
Si vous avez vu notre autre post, vous savez que nous avons mis WARP à la disposition des derniers membres de notre liste d'attente aujourd'hui. En créant WARP, notre objectif était de sécuriser et d'améliorer la connexion entre vos appareils mobiles et Internet. Au cours du projet, nous avons rencontré des problèmes avec les versions de téléphone et de système d'exploitation, les différents réseaux et notre propre infrastructure, alors que nous travaillions pour répondre à une liste d'attente insatisfaite comportant près de deux millions de personnes.
Pour comprendre tous ces problèmes et comment nous les avons résolus, il nous faut d'abord rappeler comment fonctionne le réseau Cloudflare :
Fonctionnement de notre réseau
Le réseau Cloudflare est composé de centres de données situés dans 194 villes, dans plus de 90 pays. Chaque centre de données Cloudflare comprend de nombreux serveurs qui reçoivent un flot continu de requêtes répartis entre les serveurs qui les traitent. Nous utilisons un ensemble de routeurs pour effectuer cette opération :
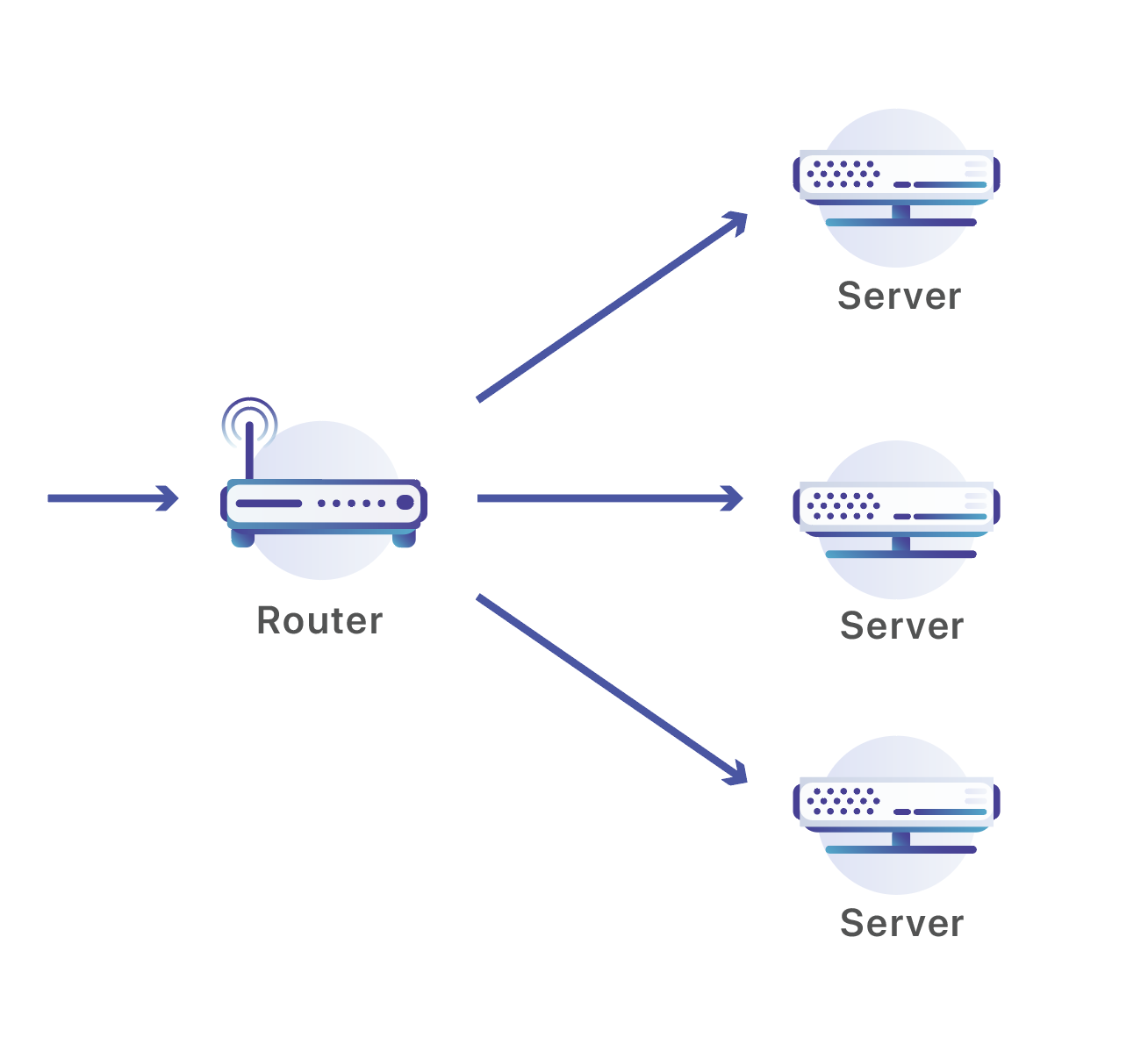
Nos routeurs écoutent les adresses IP Anycast qui sont annoncées sur l’Internet public. Si vous avez un site sur Cloudflare, votre site est disponible via deux de ces adresses. Dans ce cas, je fais une requête DNS pour « workers.dev », un site qui est géré par Cloudflare :
➜ creuser workers.dev
;; QUESTION SECTION:
;workers.dev. IN A
;; ANSWER SECTION:
workers.dev. 161 IN A 198.41.215.162
workers.dev. 161 IN A 198.41.214.162
;; SERVER: 1.1.1.1#53(1.1.1.1)
workers.dev est disponible à deux adresses 198.41.215.162 et 198.41.214.162 (avec deux adresses IPv6 disponibles via la requête DNS AAAA). Ces deux adresses sont diffusées depuis chacun de nos centres de données à travers le monde. Lorsque quelqu'un se connecte à une propriété Internet sur Cloudflare, chaque périphérique réseau par lequel les paquets transitent choisira le chemin le plus court vers le centre de données Cloudflare le plus proche de l’ordinateur ou du téléphone de cet utilisateur.
Une fois que les paquets ont atteint notre centre de données, nous les envoyons à l'un des nombreux serveurs en service. Traditionnellement, on peut utiliser un équilibreur de charge pour faire ce type de répartition de trafic sur plusieurs machines. Malheureusement, mettre un ensemble d'équilibreurs de charge capables de gérer notre volume de trafic dans chaque centre de données serait bien trop onéreux et ne serait pas aussi facile à mettre en place que nos serveurs. Au lieu de cela, nous utilisons des appareils conçus pour fonctionner sur des volumes exceptionnels de trafic : des routeurs réseau.
Une fois qu'un paquet atteint notre centre de données, il est traité par un routeur. Ce routeur envoie le trafic à l'un des ensembles de serveurs responsables de la gestion de cette adresse, à l'aide d'un algorithme de routage appelé ECMP (Equal-Cost Multi-Path). ECMP se réfère à la situation dans laquelle le routeur n’a pas de « gagnant » entre plusieurs itinéraires de mérite égal, il dispose de plusieurs « prochains bonds » corrects, tous avec la même destination finale. Dans notre cas, nous contournons un peu ce concept. Plutôt que d'utiliser ECMP pour créer un équilibre entre plusieurs liens intermédiaires, nous faisons en sorte que le lien intermédiaire s’adresse à la destination finale de notre trafic : nos serveurs.
