
ほぼ3年前、弊社はサイトをダウンさせる可能性のある正規トラフィックの圧倒的な急増から顧客のサイトを保護するため、Cloudflare Waiting Roomを立ち上げました。Waiting Roomは、過剰なトラフィックをカスタマイズ可能なオンブランドの待機室に配置することで、トラフィックが集中する時間帯でもサイトで空き枠ができると同時に動的にユーザーを接続し、ユーザーエクスペリエンスをコントロールできるようにします。待機室のリリース以来、モバイルアプリ対応、アナリティクス、Waiting Roomバイパスルールさらにその他を含め、顧客からのフィードバックに基づいて機能を拡張し続けています。
弊社は新機能を発表し、待機室の機能を拡張することで顧客の問題の解決に意欲的に取り組んでいます。今回は、私たちの製品のコアとなるメカニズムが進化してきた過程、つまり、トラフィックの急増に対応してキューに入れる仕組みについて、その舞台裏をお話しします。
Waiting Roomが構築される過程での課題
下の図は、顧客が自社WebサイトでWaiting Roomを有効にしたときの配置を簡単に示した概要図です。
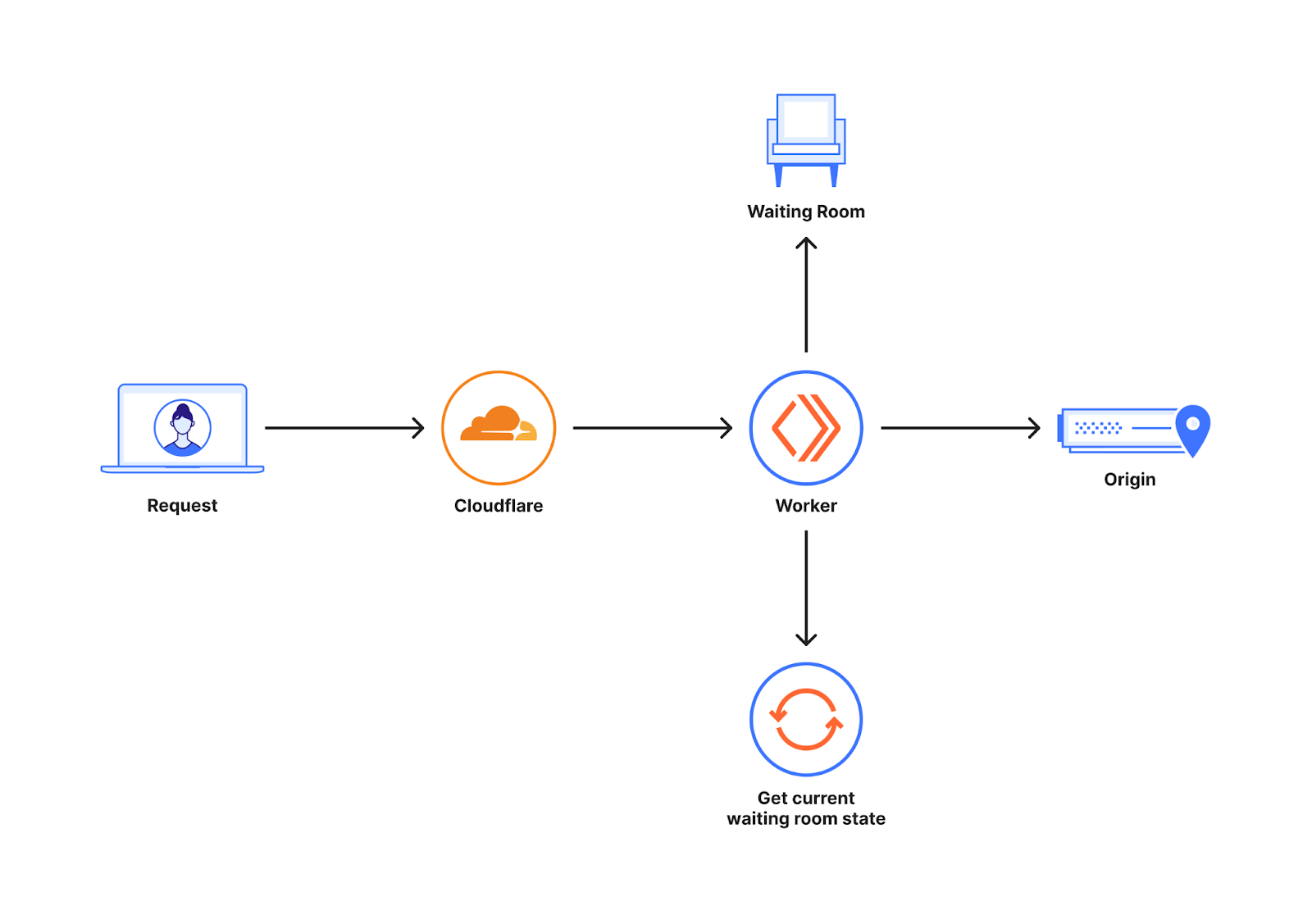
Waiting RoomはCloudflareデータセンターのグローバルネットワーク上で動作するWorkers上に構築されます。顧客のWebサイトへのリクエストは、さまざまなCloudflareデータセンターに送られる可能性があります。最小限の遅延を実現しパフォーマンスの強化を最適化するため、これらのリクエストは地理的に最も近いデータセンターにルーティングされます。新しいユーザーがWaiting Roomがカバーするホスト/パスにリクエストを行うと、Waiting Room Workerはユーザーをオリジンに送るか待機室に送るかを決定します。この決定は、待機室の状態からどれだけのユーザーがオリジン上にいるかを読み取ることで行われます。
待機室の状態は、世界中のトラフィックに基づいて絶えず変化します。この情報は、中心的場所に保存される場合もあり、さらに変化が最終的に世界中に伝播することもあります。この情報を中心的場所に保存すると、中心的場所がリクエストの発信元から非常に遠くなる可能性があるため、各リクエストに大幅な遅延が発生する可能性があります。このため、どのデータセンターも、ある時点で利用可能な世界中のWebサイトのトラフィック・パターンのスナップショットである個別の待機室の状態で動作します。ユーザーをWebサイトに入れる前に世界中のあらゆる場所からの情報を待つことになると、リクエストに大きな遅延を発生させることになるので、避けなければなりません。この理由により、中心的場所は設けず、代わりにトラフィックの変化が最終的に世界中に伝搬されるパイプラインを持つことにしたのです。
バックグラウンドで待機室の状態を集約するこのパイプラインは、CloudflareのDurable Objects上に構築しています。アグリゲーション・パイプラインがどのように機能するのか、そしてそこで弊社が取った様々な設計上の決定について紹介した2021年のブログ記事で詳細を説明しています。このパイプラインでは、すべてのデータセンターがトラフィックの変化に関する更新情報を数秒以内に取得できるようにしています。
Wainting Roomは、その時点で見えている状態に基づき、ユーザーをWebサイトに送るかキューに入れるかを判断することになります。顧客のWebサイトが過負荷にならないよう、適切なタイミングでキューに入れるようにしなければなりません。また、誤ってトラフィックが急増したと判断した場合にキューに入れることになるかもしれないため、キューに入れるのが早急すぎるのも問題になります。キューに入れられることで、Webサイトに到達するのを断念するユーザーも出てくるかもしれません。Wainting Roomは、100カ国以上、300以上の都市にまたがるCloudflareのネットワーク内のすべてのサーバーで実行されています。すべての新規ユーザーに対して、Webサイトに行くかキューとして待つかの決定を最小限の遅延で行えることを弊社は目指しています。いつキューに入れるかという決断は、Waiting Roomにとって難題です。このブログでは、そのトレードオフにどのようにアプローチしたかを紹介します。弊社のアルゴリズムは、顧客の設定した制限を尊重し続けながら、誤検出を減らすように進化してきました。
