


Le 1er avril 2018, Cloudflare a annoncé le résolveur DNS public 1.1.1.1. Au fil des années, nous avons ajouté à la plateforme la page de débogage pour la résolution d'incidents, une fonction de purge du cache mondial, 0 TTL pour les zones sur Cloudflare, Upstream TLS et 1.1.1.1 for Families. Dans cet article, nous souhaitons partager des informations détaillées sur ce qui se déroule en coulisses et les changements que nous mettons en œuvre.
Au démarrage du projet, nous avons porté notre choix sur le résolveur DNS Knot Resolver. Nous avons commencé à développer un système entier autour de ce résolveur, afin de relever les défis du scénario d'utilisation de Cloudflare. Nous avions la chance remarquable de disposer d'un résolveur DNS récursif testé en conditions réelles, ainsi que d'un validateur DNSSEC ; cela nous permettait de consacrer notre énergie à d'autres tâches, au lieu de nous préoccuper de l'implémentation du protocole DNS.
Knot Resolver est assez flexible, grâce à son système de plugins basé sur Lua. Il nous a permis d'étendre rapidement les fonctionnalités de base afin de prendre en charge différentes caractéristiques du produit, telles que DoH/DoT, la journalisation, l'atténuation des attaques basées sur BPF, le partage du cache et la surcharge de la logique d'itération. Au fur et à mesure de l'augmentation du volume de trafic, nous avons atteint certaines limites.
Les enseignements que nous avons tirés
Avant d'aller plus loin, découvrons d'abord une représentation simplifiée de la topologie d'un datacenter de Cloudflare, qui aidera à comprendre ce dont nous allons parler plus loin dans cet article. Chez Cloudflare, tous les serveurs sont identiques : la pile logicielle sur un serveur est exactement la même que celle d'un autre serveur ; seule la configuration peut être différente. Cette topologie réduit considérablement la complexité de la maintenance du parc.

Le résolveur s'exécute sous la forme d'un processus démon, kresd, et il ne fonctionne pas seul. La charge que représentent les requêtes, en particulier les requêtes DNS, est répartie par Unimog sur les serveurs au sein d'un datacenter. Les requêtes DoH sont terminées par notre terminaison TLS. Les configurations et autres petits objets peuvent être diffusés en quelques secondes dans le monde entier par Quicksilver. Déchargé de cette tâche, le résolveur peut se concentrer sur son objectif : résoudre les requêtes DNS, sans se préoccuper des détails du protocole de transport. Parlons maintenant de trois domaines essentiels que nous souhaitons améliorer : le blocage des E/S dans les plugins, l'utilisation plus efficace de l'espace de cache et l'isolement des plugins.
Fonctions de rappel bloquant la boucle d'événements
Knot Resolver dispose d'un système de plugins très flexible, qui permet d'étendre ses fonctionnalités de base. Les plugins sont appelés des « modules » et sont basés sur des fonctions de rappel (« callbacks »). À certaines étapes du traitement de la requête, ces fonctions de rappel seront invoquées avec le contexte de la requête en cours. Ce fonctionnement permet à un module d'inspecter, de modifier et même de produire des requêtes et des réponses. Ces fonctions de rappel sont intentionnellement simples, afin d'éviter le blocage de la boucle d'événements sous-jacente. Cet aspect est important, car le service repose sur un thread unique et la boucle d'événements doit répondre à de nombreuses requêtes à la fois. Par conséquent, si même une seule requête est bloquée lors d'une fonction de rappel, aucune autre requête concurrente ne peut être traitée tant que la fonction de rappel n'est pas terminée.
Cette configuration nous convenait parfaitement jusqu'à ce que nous ayons besoin d'effectuer des opérations de blocage, par exemple, pour extraire des données de Quicksilver avant de répondre au client.
Efficacité du cache
Puisque les requêtes relatives à un domaine peuvent être transmises à n'importe quel nœud situé dans un datacenter, il serait improductif de résoudre une requête de manière répétée alors qu'un autre nœud a déjà la réponse. Par intuition, la latence pourrait être améliorée si le cache pouvait être partagé entre les serveurs ; nous avons donc créé un module de cache permettant de multi-diffuser les entrées de cache nouvellement ajoutées. Les nœuds situés dans le même datacenter pourraient alors s'abonner aux événements et mettre à jour leur cache local.
L'implémentation du cache par défaut dans Knot Resolver est LMDB. Cette implémentation se montre rapide et fiable pour les déploiements de petite et moyenne taille ; dans notre cas, toutefois, l'éviction depuis le cache est rapidement devenue un problème. Le cache lui-même ne tient pas compte du TTL, de la popularité, etc., et lorsqu'il est saturé, il efface toutes les entrées et recommence. Des scénarios tels que l'énumération de zones peuvent remplir le cache de données qui ne seront probablement pas récupérées ultérieurement.
En outre, notre module de cache multidiffusion n'a fait qu'aggraver la situation en amplifiant le volume de données moins utiles transmises à tous les nœuds, entraînant un taux d'occupation très élevé du cache. Nous avons ensuite constaté un pic de latence, car tous les nœuds effaçaient le cache et repartaient de zéro à peu près en même temps.
Isolement du module
À mesure que la liste des modules Lua s'agrandissait, le débogage des problèmes est devenu de plus en plus difficile. En effet, un état Lua unique est partagé parmi l'ensemble des modules ; par conséquent, toute défaillance d'un module peut en affecter un autre. À titre d'exemple, lorsqu'un incident affectait un état Lua (un trop grand nombre de coroutines ou un manque de mémoire, par exemple), nous nous estimions chanceux si le programme cessait simplement de fonctionner ; cependant, les traces d'appels résultantes étaient difficiles à lire. Il est également difficile de forcer la désinstallation ou la mise à niveau d'un module en cours d'exécution, car celui-ci possède un état non seulement dans le runtime Lua, mais également dans la bibliothèque FFI (Foreign Function Interface) ; par conséquent, la sécurité de la mémoire n'est pas garantie.
