
Récemment à laNetdev 0x13, lors de la conférence sur les réseaux Linux à Prague, je suisbrièvement intervenu sur « Linux chez Cloudflare ». La discussion a surtout porté sur BPF. Il semble, peu importe la question, que la réponse soit BPF.
Voici une transcription d'une version légèrement modifiée de cette discussion.
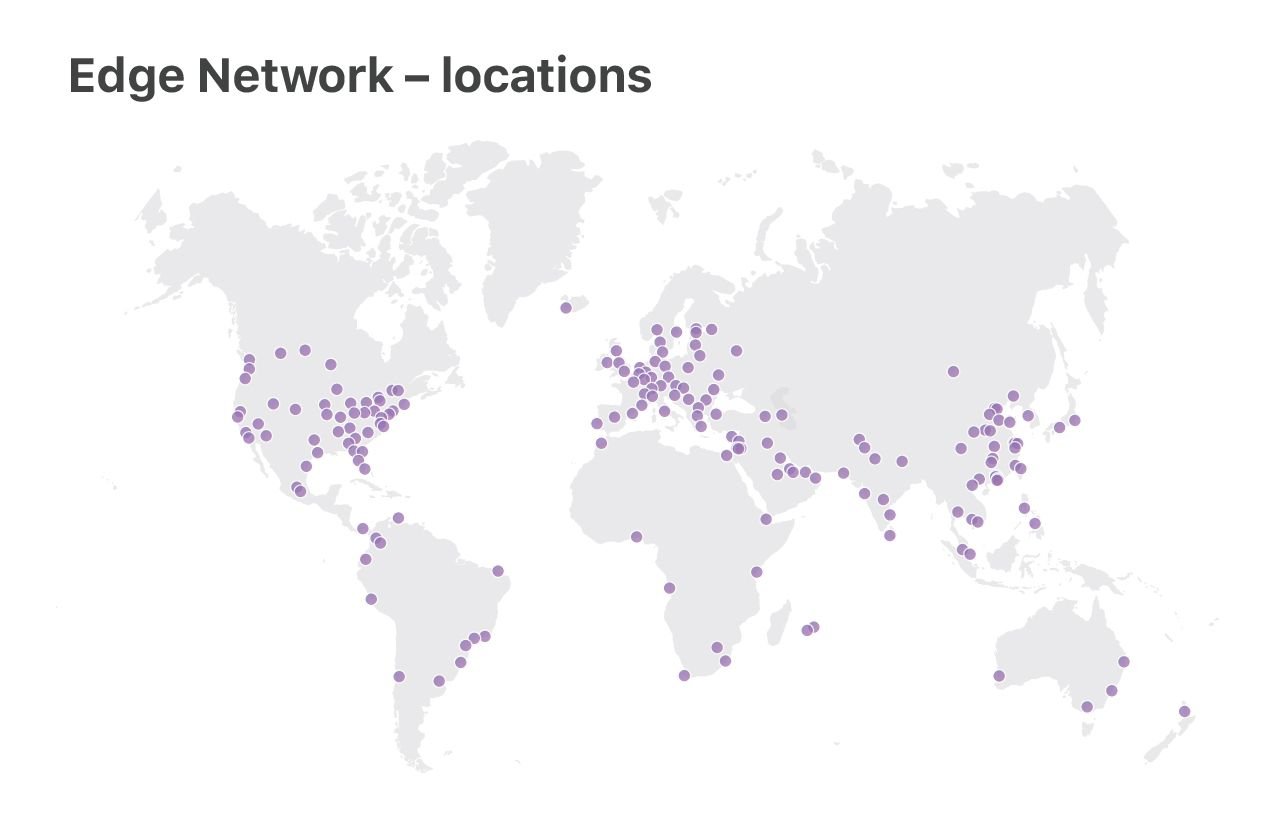
Chez Cloudflare, nous utilisons Linux sur nos serveurs. Nous exploitons deux catégories de centres de données : les grands centres de données « Principaux » qui traitent les journaux, analysent les attaques et effectuent les analyses informatiques, et le parc de serveurs « Edge » qui fournit du contenu client à partir de 180 emplacements dans le monde.
Dans cette présentation, nous allons nous concentrer sur les serveurs « Edge ». C'est ici que nous utilisons les dernières fonctionnalités de Linux, optimisons la performance et accordons une grande attention à la résilience DoS.
