
Vor fast drei Jahren haben wir Cloudflare Waiting Room auf den Markt gebracht, um die Websites unserer Kunden vor Spitzen im legitimen Datenverkehr zu schützen, die ihre Websites zum Absturz bringen könnten. Waiting Room gibt den Kunden die Kontrolle über die Benutzererfahrung, und zwar selbst in Zeiten hohen Traffic-Aufkommens. Dafür wird überschüssiger Datenverkehr in einen anpassbaren, markengerechten Warteraum geleitet. Nutzer werden dynamisch zugelassen, wenn Plätze auf den Websites frei werden. Seit der Einführung von Waiting Room haben wir die Funktionalität auf Grundlage von Kundenfeedback mit Features wie einer Unterstützung für Mobilgeräte-Apps, Analysen, Regeln zur Umgehung von Waiting Room und einigem mehr erweitert.
Wir lieben es, neue Funktionen vorzustellen und für unsere Kunden Probleme zu lösen, indem wir die Möglichkeiten von Waiting Room erweitern. Heute möchten wir Ihnen jedoch einen Blick hinter die Kulissen ermöglichen, um Ihnen zu zeigen, wie wir den Kernmechanismus unseres Produkts weiterentwickelt haben. Es geht also darum, wie es bei hohem Traffic-Aufkommen den Datenverkehr in einer Warteschlange einspeist.
Wie wurde Waiting Room entwickelt und was sind die Herausforderungen?
Das folgende Diagramm gibt einen schnellen Überblick darüber, wo Waiting Room angesiedelt ist, wenn ein Kunde die Funktion für seine Website aktiviert.
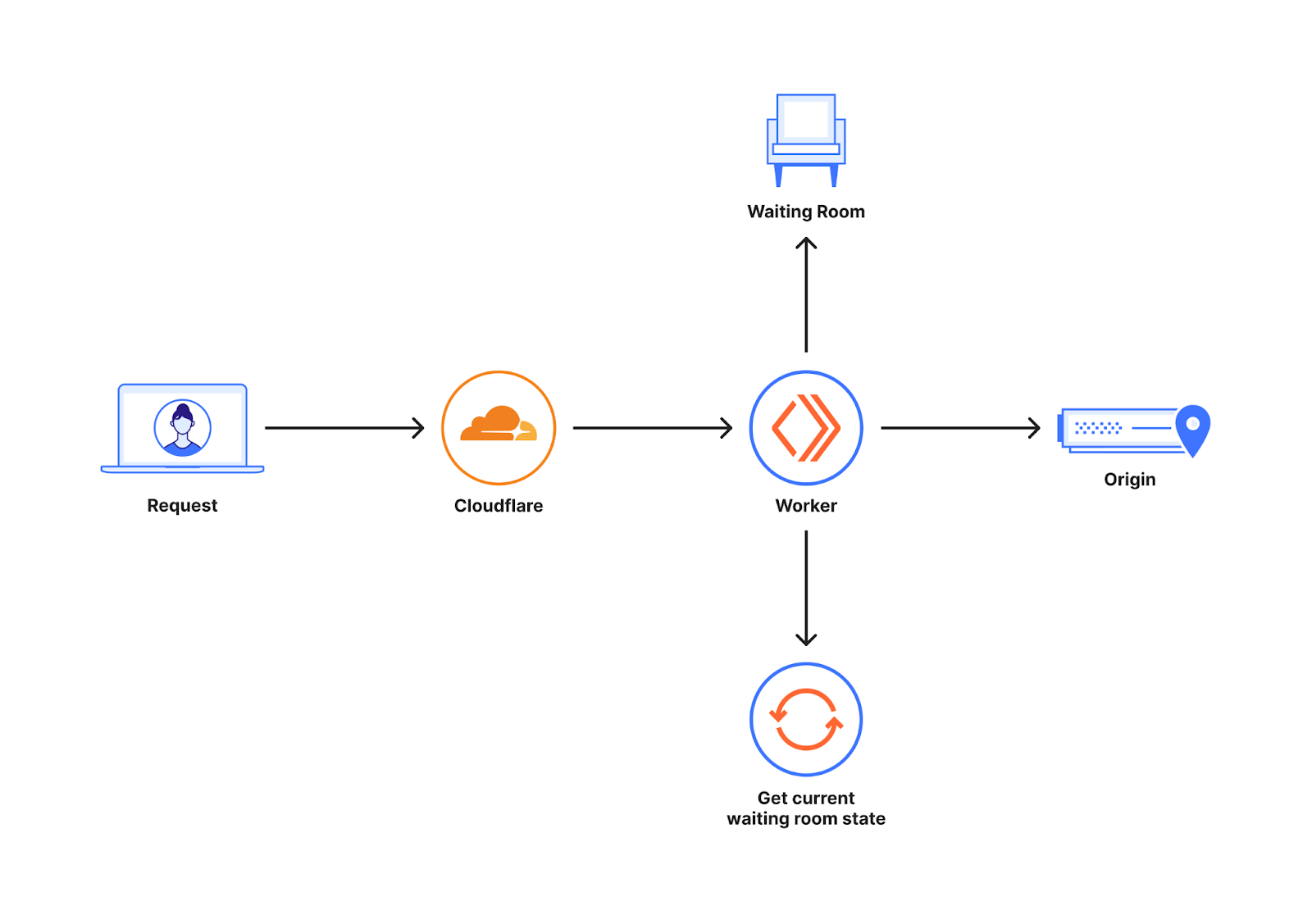
Waiting Room ist auf unserem Produkt Workers aufgebaut, das in einem globalen Netzwerk von Cloudflare-Rechenzentren betrieben wird. Die Anfragen an die Website eines Kunden können an viele verschiedene Cloudflare-Rechenzentren geleitet werden. Um minimale Latenz und eine verbesserte Performance zu erreichen, werden sie an das Rechenzentrum geleitet, das sich räumlich in geringstmöglicher Entfernung befindet. Stellt ein neuer Nutzer eine Anfrage an den von Waiting Room abgedeckten Host/Pfad, entscheidet der Worker von Waiting Room, ob er den Nutzer an den Ursprungsserver oder an den Warteraum weiterleitet. Diese Entscheidung wird anhand des Status des jeweiligen Warteraums getroffen. Dieser gibt Aufschluss darüber, wie viele Nutzer gerade auf den Ursprungsserver zugreifen.
Der Status ändert sich ständig in Abhängigkeit des weltweiten Traffics. Diese Information kann entweder an einem zentralen Ort gespeichert werden oder die Änderungen können nach und nach an alle Standorte weltweit übertragen werden. Die Speicherung dieser Informationen an einem zentralen Ort kann bei jeder Anfrage zu einer erheblichen Latenz führen, weil der zentrale Ort unter Umständen sehr weit von dem Ort entfernt ist, von dem die Anfrage ausgeht. Daher arbeitet jedes Rechenzentrum mit einem eigenen Wartesaalstatus, der eine Momentaufnahme des zu diesem Zeitpunkt weltweit verfügbaren Traffic-Musters für die betreffende Website darstellt. Wir wollen nicht auf Informationen aus anderen Teilen der Welt warten, bevor wir einem Nutzer Zugang zu der Website gewähren, da das zu einer erheblichen Latenz bei der Anfrage führt. Deshalb haben wir uns gegen eine zentrale Stelle und für eine Pipeline entschieden, über die Änderungen im Datenverkehr nach und nach in der ganzen Welt verbreitet werden.
Diese Pipeline, die den Status des Warteraums im Hintergrund aus verschiedenen Daten ermittelt, beruht auf Durable Objects von Cloudflare. Im Jahr 2021 haben wir einen Blogbeitrag verfasst, in dem die Funktionsweise der Aggregations-Pipeline und die verschiedenen Design-Entscheidungen beschrieben werden, die wir dabei getroffen haben – für den Fall, dass Sie sich dafür interessieren. Diese Pipeline sorgt dafür, dass jedes Rechenzentrum innerhalb weniger Sekunden aktualisierte Informationen über Änderungen im Datenverkehr erhält.
Waiting Room muss auf Grundlage des aktuellen Status entscheiden, ob Nutzer zur Website weitergeleitet oder in eine Warteschlange eingereiht werden. Die Warteschlange muss zum richtigen Zeitpunkt eingerichtet werden, damit die Website des Kunden nicht unter der Last zusammenbricht. Gleichzeitig darf aber auch nicht zu früh eine Warteschlange geschaffen werden, weil es am Ende möglicherweise doch nicht zu dem erwarteten Anstieg des Traffic kommt. In diesem Fall könnte eine Warteschlange dazu führen, dass manche Nutzer den Aufruf der Website abbrechen. Waiting Room läuft auf jedem Server im Cloudflare-Netzwerk, das sich über 300 Städte in mehr als 100 Ländern erstreckt. Wir wollen sicherstellen, dass für jeden neuen Nutzer die Entscheidung darüber, ob er auf die Website oder in die Warteschlange geleitet wird, mit minimaler Latenz erfolgt. Das stellt Waiting Room vor eine Herausforderung. In diesem Blogbeitrag erläutern wir, wie wir an dieses Dilemma herangetreten sind. Unser Algorithmus hat sich weiterentwickelt, um die Zahl der Fehlalarme zu verringern und gleichzeitig die vom Kunden gesetzten Grenzen zu respektieren.
So entscheidet Waiting Room über die Einreihung in eine Warteschlange
Maßgeblich für die Entscheidung von Waiting Room, mit der Warteschlangenbildung zu beginnen, ist Ihre Konfiguration der Traffic-Einstellungen. Bei der Konfiguration eines Warteraums können Sie zwei Grenzwerte für den Datenverkehr festlegen: die Gesamtzahl der aktiven Nutzer und die Anzahl der neuen Nutzer pro Minute. Die Gesamtzahl der aktiven Nutzer ist ein Zielschwellenwert für die Anzahl der Nutzer, die gleichzeitig auf den von Waiting Room abgedeckten Seiten zugelassen sein sollen. Die Anzahl der neuen Nutzer pro Minute ist der Schwellenwert für die maximale Anzahl von Nutzern, die pro Minute auf Ihre Website zugreifen. Ein sprunghafter Anstieg einer dieser Werte kann zu einer Warteschlange führen. Eine weitere Konfiguration, die sich auf die Berechnung der insgesamt aktiven Nutzer auswirkt, ist die Sitzungsdauer. Ein Nutzer gilt für die Minuten der Sitzungsdauer als aktiv, da die Anfrage an eine beliebige Seite gestellt wird, für die ein Warteraum besteht.
