


Cloudflareは現在、すべてのAPIエンドポイントを自動的に検出し、すべてのAPI Gatewayのお客様に対し、APIスキーマを学習します。お客様はこれらの新機能を使用することで、既存のAPIに関する情報がほとんどない場合でも、APIエンドポイントに有用なセキュリティモデルを適用することができます。
APIを保護するための最初のステップは、APIのホスト名とエンドポイントを知ることです。よく聞かれることとして、顧客がAPIのカタログ化と管理の取り組みを、「スプレッドシートを電子メールで送り、開発者にすべてのエンドポイントをリストアップしてもらう」という形で始めざるを得ないという話があります。
この方法の問題点がお分かりになりますか。もしかしたら、実際に見たことがあるかもしれません。「Eメールで問い合わせる」というアプローチでは特定の時点での内容が作成されるため、次のコードリリースで変更される可能性が高くなります。属人的な知識であるため、その知識は組織を去る人々とともに消えてしまうかもしれません。最後に、ヒューマンエラーの可能性があります。
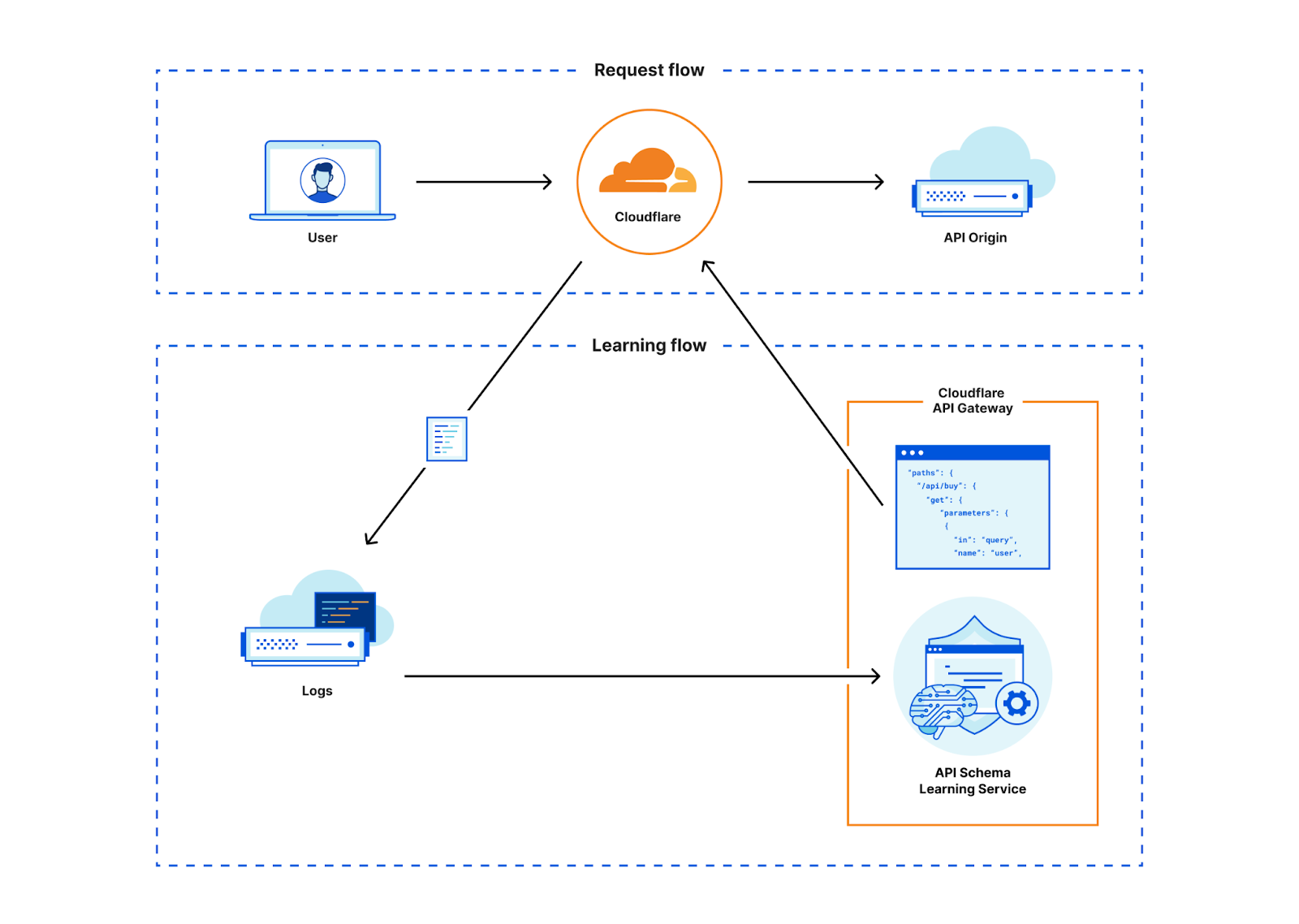
グループ作業によって収集された正確なAPIインベントリがあったとしても、APIスキーマを強制することによって、APIが意図したとおりに使用されていることを検証するには、そのスキーマを構築するためにさらに多くの集合的な知識が必要になります。そこで、API Gatewayの新しいAPI Discoveryとスキーマ学習機能を組み合わせることにより、Cloudflareグローバルネットワーク全体のAPIを自動的に保護し、手動によるAPIの検出やスキーマ構築の必要性を排除できます。
API GatewayによるAPIの検出と保護
API GatewayはAPI Discoveryと呼ばれる機能を通じてAPIを検出します。以前は、API Discoveryは、お客様固有のセッション識別子(HTTPヘッダーまたはCookie)を使用してAPIエンドポイントを特定し、その分析をお客様に表示していました。
この方法で検出することはうまくいきましたが、3つの欠点がありました。
- お客様はセッションを区別するために、どのヘッダーやCookieを使用したかを知る必要がありました。セッション識別子は一般的ですが、適切なトークンを見つけるには時間がかかります。
- API Discoveryにセッション識別子が必要なため、完全に認証されていないAPIを監視してレポートすることができませんでした。お客様は、引き続きすべてのAPIエンドポイントが文書化され、乱用が最小限に抑えられていることを確認するために、セッションレスのトラフィックを可視化することを望んでいます。
- セッション識別子がダッシュボードに入力されると、お客様は検出プロセスが完了するまで最大24時間待たなければなりませんでした。誰も待つのは好きではありません。
このアプローチには欠点もありましたが、セッションベースの製品から始めることで、顧客に迅速に価値を提供できることはわかっていました。顧客を獲得し、より多くのトラフィックをシステムに通すにつれて、新しいラベル付けされたデータが当社製品をさらに構築するために非常に有用であることがわかっていました。既存のAPIメタデータと新しいラベル付きデータで機械学習モデルをトレーニングできれば、どのエンドポイントがAPI用かを特定するためのセッション識別子は必要なくなります。そこで、私たちはこの新しいアプローチを構築することにしました。