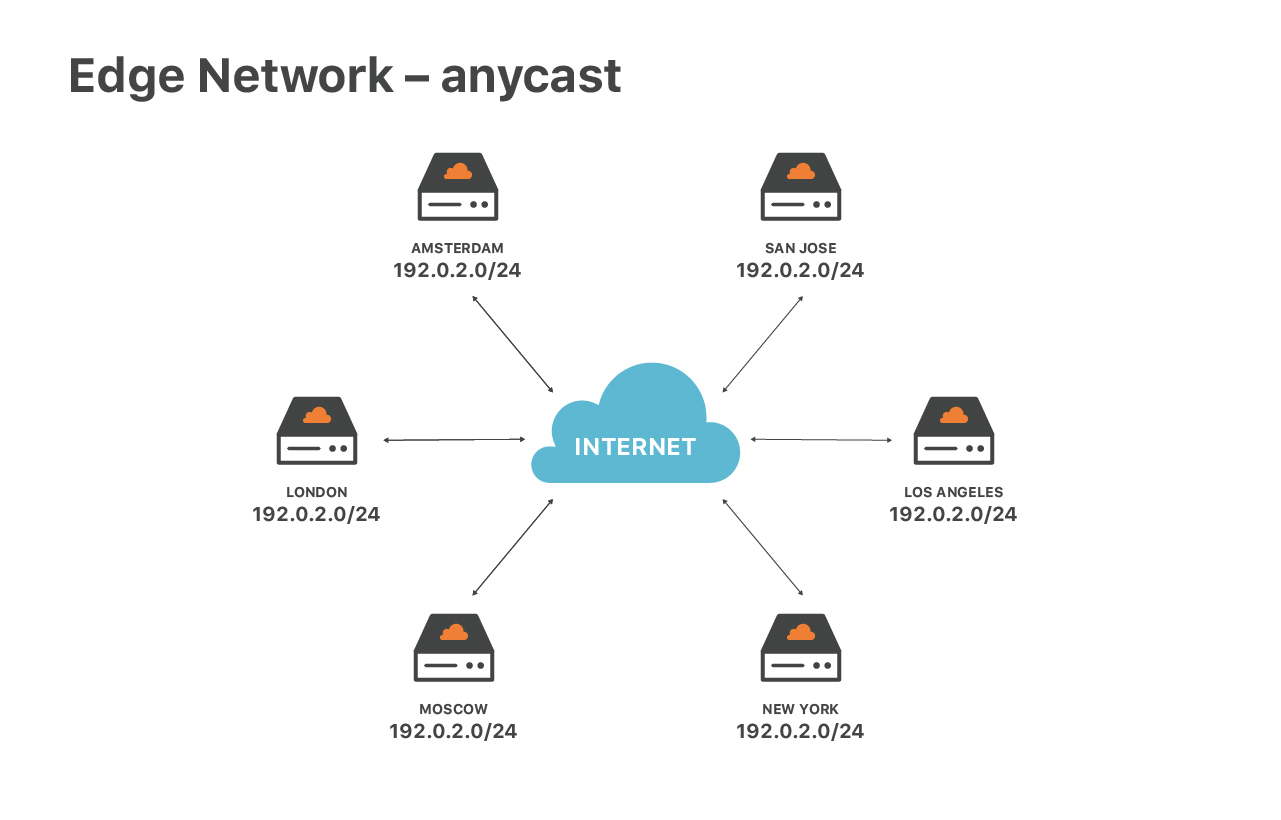
Notre service de périphérie est particulier en raison de la configuration de notre réseau. Nous avons largement recours au routage anycast. Anycast signifie que le même ensemble d'adresses IP est annoncé par tous nos centres de données.
Cette conception possède de grands avantages. Premièrement, elle garantit la vitesse optimale aux utilisateurs finaux. Où que vous vous trouviez, vous atteindrez toujours le centre de données le plus proche. Anycast nous aide par ailleurs à répartir le trafic DoS. Lors des attaques, chacun des emplacements reçoit une petite fraction du trafic total, ce qui facilite l'ingestion et le filtrage du trafic indésirable.
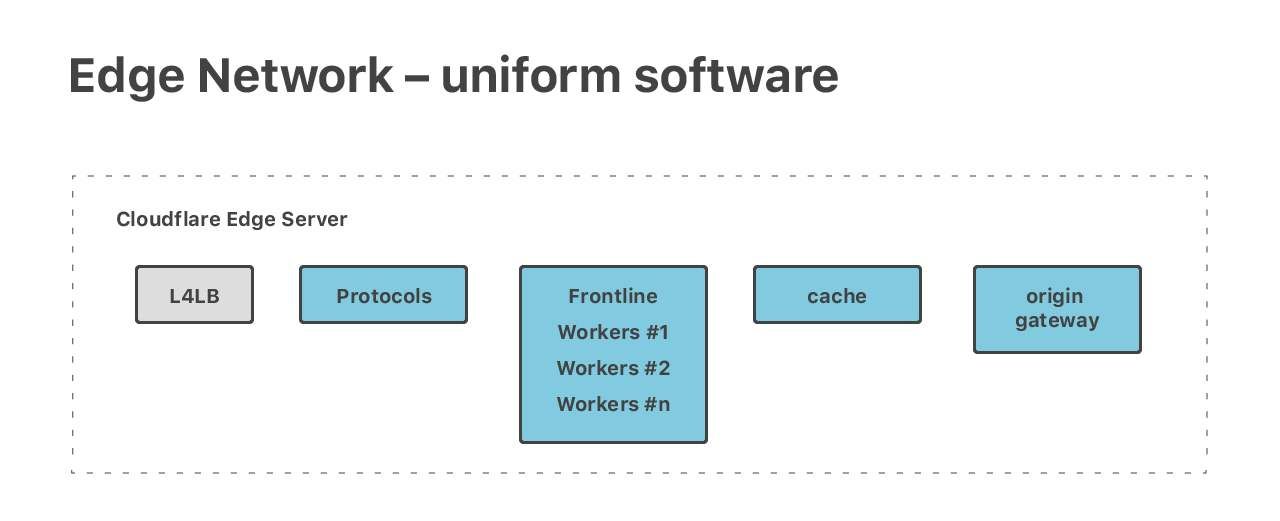
Anycast nous permet de maintenir la même configuration de mise en réseau dans tous les centres de données périphériques. Nous avons appliqué la même conception dans nos centres de données. Notre pile de logiciels est uniforme sur tous les serveurs périphériques. Tous les logiciels sont exécutés sur tous les serveurs.
En principe, chaque machine peut gérer toutes les tâches, et nous exécutons de nombreuses tâches diverses et exigeantes. Nous avons une pile HTTP complète, des Cloudflare Workers magiques, deux ensembles de serveurs DNS (faisant autorité et résolveur), ainsi que de nombreuses autres applications publiques, telles que Spectrum et Warp.
Même si tous les logiciels sont exécutés sur tous les serveurs, les requêtes traversent généralement de nombreuses machines dans leur déplacement vers la pile. Par exemple, une requête HTTP peut être gérée par une machine différente au cours de chacune des 5 étapes du traitement.