Das folgende Diagramm stammt von einem unserer internen Überwachungstools für einen Kunden und zeigt das Muster des Traffics eines Kunden für einen Zeitraum von zwei Tagen. Dieser Kunde für neue Nutzer pro Minute und aktive Nutzer insgesamt jeweils eine Obergrenze von 200 festgelegt.
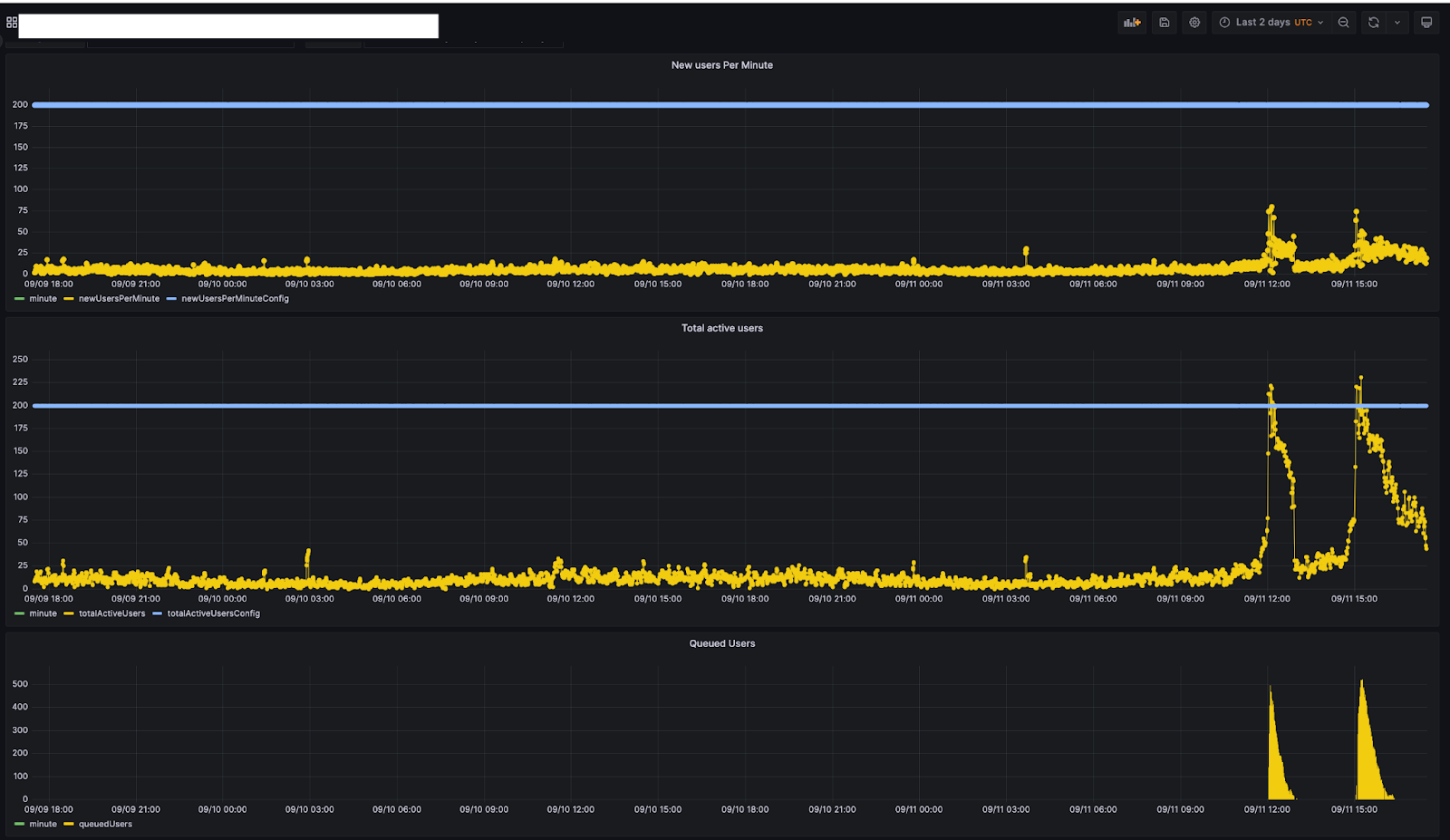
Wenn Sie sich den Datenverkehr ansehen, stellen Sie fest, dass am 11. September gegen 11:45 Uhr Nutzer in eine Warteschlange eingereiht wurden. Zu diesem Zeitpunkt lag die Gesamtzahl der aktiven Nutzer bei etwa 200. Als die Gesamtzahl der aktiven Nutzer (gegen 12:30 Uhr) zurückging, sank die Zahl der Nutzer in der Warteschlange auf 0. Am 11. September gegen 15:00 Uhr, als die Gesamtzahl der aktiven Nutzer bei 200 lag, begann die Warteschlangenbildung erneut. Mit der Einreihung von Nutzern in eine Warteschlange zu diesem Zeitpunkt wurde dafür gesorgt, dass der Datenverkehr auf der Website innerhalb der vom Kunden festgelegten Grenzen blieb.
Sobald ein Nutzer Zugang zur Website erhält, erhält er von uns ein verschlüsseltes Cookie. Dies zeigt an, dass er bereits Zugang erhalten hat. Der Inhalt des Cookies kann wie folgt aussehen.
{
"bucketId": "Mon, 11 Sep 2023 11:45:00 GMT",
"lastCheckInTime": "Mon, 11 Sep 2023 11:45:54 GMT",
"acceptedAt": "Mon, 11 Sep 2023 11:45:54 GMT"
}
Das Cookie ist wie ein Ticket, das den Eintritt in den Warteraum anzeigt. Die bucketId gibt an, zu welcher Gruppe von Nutzern dieser Nutzer gehört. Der acceptedAt-Zeitpunkt und die lastCheckInTime verraten, wann die letzte Interaktion mit den Workern erfolgt ist. Diese Informationen erlauben es, die Gültigkeit des Tickets für den Eintritt zu überprüfen, indem ein Abgleich mit dem Wert der Sitzungsdauer stattfindet, den der Kunde bei Konfiguration des Warteraums festgelegt hat. Ist das Cookie gültig, lassen wir den Nutzer passieren. So wird gewährleistet, dass Nutzer, die sich auf der Website befinden, dort auch weiterhin surfen können. Ist das Cookie ungültig, erstellen wir ein neues, das den Nutzer als neuen Nutzer ausweist. Besteht für die Website eine Warteschlange, wird er dann an deren Ende eingereiht. Im nächsten Abschnitt werden wir uns anschauen, wie wir entscheiden, wann diese Nutzer in die Warteschlange eingespeist werden.
Um den gesamten Vorgang verständlicher zu machen, sehen wir uns den Inhalt des Warteraum-Status an. Für den oben erwähnten Kunden könnte der Status zum Zeitpunkt „Mon, 11 Sep 2023 11:45:54 GMT“ wie folgt aussehen:
{
"activeUsers": 50,
}
Wie bereits erwähnt, hat der Kunde in seiner Konfiguration für die Zahl der neuen Nutzer pro Minute und die Gesamtzahl der aktiven Nutzer jeweils eine Obergrenze von 200 festgelegt.
Der Status zeigt also an, dass es noch Platz für neue Nutzer gibt, da aktuell nur 50 aktive Nutzer verzeichnet werden, während bis zu 200 möglich wären. Es ist daher noch Platz für weitere 150 Nutzer. Nehmen wir an, dass diese 50 Nutzer aus einem Rechenzentren in San Jose (20 Nutzer) und einem in London (30 Nutzer) kommen. Wir verfolgen auch die Zahl der weltweit aktiven Worker und die Zahl der Worker, die in dem Rechenzentrum aktiv sind, in dem der Status berechnet wird. Der nachstehende Statusschlüssel könnte in San Jose berechnet worden sein.
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Nehmen wir an, dass wir zum Zeitpunkt „Mon, 11 Sep 2023 11:45:54 GMT“ eine Anfrage an den Warteraum in dem Rechenzentrum in San Jose erhalten.
Um zu sehen, ob der Nutzer, dessen Anfrage San Jose erreicht hat, Zugang zum Ursprungsserver erhält, überprüfen wir zunächst den Traffic-Verlauf der letzten Minute, um die Verteilung des Datenverkehrs zu dieser Zeit zu sehen. Der Grund dafür ist, dass viele Websites in bestimmten Teilen der Welt sehr beliebt sind. Bei nicht wenigen dieser Websites kommt der Datenverkehr in der Regel aus denselben Rechenzentren.
Wenn wir uns den Traffic-Verlauf für die Minute „Mon, 11 Sep 2023 11:44:00 GMT“ ansehen, stellen wir fest, dass San Jose zu dieser Zeit 20 der maximal möglichen Zahl von 200 Nutzern verzeichnet (10 %) hat. Für die aktuelle Zeit „Mon, 11 Sep 2023 11:45:54 GMT“ teilen wir die auf der Website verfügbaren Slots im gleichen Verhältnis auf wie bei dem Datenverkehrsverlauf der vorangegangenen Minute. Wir können also 10 % der 150 verfügbaren Slots von San Jose freigeben, was 15 Nutzern entspricht. Wir wissen auch, dass drei Worker aktiv sind, da der Wert von „dataCenterWorkersActive“ 3 ist.
Die Anzahl der für das Rechenzentrum verfügbaren Slots wird gleichmäßig auf die Worker im Rechenzentrum aufgeteilt. Jeder Worker in San Jose kann also 15/3 Nutzer auf die Website schicken. Wenn der Worker, der den Datenverkehr erhalten hat, in der laufenden Minute keine Nutzer zu dem Ursprungsserver geleitet hat, kann er bis zu fünf Nutzer (15/3) senden.
Nehmen wir nun an, dass zur gleichen Zeit („Mon, 11 Sep 2023 11:45:54 GMT“) eine Anfrage an ein Rechenzentrum in Delhi eingeht. Der Worker im Rechenzentrum in Delhi prüft die „trafficHistory“ und stellt fest, dass keine Slots für diese Anfrage zugewiesen sind. Für diesen Traffic haben wir die Anywhere-Slots reserviert, da wir wirklich weit von der Obergrenze entfernt sind.
{
"activeUsers":50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Die Anywhere-Slots werden unter allen aktiven Workern auf der ganzen Welt aufgeteilt. Es kann sich also jeder Worker rund um den Globus ein Stück von diesem Kuchen sichern. Es verbleiben 150 Slots, und 75 % davon sind 113.
