
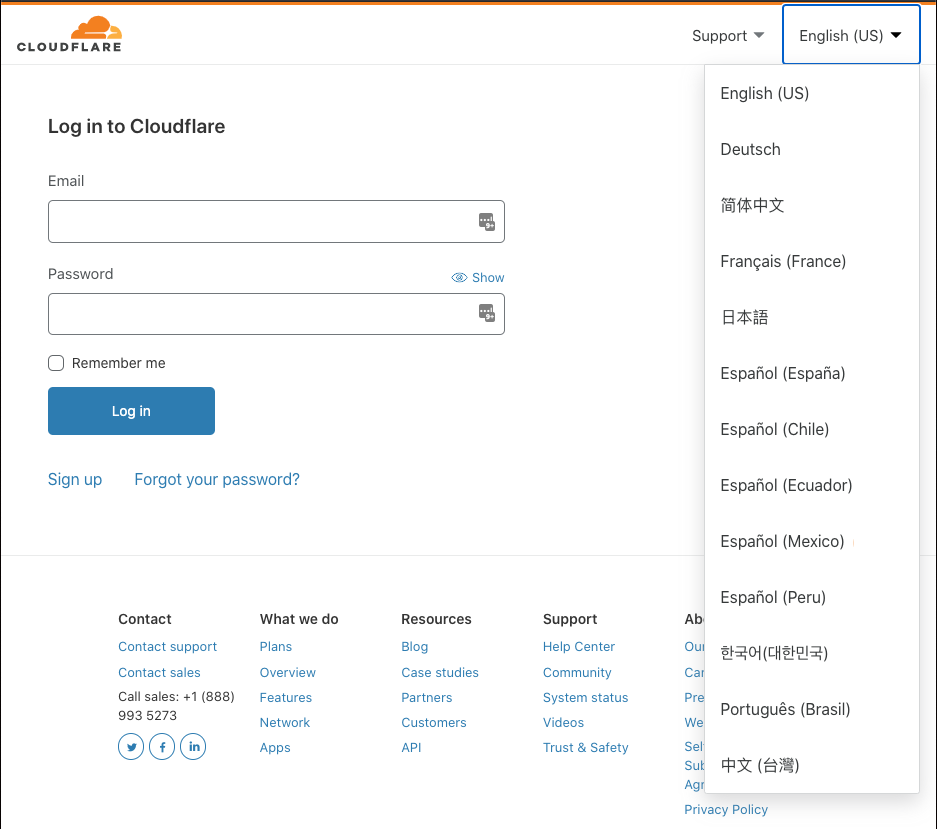
Le tableau de bord de Cloudflare est désormais traduit en quatre nouvelles langues (et a été adapté à certaines spécificités locales) : l’espagnol (avec des adaptations spécifiques pour le Chili, l’Équateur, l’Espagne, le Mexique et le Pérou), le portugais brésilien, le coréen et le chinois traditionnel. Notre clientèle est internationale et diversifiée. Pour contribuer à bâtir un Internet meilleur pour tous, nous devons impérativement proposer nos produits et services à nos clients dans leur langue maternelle.
Cloudflare a commencé à travailler à l’internationalisation de son tableau de bord l’année dernière. Nous avons introduit fin 2019 la première langue autre que l’anglais américain : l’allemand. À la fin du mois de mars 2020, nous avons lancé trois langues supplémentaires : le français, le japonais et le chinois simplifié. Si vous souhaitez utiliser le tableau de bord Cloudflare dans l’une de ces langues, vous pouvez modifier vos préférences linguistiques dans le coin supérieur droit de celui-ci. Votre choix sera enregistré et utilisé lors de toutes vos sessions.
Avec ce billet, je voudrais aider les personnes peu habituées à l’internationalisation et à la localisation à mieux comprendre comment cela fonctionne. J’aimerais également vous raconter comment nous avons fait de l’internationalisation et de la localisation de notre candidature un processus standard et reproductible, et vous donner quelques conseils qui pourraient vous aider à faire de même.
Les débuts
La première étape de l’internationalisation consiste à externaliser toutes les chaînes de votre application. Concrètement, cela signifie que nous extrayons tout texte susceptible d’être lu par un utilisateur, et que nous l’extrayons de votre code d’application pour le placer dans des fichiers séparés et autonomes. Il y a plusieurs raisons à cela :
- Cela permet aux équipes de traducteurs de travailler sur la traduction de ces contenus textuels sans avoir besoin de visualiser ou de modifier le code de l’application.
- La plupart des traducteurs utilisent généralement des applications de traduction qui automatisent certaines tâches et leur fournissent des outils très utiles (mémoire de traduction, suivi des modifications et différents outils d’analyse et de mise en forme). Ces applications ne sont compatibles qu’avec des formats de fichiers texte standard (par exemple des fichiers json, xml, md ou csv).
