


El 25 de agosto de 2023, empezamos a observar algunos ataques de inundación HTTP inusualmente voluminosos que afectaban a muchos de nuestros clientes. Nuestro sistema DDoS automatizado detectó y mitigó estos ataques. Sin embargo, no pasó mucho tiempo antes de que empezaran a alcanzar tamaños sin precedentes, hasta alcanzar finalmente un pico de 201 millones de solicitudes por segundo, casi el triple que el mayor ataque registrado hasta ese momento.
Lo más inquietante es que el atacante fuera capaz de generar semejante ataque con una botnet de solo 20 000 máquinas. Hoy en día existen botnets formadas por cientos de miles o millones de máquinas. La web suele recibir solo entre 1000 y 3000 millones de solicitudes por segundo, por eso no parece imposible que utilizando este método se pudiera concentrar el volumen de solicitudes de toda una web en un pequeño número de objetivos.
Detección y mitigación
Se trataba de un vector de ataque novedoso a una escala sin precedentes, pero las soluciones de protección de Cloudflare pudieron mitigar en gran medida los efectos más graves de los ataques. Si bien al principio observamos cierto impacto en el tráfico de los clientes, que afectó aproximadamente al 1 % de las solicitudes durante la oleada inicial de ataques, hoy hemos podido perfeccionar nuestros métodos de mitigación para detener el ataque de cualquier cliente de Cloudflare sin que nuestros sistemas se vean afectados.
Nos dimos cuenta de estos ataques mientras otros dos grandes empresas del sector, Google y AWS, observaban lo mismo. Trabajamos para consolidar los sistemas de Cloudflare y garantizar que, a día de hoy, todos nuestros clientes estén protegidos de este nuevo método de ataque DDoS sin que afecte a ningún cliente. También hemos participado con Google y AWS en una divulgación coordinada del ataque a los proveedores afectados y a los proveedores de infraestructuras críticas.
Este ataque fue posible mediante el abuso de algunas funciones del protocolo HTTP/2 y de detalles de implementación del servidor (para más información, véase CVE-2023-44487). Dado que el ataque aprovecha una deficiencia subyacente en el protocolo HTTP/2, creemos que cualquier proveedor que haya implementado este protocolo será objeto del ataque. Esto incluye todos los servidores web modernos. Nosotros, junto con Google y AWS, hemos revelado el método de ataque a los proveedores de servidores web, que esperamos implementen revisiones. Mientras tanto, la mejor protección es utilizar un servicio de mitigación de DDoS como el de Cloudflare frente a cualquier servidor web o API pública.
Este artículo analiza los detalles del protocolo HTTP/2, la función que explotaron los atacantes para generar estos ataques masivos, y las estrategias de mitigación que adoptamos para garantizar la protección de todos nuestros clientes. Nuestra esperanza es que, al publicar estos detalles, otros servidores y servicios web afectados dispongan de la información que necesitan para aplicar estrategias de mitigación. Y, además, el equipo de estándares del protocolo HTTP/2, así como los equipos que trabajen en futuros estándares web, puedan diseñarlos mejor para evitar este tipo de incidentes.
Detalles del ataque RST
HTTP es el protocolo de aplicación que permite la transferencia de información en la web. La semántica HTTP es común a todas las versiones de HTTP. La arquitectura general, la terminología y los aspectos del protocolo, como los mensajes de solicitud y respuesta, los métodos, los códigos de estado, los campos de encabezado y finalizador, el contenido de los mensajes y mucho más. Cada versión individual de HTTP define cómo se transforma la semántica en un "formato para transmisión" (wire format) para el intercambio a través de Internet. Por ejemplo, un cliente tiene que serializar un mensaje de solicitud en datos binarios y enviarlo, y luego el servidor lo vuelve a analizar en un mensaje que pueda procesar.
HTTP/1.1 utiliza una forma textual de serialización. Los mensajes de solicitud y respuesta se intercambian como una secuencia de caracteres ASCII, enviados a través de una capa de transporte fiable como TCP y utiliza el siguiente formato (donde CRLF significa "retorno de carro" y "salto de línea"):
HTTP-message = start-line CRLF
*( field-line CRLF )
CRLF
[ message-body ]
Por ejemplo, una solicitud GET muy sencilla para https://blog.cloudflare.com/ tendría este aspecto en el formato para transmisión:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Y la respuesta sería la siguiente:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Este formato encapsula los mensajes en la transmisión, lo que significa que es posible utilizar una única conexión TCP para intercambiar varias solicitudes y respuestas. Sin embargo, el formato requiere que cada mensaje se envíe entero. Además, para correlacionar correctamente las solicitudes con las respuestas, se requiere un orden estricto, lo que significa que los mensajes se intercambian en serie y no se pueden multiplexar. Dos solicitudes GET, para https://blog.cloudflare.com/ y https://blog.cloudflare.com/page/2/,, serían:
GET / HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLFGET /page/2/ HTTP/1.1 CRLFHost: blog.cloudflare.comCRLFCRLF
Con las respuestas:
HTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>CRLFHTTP/1.1 200 OK CRLFServer: cloudflareCRLFContent-Length: 100CRLFtext/html; charset=UTF-8CRLFCRLF<100 bytes of data>
Las páginas web requieren interacciones HTTP más complicadas que estos ejemplos. Cuando visites el blog de Cloudflare, tu navegador cargará numerosos scripts, estilos y activos multimedia. Si visitas la página principal utilizando HTTP/1.1 y decides rápidamente ir a la página 2, tu navegador puede elegir entre dos opciones. O bien esperar todas las respuestas en cola para la página que ya no quieres antes de que la página 2 pueda siquiera comenzar, o bien cancelar las solicitudes abiertas cerrando la conexión TCP y abriendo una nueva conexión. Ninguna de estas opciones es muy práctica. Los navegadores tienden a sortear estas limitaciones gestionando un conjunto de conexiones TCP (hasta 6 por host) e implementando una compleja lógica de envío de solicitudes sobre el conjunto.