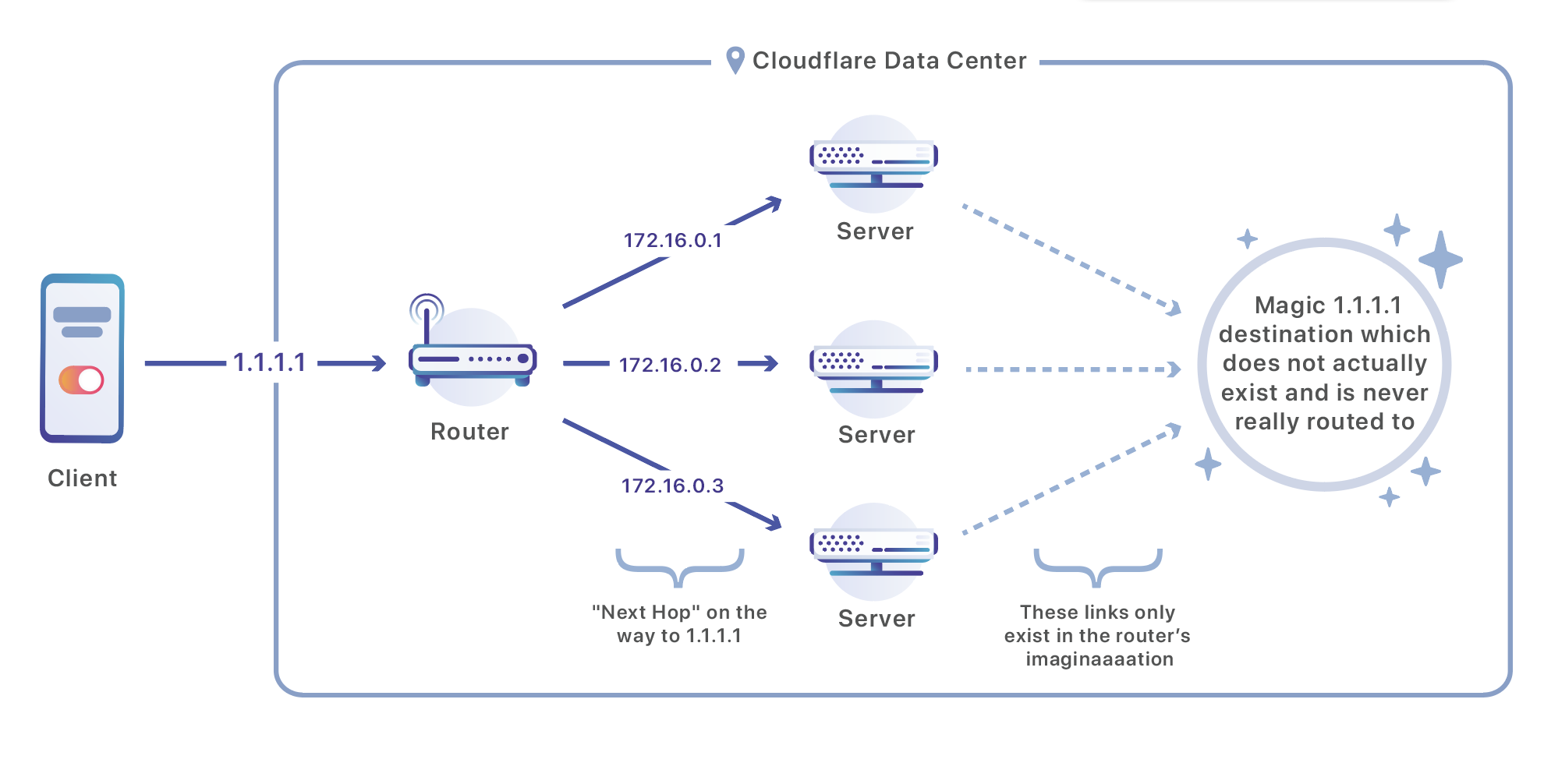
Voici la configuration d'un routeur de marque Juniper que l’on peut trouver dans l'un de nos centres de données et qui est configuré pour équilibrer le trafic sur trois destinations :
user@host# show routing-options
static {
route 172.16.1.0/24 next-hop [ 172.16.2.1 172.16.2.2 172.16.2.3 ];
}
forwarding-table {
export load-balancing-policy;
}
Étant donné que le « prochain bond » est notre serveur, le trafic sera divisé entre plusieurs machines de manière très efficace.
TCP, IP et ECMP
L’IP est responsable de l'envoi de paquets de données à partir d'adresses comme 93.184.216.34 à 208.80.153.224 (ou [2606:2800:220:1:248:1893:25c8:1946] à [2620:0:860:ed1a::1] dans le cas de IPv6) par Internet. C'est le « Protocole Internet ».
TCP (Transmission Control Protocol) fonctionne au sommet d’un protocole comme IP qui peut envoyer un paquet d'un endroit à un autre et rend la transmission de données fiable et utile pour plusieurs processus à la fois. Il est chargé de prendre les paquets peu fiables et mal classés qui pourraient arriver sur un protocole comme IP et de les livrer de manière fiable, dans le bon ordre. Il introduit également le concept d'un « port », un numéro de 1-65535 qui aide à acheminer le trafic sur un ordinateur ou un téléphone vers un service spécifique (comme le Web ou la messagerie électronique). Chaque connexion TCP a un port source et un port destination inclus dans l'en-tête que TCP ajoute au début de chaque paquet. Sans cette idée de ports, il ne serait pas facile de savoir quel message est destiné à quel programme. Par exemple, Google Chrome et Mail peuvent vouloir envoyer des messages via votre connexion Wi-Fi en même temps, de sorte qu'ils utiliseront chacun leur propre port.
Voici un exemple de demande effectuée pour https://cloudflare.com/ au 198.41.215.162, sur le port par défaut pour HTTPS: 443. De manière aléatoire, mon ordinateur m'a assigné le port 51602 sur lequel il restera à l’écoute pour obtenir une réponse, qui (espérons-le) recevra le contenu du site :
Internet Protocol Version 4, Src: 19.5.7.21, Dst: 198.41.215.162
Protocol: TCP (6)
Source: 19.5.7.21
Destination: 198.41.215.162
Transmission Control Protocol, Src Port: 51602, Dst Port: 443, Seq: 0, Len: 0
Source Port: 51602
Destination Port: 443
En regardant la même requête du côté Cloudflare, on obtiendra une image miroir, une demande de mon adresse IP publique provenant de mon port source, destinée au port 443 (je décide d’ignorer NAT pour le moment, nous y reviendrons plus en détails plus tard) :
Internet Protocol Version 4, Src: 198.41.215.16, Dst: 19.5.7.21
Protocol: TCP (6)
Source: 198.41.215.162
Destination: 19.5.7.21
Transmission Control Protocol, Src Port: 443, Dst Port: 51602, Seq: 0, Len: 0
Source Port: 443
Destination Port: 51602
Nous pouvons maintenant revenir à ECMP ! Théoriquement, il pourrait être possible d'utiliser ECMP pour équilibrer les paquets entre les serveurs de manière aléatoire, mais il faut mieux éviter de le faire. Un message sur Internet est généralement composé de plusieurs paquets TCP. Si chaque paquet était envoyé à un serveur différent, il serait impossible de reconstruire le message original en un endroit quelconque et d'agir sur celui-ci. Par ailleurs, le résultat serait catastrophique pour la performance : nous comptons sur notre capacité à maintenir actives des sessions TCP et TLS de longue durée qui nécessitent une connexion persistante à un seul serveur. Pour assurer cette continuité, nos routeurs n'équilibrent pas le trafic de manière aléatoire. Ils utilisent la combinaison de quatre valeurs : l'adresse source, le port source, l'adresse de destination et le port de destination. Le trafic avec la même combinaison de ces quatre valeurs arrivera toujours au même serveur. Dans le cas de mon exemple ci-dessus, tous mes messages destinés à cloudflare.com arriveront sur un seul serveur qui pourra reconstruire les paquets TCP de ma requête et retourner les paquets dans une réponse.
Entrez dans WARP
Pour une requête conventionnelle, il est très important que notre routage ECMP envoie tous vos paquets sur le même serveur pendant la durée de votre requête. Sur le Web, une requête dure généralement moins de dix secondes et le système fonctionne bien. Malheureusement, nous avons rapidement rencontré des problèmes avec WARP.
WARP utilise une clé de session négociée avec un chiffrement à clé publique pour sécuriser les paquets. Pour une connexion réussie, les deux parties doivent négocier une connexion qui n'est valide que pour ce client particulier et le serveur spécifique auquel elles s’adressent. Cette négociation prend du temps et doit être terminée chaque fois qu'un client s’adresse à un nouveau serveur. Pire encore, si des paquets sont supposées arriver sur un serveur et finissent sur un autre, ils ne peuvent pas être déchiffrés et la connexion est interrompue. Détecter ces paquets défaillants et redémarrer la connexion à partir de zéro prend tellement de temps que nos testeurs alpha l'ont expérimenté comme une perte totale de leur connexion Internet. Comme vous pouvez l'imaginer, les testeurs ne quittent pas WARP très longtemps lorsque cela les empêche d'utiliser l'Internet.
WARP a connu de nombreuses défaillances dues au fait que les appareils changeaient de serveurs beaucoup plus souvent que ce que nous avions prévu. Si vous vous souvenez, notre configuration de routeur ECMP utilise une combinaison (Source IP, port source, IP de destination, port de destination) pour faire correspondre un paquet à un serveur. L’IP de destination ne change généralement pas, les clients WARP se connectant toujours aux mêmes adresses Anycast. De même, le port de destination ne change pas, nous écoutons toujours sur le même port le trafic WARP. Les deux autres valeurs, l’IP source et le port source, changeaient beaucoup plus souvent que ce que nous avions prévu.
Nous avions prévu une source de ces changements. WARP fonctionne sur les téléphones portables, qui passent généralement de connexions cellulaires au Wi-Fi. Lorsque vous effectuez ce changement, vous passez soudain d’une communication sur Internet via l'espace d'adresse IP de votre opérateur cellulaire (comme AT&T ou Verizon) à celui du fournisseur de services Internet que votre connexion Wi-Fi utilise (comme Comcast ou Google Fiber). Il est pratiquement impossible que votre adresse IP ne change pas lorsque vous passez d'une connexion à une autre.
