


Am 1. April 2018 kündigte Cloudflare den öffentlichen DNS-Resolver 1.1.1.1 an. Im Laufe der Jahre haben wir die Debug-Seite zur Fehlerbehebung, die globale Cache-Bereinigung, 0 TTL für Zonen auf Cloudflare, Upstream TLS und 1.1.1.1 für Familien zur Plattform hinzugefügt. In diesem Beitrag möchten wir Ihnen einige Details und Änderungen hinter den Kulissen vorstellen.
Als das Projekt begann, wurde Knot Resolver als DNS-Resolver ausgewählt. Wir begannen, ein ganzes System darauf zu entwickeln, damit es für den Anwendungsfall von Cloudflare geeignet war. Einen praxiserprobten rekursiven DNS-Resolver sowie einen DNSSEC-Validator zu haben, war fantastisch, denn so konnten wir unsere Energie anderweitig einsetzen, anstatt uns um die Implementierung des DNS-Protokolls zu kümmern.
Knot Resolver ist in Bezug auf sein Lua-basiertes Plugin-System recht flexibel. Es ermöglichte uns, die Kernfunktionalität schnell zu erweitern, um verschiedene Produktfunktionen wie DoH/DoT, Protokollierung, BPF-basierte Angriffsabwehr, Cache-Sharing und Überschreibung der Iterationslogik zu unterstützen. Als der Traffic zunahm, stießen wir an gewisse Grenzen.
Welche Lektionen wir gelernt haben
Bevor wir tiefer in die Materie einsteigen, lassen Sie uns zunächst ein vereinfachtes Cloudflare-Rechenzentrum aus der Vogelperspektive betrachten, damit wir klären, worüber wir später sprechen werden. Bei Cloudflare ist jeder Server identisch: Der Software-Stack, der auf einem Server läuft, ist genau der gleiche wie auf jedem anderen Server, nur die Konfiguration kann sich unterscheiden. Diese Art der Konfiguration macht es viel einfacher, die Server zu verwalten.

Der Resolver läuft als Daemon-Prozess, kresd, und ist nicht allein. Anfragen, insbesondere DNS-Anfragen, werden von Unimog auf die Server in einem Rechenzentrum verteilt. DoH-Anfragen werden an unserem TLS-Terminator beendet. Configs und andere kleine Daten können von Quicksilver in Sekundenschnelle weltweit zugestellt werden. Mit all dieser Unterstützung kann sich der Resolver auf sein eigentliches Ziel konzentrieren – die Auflösung von DNS-Anfragen – und muss sich nicht um die Details des Transportprotokolls kümmern. Lassen Sie uns nun über 3 Schlüsselbereiche sprechen, die wir hier verbessern wollten – die Blockierung von E/A in Plugins, eine effizientere Nutzung des Cache-Speicherplatzes und die Isolierung von Plugins.
Callbacks, die die Ereignisschleife blockieren
Knot Resolver verfügt über ein sehr flexibles Plugin-System zur Erweiterung seiner Kernfunktionen. Die Plugins werden Module genannt und basieren auf Callbacks. An bestimmten Punkten während der Anfrageverarbeitung werden diese Callbacks mit dem aktuellen Abfragekontext aufgerufen. Dadurch kann ein Modul Anfragen/Antworten prüfen, ändern und sogar eigene Anfragen/Antworten erstellen. Diese Callbacks sind so konzipiert, dass sie einfach sind, damit die zugrunde liegende Ereignisschleife nicht blockiert wird. Das ist wichtig, weil der Dienst nur einen Thread hat und die Ereignisschleife für die gleichzeitige Bearbeitung vieler Anfragen zuständig ist. Wenn also auch nur eine Anfrage in einem Callback aufgehalten wird, bedeutet dies, dass keine anderen gleichzeitigen Anfragen bearbeitet werden können, bis der Callback beendet ist.
Diese Konfiguration hat für uns gut funktioniert, bis wir blockierende Aktionen durchführen mussten, z. B. um Daten aus Quicksilver zu ziehen, bevor wir dem Client antworten konnten.
Cache-Effizienz
Anfragen für eine Domain könnten bei jedem beliebigen Knoten innerhalb eines Rechenzentrums landen. Daher wäre es eine Verschwendung, eine Anfrage wiederholt aufzulösen, wenn ein anderer Knoten bereits die Antwort hat. Intuitiv könnte die Latenzzeit verbessert werden, wenn der Cache von den Servern gemeinsam genutzt werden könnte. Daher haben wir ein Cache-Modul entwickelt, das die neu hinzugefügten Cache-Einträge per Multicasting überträgt. Knoten innerhalb desselben Rechenzentrums könnten dann die Ereignisse abonnieren und ihren lokalen Cache aktualisieren.
Die standardmäßige Cache-Implementierung in Knot Resolver ist LMDB. Sie ist schnell und zuverlässig für kleine bis mittlere Implementierungen. Aber in unserem Fall wurde die Löschung aus dem Cache bald zu einem Problem. Der Cache selbst achtet nicht auf TTL, Popularität usw. Wenn er voll ist, löscht er einfach alle Einträge und beginnt von vorne. Szenarien wie die Zone Enumeration könnten den Cache mit Daten füllen, die später wahrscheinlich nicht mehr abgerufen werden können.
Darüber hinaus verschlimmerte unser Multicast-Cachemodul die Situation, indem es die weniger nützlichen Daten an alle Knoten weiterleitete und deren Zwischenspeicher gleichzeitig an das Kapazitätslimit brachte. Dann nahm die Latenz sprunghaft zu, weil alle Knoten den Cache löschten und etwa zur gleichen Zeit neu starteten.
Modul-Isolierung
Da die Liste der Lua-Module immer länger wurde, wurde die Fehlersuche immer schwieriger. Das liegt daran, dass ein einziger Lua-Status von allen Modulen gemeinsam genutzt wird, so dass ein Modul, das sich falsch verhält, Auswirkungen auf andere Module haben kann. Wenn z.B. im Lua-Status etwas schief lief, z.B. zu viele Coroutines oder zu wenig Speicher, hatten wir Glück, wenn das Programm einfach abstürzte. Die daraus resultierenden Stacktraces waren jedoch schwer zu lesen. Es ist auch schwierig, ein laufendes Modul gewaltsam abzuschalten oder zu aktualisieren, da es nicht nur einen Status in der Lua-Laufzeitumgebung hat, sondern auch FFI, so dass die Sicherheit des Speichers nicht gewährleistet ist.