Sur le plan technique, la séparation du code d’application et du contenu à traduire permet d’apporter des modifications aux chaînes sans recompiler et/ou redéployer le code. Dans notre application basée sur React, l’extraction de la plupart des chaînes consistait à modifier des blocs de code tels que le suivant :
<Button>Cancel</Button>
<Button>Next</Button>
Pour obtenir ce qui suit :
<Button><Trans id="signup.cancel" /></Button>
<Button><Trans id="signup.next" /></Button>
// And in a separate catalog.json file for en_US:
{
"signup.cancel": "Cancel",
"signup.next": "Next",
// ...many more keys
}
L’élément <Trans> ci-dessus constitue la base fondamentale de l’internationalisation dans notre application. Dans ce schéma, les chaînes traduites sont conservées dans de grands dictionnaires indexés par un identifiant de traduction. Nous appelons ces dictionnaires des catalogues de traduction, et il en existe un ensemble pour chaque langue que nous proposons.
Au moment de l’exécution, l’élément <Trans> recherche la traduction dans le catalogue correspondant à l’identifiant indiqué et insère ensuite cette traduction dans la page (via le DOM). Tout le texte statique d’une application peut être extrait au moyen de simples transformations telles que celle-ci.
Cependant, lorsqu’il faut combiner des données dynamiques avec du texte statique, la solution devient un peu plus compliquée. Prenons l’exemple suivant, simple en apparence, qui est truffé de pièges d’internationalisation :
<span>Vous avez sélectionné { totalSelected } Page Rules.</span>
On pourrait être tenté d’extraire cette phrase en la découpant en plusieurs parties, de cette manière :
<Button><Trans id="signup.cancel" /></Button>
<Button><Trans id="signup.next" /></Button>
// And in a separate catalog.json file for en_US:
{
"signup.cancel": "Cancel",
"signup.next": "Next",
// ...many more keys
}
Cela suffit à accomplir cette tâche et peut même sembler être une solution élégante. Après tout, les champs selected.prefix et pageRules.suffix semblent destinés à être réutilisés. Malheureusement, le fait de découper des phrases et de reconstituer des éléments traduits de cette manière s’avère être le plus grand écueil de l’extraction de chaînes pour leur internationalisation.
Le problème est qu’une fois traduits, les différents mots qui composent une phrase peuvent être modifiés de différentes manières en fonction du contexte (singulier ou pluriel, genre, accord sujet/verbe, etc.). Cela varie considérablement d’une langue à l’autre, tout comme l’ordre des mots. En français, par exemple, la phrase « Je mange une pomme » suit un ordre sujet-verbe-complément, alors que d’autres langues peuvent suivre un ordre sujet-complément-verbe (Je une pomme mange), verbe-sujet-complément (Mange je une pomme), ou même d’autres ordres. En raison de ces subtiles différences entre les langues, le fait de coller ensemble des mots traduits individuellement pour reconstituer une phrase entraînera presque toujours des erreurs.
L’exemple de code ci-dessus contient des traductions réelles que nous avons reçues de nos équipes de traduction lorsque nous leur avons demandé de traduire « Vous avez sélectionné » et « Page Rules » séparément. Voici ce que donnerait cette phrase une fois traduite dans les différentes langues :
| Langue | Traduction |
|---|---|
| Japanese | 選択しました { totalSelected } ページ ルール。 |
| German | Sie haben ausgewählt { totalSelected } Page Rules |
| Portuguese (Brazil) | Você selecionou { totalSelected } Page Rules. |
À titre de comparaison, nous leur avons également présenté la phrase en entier en employant un caractère de remplacement pour la variable, et voici le résultat :
| Langue | Traduction |
|---|---|
| Japanese | %{ totalSelected } 件のページ ルールを選択しました。 |
| German | Sie haben %{ totalSelected } Page Rules ausgewählt. |
| Portuguese (Brazil) | Você selecionou %{ totalSelected } Page Rules. |
Comme vous pouvez le constater, les traductions sont différentes en japonais et en allemand. Voilà un problème à résoudre absolument.
Ainsi, afin de garantir que les traducteurs seront en mesure de restituer fidèlement le sens de votre document, vous devez extraire chaque phrase intacte. Notre élément <Trans> permet d’injecter facilement des valeurs dans des modèles de chaînes, ce qui nous permet de faire exactement cela :
<span>
<Trans id="pageRules.selectedForDeletion" values={{ count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ count } Page Rules.",
// ...
}
// Japanese catalog.json
{
"pageRules.selected": "%{ count } 件のページ ルールを選択しました。",
// ...
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ count } Page Rules ausgewählt.",
// ...
}
// Portuguese(Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ count } Page Rules.",
// ...
}
Les traducteurs disposent ainsi du contexte complet de la phrase, ce qui garantit que tous les mots seront traduits en conservant leur sens originel.