HTTP/2 aborda muchos de los problemas de HTTP/1.1. Cada mensaje HTTP se serializa en un conjunto de tramas HTTP/2 que tienen tipo, longitud, etiquetas, identificador (Id.) de secuencia y carga malintencionada. El identificador de secuencia deja claro qué bytes de la transmisión corresponden a cada mensaje, lo que permite una multiplexación y concurrencia seguras. Las secuencias son bidireccionales. Los clientes envían tramas y los servidores responden con tramas que utilizan el mismo Id.
En HTTP/2, nuestra solicitud GET de https://blog.cloudflare.comse intercambiaría a través del identificador de secuencia 1. El cliente enviaría una trama HEADERS, y el servidor respondería con una trama HEADERS, seguida de una o más tramas DATA. Las solicitudes del cliente siempre utilizan identificadores de secuencia impares, por lo que las solicitudes posteriores utilizarían identificadores de secuencia 3, 5, etc. Las respuestas se pueden servir en cualquier orden, y se pueden intercalar tramas de distintas secuencias.
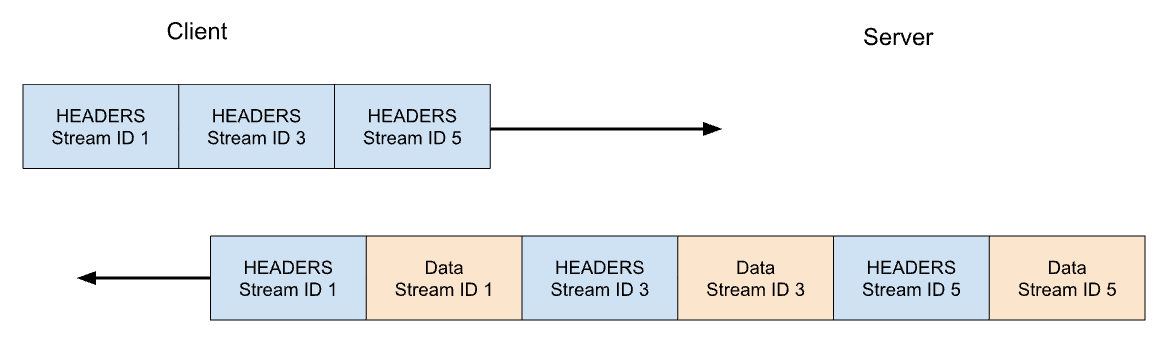
La multiplexación de secuencias y la concurrencia son potentes funciones de HTTP/2. Permiten un uso más eficiente de una única conexión TCP. HTTP/2 optimiza la obtención de recursos, especialmente cuando se combina con la priorización. Por otro lado, facilitar a los clientes el lanzamiento de grandes cantidades de trabajo paralelo puede aumentar el pico de demanda de recursos del servidor en comparación con HTTP/1.1. Este es un vector obvio de denegación de servicio.
Para ofrecer protección, HTTP/2 proporciona una noción de secuencias concurrentes activas máximas. El parámetro SETTINGS_MAX_CONCURRENT_STREAMS permite a un servidor anunciar su límite de concurrencia. Por ejemplo, si el servidor declara un límite de 100, entonces solo pueden estar activas 100 solicitudes en cualquier momento. Si un cliente intenta abrir una secuencia por encima de este límite, el servidor la rechazará mediante una trama RST_STREAM. El rechazo de la secuencia no afecta a las demás secuencias en curso en la conexión.
La realidad es un poco más complicada. Las secuencias tienen un ciclo de vida. A continuación se muestra un diagrama de la máquina de estado de la secuencia HTTP/2. El cliente y el servidor gestionan sus propias vistas del estado de una secuencia. Las tramas HEADERS, DATA y RST_STREAM activan transiciones cuando se envían o reciben. Aunque las vistas del estado de la secuencia son independientes, están sincronizadas.
Las tramas HEADERS y DATA incluyen una etiqueta END_STREAM, que cuando se establece en el valor 1 (verdadero), puede activar una transición de estado.

Examinemos esto con un ejemplo de una solicitud GET que no tiene contenido de mensaje. El cliente envía la solicitud como una trama HEADERS con la etiqueta END_STREAM establecida en 1. El cliente primero pasa la secuencia del estado inactivo al estado abierto, y luego pasa inmediatamente al estado semicerrado. El estado semicerrado del cliente significa que ya no puede enviar tramas HEADERS ni DATA, solo tramas WINDOW_UPDATE, PRIORITY o RST_STREAM. Sin embargo, puede recibir cualquier trama.