Les changements de port se sont toutefois produits encore plus fréquemment que ce que l’on pourrait attendre de commutateurs réseau. Pour comprendre pourquoi, il convient de présenter une autre composante des mécanismes habituels sur Internet : NAT (Translation d'adresse réseau).
NAT
Une adresse IPv4 est composée de 32 bits (souvent écrits en quatre nombres de huit bits). Si vous excluez les adresses réservées qui ne peuvent pas être utilisées, il vous reste 3 706 452 992 adresses possibles. Ce nombre est resté constant depuis que l'IPv4 a été déployé sur l'ARPANET en 1983, alors même que le nombre d'appareils a explosé (bien qu'il puisse augmenter un peu bientôtsi le 0.0.0.0/8 devient disponible). Ces données sont basées sur les prédictions et les estimations de Gartner Research :
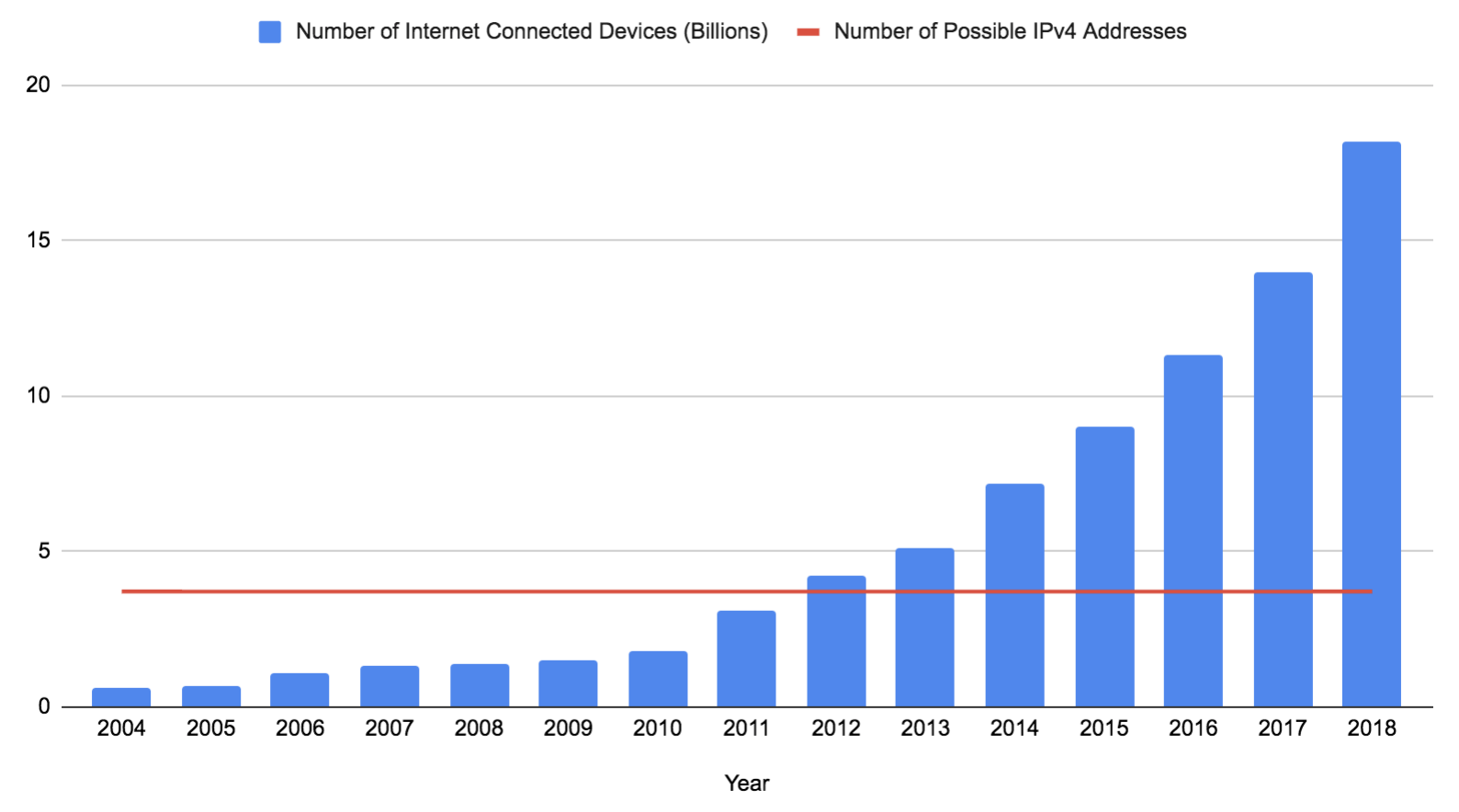
IPv6 apporte une solution permanente à ce problème. Il étend la longueur d'une adresse de 32 à 128 bits, avec 125 bits disponibles dans une adresse Internet valide pour le moment (toutes les adresses IPv6 publiques ont les trois premiers bits réglés à 001, les 87,5 % restants de l'espace d'adresse IPv6 ne sont pas encore considérés comme nécessaire). 2125 est un nombre incroyablement élevé et serait plus que suffisant pour que chaque appareil sur Terre dispose de sa propre adresse. Malheureusement, 21 ans après sa publication, IPv6 n'est toujours pas pris en charge sur de nombreux réseaux. Une grande partie d'Internet repose encore sur IPv4, et comme nous l’avons vu ci-dessus, le nombre d'adresses IPv4 est insuffisant pour que chaque appareil ait la sienne.
Pour résoudre ce problème, plusieurs appareils sont généralement mis derrière une seule adresse IP adressable par Internet. Un routeur est utilisé pour effectuer la NAT (Translation d’adresse réseau), pour prendre les messages qui arrivent sur cette adresse IP publique unique et les transmettre à l'appareil approprié sur leur réseau local. En effet, tout se passe comme si tous les habitants d’un immeuble avait la même adresse et que le facteur était chargé de trier le courrier pour délivrer chaque courrier à la bonne personne.
Lorsque vos appareils envoient un paquet destiné à Internet, votre routeur l'intercepte. Le routeur réécrit ensuite l'adresse source à l'adresse Internet publique unique qui vous est attribuée, et le port source à un port unique pour tous les messages envoyés sur tous les appareils connectés à Internet sur votre réseau. Tout comme votre ordinateur choisit un port source aléatoire pour vos messages qui était unique entre tous les différents processus sur votre ordinateur, votre routeur choisit un port source aléatoire unique pour toutes les connexions Internet sur l'ensemble de votre réseau. Il se souvient du port qu'il sélectionne pour vous comme appartenant à votre connexion et permet au message de continuer son chemin sur Internet.
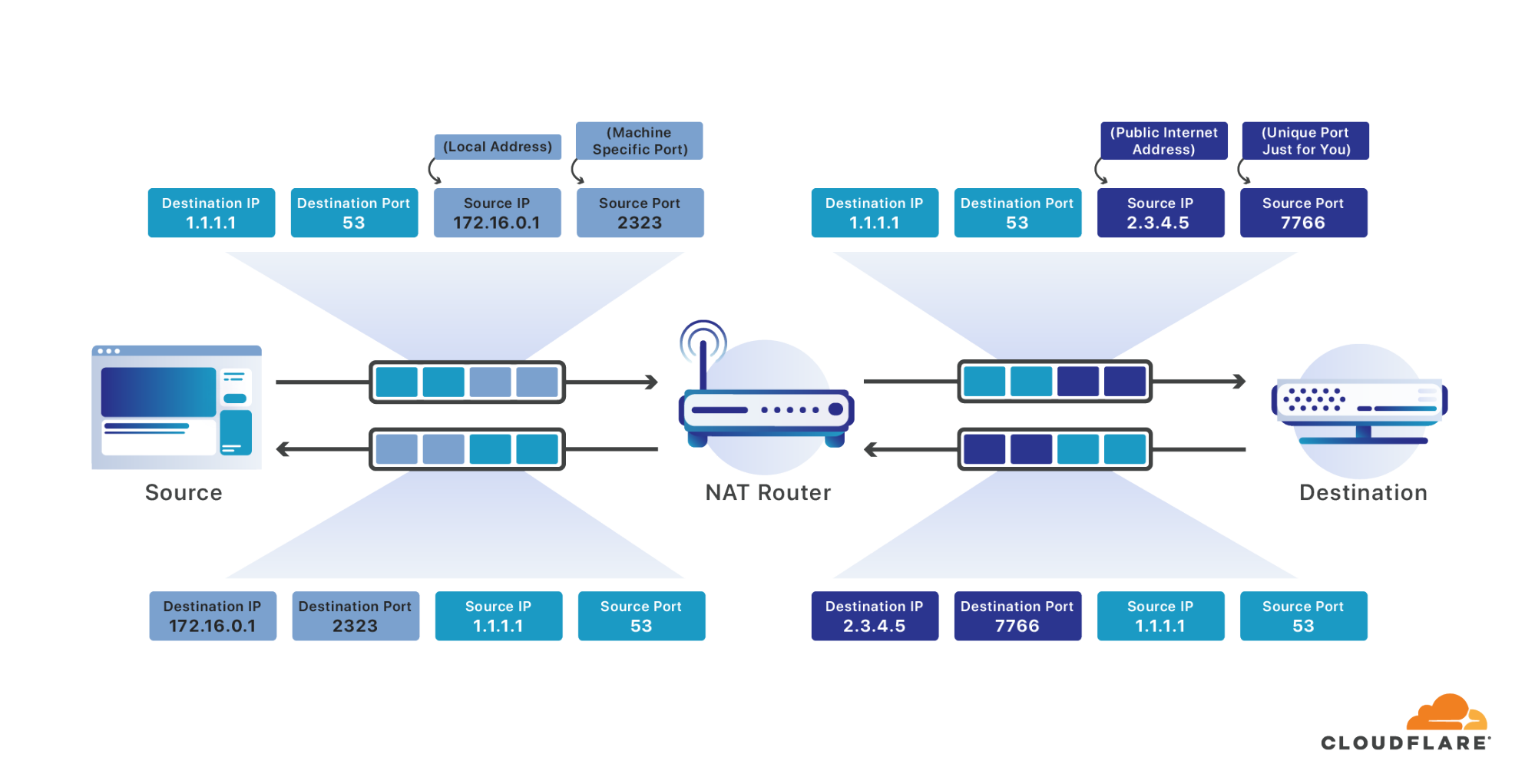
Lorsqu'une réponse arrive destinée au port qu’il vous a attribué, il la fait correspondre à votre connexion et la réécrit à nouveau, remplaçant cette fois l'adresse de destination par votre adresse sur le réseau local et le port de destination, avec le port source d'origine que vous avez spécifié. Il a permis de manière transparente à tous les appareils de votre réseau d'agir comme s'il s'agissait d'un gros ordinateur avec une seule adresse IP connectée à Internet.