Vous avez peut-être remarqué un autre problème potentiel. Que se passe-t-il dans cet exemple lorsque totalSelected est seulement égal à 1 ? Avec le code ci-dessus, l’utilisateur verrait « Vous avez sélectionné 1 Page Rules à supprimer ». La mise au pluriel de la phrase doit être conditionnelle et basée sur la valeur de nos données dynamiques. Il s’agit d’un cas d’utilisation assez courant, et notre élément <Trans> s’en charge automatiquement via la fonctionnalité smart_count :
<span>
<Trans id="pageRules.selectedForDeletion" values={{ smart_count: totalSelected }} />
</span>
// English catalog.json
{
"pageRules.selected": "You've selected %{ smart_count } Page Rule. |||| You've selected %{ smart_count } Page Rules.",
}
// Japanese catalog.json
{
"pageRules.selected": "%{ smart_count } 件のページ ルールを選択しました。 |||| %{ smart_count } 件のページ ルールを選択しました。",
}
// German catalog.json
{
"pageRules.selected": "Sie haben %{ smart_count } Page Rule ausgewählt. |||| Sie haben %{ smart_count } Page Rules ausgewählt.",
}
// Portuguese (Brazil) catalog.json
{
"pageRules.selected": "Você selecionou %{ smart_count } Page Rule. |||| Você selecionou %{ smart_count } Page Rules.",
}
Ici, les versions au singulier et au pluriel sont délimitées par ||||. <Trans> sélectionnera automatiquement la bonne traduction à utiliser en fonction de la variable totalSelected.
Un autre obstacle se présente lorsque le balisage est mélangé à un bloc de texte que nous voudrions extraire sous la forme d’une seule chaîne. Par exemple, que faut-il faire pour qu’une phrase apparaisse comme un lien vers une autre page ?
<VerificationReminder>
Don't forget to <Link>verify your email address.</Link>
</VerificationReminder>
Pour résoudre ce cas d’utilisation, l’élément <Trans> permet d’injecter des éléments arbitraires dans les caractères de remplissage d’une chaîne traduite, par exemple :
<VerificationReminder>
<Trans id="notification.email_verification" Components={[Link]} componentProps={[{ to: '/profile' }]} />
</VerificationReminder>
// catalog.json
{
"notification.email_verification": "Don't forget to <0>verify your email address.</0>",
// ...
}
Dans cet exemple, l’élément <Trans> remplacera les caractères génériques (<0>,<1>, etc.) par des instances appartenant au type d’élément qui appartient à cette catégorie dans le tableau Components (Éléments). Il transfère également toutes les données indiquées dans componentProps vers cette instance. L’exemple ci-dessus correspondrait à ce qui suit dans React :
// en-US
<VerificationReminder>
Don't forget to <Link to="/profile">verify your email address.</Link>
</VerificationReminder>
// es-ES
<VerificationReminder>
No olvide <Link to="/profile">verificar la dirección de correo electrónico.</Link>
</VerificationReminder>
N’oublions pas la sécurité
La fonctionnalité décrite ci-dessus a suffi à nous permettre d’extraire nos chaînes. Cependant, cela a parfois engendré du code compliqué et répétitif très peu pratique à manipuler. Quelques embûches sont rapidement apparues.
Premièrement, les petites chaînes codées en dur devenaient plus faciles à cacher à la vue de tous et, comme elles n’étaient pas vraiment visibles pour les développeurs tant que le reste de la page n’était pas traduit, la boucle de rétroaction pour les détecter se comptait souvent en jours voire en semaines. La solution la plus courante pour résoudre ces problèmes consiste à intégrer un mode de pseudo-localisation à votre application au cours du développement, qui transforme toutes les chaînes correctement internationalisées en remplaçant chaque caractère par un caractère unicode d’apparence similaire.
Par exemple Vous avez sélectionné 3 Page Rules. peut devenir Ỽօմʂ ąѵҽՀ ʂéӀҽçէìօղղé 3 Þáϱè Rúℓèƨ.
Autre fonctionnalité pratique à votre disposition dans un mode de pseudo-localisation : la possibilité de rétrécir ou d’allonger toutes les chaînes selon une valeur fixe afin de tenir compte des différences de largeur entre les contenus. Voici la même phrase pseudo-localisée dont la longueur a été augmentée de 50 % : Ỽօմʂ ąѵҽՀ ʂéӀҽçէìօղղé 3 Þáϱè Rúℓèƨ. ℓôřè₥ ïƥƨú₥ δô. Cela permet d’aider les ingénieurs et les graphistes à repérer les endroits où la longueur du contenu pourrait poser problème. Nous avons identifié ce problème pour la première fois lorsque nous avons lancé notre version en langue allemande, dont les mots sont parfois un peu plus longs que ceux de l’anglais.
Ainsi, à de nombreux endroits, le texte des éléments de la page débordait, comme dans ce bouton « Ajouter » :
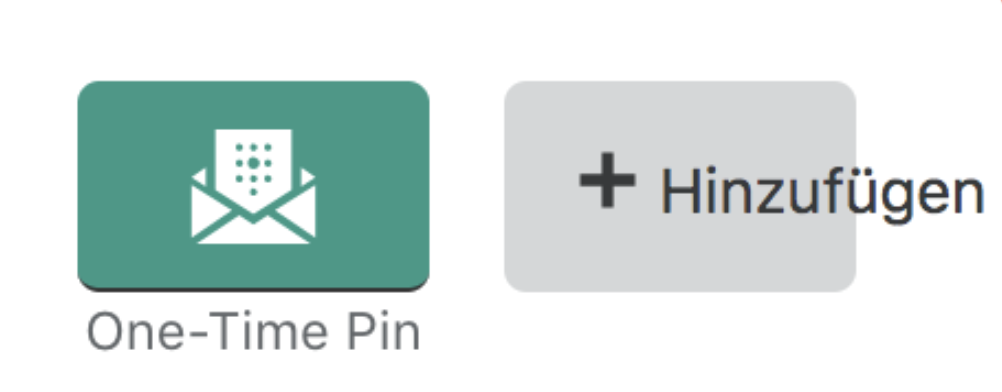
Il n’existe pas beaucoup de solutions faciles pour résoudre ce type de problèmes sans nuire à l’expérience utilisateur.