待機室がユーザーをキューに入れるか否かを決定する仕組み
待機室がいつキューイングを開始するかを決定するうえで最も重要になる要因は、トラフィック構成の仕方になります。待機室のコンフィグを行う際に設定するトラフィック制限は2種類あり、それぞれ総アクティブユーザー数と1分当たりの新規ユーザー数となります。総アクティブユーザー数は、待機室がカバーするページで同時に許可したいユーザー数の目標しきい値となります。1分当たりの新規ユーザー数は、1分あたりのWebサイトへのユーザー流入の最大速度の目標しきい値の定義となります。これらの値のいずれかが急上昇すると、キューが発生します。総アクティブユーザー数の計算方法に影響するもう1つの設定に、セッション時間があります。待機室がカバーするあらゆるページに対して行われたリクエスト以降、ユーザーはセッション時間でアクティブであるとみなされます。
下のグラフは、ある顧客の社内モニタリングツールによるもので、該当の顧客の2日間のトラフィック・パターンを示したものです。この顧客では、1分あたりの新規ユーザー数とアクティブユーザー総数数の上限をそれぞれどちらも200に設定しています。
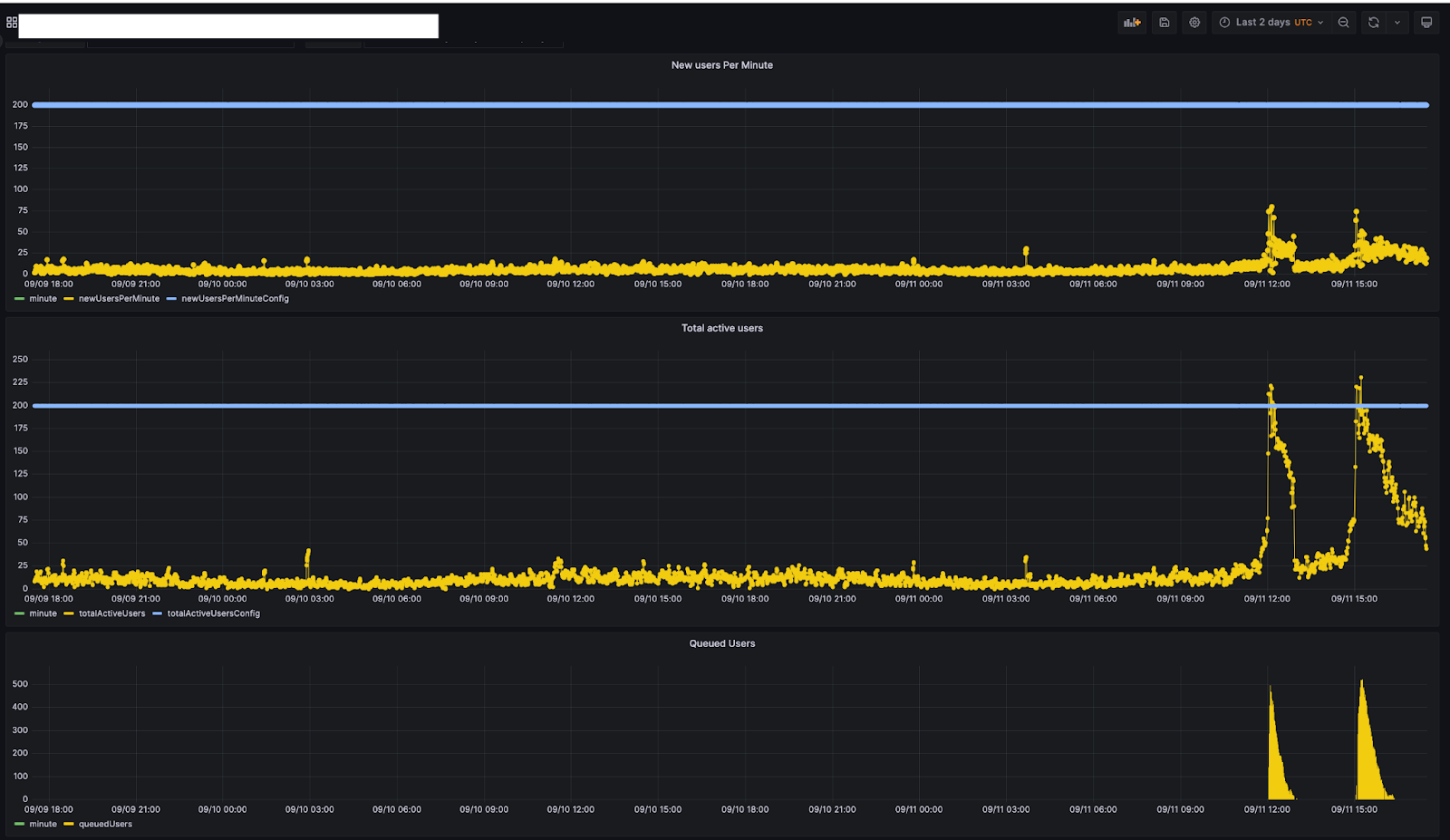
トラフィックを見ると、9月11日の11時45分頃にユーザーのキューが作られているのがわかります。その時点では、総アクティブユーザー数は約200人でした。総アクティブユーザー数が減少するにつれ(12:30頃)、キューに入れられたユーザー数は0になっています。この時間帯にユーザーがキューに入れられたことで、Webサイトへのトラフィックが顧客によって設定された制限値に収まっていたことになります。
ユーザーがWebサイトにアクセスすると、暗号化されたクッキーが渡されます。クッキーの内容は、次のようなものとなります。
{
"bucketId": "Mon, 11 Sep 2023 11:45:00 GMT",
"lastCheckInTime": "Mon, 11 Sep 2023 11:45:54 GMT",
"acceptedAt": "Mon, 11 Sep 2023 11:45:54 GMT"
}
クッキーは、待機室への入室を示すチケットのようなものです。bucketIdは、このユーザーがどのクラスタに属しているかを示しています。acceptedAt時間とlastCheckIn時間は、Workerとの最後のやりとりがいつ行われたかを示しています。この情報は、顧客が待機室を設定するときに設定したセッション持続時間の値と比較する際、チケットが入室するために有効かどうかを確認できます。クッキーが有効であれば、ユーザーを通過させ、WebサイトにいるユーザーがWebサイトを閲覧し続けられるようにします。クッキーが無効な場合、そのユーザーを新しいユーザーとして扱い新たにクッキーを作成し、Webサイト上で待ち行列が発生している場合はそのユーザーはキューの後ろに回されます。次の節では、ユーザーをキューに入れるタイミングの決定方法を見ていきます。
これをさらに理解するために、待機室ステートの内容を見てみます。上で説明した顧客の場合、"Mon, 11 Sep 2023 11:45:54 GMT"時点で、状態は次のようになっていました。
{
"activeUsers": 50,
}
前述のとおり、この顧客のコンフィギュレーションでは、1分あたりの新規ユーザー数は200、総アクティブユーザー数は200であったことが分かります。
つまり、200人に対応できるところにアクティブユーザーが50人しかいないため、新しいユーザーのためのスペースがあることを示しています。したがって、あと150人分のスペースがあることになります。この50人のユーザーが、サンノゼ(20人)とロンドン(30人)の2つのデータセンターから来たと仮定します。また弊社では、全世界で活動しているWorkerの数と、状態が計算されるデータセンターで活動しているWorkerの数も記録しています。下のキーはサンノゼで計算されたものです。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
"Mon, 11 Sep 2023 11:45:54 GMT",の時点で、サンノゼのデータセンターでその待機室へのリクエストがあったとします。
