
This is a Korean translation of a existing post by Marek Majkowski, translated by Junho Choi.
사내에서 DDoS 대응팀은 종종 "패킷 버리는 사람들"이라 불립니다. 다른 팀이 우리 네트워크를 통해 지나가는 트래픽으로 스마트한 일을 하며 신나할 때 우리는 그걸 버리는 여러가지 방법을 찾아가며 즐거워 합니다.

CC BY-SA 2.0 image by Brian Evans
DDoS 공격을 견뎌내기 위해서는 빠르게 패킷을 버릴 수 있는 능력이 매우 중요합니다.
쉽게 들리겠지만 서버에 도달한 패킷을 버리는 것은 여러 단계에서 가능합니다. 각 기법은 장점과 한계점이 있습니다. 이 블로그 글에서는 지금까지 시도해 본 기법들을 모두 정리해 보도록 하겠습니다.
테스트 벤치마크
각 기법의 상대적인 성능을 시각화하기 위해서 먼저 숫자를 볼 것입니다. 벤치마크는 합성 테스트이므로 실제 숫자와는 일부 차이가 있을 수 있습니다. 테스트를 위해서는 10Gbps 네트워크 카드가 달린 인텔 서버를 사용할 것입니다. 하드웨어가 아니라 운영체제의 한계를 보여주기 위한 테스트이므로 하드웨어의 상세 사항은 적지 않겠습니다.
테스트 설정은 다음과 같습니다:
- 작은 크기의 UDP 패킷을 14Mpps (Mpps = 초당 백만 패킷) 에 도달하도록 대량으로 전송
- 이 트래픽은 테스트 서버의 단일 CPU에 전달되도록 함
- 단일 CPU에서 커널에 의해 처리되는 패킷의 개수를 측정
테스트는 사용자 공간 어플리케이션의 속도나 패킷 처리 속도를 최대화하려는 것이 아니라 커널의 병목 지점을 알고자 하는 것입니다.
합성 트래픽은 conntrack에 최대한의 부하를 주도록 준비되었습니다 - 임의의 소스 IP와 포트 필드를 사용합니다. tcpdump는 다음과 같이 보일 것입니다:
$ tcpdump -ni vlan100 -c 10 -t udp and dst port 1234
IP 198.18.40.55.32059 > 198.18.0.12.1234: UDP, length 16
IP 198.18.51.16.30852 > 198.18.0.12.1234: UDP, length 16
IP 198.18.35.51.61823 > 198.18.0.12.1234: UDP, length 16
IP 198.18.44.42.30344 > 198.18.0.12.1234: UDP, length 16
IP 198.18.106.227.38592 > 198.18.0.12.1234: UDP, length 16
IP 198.18.48.67.19533 > 198.18.0.12.1234: UDP, length 16
IP 198.18.49.38.40566 > 198.18.0.12.1234: UDP, length 16
IP 198.18.50.73.22989 > 198.18.0.12.1234: UDP, length 16
IP 198.18.43.204.37895 > 198.18.0.12.1234: UDP, length 16
IP 198.18.104.128.1543 > 198.18.0.12.1234: UDP, length 16
타겟 서버에서는 모든 패킷이 단 하나의 RX 큐로만 전송 될 것이므로 CPU를 하나만 사용하게 됩니다. 하드웨어 흐름 제어를 통해서 다음과 같이 설정 합니다:
ethtool -N ext0 flow-type udp4 dst-ip 198.18.0.12 dst-port 1234 action 2
벤치마크는 항상 어렵습니다. 테스트를 준비하는 동안 활성화된 생 소켓은 성능 저하를 일으킨다는 점을 발견하였습니다. 나중에 생각해 보면 당연한 것이지만 놓치기 쉽습니다. 테스트를 시작하기 전에 동작 중인 tcpdump 프로세스가 없는지 확인하도록 합시다. 다음 명령으로 활성화되어 있는 잘못된 프로세스를 찾을 수 있습니다:
$ ss -A raw,packet_raw -l -p|cat
Netid State Recv-Q Send-Q Local Address:Port
p_raw UNCONN 525157 0 *:vlan100 users:(("tcpdump",pid=23683,fd=3))
마지막으로 서버의 Intel Turbo Boost 기능을 끄도록 합니다.