BigPineapple entre en scène
Nous n'avons trouvé aucun logiciel existant susceptible de répondre à nos exigences très spécifiques, et avons donc fini par développer une solution nous-mêmes. La première tentative a consisté à intégrer le cœur de Knot Resolver à un service léger, écrit en langage Rust (edgedns modifié).
Cela s'est avéré difficile, en raison de la nécessité d'effectuer des conversions continues entre le stockage et les types C/FFI, ainsi qu'en raison d'autres singularités (par exemple, l'interface ABI permettant la recherche d'enregistrements dans le cache s'attend à ce que les enregistrements fournis soient immuables jusqu'au prochain appel ou jusqu'à la fin de la transaction de lecture). Cependant, nous avons beaucoup appris en essayant de mettre en œuvre cette sorte de fonctionnalité partagée dans laquelle l'hôte (le service) fournit certaines ressources à l'invité (la bibliothèque centrale du résolveur) et en réfléchissant à comment nous pourrions améliorer cette interface.
Dans les itérations ultérieures, nous avons remplacé l'ensemble de la bibliothèque récursive par une nouvelle bibliothèque, basée sur un runtime asynchrone ; nous lui avons également ajouté un système de modules remanié, en réécrivant habilement le service en langage Rust à mesure que nous remplacions un nombre croissant de composants. Ce runtime asynchrone était tokio, qui proposait une élégante interface de gestion des pools de threads permettant d'exécuter des tâches bloquantes et non bloquantes, ainsi qu'un écosystème facilitant l'utilisation d'autres crates (bibliothèques Rust).
Par la suite, à mesure que la gestion des combinateurs de Futures devenait fastidieuse, nous avons commencé à tout convertir en fonctions async/await. C'était avant l'arrivée de la fonctionnalité async/await inaugurée dans Rust 1.39, qui nous a conduits à utiliser nightly (version bêta de Rust) pendant un certain temps, et qui nous a causé quelques difficultés. Lorsque la fonction async/await a été stabilisée, elle nous a permis d'écrire de manière ergonomique notre routine de traitement des requêtes, semblable à Go.
Toutes les tâches peuvent être exécutées simultanément, et certaines tâches sollicitant fortement les E/S peuvent être divisées en fragments plus petits, afin de tirer parti d'un ordonnancement plus granulaire. Puisque le runtime exécute les tâches dans un pool de threads, plutôt que dans un thread unique, il bénéficie également de l'approche work stealing (« vol de travail »). Cette approche permet d'éviter un problème que nous rencontrions auparavant, à savoir que si le traitement d'une requête demandait beaucoup de temps, cela bloquait toutes les autres requêtes dans la boucle d'événements.
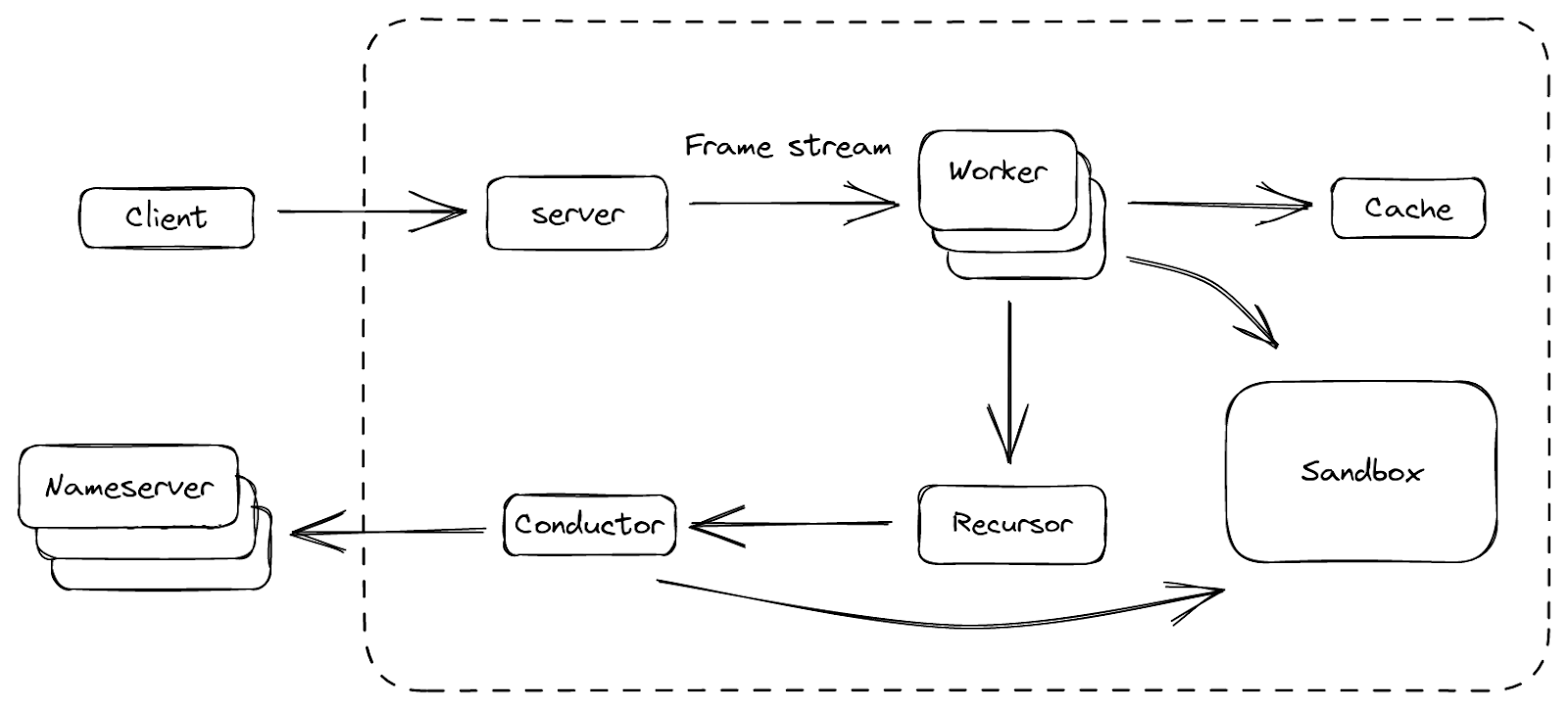
Enfin, nous avons créé une plateforme dont nous sommes satisfaits, que nous avons appelée BigPineapple. La figure ci-dessus présente une vue d'ensemble de ses principaux composants et des flux de données circulant entre eux. Dans BigPineapple, le module serveur reçoit les requêtes entrantes du client, les valide, puis les transforme en flux de trames unifiés pouvant ensuite être traités par le module Workers. Ce dernier dispose d'un ensemble d'instances Workers dont la tâche consiste à déterminer la réponse à la question contenue dans la requête. Chaque instance Workers interagit avec le module de cache, afin de vérifier si la réponse est présente dans le cache et si elle est toujours valide. Dans le cas contraire, il fait appel au module de récursivité afin d'itérer la requête de manière récursive. Le récurseur n'utilise pas les E/S ; lorsqu'il a besoin de quelque chose, il délègue la sous-tâche au module conducteur, qui utilise alors des requêtes sortantes pour obtenir les informations auprès des serveurs de noms en amont. Pendant tout le processus, certains modules peuvent interagir avec le module Sandbox afin d'étendre ses fonctionnalités, en exécutant les plugins qu'il contient.