サンノゼに到達したユーザーがオリジンに到達できるか確認するために、まず過去1分間のトラフィック履歴をチェックし、その時点でのトラフィックの分布を見ます。というのも、世界の特定の地域で人気があるWebサイトが多くあるためです。これらのWebサイトの多くでは、同じデータセンターからトラフィックが来る傾向があります。
"Mon, 11 Sep 2023 11:44:00 GMT"時点のトラフィック履歴を見ると、サンノゼにはその時点で200人中20人(10%)のユーザーがアクセスしていることがわかります。最新の時刻"Mon, 11 Sep 2023 11:45:54 GMT"では、過去1分間のトラフィック履歴と同じ比率でWebサイトで利用可能なスロットを分割します。つまり、サンノゼから送れるのは150スロットの10%、つまり15ユーザーということになります。また"dataCenterWorkersActive"は3なので、アクティブなWorkerが3つあることもわりかます。
データセンターで利用可能なスロットの数は、データセンターのWorkerで均等に分けられます。したがって、サンノゼのすべてのWorkerである15/3のユーザーをWebサイトに送ることができます。もしトラフィックを受け取ったWorkerがその時点でオリジンにユーザーを送っていなければ、最大5人(15÷3)まで送ることができます。
同じ時刻("Mon, 11 Sep 2023 11:45:54 GMT")に、デリーのデータセンターにリクエストがあったとします。デリーのデータセンターのWorkerはtrafficHistoryをチェックし、そのために割り当てられたスロットがないことを確認します。このようなトラフィックのために、弊社はAnywhereスロットを用意しておきました。
{
"activeUsers":50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
世界中のWorkerがこの全量の一部を利用できるため、Aynwereスロットは世界中のアクティブなWorkerすべての間で割り振られます残りの150スロットの75%は、113となります。
ステートキーはまた、世界中で湧き出るように発生したWorkerの数(globalWorkersActive)も記録しています。割り当てられたAnywhereスロットは、利用可能であれば世界中のすべてのアクティブWorkerに分配されます。待機室の状態を見ると、globalWorkersActiveは10となっています。つまり、アクティブなWorkerごとに、113÷10≒11人ものユーザーを送ることができます。つまり、Mon, 11 Sep 2023 11:45:00 GMTにWorkerに来た最初の11人のユーザーはオリジンに受け入れられます。余分なユーザーは、キューに入れられます。前述したMon, 11 Sep 2023 11:45: 00 GMTの時点でのサンノゼでの余剰スロット(5)により、サンノゼのWorkerからWebサイトに最大16(5+11)ユーザを確実に受け入れることができることになります。
Workerレベルでのキューイングは、データセンターで利用可能なスロットの前にユーザーをキューに入れてしまう可能性があります。
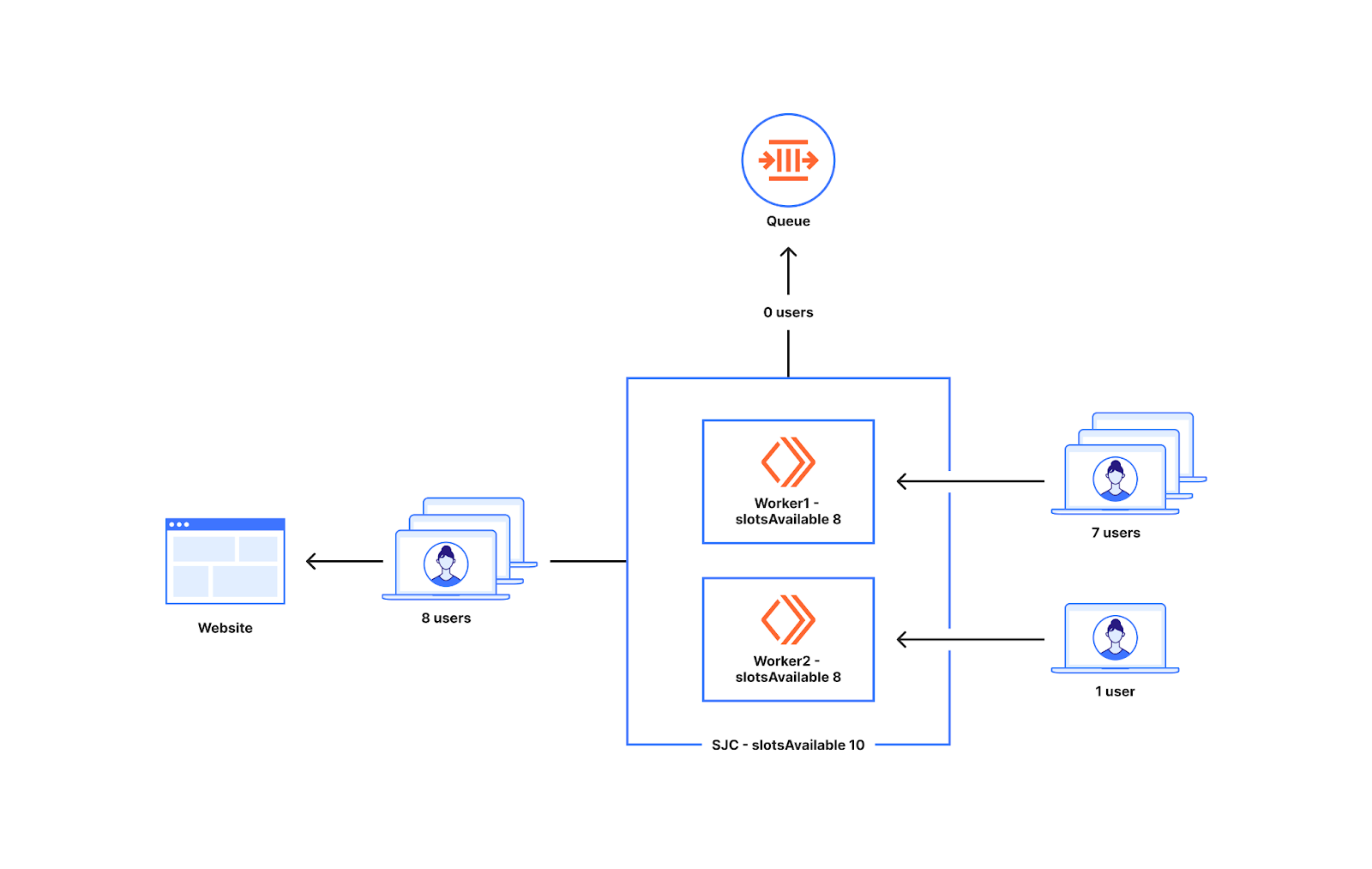
上の例からわかるように、キューに入れるかどうかはWorkerレベルで決まります。世界中のWorkerのもとへ行く新規ユーザーの数は、一様ではありません。トラフィックが2つのWorkerに一様に分配されない場合に起こることの理解のため、下の図を見てください。
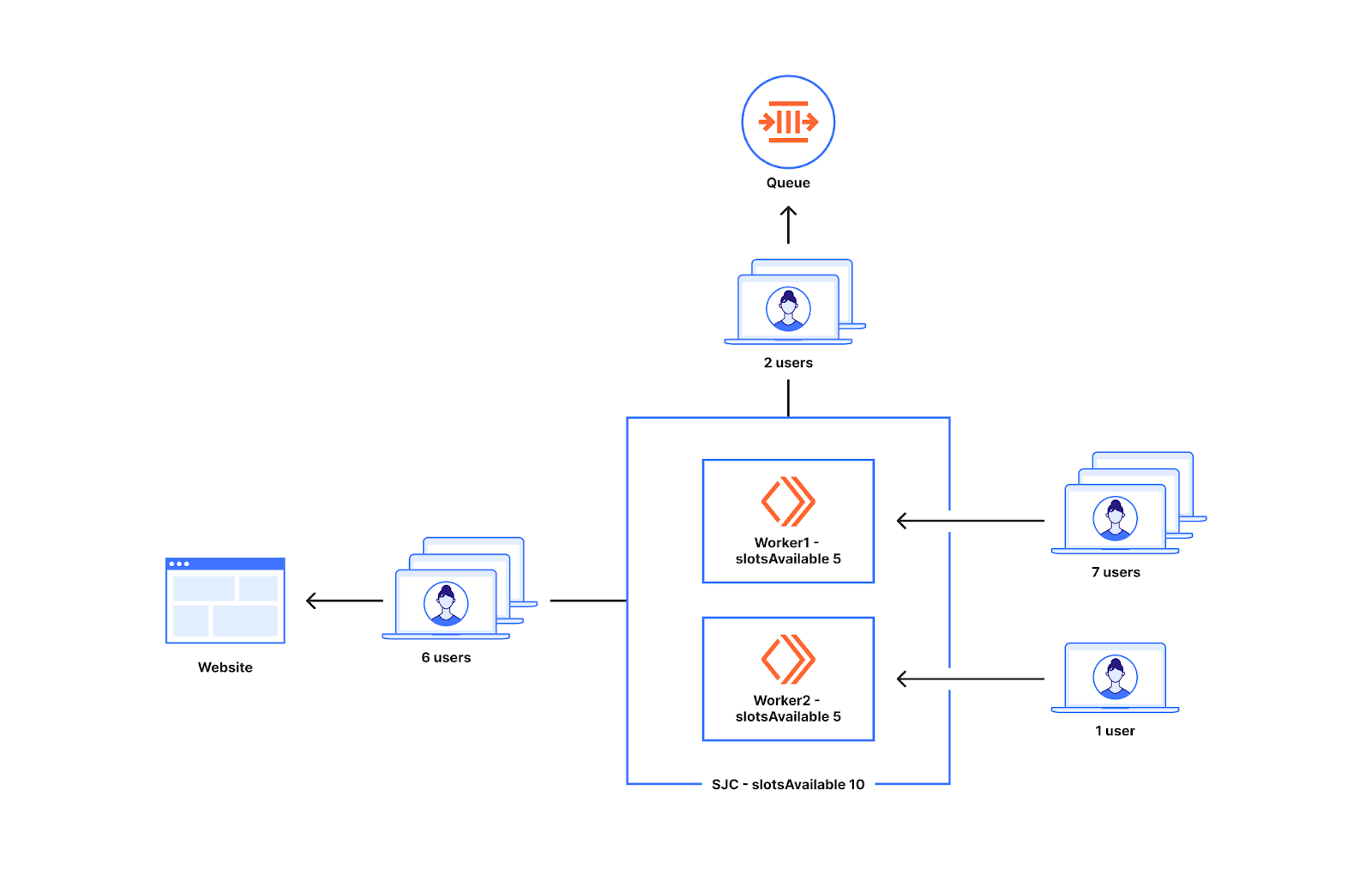
サンノゼのデータセンターの空き枠が10だとします。サンノゼでは2つのWorkerが稼働しています。7人のユーザーがWorker1に行き、1人のユーザーがWorker2に行きます。この状況ではWorker1の7人のユーザーのうち5人をWebサイトに投入し、Workerには5枠しかないため、残りの2人はキューに入れられます。Worker2に現れた1人のユーザーもオリジンに行けます。こうして、実際には8人のユーザーしか現れていない中、10人のユーザーがサンノゼのデータセンターから送られることが可能であるのに2人のユーザをキューに入れることになります。