セッション識別子に基づくデータから学んだことを利用し、セッション識別子に関係なく、ドメインへのすべてのAPIトラフィックを明らかにする機械学習モデルを構築しました。新しい機械学習ベースのAPI Discoveryにより、Cloudflareはお客様からの事前入力なしに、当社のネットワークを経由するすべてのAPIトラフィックを継続的に検出します。このリリースにより、API Gatewayのお客様はAPI Discoveryをこれまで以上に迅速に開始できるようになり、これまで発見できなかった認証されていないAPIを検出できるようになります。
セッション識別子はAPI Gatewayにとって重要であることに変わりはありません。セッション識別子はAPI Gatewayの不正利用防止のレート制限やシーケンス分析の基礎となるからです。新しいアプローチがどのように機能するかについては、以下の「仕組み」セクションをご覧ください。
ゼロから始めるAPI保護
API Discoveryを使用して新しいAPIを見つけたところで、それらをどのように保護するのでしょうか。攻撃を防御するためには、APIの開発者は、APIがどのように使用されることを想定しているかを正確に知っておく必要があります。幸運なことに、開発者はAPIに受け入れられる入力をコード化したAPIスキーマファイルをプログラムによって生成し、API Gatewayのスキーマ検証にアップロードすることができます。
しかし、多くのお客様が、開発者がAPIを構築するのと同じくらい速くAPIを見つけることができないことは、すでにお話ししました。また、APIを検出したとしても、セキュリティチームがHTTPリクエストメソッドとパス以上のものをログで見ることはめったにないことを考えると、何百もあるようなAPIエンドポイントのそれぞれについて一意のOpenAPIスキーマを正確に構築することは非常に困難です。
API Gatewayの利用パターンを調べたところ、お客様はAPIを検出することはあってもスキーマを適用することはほとんどありませんでした。その理由を尋ねると、答えは簡単でした。「APIの存在を知っていても、スキーマを提供できるように、それぞれのAPIの所有者を追跡するのにとても時間がかかります。このようなタスクの優先順位を、他のやらなければならないセキュリティアイテムよりも高くするのは難しいのです。」時間と専門知識の不足は、お客様が保護を可能にする上で最大のギャップでした。
そこで私たちはこのギャップを埋めようと考えました。私たちは、APIエンドポイントを検出するために使用したのと同じ学習プロセスを、スキーマを自動的に学習するために、一度検出したエンドポイントに適用できることを発見しました。この方法を使うことで、発見したすべてのエンドポイントに対して、リアルタイムでOpenAPI形式のスキーマを生成できるようになりました。私たちはこの新機能をスキーマ学習と呼んでいます。その後、お客様はCloudflareが生成したスキーマをSchema Validationにアップロードして、有用なセキュリティモデルを実施することができます。
仕組み
