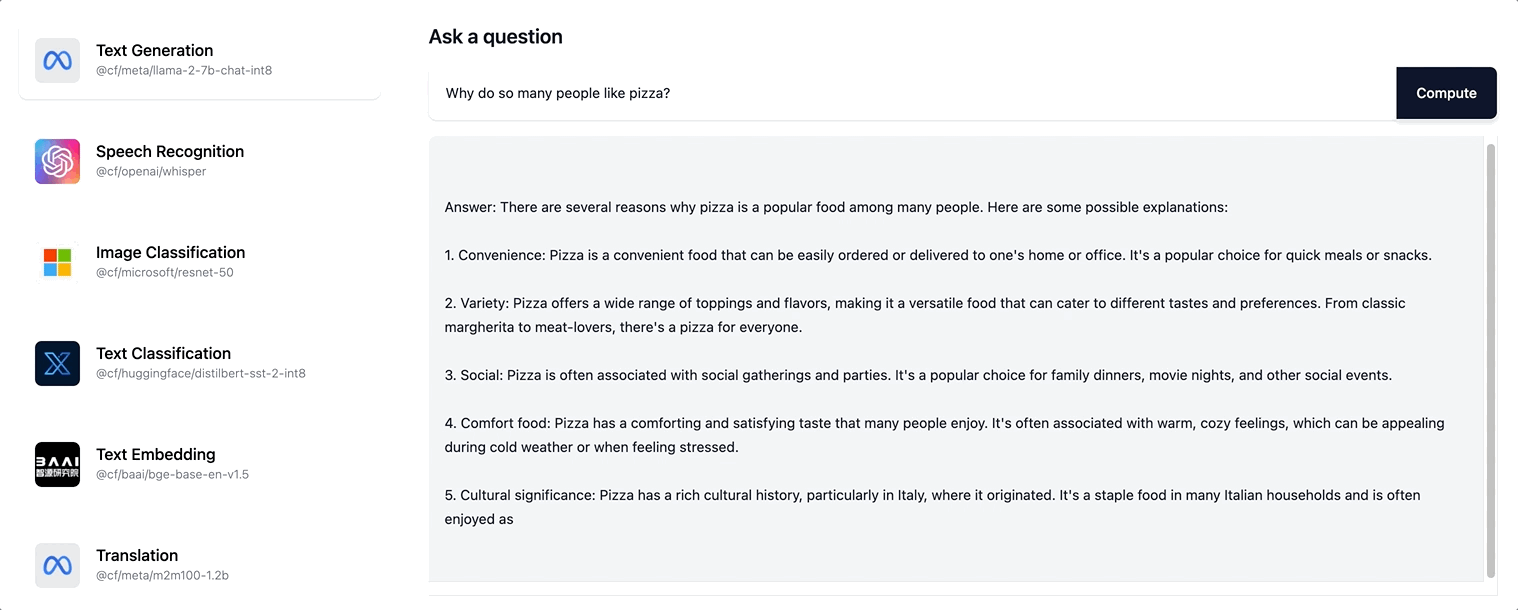
Workers AI prend en charge la diffusion en continu de réponses au format texte pour le modèle Llama-2 ainsi que pour les éventuels futurs modèles LLM que nous ajoutons à notre catalogue.
Mais ce n'est pas tout.
Précision supérieure, longueurs de contexte et de séquence plus importantes
Une autre demande que nous avons fréquemment reçue de notre communauté suite au lancement de Workers AI concernait l'utilisation de questions et de réponses plus longues dans notre modèle Llama-2. Dans la terminologie des LLM, cela se traduit par une longueur de contexte (le nombre de jetons acceptés en tant qu'entrée par le modèle avant l'exécution de la prédiction) et une longueur de séquence (le nombre de jetons que le modèle génère dans la réponse) plus importantes.
Nous sommes à l'écoute de notre communauté et, conjointement à la diffusion en continu, nous ajoutons aujourd'hui au catalogue une variante 16 bits de Llama-2 avec une précision totale et augmentons les longueurs de contexte et de séquence de la version 8 bits existante.
| Modèle | Longueur de contexte (entrée) | Longueur de séquence (résultat) |
|---|---|---|
| @cf/meta/llama-2-7b-chat-int8 | 2048 (768 avant) | 1800 (256 avant) |
| @cf/meta/llama-2-7b-chat-fp16 | 3072 | 2500 |
La diffusion en continu, la précision supérieure et l'allongement des longueurs de contexte et de séquence offrent une meilleure expérience utilisateur et permettent de créer de nouvelles applications plus riches avec les grands modèles de langage dans Workers AI.
Consultez la documentation pour développeurs de Workers AI pour plus d'informations et d'options. Si vous avez des questions ou des commentaires concernant Workers AI, n'hésitez pas à venir nous en faire part dans la Communauté Cloudflare et sur le Discord Cloudflare.
Si vous vous intéressez à l'apprentissage automatique et l'IA serverless, l'équipe de Cloudflare Workers AI développe une plateforme et des outils de portée mondiale qui permettent à nos clients d'exécuter des tâches d'inférence rapides et à faible latence sur notre réseau. Consultez notre page d'offres d'emploi pour découvrir les opportunités que nous vous proposons.