Hello BigPineapple
Wir fanden keine bestehende Software, die unsere etwas nischenhaften Anforderungen erfüllte, also begannen wir schließlich, selbst etwas zu entwickeln. Der erste Versuch bestand darin, den Kern von Knot Resolver in einen in Rust geschriebenen, schlanken Dienst (modifiziertes edgedns) zu packen.
Dies erwies sich als schwierig, da ständig zwischen den Speichertypen und den C/FFI-Typen konvertiert werden musste und einige andere Eigenheiten (z.B. erwartet die ABI für die Suche nach Datensätzen aus dem Cache, dass die ausgegebenen Datensätze bis zum nächsten Aufruf oder dem Ende des Lesevorgangs unveränderlich sind). Wir lernten jedoch viel bei dem Versuch, diese Art von geteilter Funktionalität zu implementieren, bei der der Host (der Dienst) dem Gast (der Resolver-Kernbibliothek) einige Ressourcen zur Verfügung stellt, und wie wir diese Schnittstelle verbessern können.
In den späteren Iterationen ersetzten wir die gesamte rekursive Bibliothek durch eine neue, die auf einer asynchronen Laufzeit basiert. Außerdem wurde ein umgestaltetes Modulsystem hinzugefügt, das den Dienst im Laufe der Zeit heimlich in Rust umschrieb, während wir immer mehr Komponenten austauschten. Diese asynchrone Laufzeitumgebung war tokio – sie bot eine ordentliche Thread-Pool-Schnittstelle für die Ausführung von nicht-blockierenden und blockierenden Aufgaben sowie ein gutes Ökosystem für die Arbeit mit anderen Crates (Rust-Bibliotheken).
Danach, als die Futures-Kombinatoren mühsam wurden, begannen wir, alles in async/await umzuwandeln. Das war noch vor der async/await-Funktion, die in Rust 1.39 Einzug hielt, was uns dazu veranlasste, eine Zeit lang Nightly (Rust Beta) zu verwenden, dies führte allerdings zu einigen Problemen führte. Nachdem sich async/await stabilisierte, konnten wir unseren Ablauf zur Verarbeitung von Anfragen ergonomisch schreiben, ähnlich wie bei Go.
Alle Aufgaben können gleichzeitig ausgeführt werden, und bestimmte E/A-lastige Vorgänge können in kleinere Teile aufgeteilt werden, um von einer detaillierteren Planung zu profitieren. Da die Laufzeitumgebung Aufgaben in einem Threadpool und nicht in einem einzelnen Thread ausführt, profitiert sie auch vom „Work Stealing“. Dadurch wird ein Problem vermieden, das wir früher hatten, nämlich dass eine einzelne Anfrage nur sehr langsam verarbeitet wird und alle anderen Anfragen in der Ereignisschleife blockiert.
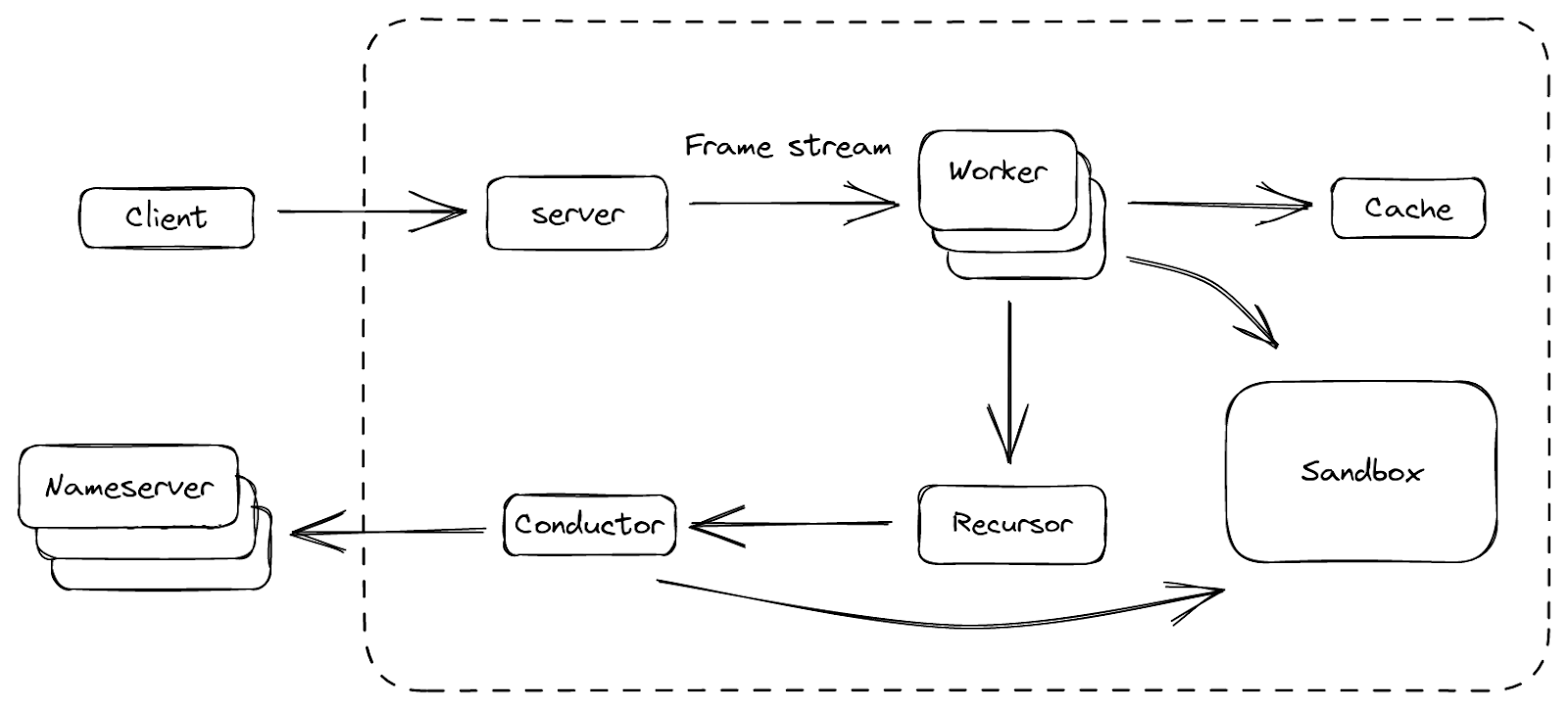
Schließlich haben wir eine Plattform geschmiedet, mit der wir zufrieden sind. Wir tauften sie BigPineapple. Die Abbildung oben zeigt einen Überblick über die Hauptkomponenten und den Datenfluss zwischen ihnen. Innerhalb von BigPineapple empfängt das Servermodul eingehende Anfragen vom Client, validiert sie und wandelt sie in einheitliche Frame-Streams um, die dann vom Worker-Modul verarbeitet werden können. Das Worker-Modul verfügt über eine Reihe von Workern, deren Aufgabe es ist, die Antwort auf die Frage in der Anfrage herauszufinden. Jeder Worker interagiert mit dem Cache-Modul, um zu prüfen, ob die Antwort vorhanden und noch gültig ist, andernfalls steuert er das Rekursor-Modul an, um die Anfrage rekursiv zu wiederholen. Der Rekursor führt keine E/A aus. Wenn er etwas benötigt, delegiert er die Teilaufgabe an das Conductor-Modul. Der Conductor verwendet dann ausgehende Abfragen, um die Informationen von vorgelagerten Nameservern zu erhalten. Während des gesamten Prozesses können einige Module mit dem Sandbox-Modul interagieren, um dessen Funktionalität zu erweitern, indem die Plugins darin ausgeführt werden.