echo 1 | sudo tee /sys/devices/system/cpu/intel_pstate/no_turbo
Turbo Boost 기능은 성능을 20% 정도 늘려 주는 좋은 기능이지만 이 테스트에서는 표준 편차를 매우 나쁘게 합니다. 이 기능이 활성화되어 있으면 성능 지표에서 ±1.5% 의 편차를 갖습니다만 끄고 나면 적절한 숫자인 0.25%가 됩니다.
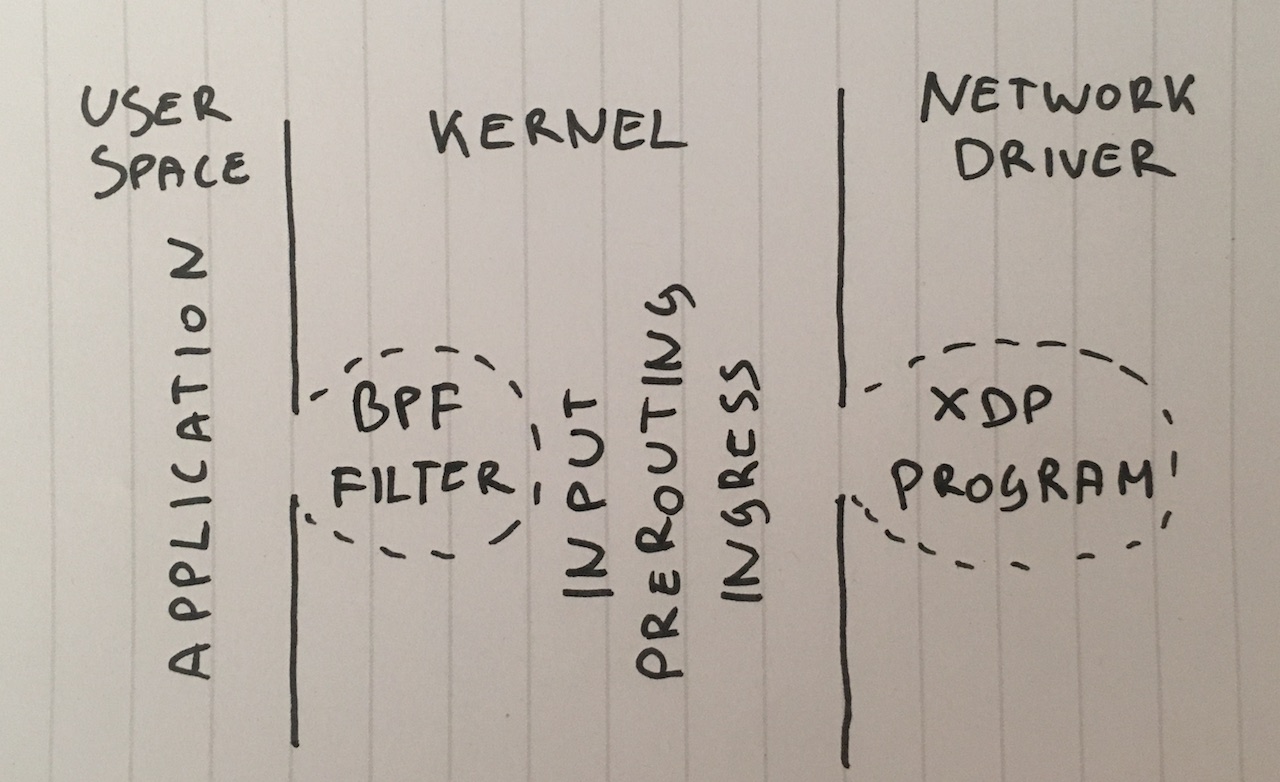
1단계: 어플리케이션에서 패킷 버리기
패킷이 어플리케이션에 전달 되면 사용자 공간 코드에서 버리는 것부터 시작해 봅시다. 테스트 셋업을 위해서 iptables가 성능에 영향이 없는지 확인합니다:
iptables -I PREROUTING -t mangle -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
iptables -I INPUT -t filter -d 198.18.0.12 -p udp --dport 1234 -j ACCEPT
어플리케이션 코드는 데이터를 받아서 사용자 공간에서 버리는 간단한 반복문입니다.
