


Cloudflare peut désormais identifier automatiquement tous les points de terminaison d'API et apprendre les schémas d'API pour l'ensemble de nos clients abonnés au service API Gateway. Les clients peuvent utiliser ces fonctionnalités pour appliquer un modèle de sécurité positive sur leurs points de terminaison d'API, même s'ils ne disposent que de peu (voire pas) d'informations sur leurs API existantes à l'heure actuelle.
La première étape de la sécurisation de vos API consiste à connaître les noms d'hôte et les points de terminaison d'API. Nous entendons souvent dire que les clients se voient contraints de commencer leurs efforts de catalogage et de gestion de leurs API de la manière suivante : « Nous faisons circuler une feuille de calcul par e-mail et demandons aux développeurs de dresser la liste de l'ensemble de leurs points de terminaison ».
Pouvez-vous imaginer les problèmes associés à cette approche ? Vous en avez peut-être même déjà fait directement l'expérience. L'approche « e-mail et demande de liste » dresse un inventaire ponctuel qui changera probablement avec la version de code suivante. Elle repose sur une connaissance tribale susceptible de disparaître lorsque les collaborateurs quittent l'entreprise. Enfin, dernier point et non des moindres, cette approche se révèle sujette à l'erreur humaine.
Même si vous disposiez d'un inventaire précis de vos API résultant d'un effort collectif, le fait de valider qu'une API était utilisée comme prévu via l'application d'un schéma d'API nécessiterait encore plus de connaissances collectives pour établir ce schéma. Désormais, les nouvelles fonctionnalités d'identification des API et d'apprentissage des schémas d'API Gateway s'allient pour protéger automatiquement les API sur l'ensemble du réseau mondial de Cloudflare et éliminer le besoin d'identification manuelle des API et d'établissement de schéma.
Le service API Gateway identifie et protège les API
API Gateway identifie les API par l'intermédiaire d'une fonctionnalité nommée API Discovery (identification des API). Par le passé, la fonctionnalité API Discovery utilisait des identifiants de session spécifiques au client (en-têtes HTTP ou cookies) pour identifier les points de terminaison d'API et afficher leurs données d'analyse à nos clients.
Ce processus d'identification fonctionnait, mais présentait trois inconvénients :
- Les clients devaient savoir quels en-têtes ou cookies ils utilisaient pour circonscrire les sessions. Les identifiants de session sont courants, mais trouver le jeton approprié à utiliser peut demander du temps.
- La nécessité d'utiliser un identifiant de session pour l'identification des API nous empêchait de surveiller et de signaler les API totalement non authentifiées. Les clients d'aujourd'hui souhaitent toujours disposer d'une visibilité sur le trafic hors session afin de s'assurer que tous les points de terminaison d'API sont documentés et de cantonner l'utilisation abusive au minimum.
- Une fois l'identifiant de session saisi dans le tableau de bord, les clients devaient attendre jusqu'à 24 heures que le processus d'identification se termine. Personne n'aime attendre.
Cette approche avait des lacunes, mais nous savions que nous pouvions proposer rapidement de la valeur aux clients en commençant par un produit basé sur les sessions. À mesure que nous gagnions des clients et que nous voyions davantage de trafic transiter par notre système, nous savions que nos données nouvellement étiquetées s'avéreraient extrêmement utiles pour développer encore notre produit. Si nous pouvions nourrir un modèle d'apprentissage automatique avec nos métadonnées existantes sur les API et les nouvelles données étiquetées, nous n'aurions plus besoin d'un identifiant de session pour déterminer quels points de terminaison correspondaient à quelles API. Nous avons donc décidé de bâtir cette nouvelle approche.
Nous sommes partis de ce que nous avons appris des données basées sur des identifiants de session et avons développé un modèle d'apprentissage automatique pour révéler l'ensemble du trafic d'API vers un domaine, indépendamment de l'identifiant de session. Grâce à notre nouvelle fonctionnalité d'identification des API (API Discovery) basée sur l'apprentissage automatique, Cloudflare identifie en continu l'ensemble du trafic d'API routé via notre réseau sans action préalable du client. Avec ce lancement, les clients du service API Gateway pourront commencer à utiliser la fonctionnalité API Discovery plus rapidement que jamais et découvriront les API non authentifiées qu'ils ne pouvaient pas identifier par le passé.