Sehen wir uns einige von ihnen genauer an und betrachten wir, wie sie uns geholfen haben, die Probleme zu überwinden, die wir zuvor hatten.
Aktualisierte E/A-Architektur
Ein DNS-Resolver kann als Vermittler zwischen einem Client und mehreren autoritativen Nameservern betrachtet werden: Er nimmt Anfragen vom Client entgegen, holt rekursiv Daten von den vorgelagerten Nameservern ab, stellt dann die Antworten zusammen und sendet sie zurück an den Client. Es gibt also sowohl eingehenden als auch ausgehenden Traffic, der vom Server bzw. der Conductor-Komponente verarbeitet wird.
Der Server lauscht an einer Liste von Schnittstellen, die verschiedene Transportprotokolle verwenden. Diese werden später in Datenströme von „Frames“ abstrahiert. Jeder Frame ist eine übergeordnete Darstellung einer DNS-Nachricht mit einigen zusätzlichen Metadaten. Dabei kann es sich um ein UDP-Paket, ein Segment eines TCP-Streams oder die Payload einer HTTP-Anfrage handeln, aber sie werden alle auf die gleiche Weise verarbeitet. Der Frame wird dann in eine asynchrone Aufgabe umgewandelt, der wiederum von einer Reihe von Workern aufgegriffen wird, die für die Lösung dieser Aufgaben zuständig sind. Die erledigten Aufgaben werden wieder in Antworten umgewandelt und an den Client zurückgeschickt.
Diese „Frame“-Abstraktion über die Protokolle und ihre Kodierungen vereinfacht die Logik, die zur Regulierung der Frame-Quellen verwendet wird, wie z.B. die Durchsetzung von Fairness, um ein Aushungern (Starvation) zu verhindern, und die Steuerung des Tempos, um den Server vor Überlastung zu schützen. Bei den bisherigen Implementierungen haben wir unter anderem gelernt, dass bei einem öffentlich zugänglichen Dienst die maximale Performance der E/A weniger wichtig ist als die Fähigkeit, den Kunden ein angemessenes Tempo zu bieten. Das liegt vor allem daran, dass die Zeit und die Rechenkosten jeder rekursiven Anfrage sehr unterschiedlich sind (z.B. ein Cache-Treffer im Vergleich zu einem Cache-Fehlschlag) und es schwierig ist, dies im Voraus abzuschätzen. Die Cache-Fehlschläge bei rekursiven Diensten verbrauchen nicht nur die Ressourcen von Cloudflare, sondern auch die Ressourcen der abgefragten autoritativen Nameserver, so dass wir dies berücksichtigen müssen.
Auf der anderen Seite des Servers befindet sich der Conductor, der alle ausgehenden Verbindungen verwaltet. Es ist hilfreich, einige Fragen zu beantworten, bevor man sich an den vorgeschalteten Server wendet: Welcher Nameserver ist in Bezug auf die Latenzzeit am schnellsten zu erreichen? Was ist zu tun, wenn alle Nameserver nicht erreichbar sind? Welches Protokoll soll für die Verbindung verwendet werden, und gibt es bessere Optionen? Der Conductor ist in der Lage, diese Entscheidungen zu treffen, indem er die Metriken des vorgelagerten Servers verfolgt, wie RTT, QoS usw. Mit diesem Wissen kann er auch Aspekte wie die Kapazität der vorgelagerten Server und den Verlust von UDP-Paketen abschätzen und die notwendigen Maßnahmen ergreifen, z.B. einen erneuten Versuch, wenn er glaubt, dass das vorherige UDP-Paket den vorgelagerten Server nicht erreicht hat.