Ce processus fonctionne très bien pour la durée d'une requête commune sur Internet. Cependant, seul votre routeur a tellement d'espace qu'il supprimera utilement les affectations de vieux ports, en libérant de l'espace pour les nouveaux. Il attend généralement que la connexion n'ait pas de messages pendant au moins trente secondes avant de supprimer une affectation, ce qui rend peu probable l’arrivée d’une réponse sans qu’elle puisse être redirigée vers la source appropriée. Malheureusement, les sessions WARP doivent durer beaucoup plus que trente secondes.
Lorsque vous envoyez un message après l'expiration de votre session NAT, un nouveau port source vous est attribué. Ce nouveau port entraîne la modification de votre mappage ECMP (basé sur l’IP source, le port source, l’IP de destination, le port de destination), ce qui nous amène à acheminer vos requêtes vers une nouvelle machine dans le centre de données Cloudflare où vos messages arrivent. Cela interrompt votre session WARP et votre connexion Internet.
Nous avons expérimenté de nombreuses méthodes pour maintenir active votre session NAT en envoyant périodiquement des messages keep-alive qui empêchent les routeurs et les opérateurs mobiles de rejeter les mappages. Malheureusement, réveiller la radio de votre appareil toutes les trente secondes a des conséquences néfastes sur la durée de vie de votre batterie, et cette mesure n'a pas permis de prévenir complètement les changements de port et d'adresse. Nous avions besoin d'un moyen de toujours mapper les sessions vers la même machine, même si leur port source (et même l'adresse source) avaient changé.
Heureusement, chez Cloudflare nous avions une solution qui venait d'ailleurs. Nous n'utilisons pas d'équilibreurs de charge dédiés, mais nous rencontrons effectivement les nombreux problèmes similaires à ceux que les équilibreurs de charge résolvent. Nous avons longtemps eu besoin de mapper le trafic vers les serveurs Cloudflare avec plus de contrôle que le routage ECMP le permet seul. Plutôt que de déployer une couche complète d'équilibreurs de charge, nous utilisons chaque serveur de notre réseau comme un équilibreur de charge, en envoyant tout d’abord les paquets à une machine arbitraire, puis en nous appuyant sur cette machine pour transmettre le paquet à l'hôte approprié. Cette opération consomme un niveau de ressources minimum et nous permet d'étendre notre infrastructure d'équilibrage de charge à chaque nouvelle machine que nous ajoutons. Nous avons encore de nombreuses choses à dire sur le fonctionnement de cette infrastructure et sur ce qui la rend unique. Abonnez-vous à ce blog pour être informé lorsque ce post sera publié.
Cependant, pour que notre technique d'équilibrage de charge fonctionne, nous avions besoin d'un moyen pour identifier à quel client un paquet WARP était associé avant qu'il puisse être déchiffré. Pour comprendre comment nous l’avons fait, il est utile de comprendre comment WARP chiffre vos messages. La manière habituelle pour connecter un appareil à un réseau distant consiste à utiliser un VPN. Les VPN utilisent un protocole tel que IPsec pour permettre à votre appareil d'envoyer des messages en toute sécurité à un réseau distant. Malheureusement, les VPN sont plutôt mal vus. Ils ralentissent les connexions, épuisent les batteries et leur complexité est souvent une source de vulnérabilités compromettant la sécurité. Les utilisateurs de réseaux d'entreprise qui recourent à des VPN les détestent souvent, et l'idée de parvenir à convaincre des millions de consommateurs d’installer volontairement un VPN semblait ridicule.
Après avoir examiné et testé plusieurs options plus modernes, nous sommes tombés sur WireGuard®. WireGuard est un protocole moderne, haute performance, et surtout simple, créé par Jason Donenfeld pour résoudre le même problème. La base de son code d'origine est inférieure à 1 % de la taille d'une implémentation IPsec populaire, ce qui nous facilite non seulement notre compréhension du système et sa sécurité. Nous avons choisi Rust comme le langage qui était le plus susceptible de nous apporter la performance et la sécurité recherchées, et nous avons mis en œuvre WireGuard, tout en optimisant largement le code pour obtenir un fonctionnement rapide sur les plateformes que nous ciblions. Ensuite, nous avons mis le projet en open source.

WireGuard change deux choses très importantes sur le trafic que vous envoyez sur Internet. La première est qu'il utilise UDP et non TCP. La deuxième est qu'il utilise une clé de session négociée avec un chiffrement à clé publique pour sécuriser le contenu de ce paquet UDP.
TCP est le protocole conventionnel utilisé pour le chargement d'un site Web sur Internet. Il combine la possibilité d'adresser les ports (point que nous avons évoqué précédemment) avec une livraison fiable et un contrôle de flux fiables. Une livraison fiable garantit qu’en cas de perte d’un message, TCP finira par renvoyer les données manquantes. Le contrôle de flux donne à TCP les outils dont il a besoin pour traiter de nombreux clients partageant tous le même lien qui dépassent sa capacité. UDP est un protocole beaucoup plus simple qui vise avant tout la simplicité. Il fait de son mieux pour envoyer un message, et si le message est manquant ou si les données pour les liens sont trop nombreuses, ce message tombe aux oubliettes.
Le manque de fiabilité d'UDP serait normalement un problème lors de la navigation sur Internet, mais nous n'envoyons pas simplement UDP. Nous envoyons un paquet TCP complet à l'intérieur de nos paquets UDP.
À l'intérieur du payload chiffré par WireGuard, nous avons un en-tête TCP complet qui contient toutes les informations nécessaires pour assurer une livraison fiable. Nous l'enveloppons ensuite avec le chiffrement de WireGuard et utilisons UDP pour l'envoyer sur Internet (de manière moins que fiable). S’il est perdu, TCP fait son travail, tout comme si un lien réseau avait perdu le message et le renvoyait. Si nous avions au contraire enveloppé notre session TCP interne, chiffrée, dans un autre paquet TCP, comme le font d'autres protocoles, nous augmenterions considérablement le nombre de messages réseau requis, en détériorant la performance.
Le deuxième élément intéressant de WireGuard qui nous intéresse est le chiffrage à clé publique. WireGuard vous permet de sécuriser chaque message que vous envoyez, de sorte que seule la destination spécifique à laquelle vous l'envoyez peut la déchiffrer. Il s’agit d’un moyen puissant pour assurer votre sécurité lorsque vous naviguez sur Internet, ce qui signifie qu'il est impossible de lire quoi que ce soit à l'intérieur du payload chiffré jusqu'à ce que le message ait atteint le serveur qui a la charge de votre session.