Pour obtenir les meilleurs résultats, la largeur variable du contenu doit être prise en compte dès la conception des pages. Dans la mesure où il est souvent nécessaire de faire remonter ces erreurs en haut de la chaîne de conception pour demander une modification du design, le processus a tendance à prendre du temps. Si vous n’avez pas beaucoup réfléchi au design du contenu en général, il peut être judicieux de commencer à vous y intéresser dans le cadre d’une internationalisation. Le fait de disposer de normes et d’une cohérence en ce qui concerne la copie utilisée pour les différents éléments de votre application peut non seulement réduire le nombre de mots à traduire, mais aussi vous éviter d’avoir à réfléchir aux problèmes liés à la longueur des contenus à chaque nouvelle phrase.
L’autre problème que nous avons rencontré est celui des identifiants de traduction, surtout les plus longs et les plus répétitifs, qui sont particulièrement sujets aux fautes de frappe.
Petit quiz surprise : parmi ces deux codes, lequel fera planter notre application ? traffic.load_balancing.analytics.filters.origin_health_title ou traffic.load_balancing.analytics.filters.origin_heath_title
Nichées parmi des centaines d’autres lignes de modifications, celles-ci sont difficiles à repérer au moment du contrôle des codes. La plupart des applications ont une fonction de récupération pour éviter que les traductions erronées n’entraînent une erreur dans les pages. Par conséquent, un bug comme celui-ci peut passer totalement inaperçu s’il est suffisamment bien dissimulé (par exemple dans un message d’aide).
Heureusement, notre base de code étant de plus en plus souvent écrite en TypeScript, nous avons pu utiliser l’outil de vérification de la typographie pour faire remonter les informations aux développeurs pendant qu’ils écrivaient le code. Voici un exemple dans lequel notre éditeur de code souligne en rouge que la valeur de l’identifiant est incorrecte (car il manque un « l ») :

Non seulement cela a permis de mettre les problèmes en évidence, mais cela signifie également que les violations feront échouer les compilations, en empêchant que du code erroné n’entre dans la base de données.
Adapter les fichiers de traduction
Au début, vous commencerez probablement avec un fichier de traduction pour chaque langue dans laquelle vous traduirez votre contenu. De plus, la méthode de désignation de vos codes peut demeurer assez simple. Au fur et à mesure que votre application évolue, votre fichier de traduction deviendra trop volumineux et devra être découpé en plusieurs fichiers indépendants. Les fichiers trop volumineux risquent de saturer les applications de traduction ou, si vous ne les contrôlez pas, votre éditeur de code. La totalité de nos textes traduits (sans les codes), regroupés dans un seul fichier, représente environ 50 000 mots. À titre de comparaison, c’est à peu près autant qu’un exemplaire du « Guide du voyageur galactique » ou d’« Abattoir 5 ».
Nous divisons nos traductions en un certain nombre de fichiers « catalogue » correspondant à peu près à des entités verticales (comme Firewall ou Cloudflare Workers). Cette solution convient bien à nos développeurs, car elle leur permet de prévoir où trouver les chaînes et de réduire le nombre de lignes d’un catalogue de traduction pour obtenir un volume gérable. Cela fonctionne également bien pour les équipes de traduction extérieures, les traducteurs (ou les petites équipes) préférant travailler sur des entités verticales.
En plus des catalogues classés par fonctionnalités, nous disposons d’un fichier catalogue commun pour les chaînes qui sont réutilisées dans l’ensemble de l’application. Il nous permet de réduire la taille des identifiants ( common.delete plutôt que some_page.some_tab.some_feature.thing.delete) et la probabilité de duplication, puisque les développeurs vérifient généralement le catalogue commun avant d’ajouter de nouvelles chaînes.
Bibliothèques
Jusqu’à présent, nous avons longuement parlé de notre élément <Trans> et des possibilités qu’il offre. Voyons maintenant de quoi il est composé.
Il n’est sans doute pas surprenant que nous n’ayons pas voulu réinventer la roue en créant une bibliothèque d’internationalisation complète. Lorsque nous avons internationalisé certaines parties de notre application écrite en Backbone, nous utilisions déjà la bibliothèque Polyglot d’Airbnb, une « minuscule bibliothèque d’aide à l’internationalisation écrite en JavaScript » qui, entre autres, « fournit une solution simple d’interpolation et de pluralisation, fondée sur le savoir-faire d’Airbnb qui a ajouté la fonctionnalité de l’internationalisation à ses applications Backbone.js et Node ».
Nous avons passé en revue quelques-unes des bibliothèques les plus répandues ayant été spécialement conçues pour l’internationalisation des applications React, mais nous avons finalement décidé de conserver Polyglot. Nous avons créé notre élément <Trans> pour combler le vide avec React. Notre choix a été motivé par plusieurs raisons :
- Nous ne voulions pas ré-internationaliser le code existant dans notre application pour pouvoir migrer vers une nouvelle bibliothèque compatible i18n.