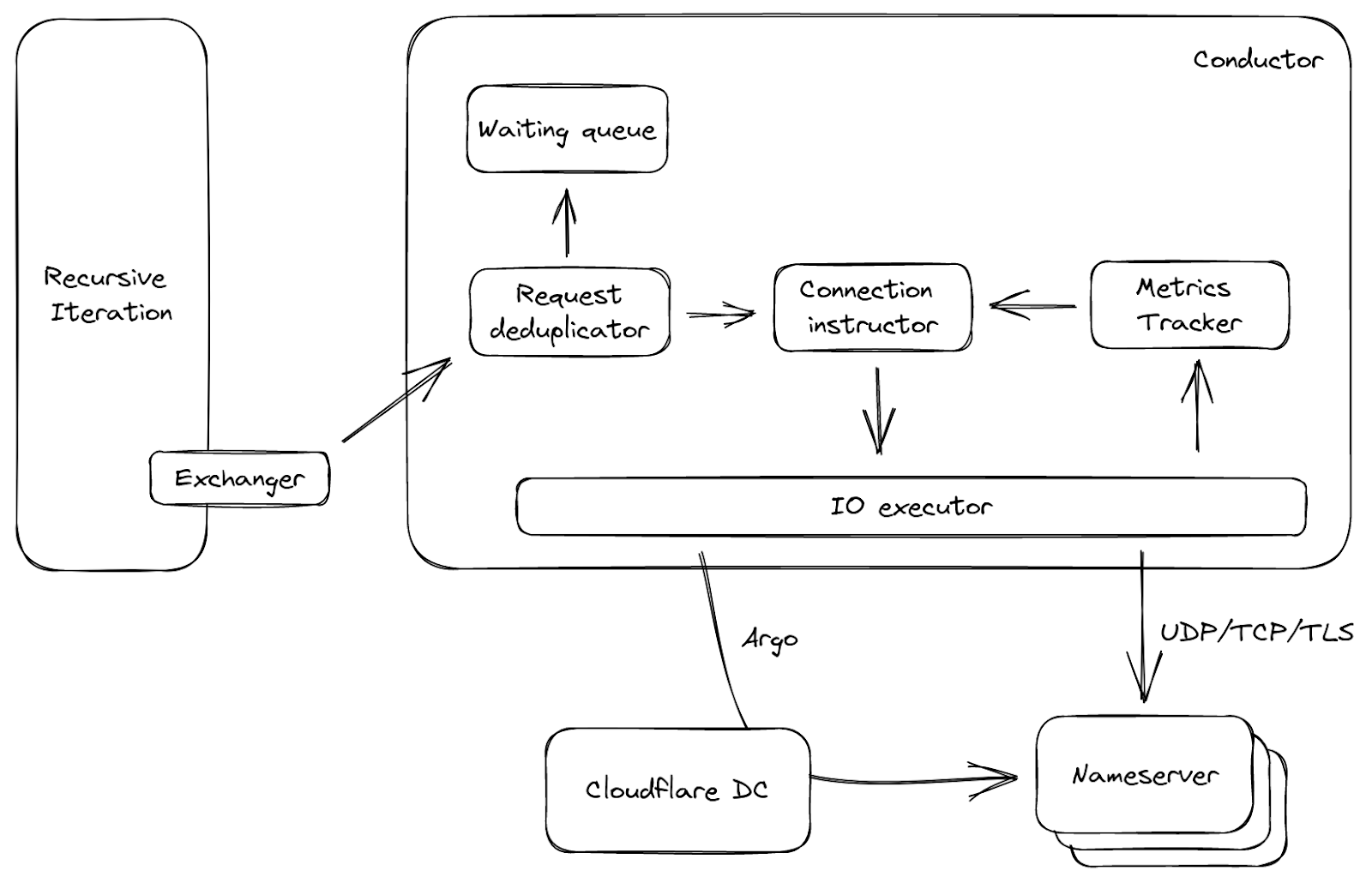
Abbildung 3 zeigt einen vereinfachten Datenfluss über den Conductor. Er wird von dem oben erwähnten Exchanger aufgerufen, mit vorgelagerten Anfragen als Input. Die Anfragen werden zunächst dedupliziert: Das bedeutet, dass in einem kleinen Zeitfenster, wenn viele Anfragen an den Conductor kommen und die gleiche Frage stellen, nur eine von ihnen durchgelassen wird, die anderen werden in eine Warteschlange gestellt. Dies ist üblich, wenn ein Cache-Eintrag abläuft, und kann unnötigen Traffic im Netzwerk reduzieren. Auf der Grundlage der Anfrage und der vorgelagerten Metriken wählt der Verbindungsausführende (Connection-Instructor) dann entweder eine offene Verbindung aus, falls vorhanden, oder er generiert eine Reihe von Parametern. Mit diesen Parametern kann sich der E/A-Ausführende (I/O-Executor) direkt mit dem Upstream verbinden oder sogar mithilfe unserer Argo Smart Routing-Technologie eine Route über ein anderes Cloudflare-Rechenzentrum nehmen!
Der Cache
Die Zwischenspeicherung in einem rekursiven Dienst ist von entscheidender Bedeutung, da ein Server eine zwischengespeicherte Antwort in weniger als einer Millisekunde ausgeben kann, während es Hunderte von Millisekunden dauert, bis er bei einem Cache-Fehlschlag reagiert. Da der Speicherplatz beschränkt ist (und in der Architektur von Cloudflare auch eine gemeinsam genutzte Ressource), war die Verbesserung des Cache-Speichers eines unserer wichtigsten Vorhaben. Der neue Cache ist anstelle eines KV-Speichers mit einer Datenstruktur für den Cache-Ersatz (ARC) ausgestattet. Dadurch wird der Speicherplatz auf einem einzelnen Knoten gut genutzt, da weniger beliebte Einträge nach und nach gelöscht werden und die Datenstruktur resistent gegen Scans ist.