Der Statusschlüssel hält auch die Anzahl der Worker (globalWorkersActive) fest, die auf der ganzen Welt entstanden sind. Die zugewiesenen Anywhere-Slots werden unter allen aktiven Workern weltweit aufgeteilt, sofern verfügbar. Der Wert für globalWorkersActive ist 10, wenn wir uns den Waiting Room-Status ansehen. Wenn die zehn aktiven Worker die 113 Slots gleichmäßig untereinander aufteilen, entfallen auf jeden von ihnen ungefähr 11 Nutzer, die sie weiterleiten können. Die ersten 11 Nutzer, die in der Minute Mon, 11 Sep 2023 11:45:00 GMT einen Worker erreichen, werden also zum Ursprungsserver vorgelassen. Alle weiteren Nutzer landen in einer Warteschlange. Mit den zuvor erwähnten (fünf) zusätzlichen reservierten Slots in San Jose für die Minute Mon, 11 Sep 2023 11:45:00 GMT wird sichergestellt, dass wir bis zu 16 (5 + 11) Nutzern von einem Worker aus San Jose Zugang zur Website gewähren können.
Die Warteschlangenbildung auf Worker-Ebene kann dazu führen, dass Warteschlangen schon vor Füllung aller verfügbaren Slots gebildet werden
Wie aus dem obigen Beispiel hervorgeht, wird auf Worker-Ebene entschieden, ob eine Warteschlange gebildet wird. Die Anzahl der neuen Nutzer, die an die Worker auf der ganzen Welt verteilt werden, kann unterschiedlich sein. Das folgende Diagramm verdeutlicht, was bei einer ungleichmäßigen Verteilung des Datenverkehrs auf zwei worker passieren kann.
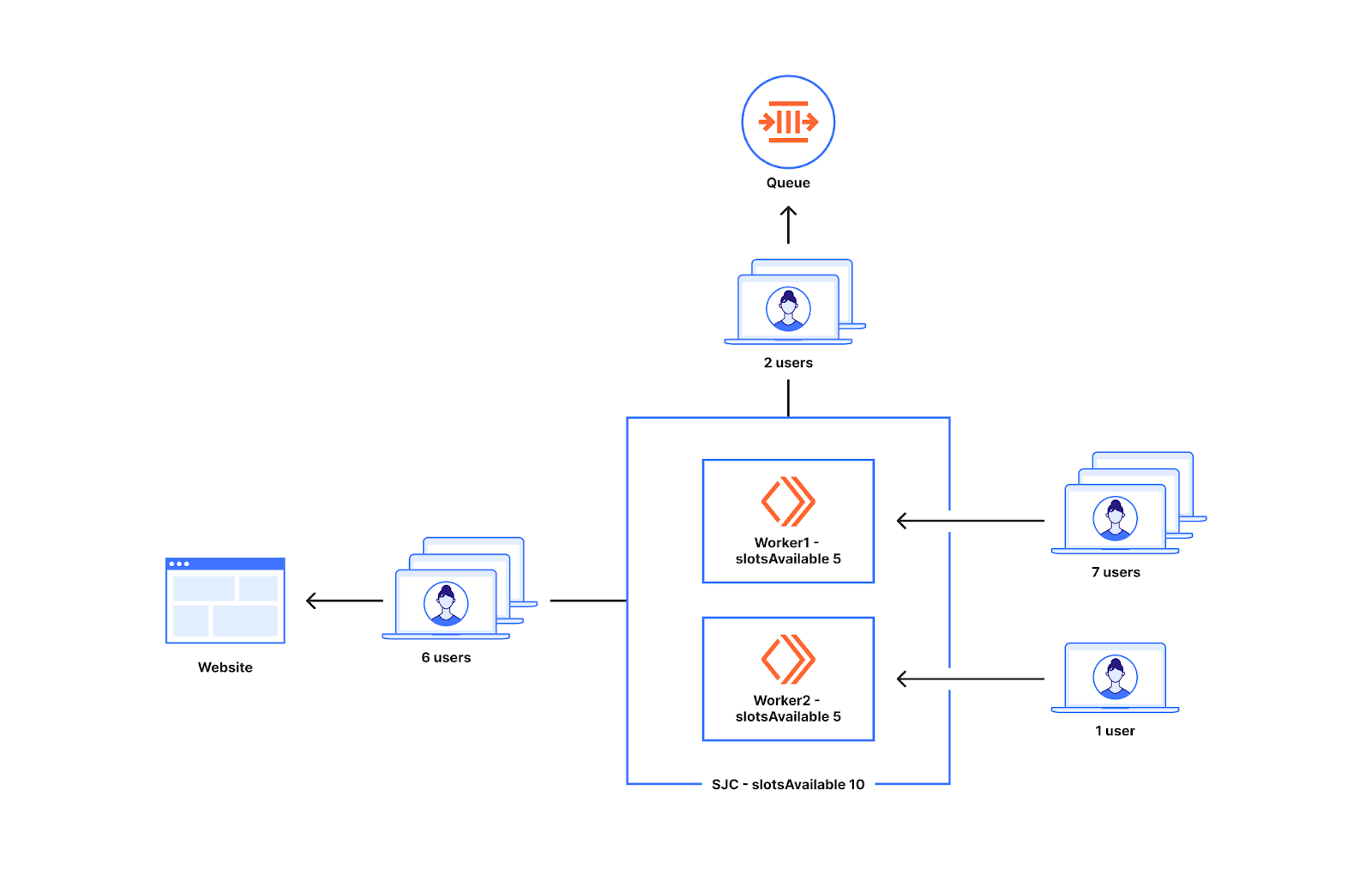
Angenommen, in einem Rechenzentrum in San Jose sind zehn Slots verfügbar. In San Jose sind zwei Worker im Einsatz. Sieben Nutzer gehen an Worker1 und einer geht an Worker2. In dieser Situation erlaubt Worker1 fünf der sieben Nutzer Zugang zur Website. Zwei von ihnen werden in die Warteschlange gestellt, da Worker1 nur fünf Slots zur Verfügung hat. Der eine Nutzer, der bei Worker2 landet, wird ebenfalls zum Ursprungsserver vorgelassen. Somit werden zwei Nutzer in die Warteschlange eingereiht, während in Wirklichkeit zehn Nutzer vom Rechenzentrum in San Jose freigegeben werden können, wenn nur acht Nutzer erscheinen.
Dieses Problem bei der gleichmäßigen Verteilung der Slots auf die Worker führt dazu, dass Warteschlangen bereits vor den konfigurierten Traffic-Obergrenzen eines Warteraums gebildet werden. Üblicherweise beträgt der Abstand zum Limit 20–30 %. Dieser Ansatz bringt Vorteile mit sich, die wir im Folgenden erörtern werden. Wir haben unsere Herangehensweise angepasst, um die Häufigkeit von Warteschlangen außerhalb des 20–30 %-Bereichs zu verringern und die Warteschlangen so nah wie möglich an den Obergrenzen zu halten. Gleichzeitig wollen wir sicherstellen, dass der Warteraum darauf vorbereitet ist, Traffic-Spitzen abzufedern. Im weiteren Verlauf dieses Blogbeitrags werden wir darauf eingehen, wie uns das durch eine Anpassung bei der Zuweisung und Zählung von Slots gelungen ist.
Worin besteht der Vorteil, wenn Worker diese Entscheidungen treffen?
Im obigen Beispiel ging es darum, wie ein Worker in San Jose und Delhi darüber entscheidet, ob Nutzer zum Ursprungsserver vorgelassen werden. Der Vorteil von Entscheidungen auf Worker-Ebene besteht darin, dass diese gefällt werden können, ohne dass sich die Latenz der Anfrage dadurch signifikant erhöht. Das liegt daran, dass für die Entscheidungsfindung das Rechenzentrum nicht verlassen werden muss, um Informationen über den Warteraum zu erhalten – schließlich arbeiten wir immer mit dem Status, der im Rechenzentrum gerade verfügbar ist. Die Warteschlangenbildung beginnt, wenn die Slots innerhalb des Workers aufgebraucht sind. Das Fehlen zusätzlicher Latenzzeiten ermöglicht es den Kunden, den Warteraum jederzeit einzuschalten, ohne sich über zusätzliche Latenzzeiten für ihre Benutzer Gedanken zu machen.
Bei Waiting Room geht es vor allem darum sicherzustellen, dass die Websites der Kunden jederzeit betriebsbereit sind – selbst bei unerwarteten und überwältigenden Datenverkehrsspitzen. Zu diesem Zweck ist es von entscheidender Bedeutung, dass bei einem Warteraum die Priorität darin besteht, in der Nähe der vom Kunden für den Traffic festgelegten Obergrenzen zu bleiben oder diese zu unterschreiten. Wenn in einem Rechenzentrum irgendwo auf der Welt, z. B. in San Jose, eine Datenverkehrsspitze auftritt, dauert es einige Sekunden, bis die Information über den lokalen Status nach Delhi gelangt.
Durch die Verteilung der Slots auf verschiedene Worker wird sichergestellt, dass die Nutzung leicht veralteter Daten nicht dazu führt, dass das Gesamtlimit deutlich überschritten wird. Der Wert für activeUsers kann beispielsweise im Rechenzentrum in San Jose 26 und in dem anderen Rechenzentrum, in dem die Traffic-Spitze auftritt, 100 betragen. Zu diesem Zeitpunkt kann das Senden zusätzlicher Nutzer aus Delhi nicht dazu führen, dass die Gesamtobergrenze weit überschritten wird, weil man dort von vornherein nur über einen Teil des Kuchens verfügt. Daher ist die Bildung von Warteschlangen vor dem Erreichen des Gesamtlimits Teil des Konzepts. So wird dafür gesorgt, dass die Gesamtobergrenzen eingehalten werden. Im nächsten Abschnitt werden wir uns mit den Ansätzen befassen, die wir implementiert haben, um die Warteschlangen so nah wie möglich an die Schwellenwerte heranzuführen, ohne das Risiko einer Überschreitung zu erhöhen.