Les identifiants de session conservent une grande importance pour le service API Gateway, car ils forment la base de nos limitations de débit visant à prévenir les abus volumétriques, ainsi que de notre fonctionnalité d'analyse des séquences, Sequence Analytics. Vous trouverez plus d'informations sur les performances de la nouvelle approche dans la section « Fonctionnement » ci-dessous.
Une protection des API partant de zéro
Maintenant que vous avez découvert de nouvelles API à l'aide de la fonctionnalité API Discovery, comment allez-vous les protéger ? Pour vous défendre contre ces attaques, les développeurs d'API doivent savoir exactement de quelle manière s'attendre à ce que leurs API soient utilisées. Heureusement, les développeurs peuvent générer de manière programmatique un schéma d'API qui codifie les entrées acceptables au sein d'une API et importer ce dernier dans la fonction de validation de schéma du service API Gateway.
Nous avons toutefois déjà parlé de la manière dont de nombreux clients ne parviennent pas à identifier leurs API aussi vite que les développeurs les créent. Lorsqu'ils identifient des API, il s'avère particulièrement difficile de tracer avec précision un schéma OpenAPI unique pour chacun des points de terminaison d'API (potentiellement des centaines), compte tenu du fait que les équipes de sécurité voient rarement plus que la méthode de requête et le chemin HTTP dans leurs journaux.
Lorsque nous avons examiné les schémas d'utilisation du service API Gateway, nous avons constaté que les clients identifiaient les API, mais n'appliquaient pratiquement jamais de schéma. Nous leur avons demandé pourquoi et la réponse fut des plus simples : « Même quand je sais qu'une API existe, il me faut un temps considérable pour déterminer qui possède chaque API afin de leur demander de me fournir un schéma. J'ai du mal à accorder une priorité supérieure à ces tâches par rapport à d'autres tâches de sécurité plus impérieuses. » Le manque de temps et d'expertise constituait le plus gros obstacle à la mise en place de protections par nos clients.