作業員間でスロットを均等に分割するこの問題により、待機室の設定されたトラフィック制限(通常は設定された制限の20~30%以内)より前に待ち行列ができることになります。このアプローチには、次に述べる利点があります。弊社は、この20~30%のキューイング発生頻度を減らし、可能な限り限界に近く引き上げ、Waiting Roomがそれでもトラフィック急増に備えられるよう、アプローチを変更しました。このブログの後半では、スロットの割り当てとカウントの方法を更新することでこれを実現した方法を紹介していきます。
Workerがこのような決断を下すことにおける利点
上記の例では、サンノゼとデリーのWorkerがユーザーをオリジンに通すかどうか決定する仕組みについて説明しました。Workerレベルで決断を下すことの利点は、リクエストに大きな遅延をもたらすことなく決断を下せる点にあります。常にデータセンターで現在利用可能な状態で作業しているため、決断を下すためにデータセンターから離れる必要なく待機室に関する情報を得ることができるためです。キューイングが始まるのは、Worker内のスロットがなくなった時点です。遅延が加わらないため、顧客はユーザーへの余分な遅延を心配することなく、常に待機室をオンにすることができます。
Waiting Roomの最優先事項は、予期せぬ圧倒的なトラフィックの急増に直面しても、顧客のサイトが常に稼働し続けられるようにすることです。そのためには、待機室がその部屋に対して顧客が設定したトラフィック制限に近い、またはそれ以下にとどまることを優先することが大切になります。世界各地であるデータセンター、たとえばサンノゼでトラフィックの急増が発生した場合、データセンター現地の状態がデリーに届くには、数秒かかります。
Worker間でスロットを分割すると、多少古いデータで作業しても、全体的な上限を影響のある量で超えてしまうことがないようになります。例えば、activeUsersの数がサンノゼのデータセンターでは26で、スパイクが起きているもう一つのデータセンターでは100になることがあります。その時点では、デリーから追加ユーザーを送っても、デリーには全体の余剰分の一部しかないため、全体の上限をそれほどオーバーしません。したがって、全体の上限に達する前にキューに入れることは、全体の上限が尊重されるようにするための設計の一部なのです。次の段落では、トラフィック制限を超過するリスクを増大させることなく、可能な限り制限に近いところでキューに入れるために実装したアプローチについて説明します。
待機室の制限に比べトラフィックが少ない場合にスロットを多く割当てる
弊社で真っ先に対処したかったケースは、トラフィックが限界から遠く離れたときに発生するキューイングでした。キューに入れられたエンドユーザーにとってこの状況に直面するのはまれなことであり、通常は1回のリフレッシュ・インターバル(20秒)となるものの、キューイング・アルゴリズムを更新する際の最優先事項箱のことでした。これを解決するために、スロットを割り当てる際に利用率(トラフィックの限界からどれだけ離れているか)を見て、トラフィックが限界から非常に距離が離れている場合はより多くのスロットを割り当てるようにしました。この背景には、より多くのユーザーがオリジンにいるときに、Workerごとで利用可能なスロットを再調整できるようにしながらも、低い制限値で起こるキューイングを防ぎたいとの狙いがありました。
これを理解するために、2つのWorkerにトラフィックが不均一に分配される例をもう一度見てみます。前に説明したのと似たような、2つのWorkerが以下の通りあるとします。この場合、稼働率は低くなっています(10%)。つまり、限界までかなりの余裕があることになります。割り当てられたスロット(8)は、サンノゼデータセンターのslotsAvailableの10に近くなっています。下図を見ればわかるように、Workerのどちらかにアクセスする8人のユーザー全員が、この変更後のスロット割り当てでWebサイトにアクセスできるようになりました。Workerあたりにより多くのスロットを低い利用率で提供していることがその理由です。
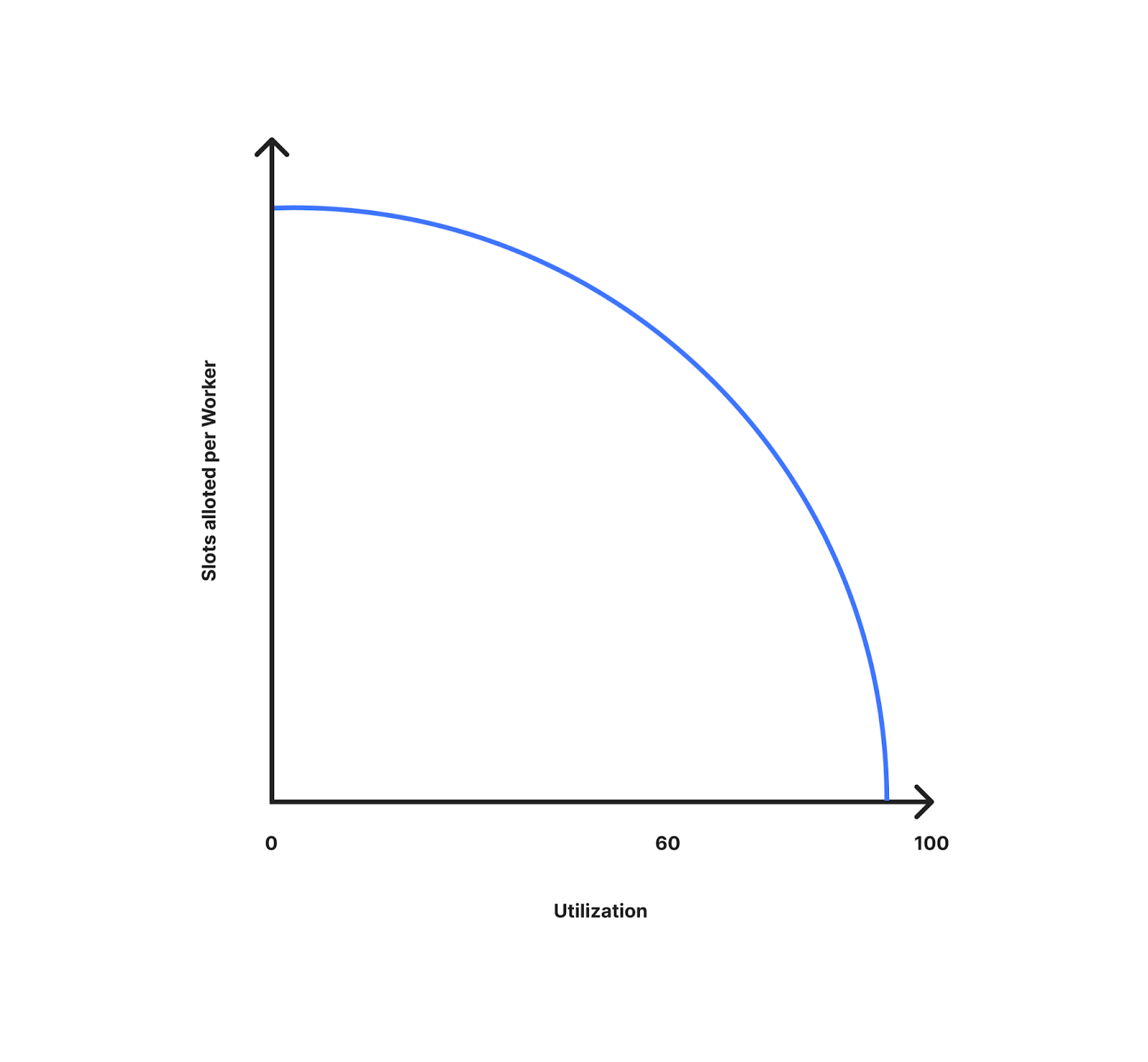