Zuweisung von mehr Slots bei geringem Traffic-Aufkommen im Verhältnis zu den Warteraumgrenzen
Zunächst wollten wird die Warteschlangenbildung angehen, die auftritt, wenn das Datenverkehrsaufkommen noch weit von den Grenzwerten entfernt ist. Dieser Fall ist selten und erstreckt sich in der Regel für die Endnutzer, die sich in der Warteschlange befinden, nur über ein Auffrischungsintervall (20 Sekunden). Trotzdem hatte dies für uns bei der Aktualisierung unseres Warteschlangen-Algorithmus oberste Priorität. Um dieses Problem zu lösen, haben wir uns bei der Zuweisung von Slots die Auslastung (also wie weit man von den Traffic-Obergrenzen entfernt ist) angesehen und mehr Slots zugewiesen, wenn der Datenverkehr wirklich noch weit von der Schwelle entfernt war. Der Gedanke dahinter war, die Warteschlangen zu vermeiden, die bei niedrigeren Grenzwerten auftreten. Gleichzeitig wollten wir noch in der Lage sein, die Zahl der verfügbaren Slots pro Worker anzupassen, wenn mehr Nutzer auf den Ursprungsserver zugreifen.
Um das zu verdeutlichen, wollen wir noch einmal das Beispiel mit der ungleichmäßigen Verteilung des Datenverkehrs auf zwei Worker heranziehen. Im Folgenden sind zwei Worker dargestellt, die dem zuvor besprochenen ähneln. In diesem Fall ist die Auslastung niedrig (10 %). Das heißt, dass wir weit von den Grenzwerten entfernt sind. Die (acht) zugewiesenen Slots liegen also näher an den slotsAvailable für das Rechenzentrum in San Jose (zehn). Wie das folgende Diagramm zeigt, können alle acht Nutzer, die bei einem der beiden Worker landen, die Website mit dieser geänderten Slot-Zuweisung erreichen, da wir bei geringerer Auslastung mehr Slots pro Worker bereitstellen.
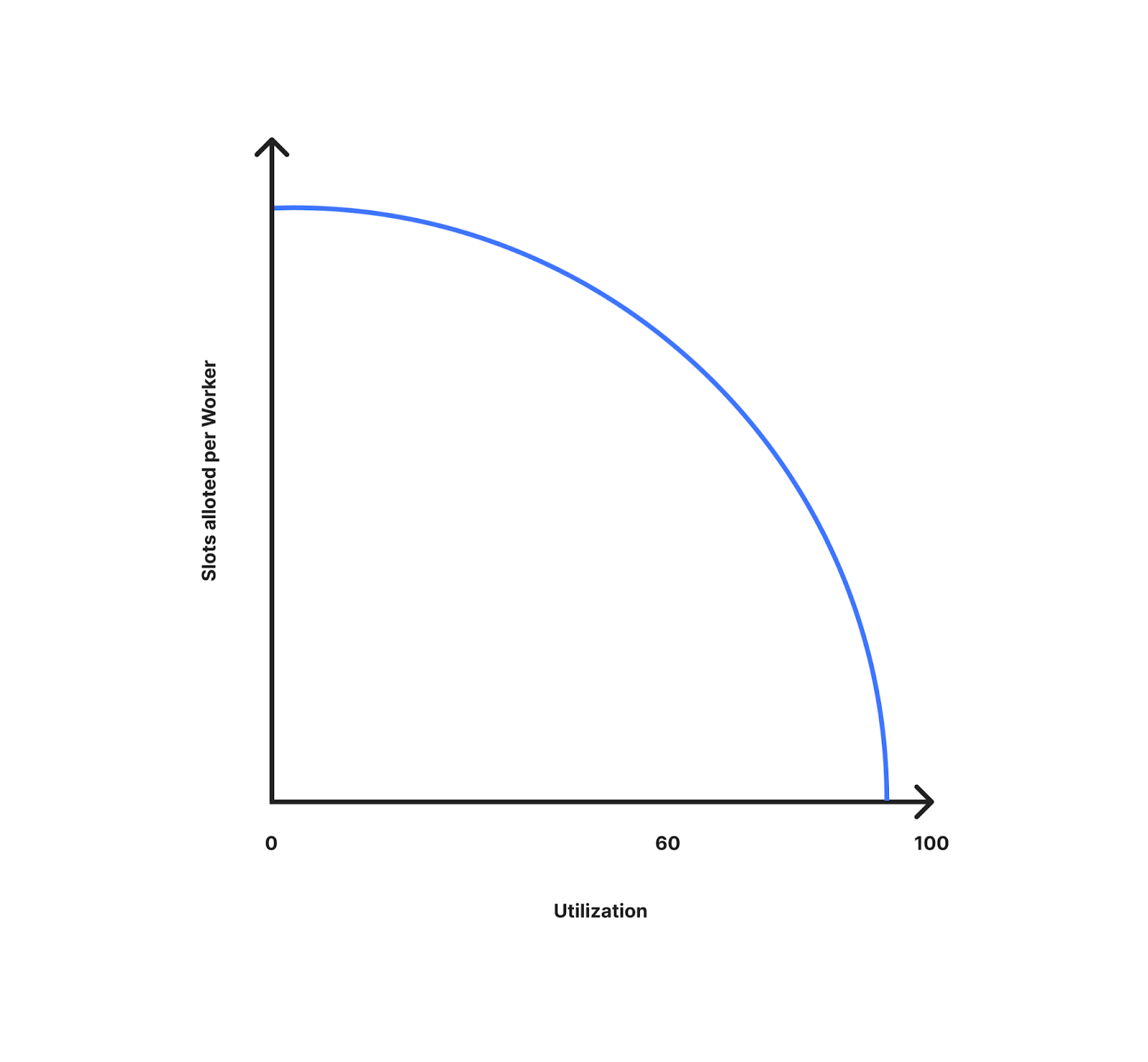
Das folgende Diagramm zeigt, wie sich die Zahl der zugewiesenen Slots pro Worker mit der Auslastung (der Entfernung zu den Obergrenzen) ändert. Wie Sie hier sehen können, werden bei geringerer Auslastung den einzelnen Workern mehr Slots zugewiesen. Mit zunehmender Auslastung verringert sich die Zahl der zugewiesenen Slots pro Worker, da man sich den Grenzwerten annähert und wir besser auf Traffic-Spitzen vorbereitet sind. Bei einer Auslastung von 10 % kommt jeder Worker nahe an die für das Rechenzentrum verfügbaren Slots heran. Bei einer Auslastung von annähernd 100 % nähert sich der Wert den verfügbaren Slots, geteilt durch die Anzahl der Worker im Rechenzentrum.
Wie lassen sich mehr Slots bei geringerer Auslastung erreichen?
Dieser Abschnitt befasst sich mit der Mathematik, die uns dabei hilft. Wenn Sie an diesen Details nicht interessiert sind, lesen Sie bitte den Abschnitt „Risiko der Überversorgung“.
Um dies besser zu verstehen, gehen wir noch einmal auf das vorherige Beispiel ein, bei dem Anfragen im Rechenzentrum in Delhi eingehen. Der activeUsers-Wert ist 50, also beträgt die Auslastung 50/200, was etwa 25 % entspricht.
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 1,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Die Idee ist, bei niedriger Auslastung mehr Slots zuzuweisen. Dadurch wird sichergestellt, dass die Kunden keine unerwarteten Warteschlangen erleben, wenn der Traffic weit vom Schwellenwert entfernt ist. Zum Zeitpunkt Mon, 11 Sep 2023 11:45:54 GMT beträgt die Auslastung durch die Anfragen an Delhi basierend auf dem lokalen Statusschlüssel 25 %.
Um bei geringerer Auslastung mehr verfügbare Slots zuweisen zu können, haben wir einen „workerMultiplier“ hinzugefügt, der sich proportional zur Auslastung entwickelt. Bei geringerer Auslastung ist er niedriger und bei höherer Auslastung liegt er nahe bei eins.
workerMultiplier = (utilization)^curveFactor
adaptedWorkerCount = actualWorkerCount * workerMultiplier
utilization – wie weit man von den Grenzwerten entfernt ist.
curveFactor – ist der anpassbare Exponent, der darüber entscheidet, wie aggressiv wir mit der Verteilung zusätzlicher Budgets bei niedrigeren Worker-Zahlen umgehen. Um dies zu verstehen, schauen wir uns den Graph dazu an, wie y = x und y = x^2 zwischen den Werten 0 und 1 aussehen.
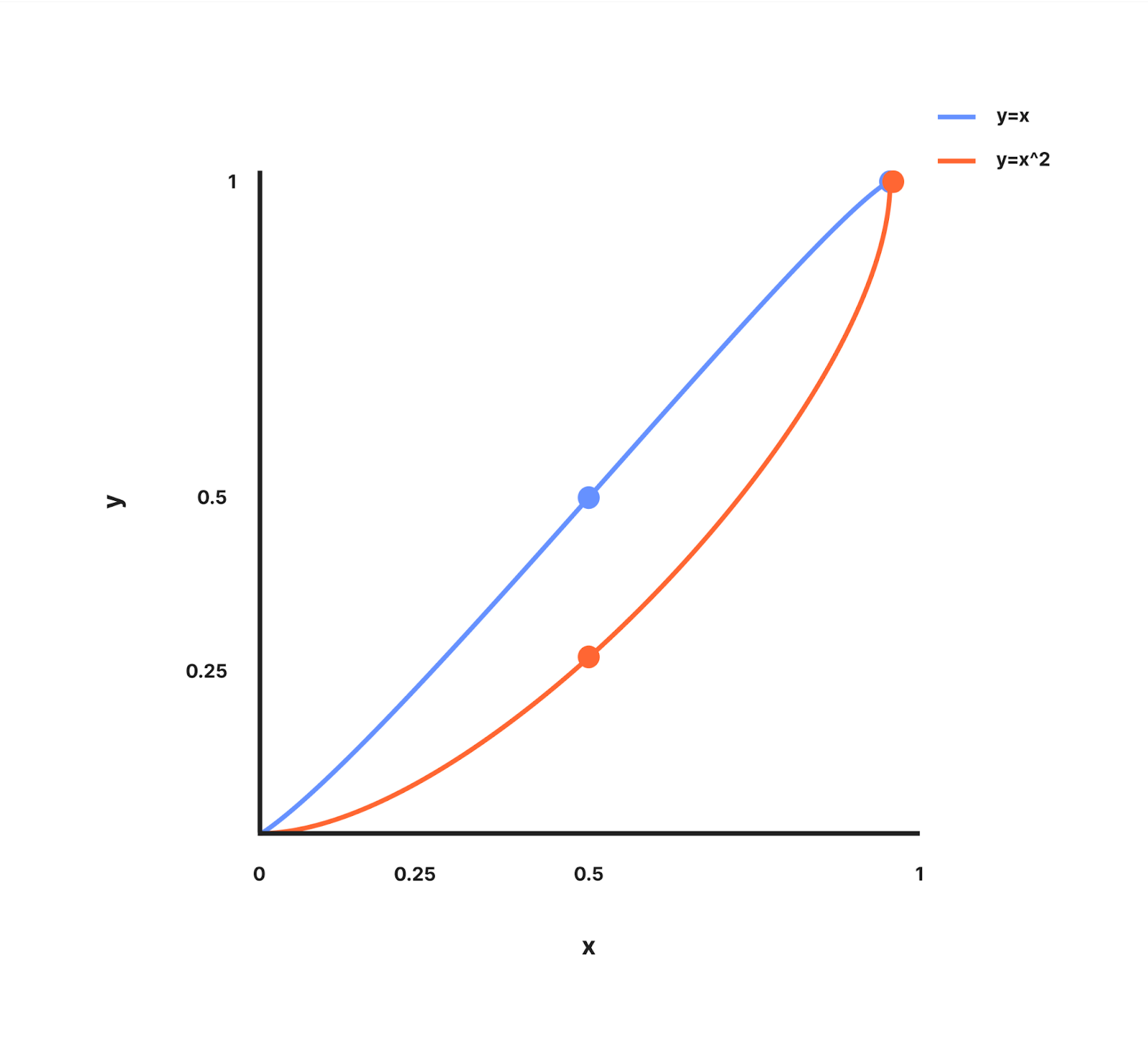
Der Graph für y=x ist eine gerade Linie, die durch (0, 0) und (1, 1) verläuft.