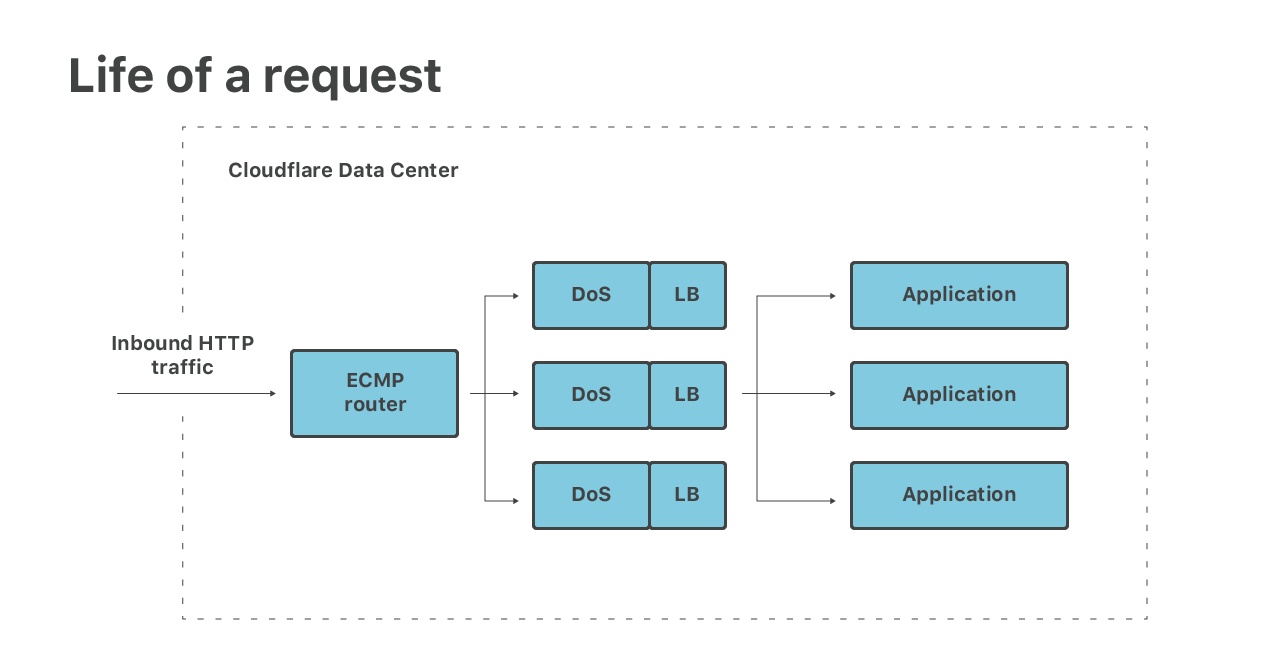
Laissez-moi vous expliquer les premières étapes du traitement des paquets entrants :
(1) Premièrement, les paquets atteignent notre routeur. Le routeur effectue l’ECMP et transmet les paquets sur nos serveurs Linux. Nous utilisons l’ECMP pour répartir chaque IP cible sur de nombreuses machines (au moins 16). Ceci est utilisé comme une technique d'équilibrage de charge rudimentaire.
(2) Sur les serveurs, nous ingérons des paquets avec XDP/eBPF. Dans XDP, nous passons par deux étapes. Tout d'abord, nous effectuons des atténuations DoS volumétriques, en éliminant les paquets appartenant à de très grandes attaques de couche 3.
(3) Ensuite, toujours dans XDP, nous effectuons un équilibrage de charge de couche 4. Tous les paquets non impliqués dans les attaques sont redirigés sur les machines. Ceci est utilisé pour contourner les problèmes ECMP, nous donne un équilibrage de charge à granularité fine et nous permet de mettre gracieusement les serveurs hors service.
(4) Après la redirection, les paquets atteignent une machine désignée. À ce stade, ils sont ingérés par la pile de réseau Linux normale, passent par le pare-feu iptables habituel et sont envoyés à un socket réseau approprié.
(5) Enfin, les paquets sont reçus par une application. Par exemple, les connexions HTTP sont gérées par un serveur de « protocole », chargé d'effectuer le cryptage TLS et de traiter les protocoles HTTP, HTTP/2 et QUIC.
C'est au cours de ces premières phases du traitement des requêtes que nous utilisons les nouvelles fonctionnalités les plus intéressantes de Linux. Nous pouvons regrouper les fonctionnalités modernes utiles en trois catégories :
- Traitement DoS
- L'équilibrage de charge
- Répartition de socket
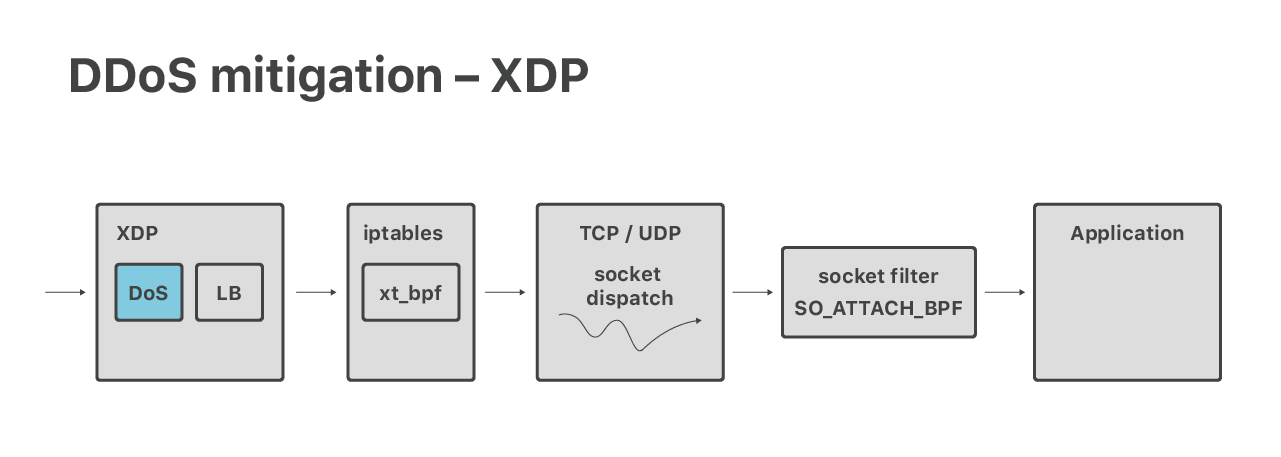
Discutons du traitement DoS plus en détail. Comme mentionné précédemment, la première étape après le routage ECMP est la pile XDP de Linux où, entre autres, nous exécutons des mesures d'atténuation de DoS.