s = socket.socket(AF_INET, SOCK_DGRAM)
s.bind(("0.0.0.0", 1234))
while True:
s.recvmmsg([...])
코드가 준비되었으면 실행해 봅시다:
$ ./dropping-packets/recvmmsg-loop
packets=171261 bytes=1940176
ethtool과 우리가 만든 간단한 mmwatch 도구를 사용해서 측정한 것 처럼 이 테스트는 하드웨어 수신 큐에서 겨우 175kpps만 수신하고 있습니다:
$ mmwatch 'ethtool -S ext0|grep rx_2'
rx2_packets: 174.0k/s
하드웨어는 기술적으로 케이블에서 14Mpps 로 수신하고 있지만 커널 작업을 수행하는 하나의 CPU가 관리하는 단일 RX 큐에 모두 보내는 것은 불가능합니다. mpstat으로 확인해 볼 수 있습니다:
$ watch 'mpstat -u -I SUM -P ALL 1 1|egrep -v Aver'
01:32:05 PM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:32:06 PM 0 0.00 0.00 0.00 2.94 0.00 3.92 0.00 0.00 0.00 93.14
01:32:06 PM 1 2.17 0.00 27.17 0.00 0.00 0.00 0.00 0.00 0.00 70.65
01:32:06 PM 2 0.00 0.00 0.00 0.00 0.00 100.00 0.00 0.00 0.00 0.00
01:32:06 PM 3 0.95 0.00 1.90 0.95 0.00 3.81 0.00 0.00 0.00 92.38
CPU #1 은 시스템 27% + 사용자 공간 2%를 사용하고 있으므로 어플리케이션 코드가 병목이 아니라는 것을 확인할 수 있습니다만 CPU #2의 SOFTIRQ는 자원을 100% 사용하고 있습니다.
다른 이야기지만 recvmmsg(2)를 사용하는 것은 중요합니다. Spectre대응이 된 커널에서 시스템 콜은 더 무겁기 때문인데, 우리의 경우 커널 4.14에 KPTI와 retpoline를 사용하고 있습니다:
$ tail -n +1 /sys/devices/system/cpu/vulnerabilities/*
==> /sys/devices/system/cpu/vulnerabilities/meltdown <==
Mitigation: PTI
==> /sys/devices/system/cpu/vulnerabilities/spectre_v1 <==
Mitigation: __user pointer sanitization
==> /sys/devices/system/cpu/vulnerabilities/spectre_v2 <==
Mitigation: Full generic retpoline, IBPB, IBRS_FW
2단계: conntrack의 부하
이 테스트는 임의의 소스 IP와 포트를 선택해서 conntrack 계층에 부하를 주도록 설계되어 있습니다. conntrack 엔트리의 갯수를 보면 알 수 있는데, 테스트 도중에 이미 최대값에 도달해 있는 것을 볼 수 있습니다:
$ conntrack -C
2095202
$ sysctl net.netfilter.nf_conntrack_max
net.netfilter.nf_conntrack_max = 2097152
dmesg에서도 conntrack이 오류 메시지를 내고 있는 것을 볼 수 있습니다:
[4029612.456673] nf_conntrack: nf_conntrack: table full, dropping packet
[4029612.465787] nf_conntrack: nf_conntrack: table full, dropping packet
[4029617.175957] net_ratelimit: 5731 callbacks suppressed
속도를 올리기 위해 이 기능을 끄도록 합니다:
iptables -t raw -I PREROUTING -d 198.18.0.12 -p udp -m udp --dport 1234 -j NOTRACK
그리고 테스트를 다시 돌려 봅시다:
$ ./dropping-packets/recvmmsg-loop
packets=331008 bytes=5296128
이것만으로 어플리케이션 수신 성능이 333kbps로 올라 갔습니다. 만세!