Nous avons donc décidé de supprimer cet obstacle et découvert que le même processus d'apprentissage que celui que nous utilisions pour identifier les points de terminaison d'API pouvait être appliqué aux mêmes points de terminaison une fois ceux-ci identifiés afin d'apprendre automatiquement un schéma. Grâce à cette méthode, nous pouvons désormais générer un schéma au format OpenAPI pour chaque point de terminaison que nous identifions, en temps réel. Nous appelons cette nouvelle fonctionnalité l'apprentissage de schéma (Schema Learning). Les clients peuvent ensuite importer ce schéma généré par Cloudflare dans la fonctionnalité de validation de schéma (Schema Validation) afin de mettre en place un modèle de sécurité positive.
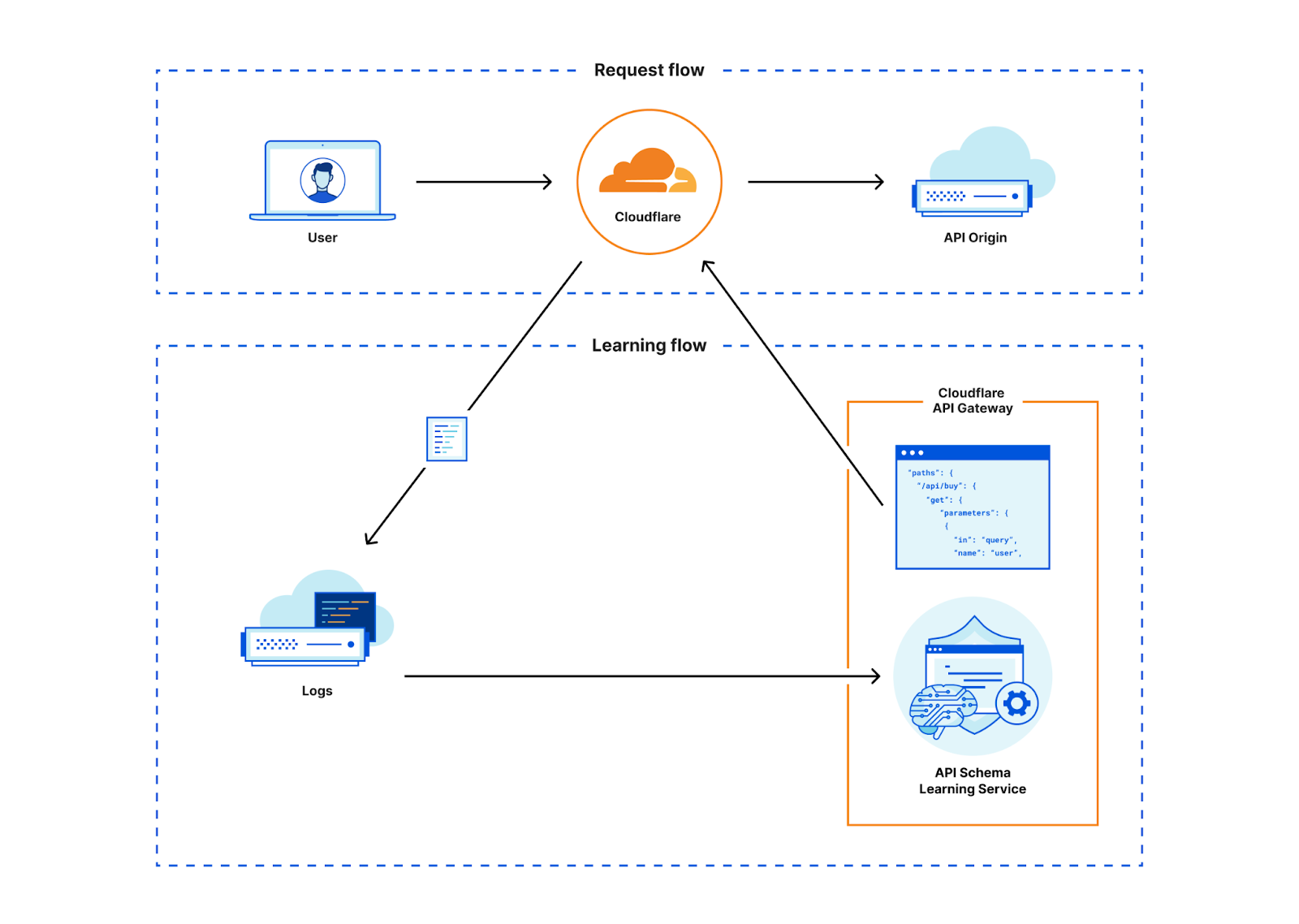
Fonctionnement
Identification des API basée sur l'apprentissage automatique
Avec les API RESTful, les requêtes se composent de différentes méthodes et de différents chemins HTTP. Prenons pour exemple l'API Cloudflare. Vous remarquerez une tendance commune parmi les chemins qui pourrait faire dénoter les requêtes vers cette API par rapport aux autres requêtes vers ce blog : les requêtes d'API commencent toutes par /client/v4 et se poursuivent par le nom du service, un identifiant unique et, parfois, les noms des fonctionnalités du service et d'autres identifiants.
Comment avons-nous pu identifier facilement les requêtes d'API ? Au premier coup d'œil, ces requêtes semblent simples à identifier de manière programmatique à l'aide d'un instrument heuristique (p. ex. « le chemin commence par /client »), mais le cœur même de notre nouvelle fonctionnalité d'identification contient un modèle d'apprentissage automatique soutenant un outil de classification qui attribue un score aux transactions HTTP. Si les chemins d'API sont si structurés, pourquoi a-t-on besoin de l'apprentissage automatique pour cette tâche ? Pourquoi ne pas utiliser un simple instrument heuristique ?
La réponse se réduit à cette question : qu'entend-on réellement par requête d'API et en quoi diffère-t-elle d'une requête sans lien avec une API ? Examinons deux exemples.
Comme pour l'API Cloudflare, bon nombre des API de nos clients suivent un certain schéma, comme la mise en préfixe du chemin de leur requête d'API à l'aide d'un identifiant « api » et d'un numéro de version, par exemple : /api/v2/user/7f577081-7003-451e-9abe-eb2e8a0f103d.
Le simple fait de rechercher la mention « api » ou un numéro de version dans le chemin constitue déjà un instrument heuristique plutôt efficace qui nous informe que la chaîne fait très probablement partie d'une API, mais ce n'est malheureusement pas toujours aussi simple.