Der Graph für y=x^2 ist eine gekrümmte Linie, bei der y langsamer ansteigt als x, wenn x < 1 ist, und die durch (0, 0) und (1, 1) verläuft.
Unter Verwendung des Konzepts, nach dem die Kurven funktionieren, haben wir die Formel für „workerCountMultiplier“ abgeleitet, wobei y=workerCountMultiplier, x=utilization und curveFactor die anpassbare Potenz ist, die bestimmt, wie offensiv wir mit der Verteilung zusätzlicher Budgets bei niedrigeren Worker-Zahlen umgehen. Wenn der curveFactor 1 ist, ist der workerMultiplier gleich der Auslastung.
Kommen wir auf das zuvor besprochene Beispiel zurück und schauen wir uns an, welchen Wert der Kurvenfaktor haben wird. Zum Zeitpunkt Mon, 11 Sep 2023 11:45:54 GMT entsprechen die Anfragen an Delhi basierend auf dem lokalen Statusschlüssel einer Auslastung von 25 %. Die Anywhere-Slots werden unter allen aktiven Workern weltweit aufgeteilt, da jeder Worker sich einen Teil dieses Kuchens sichern kann, d. h. 75 % der verbleibenden 150 Slots (113).
globalWorkersActive ist 10, wenn wir uns den Status des Warteraums ansehen. In diesem Fall dividieren wir die 113 Slots nicht durch 10, sondern durch die angepasste Worker-Zahl, die sich aus globalWorkersActive * workerMultiplier ergibt. Ist der curveFactor 1, ist der workerMultiplier gleich der Auslastung, die bei 25 % oder 0,25 liegt.
Effektiver workerCount = 10 * 0,25 = 2,5
Jeder aktive Worker kann also bis zu 113/2,5 senden, was ungefähr 45 Nutzern entspricht. Die ersten 45 Nutzer, die in der Minute Mon, 11 Sep 2023 11:45:00 GMT zu einem Worker gelangen, erhalten Zugang zum Ursprungsserver. Die restlichen Nutzer finden sich in einer Warteschlange wieder.
Daher erhält jeder Worker bei geringerer Auslastung (also wenn der Traffic weiter von den Obergrenzen entfernt ist) mehr Slots. Wenn jedoch die Summe der Slots addiert wird, besteht eine höhere Wahrscheinlichkeit, dass das Gesamtlimit überschritten wird.
Risiko der Überversorgung
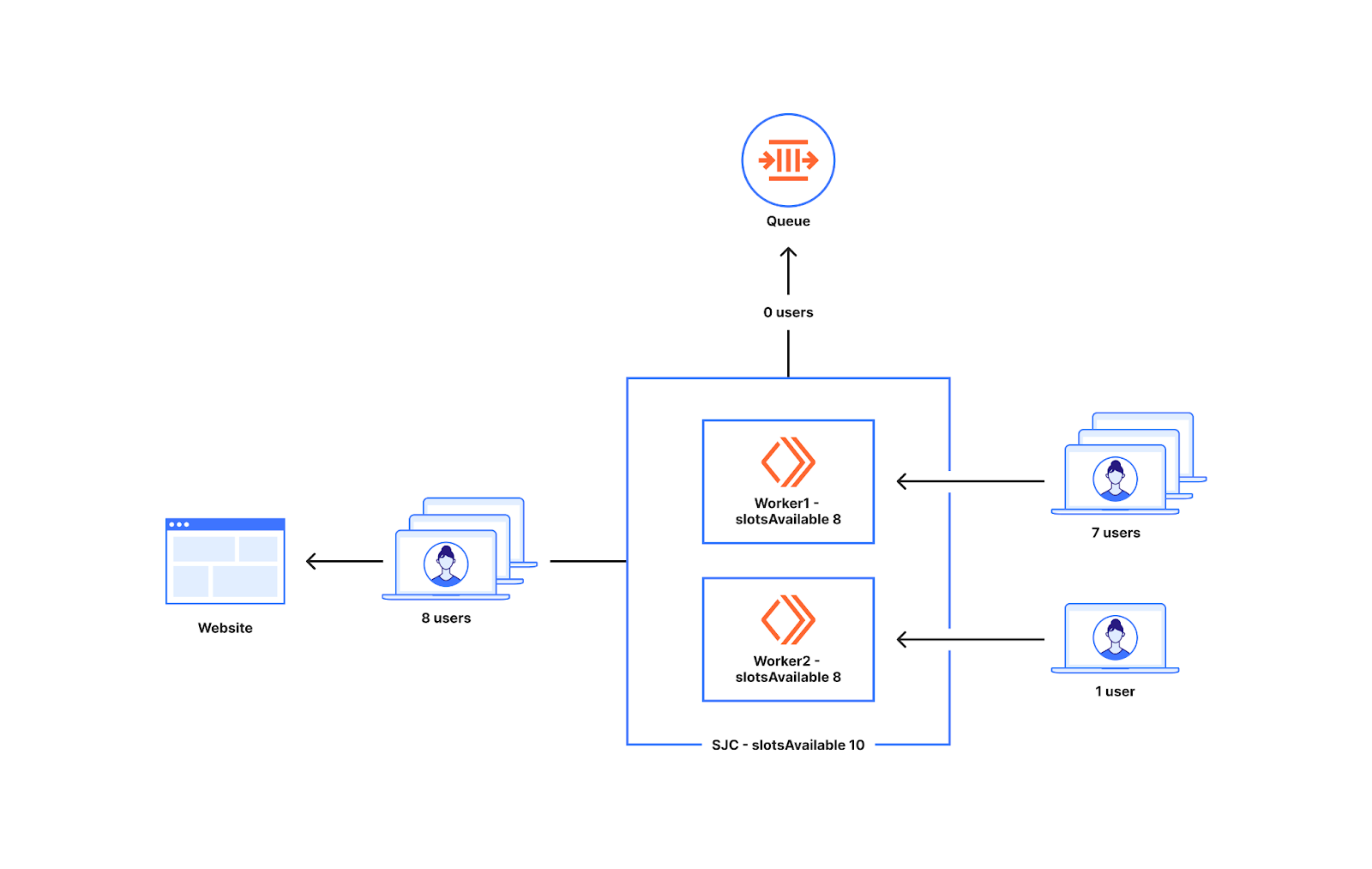
Die Methode, bei der bei niedrigeren Grenzwerten mehr Slots zugewiesen werden, verringert die Gefahr von Warteschlangen, wenn das Traffic-Aufkommen im Verhältnis zu den Schwellenwerten gering ist. Bei niedrigerer Auslastung könnte jedoch eine einheitliche, weltweit auftretende Traffic-Spitze dazu führen, dass mehr Nutzer als erwartet den Ursprungsserver ansteuern. Das folgende Diagramm zeigt den Fall, in dem dies ein Problem darstellen kann. Wie Sie sehen können, sind zehn Slots für das Rechenzentrum verfügbar. Bei einer Auslastung von 10 %, die wir zuvor besprochen haben, kann jeder Worker acht Slots haben. Wenn acht Nutzer bei einem Worker und sieben bei einem anderen landen, werden fünfzehn Nutzer auf die Website geschickt, obwohl nur zehn Slots für das Rechenzentrum zur Verfügung stehen.
Bei der Vielzahl von Kunden und der Art unseres Datenverkehrs konnten wir Fälle beobachten, in denen dies zu einem Problem wurde. Eine Traffic-Spitze bei niedriger Auslastung könnte zu einer Überschreitung der globalen Schwellenwerte führen. Das ist darauf zurückzuführen, dass bei niedrigeren Limits zu viel bereitgestellt wird, was das Risiko einer erheblichen Überschreitung der Traffic-Grenzen erhöht. Wir mussten einen sichereren Ansatz implementieren, bei dem die Obergrenzen nicht überschritten werden und gleichzeitig die Gefahr von Warteschlangen bei geringem Datenverkehrsaufkommen im Verhältnis zu den Grenzwerten verringert wird.
Wenn wir einen Schritt zurücktreten und über unseren Ansatz nachdenken, gehen wir unter anderem davon aus, dass das Traffic-Aufkommen in einem Rechenzentrum direkt mit der Anzahl der Worker korreliert, die dort angesiedelt sind. In der Praxis hat sich gezeigt, dass dies nicht für alle Kunden zutrifft. Selbst wenn der Datenverkehr mit der Anzahl der Worker korreliert, kann es sein, dass die Zahl der neuen Nutzer, die bei den Workern in den Rechenzentren landen, nicht korreliert. Der Grund dafür ist, dass die von uns zugewiesenen Slots für neue Nutzer bestimmt sind, der Datenverkehr in einem Rechenzentrum aber sowohl aus bereits auf der Website befindlichen Nutzern als auch aus neuen Nutzern besteht, die versuchen, die Website aufzurufen.
Im nächsten Abschnitt sprechen wir über einen Ansatz, bei dem nicht auf die Zahl der Worker zurückgegriffen wird und stattdessen Worker mit anderen Workern im Rechenzentrum kommunizieren. Zu diesem Zweck haben wir einen neuen Dienst eingeführt, bei dem es sich um einen Zähler von Durable Objects handelt.