Historiquement, nos mesures d'atténuation des attaques volumétriques étaient exprimées dans la grammaire classique de BPF et de style iptables. Récemment, nous les avons adaptés pour qu'ils s'exécutent dans le contexte XDP/eBPF, ce qui s'est avéré étonnamment difficile. Lisez la suite de nos aventures :
- L4Drop : Atténuations XDP DDoS
- xdpcap : Capture de paquets XDP
- Discours sur l'atténuation DoS basée sur XDP par Arthur Fabre
- XDP en pratique : intégration de XDP dans notre pipeline d’atténuation des attaques DDoS (PDF)
Au cours de ce projet, nous avons rencontré un certain nombre de limitations eBPF/XDP. L'une d'elles était le manque de primitives de concurrence. Il était très difficile de mettre en œuvre des choses comme des « seaux à jetons sans course ». Plus tard, nous avons découvert que Julia Kartseva, ingénieure chez Facebook, avait les mêmes problèmes. En février, ce problème a été résolu avec l'introduction de l’assistant bpf_spin_lock.
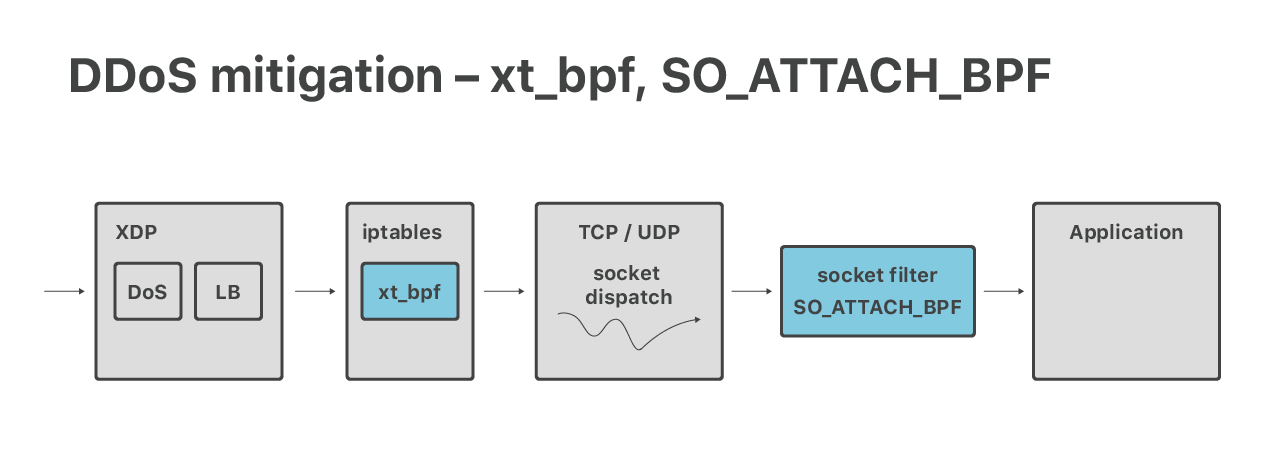
Bien que nos défenses DoS volumétriques modernes soient réalisées dans la couche XDP, nous dépendons toujours d’iptables pour les atténuations de la couche d'application 7. Ici, les fonctionnalités d’un pare-feu de niveau supérieur sont utiles : connlimit, hashlimits et ipsets. Nous utilisons également le module xt_bpf iptables pour exécuter cBPF dans iptables, afin de faire correspondre les charges utiles des paquets. Nous en avons parlé par le passé :
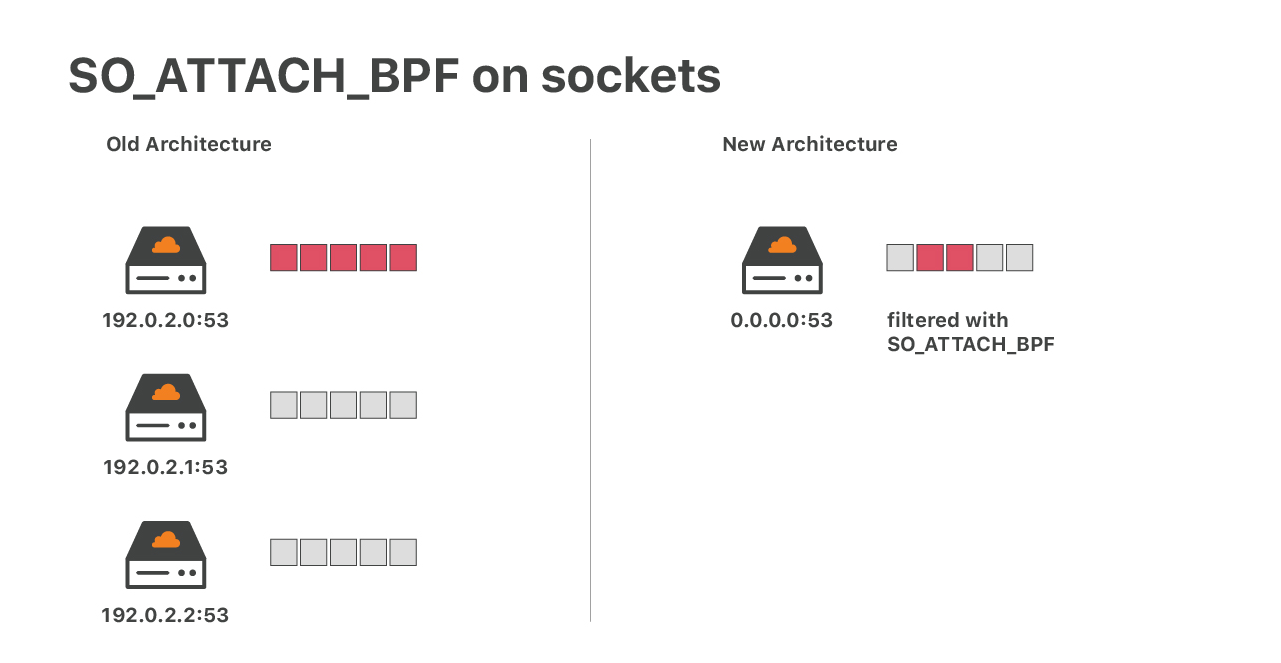
Après XDP et iptables, nous avons une dernière couche de défense DoS côté noyau.