Una vez que el servidor recibe y analiza la trama HEADERS, cambia el estado de la secuencia de inactivo a abierto y luego a semicerrado, para que coincida con el cliente. El estado semicerrado del servidor significa que puede enviar cualquier trama, pero solo recibir tramas WINDOW_UPDATE, PRIORITY o RST_STREAM.
La respuesta a la solicitud GET incluye el contenido del mensaje, por lo que el servidor envía una trama HEADERS con la etiqueta END_STREAM establecida en 0, y luego una trama DATA con la etiqueta END_STREAM establecida en 1. La trama DATA marca la transición de la secuencia de semicerrado a cerrado en el servidor. Cuando el cliente la recibe, también pasa a cerrado. Una vez se cierra una secuencia, no se pueden enviar ni recibir tramas.
Aplicando de nuevo este ciclo de vida al contexto de la concurrencia, HTTP/2 establece:
Las secuencias que están en estado "abierto" o en cualquiera de los estados "semicerrado" cuentan para el número máximo de secuencias que un punto final puede abrir. Las secuencias en cualquiera de estos tres estados cuentan para el límite anunciado en el ajuste SETTINGS_MAX_CONCURRENT_STREAMS.
En teoría, el límite de concurrencia es útil. Sin embargo, hay factores prácticos que dificultan su eficacia, de los que hablaremos más adelante en el blog.
Anulación de solicitudes HTTP/2
Antes hemos hablado de la anulación por parte del cliente de solicitudes en curso. El protocolo HTTP/2 admite esta función de una forma mucho más eficaz que HTTP/1.1. En lugar de tener que interrumpir toda la conexión, un cliente puede enviar una trama RST_STREAM para una única secuencia. Esta ventaja indica al servidor que deje de procesar la solicitud y anule la respuesta, lo que libera recursos del servidor y evita malgastar ancho de banda.
Consideremos nuestro ejemplo anterior de tres solicitudes. Esta vez el cliente anula la solicitud en la secuencia 1 después de que se hayan enviado todas las tramas HEADERS. El servidor analiza esta trama RST_STREAM antes de estar preparado para servir la respuesta y, en su lugar, solo responde a las secuencias 3 y 5:
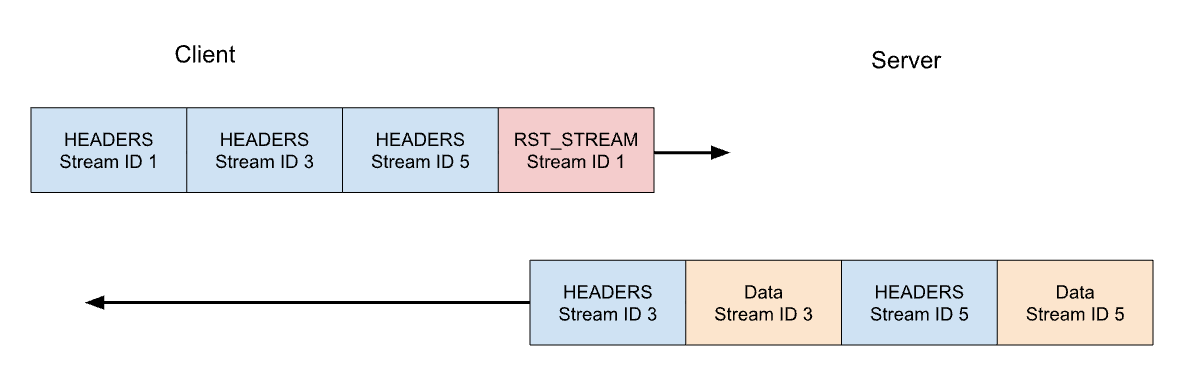
La anulación de solicitudes es una función útil. Por ejemplo, al desplazarse por una página web con varias imágenes, un navegador web puede cancelar las imágenes que quedan fuera de la ventanilla, lo que significa que las imágenes que entran en ella pueden cargarse más rápido. El protocolo HTTP/2 hace que este comportamiento sea mucho más eficiente en comparación con HTTP/1.1.
Una secuencia de solicitud que se anula, pasa rápidamente por el ciclo de vida de la secuencia. La trama HEADERS del cliente con la etiqueta END_STREAM establecida en 1 pasa del estado de inactivo a abierto a semicerrado, luego RST_STREAM marca inmediatamente una transición de semicerrado a cerrado.

Recuerda que solo las secuencias que están en estado abierto o semicerrado contribuyen al límite de concurrencia de la secuencia. Cuando un cliente anula una secuencia, obtiene instantáneamente la capacidad de abrir otra en su lugar, y puede enviar otra solicitud inmediatamente. Este es el quid de la cuestión que permite el funcionamiento de CVE-2023-44487.