Senkung der Anzahl von Teilungen der Slots durch die Einführung von Data Center Counters
Aus dem obigen Beispiel geht hervor, dass eine Überbelegung auf Worker-Ebene das Risiko birgt, mehr Slots zu verbrauchen, als einem Rechenzentrum zugewiesen sind. Wenn wir keine Überversorgung auf niedriger Ebene vornehmen, besteht wie bereits besprochen das Risiko, dass die Nutzer in der Warteschlange landen, lange bevor die konfigurierten Obergrenzen erreicht sind. Es muss also eine Lösung gefunden werden, mit der beides erreicht werden kann.
Die Überversorgung wurde vorgenommen, damit den Workern nicht schnell die Slots ausgehen, wenn eine ungerade Zahl neuer Nutzer bei einer Reihe von Workern landet. Wenn zwei Worker in einem Rechenzentrum in der Lage sind, untereinander zu kommunizieren, müssen wir die Slots nicht auf Grundlage der Anzahl der Worker im Rechenzentrum aufteilen. Damit diese Kommunikation stattfinden kann, haben wir Zähler eingeführt. Dabei handelt es sich um eine Reihe kleiner, langlebiger Durable Object-Instanzen, die das Zählen für eine Reihe von Workern im Rechenzentrum übernehmen.
Das folgende Diagramm macht besser verständlich, wieso es hilfreich ist, die Verwendung von Worker-Zählern zu vermeiden. Unten sind zwei Worker zu sehen, die mit einem Data Center Counter kommunizieren. Wie wir bereits besprochen haben, entscheiden die Worker anhand des Warteraumstatus, ob sie den Nutzern Zugang zur Website gewähren. Die Anzahl der durchgelassenen Nutzer wurde zuvor im Worker gespeichert. Durch die Einführung von Zählern erfolgt dies nun im Data Center Counter. Jedes Mal, wenn ein neuer Nutzer eine Anfrage an den Worker stellt, kommuniziert der Worker mit dem Zähler, um den aktuellen Wert des Zählers zu erfahren. Im folgenden Beispiel ist der Zählerwert für die erste neue Anfrage an den Worker 9. Wenn in einem Rechenzentrum zehn Slots verfügbar sind, bedeutet dies, dass der Nutzer die Website besuchen kann. Wenn bei dem nächsten Worker ein neuer Nutzer landet und kurz danach eine Anfrage stellt, erhält er den Wert 10. Der Nutzer wird dann auf Grundlage der für den Worker verfügbaren Slots in die Warteschlange eingereiht.
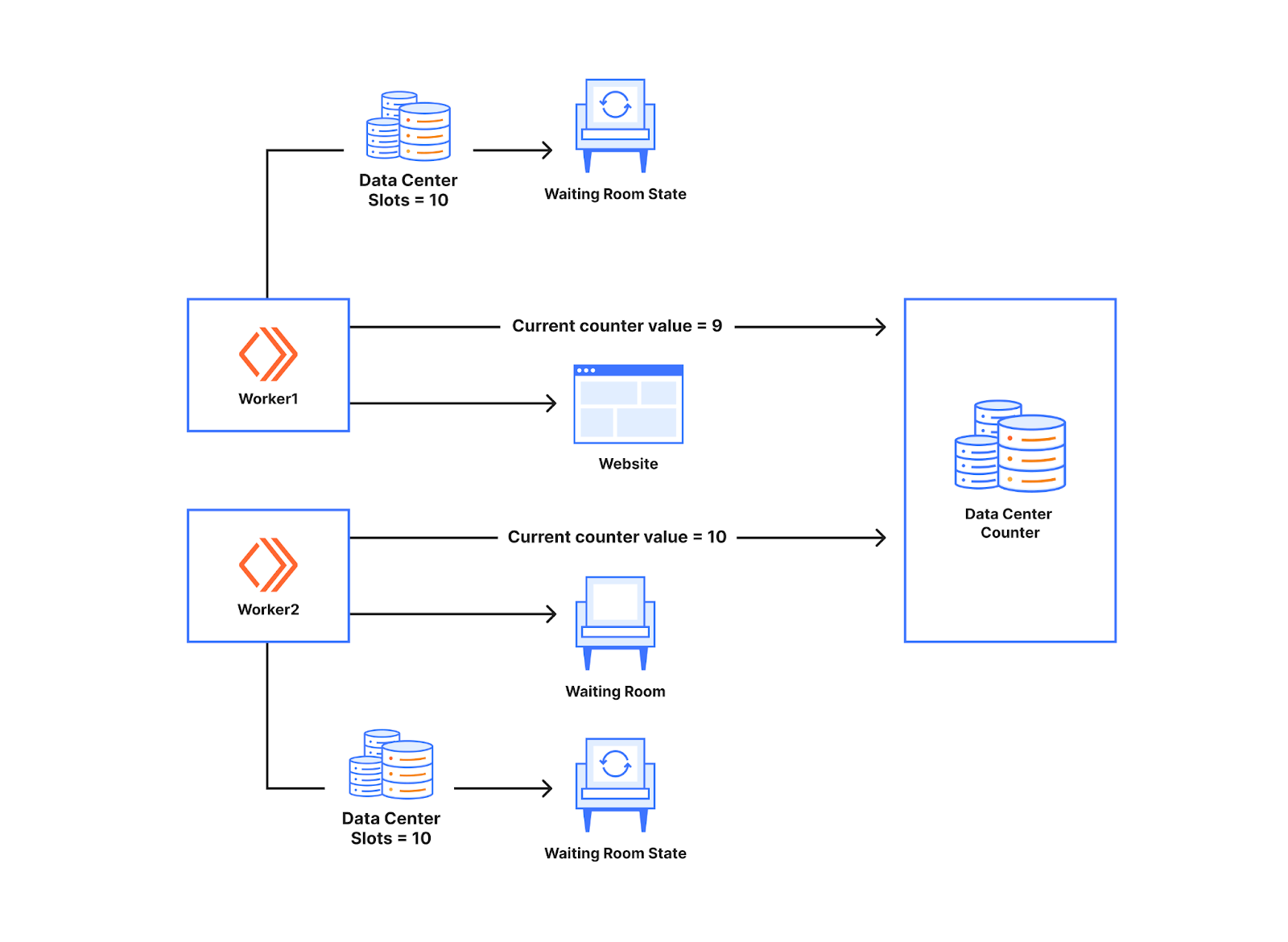