PS. SO_BUSY_POLL 을 사용하면 470kpps로 올릴 수 있습니다만 이번에 다루지는 않도록 하겠습니다.
3단계: 소켓에서 BPF로 버리기
더 나아가서, 왜 패킷을 사용자 공간까지 전달해야 할까요? 많이 사용되지는 않지만 기존의 BPF필터를 setsockopt(SO_ATTACH_FILTER)를 사용하여 SOCK_DGRAM 소켓에 붙일 수 있는데 이렇게 하면 커널 공간에서 패킷을 버리는 필터를 프로그래밍할 수 있습니다.
코드는 여기에 있습니다. 실행해 보도록 합니다:
$ ./bpf-drop
packets=0 bytes=0
BPF(기존의 것과 확장 eBPF는 비슷한 성능을 갖습니다)로 버리게 되면 대략 512kpps를 처리할 수 있습니다. BPF필터는 소프트웨어 인터럽트 모드에 있는 동안 패킷을 버리게 되므로 사용자 공간 어플리케이션을 깨우기 위해 필요한 CPU가 절약됩니다.
4단계: 라우팅 후에 iptables DROP
다음 단계로 다음과 같은 규칙을 추가해서 iptables 방화벽의 INPUT 체인에서 패킷을 버리도록 합니다:
iptables -I INPUT -d 198.18.0.12 -p udp --dport 1234 -j DROP
conntrack을 이미 -j NOTRACK으로 사용하지 않도록 했다는 점을 기억합시다. 이 두 규칙을 사용해서 608kpps에 도달하였습니다.
다음은 iptables 카운터의 숫자입니다:
$ mmwatch 'iptables -L -v -n -x | head'
Chain INPUT (policy DROP 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination
605.9k/s 26.7m/s DROP udp -- * * 0.0.0.0/0 198.18.0.12 udp dpt:1234
600kpps도 나쁘지 않습니다만 더 잘 할 수 있습니다!
5단계: PREROUTING에서 iptables DROP
더 빠른 기법은 라우팅되기 전에 패킷을 버리는 것입니다. 다음 규칙을 사용하도록 합니다:
iptables -I PREROUTING -t raw -d 198.18.0.12 -p udp --dport 1234 -j DROP
이렇게 하면 무려 1.688Mpps를 얻게 됩니다.
이것으로 성능이 매우 향상 됩니다만 이유는 잘 이해되지 않습니다. 아마도 라우팅 계층이 비정상적으로 복잡하거나 서버 설정의 버그로 생각이 됩니다.
어떤 경우에도 iptables의 raw 테이블에 추가하는 것이 매우 빠릅니다.
6단계: CONNTRACK이전에 nftables DROP
요즘 iptables는 구식으로 여겨지고 있습니다. 새로운 유행은 nftables입니다. 왜 nftables가 더 나은지에 대해서는 기술적인 설명 비디오을 보기 바랍니다. nftables는 오래된 iptables보다 여러가지 이유에서 더 빠릅니다만 그 중의 한가지 소문은 retpolines (간접 점프를 예측하지 않음) 기능이 iptables의 성능을 크게 약화시킨다는 것입니다.