Restablecimientos rápidos que conducen a la denegación de servicio
Se puede abusar de la anulación de solicitudes HTTP/2 para restablecer rápidamente un número ilimitado de secuencias. Cuando un servidor HTTP/2 es capaz de procesar las tramas RST_STREAM enviadas por el cliente y cambiar el estado con suficiente rapidez, estos restablecimientos rápidos no causan ningún problema. Los problemas empiezan a surgir cuando se produce algún tipo de retraso o demora en la limpieza. El cliente puede hacer tantas solicitudes que se acumule trabajo atrasado, lo que se traduce en un consumo excesivo de recursos en el servidor.
Una arquitectura común de implementación HTTP consiste en ejecutar un proxy HTTP/2 o un equilibrador de carga delante de otros componentes. Cuando llega una solicitud de un cliente, se envía rápidamente y el trabajo real se realiza como una actividad asíncrona en otro lugar. Esta operación permite al proxy gestionar el tráfico de clientes de forma muy eficiente. Sin embargo, esta separación de preocupaciones puede dificultar que el proxy ordene los trabajos en proceso. Por lo tanto, estas implementaciones son más propensas a tropezar con problemas derivados de los restablecimientos rápidos.
Cuando los proxies inversos de Cloudflare procesan el tráfico entrante de clientes HTTP/2, copian los datos del socket de la conexión en un búfer y procesan esos datos almacenados en búfer en orden. A medida que se lee cada solicitud (tramas HEADERS y DATA), se envía a un servicio ascendente. Cuando se leen tramas RST_STREAM, se elimina el estado local de la solicitud y se notifica al servicio ascendente que la solicitud se ha anulado. Todo el proceso se repite hasta que se consuma todo el búfer. Sin embargo, se puede abusar de esta lógica. Si un cliente malintencionado empieza a enviar una enorme cadena de solicitudes y restablecimientos al inicio de una conexión, nuestros servidores las leerán todas con impaciencia y añadirán tensión a los servidores ascendentes hasta el punto de ser incapaces de procesar ninguna nueva solicitud entrante.
Algo que es importante destacar es que la concurrencia de secuencias por sí sola no puede mitigar el restablecimiento rápido. El cliente puede editar las solicitudes para crear altas tasas de solicitudes, independientemente del valor SETTINGS_MAX_CONCURRENT_STREAMS elegido por el servidor.
Análisis exhaustivo de Rapid Reset
A continuación, mostramos un ejemplo de restablecimiento rápido reproducido utilizando un cliente de prueba de concepto que intenta enviar un total de 1000 solicitudes. He utilizado un servidor estándar sin ningún tipo de medida de mitigación, que escucha en el puerto 443 en un entorno de prueba. El tráfico se examina utilizando Wireshark y se filtra para que solo muestre el tráfico HTTP/2 para mayor claridad. Descarga la interfaz pcap para ver explicación.

Es un poco difícil de ver, porque hay muchas tramas. Podemos ver un resumen rápido con la herramienta Estadísticas > HTTP2 de Wireshark:
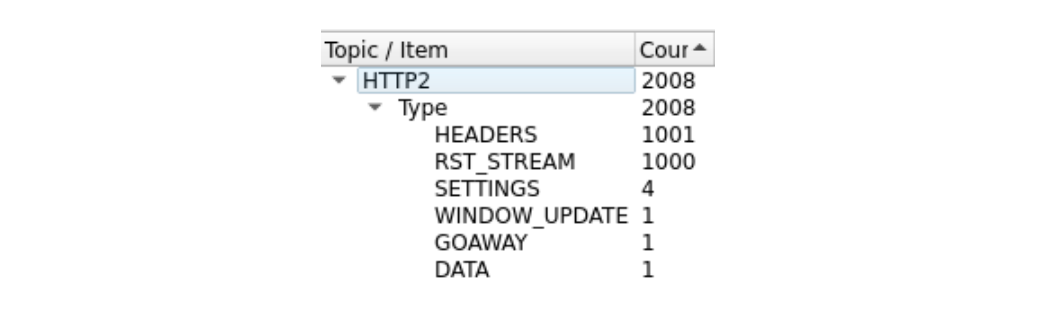
La primera trama de este rastreo, en el paquete 14, es la trama SETTINGS del servidor, que anuncia una concurrencia de secuencia máxima de 100. En el paquete 15, el cliente envía unas cuantas tramas de control y luego empieza a hacer solicitudes que se restablecen rápidamente. La primera trama HEADERS tiene 26 bytes de longitud, todas las tramas HEADERS posteriores tienen solo 9 bytes. Esta diferencia de tamaño se debe a una tecnología de compresión llamada HPACK. En total, el paquete 15 contiene 525 solicitudes, que llegan hasta la secuencia 1051.