Der Data Center Counter fungiert als Synchronisationspunkt für die Worker im Warteraum. Er ermöglicht es den Workern, miteinander zu kommunizieren, ohne dass sie dies jedoch direkt tun. Das Ganze ist mit einem Fahrkartenschalter vergleichbar: Immer, wenn ein Worker jemanden hereinlässt, fordert er am Schalter Tickets an, sodass ein anderer Worker, der die Tickets am Schalter anfordert, nicht dieselbe Ticketnummer erhält. Ist der Wert des Tickets gültig, kann der neue Nutzer die Website besuchen. Taucht also eine unterschiedliche Anzahl neuer Nutzer bei den Workern auf, werden wir den Workern weder zu viele noch zu wenige Slots zuweisen, da die Anzahl der verwendeten Slots vom Zähler für das Rechenzentrum berechnet wird.
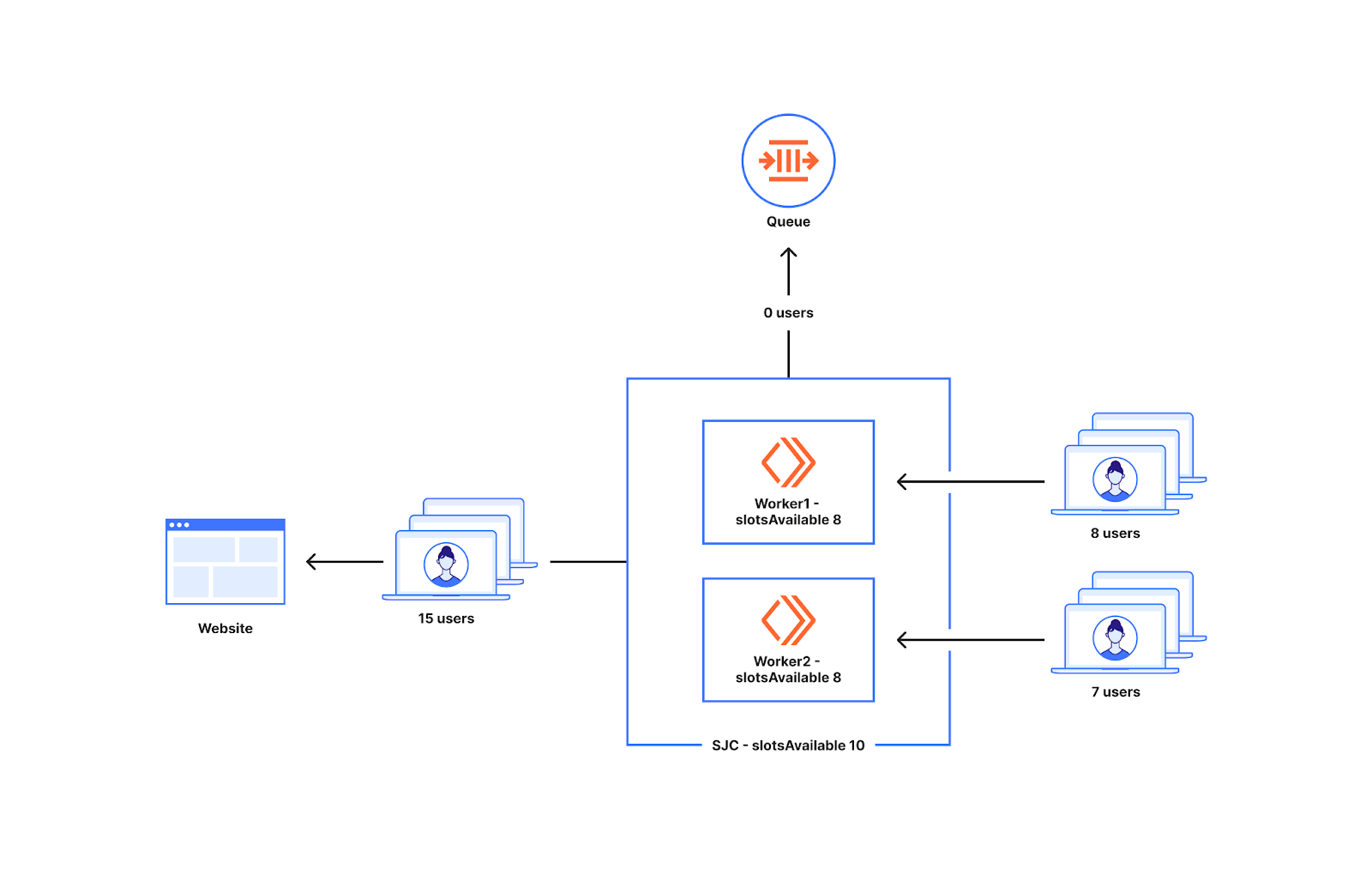
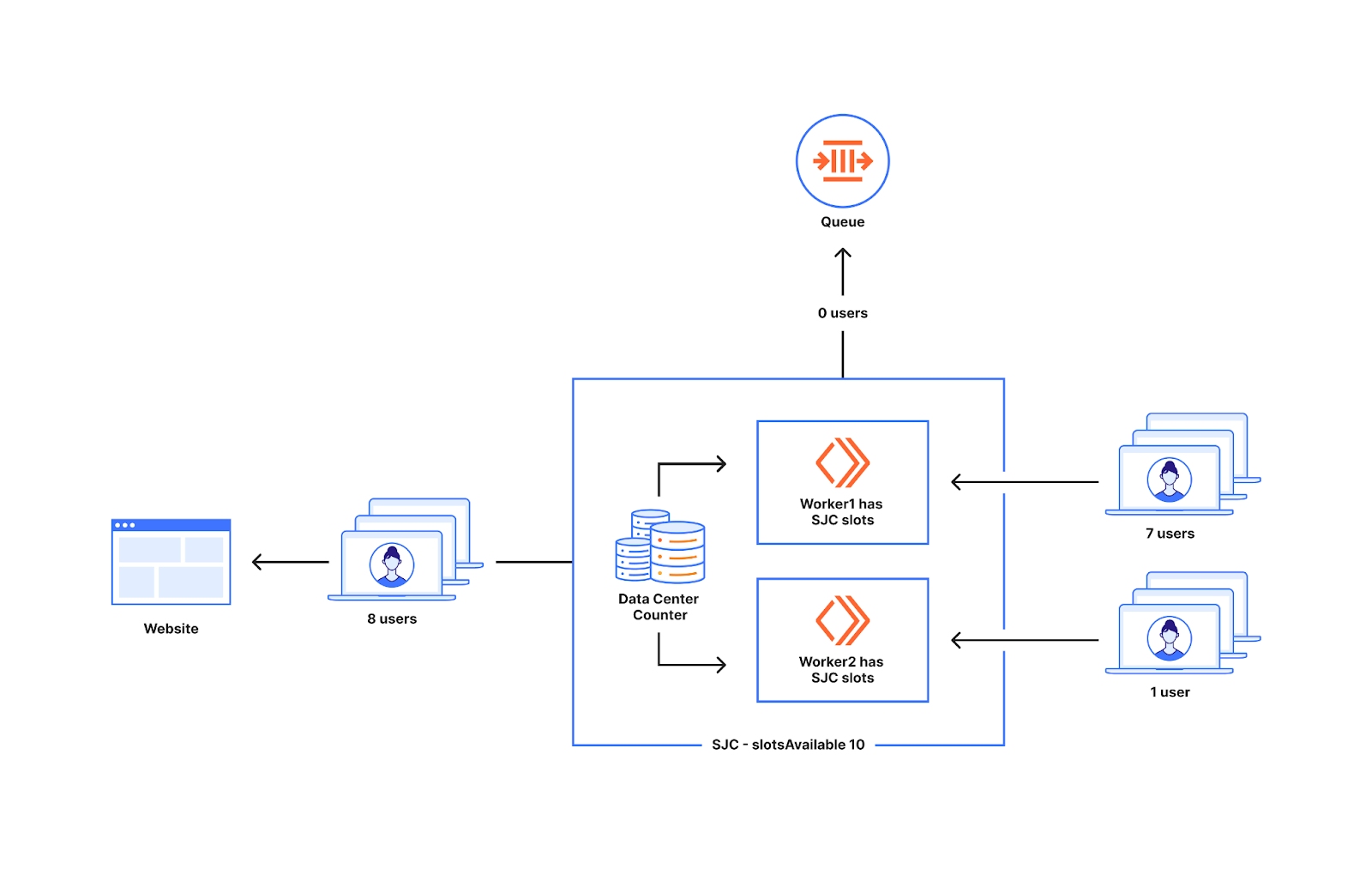
Das nachstehende Diagramm zeigt das Verhalten, wenn eine ungerade Anzahl neuer Nutzer bei den Workern landet: Ein Worker erhält sieben neue Nutzer und der andere Worker einen neuen Nutzer. Alle acht Nutzer, die bei den Workern im untenstehenden Diagramm auftauchen, gelangen auf die Website, da für das Rechenzentrum zehn Slots verfügbar sind und die Gesamtzahl der Nutzer unter zehn liegt.
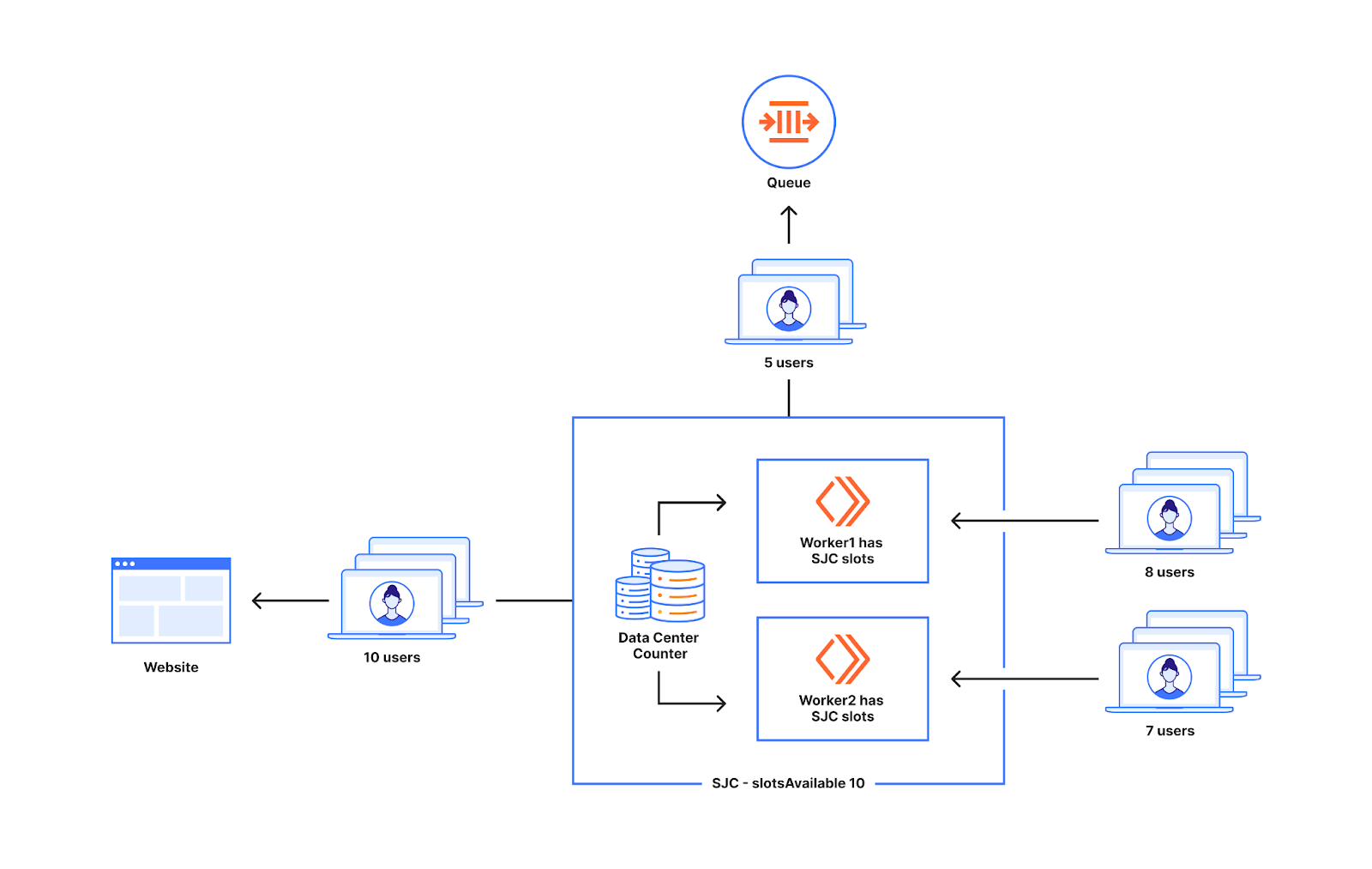
Dies führt auch nicht dazu, dass zu viele Nutzer auf die Website geschickt werden, da wir keine zusätzlichen Nutzer schicken, wenn der Zählerwert gleich den slotsAvailable für das Rechenzentrum ist. Von den fünfzehn Nutzern, die bei den Workern im untenstehenden Diagramm landen, gelangen zehn auf die Website und fünf werden in die Warteschlange geschickt, was den Erwartungen entspricht.
Das Risiko einer Überversorgung bei geringerer Auslastung besteht ebenfalls nicht, da die Zähler den Workern helfen, miteinander zu kommunizieren
Um dies besser zu verstehen, betrachten wir das vorhergehende Beispiel und sehen uns an, wie es mit dem tatsächlichen Status des Warteraums funktioniert.
Der Status des Warteraums für den Kunden ist wie folgt:
{
"activeUsers": 50,
"globalWorkersActive": 10,
"dataCenterWorkersActive": 3,
"trafficHistory": {
"Mon, 11 Sep 2023 11:44:00 GMT": {
San Jose: 20/200, // 10%
London: 30/200, // 15%
Anywhere: 150/200 // 75%
}
}
}
Das Ziel ist es, die Slots nicht unter den Workern aufzuteilen, sodass wir diese Information des Status nicht verwenden müssen. Zum Zeitpunkt Mon, 11 Sep 2023 11:45:54 GMT kommen die Anfragen in San Jose an. Wir können also 10 % der 150 verfügbaren Slots von San Jose senden, was 15 entspricht.