下図は、Workerあたり割り当てられるスロットが利用率(限界からどれだけ離れているか)によって変化する様子を示したものです。ここでわかるように、利用率が低いほどWorkerに多くのスロットが割り当てられています。利用率が上がるにつれて、Workerあたり割り当てられるスロットは減少していきます。限界に近づきつつあり、トラフィックの急増に備えることができるためです。利用率10%の場合、すべてのWorkerがデータセンターで利用可能なスロットに近づくことになります。利用率が100%に近くなると、利用可能なスロットをデータセンターのWorker数で割った値に近くなります。
低い稼働率でより多くのスロットを達成する方法
このセクションでは、目的を達成するための数学について掘り下げていきます。もし詳細に関心がない場合、「過剰プロビジョニングのリスク」の章へとお進みください。
理解を深めるため、デリーデータセンターにリクエストが来る前の例をもう一度見てみましょう。activeUsersの値は50なので、利用率は50÷200で約25%となります。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
ここでは、より低い利用レベルでより多くのスロットを割り当てることを目指しています。これにより、トラフィックが上限まで遠く離れている際、顧客が予期せぬキューの挙動に出くわさないようになります。Mon, 11 Sep 2023 11:45:54 GMTの時点で、Delhiへのリクエストは、ローカルのステートキーに基づき、25%の使用率となっています。
利用率が低いときに利用できるスロットを増やすことを狙い、利用率に比例して動くworkerMultiplierを追加しました。利用率が低いと倍率は低くなり、利用率が高いと1に近くなります。
workerMultiplier = (utilization)^curveFactor
adaptedWorkerCount = actualWorkerCount * workerMultiplier
utilization - 限界からどれだけ離れているか。
curveFactor - curveFactorは調整可能な指数で、Workerのカウントが低いときに、どれだけ積極的に余分な予算を配分するかを決定します。これを理解するために、y = xとy = x^2が値0と1の間でどのように見えるかを示すグラフを見てみましょう。
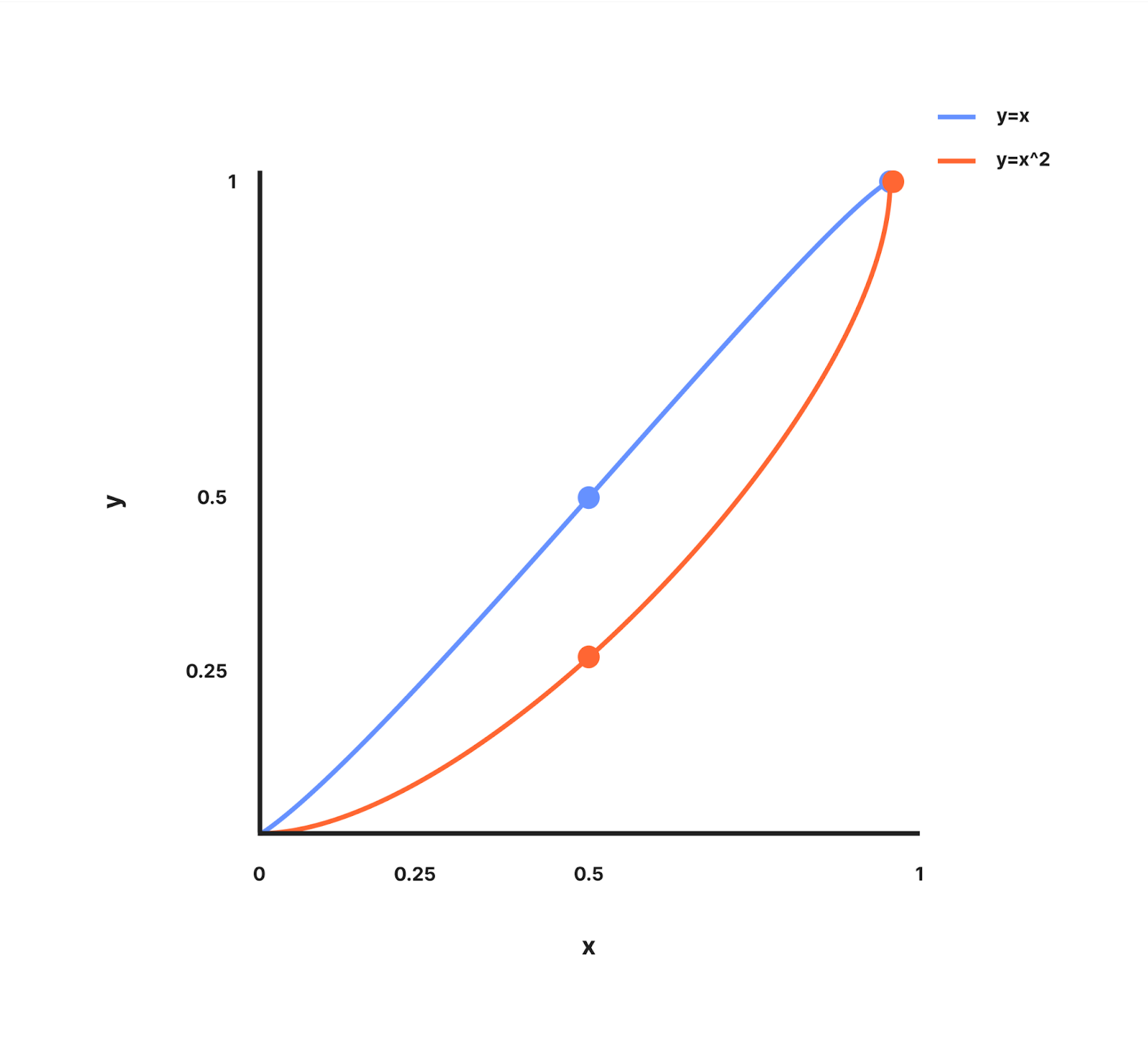
y=xのグラフは、(0, 0)と(1, 1)を通る直線になります。
y=x^2 のグラフは、x が< 1 のとき、y が x よりも遅く増加し、(0, 0) と (1, 1) を通る曲線になります
ここで、曲線の仕組みを用い、y=workerCountMultiplier、x=utilizationの指揮を導き出しました。curveFactorは、Workerの数が少ないときにどれだけ積極的に余分な予算を配分するかを決定する調整可能なパワーとなります。curveFactorが1のとき、workerMultiplierは利用率と等しくなります。
前に議論した例に戻り、カーブファクターの値がどうなるか見てみましょう。Mon, 11 Sep 2023 11:45:54 GMTの時点で、デリーへのリクエストはローカルのステートキーに基づき25%の使用率となっています。世界中のあらゆるWorkerがこの余剰分の一部を利用できるので、Anywhereスロットは世界中のすべてのアクティブなWorker、すなわち残りの150スロットの75%に相当する113個で分けられます。
待機室の状態を見ると、globalWorkersActiveは10となっています。この場合、113スロットを10で割るのではなく、調整したWorkerの数であるglobalWorkersActive×workerMultiplierのカウントで割ります。curveFactorが1の場合、workerMultiplierは25%または0.25の稼働率に等しくなります。
実質的なWrokerCountは、10 × 0.25 = 2.5 となります。
つまり、アクティブなWorkerは、113÷2.5、つまり約45人のユーザーを送ることができることになります。Mon, 11 Sep 2023 11:45:00 GMTの時点でWorker来た45人のユーザーが、オリジンに受け入れられ、超過したユーザーはキューに入れられます。
