
The @Cloudflare team just pushed a change that improves our network's performance significantly, especially for particularly slow outlier requests. How much faster? We estimate we're saving the Internet ~54 years *per day* of time we'd all otherwise be waiting for sites to load.
— Matthew Prince ? (@eastdakota) June 28, 2018
目前已经有1000万个网站,应用程序和API使用Cloudflare加快其用户的上网速度。我们曾经最多通过151个数据中心每秒上传一千多万个请求。多年来,随着请求的增加,我们对我们的NGINX版本进行了许多修改。这篇文章讲述了其中一项修改内容。
NGINX的工作原理
NGINX是使用事件循环来解决C10K问题的程序之一。每次有一个网络事件进入时(一个新连接、请求或通知(让我们可以发送更多数据)等),NGINX就会被唤醒并开始处理事件,然后返回做它需要做的任何事情(可能是处理其他事件)。当事件到达时,与该事件关联的数据就已准备就绪,这使得NGINX可以同时有效地处理许多请求而无需等待。
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/以下是从文件描述符读取数据的一段代码:
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}当fd是网络套接字时,网站将返回已经到达的字节。最后的调用将返回 EWOULDBLOCK,这意味着我们已经耗尽了本地读缓冲区,因此在更多数据可用之前,我们不能再次从套接字中读取数据。
磁盘I / O与网络I / O不同
当 fd是Linux上的一个普通文件时, EWOULDBLOCK和 EAGAIN不可能出现,而read总是等待读取整个缓冲区。即使文件是由 O_NONBLOCK打开的,也是如此。
引用 open(2):
请注意,此标记对常规文件和块设备无效
换句话说,上面的代码基本上减少到:
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}这意味着如果事件处理程序需要从磁盘读取,那么在整个读取过程完成之前,它会一直阻止事件循环,从而导致接下来的事件处理程序都被延迟。
这对于大多数工作负载来说都很好,因为从磁盘读取通常足够快,并且与等待数据包从网络到达相比更加可预测。而且现在每个人都有SSD,我们的缓存磁盘都是SSD。现代SSD具有非常低的延迟,通常为10sμs。最重要的是,我们可以使用多个工作进程运行NGINX,这样以来,速度较慢的事件处理程序不会阻止其他进程中的请求。大多数情况下,我们可以依靠NGINX的事件处理来快速有效地处理请求。
SSD性能:并不总是像预想的那样
您可能已经猜到这些理想的假设并非总能如愿。如果每次读取需要50μs,那么在4KB块中读取0.19MB只需要2ms(我们读取的还是相比一般要更大的块)。但是我们测验到,我们到第一个字节的时间有时会更久,特别是在第99和第9百分位。换句话说,每100(或每1000)read的最慢读取时间通常比真正所需要的时间更长。
固态硬盘虽然很快,但它们非常复杂。其中包括计算机排队和重新排序I / O,还有执行垃圾收集和碎片整理等各种后台任务。有时会因为有一个请求变得很慢而影响整个进程。我的同事Ivan Babrou运行了一些I / O基准测试,并且看到了读取时间最长高达1秒。此外,我们的一些SSD比其他SSD的性能异常值更多。往后,我们将在购买SSD时更多地考虑性能稳定性,但与此同时,我们需要为现有硬件提供解决方案。
使用 SO_REUSEPORT平均分散负载
偶然的慢响应问题很难避免,我们真正想要避免的是1秒的I / O阻塞我们在同一秒内收到的1000个其他请求。从概念上讲,NGINX可以并行处理许多请求,但它一次只能运行1个事件处理程序。所以我添加了衡量这一点的指标:
gettimeofday(&start, NULL);
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
gettimeofday(&event_start_handle, NULL);
// handle event[1]: send out response to GET http://cloudflare.com/