Examinons maintenant certaines de ces fonctionnalités et la manière dont elles nous ont aidés à surmonter les problèmes que nous rencontrions auparavant.
Architecture d'E/S mise à jour
Un résolveur DNS peut être considéré comme un agent entre un client et plusieurs serveurs de noms de référence : il reçoit les requêtes du client, récupère de manière récursive les données auprès des serveurs de noms en amont, puis compose les réponses et les renvoie au client. Il traite donc du trafic entrant et du trafic sortant, respectivement gérés par le serveur et le conducteur.
Le serveur écoute sur une série d'interfaces utilisant différents protocoles de transport, qui sont ensuite simplifiés sous la forme de flux de trames. Chaque trame est une représentation de haut niveau d'un message DNS, avec quelques métadonnées supplémentaires. Concrètement, il peut s'agir d'un paquet UDP, d'un segment de flux TCP ou du contenu d'une requête HTTP, mais tous sont traités de la même manière. La trame est ensuite convertie en tâche asynchrone, qui est à son tour prise en charge par un ensemble d'instances Workers chargées de résoudre ces tâches. Les tâches terminées sont reconverties en réponses, puis renvoyées au client.
Cette simplification des protocoles et de leurs encodages sous forme de « trames » a, à son tour, permis de simplifier la logique utilisée pour la régulation des sources de trames – par exemple, l'application de l'équité, permettant d'éviter l'épuisement des ressources, et le contrôle de la cadence, permettant d'éviter la saturation du serveur. L'une des choses que nous avons apprises avec les implémentations précédentes est que, pour un service ouvert au public, la performance maximale des E/S importe moins que la capacité de cadencer équitablement les clients. Cela s'explique principalement par le fait que le coût de chaque requête récursive diffère considérablement en termes de temps et de puissance de calcul (par exemple, une mise en cache réussie par rapport à un échec de mise en cache), et qu'il est difficile de le deviner à l'avance. Les échecs de mise de cache du service récursif consomment non seulement les ressources de Cloudflare, mais également les ressources des serveurs de noms de référence interrogés ; nous devons donc tenir compte de ce paramètre.
De l'autre côté du serveur se trouve le conducteur, qui gère toutes les connexions sortantes. Il aide à répondre à certaines questions avant de contacter les serveurs en amont : quel est le serveur de noms le plus rapide auquel établir une connexion, en termes de latence ? Que faire si tous les serveurs de noms ne sont pas joignables ? Quel protocole utiliser pour la connexion, et existe-t-il des approches plus intéressantes ? Le conducteur est capable de prendre ces décisions en surveillant les indicateurs du serveur en amont, tels que le temps de réponse, la qualité de service, etc. Ces connaissances lui permettent également de deviner des éléments tels que la capacité en amont ou la perte de paquets UDP, puis de prendre les mesures nécessaires – par exemple, réessayer, s'il pense que le paquet UDP précédent n'est pas parvenu au serveur en amont.