機械学習ベースのAPI検出
RESTful APIの呼び出しは、異なるHTTPメソッドとパスで構成されています。例えばCloudflare APIですが、このブログへのリクエストのうち、このAPIへのリクエストには特徴的なパスの共通傾向があることにお気づきでしょう。つまり、API呼び出しはすべて「/client/v4」で始まり、サービス名、一意の識別子、そして時にはサービス機能名とさらなる識別子で続いているということです。
API呼び出しはどのようにして簡単に特定できるのでしょうか。一見すると、これらのリクエストは「/clientで始まるパス」のようなヒューリスティックな方法でプログラムで簡単に発見できるように思えますが、新しいDiscoveryの中核には、HTTPトランザクションをスコアリングする分類機能を強化する機械学習モデルが含まれています。APIパスがそれほど構造化されているのであれば、なぜ機械学習が必要なのでしょうか。
その答えは、「何がAPI呼び出しで、非API呼び出しとは何が違うのか」ということです。2つの例を見てみましょう。
Cloudflare APIのように、多くのお客様のAPIは、API呼び出しのパスの前に「API」識別子とバージョンを付けるなどのパターンに従っています。(例: /API/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d)
ですから、パスの中で「API」やバージョンを探すだけで、これがAPIの一部である可能性が非常に高いことを教えてくれる、かなり優れたヒューリスティックな方法なのですが、残念ながらいつもそう簡単なわけではありません。
さらに2つの例を考えてみましょう。/users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpgと、/users/7f577081-7003-451e-9abe-eb2e8a0f103dでは、拡張子「.jpg」だけが異なります。最初のパスはユーザーのサムネイルのような静的なリソースかもしれません。2つ目のパスは、パスだけでは多くの手がかりを与えてくれません。
ヒューリスティックを手作業で作るのはすぐに難しくなります。人間はパターンを見つけるのが得意ですが、Cloudflareが毎日目にするデータの規模を考えると、ヒューリスティックを構築するのは困難です。そのため、私たちは機械学習を使ってヒューリスティックを自動的に導き出しており、それには再現性があり、一定の精度を保っていることも確認しています。
学習用に入力されるのは、前述のDiscoveryを通じ、セッション識別子に基づいて収集した、HTTPリクエスト/レスポンスサンプルの「content-type」やファイル拡張子などの特徴です。残念ながら、このデータのすべてがAPIであるとは限りません。さらに、API以外のトラフィックを表すサンプルも必要です。そのため、セッション識別子のDiscoveryデータから始め、手作業でクリーンアップし、非APIトラフィックのサンプルをさらに導出しました。モデルをデータに適合させすぎないよう、細心の注意を払いました。モデルが訓練データを超えて汎化することを望んでいるためです。
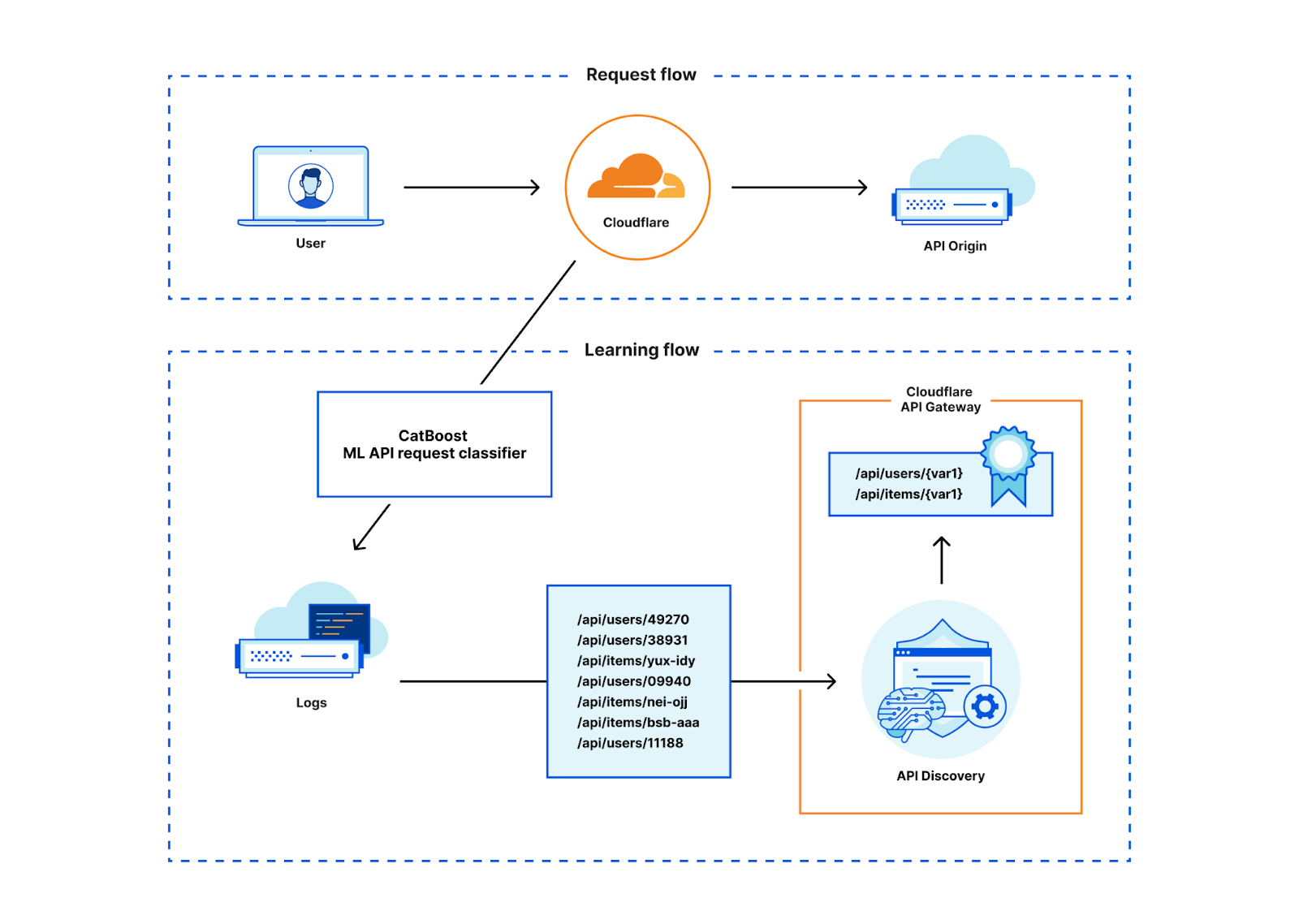