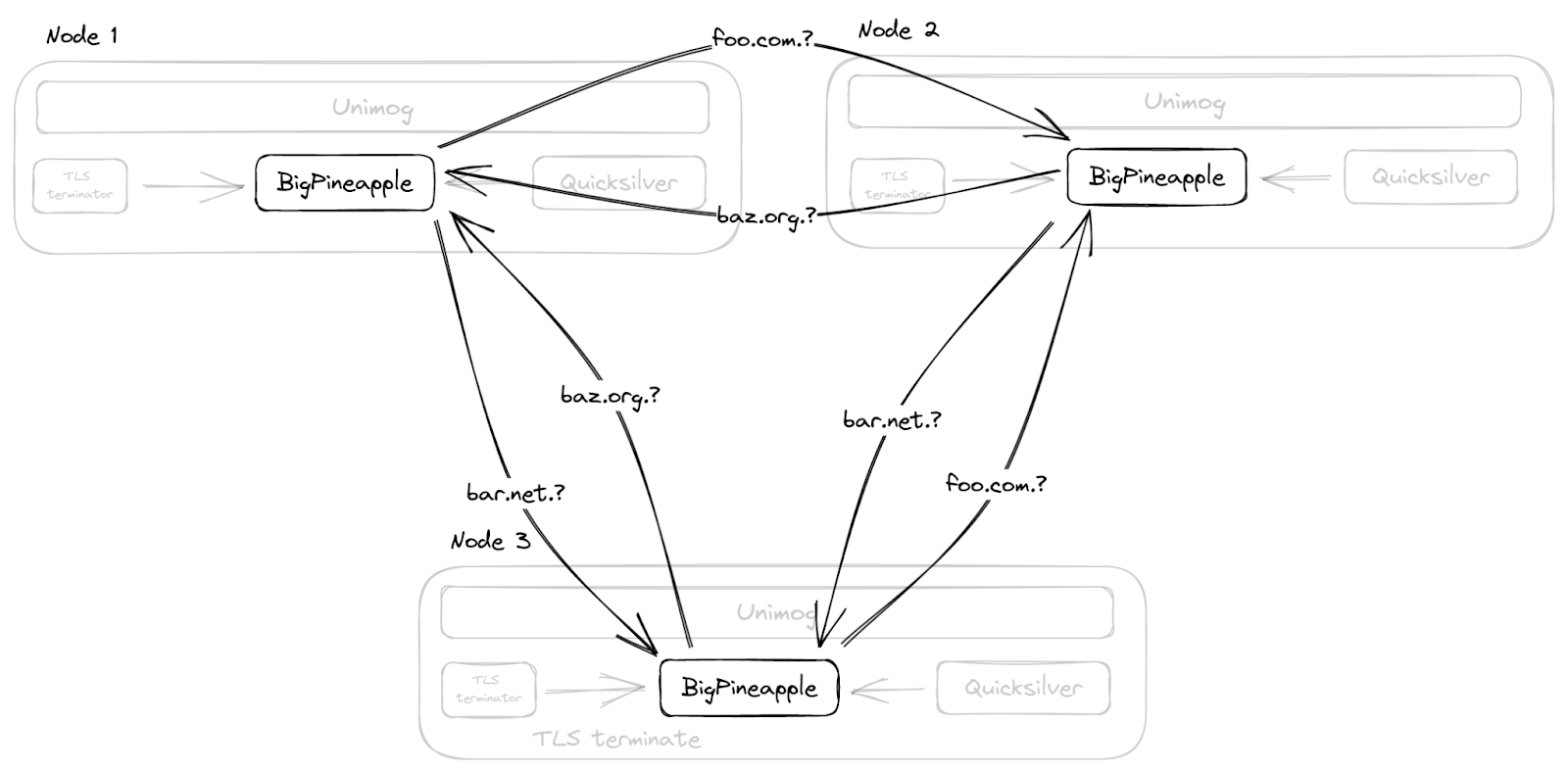
Anstatt den Cache im gesamten Rechenzentrum mit Multicast zu duplizieren, wie wir es zuvor getan haben, kennt BigPineapple seine Peer-Knoten im selben Rechenzentrum und leitet Anfragen von einem Knoten an einen anderen weiter, wenn es einen Eintrag in seinem eigenen Cache nicht findet. Dies geschieht durch konsistentes Hashing der Abfragen auf die intakten Knoten in jedem Rechenzentrum. So durchlaufen beispielsweise Abfragen für dieselbe registrierte Domain dieselbe Untergruppe von Knoten, was nicht nur die Trefferquote im Cache erhöht, sondern auch dem Infrastruktur-Cache hilft, der Informationen über die Performance und die Funktionen der Nameserver speichert.
Asynchrone rekursive Bibliothek
Die rekursive Bibliothek ist das DNS-Gedächtnis von BigPineapple, denn sie weiß, wie sie die Antwort auf die Frage in der Abfrage finden kann. Ausgehend von der Root, zerlegt es die Client-Anfrage in Unterabfragen und verwendet diese, um rekursiv Wissen von verschiedenen autoritativen Nameservern im Internet zu sammeln. Dieser Prozess führt zu einer Antwort. Dank async/await kann es als eine Funktion wie diese abstrahiert werden:
async fn resolve(Request, Exchanger) → Result<Response>;
Die Funktion enthält die gesamte Logik, die erforderlich ist, um eine Antwort auf eine bestimmte Anfrage zu generieren, aber sie führt selbst keine E/A aus. Stattdessen übergeben wir ein Exchanger trait (Rust-Interface), das weiß, wie man asynchron DNS-Nachrichten mit vorgelagerten autoritativen Nameservern austauscht. Der Exchanger wird in der Regel an verschiedenen Await-Punkten aufgerufen – wenn zum Beispiel eine Rekursion beginnt, wird als erstes die nächstgelegene zwischengespeicherte Delegation für die Domain gesucht. Wenn er die endgültige Delegation nicht im Cache hat, muss er fragen, welche Nameserver für diese Domain zuständig sind, und auf die Antwort warten, bevor er weitermachen kann.
Dank dieses Designs, das das Warten auf Antworten von der rekursiven DNS-Logik entkoppelt, ist es viel einfacher zu testen, indem eine Scheinimplementierung des Exchangers bereitgestellt wird. Außerdem wird der Code für die rekursive Iteration (und insbesondere die DNSSEC-Validierungslogik) dadurch viel lesbarer, da er sequentiell geschrieben wird, anstatt über viele Callbacks verstreut zu sein.
Übrigens: Einen rekursiven DNS-Resolver von Grund auf zu programmieren, macht überhaupt keinen Spaß!
Nicht nur wegen der Komplexität der DNSSEC-Validierung, sondern auch wegen der notwendigen „Workarounds“ (Notbehelfe), die für verschiedene RFC-inkompatible Server, Forwarder, Firewalls usw. erforderlich sind. Deshalb haben wir deckard nach Rust portiert, um es zu testen. Als wir mit der Migration zu dieser neuen asynchronen rekursiven Bibliothek begannen, ließen wir sie zunächst im „Schattenmodus“ laufen: Wir verarbeiteten reale Abfragebeispiele aus dem Produktionsdienst und verglichen die Unterschiede. In der Vergangenheit haben wir dies auch mit dem autoritativen DNS-Dienst von Cloudflare gemacht. Bei einem rekursiven Dienst ist es etwas schwieriger, da ein rekursiver Dienst alle Daten im Internet nachschlagen muss und autoritative Nameserver aufgrund von Lokalisierung, Load Balancing usw. oft unterschiedliche Antworten für dieselbe Abfrage geben, was zu vielen falsch-positiven Ergebnissen führt.
Im Dezember 2019 haben wir den neuen Dienst schließlich auf einem öffentlichen Test-Endpunkt aktiviert (siehe Ankündigung), um verbleibende Probleme zu beseitigen, bevor wir die Produktions-Endpunkte langsam auf den neuen Dienst migrieren. Selbst danach haben wir immer noch Probleme mit der DNS-Rekursion (und insbesondere mit der DNSSEC-Validierung) festgestellt, aber das Beheben und Reproduzieren dieser Probleme ist dank der neuen Architektur der Bibliothek viel einfacher geworden.