Examinons deux exemples supplémentaires : /users/7f577081-7003-451e-9abe-eb2e8a0f103d.jpg et /users/7f577081-7003-451e-9abe-eb2e8a0f103d, tous deux ne différant que par la présence d'une extension « .jpg ». Le premier chemin pourrait simplement conduire à une ressource statique, comme la miniature d'un utilisateur. Le second ne nous permet pas de déduire beaucoup d'indices du chemin en lui-même.
L'élaboration manuelle de tels instruments heuristiques peut rapidement s'avérer difficile. Les êtres humains sont doués pour repérer des tendances, mais compte tenu de l'échelle des données que Cloudflare observe chaque jour, l'élaboration d'instruments heuristiques constitue un véritable défi. Nous faisons donc appel à l'apprentissage machine pour dériver automatiquement ces instruments, afin de nous assurer qu'ils sont reproductibles et qu'ils fassent preuve d'une certaine précision.
Les données d'apprentissage sont des éléments d'échantillons de requêtes/réponses HTTP, comme le type de contenu ou l'extension de fichier, collectés via la procédure d'identification basée sur des identifiants de session dont nous avons discuté plus haut. Malheureusement, toutes les données que nous recueillons dans cet ensemble n'appartiennent pas nécessairement à une API. De même, nous avons également besoin d'échantillons représentant le trafic non lié aux API. Nous avons donc commencé le processus par les données issues de l'identification basée sur les identifiants de session, avant de les nettoyer manuellement et d'en dériver des échantillons supplémentaires de trafic non API. Nous avons pris grand soin de ne pas chercher à trop faire correspondre le modèle aux données, car nous souhaitons que le modèle puisse généraliser les entrées, au-delà des données d'apprentissage.
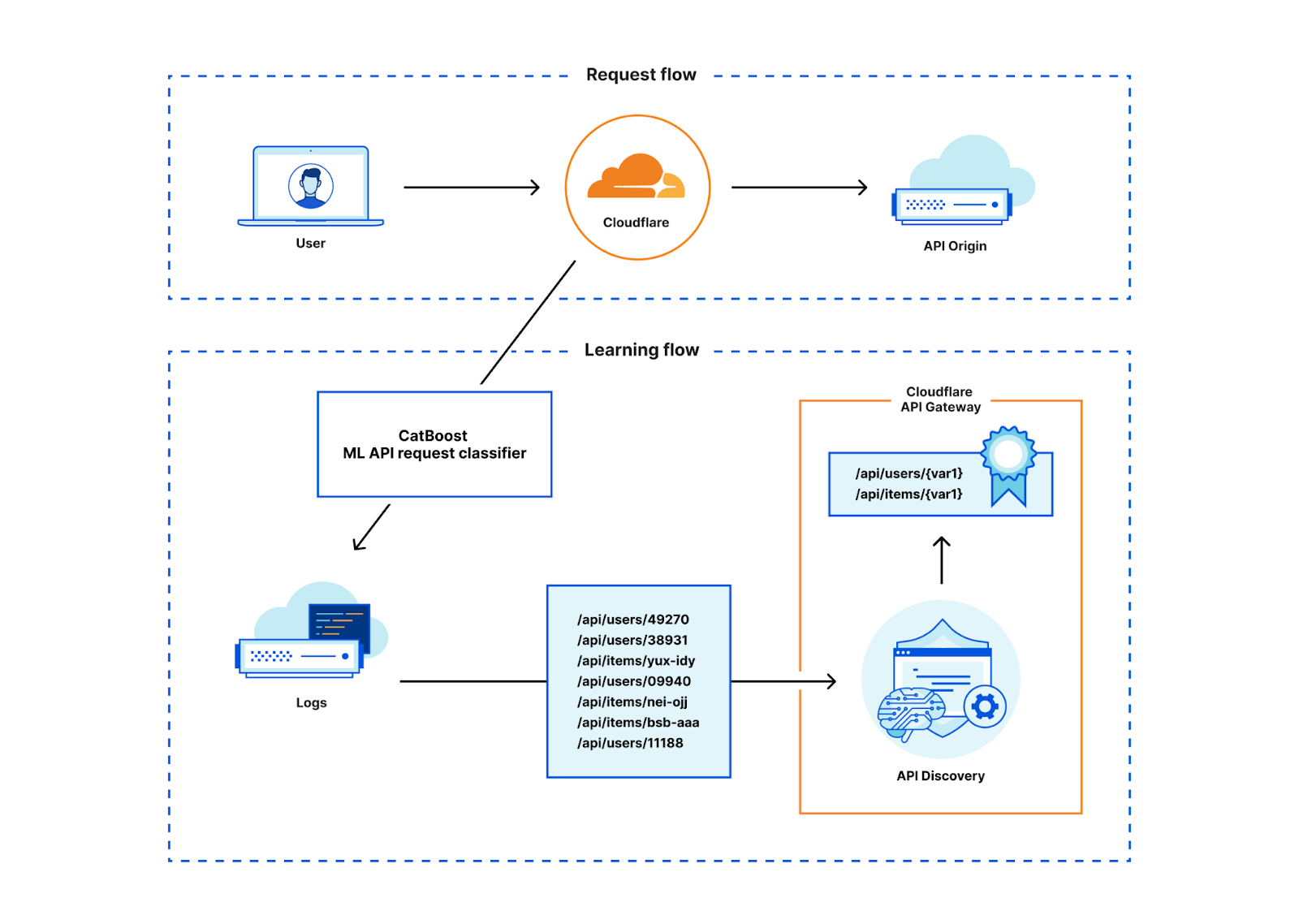
Pour entraîner le modèle, nous nous sommes servis de la bibliothèque CatBoost, de laquelle nous avons déjà une bonne expertise, car elle soutient les modèles d'apprentissage de notre solution de gestion des bots. Pour simplifier, vous pouvez considérer le modèle résultant comme un organigramme nous spécifiant les conditions que nous devons vérifier, les unes après les autres. Pour prendre un exemple, si le chemin contient « api », vous devez alors vérifier la présence éventuelle d'une extension de fichier, et ainsi de suite. À la fin de l'organigramme se trouve un score qui nous indique la probabilité qu'une transaction HTTP appartienne à une API.