이 글은 nftables와 iptables의 속도 비교가 아니므로, 생각해 볼 수 있는 가장 빠른 패킷 버리기만을 시도해 보도록 합니다:
nft add table netdev filter
nft -- add chain netdev filter input { type filter hook ingress device vlan100 priority -500 \; policy accept \; }
nft add rule netdev filter input ip daddr 198.18.0.0/24 udp dport 1234 counter drop
nft add rule netdev filter input ip6 daddr fd00::/64 udp dport 1234 counter drop
카운터는 다음의 명령을 통해 볼 수 있습니다:
$ mmwatch 'nft --handle list chain netdev filter input'
table netdev filter {
chain input {
type filter hook ingress device vlan100 priority -500; policy accept;
ip daddr 198.18.0.0/24 udp dport 1234 counter packets 1.6m/s bytes 69.6m/s drop # handle 2
ip6 daddr fd00::/64 udp dport 1234 counter packets 0 bytes 0 drop # handle 3
}
}
nftables의 "ingress" 후크는 약 1.53mpps를 달성하였습니다. 이것은 iptables의 PREROUTING 계층보다 약간 느린 것입니다. 이건 잘 이해되지 않는데 기술적으로 "ingress"는 PREROUTING 이전에 처리 되므로 더 빨라야 하기 때문입니다.
이 테스트에서 nftables는 iptables보다 아주 약간 느렸습니다. 그래도 nftables가 더 나을 겁니다. :P
7단계: tc ingress 처리에서 DROP
약간 의외의 사실은 tc (traffic control) ingress 후크는 PREROUTING보다도 이전에 실행된다는 것입니다. tc는 기본적인 규칙에 기반해서 패킷을 선택 가능하고 심지어 버릴 수도(action drop) 있습니다. 문법은 다소 깔끔하지 않으므로 이 스크립트를 이용해서 설정하는 것을 권장합니다. 약간 복잡한 tc 규칙 설정이 필요한데 명령행으로는 다음과 같습니다:
tc qdisc add dev vlan100 ingress
tc filter add dev vlan100 parent ffff: prio 4 protocol ip u32 match ip protocol 17 0xff match ip dport 1234 0xffff match ip dst 198.18.0.0/24 flowid 1:1 action drop
tc filter add dev vlan100 parent ffff: protocol ipv6 u32 match ip6 dport 1234 0xffff match ip6 dst fd00::/64 flowid 1:1 action drop
다음과 같이 확인 합니다:
$ mmwatch 'tc -s filter show dev vlan100 ingress'
filter parent ffff: protocol ip pref 4 u32
filter parent ffff: protocol ip pref 4 u32 fh 800: ht divisor 1
filter parent ffff: protocol ip pref 4 u32 fh 800::800 order 2048 key ht 800 bkt 0 flowid 1:1 (rule hit 1.8m/s success 1.8m/s)
match 00110000/00ff0000 at 8 (success 1.8m/s )
match 000004d2/0000ffff at 20 (success 1.8m/s )
match c612000c/ffffffff at 16 (success 1.8m/s )
action order 1: gact action drop
random type none pass val 0
index 1 ref 1 bind 1 installed 1.0/s sec
Action statistics:
Sent 79.7m/s bytes 1.8m/s pkt (dropped 1.8m/s, overlimits 0 requeues 0)
backlog 0b 0p requeues 0
tc ingress 후크의 u32 매칭을 하면 단일 CPU에서 1.8mpps로 버릴 수 있게 되었습니다. 이것 멋지네요!
하지만 더 빠를 수 있습니다...
8단계: XDP_DROP
마지막으로 최종 병기는 XDP - eXpress Data Path입니다.
XDP를 사용하면 네트워크 드라이버 수준에서 eBPF코드를 실행할 수 있습니다. 더 중요한 것은 이 단계는 skbuff 메모리 할당 이전에 일어나므로 매우 빠르게 수행 됩니다.
일반적으로 XDP프로젝트는 두 가지로 구성 됩니다.