したがって、利用率が低い場合(トラフィックが上限まで遠い場合)には、各Workerがさらに多くのスロットを得ることになります。しかし、スロットの合計を合算した場合では、全体の上限を超える可能性が高まります。
過剰プロビジョニングのリスク
より低い上限でより多くのスロットをもたらす方法により、トラフィックがトラフィック上限に対して低い場合にキューが発生する可能性を減少させます。ただし、より低い利用率レベルでは、世界中で一様なスパイクが発生し多彩に予想以上に多くのユーザーがオリジンに入る可能性があります。下図は、これが問題となるケースを示しています。ご覧の通り、利用できるデータセンターのスロットは10です。前に説明した10%の利用率では、それぞれ8つのスロットを持つことができます。あるWorkerに8人のユーザーが現れ、別のWorkerに7人のユーザーが現れた場合、データセンターで利用可能なスロットは最大10個しかないのにも関わらず、15人のユーザーをWebサイトに送ることになります。
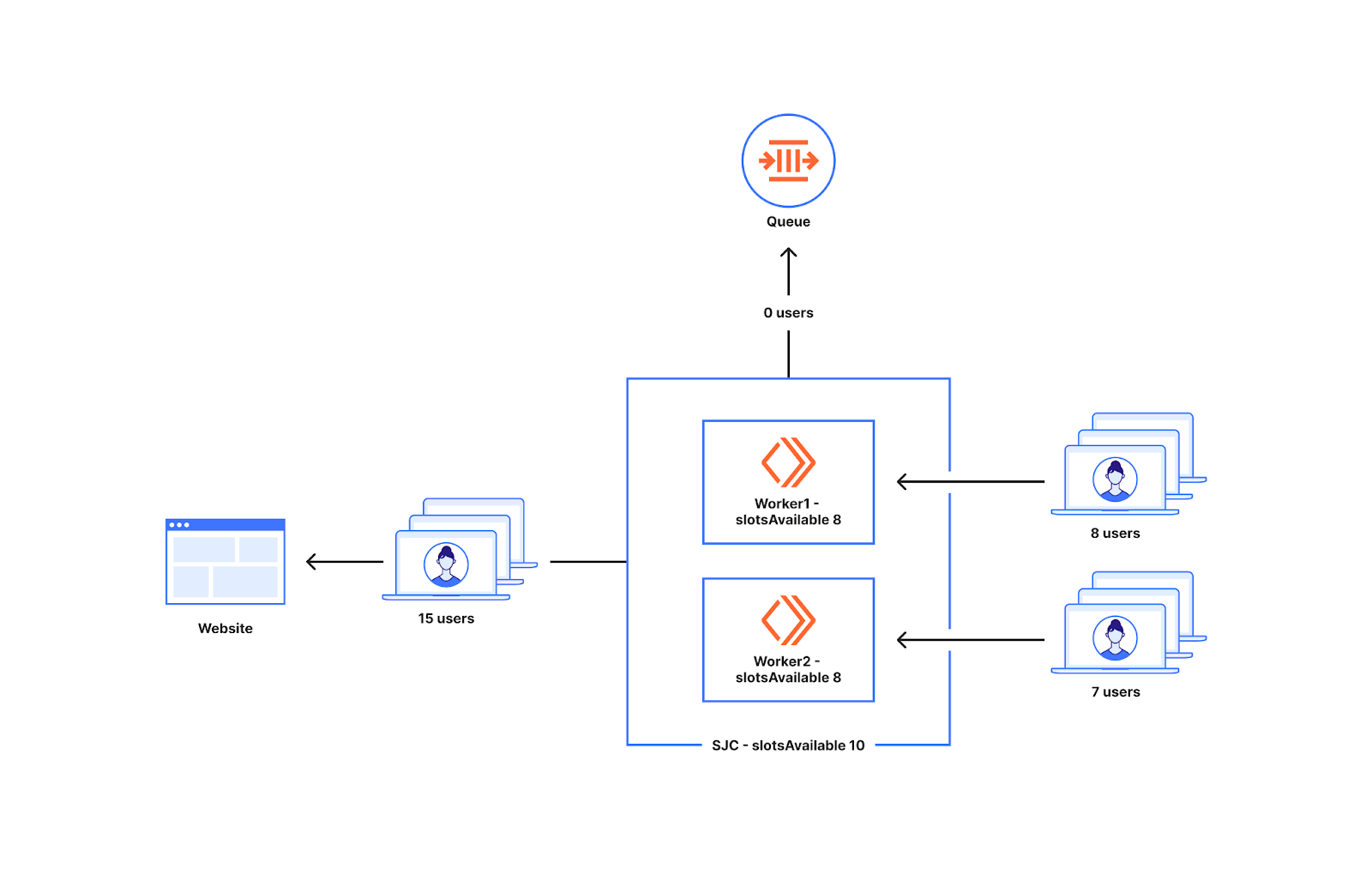
さまざまな顧客やトラフィックの種類に対応する弊社では、これが問題になるケースを検証することが可能でした。低い利用水準からのトラフィックスパイクは、グローバルでのリミットのオーバーシュートを引き起こす可能性があります。低い制限値で過剰にプロビジョニングしているため、トラフィック制限を大幅に超過するリスクが高まるのがその理由です。交通量が制限に比して少ないときに待ち行列ができる可能性を減らすと同時に、制限を超えないより安全なアプローチを導入する必要がありました。
少し戻って弊社のアプローチについて考えてみると、データセンター内のトラフィックは、データセンター内に見られるWorkerの数に直接相関することを前提としていました。実際には、これはすべての顧客に当てはまるわけではないことがわかったのです。たとえトラフィックがWorkerの数と相関していたとしても、データセンターのWorkerに向かう新規ユーザーは相関しないかもしれないのです。というのも、弊社が割り当てるスロットは新規ユーザーのためのものであるものの、データセンターが目にするトラフィックは、すでにWebサイトにアクセスしているユーザーとWebサイトにアクセスしようとする新規ユーザーの両方で構成されているためです。
次のセクションでは、Workerの数を用いず、代わりにWorkerがデータセンター内の他のWorkerと通信するアプローチについてお話しします。これに際し、弊社ではDurable Objectカウンターという新しいサービスを導入しました。
データセンターカウンターを導入することで、スロット分割回数を減らす
上記の例から、Workerレベルでのオーバープロビジョニングは、データセンターに割り当てられている以上のスロットを使用するリスクがあることがわかりました。低レベルで過剰供給しなければ、最初に説明したように、設定された上限に達する前にユーザーがキューに入るリスクがあります。この両方を達成できる解決策が必要となります。
オーバープロビジョニングは、不均等な数の新規ユーザーがWorkerに達した際、Workerがすぐにスロットを使い果たさないようにするために行われていました。データセンター内の2つのWorker間での通信方法があれば、データセンター内のWorker間でスロットを分ける必要はありません。その通信を実現するため、カウンターを導入しました。カウンターは、データセンター内のWorkerをカウントする、一群の小型のdurable objectです。
Workerカウントが使用されることを回避するに当たりどのように役立つかを理解するため、下図を見てみましょう。下のデータセンターカウンターには2つのWorkerが通信しています。先ほど説明したように、Workerは待機室の状態に基づいてユーザーをWebサイトに通しています。この際、通過させたユーザーの数はWorkerのメモリに保存されます。カウンターを導入することで、これがデータセンターカウンターで行われるようになります。新しいユーザーがWorkerに要求を出すたびに、Workerはカウンターに通信し、カウンターの現在値を知ることになります。以下の例では、Workerに対する最初の新しいリクエストに対し、受信したカウンターの値は9となっています。データセンターに10スロットの空きがある場合、そのユーザーはWebサイトにアクセスできることになります。次のWorkerが新しいユーザーを受信し、その直後にリクエストした場合10の値が得られ、Workerの利用可能なスロット数に基づきユーザーがキューに入れられようになります。
