


Lorsque nous avons annoncé D1 au mois de mai de cette année, nous savions que cela marquerait le début de quelque chose de nouveau – notre première base de données SQL avec Cloudflare Workers. Avant D1, nous avions annoncé des options de stockage telles que KV (key-value store), Durable Objects (emplacement unique, stockage de données à forte cohérence) et R2 (stockage Blob). Cependant, la question est toujours restée la même : « Comment puis-je stocker et interroger des données relationnelles sans me préoccuper de la latence, et avec une API simple d'utilisation ? »
La « base de données Cloudflare » tant attendue était véritablement la pièce manquante qui permettrait de créer intégralement votre application sur le réseau mondial de Cloudflare, en passant d'une feuille blanche en VSCode à une application full stack en quelques secondes seulement. D1 est compatible avec la célèbre API SQLite, et permet ainsi aux développeurs de créer leurs bases de données sans être submergés par la complexité et sans devoir gérer chaque couche sous-jacente.
Depuis l'annonce du lancement en mai et la bêta privée en juin, nous avons accompli de grands progrès dans la réalisation de notre vision d'une base de données serverless. D1 est toujours en bêta privée, mais une bêta ouverte se profile déjà à l'horizon, et nous sommes ravis de vous présenter et vous raconter le parcours de la construction de D1 et les événements à venir.
L'expérience D1
Les commentaires sur Cloudflare Workers nous avaient appris que l'utilisation de Wrangler comme mécanisme de création et de déploiement d'applications est une solution très appréciée, plébiscitée par beaucoup. C'est pourquoi, lorsque Wrangler 2.0 a été annoncé en mai dernier, en même temps que D1, nous avons tiré parti de l'interface de ligne de commande nouvelle et améliorée pour construire chaque facette de l'expérience, de la création des données jusqu'à chaque mise à jour et itération. Découvrons la procédure d'installation en quelques étapes faciles.