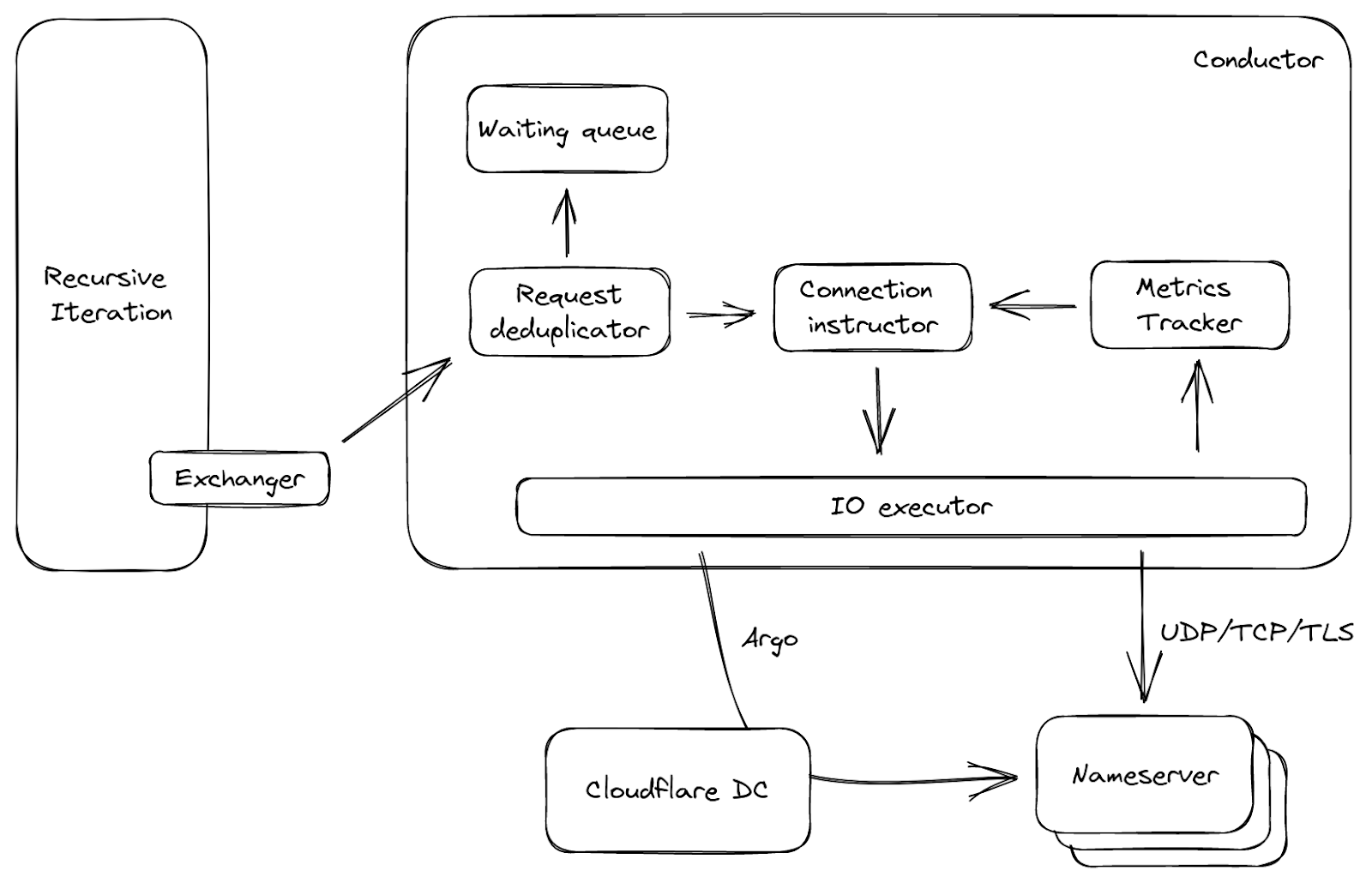
La figure 3 illustre un flux de données simplifié concernant le conducteur. Il est appelé par l'échangeur mentionné ci-dessus, avec un trafic entrant constitué de requêtes en amont. Les requêtes sont d'abord dédupliquées : dans un intervalle réduit, si un grand nombre de requêtes parviennent au conducteur et posent la même question, une seule d'entre elles est autorisée à passer, et les autres sont placées dans une file d'attente. Cette approche est courante lorsqu'une entrée du cache arrive à expiration, et permet de réduire le trafic inutile sur le réseau. Ensuite, en fonction de la requête et des indicateurs des serveurs en amont, l'instructeur de connexion choisit une connexion ouverte, le cas échéant, ou génère un ensemble de paramètres. Avec ces paramètres, l'exécuteur d'E/S est en mesure de se connecter directement au serveur en amont, ou même d'emprunter un itinéraire via un autre datacenter de Cloudflare, grâce à notre technologie de routage intelligent Argo !
Le cache
La mise en cache dans un service récursif est essentielle, car un serveur peut renvoyer une réponse mise en cache en moins d'une milliseconde, tandis que la réponse à un échec de mise en cache demande des centaines de millisecondes. La mémoire étant une ressource limitée (ainsi qu'une ressource partagée dans l'architecture de Cloudflare), une utilisation plus efficace de l'espace pour le cache était l'un des aspects essentiels que nous voulions améliorer. L'implémentation du nouveau cache repose sur une structure de données de remplacement du cache (ARC), à la place d'un référentiel clés-valeurs. Cette approche permet une utilisation efficace de l'espace sur un nœud unique, car les entrées les moins demandées sont progressivement écartées et la structure de données est résistante aux analyses.
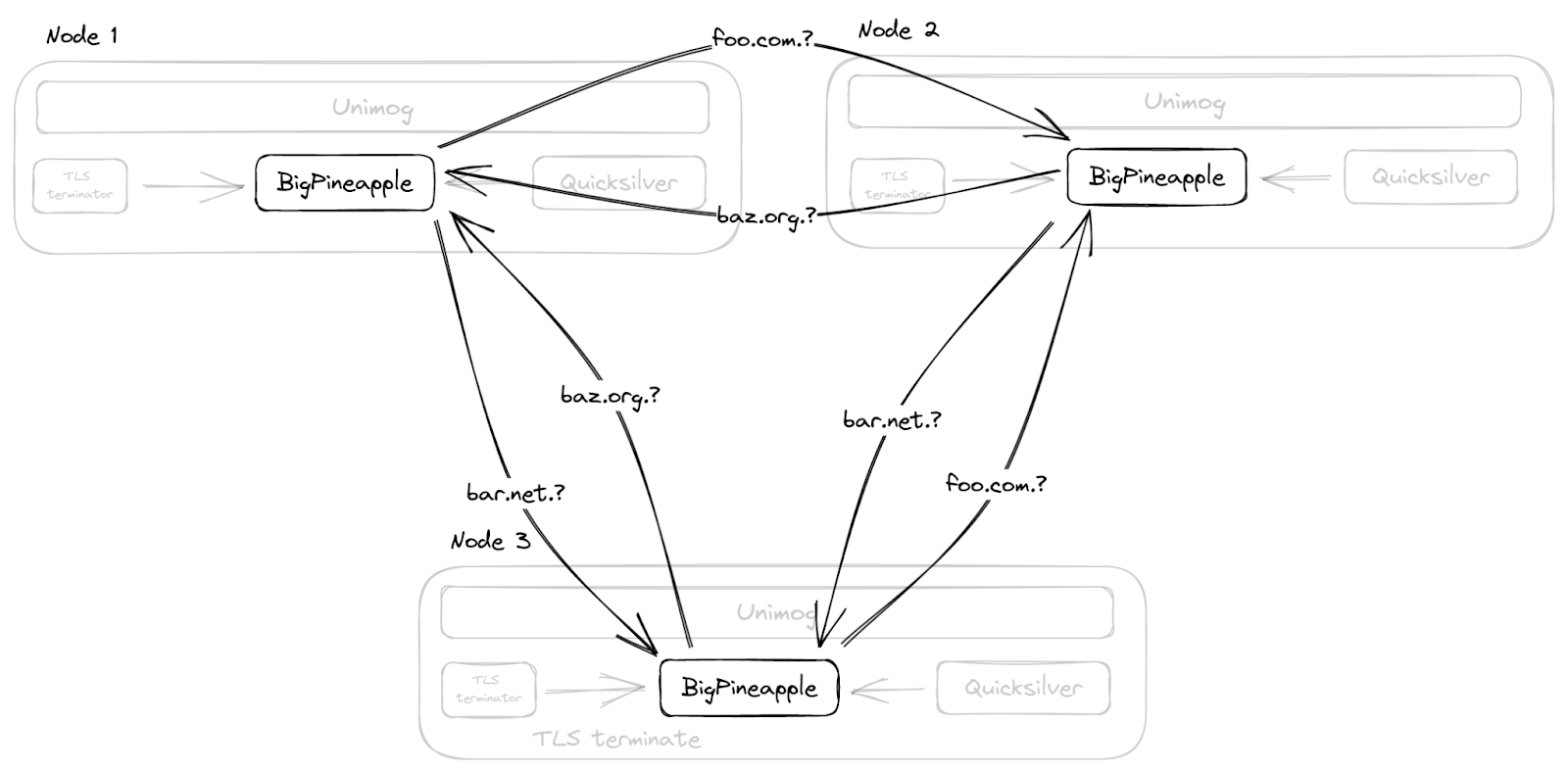
Par ailleurs, au lieu d'utiliser la multi-diffusion pour dupliquer le cache dans l'ensemble du datacenter, comme nous le faisions auparavant, BigPineapple est conscient de ses nœuds d'interconnexion dans le même datacenter et relaie les requêtes d'un nœud à l'autre s'il ne parvient pas à trouver une entrée dans son cache. À cette fin, un hachage cohérent des requêtes est effectué au niveau des nœuds sains dans chaque datacenter. Par exemple, les requêtes correspondant à un même domaine enregistré sont acheminées par le même sous-ensemble de nœuds, ce qui augmente le taux de réussite de mise en cache, mais aide également le cache d'infrastructure, qui stocke des informations concernant les performances et les fonctionnalités des serveurs de noms.
Bibliothèque récursive asynchrone
La bibliothèque récursive est le « cerveau DNS » de BigPineapple, car elle sait comment trouver la réponse à la question contenue dans la requête. En partant de la racine, elle décompose la requête du client en sous-requêtes, puis utilise celles-ci pour collecter des informations de manière récursive auprès de différents serveurs de noms de référence sur Internet. Le produit de ce processus est la réponse. Grâce à async/await, elle peut être simplifiée sous la forme d'une fonction telle que :