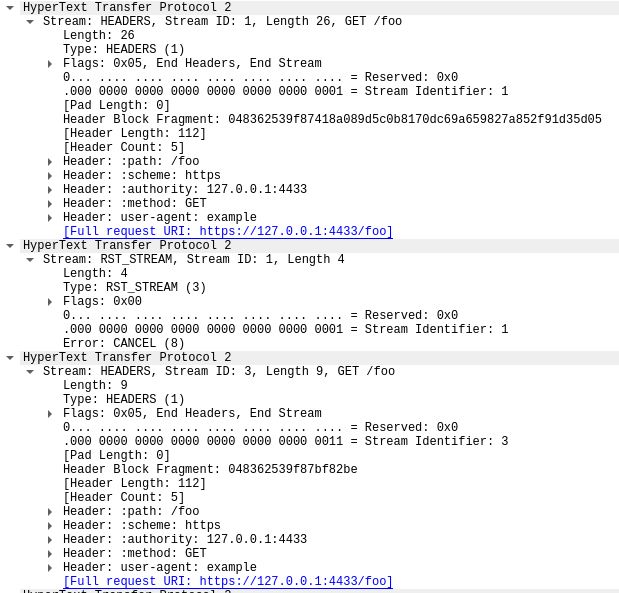
Curiosamente, la trama RST_STREAM para la secuencia 1051 no cabe en el paquete 15, por lo que en el paquete 16 vemos que el servidor envía una respuesta 404. A continuación, en el paquete 17, el cliente sí envía la trama RST_STREAM, antes de pasar a enviar las 475 solicitudes restantes.
Observa que, aunque el servidor anunciaba 100 secuencias simultáneas, los dos paquetes enviados por el cliente enviaban muchas más tramas HEADERS. El cliente no tenía que esperar ningún tráfico de retorno del servidor, solo estaba limitado por el tamaño de los paquetes que podía enviar. No se ven tramas RST_STREAM del servidor en este rastreo, lo que indica que el servidor no observó una violación de secuencia concurrente.
Impacto en los clientes
Como se ha mencionado anteriormente, a medida que se anulan las solicitudes, los servicios ascendentes reciben una notificación y pueden cancelar las solicitudes antes de gastar demasiados recursos en ello. Así fue este ataque, en el que la mayoría de las solicitudes maliciosas nunca se reenviaron a los servidores de origen. Sin embargo, el gran tamaño de estos ataques causó cierto impacto.
En primer lugar, cuando la tasa de solicitudes entrantes alcanzó picos nunca vistos, recibimos informes de un aumento de los niveles de errores 502 que recibían los clientes. Esto ocurrió en nuestros centros de datos más afectados, mientras trabajaban para procesar todas las solicitudes. Aunque nuestra red está diseñada para hacer frente a grandes ataques, esta vulnerabilidad concreta expuso un punto débil de nuestra infraestructura. Profundicemos un poco más en los detalles, centrándonos en cómo se gestionan las solicitudes entrantes cuando llegan a uno de nuestros centros de datos:
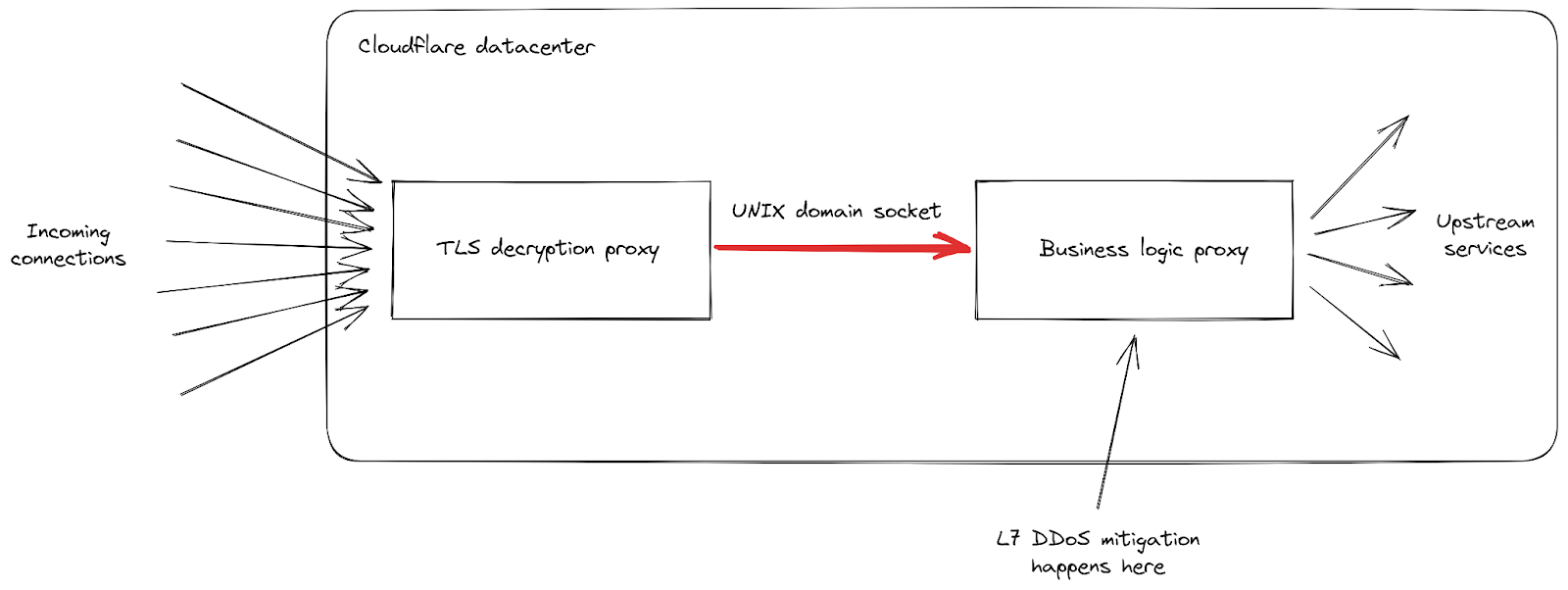
Podemos ver que nuestra infraestructura está compuesta por una cadena de diferentes servidores proxy con distintas responsabilidades. En concreto, cuando un cliente se conecta a Cloudflare para enviar tráfico HTTPS, primero llega a nuestro proxy de descifrado TLS: descifra el tráfico TLS, procesa el tráfico HTTP 1, 2 o 3, y luego lo reenvía a nuestro proxy de "lógica empresarial". Este se encarga de cargar todas las configuraciones para cada cliente, luego enruta las solicitudes correctamente a otros servicios ascendentes, y lo que es más importante en nuestro caso, también se encarga de las funciones de seguridad. Aquí es donde se procesa la mitigación del ataque a la capa 7.