Prenons un cas où nos mesures d'atténuation UDP échouent. Dans un tel cas, nous pourrions nous retrouver avec un flux de paquets frappant notre socket UDP d'application. Cela pourrait provoquer un débordement du socket, entraînant une perte de paquets. Ceci est problématique. Les bons et les mauvais paquets seraient supprimés sans distinction. Pour des applications comme DNS, cela est catastrophique. Dans le passé, pour réduire les dommages, nous utilisions un socket UDP par adresse IP. Une inondation non atténuée était néfaste, mais, au moins, elle n’affectait pas le trafic vers les autres adresses IP du serveur.
De nos jours, l'architecture n'est plus adaptée. Nous exploitons plus de 30 000 adresses IP DNS et l’exécution de ce nombre de sockets UDP n'est pas optimal. Notre solution moderne consiste à exécuter un seul socket UDP ayant un filtre de socket eBPF complexe, à l'aide de l'option de socket SO_ATTACH_BPF. Nous avons parlé d’exécuter eBPF sur des sockets réseau dans des articles de blog précédents :
- eBPF, sockets, distance de saut et assemblage eBPF de l’écriture manuelle
- SOCKMAP - Épissure TCP de l'avenir
Le taux eBPF mentionné limite les paquets. Il conserve l'état et le nombre de paquets dans une carte eBPF. Nous pouvons être certains qu'une seule adresse IP inondée n'affectera pas le reste du trafic. Cela fonctionne bien mais, lors du travail sur ce projet, nous avons trouvé un bogue plutôt inquiétant dans le vérificateur eBPF :
J'imagine qu'exécuter eBPF sur un socket UDP n'est pas chose commune.
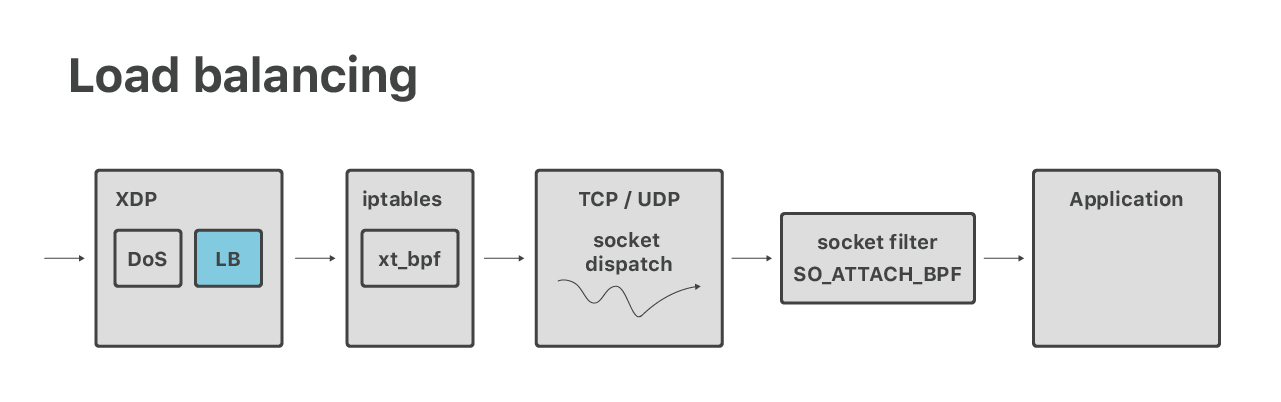
Outre le DoS, dans XDP, nous exécutons également une couche d'équilibrage de charge de couche 4. C'est un nouveau projet et nous n'en avons pas encore beaucoup parlé. Sans entrer dans les détails, dans certains cas, nous devons effectuer une recherche de socket à partir de XDP.
Le problème est relativement simple, notre code doit rechercher dans la structure du noyau « socket » un 5-tuple extrait d'un paquet. Ceci est généralement facile, un assistant bpf_sk_lookup est disponible à cet effet. Sans surprise, il y a eu quelques complications. L'impossibilité de vérifier si un paquet ACK reçu était un élément valide d'un établissement de liaison à trois voies lorsque les cookies SYN sont activés constituait un des problèmes. Mon collègue Lorenz Bauer travaille sur l'ajout d'un support pour ce cas.