Der Durable Object-Zähler in San Jose meldet für jeden neuen Nutzer, der das Rechenzentrum erreicht, den aktuellen Zählerwert zurück. Danach erhöht er den Wert um 1. So erhalten die ersten 15 neuen Nutzer, die den Worker erreichen, einen eindeutigen Zählerwert. Wenn der für einen Nutzer erhaltene Wert kleiner als 15 ist, kann er einen der Slots im Rechenzentrum nutzen.
Wenn die für das Rechenzentrum verfügbaren Slots aufgebraucht sind, können die Nutzer die für Anywhere -Rechenzentren zugewiesenen Slots nutzen, da diese nicht für ein bestimmtes Rechenzentrum reserviert sind. Sobald ein Worker in San Jose einen Ticketwert von 15 übermittelt bekommt, ist klar, dass ein Aufruf der Website mit einem der Slots aus San Jose nicht möglich ist.
Die Anywhere-Slots stehen allen aktiven Workern weltweit zur Verfügung, d. h. 75 % der verbleibenden 150 Slots (113). Die Anywhere-Slots werden von einem Durable Object verwaltet. Mit diesem können Worker aus verschiedenen Rechenzentren kommunizieren, wenn sie Anywhere-Slots nutzen wollen. Selbst wenn 128 (113 + 15) Nutzer bei demselben Worker für diesen Kunden landen, werden sie nicht in eine Warteschlange eingereiht. Dadurch kann der Warteraum eine ungerade Zahl neuer Nutzer bewältigen, die bei Workern auf der ganzen Welt landen. Dies wiederum trägt dazu bei, dass sich die Kunden nahe an den konfigurierten Grenzen in die Warteschlange einreihen können.
Warum funktionieren die Zähler für uns so gut?
Als wir Waiting Room entwickelt haben, wollten wir, dass die Entscheidungen für den Zugang zur Website auf der Worker-Ebene selbst getroffen werden – ohne Austausch mit anderen Diensten, wenn die Anfrage zur Website unterwegs ist. Wir haben diese Entscheidung getroffen, um zusätzliche Latenz bei Nutzeranfragen zu vermeiden. Durch die Einführung eines Synchronisationspunkts bei einem Durable Object-Zähler weichen wir davon ab, indem wir einen Aufruf an einen Durable Object-Zähler einführen.
Das Durable Object für das Rechenzentrum bleibt jedoch innerhalb desselben Rechenzentrums. Das führt zu einer minimalen zusätzlichen Latenz, die in der Regel weniger als 10 ms beträgt. Bei den Aufrufen des Durable Object, das Anywhere-Rechenzentren verwaltet, muss der Worker möglicherweise Ozeane und große Entfernungen überqueren. Dadurch kann die Latenz in diesen Fällen 60 ms oder 70 ms betragen. Die unten gezeigten 95 %-Perzentil-Werte sind höher, da Aufrufe an weiter entfernte Rechenzentren gehen.
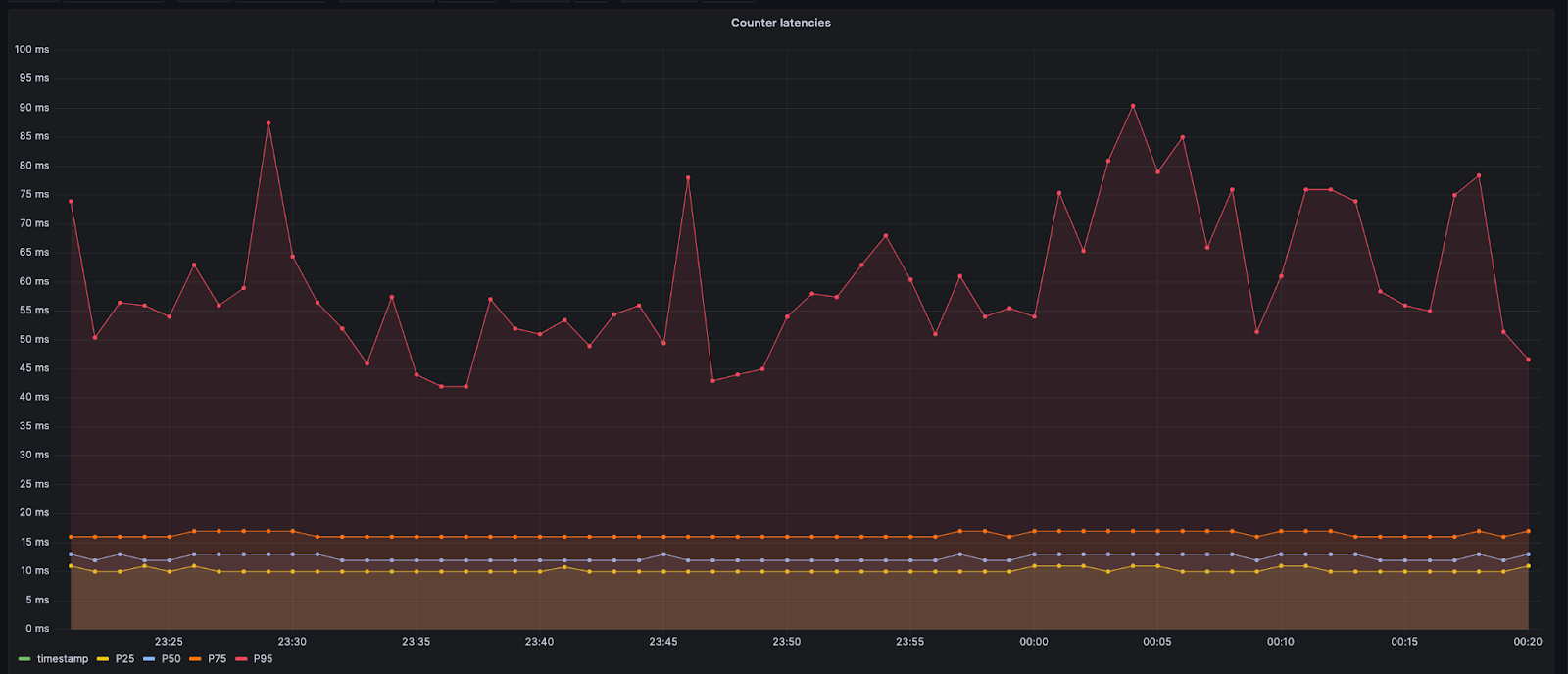
Die Entscheidung, Zähler hinzuzufügen, führt zu einer geringfügigen Erhöhung der Latenz für neue Nutzer, die die Website besuchen. Wir hielten diesen Kompromiss für akzeptabel, da dadurch die Anzahl der Nutzer reduziert wird, die vor Erreichen der Obergrenzen in die Warteschlange verwiesen werden. Außerdem werden die Zähler nur benötigt, wenn neue Nutzer versuchen, die Website aufzurufen. Sobald neue Nutzer den Ursprungsserver erreichen, wird ihnen direkt von den Workern Zugang erteilt, da der entsprechende Nachweis in den die Kunden begleitenden Cookies enthalten ist und wir sie auf dieser Grundlage passieren lassen können.
Zähler sind wirklich einfache Dienste, die außer zählen nichts weiter tun. Deshalb beanspruchen sie Speicher und CPU auch nur geringfügig. Außerdem betreiben wir viele Zähler auf der ganzen Welt, die die Koordination zwischen Untergruppen von Workern übernehmen. Das hilft den Zählern, die Last der Synchronisationsanforderungen der Worker zu bewältigen. Zusammengenommen machen diese Faktoren zusammengenommen Zähler zu einer praktikablen Lösung für unseren Anwendungsfall.
Zusammenfassung
Bei der Entwicklung von Waiting Room stand für uns an erster Stelle, sicherzustellen, dass die Websites unserer Kunden unabhängig vom Volumen oder von der Zunahme des legitimen Datenverkehrs einsatzfähig und erreichbar bleiben. Waiting Room läuft auf jedem Server im Netzwerk von Cloudflare, das sich über 300 Städte in mehr als 100 Ländern erstreckt. Wir wollen dafür sorgen, dass bei jedem neuen Nutzer die Entscheidung, ob er zur Website vorgelassen wird oder in die Warteschlange geleitet wird, mit minimaler Latenz und zum richtigen Zeitpunkt getroffen wird. Das ist kein leichtes Unterfangen, denn wenn die Einreihung in die Warteschlange eines Rechenzentrums zu früh erfolgt, kann das dazu führen, dass die vom Kunden festgelegten Obergrenzen gar nicht erst erreicht werden. Erfolgt die Einreihung in die Warteschlange dagegen zu spät, werden die vorgegebenen Schwellenwerte womöglich überschritten.
Bei unserem ursprünglichen Ansatz, bei dem wir die Slots gleichmäßig auf unsere Worker verteilt haben, wurden Warteschlangen machmal zu früh geschaffen, dafür haben wir aber die vom Kunden gesetzten Grenzen ziemlich gut eingehalten. Bei unserem nächsten Ansatz haben wir bei geringer Auslastung (geringes Traffic-Aufkommen im Verhältnis zu den vom Kunden vorgegebenen Obergrenzen) mehr Slots zugewiesen. In den Fällen, in denen wir die Warteschlange früher geschaffen haben, als durch die Kundengrenzen eigentlich vorgegeben, haben wir damit besser abgeschnitten, weil den einzelnen Workern mehr Slots zur Verfügung standen. Wie wir jedoch gesehen haben, führte dies dazu, dass bei einem plötzlichen Anstieg des Datenverkehrsaufkommens nach einer Periode geringer Auslastung eher zu Überschreitungen neigten.
Mit Zählern erhalten wir das Beste aus beiden Welten, da damit eine Verteilung der Slots auf Grundlage der Anzahl von Workern vermieden wird. Mit Zählern können wir im Einklang mit den vom Kunden festgelegten Schwellenwerten sicherstellen, dass die Warteschlange weder zu früh noch zu spät angelegt wird. Das geht mit einer geringfügig höheren Latenz bei jeder Anfrage eines neuen Nutzers einher, was wir jedoch als vernachlässigbar erachten. Diese Lösung bietet immer noch ein besseres Nutzererlebnis als eine zu frühe Einreihung in die Warteschlange.
Wir arbeiten ständig an der Optimierung unseres Ansatzes, um sicherzustellen, dass die Warteschlangen immer zum richtigen Zeitpunkt gebildet werden und vor allem, um Ihre Website zu schützen. Da immer mehr Kunden Waiting Room nutzen, lernen wir mehr über die verschiedenen Arten von Datenverkehr. Das hilft uns, das Produkt für alle zu verbessern.