


Cloudflare construit la meilleure plate-forme informatique du monde. Nous souhaitons vous faciliter le développement sur cette dernière, afin de vous permettre de profiter d'une expérience fluide et limpide. Toutefois, le simple fait de construire la meilleure plate-forme informatique qui soit ne suffit pas. Vos applications reposent avant sur les données avec lesquelles elles interagissent.
Cloudflare propose actuellement plusieurs solutions de stockage de données : Workers KV, R2 et Durable Objects. Les trois solutions sont conformes aux objectifs de conception de Cloudflare pour Workers : mondiales par défaut, évolutives à l'infini et agréables à utiliser pour les développeurs. Nous avons établi des partenariats avec des solutions de stockage tierces, comme Fauna, MongoDB et Prisma, car ces plates-formes de données s'inscrivent parfaitement dans nos objectifs de conception. En outre, ces entreprises sont à l'origine de didacticiels pour les bases de données qui prennent déjà en charge les connexions HTTP.
Le seul domaine qui a été malheureusement oublié est celui des bases de données relationnelles. Cloudflare s'appuie elle-même sur des bases de données relationnelles en tant qu'entreprise et nous ne sommes pas les seuls. En avril, nous vous avons demandé quelles bibliothèques Node vous souhaitiez nous voir prendre en charge et quatre des cinq premières demandes concernaient les bases de données. Pour la Full Stack Week, nous nous sommes posé la question de savoir comment nous pouvions inclure les bases de données relationnelles, de sorte qu'elles s'inscrivent dans nos objectifs de conception ?
Aujourd'hui nous faisons le premier pas vers ce but en annonçant la prise en charge par Workers de ce type de bases de données, notamment Postgres et MySQL.
L'établissement d'une connexion vers une base de données n'est pas chose aisée. Si l'opération consistait uniquement à transmettre une chaîne de connexion à un pilote de base de données, nous l'aurions déjà fait. Nous avons dû surmonter plusieurs obstacles pour arriver à ce stade et il en reste encore quelques-uns.
L'objectif avoué de cette annonce consiste à mettre en place une collaboration avec vous, nos développeurs, afin de résoudre les problématiques uniques liées à l'accès aux bases de données au sein de Workers. Si vous souhaitez travailler avec nous, n'hésitez pas à remplir ce formulaire ou à nous contacter sur Discord. Nous n'en sommes qu'aux débuts. Si vous souhaitez simplement récupérer le code afin de vous amuser un peu avec, utilisez cet exemple pour commencer à connecter votre propre base de données ou consultez notre démo.
Pourquoi les Database Connectors se révèlent-ils si compliqués à construire ?
Les connexions aux bases de données serverless sont difficiles à prendre en charge pour plusieurs raisons.
Les bases de données se montrent exigeantes. Elles nécessitent souvent des connexions TCP, car elles supposent l'établissement de connexions durables entre un serveur d'application et la base de données. L'environnement d'exécution (runtime) de Workers n'est actuellement pas compatible avec les connexions TCP. Nous avons donc dû nous limiter à la prise en charge de bases de données ou de proxys HTTP.
Comme dans tout type de relation, il ne suffit pas d'établir une connexion. Les développeurs appuient leurs bases de données sur des bibliothèques client afin de faciliter l'envoi de requêtes et la gestion des réponses. Comme l'environnement d'exécution de Workers n'est pas totalement compatible avec Node.js, nous devons soit déployer notre propre bibliothèque de base de données, soit en trouver une qui ne repose pas sur des bibliothèques intégrées non compatibles.
Enfin, les bases de données sont sensibles. Il est souvent nécessaire de faire appel à des bibliothèques externes pour gérer les connexions partagées entre un serveur d'application et une base de données, car l'établissement de ces connexions a tendance à se montrer coûteux.
Surmonter les obstacles
Notre démarche actuelle jette les bases qui nous permettront à l'avenir de résoudre chacune de ces difficultés de manière créative.
