

今天,我们的 Tiered Cache (分层缓存)系统进行的更改导致用户的一些请求失败,状态码为 530。影响总共持续了接近 6 个小时。我们估计,高峰期约 5% 的请求没有得到响应。由于我们系统的复杂性和测试中的盲点,当更改发布到测试环境中时,我们没有发现这一点。
这一故障是由我们处理跨位置可缓存请求的方式产生的副作用导致的。乍一看,这些错误似乎是由另一个系统引起的,后者在一段时间前部署了新版本。我们的团队进行了多次尝试,以确定到底是什么导致了这些问题。一旦发现问题所在,我们加速进行了回滚,并在 87 分钟内完成。
对此故障我们表示抱歉,并正在采取措施以确保此类事件不再重现。
背景
Cloudflare 的产品之一是我们的内容分发网络(CDN)。该产品用于在全球缓存网站的资源。然而,某个数据中心不一定缓存了某个资源。该资源有可能是新的,已经过期,或已被清除。如果发生这种情况,当有用户请求该资源时,我们的 CDN 就需要从网站的源服务器获取新的副本。然而,用户正在访问的数据中心仍可能依然远离源服务器。这给客户带来了另一个问题:每次资源没有缓存在该数据中心时,我们都需要从源服务器获取新的副本。
为了提高命中率,我们引入了 Tiered Cache。通过使用 Tiered Cache,我们将 CDN 中的数据中心组织成一种层级结构,其中“下层”数据中心更接近最终用户,而“上层”数据中心更接近源服务器。当下层发生缓存不命中时,系统就会检查上层。如果上层有该资源的新副本,我们就能予以提供来响应请求。这提高了性能,并减少了 Cloudflare 为检索未缓存在下层的资源而不得不联系源服务器的次数。
事件时间线和影响
08:40 UTC (世界标准时间),某个 CDN 组件一个存在 bug 的软件版本开始慢慢推出。当用户访问某个配置了 Tiered Cache、Cloudflare Images 或 Bandwidth Alliance 的网站时,这个 bug 就会被触发。这个 bug 导致一部分客户收到 HTTP 状态码 530 —— 表示发生了错误。可从数据中心的本地缓存直接提供的内容不受影响。
在有问题的组件发布到一部分数据中心后,我们接到客户报告的 530 错误断续增加,随即展开调查。
随着该软件版本发布到全球范围内的其他数据中心,所触发的 530 错误大幅增加,并收到更多客户报告,于是我们宣布发生事件。
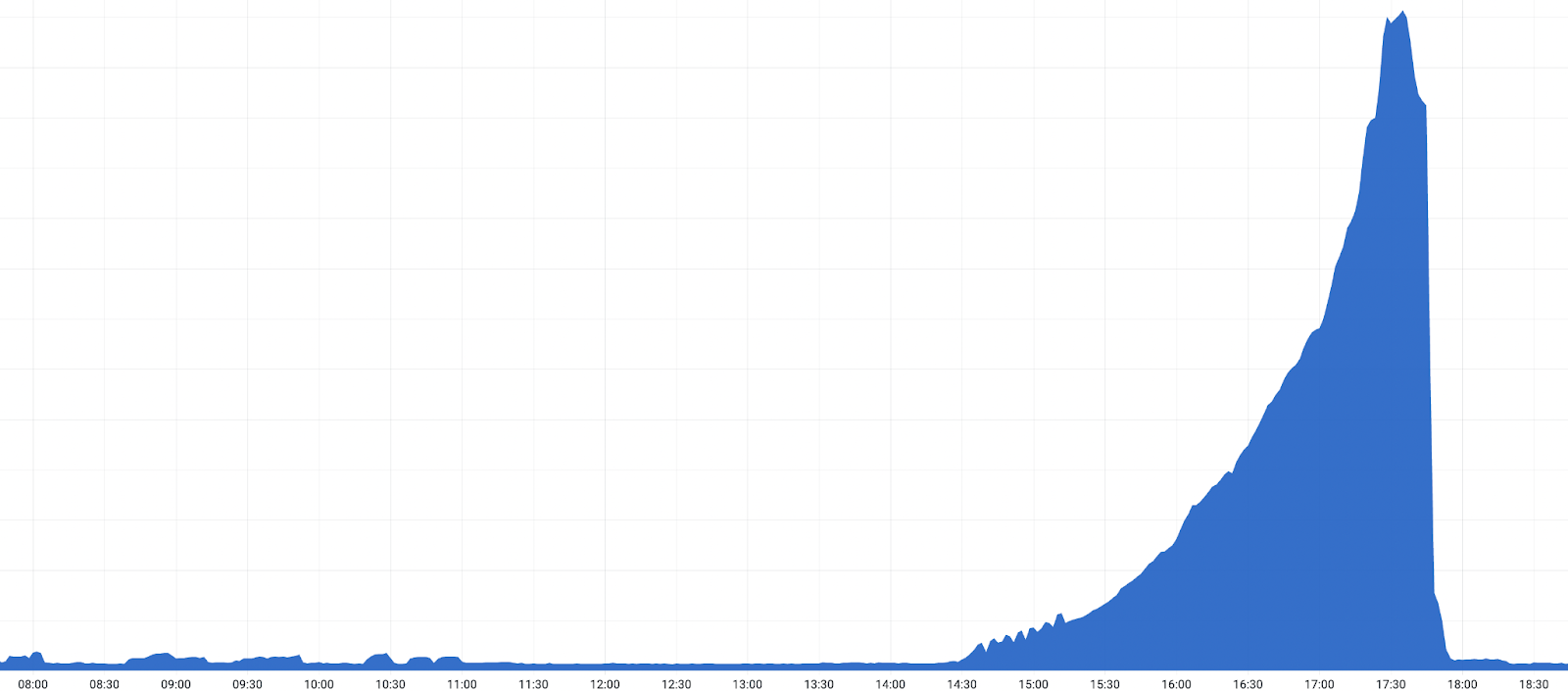
在 17:03 UTC,我们在一个数据中心回滚了该软件版本,从而证实错误是有问题的软件版本所致。回滚后,我们观察到 530 错误减少。得到证实后,我们加速在全球范围内的回滚,530 错误随之下降。所有配置为 Tiered Cache 上层的数据中心在 18:04 UTC 恢复到此前版本后,影响也结束了。
时间线:
- 2022-10-25 08:40: 该软件版本开始发布到一小部分数据中心。
- 2022-10-25 10:35: 出现一个客户警报,显示 500 错误代码增加。
- 2022-10-25 11:20: 经调查,一个小型数据中心被确定为问题的来源,并从生产中移除,同时团队在那里调查问题。
- 2022-10-25 12:30: 随着更多数据中心收到代码更改,问题开始更广泛地传播。
- 2022-10-25 14:22: 随着该软件版本开始逐渐发布到我们最大的数据中心,530 错误也增加了。
