
L'équipe @Cloudflare a tout récemment mis en place des changements qui améliorent considérablement les performances de notre réseau, surtout en ce qui concerne les requêtes aberrantes particulièrement lentes. Quel est le gain de temps ? Selon nos estimations, nous faisons gagner chaque jour environ 54 ans de temps d'attente lors du chargement de sites Web.
- @eastdakota - 28 juin 2018
10 millions de sites Web, d'applications et d'API utilisent Cloudflare pour accélérer la vitesse de navigation de leurs utilisateurs. En période de pointe, nos 151 datacenters répondent à plus de 10 millions de requêtes par seconde. Au fil des ans, nous avons apporté de nombreuses modifications à notre version de NGINX pour nous adapter à notre croissance. Cet article concerne l'un d'entre eux.
Comment fonctionne NGINX ?
NGINX fait partie des programmes qui ont popularisé l'utilisation des boucles d'événements pour résoudre le C10K problem. Chaque fois qu'un événement réseau entre en jeu (nouvelle connexion, requête, notification concernant la possibilité d'envoyer plus de données, etc.), NGINX se déclenche, gère l'événement, puis retourne à ses activités (par exemple, gérer d'autres événements). Lorsqu'un événement survient, les données correspondantes sont déjà prêtes, ce qui permet à NGINX de traiter efficacement plusieurs requêtes simultanément et sans délai.
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
// handle event[1]: send out response to GET http://cloudflare.com/
Voici à quoi peut ressembler un bout de code permettant de lire les données d'un descripteur de fichier :
// we got a read event on fd
while (buf_len > 0) {
ssize_t n = read(fd, buf, buf_len);
if (n < 0) {
if (errno == EWOULDBLOCK || errno == EAGAIN) {
// try later when we get a read event again
}
if (errno == EINTR) {
continue;
}
return total;
}
buf_len -= n;
buf += n;
total += n;
}
Lorsque fd est un socket réseau, cela renvoie les octets qui sont déjà arrivés. La dernière requête renverra EWOULDBLOCK, ce qui signifie que nous avons vidé le tampon de lecture local, et donc que nous ne devrions plus lire depuis le socket tant que nous n’aurons pas plus de données.
L'entrée/sortie de disque est différente de l'entrée/sortie réseau
S ifd est un fichier ordinaire sous Linux, EWOULDBLOCK et EAGAIN ne se produisent jamais, et read attend toujours pour lire tout le tampon. Cela est vrai même si le fichier a été ouvert avec O_NONBLOCK. D’après open(2) :
Notez que cet indicateur n'a pas d'effet pour les fichiers ordinaires et les dispositifs de bloc
En d’autres termes, le code ci-dessus se réduit essentiellement à :
if (read(fd, buf, buf_len) > 0) {
return buf_len;
}
Cela signifie que si un gestionnaire d'événements doit lire depuis le disque, il bloquera la boucle d'événements jusqu'à ce que la lecture soit achevée et que les gestionnaires d'événements suivants soient retardés.
En définitive, cela convient à la plupart des systèmes d'exploitation, car la lecture sur disque est généralement assez rapide et beaucoup plus prévisible que l'attente d'un paquet en provenance du réseau. Cette constatation est particulièrement vrai maintenant que tout le monde utilise un disque SSD, et que tous nos disques cache sont des disques SSD. Les disques SSD modernes ont une latence très faible, qui est généralement de l'ordre de quelques dizaines de µs. En outre, nous pouvons exécuter NGINX avec plusieurs processus pour éviter que les requêtes ne soient bloquées par un gestionnaire d'événements lent dans d’autres processus. La plupart du temps, nous pouvons compter sur la gestion des événements de NGINX pour traiter les demandes de service rapidement et efficacement.