Plugins in der Sandbox
Für uns ist es wichtig, dass wir die DNS-Kernfunktionalität spontan erweitern können. Deshalb hat BigPineapple sein Plugin-System neu gestaltet. Zuvor liefen die Lua-Plugins im selben Speicherbereich wie der Dienst selbst und konnten im Allgemeinen tun und lassen, was sie wollten. Dies ist praktisch, da wir Speicherreferenzen zwischen dem Dienst und den Modulen mit C/FFI frei übergeben können. Zum Beispiel, um eine Antwort unmittelbar aus dem Cache zu lesen, ohne sie erst in einen Puffer kopieren zu müssen. Aber es ist auch gefährlich, denn das Modul kann nicht-initialisierten Speicher lesen, eine Host-ABI mit einer falschen Funktionssignatur aufrufen, auf einem lokalen Socket blockieren oder andere unerwünschte Dinge tun, und außerdem hat der Dienst keine Möglichkeit, diese Aktionen zu beschränken.
Also überlegten wir, die eingebettete Lua-Laufzeit durch JavaScript oder native Module zu ersetzen. Allerdings begannen etwa zur gleichen Zeit eingebettete Laufzeiten für WebAssembly (kurz: Wasm) auf den Markt zu kommen. Zwei schöne Eigenschaften von WebAssembly-Programmen sind, dass wir sie in derselben Sprache wie den Rest des Dienstes schreiben können und dass sie in einem isolierten Speicherbereich ausgeführt werden. Also begannen wir, die Gast-/Host-Schnittstelle um die Einschränkungen der WebAssembly-Module herum zu modellieren, um zu sehen, wie das funktionieren würde.
Die Wasm-Laufzeitumgebung von BigPineapple wird derzeit von Wasmer unterstützt. Wir haben im Laufe der Zeit verschiedene Laufzeiten wie Wasmtime und WAVM ausprobiert und festgestellt, dass Wasmer in unserem Fall einfacher zu verwenden war. Die Laufzeitumgebung ermöglicht es, dass jedes Modul in seiner eigenen Instanz läuft, mit einem isolierten Speicher und einer Signal-Trap, was natürlich das zuvor beschriebene Problem der Modulisolierung löste. Darüber hinaus können wir mehrere Instanzen desselben Moduls gleichzeitig laufen lassen. Bei sorgfältiger Kontrolle können die Anwendungen im laufenden Betrieb von einer Instanz zur anderen geswappt werden, ohne dass eine einzige Anfrage verloren geht! Das ist großartig, weil die Anwendungen ohne einen Neustart des Servers aktualisiert werden können. Da die Wasm-Programme über Quicksilver verteilt werden, kann die Funktionalität von BigPineapple weltweit innerhalb weniger Sekunden sicher geändert werden!
Um die WebAssembly-Sandbox besser zu verstehen, müssen zunächst einige Begriffe erläutert werden:
- Host: das Programm, das die Wasm-Laufzeitumgebung ausführt. Ähnlich wie ein Kernel hat er über die Laufzeitumgebung die volle Kontrolle über die Gastanwendungen.
- Gastanwendung: das Wasm-Programm innerhalb der Sandbox. Innerhalb einer eingeschränkten Umgebung kann er nur auf seinen eigenen Speicherbereich zugreifen, der von der Laufzeitumgebung bereitgestellt wird, und die importierten Host-Aufrufe aufrufen. Wir nennen sie einfach eine App.
- Host-Aufruf: die im Host definierten Funktionen, die vom Gast importiert werden können. Ähnlich wie bei syscall ist dies die einzige Möglichkeit für Gastanwendungen, auf die Ressourcen außerhalb der Sandbox zuzugreifen.
- Gast-Laufzeitumgebung: eine Bibliothek für Gastanwendungen zur einfachen Interaktion mit dem Host. Es implementiert einige allgemeine Schnittstellen, so dass eine Anwendung einfach async, socket, log und tracing verwenden kann, ohne die zugrunde liegenden Details zu kennen.
Jetzt ist es an der Zeit, dass wir die Sandbox näher betrachten. Also nehmen Sie sich kurz Zeit und folgen Sie uns. Beginnen wir mit der Gastseite und sehen wir uns den gewöhnlichen App-Lifecycle an. Mit Hilfe der Gast-Laufzeitumgebung können Gastanwendungen ähnlich wie reguläre Programme geschrieben werden. Wie andere ausführbare Dateien beginnt also auch eine App mit einer Startfunktion als Einstiegspunkt, die vom Host beim Laden aufgerufen wird. Sie wird auch mit Argumenten wie in der Befehlszeile versehen. An diesem Punkt führt die Instanz normalerweise einige Initialisierungen durch und, was noch wichtiger ist, sie erfasst Callback-Funktionen für verschiedene Abfragephasen. Das liegt daran, dass eine Abfrage in einem rekursiven Resolver mehrere Phasen durchlaufen muss, bevor sie genügend Informationen sammelt, um eine Antwort zu liefern, z.B. eine Cache-Abfrage oder Unterabfragen, um eine Delegationskette für die Domain aufzulösen. Die Möglichkeit, diese Phasen zu verknüpfen, ist also notwendig, damit die Anwendungen für verschiedene Anwendungsfälle nützlich sind. Die Startfunktion kann auch einige Hintergrundaufgaben ausführen, um die Phasen-Callbacks zu ergänzen, und den globalen Status speichern. Zum Beispiel – Metriken berichten oder gemeinsam genutzte Daten aus externen Quellen vorab abrufen usw. Wiederum genau so, wie wir ein normales Programm schreiben.
Aber woher stammen die Argumente des Programms? Wie kann eine Gastanwendung Protokolle und Metriken senden? Die Antwort lautet: externe Funktionen.