Pour en revenir à notre problème d'équilibrage de la charge, vous pouvez voir que nous n’avons l’accès qu’à trois éléments avant de pouvoir déchiffrer le message : L’en-tête IP, l'en-tête UDP et l’en-tête WireGuard. Ni l'en-tête IP ni l'en-tête UDP n'incluent les informations dont nous avons besoin, car nous avons déjà échoué avec les quatre renseignements qu'ils contiennent (IP source, port source, IP destination, port de destination). Il ne nous reste que l’en-tête WireGuard comme seul emplacement permettant de trouver un identifiant qui puisse être utilisé pour garder une trace de l’identité du client avant le déchiffrage du message. Malheureusement, celui-ci n’existe pas. Voici le format du message utilisé pour initier une connexion :

sender ressemble à s’y méprendre à un identifiant client, mais il est attribué de manière aléatoire à chaque handshake. Les handshakes doivent être effectués toutes les deux minutes pour faire tourner les clés, ce qui les rend insuffisamment persistantes. Nous aurions pu diviser le protocole pour ajouter un certain nombre de champs supplémentaires, mais il est important pour nous de rester compatibles avec d'autres clients WireGuard. Heureusement, WireGuard a un bloc de trois octets dans son en-tête qui n'est pas actuellement utilisé par d'autres clients. Nous avons décidé de mettre notre identifiant dans cette zone et de toujours prendre en charge les messages d'autres clients WireGuard (mais avec un itinéraire moins fiable que celui que nous pouvons offrir). Si cette section réservée est utilisée à d'autres fins, nous pouvons ignorer ces bits ou travailler avec l'équipe WireGuard pour étendre le protocole d'une manière différente plus appropriée.
Lorsque nous commençons une session WireGuard, nous incluons notre champ clientid qui est fourni par notre serveur d'authentification avec lequel il est nécessaire de communiquer pour commencer une session WARP :

Les messages de données incluent également le même champ :

Il est important de noter que la longueur du clientid n’est que de 24 bits. Cela signifie que le nombre de valeurs clientid possibles est inférieur au nombre actuel d'utilisateurs en attente d'utiliser WARP. Cela ne pose pas de problème dans la mesure où nous n’avons pas à suivre les utilisateurs WARP individuels. clientid n'est nécessaire que pour l'équilibrage des charges, une fois qu'il a rempli sa fonction, nous le supprimons de nos systèmes aussi rapidement que possible.
Le système d'équilibrage de charge utilise maintenant un hash du clientid pour identifier la machine vers laquelle un paquet doit être acheminé, ce qui signifie que les messages WARP arrivent toujours à la même machine, même en cas de changement de réseau ou si vous passez du Wi-Fi au cellulaire, et le problème a été éliminé.
Logiciel client
Cloudflare n'a jamais développé de logiciel client auparavant. Nous sommes fiers de vendre un service utilisable par tous sans achat de matériel ni fourniture d’une quelconque infrastructure. Pour que WARP fonctionne, cependant, nous avons dû déployer notre code sur l'une des plateformes matérielles les plus répandues au monde : les smartphones.
Bien que le développement de logiciels sur les appareils mobiles est devenu de plus en plus facile au cours de cette dernière décennie, malheureusement, le développement de logiciels de gestion de réseau de bas niveau reste assez difficile. Prenons un exemple : nous avons commencé le projet en utilisant la dernière API de connexion iOS appelée Network, introduite dans iOS 12. Apple recommande fortement l'utilisation de Network en ces termes : « Vos clients vont apprécier à quel point vos connexions seront meilleures et établies de manière plus fiable. Ils apprécieront également l’amélioration de durée de vie de leur batterie due à une meilleure performance. »
Le Network framework fournit une API d’un niveau agréablement élevé qui, comme le dit Apple, s'intègre bien avec les fonctionnalités de performance intégrées dans iOS. La création d'une connexion UDP (connexion est en fait un terme inapproprié, il n'existe pas de connexions en UDP, juste des paquets) est aussi simple que :
self.connection = NWConnection(host: hostUDP, port: portUDP, using: .udp)
Et l'envoi d'un message peut être aussi facile que :
self.connection?.send(content: content)
Malheureusement, à un certain moment le code est effectivement déployé, et les rapports de bugs commencent à arriver. Le premier problème tient au fait que la simplicité de l'API ne nous a pas permis de traiter plus d'un paquet UDP à la fois. Nous utilisons généralement des paquets atteignant 1500 octets ; l'exécution d'un test de vitesse de ma connexion sur Google Fiber se traduit actuellement par une vitesse de 370 Mbps, soit près de trente-et-un mille paquets par seconde. Tenter de traiter chaque paquet individuellement ralentissait les connexions jusqu'à 40 %. Selon Apple, la meilleure solution pour obtenir la performance dont nous avions besoin était de se replier sur l'ancienne API NWUDPSession, introduite dans iOS 9.
IPv6
Si nous comparons le code requis pour créer une NWUDPSession selon l'exemple ci-dessus, vous remarquerez que nous nous soucions soudainement du protocole IPv4 ou IPv6 que nous utilisons :
let v4Session = NWUDPSession(upgradeFor: self.ipv4Session)
v4Session.setReadHandler(self.filteringReadHandler, maxDatagrams: 32)
En fait, NWUDPSession ne gère pas beaucoup des éléments les plus délicats de la création de connexions sur Internet. Par exemple, le framework Network déterminera automatiquement si une connexion doit être effectuée sur IPv4 ou 6 :
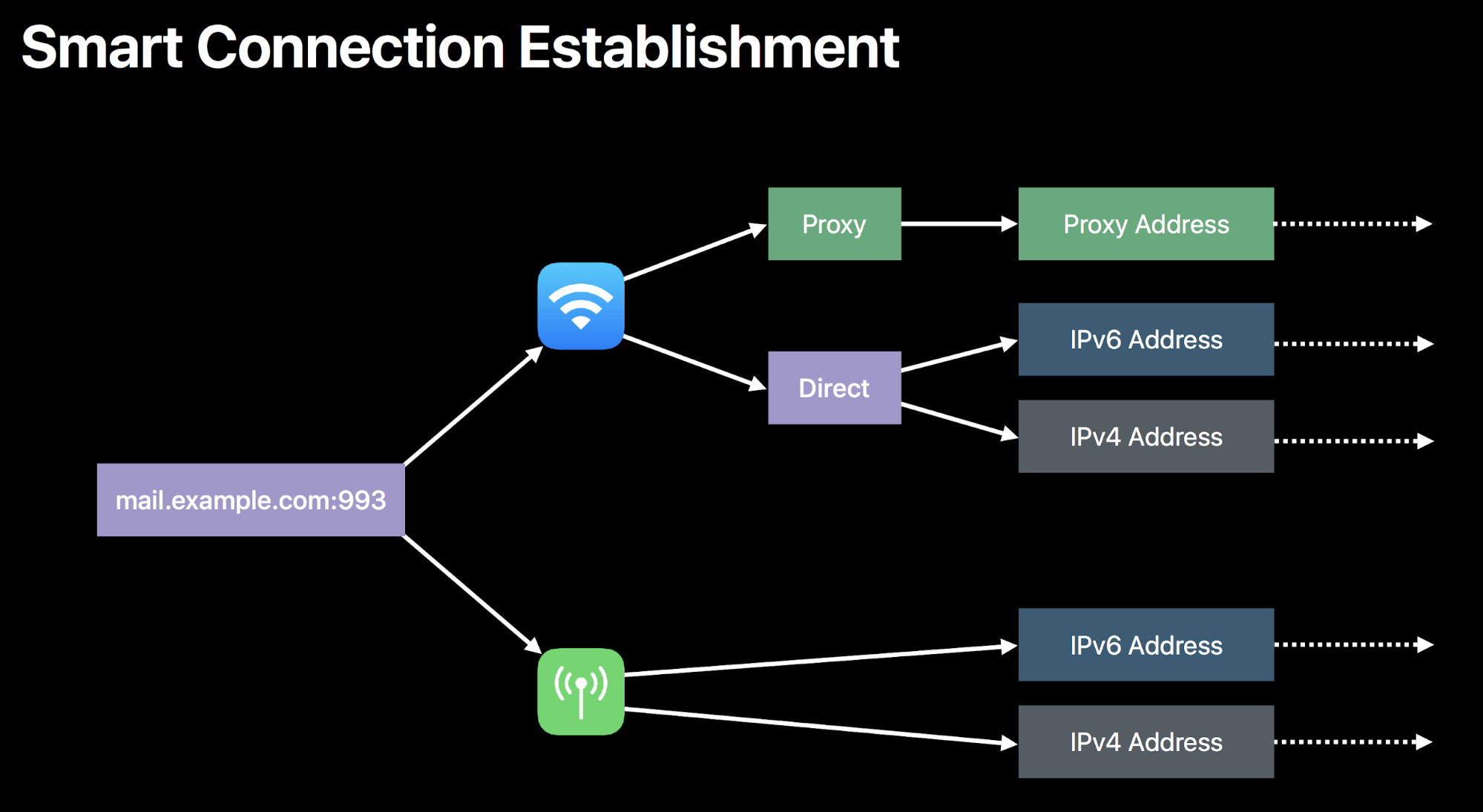
NWUDPSession ne le fait pas pour vous, nous avons donc commencé à créer notre propre logique pour déterminer quel type de connexion doit être utilisé. Une fois que nous avons commencé à faire des essais, il est rapidement devenu évident qu'ils ne sont pas créés égaux. Il est assez fréquent pour un itinéraire vers la même destination d'avoir une performance très différente selon que vous utilisez son adresse IPv4 ou IPv6. Souvent, la raison tient au fait qu'il y a tout simplement moins d'adresses IPv4 disponibles assez longtemps, ce qui permet à ces itinéraires d'être mieux optimisés par l'infrastructure d'Internet.