Les performances SSD, pas toujours fidèles à ce qui est indiqué sur l'étiquette
Vous l'aurez deviné, ces hypothèses optimistes sont parfois irréalistes. Si chaque lecture prend toujours 50 µs, alors il ne faudrait que 2 ms pour lire 0,19 Mo en blocs de 4 Ko (et nous lisons des blocs plus volumineux). Toutefois, nos propres mesures ont montré que notre délai jusqu'au premier octet est parfois bien plus long, en particulier aux 99e et 999e centiles. En d'autres termes, la lecture la plus lente pour 100 (ou pour 1 000) lectures prend souvent beaucoup plus de temps.
Les disques SSD sont très rapides, mais ils sont également réputés pour leur complexité. Ils contiennent des calculateurs qui mettent en file d'attente et réorganisent les E/S, tout en exécutant diverses tâches en arrière-plan, comme la récupération de mémoire et la défragmentation. Il peut arriver qu'une requête soit suffisamment ralentie pour avoir un impact. En effectuant des tests d’E/S, mon collègue Ivan Babrou a observé des pics de lecture allant jusqu'à 1 seconde. De plus, certains de nos disques SSD ont plus de valeurs aberrantes que d'autres. À l'avenir, nous tiendrons compte de la cohérence des performances lors de nos achats de disques SSD, mais, en attendant, nous avons besoin d'une solution pour notre matériel existant.
Répartition uniforme de la charge avec SO_REUSEPORT
Il est difficile d'éviter les réponses lentes individuelles qui se produisent de temps en temps, mais il faut à tout prix éviter les E/S d’1 seconde qui bloquent les 1 000 autres requêtes que nous recevons pendant cette même seconde. Théoriquement, NGINX peut gérer de nombreuses requêtes en parallèle, mais il n'exécute qu'un gestionnaire d'événements à la fois. J'ai donc ajouté un paramètre qui mesure cela :
gettimeofday(&start, NULL);
num_events = epoll_wait(epfd, /*returned=*/events, events_len, /*timeout=*/-1);
// events is list of active events
// handle event[0]: incoming request GET http://example.com/
gettimeofday(&event_start_handle, NULL);
// handle event[1]: send out response to GET http://cloudflare.com/
timersub(&event_start_handle, &start, &event_loop_blocked);
P99 de event_loop_blocked s'est avéré correspondre à plus de 50 % de notre TTFB. Autrement dit, la moitié du temps nécessaire pour répondre à une requête est attribuable au fait que la boucle d'événements est bloquée par d'autres requêtes. event_loop_blocked ne mesure qu'environ la moitié du blocage (car les appels retardés vers epoll_wait() ne sont pas mesurés), donc le ratio réel de la durée de blocage est beaucoup plus élevé.
Chacune de nos machines exécute NGINX avec 15 processus, ce qui signifie que des E/S lentes devraient bloquer au plus 6 % des requêtes. Cependant, les événements ne sont pas répartis de façon égale, le meilleur processus ayant reçu 11 % des requêtes (soit deux fois plus que prévu).
SO_REUSEPORT peut résoudre le problème de la répartition inégale. Marek Majkowski a déjà abordé le sujet des inconvénients dans le cadre d’autres instances NGINX, mais cet inconvénient ne s’applique en grande partie pas dans notre cas, car les connexions en amont dans notre processus de cache subsistent longtemps ; ainsi, une latence légèrement plus élevée dans l’ouverture de la connexion est négligeable. Ce changement de configuration unique pour activer SO_REUSEPORT a amélioré le pic p99 de 33 %.
Le déplacement de read() vers le pool de threads n’est pas une solution miracle
Une solution consiste à faire en sorte que read() ne bloque pas. De fait, cette fonctionnalité est intégrée en amont de NGINX ! Lorsque la configuration suivante est utilisée, read() et write() sont exécutés dans un pool de threads et ne bloquent pas la boucle d'événements :
aio threads;
aio_write on;
Cependant, en testant cela, au lieu d'améliorer le temps de réponse de 33 fois, nous avons constaté une légère augmentation de la valeur de p99. La différence se situait dans la marge d'erreur, mais nous avons été assez découragés par le résultat et avons arrêté de poursuivre dans cette voie pendant quelques temps.