Créez votre base de données
Si vous avez installé la nouvelle version de Wrangler, vous pouvez créer une base de données vide et initialisée avec une brève instruction
npx wrangler d1 create my_database_name
pour mettre votre base de données en service ! Maintenant, l'heure est venue d'ajouter vos données.
Amorcez-la
La « méthode Cloudflare » ne mériterait pas sa réputation si vous deviez vous infliger une longue et fastidieuse procédure de configuration. Nous avons donc veillé à ce que vous puissiez transférer, facilement et sans complications, vos données existantes depuis une ancienne base de données pour amorcer votre nouvelle base de données D1. Vous pouvez exécuter
wrangler d1 execute my_database-name --file ./filename.sql
et utiliser un fichier SQLite .sql existant de votre choix. Votre base de données est maintenant opérationnelle.
Développez et testez localement
Avec toutes les améliorations que nous avons apportées à Wrangler depuis le lancement de la version 2, il y a quelques mois de cela, nous sommes heureux de vous annoncer que D1 offre une prise en charge complète, locale et à distance, de wrangler dev :
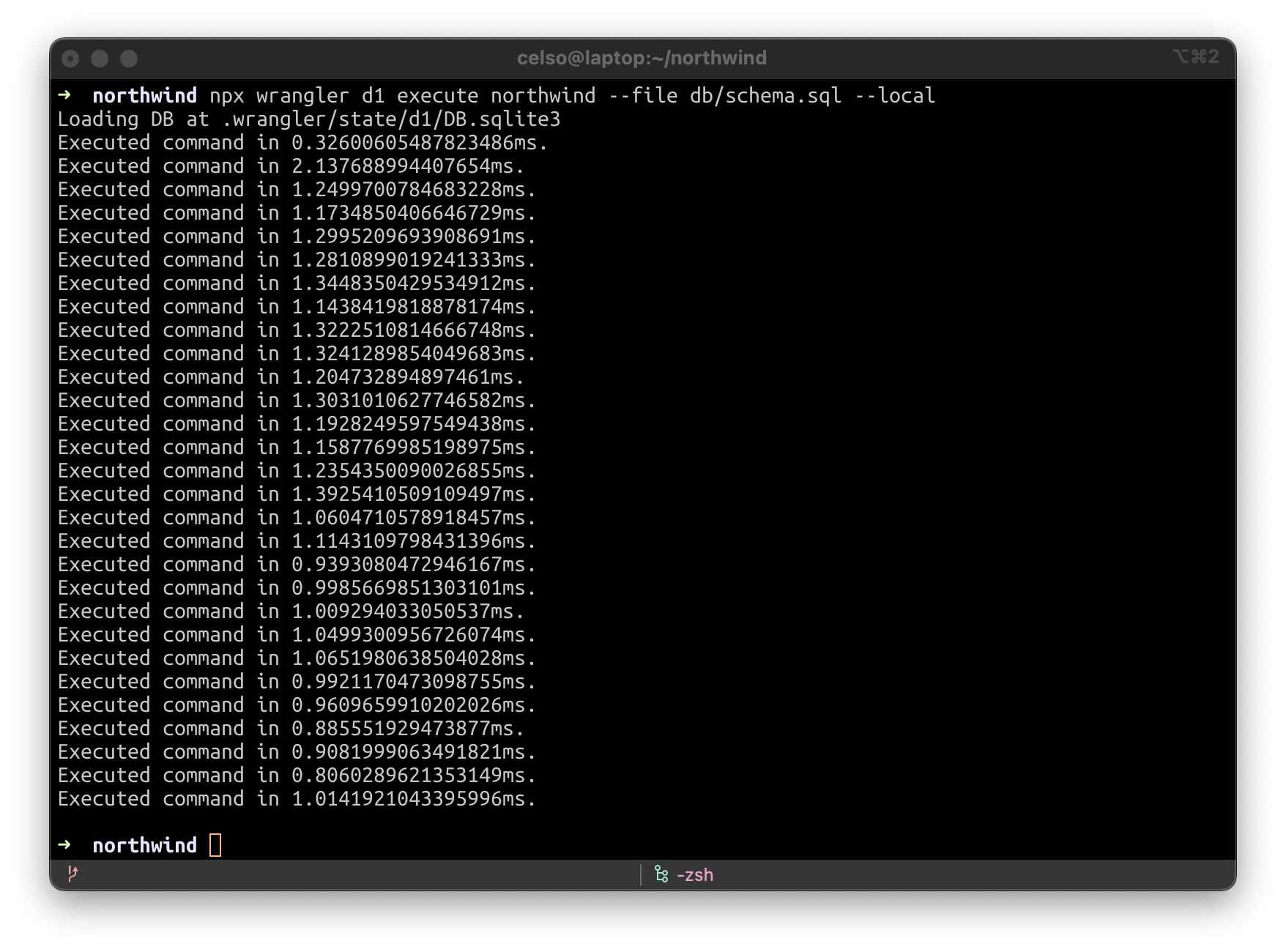
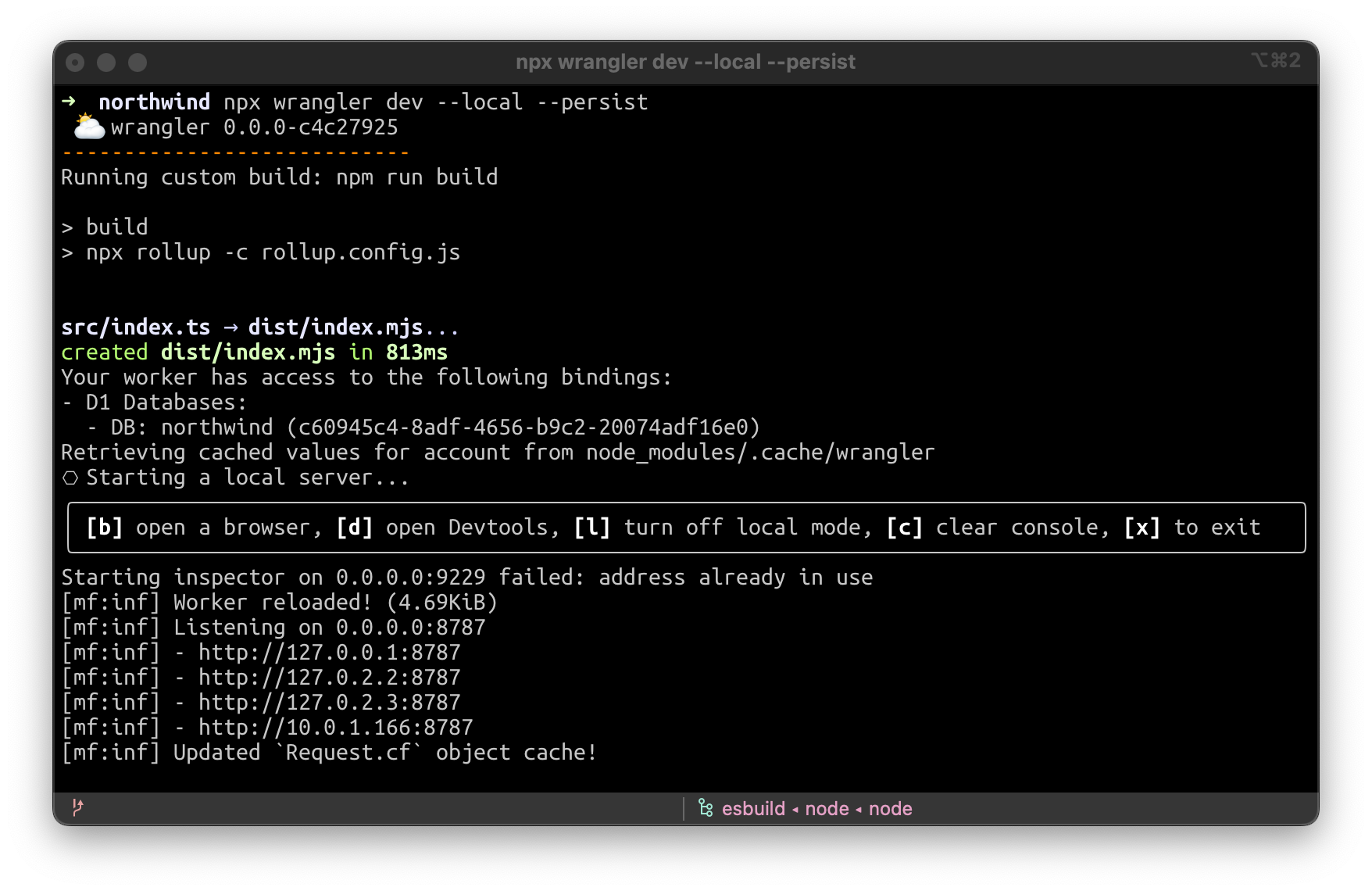
Lorsque vous exécutez wrangler dev -–local -–persist, un fichier SQLite est créé dans .wrangler/state. Vous pouvez ensuite le gérer à l'aide d'un programme d'interface graphique local, tel que SQLiteFlow (https://www.sqliteflow.com/) ou Beekeeper (https://www.beekeeperstudio.io/).
