


当社は、3年前にボット管理をローンチした際に、機械学習(ML)による検出モデルの最初のバージョンを使い始めました。一般的なボットユーザーエージェントを使って、悪性ボットを識別するようモデルを訓練し、このモデル(ML1)はボットのリクエストか人のリクエストかを属性だけで検知することができました。その後、迷惑トラフィックのうち最も対処しやすいものをすばやく、自信を持って除去するのに使える一連のヒューリスティックス(経験則)を導入しました。当社は、複数タイプのヒューリスティックスと、リクエストの特定属性に基づいた何百もの具体的ルールを設定しており、その多くはスプーフィングが非常に難しくなっています。とはいえ、機械学習は当社のボット管理ツールセットの中で極めて重要な要素です。
ゼロからの取り組みだったため、まずは静的モデルから始め、集計したHTTP分析メタデータを使ってすばやく実験を行うことができました。モデルをローンチした後、ボット管理の早期アクセス利用者からフィードバックを迅速に集め、パフォーマンスが良かった点や改善点を特定しました。攻撃者が賢くなっていたため、一連のモデルフィーチャーを新たに創製しました。ヒューリスティックスでさまざまなタイプの悪性ボットを正確に識別でき、ラベル付けしたデータの質が格段に向上しました。その後、時とともにモデルも進化し、リクエストの複数ディメンションにわたるボット挙動の変化に適応して、それまで訓練したことが無かった類のデータにも対応しました。以来、当社ネットワーク全体のトラフィックパターンを理解することによって生成されたメタデータを使って訓練した5つのモデルをローンチしてきました。
モデルが進化する一方で、Cloudflareを経由するトラフィックのパターンも変化しました。Cloudflareはデスクトップファーストの世界から出発しましたが、モバイルトラフィックが増大して、当社ネットワーク上のトラフィックの54%以上を占めるまでになりました。当社でモニターするトラフィックの大きな部分をモバイルが占めるようになったため、モバイルアプリケーションになりすますボットの検出精度を上げられるように、戦略を調整する必要がありました。デスクトップトラフィックは、接続先オリジンを問わず多くの類似点がありましたが、モバイルアプリはそれぞれ特定用途のために作られており、基盤となるAPIセットも定義されたスキーマも異なります。そのため、モバイルアプリトラフィックのあるWebサイト向けにもっと効果の高いモデルを構築する必要があることに、当社は気づきました。
モデルの構築とデプロイメントの方法
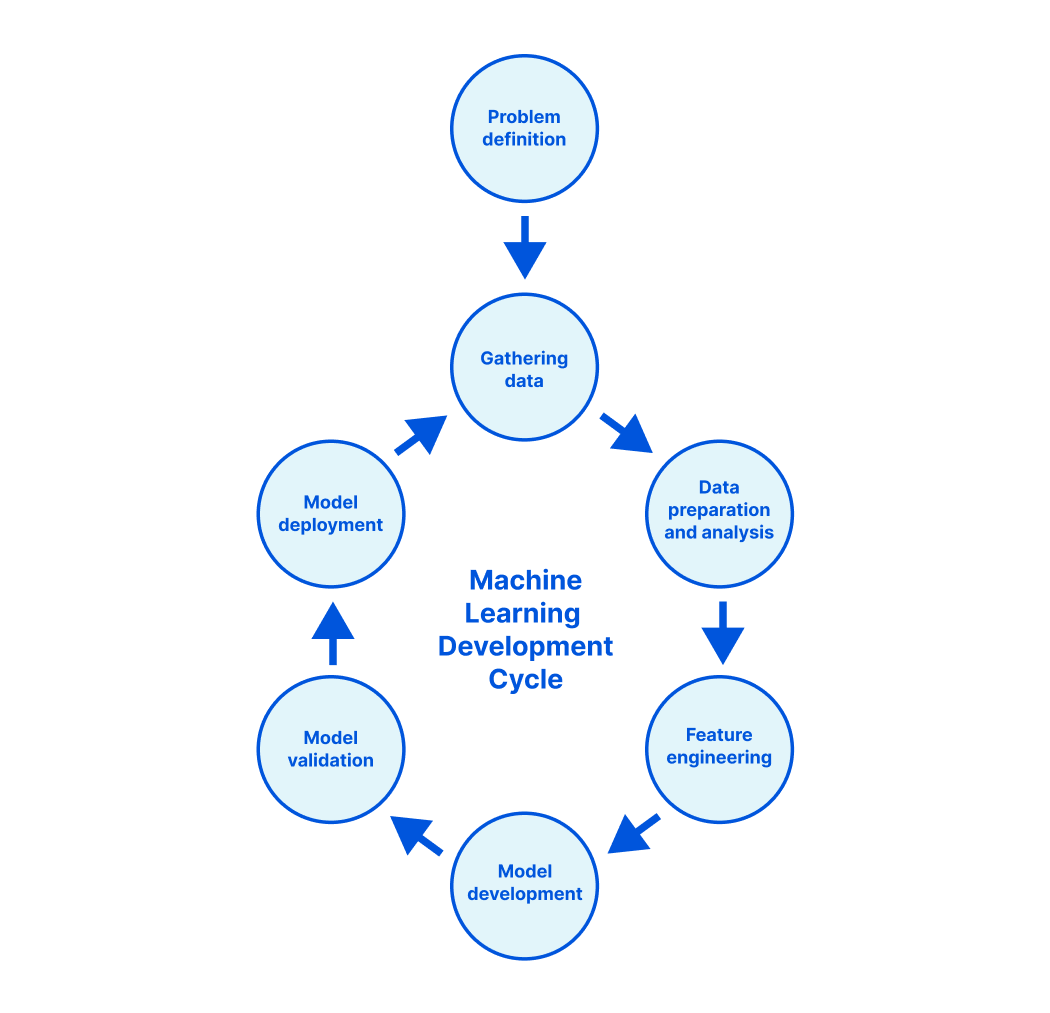
増大するモバイルトラフィックに対応するためにどのようにモデルを更新したのかをお話する前に、当社のモデル全般の構築方法と訓練方法についてまず説明する必要があるでしょう。
データ収集と準備
MLモデルの質は、訓練データの質で決まります。当社は、自社ネットワーク上のトラフィックが大量かつ多様であることを利用して、訓練データセットを生成しています。
識別するのは明らかにボットだとわかっているサンプル、つまり、ヒューリスティックスで検出したサンプルや、検証済みボット(正当な検索エンジンクローラーやアドボットなど)のサンプルです。
明らかにボットでないサンプルも識別できます。チャレンジを解決したり認証されたりして、高いスコアが付いたリクエストです。
データ分析とフィーチャー選択
このデータセットから、分散分析(ANOVA)のF値を使って最適なフィーチャーを見極めることができます。データセットは、さまざまなオペレーティングシステム、ブラウザ、デバイスタイプ、ボットカテゴリー、フィンガープリントを適切に反映したものにしたいため、フィーチャーの統計解析を行ってデータセット内の分布や予測への潜在的影響を理解します。
モデルの構築と評価