Plusieurs raisons expliquent pourquoi nous n'avons pas constaté le même niveau d'amélioration que NGINX. Lors de leur test, 200 connexions simultanées étaient utilisées pour requérir des fichiers d'une taille de 4 Mo, qui se trouvaient sur des disques rotatifs. Les disques rotatifs augmentent la latence des E/S. Il est donc logique qu'une optimisation des temps de latence ait un effet plus important.
Nous nous intéressons aussi surtout aux performances dep99 (et de p999). Les solutions qui améliorent les performances moyennes ne permettent pas forcément de corriger les aberrations.
Enfin, dans notre environnement, les fichiers sont généralement beaucoup plus petits. 90 % de nos succès de cache correspondent à des fichiers de moins de 60 Ko. Plus les fichiers sont petits, moins il est facile de les bloquer (nous lisons généralement le fichier en entier en 2 fois).
Voici ce que nous voyons si nous examinons les E/S de disque nécessaires à un succès de cache :
// we got a request for https://example.com which has cache key 0xCAFEBEEF
fd = open("/cache/prefix/dir/EF/BE/CAFEBEEF", O_RDONLY);
// read up to 32KB for the metadata as well as the headers
// done in thread pool if "aio threads" is on
read(fd, buf, 32*1024);
32 Ko n'est pas une valeur statique. Si les en-têtes sont petits, il suffit de lire 4 Ko (nous n'utilisons pas d'E/S directes, donc le kernel arrondit à 4 Ko). open() semble anodin, mais il n'est pas libre. Le kernel doit au minimum vérifier si le fichier existe et si le processus d'appel est autorisé à l'ouvrir. Pour cela, il faudrait qu'il trouve le nœud d'index /cache/prefix/dir/EF/BE/CAFEBEEF et, pour ce faire, il devrait rechercher CAFEBEEF dans /cache/prefix/dir/EF/BE/. En bref, dans le pire des cas, le kernel doit effectuer les contrôles suivants :
/cache
/cache/prefix
/cache/prefix/dir
/cache/prefix/dir/EF
/cache/prefix/dir/EF/BE
/cache/prefix/dir/EF/BE/CAFEBEEF