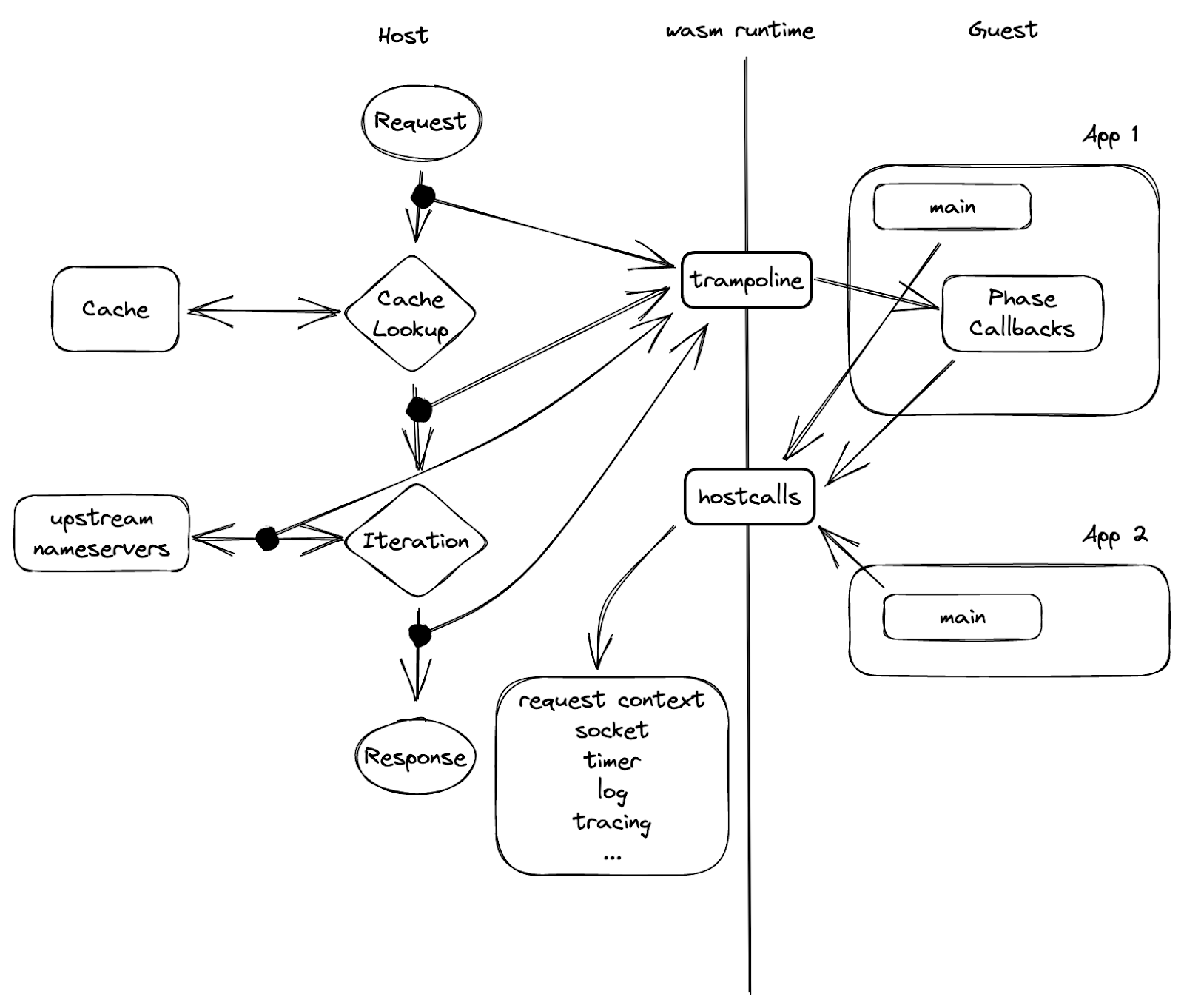
In Abbildung 5 sehen wir in der Mitte eine Schranke, die die Sandbox-Grenze darstellt und den Gast vom Host trennt. Die einzige Möglichkeit, wie eine Seite die andere erreichen kann, ist über eine Reihe von Funktionen, die von der Gegenseite zuvor exportiert wurden. Wie in der Abbildung dargestellt, werden die „Hostcalls“ vom Host exportiert und vom Gast importiert und aufgerufen, während die „Trampoline“ Gastfunktionen sind, die dem Host bekannt sind.
Sie wird „Trampolin“ genannt, weil sie zum Aufrufen einer Funktion oder einer Closure innerhalb einer Gastinstanz verwendet wird, die nicht exportiert wird. Die Phasen-Callbacks sind ein Beispiel dafür, warum wir eine Trampolin-Funktion benötigen: Jeder Callback gibt eine Closure aus und kann daher bei der Instanziierung nicht exportiert werden. Wenn also eine Gastanwendung einen Callback registrieren möchte, ruft sie einen Host-Aufruf mit der Callback-Adresse „hostcall_register_callback(pre_cache, #30987)“, auf. Wenn der Callback aufgerufen werden soll, kann der Host diesen Zeiger nicht einfach aufrufen, da er auf den Speicherbereich des Gastes verweist. Stattdessen kann er eine der oben genannten Trampoline nutzen und ihr die Adresse der Callback-Closure geben: „trampoline_call(#30987)“.
Verwaltungskosten der Isolierung
Wie eine Münze, die zwei Seiten hat, ist die neue Sandbox mit einigen zusätzlichen Kosten verbunden. Die Portabilität und Isolierung, die WebAssembly bietet, sind mit zusätzlichen Kosten verbunden. Hier führen wir zwei Beispiele auf.
Erstens ist es Gastanwendungen nicht erlaubt, den Speicher des Hosts zu lesen. Die Funktionsweise besteht darin, dass der Gast einen Speicherbereich über einen Host-Aufruf bereitstellt und der Host die Daten dann in den Speicherbereich des Gastes schreibt. Dadurch wird eine Speicherkopie erstellt, die nicht erforderlich wäre, wenn wir uns außerhalb der Sandbox befinden würden. Die schlechte Nachricht ist, dass die Gastanwendungen in unserem Anwendungsfall etwas mit der Abfrage und/oder der Antwort machen sollen, so dass sie fast immer bei jeder einzelnen Anfrage Daten vom Host lesen müssen. Die gute Nachricht hingegen ist, dass sich die Daten während des Lebenszyklus einer Anfrage nicht ändern werden. Wir weisen also direkt nach der Instanziierung der Gastanwendung einen Großteil des Speichers im Gast-Speicherbereich zu. Der zugewiesene Speicher wird nicht verwendet, sondern dient dazu, eine Lücke im Adressraum zu besetzen. Sobald der Host die Adressangaben erhält, ordnet er einen gemeinsamen Speicherbereich mit den vom Gast benötigten gemeinsamen Daten dem Speicherbereich des Gastes zu. Wenn der Gastcode mit der Ausführung beginnt, kann er einfach auf die Daten im gemeinsamen Speicher-Overlay zugreifen, ohne dass eine Kopie erforderlich ist.