- Nous ne voulions pas non plus avoir à gérer deux systèmes d’internationalisation différents pour le nouveau code et l’ancien.
- Le fait d’écrire notre propre élément trans nous a donné la flexibilité nécessaire pour écrire l’interface que nous voulions. Trans étant utilisé un peu partout, nous voulions le rendre aussi ergonomique que possible pour les développeurs.
Si vous débutez votre internationalisation dans une nouvelle application web basée sur React, react-intl et i18n-next sont deux bibliothèques populaires qui fournissent un élément similaire à <Trans> décrit ci-dessus.
Comme indiqué ci-dessus, le principal problème de l’élément <Trans> est que les chaînes doivent être enregistrées dans un fichier distinct de votre code source. Passer d’un fichier à l’autre lorsque vous écrivez un nouveau code ou modifiez des fonctionnalités existantes est absolument fastidieux. C’est encore pire si les fichiers de traduction sont placés loin dans la structure des répertoires, ce qui est souvent nécessaire.
De nouvelles bibliothèques i18n telles que jslingui permettent d’éviter ce problème en appliquant une stratégie de gestion des catalogues de traduction fondée sur l’extraction. Avec ce système, vous utilisez toujours un élément <Trans>, mais les chaînes sont conservées dans l’élément lui-même, et non dans un catalogue séparé :
<span>
<Trans>Hmm... We couldn't find any matching websites.</Trans>
</span>
Un outil que vous exécutez au moment de la compilation se charge ensuite de trouver toutes ces chaînes et de les extraire dans des catalogues pour vous. Par exemple, les catalogues suivants seraient générés à partir de ce qui précède :
// locales/en_US.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... We couldn't find any matching websites.",
}
// locales/de_DE.json
{
"Hmm... We couldn't find any matching websites.": "Hmm... Wir konnten keine übereinstimmenden Websites finden."
}
Cette méthode présente l’avantage évident de ne plus nécessiter de fichiers séparés ! Autre avantage : il n’est plus nécessaire de vérifier la typographie des codes d’identification puisqu’il n’est plus possible de faire de fautes de frappe.
Cependant, elle présente quelques inconvénients, en tout cas dans le cas d’utilisation qui nous intéresse.
Tout d’abord, les traducteurs humains apprécient souvent le contexte fourni par les codes de traduction. Cela facilite l’organisation et donne quelques indices sur la signification de la chaîne.
De plus, si nous n’avons plus à nous soucier des fautes de frappe dans les codes d’identification des traductions, nous risquons néanmoins de voir apparaître de légères erreurs (par exemple, « votre adresse email » au lieu de « votre adresse e-mail »). Le problème est presque pire, car dans ce cas, cela créerait une quasi-redondance qui serait difficile à détecter. Cela nous coûterait aussi de l’argent.
Quelle que soit la pile technique avec laquelle vous travaillez, vous trouverez probablement quelques bibliothèques i18n qui pourront vous aider. Leur choix dépend fortement des contraintes techniques de votre application, ainsi que des objectifs et de la culture de votre équipe.
Nombres, dates et heures
Nous avons déjà parlé de l’injection de chaînes dont les données ont été traduites, mais nous avons laissé de côté un problème majeur : il se peut qu’il soit nécessaire de les mettre en forme pour qu’elles soient conformes aux pratiques locales des utilisateurs. C’est le cas des dates, des heures, des chiffres, des devises et de quelques autres types de données.
Reprenons notre exemple simple de tout à l’heure :
<span>You've selected { totalSelected } Page Rules.</span>
L’absence de mise en forme appropriée ne posera pas de problème pour les petits nombres, mais dès que l’on dépassera le millier, la traduction ne sera plus correcte, car la façon dont les chiffres sont groupés et séparés par des symboles diffère selon les cultures. Voici des exemples de mise en forme du nombre trois cent mille et trois centièmes dans plusieurs langues :
| Langue (pays) | Code | Date mise en forme |
|---|---|---|
| Allemand (Allemagne) | de-DE | 300.000,03 |
| Anglais ((États-Unis)) | en-US | 300,000.03 |
| Anglais ((Royaume-Uni)) | en-GB | 300,000.03 |
| Espagnol (Espagne) | es-ES | 300.000,03 |
| Espagnol (Chili) | es-CL | 300.000,03 |
| Français (France) | fr-FR | 300 000,03 |
| Hindi (Inde) | hi-IN | 3,00,000.03 |
| Indonésien (Indonésie) | in-ID | 300.000,03 |
| Japoniais (Japon) | ja-JP | 300,000.03 |
| Coréen (Corée du Sud) | ko-KR | 300,000.03 |
| Portugais (Brésil) | pt-BR | 300.000,03 |
| Portugais (Portugal) | pt-PT | 300 000,03 |
| Russe (Russie) | ru-RU | 300 000,03 |