- 커널 문맥으로 읽어들여지는 eBPF 코드
- 코드를 지정한 네트워크 카드에 적재하고 관리하는 사용자 공간 로더
로더를 작성하는 건 꽤 어려우므로 그 대신에 새로 나온 iproute2 기능을 이용해서 코드를 간단하게 적재하도록 하겠습니다:
ip link set dev ext0 xdp obj xdp-drop-ebpf.o
짜잔!
적재된 eBPF XDP 프로그램의 소스 코드는 여기서 구할 수 있습니다. 이 프로그램은 IP 패킷을 파싱해서 IP 패킷, UDP 패킷, 지정된 서브넷과 포트의 조건에 맞는 패킷을 찾습니다:
if (h_proto == htons(ETH_P_IP)) {
if (iph->protocol == IPPROTO_UDP
&& (htonl(iph->daddr) & 0xFFFFFF00) == 0xC6120000 // 198.18.0.0/24
&& udph->dest == htons(1234)) {
return XDP_DROP;
}
}
XDP프로그램은 BPF 바이트코드를 생성하도록 최근의 clang으로 컴파일해야 합니다. 컴파일 후에 XDP프로그램을 올리고 확인할 수 있습니다:
$ ip link show dev ext0
4: ext0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 xdp qdisc fq state UP mode DEFAULT group default qlen 1000
link/ether 24:8a:07:8a:59:8e brd ff:ff:ff:ff:ff:ff
prog/xdp id 5 tag aedc195cc0471f51 jited