このモデルを学習させるために、CatBoostライブラリを使いました。CatBoostライブラリは、当社のボット管理のMLモデルにも使われているので、すでに十分な専門知識があります。単純化すると、得られたモデルをフローチャートとみなすことができます。このフローチャートは、例えば、パスに「API」が含まれる場合、ファイルに拡張子がないかもチェックする、という具合に、どの条件を次々にチェックすべきかを教えてくれます。このフローチャートの最後には、HTTPトランザクションがAPIに属する可能性を示すスコアがあります。
学習されたモデルが与えられれば、Cloudflareネットワークを通過するHTTPリクエスト/レスポンスの特徴を入力し、このHTTPトランザクションがAPIに属するかどうかの可能性を計算することができます。特徴抽出とモデルのスコアリングはRustで行われ、当社のグローバルネットワークではわずか数マイクロ秒しかかかりません。Discoveryは強力なデータパイプラインからデータを取得するため、実際には各トランザクションをスコアリングする必要はありません。はじめからデータパイプラインで終わることが分かっているトランザクションのみをスコアリングすることで、サーバーの負荷を減らすことができます。ですから、これはCPUタイムの消費も抑えた、費用対効果の高い機能です。
データパイプラインに分類結果があれば、セッション識別子ベースの検出に使っていたのと同じAPI Discoveryの仕組みを使うことができます。この既存のシステムはうまく機能し、コードを効率的に再利用できます。また、セッション識別子ベースのDiscoveryと結果を比較する際にも、システムが直接比較できるため役立ちました。
API Discoveryの結果を有用なものにするために、Discoveryの最初のタスクは、私たちが目にする固有のパスを変数に単純化することです。これについては以前にも説明しました。グローバルネットワーク全体で見られるさまざまな異なる識別子スキームを推定するのは簡単なことではなく、特にサイトが単純なGUIDや整数形式以外のカスタム識別子を使用している場合はなおさらです。API Discoveryは、いくつかの異なる変数分類機能と教師あり学習の助けを借りて、変数を含むパスを適切に正規化します。
パスを正規化した後でのみ、Discoveryの結果をユーザーがそのまま使用できるようになります。
その結果、顧客ごとに数百のエンドポイントが検出されました。
では、ML Discoveryは、APIトラフィックをタグ付けするためにヘッダーやCookieに依存するセッション識別子ベースのDiscoveryと比べてどうでしょうか。
私たちが期待しているのは、非常に類似したエンドポイントのセットを検出することです。しかし、私たちのデータには2つの問題があることが分かっていました。第一に、お客様がセッション識別子を使用して、API トラフィックだけをきれいに分離できないことがあります。この場合、Discoveryは非APIトラフィックを表面化させます。第二に、API Discoveryの最初のバージョンではセッション識別子が必要だったので、セッションの一部ではないエンドポイント(ログインエンドポイントや非認証エンドポイントなど)は、概念的に検出不可能でした。
次のグラフは、両方の検出バリアントについて、顧客ドメインで検出されたエンドポイント数のヒストグラムを示しています。