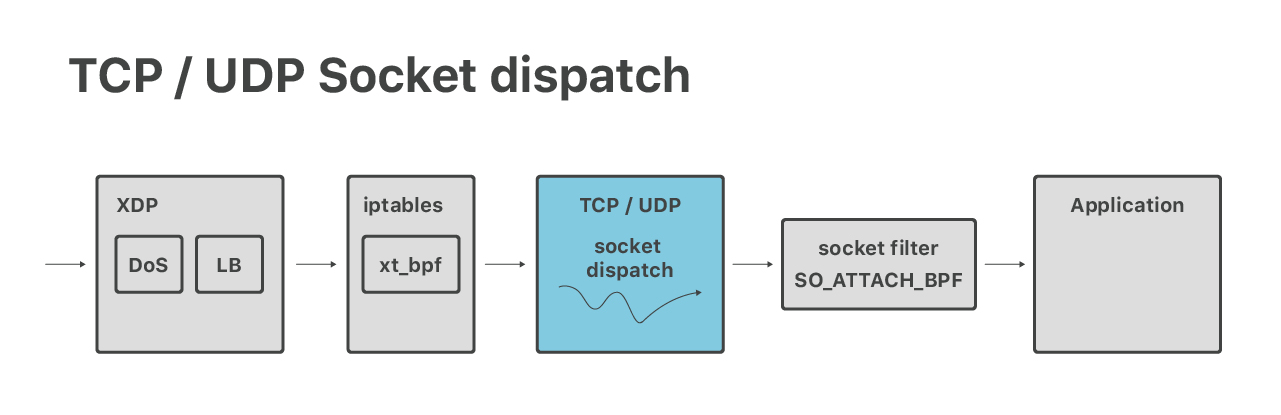
Après DoS et les couches d'équilibrage de charge, les paquets sont transmis à la pile Linux TCP/UDP habituelle. Nous faisons ici une répartition du socket. Par exemple, les paquets allant au port 53 sont transmis à un socket appartenant à notre serveur DNS.
Nous faisons de notre mieux pour utiliser les fonctionnalités de Linux vanilla, mais la situation devient complexe lorsque vous utilisez des milliers d'adresses IP sur les serveurs.
Il est relativement facile de convaincre Linux de router les paquets correctement avec l’astuce « AnyIP ». S'assurer que les paquets sont envoyés à la bonne application est un autre problème. Malheureusement, la logique de répartition des sockets Linux standard n’est pas suffisamment flexible pour répondre à nos attentes. Pour les ports populaires, tels que TCP/80, nous souhaitons partager le port entre plusieurs applications, chacune le gérant sur une plage d'adresses IP différente. Linux ne prend pas cela en charge dans d’autres contextes. Vous pouvez appeler bind () soit sur une adresse IP spécifique, soit sur toutes les adresses IP (avec 0.0.0.0).
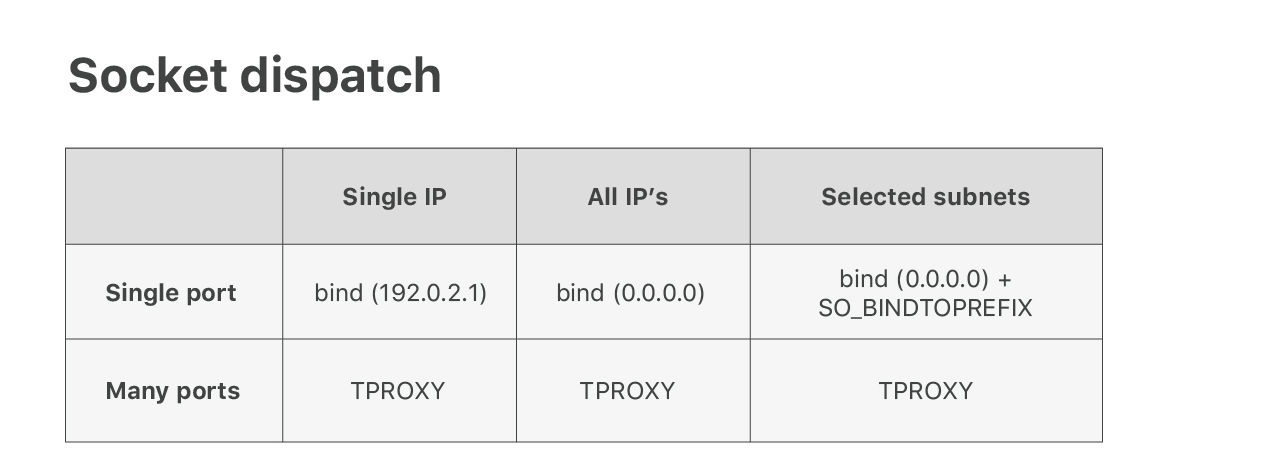
Afin de résoudre ce problème, nous avons développé un correctif de noyau personnalisé qui ajoute uneoption de socketSO_BINDTOPREFIX. Comme son nom l'indique, cela nous permet d'appeler bind () sur un préfixe IP sélectionné. Cela résout le problème de plusieurs applications partageant des ports populaires tels que 53 ou 80.
Ensuite, nous rencontrons un autre problème. Pour notre produit Spectrum, nous devons écouter sur tous les 65 535 ports. Utiliser autant de sockets d’écoute n’est pas une bonne idée (voir notre vieux blog d’histoire de guerre), nous avons donc dû trouver une autre astuce. Après quelques expériences, nous avons appris à utiliser un module inconnu iptables TPROXY à cet effet. Lisez à ce sujet ici :
Cette configuration fonctionne mais nous n'aimons pas les règles de pare-feu supplémentaires. Nous travaillons à résoudre ce problème correctement, en étendant réellement la logique de répartition des sockets. Vous l'avez deviné, nous voulons étendre la logique de répartition des sockets en utilisant eBPF. Attendez-vous à quelques correctifs de notre part.