이제 ethtool -S로 네트워크 카드의 통계를 보도록 합니다:
$ mmwatch 'ethtool -S ext0|egrep "rx"|egrep -v ": 0"|egrep -v "cache|csum"'
rx_out_of_buffer: 4.4m/s
rx_xdp_drop: 10.1m/s
rx2_xdp_drop: 10.1m/s
와! XDP를 이용하면 단일 CPU에서 초당 천만개의 패킷을 버릴 수 있습니다.

CC BY-SA 2.0 image by Andrew Filer
요약
IPv4와 IPv6 두가지를 테스트해서 다음 차트로 요약 하였습니다:
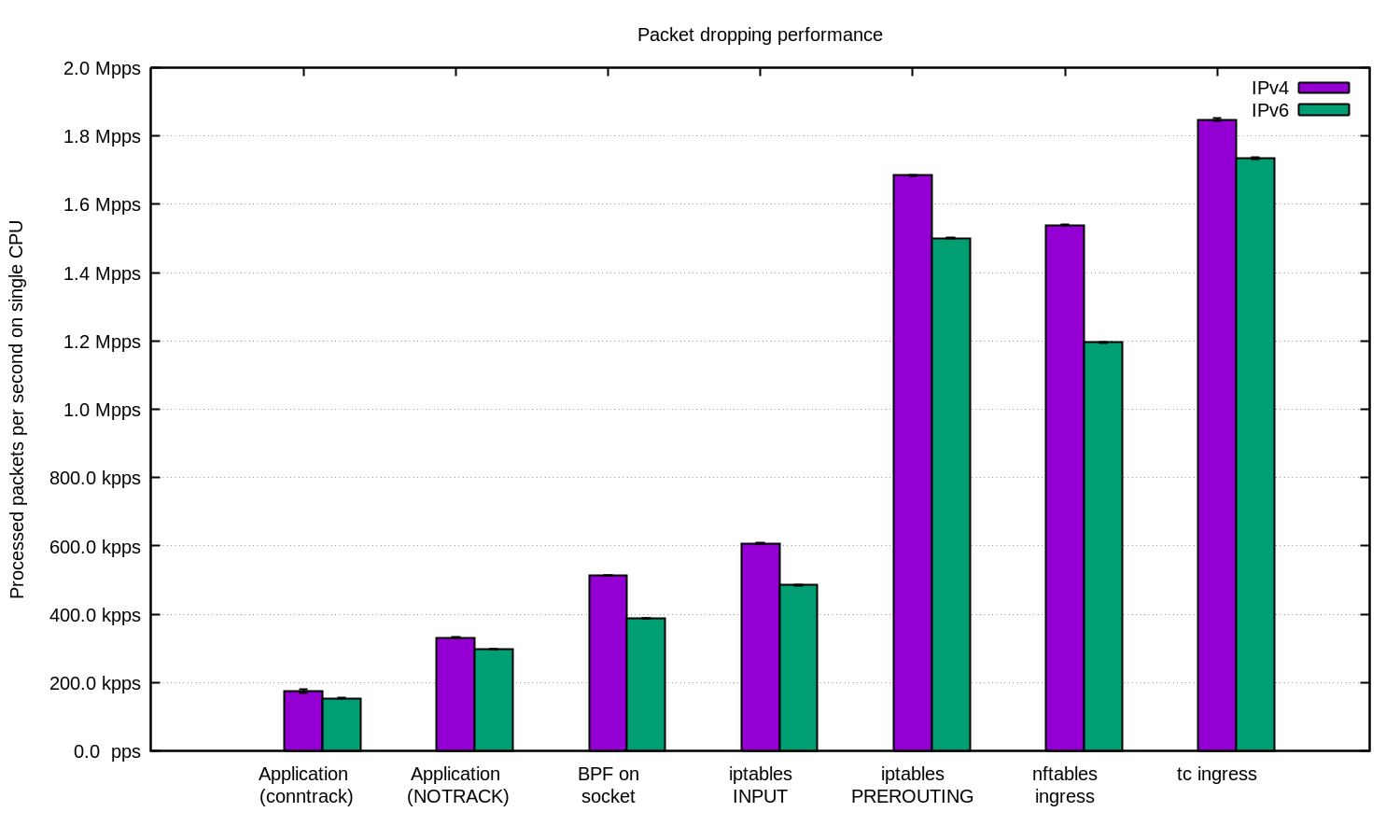
IPv6 설정이 일반적으로 약간 낮은 성능을 보여 줍니다. IPv6 패킷이 약간 더 크므로 일부 성능 차이는 불가피하다는 점을 기억하도록 합시다.
리눅스에는 패킷을 필터링하기 위한 여러가지 방법이 있는데 각각은 서로 다른 성능 및 사용의 편의성이 다릅니다.
DDoS 방어 목적을 위해서는 사용자 공간에서 처리해서 어플리케이션에서 패킷을 수신하는 것 만으로 충분할 수 있습니다. 적절히 튜닝된 어플리케이션은 꽤 괜찮은 숫자를 보여 줍니다.
임의 또는 조작된 소스 IP의 DDoS공격의 경우 conntrack을 끄면 성능을 더 얻을 수 있습니다. 하지만 conntrack이 방어에 매우 유용한 공격들이 있다는 점도 주의하세요.
다른 경우에는 리눅스 방화벽을 DDoS 방어 파이프라인에 통합하는 것도 괜찮을 수 있습니다. 이런 경우 filter 테이블 보다 매우 더 빠른 -t raw PREROUTING 계층에서 대응하도록 해 주세요.