El problema de este vector de ataque es que consigue enviar muchas solicitudes muy rápido en cada conexión. Cada una de ellas tenía que reenviarse al proxy de lógica empresarial antes de que tuviéramos la oportunidad de bloquearla. A medida que el procesamiento de solicitudes superaba la capacidad de nuestro proxy, la canalización que conecta estos dos servicios alcanzó su nivel de saturación en algunos de nuestros servidores.
Cuando esto ocurre, el proxy TLS ya no se puede conectar a su proxy ascendente, por eso algunos clientes recibieron un error básico "502 Bad Gateway" durante los ataques más graves. Es importante señalar que, a partir de hoy, los registros utilizados para crear análisis HTTP también se emiten por nuestro proxy de lógica empresarial. La consecuencia de ello es que estos errores no son visibles en el panel de control de Cloudflare. Nuestros paneles de control internos muestran que alrededor del 1 % de las solicitudes se vieron afectadas durante la oleada inicial de ataques (antes de que implementáramos las medidas de mitigación). En ese momento, se alcanzaron picos de alrededor del 12 % durante unos segundos en el ataque más grave, ocurrido el 29 de agosto. El siguiente gráfico muestra la relación de estos errores durante dos horas mientras ocurría el ataque:

Trabajamos para reducir este número drásticamente en los días siguientes, como se detalla más adelante en este artículo. Gracias a los cambios en nuestra pila y a nuestras medidas de mitigación, que reducen considerablemente el tamaño de estos ataques, este número es, en la práctica, nulo hoy día.

Errores 499 y los desafíos para la concurrencia de secuencias HTTP/2
Otro síntoma notificado por algunos clientes es un aumento de los errores 499. La razón de este inconveniente es un poco diferente y está relacionada con la máxima concurrencia de secuencias en una conexión HTTP/2 detallada anteriormente en este artículo.
Los parámetros de HTTP/2 se intercambian al inicio de una conexión mediante tramas SETTINGS. Si no se recibe un parámetro explícito, se aplican los valores por defecto. Una vez que un cliente establece una conexión HTTP/2, puede esperar las tramas SETTINGS de un servidor (lento) o puede asumir los valores por defecto y empezar a hacer solicitudes (rápido). Para el ajuste SETTINGS_MAX_CONCURRENT_STREAMS, el valor por defecto es ilimitado en la práctica (los identificadores de secuencia utilizan un espacio numérico de 31 bits, y las solicitudes utilizan números impares, por lo que el límite real es 1073741824). La especificación recomienda que un servidor no ofrezca menos de 100 secuencias. Los clientes se suelen inclinar por la velocidad, por lo que no suelen esperar a la configuración del servidor, lo que crea una especie de condición de anticipación. Los clientes arriesgan en cuanto al límite que puede elegir el servidor. Si se equivocan, la solicitud será rechazada y habrá que volver a intentar. El riesgo en las secuencias 1073741824 es ridículo. En su lugar, muchos clientes deciden limitarse a emitir 100 secuencias simultáneas, con la esperanza de que los servidores sigan la recomendación de la especificación. Cuando los servidores eligen algo por debajo de 100, esta apuesta del cliente falla y las secuencias se reinician.