async fn resolve(Request, Exchanger) → Result<Response>;
La fonction contient toute la logique nécessaire pour générer une réponse à une demande donnée, mais elle ne traite en elle-même aucune E/S. Au lieu de cela, nous transmettons un trait de l'échangeur (interface Rust) qui sait comment échanger de manière asynchrone des messages DNS avec les serveurs de noms de référence en amont. L'échangeur est généralement appelé à différents points de la fonction await. Par exemple, au début d'une récursion, l'une des premières tâches qu'il exécute consiste à rechercher la délégation mise en cache la plus proche pour le domaine. S'il ne trouve pas la délégation finale dans le cache, il doit demander quels sont les serveurs de noms responsables de ce domaine, puis attendre la réponse avant de poursuivre.
Grâce à cette approche, qui dissocie la partie « attente de réponses » de la logique DNS récursive, il est beaucoup plus facile d'effectuer des tests en fournissant une implémentation fictive de l'échangeur. En outre, le code d'itération récursive (et la logique de validation DNSSEC, en particulier) devient beaucoup plus lisible, car il est écrit de manière séquentielle, au lieu d'être disséminé dans une multitude de fonctions de rappel.
Vous allez rire, mais écrire un résolveur récursif DNS en partant de rien, ça n'a vraiment rien d'amusant !
Cela n'est pas seulement dû à la complexité de la validation DNSSEC, mais également aux « solutions de contournement » devant être mises en œuvre pour les serveurs incompatibles avec différentes RFC, les redirecteurs, les pare-feu, etc. Nous avons donc converti deckard en langage Rust, afin de faciliter les tests. Par ailleurs, lorsque nous avons commencé la migration vers cette nouvelle bibliothèque récursive asynchrone, nous l'avons d'abord exécutée en mode « shadow », c'est-à-dire en traitant des échantillons de requêtes réelles issues du service de production, puis en comparant les différences. Nous avons précédemment adopté cette approche pour le service DNS de référence de Cloudflare. Cela s'avère un peu plus difficile pour un service récursif, car il doit rechercher toutes les données sur l'ensemble de l'Internet ; or, les serveurs de noms de référence fournissent souvent des réponses différentes à une même requête, en raison de la localisation, de l'équilibrage de la charge et d'autres facteurs, ce qui entraîne un grand nombre de faux positifs.
En décembre 2019, nous avons enfin activé le nouveau service sur un point de terminaison de test public (voir notre annonce), afin de résoudre les problèmes restants, avant d'accomplir la lente migration des points de terminaison de production vers le nouveau service. Même après tout cela, nous avons continué à identifier des cas limites avec la récursion DNS (et la validation DNSSEC, en particulier) ; toutefois, la résolution et la reproduction de ces problèmes sont devenues beaucoup plus faciles en raison de la nouvelle architecture de la bibliothèque.