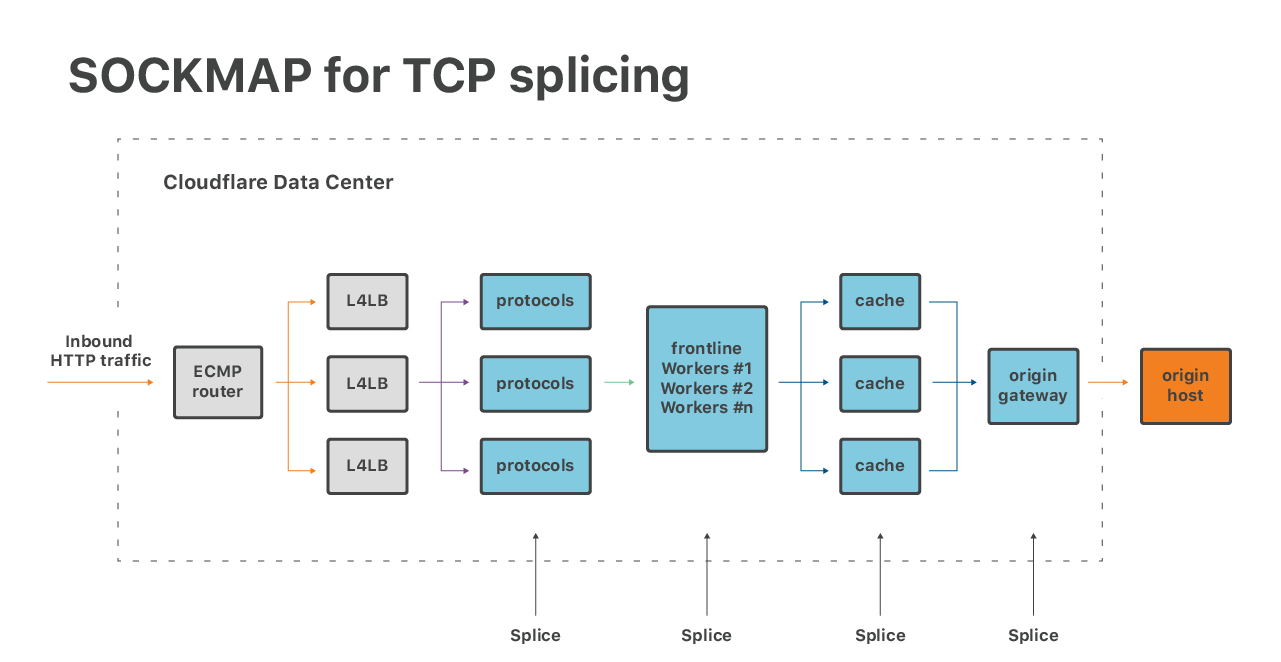
Ensuite, il existe un moyen d'utiliser eBPF pour améliorer les applications. Nous nous sommes récemment montrés enthousiastes à l'idée de faire l'épissure TCP avec SOCKMAP :
Cette technique offre un grand potentiel pour améliorer la latence de la file d’attente sur de nombreux composants de notre pile logicielle. L'implémentation du SOCKMAP actuel n'est pas encore prête pour le moment idéal, mais le potentiel est vaste.
De même, les nouveaux crochets TCP-BPF aka BPF_SOCK_OPSoffrent un excellent moyen d'inspecter les paramètres de performance des flux TCP. Cette fonctionnalité est extrêmement utile pour notre équipe performance.
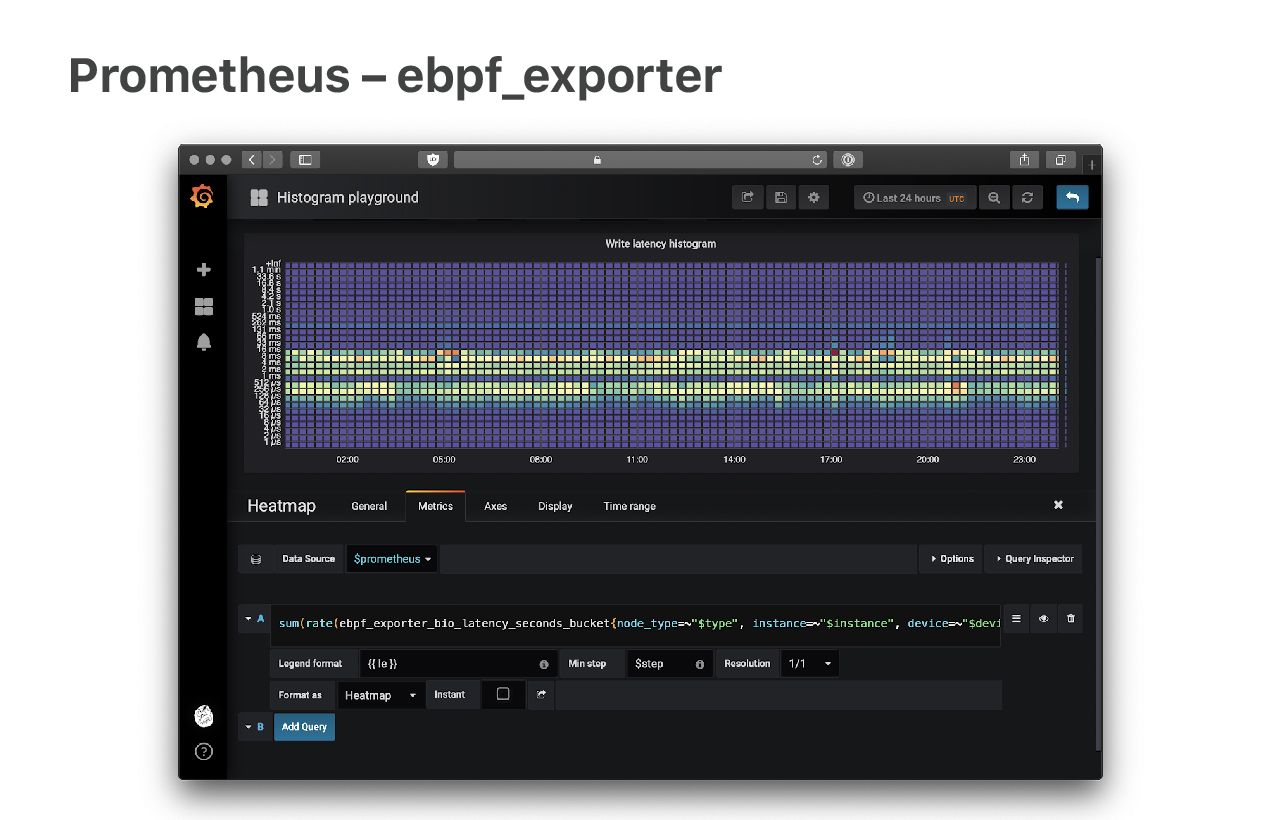
Certaines fonctionnalités de Linux n'ont pas bien vieilli et nous devons les contourner. Par exemple, nous atteignons les limites des métriques de réseau. Ne vous méprenez pas, les métriques de réseau sont impressionnantes. Malheureusement, elles ne sont pas assez granulaires. Des éléments comme TcpExtListenDrops et TcpExtListenOverflows sont signalés en tant que compteurs globaux, alors que nous devons les connaître en fonction des applications.