timersub(&event_start_handle, &start, &event_loop_blocked);p99 event_loop_blocked结果是我们TTFB的50%以上。也就是说,服务请求所花费的时间的一半是事件循环被其他请求阻止的结果。 event_loop_blocked仅测量大约一半的阻塞(因为延迟的呼叫 epoll_wait()未被测量)因此阻塞时间的实际比率要高得多。
我们的每台机器有15个工作进程运行NGINX,这意味着一个慢速I / O应该只阻止最多达6%的请求。但是,事件并不是均匀分布的,最高工作者占用了11%的请求(或者是预期的两倍)。
SO_REUSEPORT可以解决分布不均的问题。Marek Majkowski之前曾在其他NGINX实例的背景下撰写过关于下行的文章,但由于我们的缓存过程中的上行连接是长期存在的,因此这种下行很大程度上不适用于我们的情况,因此打开连接的微小延迟可忽略不计。此单一配置更改可使 SO_REUSEPORT峰值p99提高33%。
将read()移动到线程池:并非良招
解决这个问题的方法是使read()不阻塞。事实上,这是一个在上行NGINX中实现的功能!下面的配置使得 read()与 write()在一个线程池完成,而不会阻止事件循环:
aio threads;
aio_write on;然而,当我们对此进行测试时,我们实际上看到p99略有增加,而不是33倍的响应时间改进。差异在误差范围内,但我们对结果感到绝望,并暂时停止继续测试。
我们没有看到NGINX所能看到的改进程度有几个原因。在他们的测试中,他们使用200个并发连接来请求大小为4MB的文件,这些文件位于旋转磁盘上。旋转磁盘会增加I / O延迟,因此有助于解决延迟的优化会产生更大的影响。
我们也更注重p99(和p999)的性能。有助于平均性能的方法不一定有助于异常值。
最后,在我们的环境中,典型的文件大小要小得多。我们90%的缓存命中率适用于小于60KB的文件。较小的文件意味着更少的阻塞时间(我们通常在2次读取中读取整个文件)。
如果我们查看缓存命中必须执行的磁盘I / O:
// we got a request for https://example.com which has cache key 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// read up to 32KB for the metadata as well as the headers
// done in thread pool if "aio threads" is on
read(fd, buf, 32*1024);32KB不是静态数字,如果标题很小,我们只需要读取4KB(我们不使用直接IO,因此内核四舍五入为4KB)。 open()看起来没什么害处,但它实际上并不是免费的。内核至少需要检查文件是否存在以及调用进程是否有打开它的权限。为此,它必须找到 /cache/prefix/dir/EF/BE/CAFEBEEF的索引点,要做到这一点,它又必须从 /cache/prefix/dir/EF/BE/中查找 CAFEBEEF。长话短说,在最坏的情况下,内核必须执行以下查找:
/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEF
open()与仅完成1的次读取时相比,这次完成了6次 read()的单独读取!幸运的是,大多数时间查找由dentry缓存提供服务,并且不需要访问SSD。但显然 read()在线程池中完成只是图片的一半。
coup degrâce:线程池中的非阻塞open()
于是我修改了NGINX以完成 open()线程池内部的大部分内容,因此它不会阻止事件循环。结果(非阻塞打开和非阻塞读取):
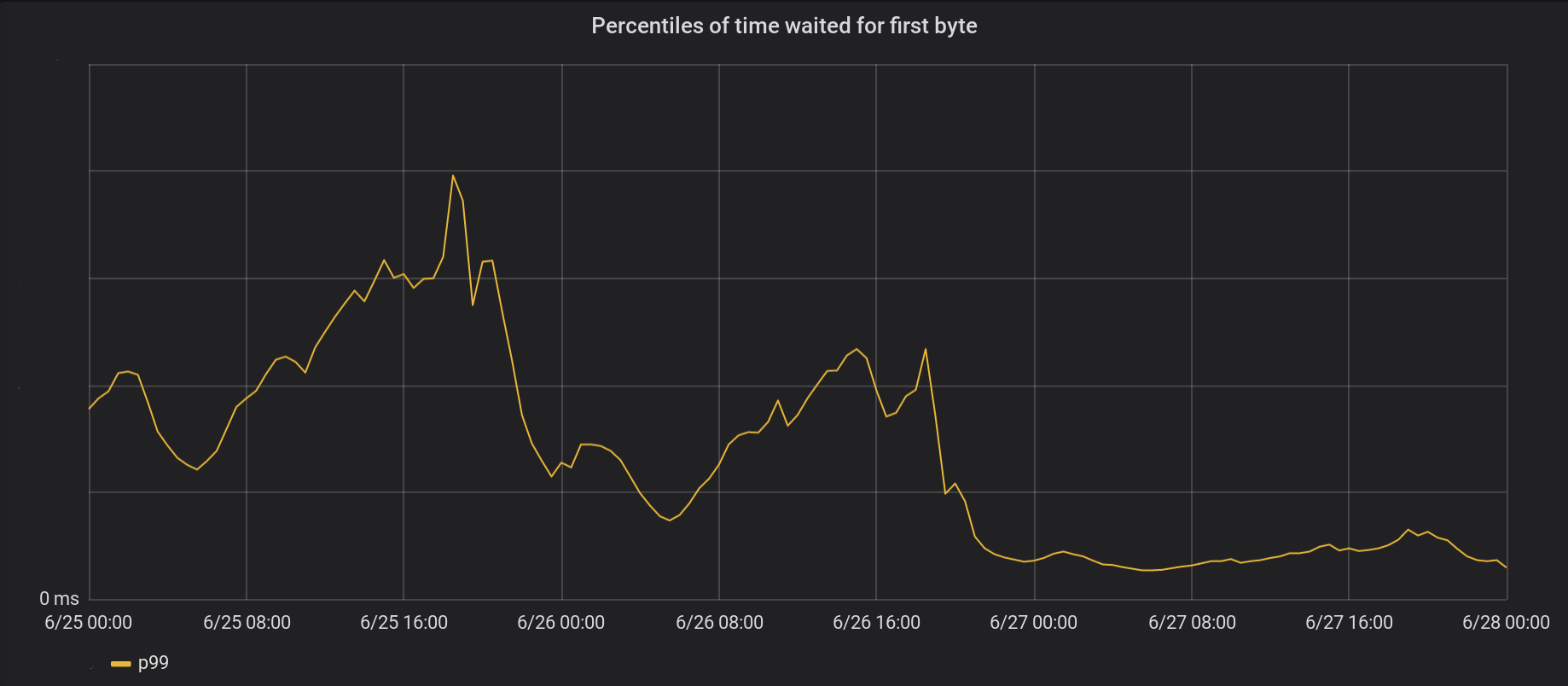
6月26日,我们对我们的5个最繁忙的数据中心进行了更改,紧接着,第二天在全球范围内推出。总体峰值p99 TTFB提高了6倍。实际上,将我们每天处理800万个请求的总时间累加,每天我们能为互联网省去相当于54年的等待时间。
我们已将工作提交给上行。有兴趣的人可以跟进。
我们的事件循环处理仍然不是完全非阻塞的。特别是,当我们第一次缓存文件(包括 open(O_CREAT)和 rename())或执行重新验证更新时,我们仍会遇到阻塞。但是,与缓存命中相比,这些是很少见的。在未来,我们会考虑将这些移出事件循环以进一步改善我们的p99延迟。
结论
NGINX是一个功能强大的平台,但在Linux上扩展极高的I / O负载仍然很难。上行NGINX可以在单独的线程中卸载读取,但从我们的规模来看,我们要做的还有更多。