Déploiement de plugins dans une sandbox
Il est important pour nous d'avoir la possibilité d'étendre « à la volée » la fonctionnalité DNS centrale ; c'est pourquoi BigPineapple dispose d'un système de plugins redéfini. Auparavant, les plugins Lua s'exécutaient dans le même espace mémoire que le service lui-même, et ils étaient généralement libres de faire ce qu'ils voulaient. Cette approche est pratique, puisqu'elle nous permet de transmettre librement, avec C/FFI, des références entre le service et les modules (par exemple, pour lire une réponse directement depuis le cache, sans devoir d'abord la copier dans un buffer). Toutefois, elle est également dangereuse. En effet, le module peut lire dans une mémoire non initialisée, appeler une interface ABI hôte avec une signature de fonction incorrecte, créer un blocage sur un socket local ou avoir d'autres comportements indésirables. Par ailleurs, le service ne dispose d'aucun moyen de limiter ces comportements.
Nous avons donc envisagé de remplacer le runtime Lua intégré par JavaScript ou des modules natifs, mais à peu près au même moment, des runtimes intégrés pour WebAssembly (Wasm, en abrégé) ont fait leur apparition. Les programmes WebAssembly possèdent deux propriétés intéressantes, à savoir qu'ils peuvent être écrits dans le même langage que le reste du service et qu'ils s'exécutent dans un espace mémoire isolé. Nous avons donc commencé à modéliser l'interface hôte/invité en fonction des limites des modules WebAssembly, afin d'évaluer l'efficacité de cette approche.
Le runtime Wasm de BigPineapple repose actuellement sur Wasmer. Au fil du temps, nous avons essayé plusieurs runtimes (comme Wasmtime ou WAVM, au début), et nous avons conclu que Wasmer était plus simple d'utilisation, dans notre cas. Le runtime permet l'exécution de chaque module dans sa propre instance, avec une mémoire isolée et un piège à signaux, ce qui résout naturellement le problème d'isolement des modules que nous avons décrits plus haut. En outre, nous pouvons exécuter simultanément plusieurs instances d'un même module. Puisqu'elles sont contrôlées avec précision, les applications peuvent être échangées à chaud entre deux instances, sans omettre une seule requête ! C'est une excellente chose, car les applications peuvent être mises à niveau « à la volée », sans redémarrage du serveur. Étant donné que les programmes Wasm sont distribués via Quicksilver, les fonctionnalités de BigPineapple peuvent être modifiées en toute sécurité dans le monde entier, en quelques secondes seulement !
Pour mieux comprendre la sandbox de WebAssembly, commençons d'abord par présenter quelques termes :
- Hôte : le programme qui exécute le runtime Wasm. De manière semblable à un kernel, il exerce, par le biais du runtime, un contrôle total sur les applications invité.
- Application invité : le programme Wasm dans la sandbox. Dans un environnement restreint, l'application peut uniquement accéder à l'espace mémoire qui lui est fourni par le runtime et exécuter les appels hôte importés. Nous l'appelons application ou « app ».
- Appel hôte : fonctions définies dans l'hôte, pouvant être importées par l'invité. Comparables à des appels système, les appels hôte constituent l'unique moyen pour les applications invité d'accéder aux ressources situées hors de la sandbox.
- Runtime invité : une bibliothèque permettant aux applications invité d'interagir facilement avec l'hôte. Il met en œuvre des interfaces communes, permettant ainsi qu'une application utilise simplement les fonctionnalités async, socket, log et tracing sans connaître les détails sous-jacents.
Le moment est maintenant venu de nous plonger dans la sandbox, alors, restez à l'écoute. Commençons par le côté invité, et examinons à quoi ressemble la durée de vie d'une application courante. Le runtime invité permet d'écrire les applications invité de la même manière que les programmes ordinaires. Ainsi, à l'instar d'autres exécutables, une application commence par une fonction de démarrage en tant que point d'entrée, qui est invoquée par l'hôte lors du chargement. Elle reçoit également des arguments de la ligne de commande. À ce stade, l'instance exécute normalement des procédures d'initialisation et, surtout, enregistre des fonctions de rappel pour les différentes phases de la requête. En effet, dans un résolveur récursif, une requête doit transiter par plusieurs phases avant de réunir suffisamment d'informations pour produire une réponse (par exemple, une recherche dans le cache ou l'exécution de sous-requêtes afin de résoudre une chaîne de délégation pour le domaine). L'interconnexion de ces phases est donc nécessaire pour que les applications soient utiles dans différents scénarios d'utilisation. La fonction de démarrage peut également exécuter des tâches en arrière-plan, afin de compléter les rappels de phase et stocker l'état global ; par exemple, elle peut produire des rapports concernant des indicateurs ou prélever des données partagées depuis des sources externes, etc. – encore une fois, de la même manière que nous écrivons un programme « normal ».
Mais d'où proviennent les arguments du programme ? Comment une application invité peut-elle envoyer des journaux et des indicateurs ? Par le biais de fonctions externes.