Compte tenu du modèle à entraîner, nous pouvons ainsi le nourrir d'éléments de requêtes/réponses HTTP circulant sur le réseau Cloudflare et calculer la probabilité que cette transaction HTTP appartienne ou non à une API. L'extraction d'éléments et la cotation du modèle s'effectuent dans Rust et ne demandent que quelques microsecondes sur notre réseau mondial. Comme la fonctionnalité d'identification obtient ses données à partir de notre puissant pipeline de données, il n'est pas réellement nécessaire de noter chaque transaction. Nous pouvons réduire la charge sur nos serveurs en ne notant que les transactions que nous sommes assurés de retrouver dans notre pipeline de données. Nous économisons ainsi du temps processeur et permettons à la fonctionnalité d'être efficace sur le plan des coûts.
Une fois les résultats de classification dans notre pipeline de données, nous pouvons utiliser le même mécanisme d'identification des API que celui que nous utilisons dans le processus d'identification basé sur les identifiants de session. Ce système existant fonctionne parfaitement et nous permet de réutiliser efficacement le code. Il nous aide également à comparer nos résultats avec ceux du processus d'identification basé sur les identifiants de session, car les systèmes sont directement comparables.
Pour que les résultats de l'identification des API soient utiles, la première tâche de la fonctionnalité consiste à simplifier les chemins uniques que nous observons sous forme de variables. Nous avons déjà discuté de ce processus antérieurement. La déduction des divers modèles d'identifiants différents que nous observons sur notre réseau mondial n'est pas chose aisée, en particulier lorsque les sites utilisent des identifiants personnalisés au-delà du simple GUID ou du format à nombres entiers. La fonctionnalité d'identification des API normalise avec une grande pertinence les chemins contenant des variables à l'aide d'une poignée d'outils de classification des variables différents et d'un processus d'apprentissage supervisé.
Les résultats d'identification ne sont prêts à être utilisés directement par nos utilisateurs qu'après ce processus de normalisation des chemins.
Les résultats : des centaines de points de terminaison identifiés par client
Alors, comment le processus d'identification par apprentissage automatique se compare-t-il à l'identification basée sur des identifiants de session, qui s'appuie sur des en-têtes ou des cookies pour étiqueter le trafic lié aux API ?