ふかん的に見ると、結果は非常によく似ています。これは、ML Discoveryが想定通りに機能していることを示す良い指標です。このプロットにはいくらかの違いが見られますが、セッション識別子だけでは概念的に検出できないエンドポイントも検出されることは、予想されることです。実際、ドメインごとの比較を詳しく見てみると、約46%のドメインで変化がないことがわかります。次のグラフは、セッションベースとMLベースの検出結果の違い(エンドポイントの割合)を比較したものです。

ドメインの15%で、1~50の間でエンドポイントの増加が見られ、9%で1~50の間の減少が見られます。ドメインの約28%で、50を超える追加エンドポイントが見つかりました。
これらの結果は、ML Discoveryが、これまでレーダーの下に隠れていた追加のエンドポイントを浮上させることができ、API Gatewayが提供する一連のツールを拡張して、API環境に秩序をもたらせることを示しています。
APIスキーマ学習によるオンザフライAPI保護
API Discoveryが完了したところで、実務者は新たに発見されたエンドポイントをどのように保護すればよいのでしょうか。API呼び出しのメタデータについてはすでに見てきたので、次はAPI呼び出しの本文を見てみましょう。APIのすべてのAPIエンドポイントに対して期待されるすべてのフォーマットのコンパイルは、APIスキーマとして知られています。API Gatewayのスキーマ検証は、リクエストの本文、パス、クエリ文字列がそのAPIエンドポイントの期待される情報を期待されるフォーマットで含んでいることを確認し、OWASPトップ10のAPI攻撃から保護する優れた方法です。しかし、期待されるフォーマットがわからない場合はどうすればよいでしょうか。
特定のAPIのスキーマがお客様に知られていない場合でも、このAPIを使用するクライアントは、ほとんどがこの未知のスキーマに適合するリクエストを送信するようにプログラムされています(さもなければ、エンドポイントへのクエリを成功させることはできません)。スキーマ学習はこの事実を利用し、お客様のために入力スキーマを自動的に再構築するために、このAPIへの成功したリクエストを調べます。例として、APIはリクエストのユーザーIDパラメーターがid12345-aという形式であることを期待するかもしれません。この期待値が明示されていなくても、APIとのやりとりを成功させたいクライアントはこの形式でユーザーIDを送信するでしょう。
スキーマ学習は、まずAPIエンドポイントへの最近成功したすべてのリクエストを識別し、次に各リクエストの異なる入力パラメーターをその位置とタイプに従って解析します。すべてのリクエストを解析した後、スキーマ学習は各ポジションの異なる入力値を調べ、それらが共通する特徴を特定します。すべての観測されたリクエストがこれらの共通性を共有していることを検証した後、スキーマ学習はこれらの共通性に従うように入力を制限し、スキーマ検証に直接使用できる入力スキーマを作成します。