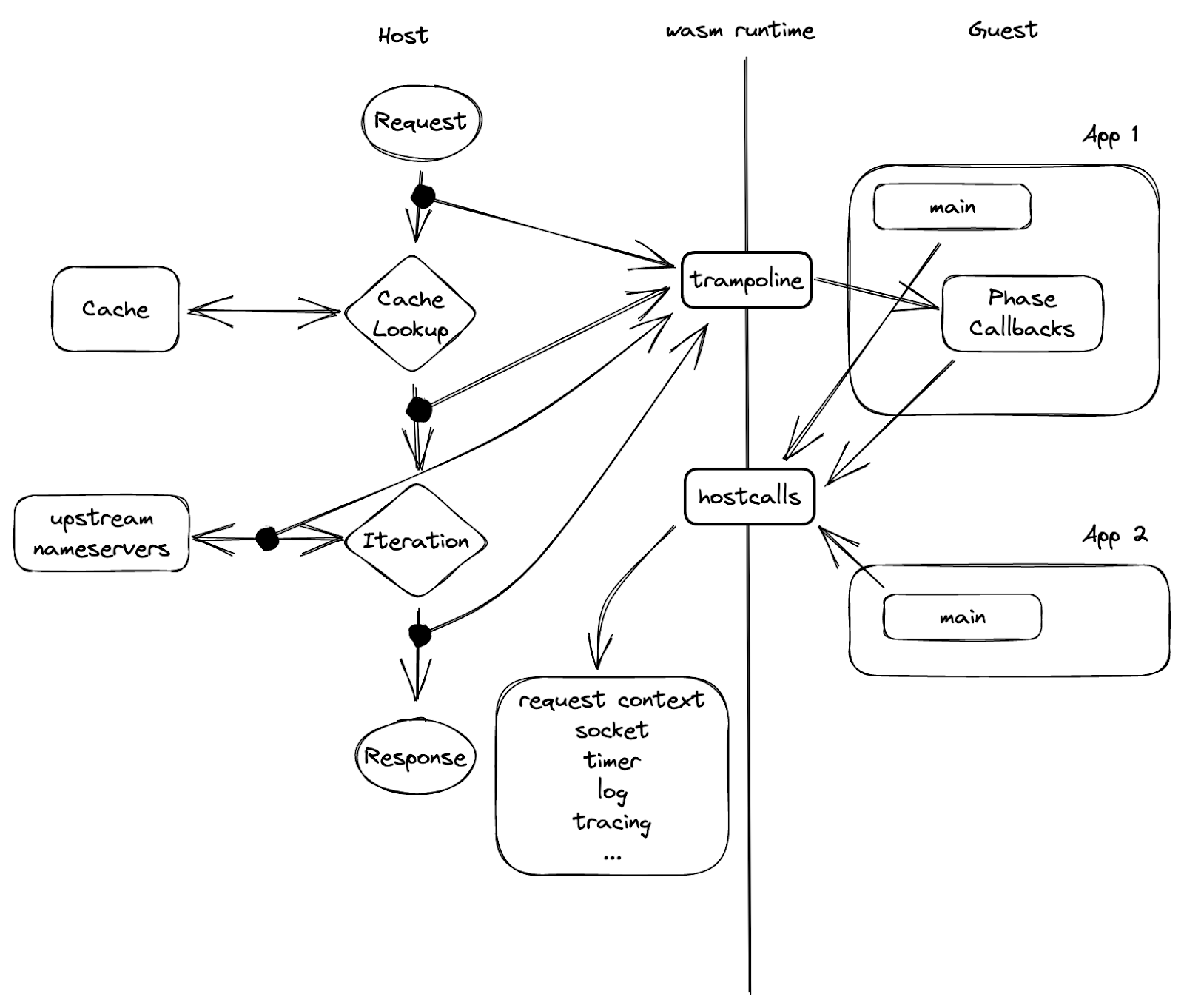
Au milieu de la Figure 5 apparaît une barrière, qui représente la limite de la sandbox et sépare l'invité de l'hôte. Le seul moyen pour un côté de communiquer avec l'autre est d'utiliser un ensemble de fonctions préalablement exportées par l'homologue. Comme l'illustre la figure, les « appels hôte » sont exportés par l'hôte, importés, puis invoqués par l'invité, tandis que le « trampoline » représente des fonctions invité dont l'hôte a connaissance.
Nous appelons cette fonction « trampoline » parce qu'elle est utilisée pour invoquer une fonction ou une fermeture dans une instance invité qui n'est pas exportée. Les rappels de phase sont un exemple de la raison pour laquelle nous avons besoin d'une fonction « trampoline » : chaque rappel renvoie une fermeture et ne peut donc pas être exporté lors de l'instanciation. Ainsi, si une application invité veut enregistrer un rappel, elle invoque un appel hôte avec l'adresse de rappel « hostcall_register_callback(pre_cache, #30987) ». Lorsque le rappel doit être invoqué, l'hôte ne peut pas simplement appeler ce pointeur, car il renvoie vers l'espace mémoire de l'invité. Ce qu'il peut faire à la place, c'est utiliser l'un des « trampolines » évoqués ci-dessus et lui fournir l'adresse de fermeture de la fonction de rappel : « trampoline_call(#30987) ».
Surcharge de données liée à l'isolement
Toutefois, il y a un revers à la médaille : la nouvelle sandbox entraîne une surcharge de données. La portabilité et l'isolement qu'offre WebAssembly ont un coût. Ici, nous allons présenter deux exemples.
Premièrement, les applications invité ne sont pas autorisées à lire la mémoire de l'hôte. Le principe de fonctionnement est le suivant : l'invité fournit une région de mémoire via un appel hôte, puis l'hôte écrit les données dans l'espace mémoire de l'invité. Cela produit une copie en mémoire, qui ne serait pas nécessaire si l'exécution se déroulait hors de la sandbox. La mauvaise nouvelle est que, dans notre scénario d'utilisation, les applications invité sont censées réagir à la requête et/ou la réponse ; elles ont donc presque toujours besoin de lire les données de l'hôte à chaque requête. La bonne nouvelle, en revanche, est que pendant le cycle de vie d'une requête, les données ne sont pas modifiées. Nous pré-allouons donc une grande quantité de mémoire dans l'espace mémoire de l'invité juste après l'instanciation de l'application de l'invité. La mémoire allouée n'est pas utilisée, mais sert plutôt à occuper un vide dans l'espace d'adressage. Une fois que l'hôte a obtenu les détails de l'adresse, il associe une région de mémoire partagée aux données communes requises par l'invité dans l'espace mémoire de l'invité. Lorsque le code invité commence à s'exécuter, il peut simplement accéder aux données d'indirection de la mémoire partagée ; aucune copie n'est nécessaire.