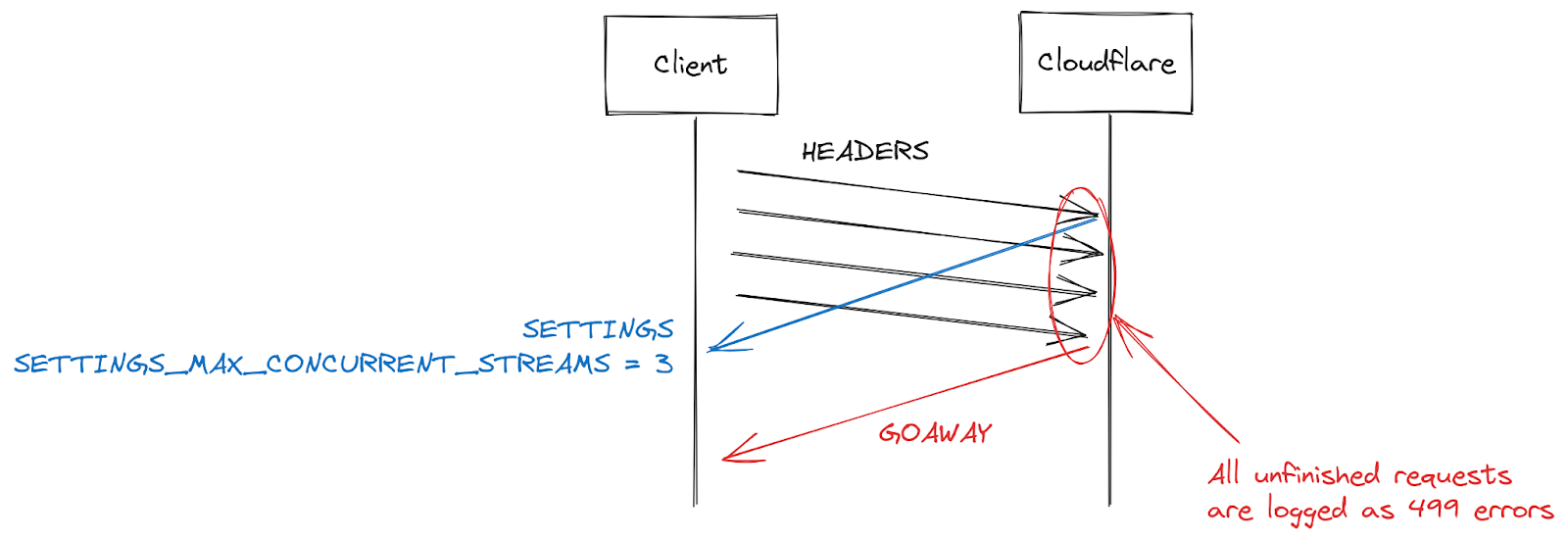
Hay muchas razones por las que un servidor puede restablecer una secuencia más allá de la superación del límite de concurrencia. HTTP/2 es estricto y exige que se cierre una secuencia cuando se produzcan errores de análisis sintáctico o lógicos. En 2019, Cloudflare desarrolló varias medidas de mitigación en respuesta a las vulnerabilidades DoS de HTTP/2. Varias de esas vulnerabilidades obedecían a un mal comportamiento del cliente, que llevaba al servidor a reiniciar una secuencia. Una estrategia muy eficaz para restringir a esos clientes consiste en contar el número de restablecimientos del servidor durante una conexión y, cuando supera algún valor umbral, cerrar la conexión con una trama GOAWAY. Los clientes legítimos pueden cometer uno o dos errores en una conexión y eso es aceptable. Un cliente que cometa demasiados errores probablemente tenga un problema o sea malintencionado, por lo que el cierre de la conexión aborda ambos casos.
Al responder a los ataques DoS habilitados por CVE-2023-44487, Cloudflare redujo la concurrencia máxima de secuencias a 64. Antes de realizar este cambio, no éramos conscientes de que los clientes no esperan a la trama SETTINGS y, en su lugar, asumen una concurrencia de 100. En efecto, algunas páginas web, como una galería de imágenes, hacen que un navegador envíe 100 solicitudes inmediatamente al inicio de una conexión. Por desgracia, las 36 secuencias que superaban nuestro límite necesitaban restablecerse, lo que activó nuestras medidas de mitigación de recuento. Esta operación implicaba cerrar las conexiones de los clientes legítimos, lo que provocaba un fallo total en la carga de la página. En cuanto nos dimos cuenta de este problema de interoperabilidad, cambiamos la concurrencia máxima de secuencias a 100.
Respuesta de Cloudflare
En 2019 se revelaron varias vulnerabilidades DoS relacionadas con implementaciones de HTTP/2. Cloudflare desarrolló e implementó una serie de detecciones y medidas de mitigación en respuesta. CVE-2023-44487 es una manifestación diferente de la vulnerabilidad HTTP/2. Sin embargo, para mitigarla pudimos ampliar las protecciones existentes para supervisar las tramas RST_STREAM enviadas por el cliente y cerrar las conexiones cuando se utilizan con fines abusivos. Los usos legítimos de RST_STREAM por parte del cliente no se ven afectados.
Además de una solución directa, hemos implementado varias mejoras en el código de procesamiento de tramas y envío de solicitudes HTTP/2 del servidor. Además, hemos mejorado las colas y la programación del servidor de lógica empresarial para reducir el trabajo innecesario y mejorar la capacidad de respuesta de la anulación. En conjunto, estos avances disminuyen el impacto de varios patrones potenciales de abuso, además de dar más espacio al servidor para procesar las solicitudes antes de que pueda saturarse.