データが準備できたら、モデルの訓練を始められます。当社はAirflowを使って社内パイプラインを構築し、このプロセスを円滑にしています。モデルの訓練にはCatboostライブラリを選びました。問題の定義に基づいて、二項分類モデルを訓練します。
訓練データは、訓練セットとテストセットに分けます。モデルに最適なハイパーパラメータを決める際には、Catboostライブラリのグリッド検索とランダム検索のアルゴリズムを使います。
そして、選んだハイパーパラメータでモデルを訓練します。
当社はこれまでに、モデルをテストするためのきめ細かなデータセットを構築し、さまざまなタイプのボットを正確に検出できるようにしていますが、誤検知を極めて低いレベルに抑えたいとも考えています。当社では、モデルをお客様のトラフィックにデプロイする前に、オフライン監視を実施します。さまざまなブラウザ、オペレーティングシステム、デバイスについて予測を実行し、検証用データセットで、現在訓練中のモデルの予測を運用モデルと比較します。これは、MLパイプラインが生成する検証レポート(各データセットの正確性とフィーチャーの重要性などの要約統計量など)をもとに行います。そして、その結果によって、訓練を繰り返すか、デプロイメントへ進む決定をします。
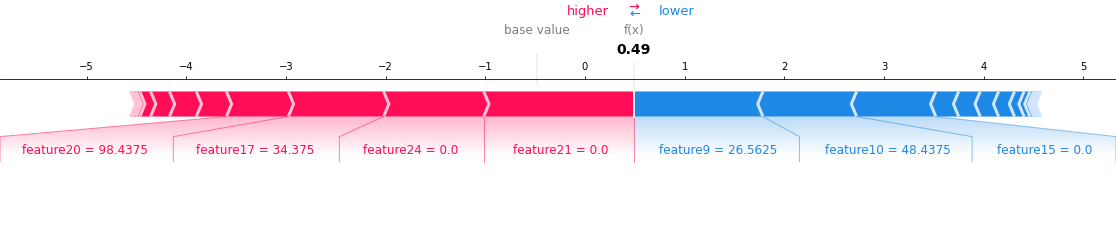
繰り返す必要がある場合は、改善の余地がどこにあるかをより良く理解したいと考えます。そのためにSHAP Explainerを使います。SHAP Explainerは、モデルの予測結果を解釈するための優れたツールです。当社のパイプラインで予測のSHAPグラフを作成し、それを深掘りして誤検知や検知漏れを理解します。これによって、より正確な予測を得るためには訓練データやフィーチャーのどこをどう改善すればよいかがわかります。前バージョンのモデルと比較して、テスト用データセットの大半で改善が見られたら、お客様のトラフィックに実験をデプロイすべきかどうかを決定します。
モデルのデプロイメント
モデルのオフライン分析はモデルのパフォーマンスを測るには良い指標ですが、結果の検証はより幅広いトラフィックについてリアルタイムで行うのが最善です。そのため、当社では新モデルは必ず、まずシャドーモードでデプロイします。シャドーモードでは、ボット管理をご利用のお客様のトラフィックに実際に影響を及ぼすことなく、トラフィックのスコアをリアルタイムでログに記録できます。これで、オンライン監視(リアルタイムトラフィックでのモデルのパフォーマンス評価)が可能になります。一連のGrafanaダッシュボードを使って、ボットタイプ別、デバイス別、ブラウザ別、オペレーティングシステム別、お客様別に評価し、モデルの確度向上を確認します。
次に、アクティブモードでテストを開始します。当社は、お客様が利用するさまざまなプランにモデルをロールアウトし、リクエストや訪問者の一定割合についてモデルを試すことができます。まずはFreeプランのお客様(I’m Under Attackモードを有効化するお客様など)にロールアウトします。Freeプランのお客さまでモデルの妥当性が確認できたら、続いてSuper Bot Fightモードのお客様へ徐々にロールアウトしていきます。それから、モデルをベータテストしたいお客様に使っていただきます。ベータ版をお試しいただいたお客様にご満足いただければ、その新モデルを安定したものとして正式にリリースします。既存のお客様は、このモデルへのアップグレードをお選びいただけます。新規のお客様には、最新バージョンがデフォルトとして提供されます。
モバイルアプリのパフォーマンス改善