La mise en forme des dates varie considérablement d’un pays à l’autre. Si votre interface utilisateur s’adresse principalement à un public américain, vous afficherez probablement les dates d’une manière qui semblera bizarre et peut-être peu compréhensible pour des utilisateurs originaires de tout autre pays du monde. La mise en forme de la date peut notamment varier en ce qui concerne les caractères de séparation, la présence ou non de zéros devant les chiffres et l’ordre dans lequel sont classés le jour, le mois et l’année. Voici quelques exemples de mise en forme de la date du 4 mars de l’année en cours :
| Langue (pays) | Code | Date mise en forme |
|---|---|---|
| Allemand (Allemagne) | de-DE | 4.3.2020 |
| Anglais ((États-Unis)) | en-US | 3/4/2020 |
| Anglais ((Royaume-Uni)) | en-GB | 04/03/2020 |
| Espagnol (Espagne) | es-ES | 4/3/2020 |
| Espagnol (Chili) | es-CL | 04-03-2020 |
| Français (France) | fr-FR | 04/03/2020 |
| Hindi (Inde) | hi-IN | 4/3/2020 |
| Indonésien (Indonésie) | in-ID | 4/3/2020 |
| Japoniais (Japon) | ja-JP | 2020/3/4 |
| Coréen (Corée du Sud) | ko-KR | 2020.3.4. |
| Portugais (Brésil) | pt-BR | 04/03/2020 |
| Portugais (Portugal) | pt-PT | 04/03/2020 |
| Russe (Russie) | ru-RU | 04.03.2020 |
La mise en forme de l’heure est elle aussi très variable. Voici comment est structurée l’heure dans certains pays :
| Langue (pays) | Code | Date mise en forme |
|---|---|---|
| Allemand (Allemagne) | de-DE | 14:02:37 |
| Anglais ((États-Unis)) | en-US | 2:02:37 PM |
| Anglais ((Royaume-Uni)) | en-GB | 14:02:37 |
| Espagnol (Espagne) | es-ES | 14:02:37 |
| Espagnol (Chili) | es-CL | 14:02:37 |
| Français (France) | fr-FR | 14:02:37 |
| Hindi (Inde) | hi-IN | 2:02:37 PM |
| Indonésien (Indonésie) | in-ID | 14.02.37 |
| Japoniais (Japon) | ja-JP | 14:02:37 |
| Coréen (Corée du Sud) | ko-KR | 오후 2:02:37 |
| Portugais (Brésil) | pt-BR | 14:02:37 |
| Portugais (Portugal) | pt-PT | 14:02:370 |
| Russe (Russie) | ru-RU | 14:02:37 |
Bibliothèques permettant de gérer les nombres, les dates et les heures
Il n’est pas facile de respecter la mise en forme de tous ces types de données dans toutes les langues. Heureusement, vous pouvez utiliser un certain nombre de bibliothèques bien établies et éprouvées.
Lorsque nous avons lancé notre projet, nous avions très souvent recours à la bibliothèque Moment.js pour la mise en forme de la date et de l’heure. Cette bibliothèque très pratique permet de remplacer les dates par des formats de longueur différente (« Jeudi » au lieu de « 9 juillet 2020 » ou « 9 juil. 2020 ») et d’afficher des dates relatives (« il y a 2 jours »), entre autres choses. Comme presque toutes nos dates étaient déjà mises en forme avec Moment.js pour des raisons de lisibilité, et comme Moment.js prend déjà en charge i18n pour un grand nombre de langues, un petit nombre de manipulations nous ont suffi à adapter les dates sans grandes difficultés.
Moment.js fait l’objet de critiques sévères (surtout en raison de son caractère surchargé), mais en fin de compte, le recours à une solution moins lourde par rapport à ce que coûterait la remise en forme de chaque date et de chaque heure ne présenterait pas d’avantages.
Il en va tout autrement pour les chiffres. Comme vous pouvez l’imaginer, notre tableau de bord affichait des milliers de chiffres bruts et non formatés. Leur recherche était une opération laborieuse et souvent manuelle.
Pour gérer le formatage des chiffres, nous avons utilisé l’API Intl (la bibliothèque d’internationalisation définie par la norme ECMAScript) :
var number = 300000.03;
var formatted = number.toLocaleString('hi-IN'); // 3,00,000.03
// This probably works in the browser you're using right now!
Heureusement, Intl est devenu assez largement compatible avec les navigateurs ces dernières années, tous les navigateurs modernes étant pleinement compatibles.
Certains moteurs JavaScript modernes tels que V8 se sont même éloignés des réalisations JavaScript auto-hébergées de ces bibliothèques en faveur de compilations en C++, ce qui permet d’accélérer considérablement.
Toutefois, les anciens navigateurs ne sont pas toujours pris en charge. Voici un site de démonstration simple (code source) développé avec Cloudflare Workers qui montre comment les dates, les heures et les nombres sont affichés dans plusieurs langues.
Certaines associations de navigateurs et de systèmes d’exploitation anciens donneront des résultats peu satisfaisants. Par exemple, voici comment les dates et les heures susmentionnées sont affichées sous Windows 8 avec Internet Explorer 10 :
 |
 |
Si vous devez prendre en charge des navigateurs plus anciens, ce problème peut être résolu à l’aide d’un polyfill.
Traduction
Toutes les chaînes étant extraites et toutes les données injectées étant soigneusement mises en forme selon des modèles locaux, la majeure partie du travail technique est achevée. À ce stade, nous pouvons maintenant affirmer que nous avons internationalisé notre application, puisque nous l’avons adaptée de manière à la rendre facile à traduire.