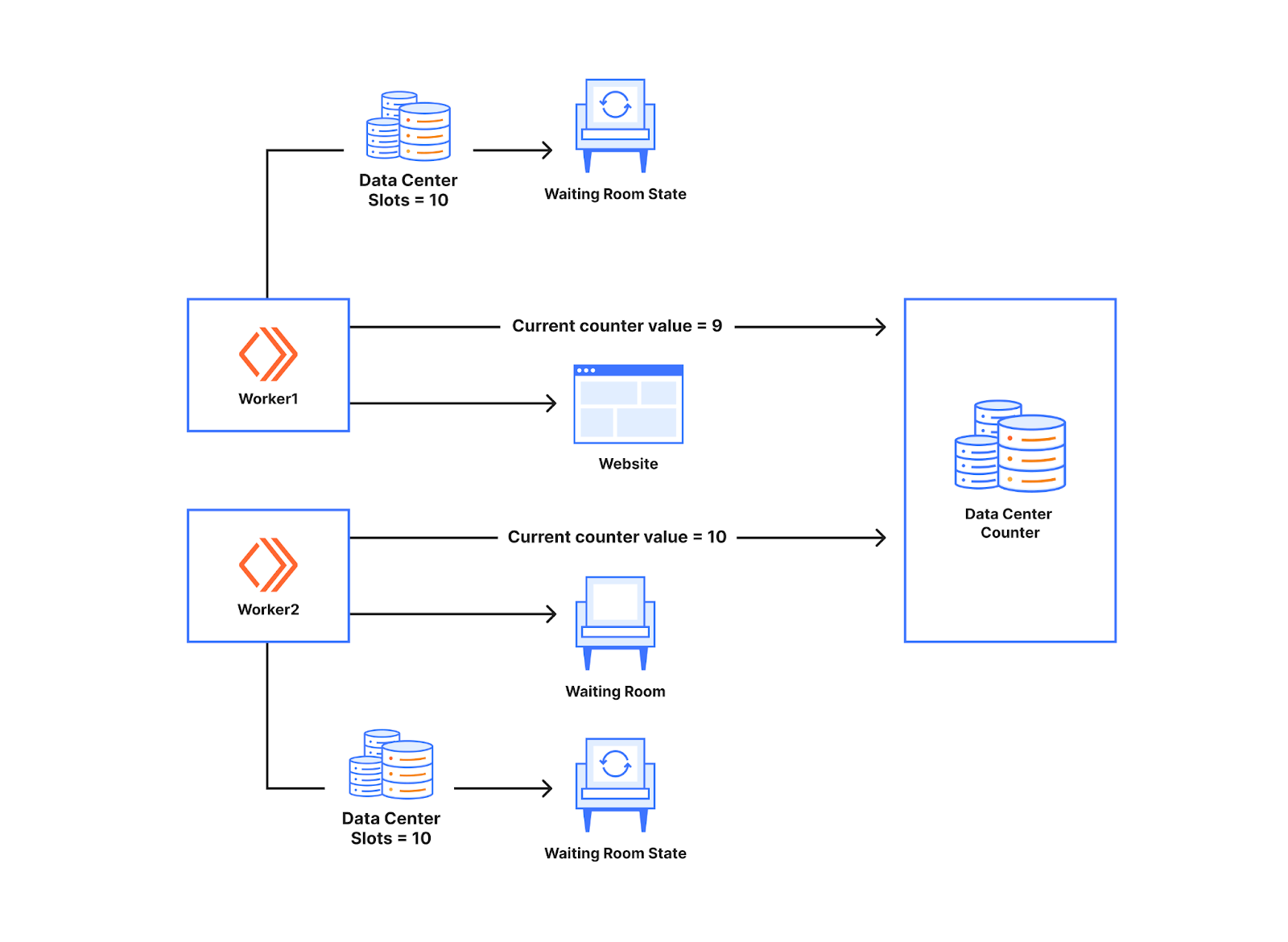
データセンターカウンターは、待機室のWorkerの同期ポイントとして機能すします。基本的に、これはWorker同士が直接通信することなくやり取りできるようにするものです。発券カウンターの仕組みに似ています。あるWorkerが誰かを入場させるたびに、カウンターからチケットを要求します。そのため、別のWorkerがカウンターからチケットを要求しても、同じチケット番号を得ることはない。チケットの持つ価値が有効であれば、新しいユーザーはWebサイトに行くことができます。そのため、Workerに異なる数の新規ユーザーが現れても、データセンター用のカウンターが使用スロット数を計算するため、Workerに対し過剰に割り当てたり、不足したりすることは起こりません。
下図は、Workerに届く新規ユーザーの数が不均等な場合の動作を示したものです。1つは7人の新規ユーザーを獲得し、もう1つのWorker は1人の新規ユーザーを獲得します。下図のWorkerに現れた8人のユーザーは、データセンターで利用可能なスロットが10であり、10を下回っているため、すべてWebサイトにアクセスできます。
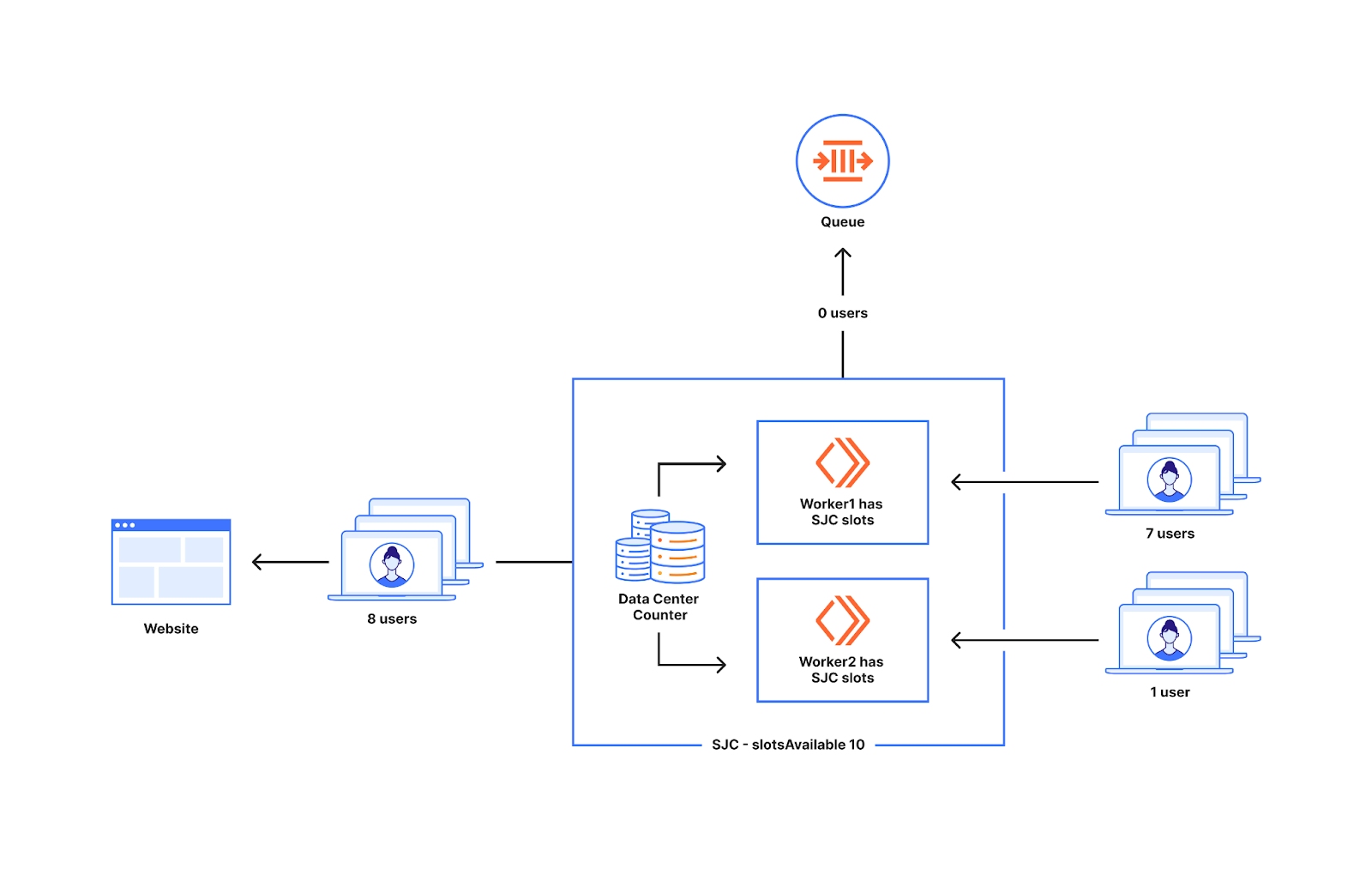
カウンターの値がデータセンターのslotsAvailableと等しい場合は余分なユーザーを送らないため、これも余分なユーザーをWebサイトに送る原因とはなりません。下図のWorkerに現れた15人のユーザーのうち、10人がWebサイトにアクセスし、5人がキューに入れられることになります。
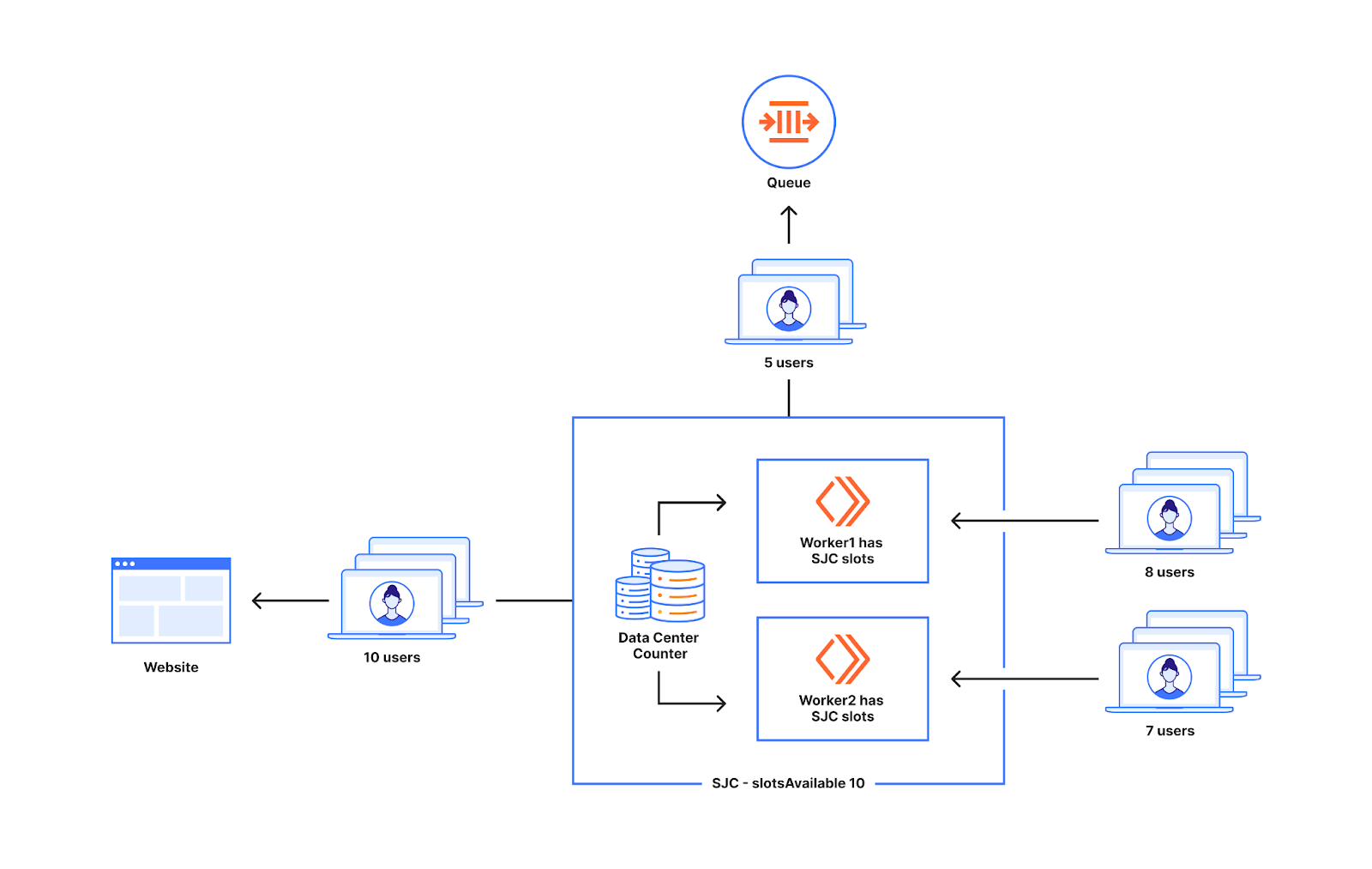
カウンターがWorker同士の意思疎通を助けるため、稼働率が低くても過剰なプロビジョニングを行うリスクは発生しません。
これをさらに理解するために、先に説明した例に戻り、実際の待機室状態でどのように機能するかを見てみましょう。
顧客の待機室の状態は、以下の通りとなっています。
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
状況からのこの情報を使う必要がないように、労働者間で枠を分けないことが目的となります。Mon, 11 Sep 2023 11:45:54 GMTの時点で、サンノゼにリクエストが来ています。つまり、サンノゼから送れる枠は150のうち10%の15となります。
サンノゼのDurable Objectカウンターは、データセンターに新しいユーザーが来るたびに、その時点のカウンターの値を返し続けます。Workerに戻った後、値を1増やします。つまり、Workerに最初に来た15人の新規ユーザーは、ユニークなカウンターの値を得ることになります。したがって、あるユーザーの受信値が15未満の場合、そのユーザーはデータセンターのスロットを使用することができることになります。
データセンターで利用可能なスロットがなくなると、ユーザーはAnywhereデータセンターに割り当てられたスロットを利用することができます。サンノゼのWorkerのチケットの値が15となった時点で、サンノゼのスロットを使ってWebサイトにアクセスすることは不可能だとわかります。
Anywhereスロットは、地球上のすべてのアクティブなWorker、つまり残りの150スロットの75%に相当する113か所で利用できます。AnywhereスロットはDurable Objectによって処理され、異なるデータセンターのWorkerがAnywhereスロットを使用したいときに通信できます。128人(113人+15人)のユーザーがこの顧客の同じWorkerに殺到した場合でさえ、キューに入れることはありません。これにより、世界中のWorkerに向かう新規ユーザーの数が不均等でも待機室が処理できるようになり、その結果、顧客が設定された上限に近い数までキューに入れられるようになります。
カウンターが発揮する威力