En premier lieu, nous nous appuyons sur cloudflared pour créer un tunnel sécurisé entre le réseau Cloudflare et un réseau privé au sein de votre infrastructure existante. La solution Cloudflared prend déjà en charge la mise en proxy HTTP vers TCP via WebSockets. L'enjeu pour nous consiste à proposer des interfaces qui ressemblent aux interfaces Sockets attendues par les bibliothèques existantes, tout en recâblant les solutions afin qu'elles redirigent les opérations de lecture et d'écriture vers notre WebSocket. Rapide, sûre et sécurisée, cette méthode comporte néanmoins des limites, dans la mesure où nous manquons de contrôle sur l'endroit où diriger les connexions finales. Nous prévoyons de résoudre ce problème dans un avenir proche, mais en attendant, notre approche se révèle essentielle pour recueillir des données concernant la latence et les performances. Ces informations nous permettront par la suite d'identifier les aspects à améliorer.
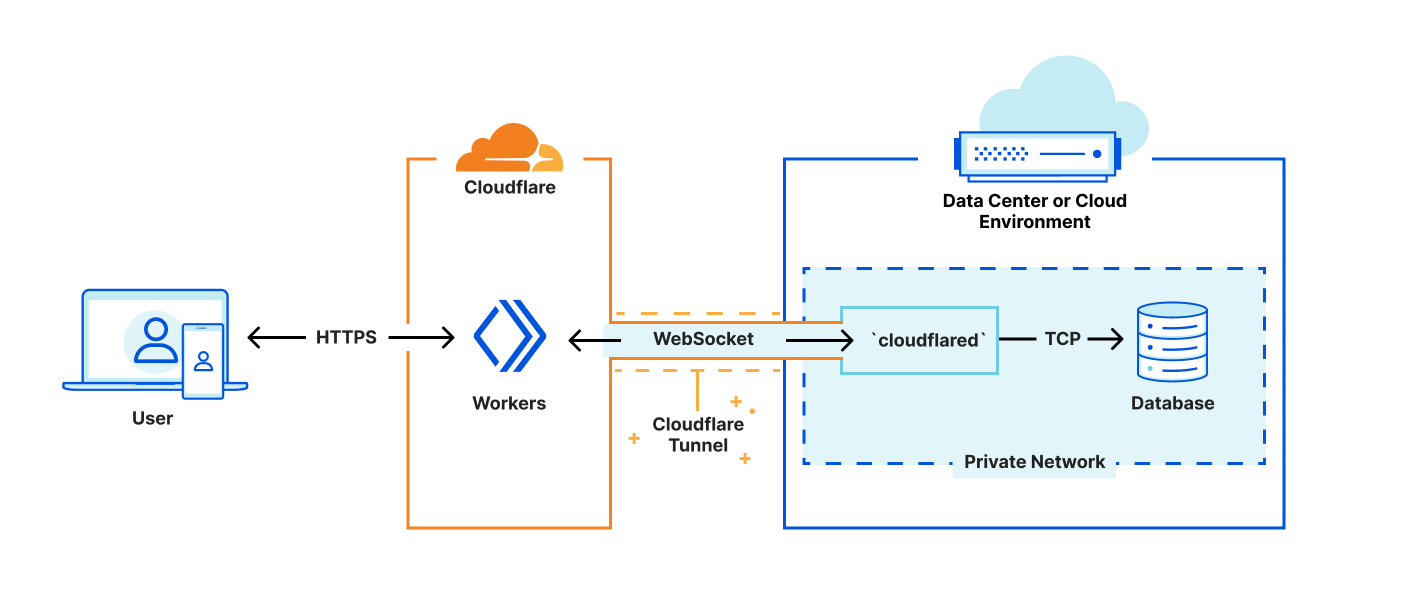
Nous créons ensuite une couche intermédiaire qui adapte l'API Socket d'un environnement d'exécution populaire afin d'établir une connexion directe aux bases de données à l'aide d'un WebSocket. Cette étape nous permet de regrouper le code en l'état, sans avoir besoin de prévoir des embranchements ou d'apporter des modifications significatives à la bibliothèque de la base de données. Dans le cadre de cette annonce, nous avons publié un didacticiel consacré à la procédure à suivre pour se connecter à une base de données Postgres et l'interroger depuis Workers, à l'aide des technologies Cloudflare existantes et d'un pilote développé par la communauté Deno, en pleine expansion. Nous sommes ravis de travailler à l'élargissement de la prise en charge, en collaboration avec les responsables en amont.