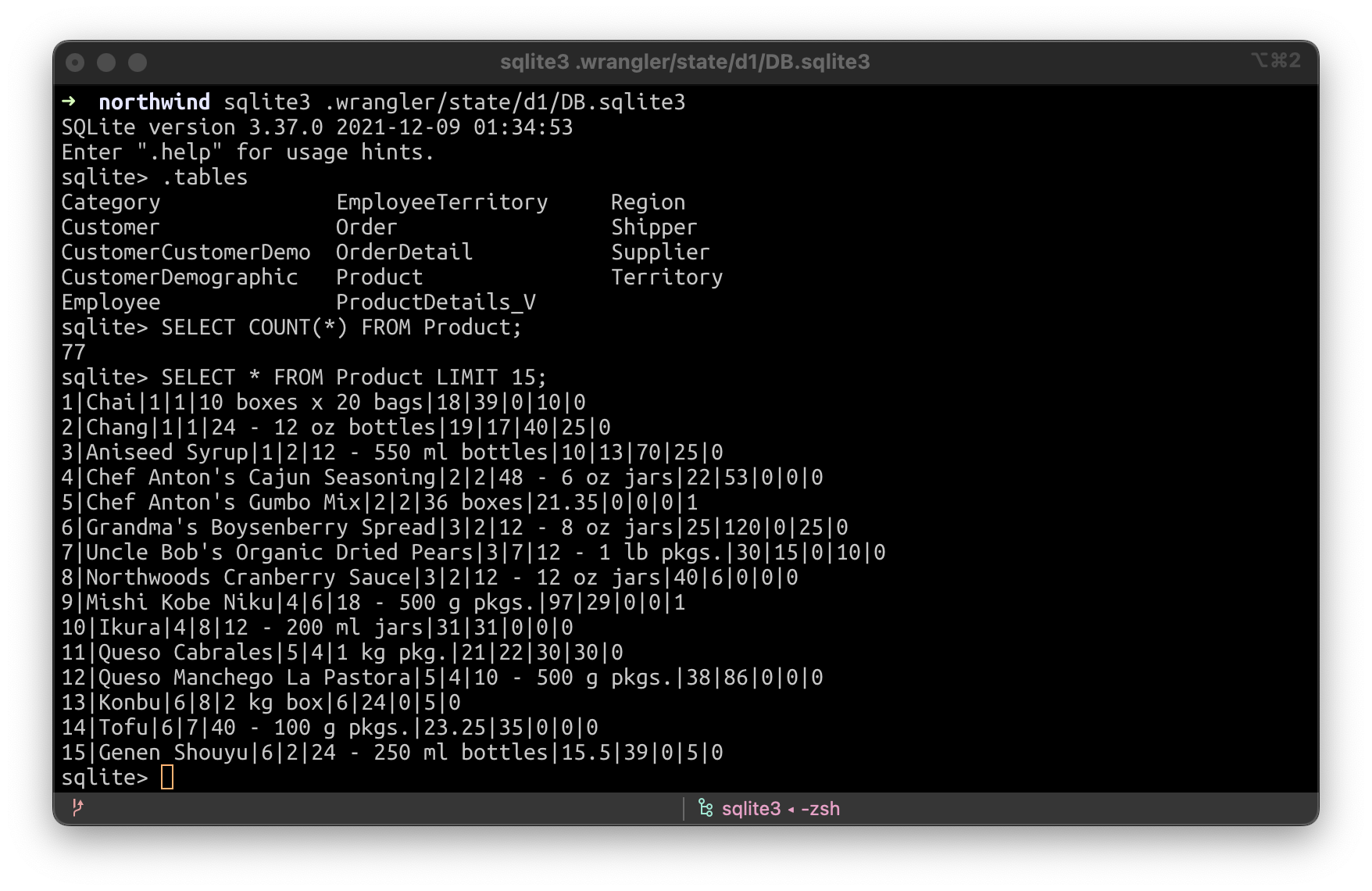
Ou vous pouvez simplement utiliser SQLite directement, avec la ligne de commande de SQLite, en exécutant sqlite3 .wrangler/state/d1/DB.sqlite3:
Sauvegardes automatiques et restauration en un clic
Même si vous testez vos modifications avec rigueur, parfois, les choses ne se déroulent pas comme vous l'aviez prévu. Mais avec Wrangler, vous pouvez créer une sauvegarde de vos données, consulter la liste de vos sauvegardes ou restaurer votre base de données à partir d'une sauvegarde existante. D'ailleurs, pendant la version bêta, nous effectuons automatiquement des sauvegardes de vos données toutes les heures et les stockons dans R2, afin que vous ayez la possibilité de les restaurer, si nécessaire.