Cela représente 6 lectures différentes effectuées par open() contre 1 seule lecture effectuée par read() ! Heureusement, la plupart du temps, les recherches sont effectuées par le dentry cache et ne nécessitent pas de déplacement vers les SSD. Mais, de toute évidence, le fait d'exécuter read() dans le pool de threads ne représente que la moitié du tableau.
Le coup de grâce : open() non bloquant dans les pools de threads
J'ai donc modifié NGINX pour qu'il exécute la majeure partie de la commande open() à l'intérieur du pool de threads afin qu'il ne bloque pas la boucle d'événements. Voici le résultat (open et read non bloquants) :
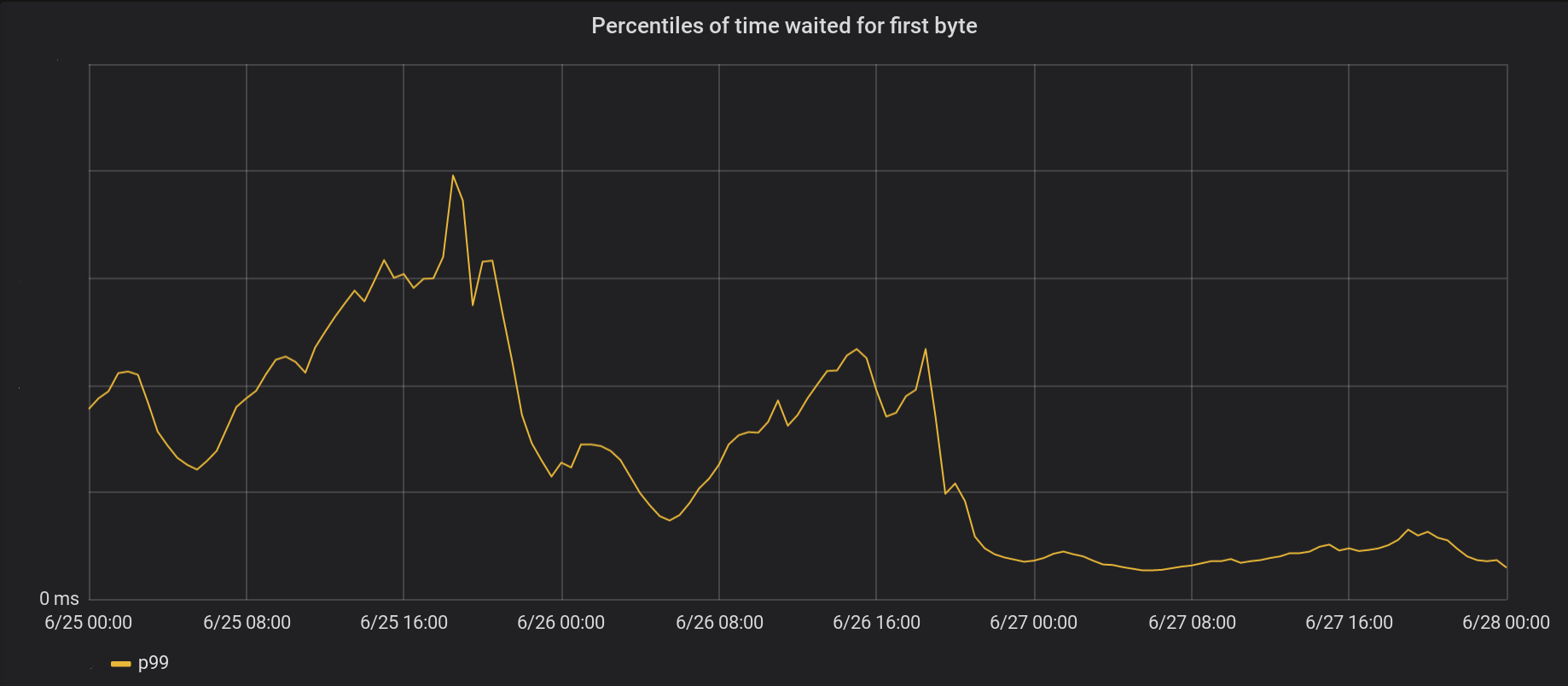
Le 26 juin, nous avons appliqué nos modifications dans 5 de nos datacenters les plus actifs, puis à tous datacenters le lendemain. Le pic global du TTFB p99 a été divisé par 6. Si on additionne le temps passé à traiter 8 millions de demandes par seconde, on économise 54 ans de temps d'attente par jour sur Internet.
Nous avons envoyé notre travail dans upstream. Les parties intéressées peuvent faire de même.
Notre gestion des boucles d'événements n'est pas encore complètement non bloquante. Nous bloquons notamment lorsque nous mettons un fichier en cache pour la première fois (open(O_CREAT) et rename()), ou lorsque nous effectuons des mises à jour de revalidation. Cependant, ce blocage est rare par rapport aux succès de cache. Nous envisagerons ultérieurement de les retirer de la boucle d'événements pour améliorer davantage notre latence p99.
Conclusion
NGINX est une plate-forme très performante, mais le fait de scaler des charges d'E/S extrêmement élevées sur Linux peut s'avérer difficile. En amont, NGINX peut décharger les lectures dans des threads séparés, mais, à notre échelle, il nous faut souvent aller un pas plus loin. Si vous aimez vous attaquer à des problèmes de rendement difficiles, postulez pour rejoindre notre équipe de San Francisco, Londres, Austin ou Champaign.