Nous nous réjouissons de la manière dont notre approche va nous permettre de commencer à gérer la charge liée au regroupement et à l'établissement de connexions. Si notre démo technologique actuelle implique l'implantation du tunnel Cloudflare sur votre propre infrastructure, nous cherchons des clients qui souhaiteraient participer au programme pilote d'un modèle dans lequel Cloudflare hébergerait le tunnel pour vous.
Ce qui nous attend
Le travail ne fait que commencer. L'objectif de notre annonce d'aujourd'hui consiste à trouver des clients désireux de développer de nouvelles applications sur Workers ou de faire migrer des applications existantes vers la plate-forme, tout en travaillant avec des données stockées au sein d'une base de données relationnelle.
Cloudflare a commencé ses activités en garantissant la sécurité, les performances et la fiabilité des sites web de ses clients. Nous sommes donc très enthousiastes à l'idée d'un avenir au sein duquel Cloudflare gèrera les connexions aux bases de données, se chargera de la réplication des données parmi les fournisseurs de cloud et proposera un accès faible latence aux données partout dans le monde.
Nous cherchons dans un premier temps à élargir la prise en charge native de TCP au sein de l'environnement d'exécution. Cette dernière nous permettra non seulement de bénéficier d'une meilleure prise en charge des bases de données, mais également d'étendre l'environnement d'exécution de Workers afin d'accueillir plus largement les infrastructures de données.
Grâce à notre position au sein de la pile (au niveau de la couche réseau), la proposition d'avantages aux bases de données du monde entier (amélioration des performances, de la sécurité et nette réduction des frais de trafic sortant) se révèle tout à fait possible. Pour ce faire, nous comptons réorienter le service de mise en proxy HTTP vers TCP que nous avons déjà construit. Nous proposerons ensuite ce dernier aux développeurs en tant que service de regroupement des connexions, afin de gérer les connexions aux bases de données en leur nom.
Enfin, notre réseau permet la mise en cache et l'accès faible latence aux données dans le monde entier. Une fois les connexions à vos données rétablies, la possibilité de les rendre accessibles via le réseau Cloudflare ouvrira la voie à de nouvelles architectures en matière de données distribuées.
Essayez nos connecteurs
Vous souhaitez vérifier certains points ? Vous trouverez ci-dessous trois étapes importantes à suivre pour bien démarrer :
- Déploiement de cloudflared au sein de votre infrastructure.
- Déploiement d'une base de données connectée à cloudflared.
- Déploiement d'une instance Workers incluant le pilote de base de données à l'origine des requêtes.
Le tutoriel Postgres est accessible ici.
Lorsque vous aurez terminé, le code devrait ressembler à ce qui suit :
import { Client } from './driver/postgres/postgres'
export default {
async fetch(request: Request, env, ctx: ExecutionContext) {
try {
const client = new Client({
user: 'postgres',
database: 'postgres',
hostname: 'https://db.example.com',
password: '',
port: 5432,
})
await client.connect()
const result = await client.queryArray('SELECT * FROM users WHERE uuid=1;')
ctx.waitUntil(client.end())
return new Response(JSON.stringify(result.rows[0]))
} catch (e) {
return new Response((e as Error).message)
}
},
}
Vous rencontrez un problème ? Remplissez ce formulaire, rejoignez-nous sur Discord ou envoyez-nous un e-mail et parlons-en !