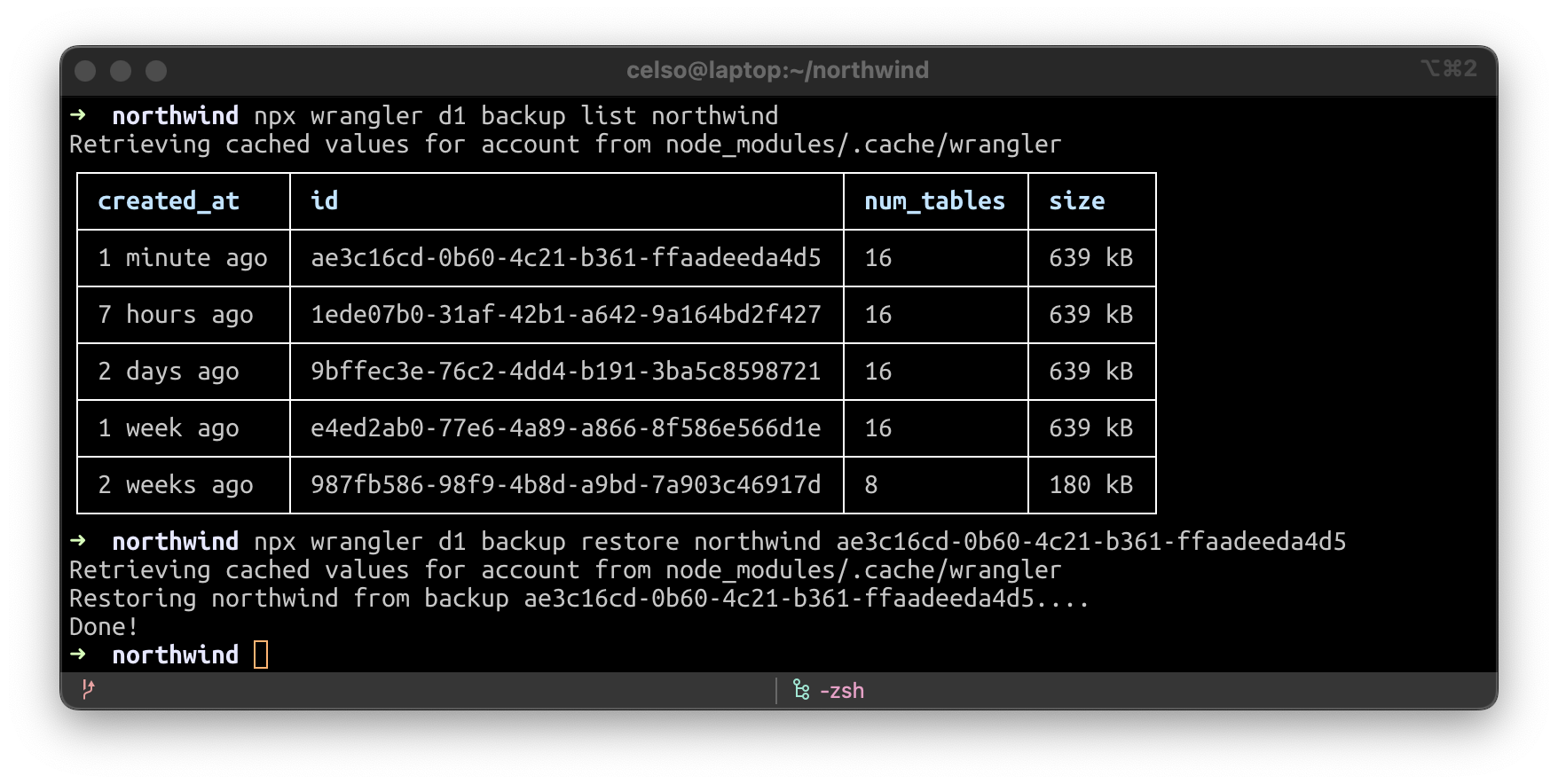
Et mieux encore : si vous souhaitez utiliser un instantané de production pour le développement local ou pour reproduire un bug, copiez-le dans le répertoire .wrangler/state et l'instruction wrangler dev –-local –-persist le prendra en compte !
Téléchargeons une sauvegarde D1 sur notre disque local. Elle est compatible SQLite.
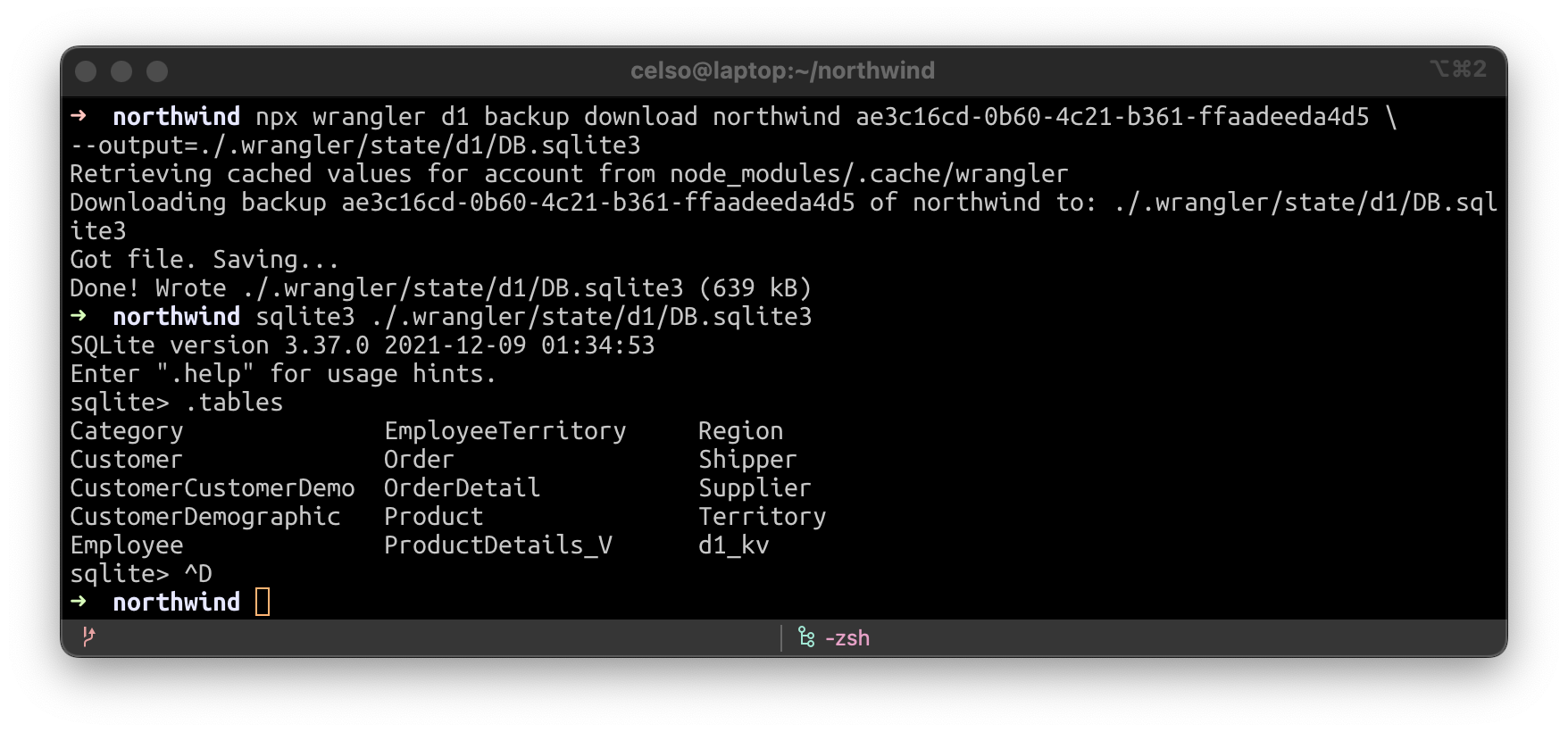
Maintenant, exécutons notre instance Workers D1 localement, à partir de la sauvegarde.