Vient ensuite le processus d’adaptation locale, qui consiste à créer un contenu adapté à la langue et aux normes culturelles des utilisateurs.
Ce n’est pas une mince affaire. Comme nous l’avons déjà dit, la somme des chaînes que contient notre application correspond au volume de texte que contient un court roman. La création d’une version traduite à la fois fidèle et compréhensible pour les utilisateurs nécessite une bonne dose de coordination et de compétences humaines.
Le travail de traduction peut être effectué de différentes manières : en faisant appel à des membres du personnel polyglottes, en confiant le travail à des traducteurs individuels ou à des agences, ou même en mettant en place des équipes de traducteurs internes. En tout état de cause, le processus doit être efficace tant pour la transmission des flux de travail que pour le transfert des ressources entre les équipes de traduction et de développement.
Un programme i18n en bonne et due forme doit offrir aux développeurs une interface de type boîte noire avec le processus : les développeurs ajoutent de nouvelles chaînes dans un fichier de catalogue de traduction et effectuent les modifications. Sans plus d’efforts de leur part, le code qu’ils ont écrit est disponible pour toutes les langues disponibles quelques jours plus tard. De même, lorsque le processus est bien mené, les traducteurs ignorent tout sur celui-ci et sur l’architecture de l’application. Ils reçoivent des fichiers qu’ils peuvent facilement charger dans leurs outils de traduction et qui indiquent clairement les morceaux de texte à traduire.
Comment cela fonctionne-t-il en pratique ?
Nous utilisons un ensemble de scripts automatisés pouvant être exécutés à la demande par l’équipe en charge de la traduction afin d’obtenir un aperçu de nos catalogues de traduction pour toutes les langues disponibles. Plusieurs choses se produisent au cours de ce processus :
- Des fichiers JSON sont générés à partir de fichiers de catalogue rédigés en TypeScript.
- Si de nouveaux fichiers de catalogue ont été ajoutés en anglais, des copies génériques sont créées pour toutes les autres langues disponibles.
- Des chaînes génériques sont ajoutées pour toutes les langues lorsque de nouvelles chaînes sont ajoutées à notre catalogue de base.
Ensuite, les catalogues de traduction sont envoyés au système de gestion des traductions via l’interface utilisateur ou des appels automatiques à l’API. Avant de les confier aux traducteurs, chaque chaîne est comparée à d’anciennes traductions présentes sous forme de chaînes et sous-chaînes dans une mémoire de traduction. Si une correspondance est trouvée, la traduction existante est utilisée. Non seulement cela permet de réduire les coûts en évitant de traduire à nouveau des chaînes déjà traduites auparavant, mais le fait de réutiliser des traductions déjà contrôlées et approuvées dans la mesure du possible contribue à améliorer la qualité.
Imaginons que vos fichiers de traduction finissent par ressembler à ceci :
{
"verify.button": "Verify Email",
"other.verify.button": "Verify Email",
"verify.proceed.link": "Verify Email to proceed",
// ...
}
Nous avons ici des chaînes reproduites mot à mot, ainsi que des sous-chaînes copiées. Les services de traduction sont facturés au mot : mieux vaut ne pas payer deux fois pour la même chose et éviter les problèmes de cohérence. Il est donc important de disposer de bases de données de traduction bien conçues afin que ces chaînes soient traduites dès les étapes de pré-traduction, avant même que les traducteurs ne reçoivent le fichier.
Une fois que le travail de traduction est déclaré terminé, les équipes de traduction peuvent mettre des heures, voire des semaines, à effectuer des relectures, en fonction d’un certain nombre de facteurs tels que la quantité de mots, la disponibilité des traducteurs et les conditions contractuelles. Les enjeux de cette phase pourraient faire à eux seuls l’objet d’un autre article de blog aussi long que celui-ci : trouver des traducteurs compétents, gérer les coûts, contrôler la qualité et la cohérence, veiller à la préservation de l’image de marque, etc. Cet article se concentrant principalement sur des considérations techniques, nous ferons ici abstraction des détails, mais ne vous méprenez pas : une erreur à ce stade ruinera tous vos efforts, même si vous avez atteint vos objectifs techniques.
Lorsque les équipes de traduction annoncent que les nouveaux fichiers sont prêts à être récupérés, les ressources sont extraites du serveur et réparties aux bons endroits dans le code de l’application. Nous effectuons ensuite une série de contrôles automatisés pour nous assurer que tous les fichiers sont valides et ne présentent aucun problème de formatage.
À ce stade, il est possible de procéder à une opération facultative (mais fortement recommandée) : la révision en contexte. Une équipe de relecteurs examine la traduction dans son contexte pour s’assurer que sa version finale est parfaite. Pour ce faire, il est particulièrement utile de disposer d’un personnel qui maîtrise à la fois le produit et la langue cible. Nous remercions chaleureusement les collaborateurs qui ont pris le temps et déployé beaucoup d’efforts pour le faire. Pour permettre à des sous-traitants externes de le faire, nous préparons des versions préliminaires spéciales de notre application qui leur permettent de réaliser des tests en activant les langues du mode de développement.