Nous nous sommes heurtés à un autre problème lorsque nous avons voulu ajouter à BigPineapple la prise en charge d'oDoH3, un protocole moderne dont la principale fonction est de déchiffrer la requête du client, de la résoudre, puis de chiffrer les réponses avant de les renvoyer. Cette fonctionnalité ne relève pas intrinsèquement des fonctionnalités DNS centrales, et devrait plutôt être étendue avec une application Wasm. Cependant, le jeu d'instructions de WebAssembly ne fournit pas certaines primitives cryptographiques, telles que AES et SHA-2, ce qui l'empêche de tirer parti des fonctionnalités du matériel hôte. Des travaux sont actuellement en cours afin d'intégrer cette fonctionnalité à Wasm avec WASI-crypto. En attendant, notre solution consiste simplement à déléguer le chiffrement hybride à clé publique à l'hôte via des appels hôte, et nous avons déjà constaté des performances 4 fois supérieures à ce que nous obtenions en exécutant cette tâche dans Wasm.
Fonction async dans Wasm
Vous vous souvenez du problème dont nous avons parlé précédemment, à savoir que les rappels pouvaient bloquer la boucle d'événements ? Le problème consiste fondamentalement à déterminer comment exécuter le code de manière asynchrone dans la sandbox. En effet, quelle que soit la complexité du rappel de traitement de la requête, si l'invocation du rappel peut être interrompue, nous pouvons définir une limite supérieure à la durée du blocage qu'elle provoque. Heureusement, l'architecture asynchrone de Rust est à la fois élégante et légère. Elle nous offre la possibilité d'utiliser un ensemble d'appels invité pour mettre en œuvre les « Future ».
En langage Rust, un Future est un module de construction de calculs asynchrones. Du point de vue de l'utilisateur, la création d'un programme asynchrone exige de s'acquitter de deux tâches : l'implémentation d'une fonction interrogeable, qui pilote la transition d'état, et le placement d'une fonction waker en tant que rappel afin de réveiller le programme lorsque la fonction interrogeable doit à nouveau être appelée en raison d'un événement externe (par exemple, le temps est passé, le socket est devenu lisible, etc.). La première de ces tâches permet l'exécution progressive du programme, par exemple, la lecture des données des E/S dans le buffer, puis le renvoi d'un nouvel état indiquant l'état de la tâche : terminée ou exécution interrompue. La deuxième tâche est utile en cas d'interruption de l'exécution d'une tâche, puisqu'elle déclenche l'interrogation du Future lorsque les conditions attendues par la tâche sont remplies, au lieu de configurer une boucle avec l'état occupé jusqu'à ce qu'elle soit terminée.
Examinons comment cette approche est mise en œuvre dans notre sandbox. Le traitement des E/S par l'invité doit se dérouler par le biais d'appels hôte, car l'invité se trouve dans un environnement restreint. En supposant que l'hôte fournisse un ensemble d'appels hôte simplifiés qui reflètent les opérations des sockets de base (ouvrir, lire, écrire et fermer), la pseudo-fonction d'interrogation de l'invité peut être définie comme suit :
fn poll(&mut self, wake: fn()) -> Poll {
match hostcall_socket_read(self.sock, self.buffer) {
HostOk => Poll::Ready,
HostEof => Poll::Pending,
}
}
Ici, l'appel hôte lit les données d'un socket et les écrit dans un buffer. En fonction de sa valeur de retour, la fonction peut se placer dans l'un des états mentionnés ci-dessus : terminé (Ready) ou exécution interrompue (Pending). La magie opère à l'intérieur de l'appel hôte. Vous souvenez-vous que sur la figure 5, il s'agit de la seule façon d'accéder aux ressources ? L'application invité ne possède pas le socket, mais elle peut acquérir un « handle » via la commande « hostcall_socket_open », qui crée à son tour un socket du côté hôte et renvoie un handle. Le handle peut renvoyer à n'importe quel objet, en théorie ; en pratique, toutefois, l'utilisation de handles de socket entier est bien adaptée aux descripteurs de fichiers du côté hôte ou aux indices dans un vecteur ou un slab. En référençant le handle renvoyé, l'application invité peut contrôler le socket réel à distance. Puisque le côté hôte est entièrement asynchrone, il peut simplement relayer l'état du socket à l'invité. Si vous avez remarqué que la fonction waker n'est pas utilisée ci-dessus, bravo ! C'est parce que lorsque l'appel hôte est exécuté, il commence à ouvrir un socket, mais il enregistre aussi la fonction waker actuelle afin qu'elle soit appelée lors de l'ouverture du socket (ou en l'absence d'ouverture du socket). Ainsi, lorsque le socket est prêt, la tâche hôte est réveillée ; elle trouve la tâche invité correspondante dans son contexte et la réveille avec la fonction trampoline, comme illustré sur la figure 5. Il existe d'autres cas dans lesquels une tâche invité doit attendre une autre tâche invité (une fonction async mutex, par exemple). Le mécanisme est ici similaire : il s'agit d'utiliser des appels hôte pour inscrire les fonctions waker.
Toutes ces fonctions compliquées sont encapsulées dans notre runtime asynchrone invité, avec une API simple d'utilisation, permettant aux applications invité d'accéder aux fonctions async normales sans se préoccuper des détails sous-jacents.
(Pas) La fin
Nous espérons que cet article de blog vous aura permis de vous faire une idée générale de la plateforme innovante sur laquelle repose 1.1.1.1. Elle évolue continuellement et aujourd'hui, plusieurs de nos produits, tels que 1.1.1.1 for Families, AS112 et Gateway DNS sont pris en charge par des applications invité exécutées sur BigPineapple. Nous sommes impatients d'y intégrer de nouvelles technologies. Si vous avez des idées, n'hésitez pas à nous en faire part dans la communauté ou par e-mail.