En règle générale, chaque produit Cloudflare doit prendre en charge IPv6. En 2016, nous avons activé IPv6 pour plus de 98 % de notre réseau, plus de quatre millions de sites, et nous avons fait une percée assez importante dans l’adoption d’IPv6 sur internet :
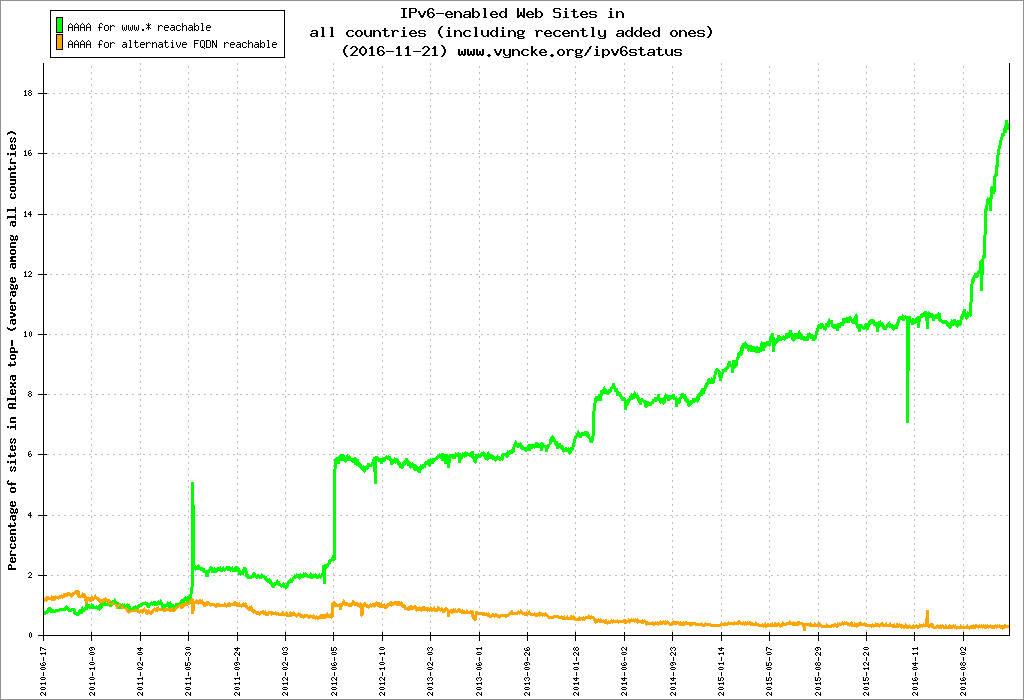
Nous ne pourrions pas proposer WARP sans le soutien d’IPv6. Nous devions nous assurer que nous utilisions toujours la connexion la plus rapide possible, tout en prenant en charge les deux protocoles de manière égale. Pour résoudre ce problème, nous nous sommes tournés vers une technologie que nous utilisons avec DNS depuis des années : Happy Eyeballs. Tel qu’il est codifié dans RFC 6555, l’idée de Happy Eyeballs est d’essayer de chercher à la fois une adresse IPv4 et IPv6 lors d’une requête DNS. Celle qui revient en premier gagne. De cette manière, vous pouvez permettre aux sites IPv6 de charger rapidement, même dans un monde qui ne le prend pas entièrement en charge.
Par exemple, je charge le site http://zack.is/. Mon navigateur Web fait en même temps une requête DNS pour l'adresse IPv4 (un enregistrement « A ») et l'adresse IPv6 (un enregistrement « AAAA ») :
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 1.1.1.1
User Datagram Protocol, Src Port: 47447, Dst Port: 53
Domain Name System (query)
Queries
zack.is: type A, class IN
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 1.1.1.1
User Datagram Protocol, Src Port: 49946, Dst Port: 53
Domain Name System (query)
Queries
zack.is: type AAAA, class INDans ce cas, la réponse à la requête A est retournée plus rapidement, et la connexion est établie en utilisant ce protocole :
Internet Protocol Version 4, Src: 1.1.1.1, Dst: 192.168.7.21
User Datagram Protocol, Src Port: 53, Dst Port: 47447
Domain Name System (response)
Queries
zack.is: type A, class IN
Answers
zack.is: type A, class IN, addr 104.24.101.191
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.24.101.191
Transmission Control Protocol, Src Port: 55244, Dst Port: 80, Seq: 0, Len: 0
Source Port: 55244
Destination Port: 80
Flags: 0x002 (SYN)
Nous n'avons pas besoin d’effectuer des requêtes DNS pour faire des connexions WARP, nous connaissons déjà les adresses IP de nos centres de données, mais nous voulons savoir laquelle des adresses IPv4 et IPv6 fournira un itinéraire plus rapide sur Internet. Pour ce faire, nous adoptons la même technique, mais au niveau du réseau : nous envoyons un paquet sur chaque protocole et utilisons le protocole qui revient en premier pour les messages suivants. Avec le traitement de quelques erreurs et la suppression de la journalisation pour des raisons de brièveté, il apparaît comme :
let raceFinished = Atomic<Bool>(false)
let happyEyeballsRacer: (NWUDPSession, NWUDPSession, String) -> Void = {
(session, otherSession, name) in
// Session is the session the racer runs for, otherSession is a session we race against
let handleMessage: ([Data]) -> Void = { datagrams in
// This handler will be executed twice, once for the winner, again for the loser.
// It does not matter what reply we received. Any reply means this connection is working.
if raceFinished.swap(true) {
// This racer lost
return self.filteringReadHandler(data: datagrams, error: nil)
}
// The winner becomes the current session
self.wireguardServerUDPSession = session
session.setReadHandler(self.readHandler, maxDatagrams: 32)
otherSession.setReadHandler(self.filteringReadHandler, maxDatagrams: 32)
}
session.setReadHandler({ (datagrams) in
handleMessage(datagrams)
}, maxDatagrams: 1)
if !raceFinished.value {
// Send a handshake message
session.writeDatagram(onViable())
}
}
Cette technique nous permet de prendre en charge l'adressage IPv6. En fait, chaque appareil qui utilise WARP prend instantanément en charge l’adressage IPv6 même sur les réseaux qui ne le prennent pas en charge. L'utilisation de WARP prend les 34 % du réseau de Comcast qui ne prend pas en charge IPv6 ou les 69 % du réseau de Charter qui ne le prend pas en charge (en 2018), et permet à ces utilisateurs de communiquer avec succès avec les serveurs IPv6.