Notre solution consiste à utiliser des sondes eBPF pour extraire les nombres directement à partir du noyau. Mon collègue Ivan Babrou a mis sur pied un exportateur de métriques Prometheus appelé « ebpf_exporter » pour faciliter ce travail. À lire :
Avec « ebpf_exporter », nous pouvons générer toutes sortes de métriques détaillées. Il est très puissant et nous a sauvés à de nombreuses reprises.
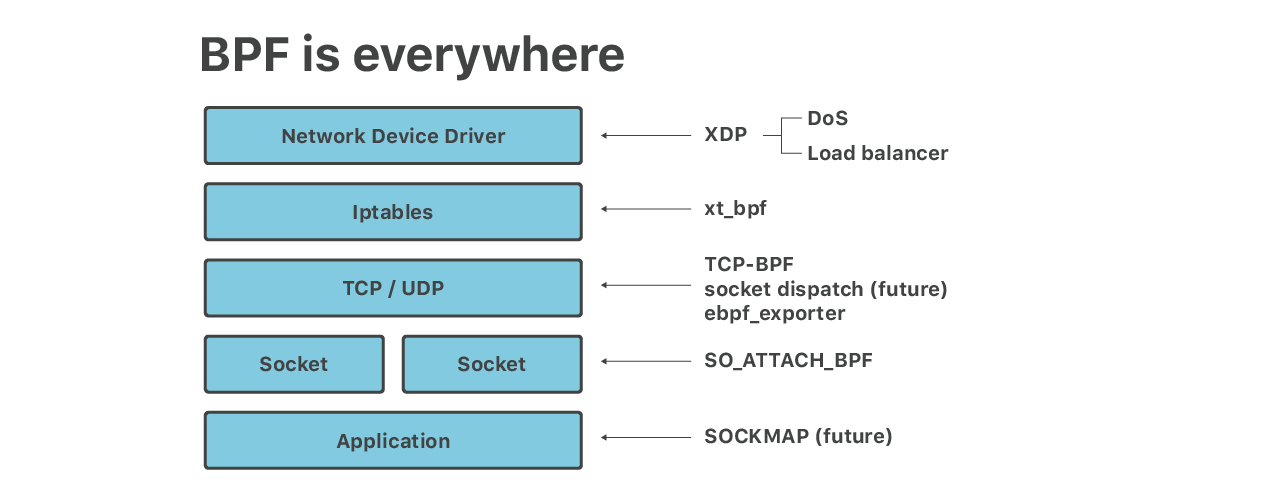
Dans cette présentation, nous avons discuté de 6 couches de fichiers BPF s'exécutant sur nos serveurs périphériques :
- Les atténuations DoS volumétriques s'exécutent sur XDP/eBPF
- Iptables xt_bpf cBPF pour les attaques des couches applicatives
- SO_ATTACH_BPF pour les limites de débit sur les sockets UDP
- Équilibreur de charge, fonctionnant sur XDP
- eBPF exécutant des assistants d'application tels que SOCKMAP pour l'épissure de sockets TCP et TCP-BPF pour les mesures TCP
- « ebpf_exporter » pour les métriques granulaires
Et nous ne faisons que commencer ! Bientôt, nous en ferons plus avec la répartition de socket basée sur eBPF, eBPF fonctionnant sur la couche Linux TC (Traffic Control) et davantage d'intégration avec les points d’encrages cgroup eBPF. Ensuite, notre équipe SRE gère une liste de plus en plus longue de scripts BCCutiles au débogage.
On a l'impression que Linux a cessé de développer de nouvelles API et que toutes les nouvelles fonctionnalités sont implémentées en tant que crochets et assistants eBPF. C'est bien et cela présente de gros avantages. Il est plus facile et plus sûr de mettre à niveau le programme eBPF que de recompiler un module du noyau. Des fonctionnalités comme TCP-BPF, exposant des données de traçage de performance de volume élevé, seraient probablement impossibles à mettre en œuvre sans eBPF.
Certains disent que « les logiciels dévorent le monde », je dirais que : « BPF dévore le logiciel ».