Mitigación previa de los ataques
Cloudflare ya disponía de sistemas para mitigar eficazmente los ataques muy grandes con métodos menos costosos. Uno de ellos se llama "IP Jail". En los ataques hipervolumétricos, este sistema recoge las direcciones IP de los clientes que participan en el ataque e impide que se conecten a la propiedad que es objeto de ataque, bien a nivel de IP, bien en nuestro proxy TLS. Sin embargo, este sistema necesita unos segundos para ser plenamente eficaz. Durante estos preciados segundos, los servidores de origen ya están protegidos, pero nuestra infraestructura aún tiene que aceptar todas las solicitudes HTTP. Como esta nueva botnet no tiene un periodo de inicialización en la práctica, necesitamos poder neutralizar los ataques antes de que se conviertan en un problema.
Para conseguirlo, hemos ampliado el sistema de IP Jail para proteger toda nuestra infraestructura. Una vez que se "bloquea" una dirección IP, no solo se bloquea su conexión a la propiedad que está siendo blanco de ataque, sino que también prohibimos que las direcciones IP correspondientes utilicen HTTP/2 a cualquier otro dominio en Cloudflare durante un tiempo. Como tales abusos de protocolo no son posibles utilizando HTTP/1.x, este enfoque limita la capacidad del atacante para ejecutar grandes ataques, mientras que cualquier cliente legítimo que comparta la misma dirección IP solo percibirá un leve impacto en rendimiento durante ese tiempo. Las medidas de mitigación basadas en la IP son una herramienta deficiente, por eso debemos ser muy prudentes al utilizarlas a esa escala, y tratar de evitar los falsos positivos en la medida de lo posible. Además, la vida útil de una IP determinada en una botnet suele ser corta, por lo que cualquier medida de mitigación a largo plazo probablemente hará más mal que bien. El siguiente gráfico muestra la rotación de direcciones IP en los ataques que presenciamos:
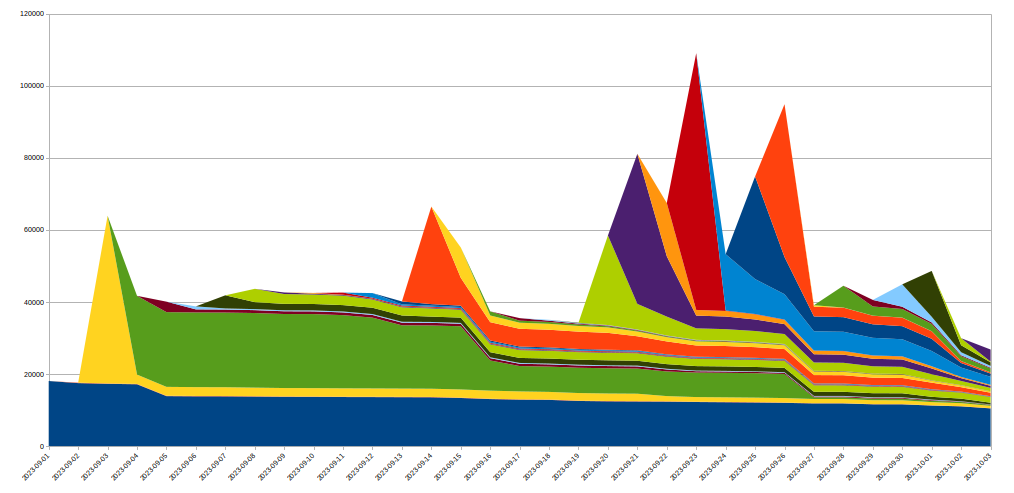
Como podemos observar, muchas direcciones IP nuevas detectadas en un día determinado desaparecen muy rápido después.
Como todas estas acciones ocurren en nuestro proxy TLS al principio de nuestra canalización HTTPS, se ahorran considerables recursos en comparación con nuestro sistema de mitigación de capa 7 habitual. Esto nos ha permitido aguantar estos ataques mucho mejor y ahora el número de errores 502 aleatorios causados por estas botnets se ha reducido a cero.
Mejoras en la observabilidad
Otro frente en el que estamos implementando cambios es la observabilidad. La devolución de errores a los clientes sin que sean visibles en los análisis de los clientes es insatisfactorio. Afortunadamente, hay un proyecto en marcha para revisar estos sistemas desde mucho antes de estos ataques. Con el tiempo, permitirá que cada servicio de nuestra infraestructura registre sus propios datos, en lugar de depender de nuestro proxy de lógica empresarial para consolidar y emitir datos de registro. Este incidente subrayó la importancia de este trabajo, y estamos redoblando nuestros esfuerzos.
También estamos trabajando en mejorar el registro a nivel de conexión para que nos permita detectar estos abusos de protocolo mucho más rápido y así mejorar nuestras capacidades de mitigación de ataques DDoS.
Conclusión
Aunque este ha sido el último ataque que ha batido récords, sabemos que no será el último. Conforme los ataques se vuelven más sofisticados, Cloudflare trabaja sin descanso para identificar proactivamente nuevas amenazas, implementando contramedidas en nuestra red global para que nuestros millones de clientes estén protegidos de forma inmediata y automática.
Cloudflare ofrece protección DDoS gratuita e ilimitada a todos nuestros clientes desde 2017. Además, ofrecemos una serie de funciones de seguridad adicionales que se adaptan a las necesidades de organizaciones de todos los tamaños. Ponte en contacto con nosotros si no estás seguro de estar protegido o quieres saber cómo puedes estarlo].