Ce test montre la prise en charge IPv6 de mon téléphone avant et après l'activation de WARP :
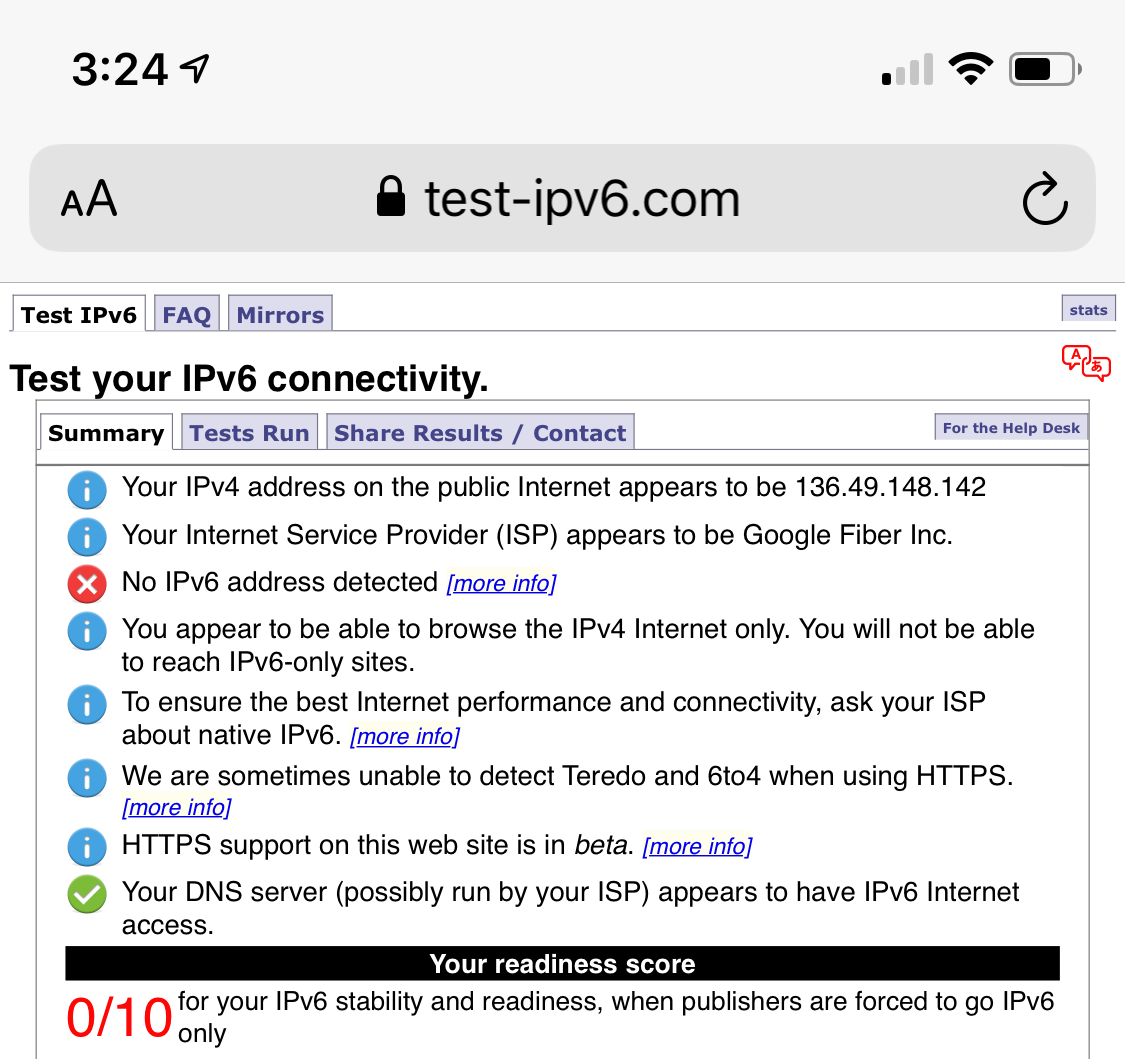
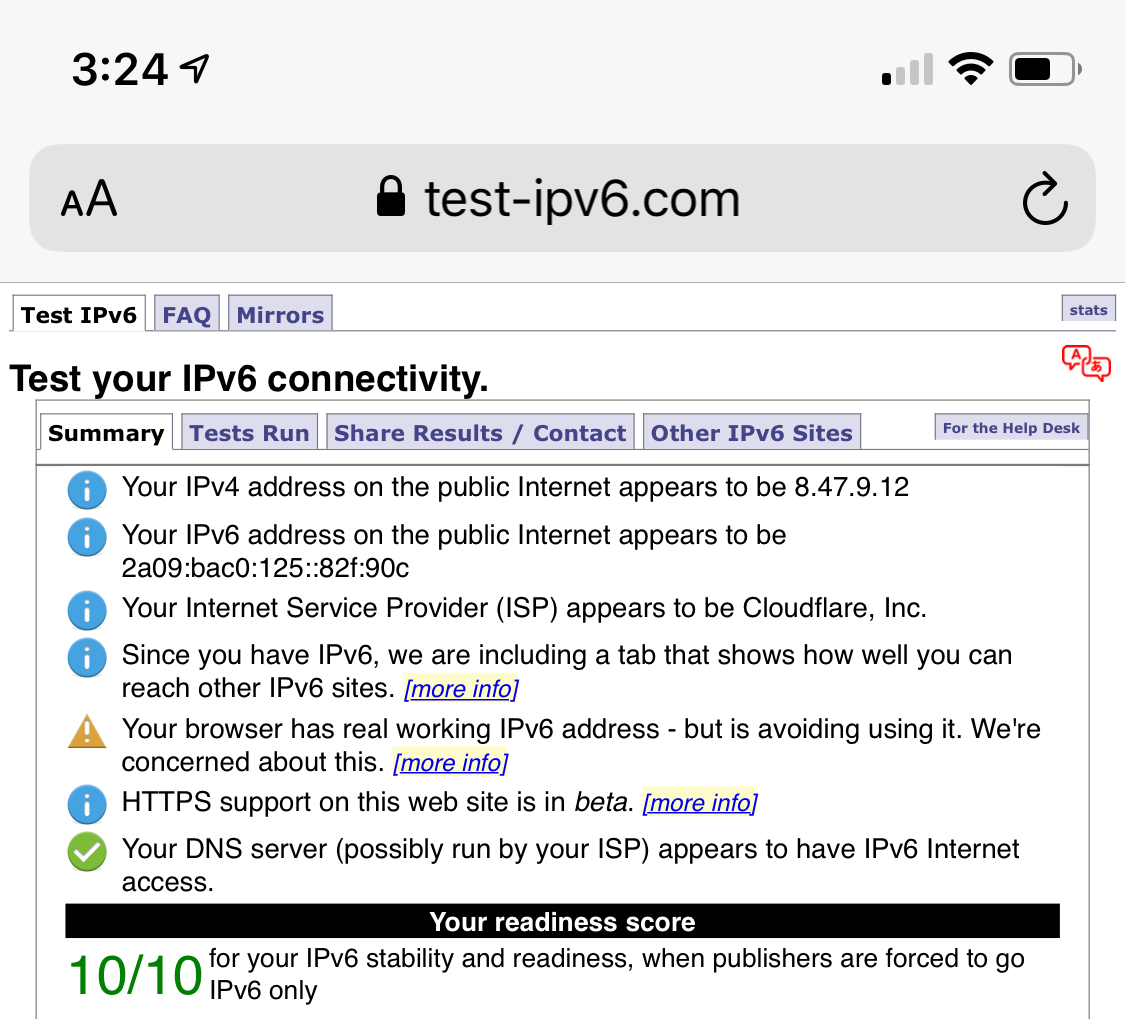
Connexions détruites
Rien n'est simple cependant, avec iOS 12.2. NWUDPSession a commencé à déclencher des erreurs qui ont détruit les connexions. Ces erreurs n'ont été identifiées qu'avec un code « 55 ». Après quelques recherches, il semble que 55 renvoie à la même erreur depuis les premières fondations du système d'exploitation FreeBSD OS X. Dans FreeBSD, cette erreur est communément appelée ENOBUFS, et elle est renvoyée lorsque le système d'exploitation n'a pas suffisamment d’espace tampon (BUFfer Space) pour gérer l'opération réalisée. Par exemple, en regardant la source d'un FreeBSD aujourd'hui, vous voyez ce code dans son implémentation IPv6 :

Dans cet exemple, si une quantité suffisante de mémoire peut être allouée pour accueillir la taille d'un en-tête IPv6 et ICMP6, l'erreur ENOBUFS (qui est mappée au numéro 55) sera renvoyée. Malheureusement, l’utilisation de FreeBSD pas Apple n'est pas en open source : comment, quand, et pourquoi cette erreur est renvoyée reste un mystère. Cette erreur s’est vérifiée par d’autres projets basés sur UDP, mais aucune résolution n'est prévue.
Ce qui est clair, c'est qu'une fois qu'une erreur 55 commence à se produire, la connexion n'est plus utilisable. Pour gérer ce cas, nous avons besoin de nous reconnecter. Mais, pour mettre en place le même mécanisme d’Happy Eyeballs, le faire sur la connexion initiale est à la fois inutile (comme nous en avons déjà parlé à propos de la connexion la plus rapide) et va nous prendre un temps précieux. Au lieu de cela, nous ajoutons une deuxième méthode de connexion qui n'est utilisée que pour recréer une session qui fonctionne déjà :
/**
Create a new UDP connection to the server using a Happy Eyeballs like heuristic.
This function should be called when first establishing a connection to the edge server.
It will initiate a new connection over IPv4 and IPv6 in parallel, keeping the connection that receives the first response.
*/
func connect(onViable: @escaping () -> Data, onReply: @escaping () -> Void, onFailure: @escaping () -> Void, onDisconnect: @escaping () -> Void)
/**
Recreate the current connections.
This function should be called as a response to error code 55, when a quick connection is required.
Unlike `happyEyeballs`, this function will use viability as its only success criteria.
*/
func reconnect(onViable: @escaping () -> Void, onFailure: @escaping () -> Void, onDisconnect: @escaping () -> Void)
En utilisant reconnect, nous sommes en mesure de recréer des sessions interrompues par des erreurs code 55, mais en ajoutant encore un temps de latence, ce qui n'est pas idéal. Comme pour tout développement de logiciel client sur une plateforme fermée toutefois, nous dépendons de la plateforme pour identifier et corriger les bugs au niveau de cette plateforme.
Honnêtement, ce n'est qu'un problème parmi une longue liste de bugs spécifiques à la plateforme que nous avons rencontrés lors de la création de WARP. Nous espérons continuer à travailler avec les fournisseurs d'appareils pour les faire réparer. Il existe un nombre inimaginable de combinaisons d'appareils et de connexions, et chaque connexion n'existe pas seulement à un moment donné. Ces connexions changent en permanence, entrent et laissent des états brisés presque plus rapidement que notre capacité à les suivre. Même maintenant, obtenir de WARP qu’il travaille sur chaque appareil et connexion existants dans le monde n'est pas un problème résolu. Nous recevons toujours des rapports de bugs quotidiens que nous trions et résolvons.