Nous nous attendons à ce qu'il détecte un ensemble très similaire de points de terminaison. Toutefois, d'après nos données, nous savions que nous trouverions deux lacunes. Premièrement, nous constatons parfois que les clients ne parviennent pas à clairement séparer le trafic uniquement lié aux API à l'aide des identifiants de session. Lorsque ce type de situation se produit, la fonctionnalité d'identification fait apparaître du trafic sans lien avec les API. Deuxièmement, comme nous avions besoin d'identifiants de session dans la première version de la fonctionnalité d'identification des API, les points de terminaison ne faisant pas partie d'une session (p. ex. les points de terminaison de connexion ou les points de terminaison non authentifiés) n'étaient théoriquement pas identifiables.
Le graphique suivant montre un histogramme du nombre de points de terminaison détectés sur les domaines des clients pour les deux variantes du processus d'identification.

À première vue, les résultats semblent très similaires, soit un point qui constitue un bon indicateur que le processus d'identification par apprentissage automatique fonctionne comme prévu. Certaines différences sont néanmoins visibles sur le graphique, mais nous nous y attendions également, car nous identifions des points de terminaison théoriquement non identifiables à l'aide d'un simple identifiant de session. Si nous effectuons une comparaison plus détaillée, domaine par domaine, nous remarquons que les deux méthodes ne présentent aucune différence pour environ 46 % des domaines. Le graphique suivant compare la différence (en pourcentage des points de terminaison) entre le processus d'identification basé sur des identifiants de session et le processus d'identification par apprentissage automatique :

Pour près de 15 % des domaines, nous constatons une augmentation des points de terminaison comprise entre 1 et 50, ainsi qu'une réduction similaire pour près de 9 % d'entre eux. Nous identifions plus de 50 points de terminaison supplémentaires pour environ 28 % des domaines.
Ces résultats soulignent le fait que l'identification par apprentissage automatique parvient à faire remonter des points de terminaison qui échappaient auparavant à la détection. Le processus étend par conséquent les outils proposés par la solution API Gateway afin de vous aider à ordonner votre environnement d'API.
Une protection des API à la volée grâce à l'apprentissage de schéma d'API
Maintenant que nous avons détaillé les rouages de la fonctionnalité d'identification des API, comment un professionnel peut-il protéger les points de terminaison nouvellement identifiés ? Nous nous sommes déjà intéressés aux métadonnées des requêtes d'API, alors examinons à présent le corps de ces requêtes. La compilation de tous les formats attendus pour l'ensemble des points de terminaison d'une API se nomme le schéma d'API. La fonctionnalité de validation de schéma de la solution API Gateway est un excellent moyen de se protéger contre les attaques sur les API figurant au Top 10 de l'OWASP. Elle permet de s'assurer que le corps, le chemin et la chaîne d'une requête contiennent les informations attendues pour un point de terminaison d'API spécifique, au format attendu. Mais qu'en est-il si vous ne connaissez pas le format attendu ?
Même si vous ne connaissez pas le schéma d'une API spécifique, les clients utilisant cette API ont été programmés pour envoyer majoritairement des requêtes qui se conforment à ce schéma inconnu (ils ne seraient pas en mesure d'interroger avec succès le point de terminaison dans le cas contraire). La fonctionnalité d'apprentissage de schéma s'appuie sur cette observation et examine les requêtes fructueuses adressées à cette API pour reconstruire automatiquement le schéma d'entrée. Une API pourrait, par exemple, s'attendre à ce que le paramètre user-ID d'une requête prenne la forme id12345-a. Même si cette attente n'est pas explicitement formulée, les clients qui souhaitent avoir une interaction fructueuse avec l'API enverront les user-ID sous ce format.
La fonctionnalité d'apprentissage de schéma identifie tout d'abord l'ensemble des requêtes fructueuses récemment envoyées vers un point de terminaison d'API, puis analyse les différents paramètres d'entrée pour chaque requête, en fonction de leur position et de leur type. Une fois toutes les requêtes analysées, la fonctionnalité d'apprentissage de schéma examine les différentes valeurs d'entrée pour chaque position et identifie les caractéristiques qu'elles ont en commun. Après avoir vérifié que l'ensemble des requêtes observées partagent ces éléments communs, la fonctionnalité d'apprentissage de schéma crée un schéma d'entrée contraignant les entrées à se conformer à ces éléments communs. Les entrées peuvent alors être directement utilisées dans le processus de validation de schéma.