より正確な入力スキーマを可能にするために、スキーマ学習は、パラメーターが異なるタイプの入力を受け取ることができるときを識別します。OpenAPIv3スキーマファイルを書いて、クエリパラメーターがUNIXタイムスタンプであることをリクエストの小さなサンプルで手動で観測したいとしましょう。あなたは、そのクエリパラメーターが昨年のUNIXエポックの始まりより大きい整数であることを強制するAPIスキーマを書きます。もしあなたのAPIがISO 8601フォーマットでもそのパラメーターを許可していた場合、あなたの新しいルールは異なるフォーマットの(しかし有効な)パラメーターがAPIにヒットしたときに誤検出を発生させるでしょう。スキーマ学習は、このような重労働をすべて自動で行い、手作業ではできない検査を行います。
誤検知を防ぐために、スキーマ学習はこれらの値の分布について統計的なテストを行い、分布が高い信頼性で境界を持つ場合にのみスキーマを書き込みます。
では、その効果は?以下は、パラメーターの種類と値に関する統計です。

パラメーター学習では、全パラメーターの半分強を文字列に分類し、次いで整数がほぼ3分の1を占めます。残りの17%は配列、ブール値、数値(浮動小数点数)パラメーターで構成され、オブジェクトパラメーターはパスやクエリではあまり見られません。

通常、パス内のパラメーター数は非常に少なく、全エンドポイントの94%がパス内のパラメーターを1つしか見ていません。

クエリでは、より多くのパラメーターが表示され、1つのエンドポイントに対して50ものパラメータが表示されることもあります!
パラメーター学習は、観測されたパラメーターの大部分について、99.9%の信頼度で数値制約を推定することができます。これらの制約は、パラメーターの値、長さ、サイズの最大値/最小値、またはパラメーターが取らなければならない一意な値の限定セットのいずれかになります。
数分でAPIを保護
本日より、API Gatewayをご利用のすべてのお客様は、以前の情報がない状態から始めても、わずか数クリックでAPIを検出し、保護できるようになりました。CloudflareダッシュボードでAPI Gatewayに入り、[Discovery]タブをクリックすると、検出されたエンドポイントが表示されます。これらのエンドポイントは、何もしなくてもすぐに利用できるようになります。次に、Discoveryから関連するエンドポイントをエンドポイント管理に追加します。スキーマ学習は、エンドポイント管理に追加されたすべてのエンドポイントに対して自動的に実行されます。24時間後、学習したスキーマをエクスポートし、スキーマ検証にアップロードします。
Enterpriseプランをご利用でAPI Gatewayを未購入のお客様は、Cloudflareダッシュボード内のAPI Gatewayトライアルを有効化するか、担当アカウントマネージャーにご連絡いただければ、API Gatewayの利用を開始できます。
今後の展開は?
今後、当社はJSONとURLエンコード形式の両方のPOST本文パラメーターや、ヘッダーとCookieのスキーマのように、より多くの形式でより多くの学習済みパラメーターをサポートすることで、スキーマ学習を強化する予定です。将来的には、スキーマ学習は特定されたAPIスキーマの変更を検出した際にもお客様に通知し、更新されたスキーマを提示する予定です。
これらの新機能に関するご意見をお聞かせください。適切な改善点を優先できるよう、お客様のご意見を担当アカウントチームまでお寄せください。ご連絡をお待ちしています!