- 2022-10-25 14:39: 随着更多客户开始报告错误增加,多个团队开始参与调查。
- 2022-10-25 17:03: 亚特兰大数据中心的 CDN 软件版本回滚,证实了根本原因。
- 2022-10-25 17:28: 最高峰时,大约 5% 的 HTTP 请求会导致状态码为 530 的错误。
- 2022-10-25 17:38: 在作为众多客户上层的大型数据中心加速进行回滚。
- 2022-10-25 18:04: 所有上层数据中心的回滚完成。
- 2022-10-25 18:30: 回滚完成。
在调查的早期阶段,有迹象显示这是我们内部 DNS 系统的问题,后者同时也在推出一个新版本。如下文所示,那只是故障的一个副作用,而非原因所在。
将分布式跟踪添加到 Tiered Cache 引发这一问题
为帮助改进我们的性能,我们定期在服务的各个部分添加监控代码。监控代码帮助我们了解各种组件的运行情况,从而确定可以改进的瓶颈。我们的团队最近在 Tiered Cache 逻辑中添加了额外的分布式跟踪。Tiered Cache 入口点代码如下:
* 修改前
function _M.go()
-- code to run here
end
* 修改后:
local trace_fn = require("opentracing").trace_fn
local function go()
-- code to run here
end
function _M.go()
trace_fn(ngx.ctx, "tiered_cache_rewrite", go)
end上面的代码用 trace_fn() 包裹现有的 go() 函数,trace_fn() 将调用 go() 函数,然后报告后者的执行时间。
但是,向 opentracing 模块注入一个函数的逻辑会清除每个请求的控制标头:
require("opentracing").configure_module(conf,
-- control header extractor
function(ctx)
-- Always clear the headers.
clear_control_headers()
-- 通常,作为处理请求的常规操作,我们从这些控制标头中提取数据,然后清除它们。
但是内部分层缓存流量预计来自下层的控制标头按原样传递。清除标头和使用上层的组合意味着,对请求的路由可能至关重要的信息变得不可用。在受影响的请求子集中,缺失通过内部 DNS 查找源服务器 IP 地址以解析的主机名。因此,系统向客户端返回 530 DNS 错误。
补救及后续步骤
为了防止这种情况再次发生,除了修复上述 bug,我们还确定了一组更改,以帮助我们在日后发现和防止类似的问题:
- 在发布计划的初期,包含一个配置为 Tiered Cache 上层的较大型数据中心。这样一来,我们就能在全球发布前更快发现类似问题。
- 扩展我们的验收测试覆盖范围,纳入更广泛的配置集,包括各种 Tiered Cache 拓扑。
- 在请求没有完整上下文,需要在控制标头中提供额外的主机信息的情况下,更积极地发出警报。
- 确保我们的系统在遇到这样的错误时能更快纠正,从而帮助在开发和测试期间发现问题。
总结
我们经历了一个影响了大量使用 Tiered Cache 的客户的事件。在确定了有问题的组件之后,我们能够快速回滚并修复问题。对于这个事件给客户和尝试访问服务的最终用户造成的任何影响,我们感到抱歉。
我们将尽快采取补救措施,防止此类事件再次发生。