弊社が待機室を構築したとき、Webサイトへのエントリーの決定は、リクエストがWebサイトに対し実行されているときに他のサービスと通信することなく、Worker自体のレベルで行われるようにした糸感が手ました。ユーザーのリクエストに遅延が加わるのを避けるために、これが必要だったのです。耐久性のあるオブジェクトカウンターに同期ポイントを導入することは、Durable Objectカウンターへの呼び出しを導入することになり、それから逸脱していることになります。
しかし、データセンターのDurable Objectは同じデータセンター内に留まります。このため、追加で発生する遅延は最小となり、通常は10 ms未満となります。Anywhereデータセンターを処理するDurable Objectへの呼び出しの場合、Workerは海を渡ったり長距離を横断したりする必要があります。このような場合、遅延は約60msまたは70msになる可能性があります。より遠距離のデータセンターに向かうコールのため、以下に示す95パーセンタイルの値はより高くなります。
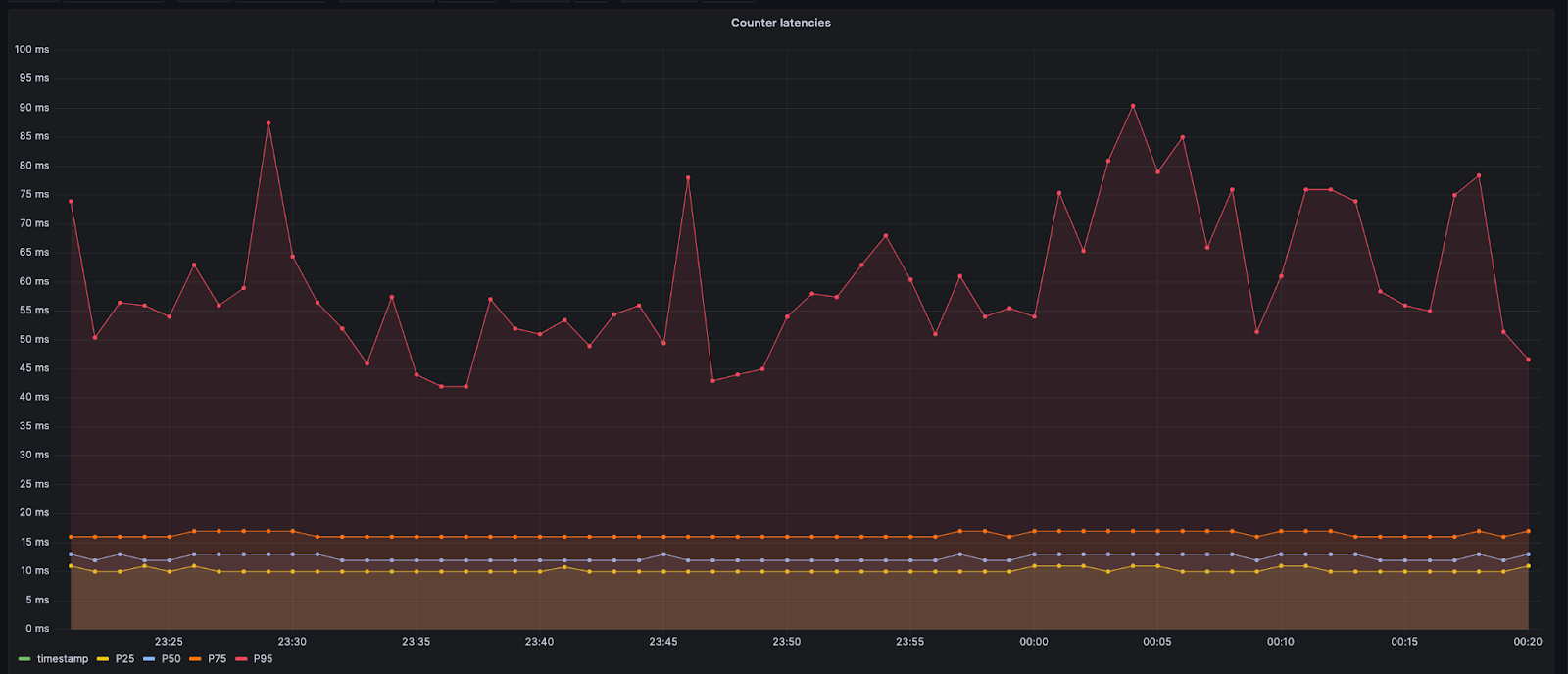
設計上カウンターを追加するとの決断は、Webサイトに初めてアクセスするユーザーにとって、若干の余分な遅延が発生することになります。上限に達する前にキューに入れられるユーザー数を減らすことができるため、トレードオフは許容範囲と判断しました。さらに、カウンターは新規ユーザーがWebサイトに入ろうとするときにのみ必要となります。新規の利用者がオリジンに到達すると、Workerから直接、入ることを許可されます。入場の証明は利用者が持ってきたクッキーに記載されているため、これをもとに入場を許可できます。
カウンターは至極シンプルなサービスであり、単純なカウントを行う以外、他には何もしません。これにより、カウンターのメモリとCPUフットプリントは非常に小さくなります。さらに、弊社は世界中に多くのカウンターを配置し、Workerのサブセット間の調整を処理しています。これにより、Workerからの同期要求の負荷をカウンターがうまく処理できます。これらの要素が積み重なり、カウンターは弊社のユースケースにとって実行可能なソリューションとなったのです。
まとめ
Waiting Roomは、合法的なトラフィックの量や急増に関係なく、顧客のサイトを確実に稼働させることを第一に考えて設計しています。Waiting Roomは、100カ国300以上の都市にまたがるCloudflareのネットワーク内のすべてのサーバーで稼働しています。弊社は、すべての新規ユーザーに対して、Webサイトに行くかキューに行くかの決定を、最小限の遅延で適切なタイミングにて行えるようにしたいと考えています。データセンターであまり早くキューイングすると、顧客が設定した上限よりも早くキューイングしてしまう可能性があるため、この判断は難しくなります。キューイングが遅すぎると、顧客が設定したリミットをオーバーシュートしてしまう可能性があります。
弊社の当初のアプローチでは、Workerに均等に枠を割り振っていたためキューに入れるのが早すぎることもあったものの、顧客が設定した上限の尊重においてはかなり優れた結果が得られました。次のアプローチでは、利用率が低いとき(顧客の制限に比べトラフィックレベルが低いとき)により多くのスロットを与えることにより、顧客の設定した上限よりも早くキューに入れたケースでもWorkerの各スロットがより多く使えるため、さらに優れた結果が得られました。しかしこれまで見てきたように、利用率が低い期間が続いた後に突然トラフィックが急増した場合、オーバーシュートする可能性が高くなりました。
カウンターを使えば、Worker カウントによるスロットの分割を避けることができ、両者の長所を得ることができます。カウンターの使用により、顧客が設定した上限に基づき、早すぎたり遅すぎたりすることなくキューを設けることができます。新しいユーザーからのリクエストに対しわずかな遅延の犠牲を払うことになるものの、それはごくわずかであり、早くからキューに入れられるよりも優れたユーザーエクスペリエンスを生み出すことがわかりました。
弊社は、常に適切なタイミングでユーザーをキューイングし、何よりも顧客のWebサイトを保護するため、このアプローチを反復し続けていきます。より多くの顧客がWaiting Roomを利用するにつれ、弊社はさまざまなトラフィックのタイプについてより多くのことを学んでおり、あらゆる方面にとってより優れた製品の構築に役立っています。