当社の最新モデルに関しては、上記の訓練プロセスによって、特にモバイルアプリトラフィックでのパフォーマンス改善を目指しました。モデルを訓練するためには、ラベル付きのデータ(「ボット」のトラフィックか「人」によるトラフィックかのアノテーションを手作業で行ったHTTPリクエストセット)が必要です。上述した通り、当社はこのラベル付きデータをさまざまなソースから収集しますが、前々から見つけるのに苦労しているのがモバイルアプリからの「人」トラフィックに関する良質のデータセットです。当社は、クライアントがブラウザのチャレンジやCAPTCHAを解決できた時のトラフィックを、「良質」のベストサンプルとしていました。残念ながら、それはデータベースに含められる良質トラフィックの種類を限定することにもなりました。モバイルアプリトラフィックのサブセットのように、「良質」トラフィックの多くはCAPTCHAを解決できないからです。CAPTCHA解決はたいていHTML + JavaScriptといったWebテクノロジーに依存しており、Webブラウザで実行され、レンダリングされることになっています。一方、ネイティブのモバイルアプリは、CAPTCHAのレンダリングが適切にできない場合があり、そのためほとんどのネイティブモバイルアプリはデータベースに入らなくなってしまいます。
つまり、ネイティブのモバイルアプリからの「人」トラフィックは、インターネット上には多く存在するにもかかわらず、当社の訓練データにはそれが反映されないのが通常でした。そのため、当社モデルのネイティブモバイルアプリトラフィックにおけるパフォーマンスは、ブラウザトラフィックに比べ芳しくありませんでした。この状況を是正するため、当社はより良いデータセットを探し始めました。
さまざまなテクニックを使って、正当なネイティブモバイルアプリトラフィックだと自信を持ってラベリングできるリクエストのサブセットを特定しました。モバイルオペレーティングシステムのオープンソースコードやよく使われるライブラリ、フレームワークを深掘りして、正当なモバイルアプリトラフィックにあるべき挙動パターンを割り出したのです。さらに、一部のお客様の協力を得て、正当なモバイルアプリトラフィックを他のタイプのトラフィックと区別できるドメイン固有のトラフィックパターンも特定しました。
そして、何度もテスト、フィードバック、イテレーションをした後に、新しいデータセットを複数作ることができ、モデルの訓練プロセスに取り入れて、モバイルアプリトラフィックにおけるパフォーマンスの大幅改善に成功しました。
モバイルパフォーマンスの改善
検証済みのモバイルアプリトラフィックから収集したデータのおかげで、最新モデルは、この種のトラフィックに見られる特有のパターンやシグナルを理解することによって、モバイルアプリトラフィックからの有効なユーザーリクエストを識別することができます。当社は今月、新たに識別した有効なモバイルリクエストのデータセットを使って訓練した最新の機械学習モデルを、ベータ版ご利用のお客様にリリースしました。結果は上々です。
あるケースでは、食品デリバリー会社でAndroidトラフィックの誤検知率が0%になりました。不可能に思えるかもしれませんが、信頼できるデータで訓練した結果です。
また別のケースでは、主要Web3プラットフォームで同様の改善が見られました。前のモデルでは、エッジケースモバイルアプリトラフィックの誤検知率が28.7%~40.7%でしたが、最新モデルではこれが0%近くに低下しています。ここでは2例しか紹介しませんが、こうした成果は広く見られ、モバイルアプリを保護するお客様の間でのMLの導入増加につながっています。まだボット管理で保護されていないモバイルアプリをお持ちでしたら、今すぐCloudflareダッシュボードを開き、お客様のトラフィックに関する新モデルの表示をご確認ください。当社では、すべてのお客様に無料のボット分析を提供していますので、お客様のモバイルアプリでボットが何をしているかをすぐ見ることができます。ブロックしたいものが表示されていれば、ボット管理をオンにしてください。お客様のモバイルアプリがAPI駆動型であれば(たいていそうです)、当社の新しいAPIゲートウェイも併せてご覧ください。