Création et gestion depuis le tableau de bord
Cependant, nous sommes conscients que tout le monde ne partage pas notre goût pour les interfaces de ligne de commande. D'ailleurs, nous pensons que les bases de données devraient être accessibles à tous les types de développeurs – même ceux qui ont peu d'expérience en matière de bases de données ! D1 est disponible directement depuis le tableau de bord de Cloudflare, offrant ainsi une parité de commande quasi-totale avec Wrangler en quelques clics seulement. L'amorçage de votre base de données, la création de tables, la mise à jour de votre base de données, l'affichage des tables et le déclenchement de sauvegardes sont tous accessibles du bout des doigts.
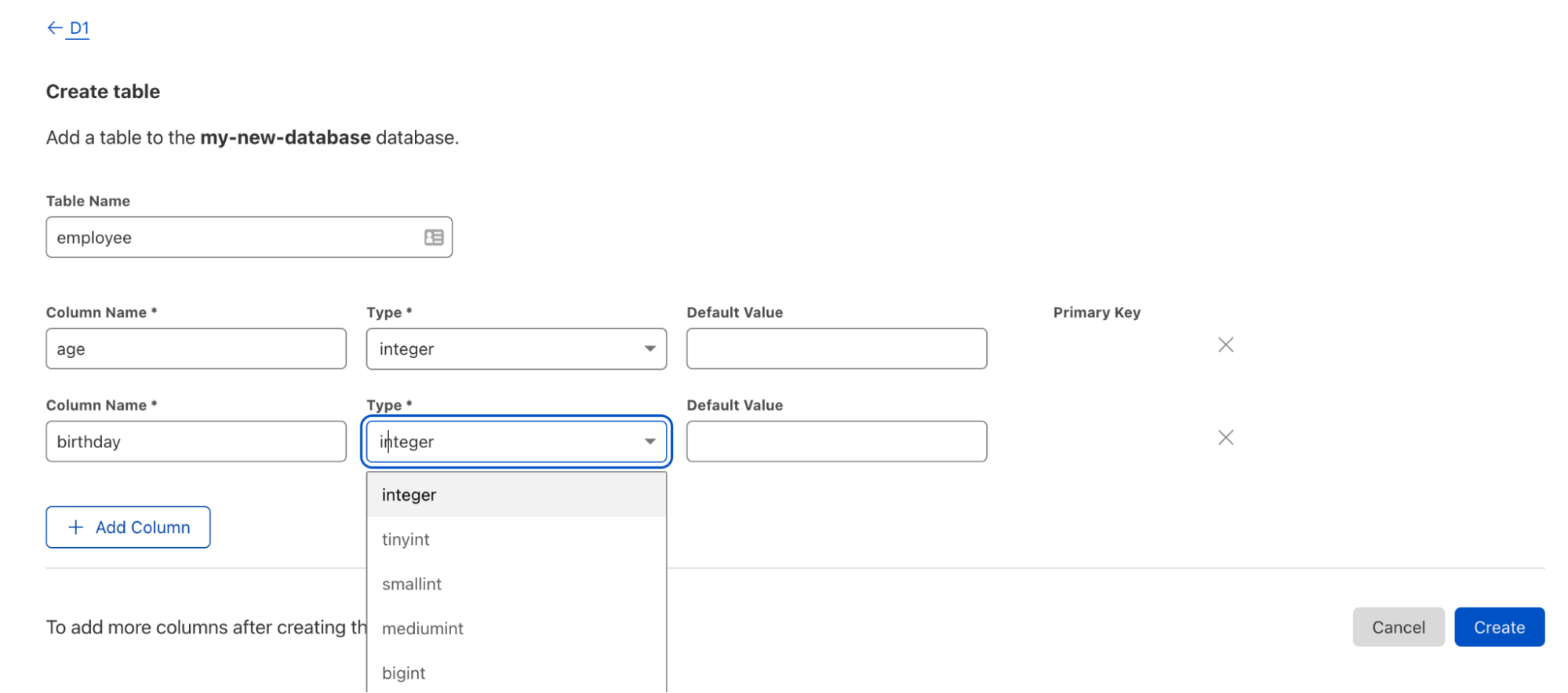
Les modifications effectuées dans l'interface utilisateur sont instantanément accessibles par votre instance Workers – aucun déploiement n'est nécessaire !