Et voilà, vous savez tout ce qu’il faut faire pour offrir une version traduite de votre application à vos utilisateurs du monde entier.
L'adaptation culturelle et linguistique permanente
Nous aimerions bien nous arrêter ici, mais jusqu’à présent, nous avons surtout parlé de ce qu’il faut faire pour y arriver une fois. Comme chacun le sait, le code évolue. De nouvelles chaînes seront ajoutées, modifiées et supprimées au fil du temps, au fur et à mesure que de nouvelles fonctionnalités seront lancées et améliorées.
La traduction étant une activité essentiellement humaine et nécessitant souvent le concours de personnes habitant aux quatre coins du globe, les délais de réalisation d’une traduction sont plus longs. Notre rythme de publication (quotidien) étant souvent plus rapide que ce rythme de production (2 à 5 jours), les développeurs qui apportent des modifications aux fonctionnalités doivent faire un choix : ralentir pour respecter ce rythme, ou livrer les produits légèrement en avance sur le calendrier de traduction, sans que la diffusion ne soit complète.
Afin de nous assurer que le lancement des fonctionnalités avant leur traduction ne provoque pas de problèmes dans les applications, nous affichons les chaînes qui n’ont pas encore été traduites dans la langue choisie dans la langue de base (en_US).
Dans certaines applications, la procédure de secours est légèrement différente : elles affichent des codes de traduction bruts (vous avez peut-être déjà vu des.phrases.bizarres.délimitées.par.des.points dans une application que vous utilisez). Nous devons faire un compromis entre la rapidité et la précision, et nous avons choisi d’optimiser la vitesse et de réduire au maximum les frais généraux. Dans certaines applications, la précision est suffisamment importante pour ralentir la cadence de l’internationalisation. Ce n’était pas notre cas.
Touches finales
Nous pouvons encore ajouter quelques petites choses afin d’optimiser la qualité de notre application nouvellement traduite.
Nous voulons en premier lieu nous assurer que les performances ne sont pas dégradées. Si notre application obligeait l’utilisateur à récupérer toutes les chaînes traduites avant d’afficher la page, elles le seraient sûrement. Ainsi, pour que tout fonctionne bien, les catalogues de traduction sont récupérés de manière asynchrone et uniquement lorsque l’application en a besoin pour afficher un certain contenu sur la page. De nos jours, cette opération est aisée grâce aux outils de fractionnement du code disponibles dans les modules bundler qui prennent en charge les instructions d’importation dynamiques tels que Parcel ou Webpack.
Nous voulons également éviter que l’utilisateur soit obligé de sélectionner constamment la langue dans laquelle il souhaite consulter les différentes pages de Cloudflare. Pour cela, nous avons fait en sorte que toute préférence linguistique qu’un utilisateur sélectionne sur notre site promotionnel ou sur notre site d’assistance soit conservée pendant qu’il navigue vers ou depuis notre tableau de bord (tous les liens sont en français pour illustrer ce propos).
Et maintenant ?
Ce fut une aventure passionnante, et nous avons beaucoup appris de ce processus. Il est difficile (voire impossible) de considérer qu’un projet i18n est vraiment achevé. Proposer des contenus dans plusieurs langues entraîne l’apparition de nouveaux bugs et vous expose à de nouveaux défis. La contrainte budgétaire vous obligera à trouver des moyens de réduire les coûts et d’accroître l’efficacité. En outre, vous découvrirez des façons d’améliorer encore plus la qualité du service de traduction pour les utilisateurs.
La liste des choses que nous aimerions améliorer est longue, mais en voici quelques unes :
- Comparaison. La comparaison des chaînes dépend de la langue et, de ce fait, le code que vous avez écrit pour trier lexicalement les listes et les tableaux de données dans votre application ne convient probablement pas à certains de vos utilisateurs. Ce problème est particulièrement flagrant dans les langues qui utilisent des systèmes d’écriture à base de logogrammes (comme le chinois ou le japonais), par opposition aux langues qui utilisent des alphabets (comme l’anglais ou l’espagnol).
- Prise en charge des langues qui se lisent de droite à gauche comme l’arabe et l’hébreu.
- La traduction des réponses de l’API est plus difficile que celle de la copie statique de votre interface utilisateur, car elle nécessite un travail de coordination entre les équipes. À l’ère des micro-services, il peut être très difficile de trouver une solution qui fonctionne bien dans la myriade de piles technologiques qui animent chaque service.
- Traduction des cartes. Nous ferons en sorte que tout le contenu de nos illustrations basées sur des cartes soit traduit.
- La traduction automatique a beaucoup progressé ces dernières années, mais pas assez pour produire des traductions ne nécessitant pas d’intervention humaine. Toutefois, nous aimerions davantage y avoir recours en premier lieu afin que des correcteurs y apportent ensuite toutes les modifications nécessaires à la bonne compréhension du texte et à la justesse du ton employé.
J’espère que vous avez apprécié cette présentation de la manière dont Cloudflare a internationalisé et traduit son tableau de bord. Rendez-vous sur notre page d’offres d’emploi pour voir les postes à plein temps et les stages que nous proposons dans le monde entier.