Pour permettre l'établissement de schémas d'entrée plus précis, la fonctionnalité d'apprentissage de schéma identifie à quel moment un paramètre peut recevoir différents types d'entrées. Disons que vous souhaitiez créer un fichier de schéma OpenAPIv3 et que vous observez manuellement (dans un petit échantillon de requêtes) qu'un paramètre de requête est un timestamp UNIX. Vous rédigez alors un schéma d'API qui contraint ce paramètre de requête à être un nombre entier plus grand que le début de l'époque UNIX de l'année dernière. Si votre API autorisait également ce paramètre au format ISO 8601, votre nouvelle règle créerait des faux positifs lorsqu'un paramètre au formatage différent (mais valide) atteindrait l'API. La fonctionnalité d'apprentissage de schéma effectue toutes ces tâches à votre place et détecte les éléments que l'inspection manuelle ne parvient pas à repérer.
Pour prévenir les faux positifs, la fonctionnalité d'apprentissage de schéma exécute un test statistique sur la distribution de ces valeurs et ne compile le schéma que lorsque la distribution est délimitée avec un haut degré de confiance.
Alors, à quel point cette fonctionnalité s'en sort-elle ? Vous trouverez ci-dessous quelques statistiques sur les types de paramètres et les valeurs que nous observons :

L'apprentissage de paramètres classe un peu plus de la moitié des paramètres dans la catégorie des chaînes. Les nombres entiers suivent, avec près d'un tiers de la distribution. Les 17 % restants se composent de paramètres de type tableau, booléens ou nombres à virgule flottante, tandis que les paramètres de type objet se voient plus rarement dans le chemin et la requête.

Le nombre de paramètres dans le chemin est habituellement très faible, avec 94 % de l'ensemble des points de terminaison ne comprenant en général qu'un seul paramètre dans leur chemin.

Côté requête, nous constatons la présence de bien plus de paramètres, avec parfois 50 paramètres différents pour un point de terminaison !
L'apprentissage de paramètres peut estimer les contraintes numériques avec un degré de confiance de 99,9 % pour la majorité des paramètres observés. Ces contraintes peuvent constituer soit un maximum/minimum de la valeur, de la longueur ou de la taille du paramètre, ou un ensemble limité de valeurs uniques qu'un paramètre doit adopter.
Protégez vos API en quelques minutes
À compter d'aujourd'hui, tous les clients de la solution API Gateway pourront désormais identifier et protéger leurs API en tout juste quelques clics, même en ne commençant avec aucune information préalable. Dans le tableau de bord Cloudflare, cliquez sur API Gateway, puis sur l'onglet Discovery (Identification) afin d'observer vos points de terminaison identifiés. Ces points de terminaison seront immédiatement disponibles, sans action requise de votre part. Ajoutez ensuite les points de terminaison pertinents de l'onglet Discovery dans la section Endpoint Management (Gestion des points de terminaison). La fonctionnalité d'apprentissage de schéma s'exécute automatiquement pour tous les points de terminaison ajoutés à la section Endpoint Management. Après 24 heures, exportez le schéma produit par la fonctionnalité d'apprentissage et importez-le dans la fonctionnalité Schema Validation (Validation de schéma).
Les clients Enterprise qui n'ont pas acheté la solution API Gateway peuvent commencer en activant l'essai de la solution API Gateway dans le tableau de bord Cloudflare Dashboard ou en contactant le responsable de leur compte.
Et maintenant ?
Nous prévoyons de renforcer la fonctionnalité d'apprentissage de schéma en prenant en charge davantage de paramètres appris dans un plus grand nombre de formats, comme les paramètres de corps POST à la fois au format JSON et « encodage URL », ainsi que les schémas d'en-têtes et de cookies. À l'avenir, la fonctionnalité d'apprentissage de schéma notifiera également les clients lorsqu'elle détectera des modifications dans le schéma d'API identifié, avant de leur présenter un schéma actualisé.
Nous sommes impatients d'entendre vos avis sur ces nouvelles fonctionnalités. Merci d'adresser vos commentaires à l'équipe chargée de votre compte, afin que nous puissions accorder la priorité aux secteurs d'amélioration appropriés. N'hésitez pas à nous faire part de vos retours !