Nous avons évoqué certaines améliorations que nous avons apportées depuis l'annonce de D1, mais comme toujours, nous voulions également vous proposer un avant-goût (avec quelques détails techniques) des événements à venir. Les transactions constituent une fonctionnalité vraiment importante d'une base de données – et sans elles, D1 ne serait pas complète.
Aperçu : comment nous intégrons les transactions JavaScript dans D1
Avec D1, nous aspirons à présenter une interface considérablement simplifiée pour la création et l'interrogation des données relationnelles, ce qui est plutôt une bonne chose. Cependant, la simplification comporte parfois des inconvénients, en raison desquels un scénario d'utilisation peut ne plus être facilement pris en charge sans l'introduction de nouveaux concepts. Les transactions D1 en sont un exemple.
Les transactions constituent un défi unique
Vous n'avez pas besoin de spécifier l'emplacement d'exécution d'une instance Cloudflare Workers ou d'une base de données D1 : elles sont simplement exécutées partout où c'est nécessaire. Pour Workers, cet emplacement est le plus proche possible des utilisateurs qui consultent votre site à l'instant même. Pour D1, aujourd'hui, nous n'essayons pas d'exécuter une copie dans chaque emplacement à travers le monde, mais nous gérons dynamiquement le nombre et l'emplacement de répliques accessibles en lecture seule en fonction du nombre et de la provenance des requêtes que reçoit votre base de données. Cependant, dans le cas de requêtes apportant des modifications à une base de données (que nous appelons généralement « écritures »), celles-ci doivent toutes être retransmises à l'unique instance principale D1 pour accomplir leur tâche, afin de préserver la cohérence.
Mais que faire si vous avez besoin d'effectuer une série de mises à jour en une seule opération ? Bien que vous puissiez envoyer plusieurs requêtes SQL avec l'instruction .batch() (qui utilise, dans l'envers du décor, des transactions de base de données), il est probable qu'à un moment donné, vous souhaiterez entrelacer les requêtes de base de données et le code JS dans une unité de travail unique.
C'est précisément à cette fin qu'ont été inventées les transactions de base de données, mais si vous essayez d'exécuter BEGIN TRANSACTION dans D1, vous obtiendrez une erreur. Regardons pourquoi.
Pourquoi les transactions natives ne fonctionnent pas
Le problème vient du fait que les instructions SQL et le code JavaScript sont exécutés dans des emplacements très différents : votre instruction SQL est exécutée dans votre base de données D1 (la base de données principale pour les écritures, ou la réplique la plus proche pour les lectures), tandis que votre instance Workers est exécutée près de l'utilisateur, qui peut être à l'autre bout du monde. Et parce que D1 est construite sur SQLite, une seule transaction d'écriture peut être ouverte à la fois. Cela signifie que si nous autorisions BEGIN TRANSACTION, n'importe quelle requête d'une instance Workers, où qu'elle soit dans le monde, pourrait effectivement bloquer l'ensemble de votre base de données ! C'est une chose qu'il serait assez dangereux d'autoriser :
- Une instance Workers pourrait démarrer une transaction, puis s'arrêter en raison d'un bug logiciel, sans appeler
ROLLBACK. L'instance principale serait bloquée dans l'attente d'autres commandes d'une instance Workers, qui n'arriveraient jamais (jusqu'à l'expiration d'un délai d'attente, probablement). - Même en l'absence de bugs ou de blocages, les transactions nécessitant plusieurs allers-retours entre JavaScript et SQL pourraient finir par bloquer l'ensemble de votre système pendant plusieurs secondes, limitant ainsi considérablement l'évolutivité d'une application construite avec Workers et D1.
Toutefois, permettre à un développeur de définir des transactions qui associent à la fois SQL et JavaScript rend la création d'applications avec Workers et D1 beaucoup plus flexible et puissante. Nous avons besoin d'une nouvelle solution (ou, dans notre cas, d'une nouvelle version d'une ancienne solution).
Une approche à suivre : les procédures stockées
Les procédures stockées sont des fragments de code transférés vers la base de données pour être exécutés à proximité immédiate des données – et à première vue, c'est exactement ce que nous voulons.
Dans la pratique, toutefois, l'utilisation des procédures stockées dans les bases de données traditionnelles est une source notoire de frustration, comme vous le diront toutes les personnes qui ont développé un système recourant intensivement à ces procédures :
- Elles sont souvent écrites dans un langage différent de celui du reste de votre application. Elles sont généralement écrites en SQL (ou plutôt, dans un dialecte spécifique de SQL) ou dans un langage intégré, tel que Tcl/Perl/Python. Et bien qu'il soit techniquement possible de les écrire en JavaScript (avec un moteur V8 intégré), elles s'exécutent dans un environnement tellement différent de celui du code de votre application que leur maintenance exige de continuellement changer de contexte.
- Utiliser à la fois du code d'application et du code interne à la base de données affecte chaque facette du cycle de développement, de la création jusqu'aux tests, au déploiement, à la restauration et au débogage. Toutefois, les procédures stockées étant généralement mises en œuvre pour résoudre un problème spécifique, et non sous la forme d'une couche d'application à usage général, elles sont souvent gérées de manière entièrement manuelle. Il est tout à fait possible qu'elles soient écrites une fois, ajoutées à la base de données, puis qu'elles ne soient jamais modifiées, par crainte de causer un dysfonctionnement.
Avec D1, nous pouvons faire mieux.