Ein weiteres Problem trat auf, als wir in BigPineapple die Unterstützung für ein modernes Protokoll, oDoH, hinzufügen wollten. Die Hauptaufgabe dieses Protokolls besteht darin, die Client-Anfrage zu entschlüsseln, sie aufzulösen und dann die Antworten zu verschlüsseln, bevor sie zurückgeschickt werden. Diese Funktion gehört nicht zum Kern von DNS und sollte stattdessen mit einer Wasm-App erweitert werden. Der WebAssembly-Befehlssatz stellt jedoch einige Krypto-Primitive wie AES und SHA-2 nicht zur Verfügung, so dass er nicht von der Hardware des Hosts profitieren kann. Es wird daran gearbeitet, diese Funktionalität mit WASI-crypto in Wasm zu integrieren. Bis dahin besteht unsere Lösung darin, den HPKE einfach über Host-Aufrufe an den Host zu delegieren. Wir haben bereits 4-fache Performance-Verbesserungen im Vergleich zur Ausführung innerhalb von Wasm festgestellt.
Async in Wasm
Erinnern Sie sich an das Problem, über das wir zuvor gesprochen haben, dass die Callbacks die Ereignisschleife blockieren könnten? Das Problem besteht im Wesentlichen darin, wie Sie den Code in der Sandbox asynchron ausführen können. Denn ganz gleich, wie komplex der Callback für die Anfrageverarbeitung ist, wenn er nachgeben kann, können wir eine Obergrenze für die Dauer der Blockierung festlegen. Glücklicherweise ist das asynchrone Framework von Rust sowohl elegant als auch schlank. Es bietet uns die Möglichkeit, eine Reihe von Gastaufrufen zu verwenden, um die „Future“s zu implementieren.
In Rust ist ein Future ein Baustein für asynchrone Berechnungen. Um ein asynchrones Programm zu erstellen, müssen Sie aus der Sicht des Nutzers zwei Dinge tun: eine abrufbare Funktion implementieren, die den Zustandsübergang steuert, und einen Waker als Callback platzieren, der sich selbst aufweckt, wenn die abrufbare Funktion aufgrund eines externen Ereignisses erneut aufgerufen werden soll (z.B. Zeit vergeht, Socket wird lesbar, und so weiter). Ersteres bedeutet, dass Sie das Programm schrittweise weiterentwickeln können, z.B. gepufferte Daten von I/O lesen und einen neuen Status ausgeben, der den Status der Aufgabe angibt: entweder abgeschlossen oder aufgegeben. Letzteres ist nützlich, wenn eine Aufgabe ausläuft, da der Future abgefragt wird, wenn die Bedingungen, auf die die Aufgabe gewartet hat, erfüllt sind, anstatt eine Schleife zu durchlaufen, bis die Aufgabe abgeschlossen ist.
Schauen wir uns an, wie dies in unserer Sandbox umgesetzt wird. In einem Szenario, in dem der Gast einige E/A durchführen muss, muss er dies über die Host-Aufrufe tun, da er sich in einer eingeschränkten Umgebung befindet. Unter der Annahme, dass der Host eine Reihe vereinfachter Host-Aufrufe bereitstellt, die die grundlegenden Socket-Aktivitäten widerspiegeln: Öffnen, Lesen, Schreiben und Schließen, kann der Gast seinen Pseudo-Poller wie unten definiert haben:
fn poll(&mut self, wake: fn()) -> Poll {
match hostcall_socket_read(self.sock, self.buffer) {
HostOk => Poll::Ready,
HostEof => Poll::Pending,
}
}
Hier liest der Host-Aufruf Daten von einem Socket in einen Puffer. Abhängig von seinem Rückgabewert kann die Funktion in einen der oben genannten Zustände übergehen: finished(Ready) oder yielded(Pending). Das eigentliche Wunder geschieht innerhalb des Host-Aufrufs. Erinnern Sie sich an Abbildung 5, dass nur so auf Ressourcen zugegriffen werden kann? Die Gastanwendung besitzt den Socket nicht, aber sie kann über „hostcall_socket_open“, ein „Handle“ erhalten, das wiederum einen Socket auf der Host-Seite erzeugt und ein Handle zurückgibt. Das Handle kann theoretisch alles sein, aber in der Praxis entsprechen Integer-Socket-Handles gut den Dateideskriptoren auf der Host-Seite oder den Indizes in einem Vektor oder Slab. Durch den Verweis auf das ausgegebene Handle kann die Gastanwendung den echten Socket fernsteuern. Da die Host-Seite vollständig asynchron ist, kann sie den Socket-Status einfach an den Gast weitergeben. Haben Sie bemerkt, dass die Waker-Funktion oben nicht verwendet wird? Keine Angst, das passt so! Das liegt daran, dass der Host-Aufruf nicht nur mit dem Öffnen eines Sockets beginnt, sondern auch den aktuellen Waker registriert, der aufgerufen wird, wenn der Socket geöffnet wird (oder nicht). Wenn also der Socket bereit ist, wird der Host-Task reaktiviert. Er findet den entsprechenden Gast-Task in seinem Kontext und reaktiviert ihn mit Hilfe der Trampolin-Funktion, wie in Abbildung 5 gezeigt. Es gibt andere Fälle, in denen ein Gast-Task auf einen anderen Gast-Task warten muss, zum Beispiel einen asynchronen Mutex. Der Mechanismus ist hier ähnlich: Verwendung von Host-Aufrufen zur Registrierung von Wakern
All diese komplizierten Dinge sind in unserer asynchronen Gast-Laufzeitumgebung mit einer einfach zu verwendenden API gekapselt, so dass die Gastanwendungen Zugriff auf reguläre asynchrone Funktionen erhalten, ohne sich um die zugrunde liegenden Details kümmern zu müssen.
(Nicht) Das Ende
Ich hoffe, dieser Blogbeitrag hat Ihnen einen Überblick über die innovative Plattform gegeben, die hinter 1.1.1.1 steckt. Sie entwickelt sich ständig weiter. Bereits heute werden mehrere unserer Produkte, wie 1.1.1.1 für Familien, AS112 und Gateway DNS, von Gastanwendungen unterstützt, die auf BigPineapple laufen. Wir freuen uns darauf, neue Technologien zu integrieren. Wenn Sie diesbezüglich Ideen haben, lassen Sie es uns in der Community oder per E-Mail wissen.