WARP+
WARP est conçu pour être un lieu dans lequel nous pouvons appliquer des optimisations qui améliorent Internet. Nous avons beaucoup d'expérience pour rendre les sites Web plus performants et WARP nous offre l’opportunité d'expérimenter en faisant la même chose pour tout le trafic Internet.
Chez Cloudflare, nous avons un produit appelé Argo. Argo rend le Time to First Byte (TTFB) 30 % plus rapide en moyenne en surveillant de manière continue des milliers d’itinéraires sur Internet entre nos centres de données. Ces données construisent une base de données qui mappe chaque plage d'adresses IP avec l'itinéraire le plus rapide possible vers chaque destination. Lorsqu'un paquet arrive, il atteint d'abord le centre de données le plus proche du client, puis ce centre de données utilise les données de nos tests pour découvrir l'itinéraire qui amènera le paquet à sa destination avec la latence la plus faible possible. Vous pouvez le penser comme un GPS au courant du trafic, mais à l’échelle d’Internet.
Argo n'a historiquement fonctionné que sur des paquets HTTP. HTTP est le protocole qui régit le web, en envoyant des messages qui chargent les sites Web au-dessus de la suite de protocoles TCP/IP. Par exemple, si je charge http://zack.is/, un message HTTP est envoyé à l'intérieur d'un paquet TCP :
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.24.101.191
Transmission Control Protocol, Src Port: 55244, Dst Port: 80
Source Port: 55244
Destination Port: 80
TCP payload (414 bytes)
Hypertext Transfer Protocol
GET / HTTP/1.1\r\n
Host: zack.is\r\n
Connection: keep-alive\r\n
Accept-Encoding: gzip, deflate\r\n
Accept-Language: en-US,en;q=0.9\r\n
\r\n
Cependant, le web moderne et sécurisé présente un problème pour nous : Lorsque je fais la même requête sur HTTPS (https://zack.is) plutôt que simplement HTTP (http://zack.is), je vois un résultat très différent sur le réseau :
Internet Protocol Version 4, Src: 192.168.7.21, Dst: 104.25.151.102
Transmission Control Protocol, Src Port: 55983, Dst Port: 443
Source Port: 55983
Destination Port: 443
Transport Layer Security
TCP payload (54 bytes)
Transport Layer Security
TLSv1.2 Record Layer: Application Data Protocol: http-over-tls
Encrypted Application Data: 82b6dd7be8c5758ad012649fae4f469c2d9e68fe15c17297…
Ma requête a été chiffrée ! Il n'est plus possible pour WARP (ou toute autre entité autre que la destination) de dire ce que contient le payload. Il pourrait s’agir de HTTP, mais il pourrait tout aussi bien s’agir de n'importe quel autre protocole. Si mon site est l'un des vingt millions qui utilisent déjà Cloudflare, nous pouvons déchiffrer le trafic et l'accélérer (avec une longue liste d'autres optimisations). Mais pour le trafic chiffré destiné à une autre source existante la technologie Argo basée uniquement sur HTTP n'allait pas fonctionner.
Heureusement, nous disposons maintenant d’une bonne expérience sur des trafics non HTTP à travers nos produits Spectrum et Magic Transit. Pour résoudre notre problème, l'équipe Argo s'est tournée vers le protocole CONNECT.
Comme nous le savons maintenant, lorsqu'une requête WARP est effectuée, elle communique d'abord sur le protocole WireGuard à un serveur fonctionnant dans l'un de nos 194 centres de données à travers le monde. Une fois que le message WireGuard a été déchiffré, nous examinons l'adresse IP de destination pour voir s'il s'agit d'une requête HTTP destinée à un site géré par Cloudflare ou d'une requête avec une autre destination. Si elle nous est destinée, elle entre dans notre chemin de service HTTP standard ; souvent, nous pouvons répondre à la demande directement à partir de notre cache dans le même centre de données.
Si elle n'est pas destinée à un site géré par Cloudflare, nous envoyons plutôt le paquet vers un processus proxy exécuté sur chaque machine. Ce proxy est charger de charger le chemin le plus rapide à partir de notre base de données Argo et de commencer une session HTTP avec une machine dans le centre de données vers lequel ce trafic doit être transmis. Il utilise la commande CONNECT pour transmettre des métadonnées (comme en-têtes) et transformer la session HTTP en une connexion qui peut transmettre les octets bruts du payload :
CONNECT 8.54.232.11:5564 HTTP/1.1\r\n
Exit-Tcp-Keepalive-Duration: 15\r\n
Application: warp\r\n
\r\n
<data to send to origin>
Une fois que le message arrive au centre de données de destination, il est soit transmis à un autre centre de données (si c'est la meilleure solution pour la performance), soit dirigé directement vers l'origine qui attend le trafic.
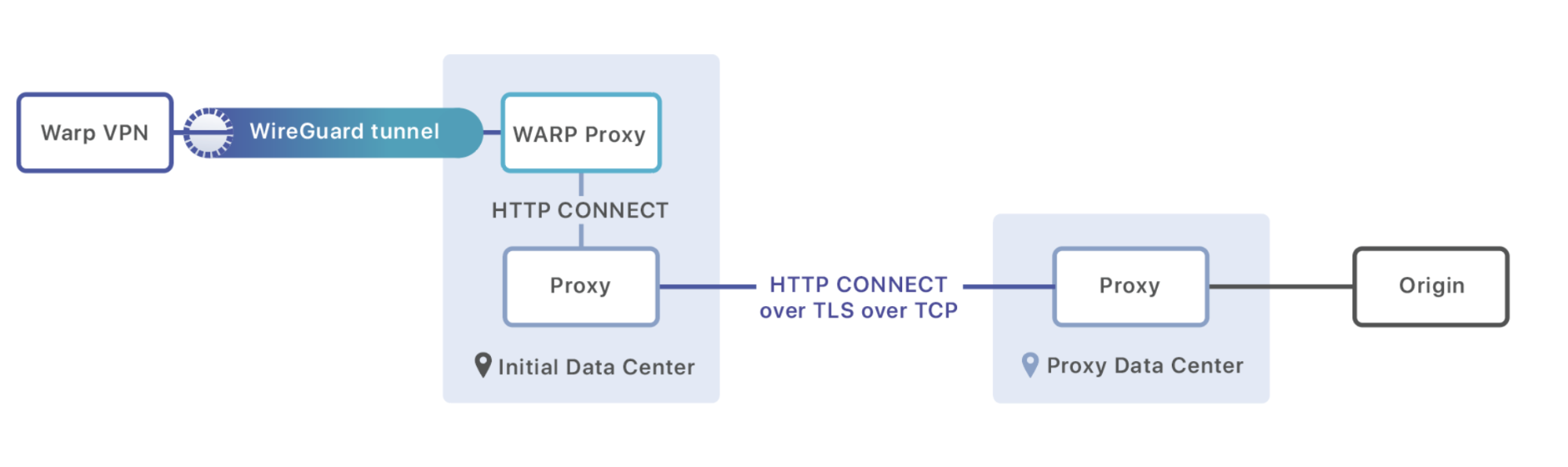
Le routage intelligent n'est que le début de WARP+. Nous avons une longue liste de projets et de plans qui visent tous à rendre votre Internet plus rapide, et nous ne pouvions être plus heureux que d'avoir enfin une plateforme avec laquelle les tester.
Notre mission
Aujourd'hui, après plus d'un an de développement, WARP est à votre disposition ainsi qu'à la disposition de votre famille et de vos amis. Mais nous n’en sommes qu’au début. Avec la possibilité d'améliorer la connexion réseau complète pour tout le trafic, nous ouvrons un nouveau monde d'optimisations et d'améliorations de sécurité qui étaient tout simplement inenvisageables auparavant. Nous avons la joie de pouvoir expérimenter, tester et enfin sortir toutes sortes de nouvelles fonctionnalités WARP et WARP+.
La mission de Cloudflare est d'aider à construire un Internet meilleur. Si nous sommes prêts à expérimenter et à résoudre ensemble des problèmes techniques difficiles, nous croyons que nous pouvons contribuer à rendre l'avenir d'Internet meilleur que l'Internet d'aujourd'hui, et nous sommes tous reconnaissants de jouer un rôle dans cette aventure. Merci de nous confier votre connexion Internet.
WARP a été créé par Oli Yu, Vlad Krasnov, Chris Branch, Dane Knecht, Naga Tripirineni, Andrew Plunk, Adam Schwartz, Irtefa, et la stagiaire Michelle Chen avec le soutien des membres de nos bureaux d'Austin, San Francisco, Champaign, Londres, Varsovie et Lisbonne.