L'objectif d'une procédure stockée était de s'exécuter à proximité immédiate des données ; le téléchargement du code et son exécution dans la base de données étaient simplement un moyen d'y parvenir. Toutefois, nous utilisons Workers, une plateforme globale d'exécution JavaScript, alors, pouvons-nous utiliser ces instances pour résoudre ce problème ?
Il s'avère que oui, absolument ! Mais ici, nous avons quelques possibilités pour parvenir précisément au résultat souhaité, et nous coopérons avec les utilisateurs de notre bêta privée pour identifier la bonne API. Dans cette section, j'aimerais vous présenter notre principale proposition actuelle et vous inviter à nous faire part de vos commentaires.
Lorsque vous connectez un projet Workers à une base de données D1, vous ajoutez la section suivante à votre fichier wrangler.toml :
[[ d1_databases ]]
# What binding name to use (e.g. env.DB):
binding = "DB"
# The name of the DB (used for wrangler d1 commands):
database_name = "my-d1-database"
# The D1's ID for deployment:
database_id = "48a4224e-...3b09"
# Which D1 to use for `wrangler dev`:
# (can be the same as the previous line)
preview_database_id = "48a4224e-...3b09"
# NEW: adding "procedures", pointing to a new JS file:
procedures = "./src/db/procedures.js"
Le fichier D1 Procedures contiendrait les indications suivantes (remarquez la nouvelle API db.transaction(), uniquement disponible dans un fichier comme celui-ci) :
export default class Procedures {
constructor(db, env, ctx) {
this.db = db
}
// any methods you define here are available on env.DB.Procedures
// inside your Worker
async Checkout(cartId: number) {
// Inside a Procedure, we have a new db.transaction() API
const result = await this.db.transaction(async (txn) => {
// Transaction has begun: we know the user can't add anything to
// their cart while these actions are in progress.
const [cart, user] = Helpers.loadCartAndUser(cartId)
// We can update the DB first, knowing that if any of the later steps
// fail, all these changes will be undone.
await this.db
.prepare(`UPDATE cart SET status = ?1 WHERE cart_id = ?2`)
.bind('purchased', cartId)
.run()
const newBalance = user.balance - cart.total_cost
await this.db
.prepare(`UPDATE user SET balance = ?1 WHERE user_id = ?2`)
// Note: the DB may have a CHECK to guarantee 'user.balance' can not
// be negative. In that case, this statement may fail, an exception
// will be thrown, and the transaction will be rolled back.
.bind(newBalance, cart.user_id)
.run()
// Once all the DB changes have been applied, attempt the payment:
const { ok, details } = await PaymentAPI.processPayment(
user.payment_method_id,
cart.total_cost
)
if (!ok) {
// If we throw an Exception, the transaction will be rolled back
// and result.error will be populated:
// throw new PaymentFailedError(details)
// Alternatively, we can do both of those steps explicitly
await txn.rollback()
// The transaction is rolled back, our DB is now as it was when we
// started. We can either move on and try something new, or just exit.
return { error: new PaymentFailedError(details) }
}
// This is implicitly called when the .transaction() block finishes,
// but you can explicitly call it too (potentially committing multiple
// times in a single db.transaction() block).
await txn.commit()
// Anything we return here will be returned by the
// db.transaction() block
return {
amount_charged: cart.total_cost,
remaining_balance: newBalance,
}
})
if (result.error) {
// Our db.transaction block returned an error or threw an exception.
}
// We're still in the Procedure, but the Transaction is complete and
// the DB is available for other writes. We can either do more work
// here (start another transaction?) or return a response to our Worker.
return result
}
}
Et dans votre instance Workers, votre liaison de base de données comporte maintenant une propriété "Procedures", où figurent les noms des fonctions :
const { error, amount_charged, remaining_balance } =
await env.DB.Procedures.Checkout(params.cartId)
if (error) {
// Something went wrong, `error` has details
} else {
// Display `amount_charged` and `remaining_balance` to the user.
}
Plusieurs instances de Procedures peuvent être déclenchées simultanément, mais une seule fonction db.transaction() peut être active à la fois : toute autre requête d'écriture ou bloc de transaction sera mise en file d'attente, mais toutes les requêtes de lecture continueront à être transmises aux répliques locales et s'exécuteront normalement. Cette API vous permet de garantir la cohérence lorsqu'elle est essentielle, avec un impact minimal sur les performances globales au niveau mondial.
Demande de commentaires
À l'image de tous nos produits, la feuille de route et le développement sont déterminés par les commentaires de nos utilisateurs. Bien que l'API D1 soit aujourd'hui en phase de bêta test, nous sommes toujours à la recherche de commentaires concernant ses spécificités. Cependant, nous sommes heureux de constater que nous avons résolu à la fois les problèmes liés aux transactions spécifiques à D1, ainsi que les problèmes relatifs aux procédures stockées, décrits plus haut :
- Le code est exécuté aussi près que possible de la base de données, ce qui élimine la latence du réseau lorsqu'une transaction est ouverte.
- Toute exception ou annulation d'une transaction entraîne une restauration instantanée ; il est impossible qu'une transaction soit accidentellement laissée en suspens et bloque l'ensemble de l'instance D1.
- Le code est écrit dans le même langage que votre instance Workers, et précisément dans le même « dialecte » (par ex. la même configuration TypeScript, puisqu'il fait partie de la même version).
- Il est déployé de manière transparente et intégré à votre instance Workers. Si deux instances Workers sont liées à la même instance D1, mais définissent des procédures différentes, elles ne verront que leur code. Si vous souhaitez partager du code entre des projets ou des bases de données, extrayez une bibliothèque comme vous le feriez avec tout autre code partagé.