더 큰 규모의 경우 XDP를 이용할 수 있습니다. 이건 정말 강력합니다. 위 차트에 XDP를 포함하면 다음과 같습니다:
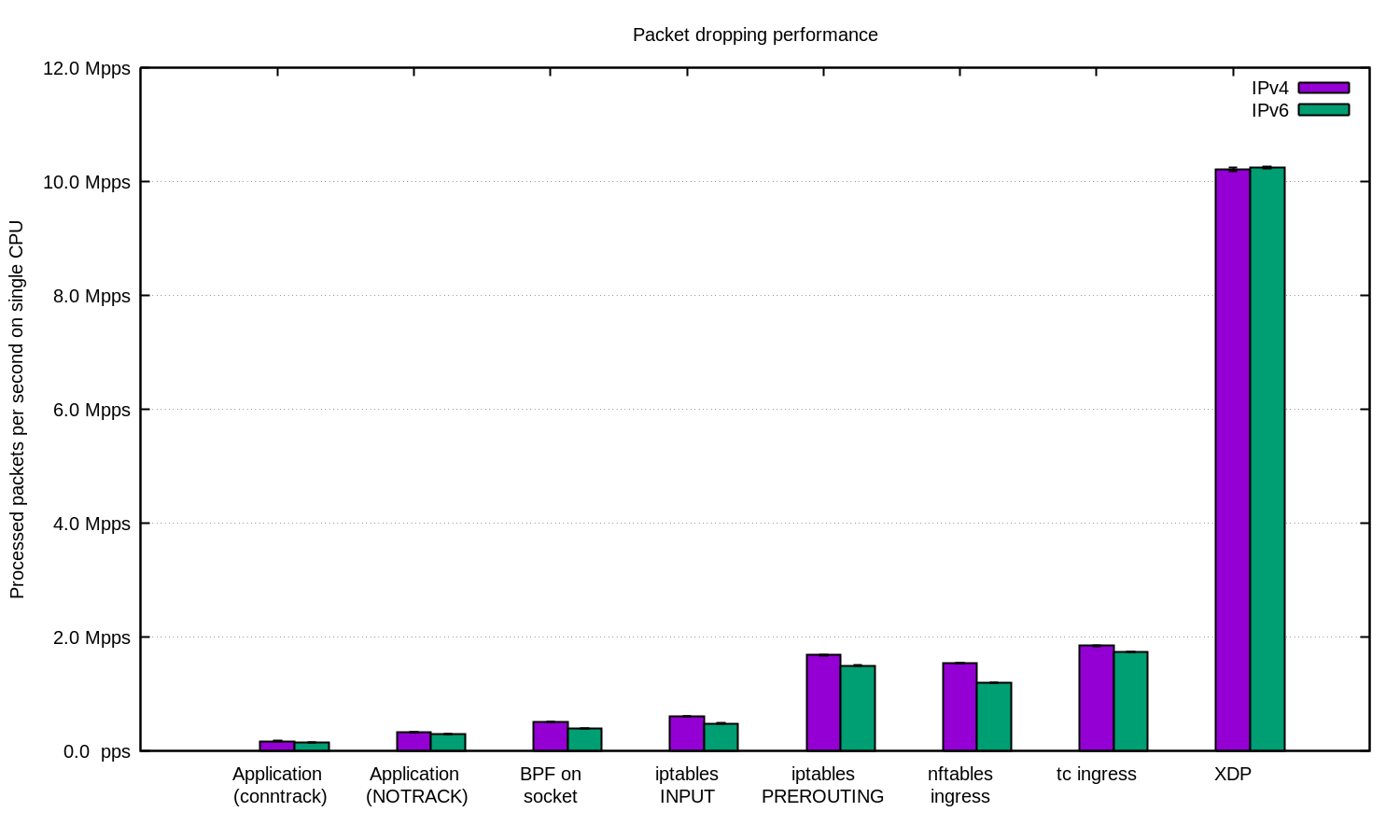
이 숫자를 재현해 보고자 한다면 문서로 잘 정리된 README를 읽어 보세요.
여기 Cloudflare에서는 이런 기법을 거의 모두 사용하고 있습니다. 사용자 공간의 트릭 중 일부는 어플리케이션에서 이용하고 있습니다. iptables 계층은 Gatebot DDoS 파이프라인에서 관리하고 있습니다. 마지막으로 기존의 독자적인 커널 오프로드 솔루션을 XDP로 대체하는 작업을 하고 있습니다.
패킷을 더 버리는 것을 돕고 싶다고요? 패킷 버리기, 시스템 엔지어링 등 많은 분야에서 채용 중입니다!
이 작업을 도와주신 Jesper Dangaard Brouer에게 특별히 감사 드립니다.