- Pendant le développement et les tests locaux, la procédure s'exécute de la même manière que pendant la production, toutefois sans l'appel réseau, ce qui permet d'effectuer les tests et le débogage avec fluidité, comme s'il s'agissait d'une fonction locale.
- Parce que les procédures et l'instance Workers qui les définissent sont traités comme une unité unique, la restauration d'une version antérieure n'entraîne jamais de décalage entre le code de la base de données et le code de l'instance Workers.
L'écosystème D1 : les contributions de la communauté
Nous vous avons parlé de ce que nous avons accompli et des événements à venir, mais l'une des particularités de ce projet réside dans les contributions de nos utilisateurs. L'un de nos aspects préférés des bêtas privées est non seulement de recevoir des commentaires et des demandes de fonctionnalités, mais également de découvrir quelles idées et quels projets se concrétisent. Si parfois, il s'agit simplement de projets personnels, avec D1, nous découvrons des contributions incroyables à l'écosystème D1. Il va sans dire que le travail investi dans D1 n'est pas seulement l'œuvre de l'équipe D1, mais également celui de la communauté au sens large et des autres développeurs de Cloudflare. Les utilisateurs ont présenté leurs contributions à D1 sur notre canal privé Discord dédié à la version bêta et ont permis à d'autres d'y accéder également. Nous voulions prendre un moment pour souligner leur importance.
workers-qb
L'utilisation de la syntaxe SQL brute est une approche puissante (et, avec l'API .bind() de D1, offre une protection contre les injections SQL), mais elle peut également s'avérer peu ergonomique. À l'inverse, la plupart des générateurs de requêtes existants supposent que vous disposez d'un accès direct à la base de données sous-jacente, et ne sont donc pas utilisables avec D1. Gabriel Massadas, développeur chez Cloudflare, a donc conçu workers-qb, un petit générateur de requêtes sans dépendance :
import { D1QB } from 'workers-qb'
const qb = new D1QB(env.DB)
const fetched = await qb.fetchOne({
tableName: "employees",
fields: "count(*) as count",
where: {
conditions: "active = ?1",
params: [true]
},
})
Consultez la page d'accueil du projet pour plus d'informations : https://workers-qb.massadas.com/.
Console D1
Bien que vous puissiez interagir avec D1 par le biais de Wrangler et du tableau de bord, Isaac McFadyen, champion de la communauté Cloudflare, a créé la toute première console D1 depuis laquelle vous pouvez exécuter rapidement une série de requêtes directement dans votre terminal. La console D1 vous dispense de passer du temps à écrire les différentes commandes Wrangler que nous avons créées ; il vous suffit d'exécuter vos requêtes.
Elle inclut toutes les fonctionnalités que vous pouvez attendre d'une console de base de données moderne, notamment la saisie multiligne, un historique des commandes, la validation d'éléments que D1 ne prend peut-être pas encore en charge et la possibilité d'enregistrer vos informations d'identification Cloudflare, afin de les utiliser ultérieurement.
Découvrez le projet dans son intégralité sur GitHub ou NPM pour plus d'informations.
Intégration test de Miniflare
Le projet Miniflare, sur lequel repose l'expérience de développement local de Wrangler, propose également des environnements de test à part entière pour les célèbres moteurs de test JavaScript Jest et Vitest. À cela s'ajoute le concept de stockage isolé, qui permet d'exécuter chaque test indépendamment des autres, afin que les modifications mises en œuvre dans un test n'affectent pas les autres. Brendan Coll, créateur de Miniflare, a supervisé le déploiement test de D1, afin qu'il offre les mêmes avantages :
import Worker from ‘../src/index.ts’
const { DB } = getMiniflareBindings();
beforeAll(async () => {
// Your D1 starts completely empty, so first you must create tables
// or restore from a schema.sql file.
await DB.exec(`CREATE TABLE entries (id INTEGER PRIMARY KEY, value TEXT)`);
});
// Each describe block & each test gets its own view of the data.
describe(‘with an empty DB’, () => {
it(‘should report 0 entries’, async () => {
await Worker.fetch(...)
})
it(‘should allow new entries’, async () => {
await Worker.fetch(...)
})
])
// Use beforeAll & beforeEach inside describe blocks to set up particular DB states for a set of tests
describe(‘with two entries in the DB’, () => {
beforeEach(async () => {
await DB.prepare(`INSERT INTO entries (value) VALUES (?), (?)`)
.bind(‘aaa’, ‘bbb’)
.run()
})
// Now, all tests will run with a DB with those two values
it(‘should report 2 entries’, async () => {
await Worker.fetch(...)
})
it(‘should not allow duplicate entries’, async () => {
await Worker.fetch(...)
})
])
Toutes les bases de données utilisées pour les tests sont exécutées en mémoire, et sont donc extrêmement rapides. Et des tests rapides et fiables constituent une part importante de la création d'applications viables dans le monde réel. Nous sommes donc ravis d'étendre cette capacité à D1.
Vous souhaitez accéder à la bêta
privée ?
Vous vous sentez inspiré ?
Nous adorons découvrir ce que les utilisateurs de notre bêta créent ou aspirent à créer, surtout lorsque nos produits se trouvent encore à un stade précoce du développement. À mesure que nous progressons vers une version bêta ouverte, nous sommes particulièrement demandeurs de commentaires de votre part. Nous ouvrons progressivement la bêta à de nouveaux utilisateurs, mais si vous n'avez pas encore reçu votre « ticket d'or » pour y accéder, inscrivez-vous ici ! Lorsque vous aurez été invité à la rejoindre, vous recevrez un e-mail de bienvenue officiel.
Comme toujours, bon développement !