



Aujourd'hui, la plateforme Workers de Cloudflare est utilisée par plus d'un million de développeurs pour créer des applications full-stack sophistiquées, qui n'auraient pas été réalisables auparavant.
Bien sûr, Workers n'a pas commencé ainsi. La plateforme était, à l'origine, une annonce formulée un jour comme celui-ci, lors d'une Semaine anniversaire. Certes, elle ne disposait pas de toutes les fonctionnalités qu'elle propose aujourd'hui, mais si vous avez eu l'occasion d'essayer la solution Workers lors de son lancement, vous aurez eu le sentiment « qu'elle était différente, et qu'elle allait changer les choses. Soudainement, passer de rien du tout à une application mondiale entièrement évolutive ne demandait plus que quelques secondes, et non des heures, des jours, des semaines ou même des mois. Ce lancement marqua le début d'une nouvelle approche de la création d'applications.
Si vous vous êtes amusé à expérimenter l'IA générative, ces derniers mois, peut-être avez-vous ressenti la même chose. En interrogeant quelques amis et collègues, les instants auxquels nous avons vécu une « révélation » étaient légèrement différents, mais le sentiment général qui prévaut actuellement dans l'ensemble du secteur est unanime : cette innovation est différente et va changer les choses.
Aujourd'hui, nous sommes ravis de proposer une série d'annonces qui auront, nous le pensons, un impact similaire à celui de Workers sur l'avenir de l'informatique. Sans noyer davantage le poisson, les voici :
- Workers AI (anciennement connu sous le nom de Constellation), qui s'exécute sur des GPU (processeurs graphiques) NVIDIA sur le réseau mondial de Cloudflare, apporte le modèle serverless à l'IA : payez uniquement ce que vous consommez, consacrez moins de temps à votre infrastructure et plus de temps à votre application.
- Vectorize, notre base de données vectorielle, qui permet d'indexer et de stocker des vecteurs de manière simple, rapide et abordable, afin de soutenir les scénarios d'utilisation nécessitant non seulement un accès aux modèles en cours d'exécution, mais également à des données personnalisées.
- AI Gateway, qui fournit aux entreprises les outils indispensables pour assurer la mise en cache, la limitation du débit et l'observation de leurs déploiements d'IA, quel que soit l'endroit où ils s'exécutent.
Mais ce n'est pas tout.
Accomplir de grands projets est un sport d'équipe, et nous ne voulons pas le faire seuls. Comme pour la plupart de nos activités, nous nous appuyons sur les épaules de géants. Nous sommes ravis de nous associer à certains des plus grands acteurs du secteur : NVIDIA, Microsoft, Hugging Face et Meta.
Nos annonces aujourd'hui marquent le tout début du voyage de Cloudflare dans le domaine de l'IA, comme cela a été le cas pour Workers, il y a six ans de cela. Nous vous encourageons à vous plonger dans chacune de nos annonces aujourd'hui ; vous ne serez pas déçus ! Toutefois, nous souhaitions également prendre du recul et vous présenter notre vision plus large de l'IA, ainsi que la manière dont ces annonces s'y intègrent.
Inférence : l'avenir des charges de travail d'IA
L'IA comporte deux processus principaux : l'apprentissage et l'inférence.
L'apprentissage d'un modèle génératif d'IA est un processus de longue haleine (qui peut parfois demander des mois), à forte intensité de calcul, qui permet d'obtenir un modèle. Les charges de travail d'apprentissage sont donc idéalement adaptées à une exécution dans des emplacements traditionnels, dans le cloud centralisé. Compte tenu des récentes difficultés liées à l'obtention d'un accès durable aux GPU, qui ont conduit les entreprises à opter pour une approche multi-cloud, nous avons parlé du service essentiel que peut offrir R2 en éliminant les frais de trafic sortant, et ainsi, de permettre l'accès aux données d'apprentissage depuis n'importe quel cloud de traitement. Cependant, ce n'est pas ce dont nous voulons parler aujourd'hui.
Si l'apprentissage nécessite, dès le début, d'importantes ressources, la tâche de traitement la plus répandue liée à l'IA est l'inférence. Si vous avez récemment posé une question à ChatGPT, généré une image ou traduit un texte, vous avez exécuté une tâche d'inférence. Étant donné que l'inférence est requise à chaque invocation (plutôt qu'une fois seulement), nous nous attendons à ce que l'inférence devienne la charge de travail dominante dans le domaine de l'IA.
Si l'apprentissage est idéalement adapté à un cloud centralisé, quel est le meilleur endroit pour exécuter l'inférence ?
Le réseau - idéal pour l'inférence
La caractéristique principale du processus d'inférence est qu'en règle générale, un utilisateur en attend l'issue. En d'autres termes, il s'agit d'une tâche sensible à la latence.
On pourrait penser que le meilleur endroit pour exécuter une tâche sensible à la latence est l'appareil lui-même,et c'est peut-être le cas, dans certaines situations, mais certains problèmes demeurent. Tout d'abord, le matériel des appareils est loin d'être aussi puissant. L'autonomie de la batterie pose également problème.
En revanche, vous disposez d'une capacité de traitement dans un cloud centralisé. Contrairement aux appareils, le matériel mis en œuvre sur les sites de cloud centralisé regorge de puissance. Le problème, bien entendu, est qu'il se trouve à des centaines de millisecondes de l'utilisateur. Et parfois, il se trouve même au-delà des frontières, ce qui engendre encore d'autres difficultés.
Pour résumer, les appareils ne sont pas encore assez puissants, et le cloud centralisé est trop éloigné. Le réseau devient donc la pierre angulaire de l'inférence : peu éloigné, doté d'une puissance de calcul adéquate, il est idéalement adapté à la tâche.
Le premier cloud d'inférence, qui s'exécute sur Region : Earth
L'un des enseignements que nous avons tirés de la création de notre plateforme de développement est que l'exécution d'applications à l'échelle du réseau permet non seulement d'optimiser les performances et l'étendue (ce qui est évidemment un avantage appréciable en soi !), mais surtout, de créer un niveau d'abstraction permettant aux développeurs de progresser rapidement dans leur travail.
Workers AI pour l'inférence serverless
Avec l'annonce de Workers AI, nous présentons le premier cloud GPU serverless à son partenaire idéal – Region: Earth. Pas besoin d'expertise en matière d'apprentissage automatique, ni de fastidieuses recherches de GPU disponibles. Tout ce que vous avez à faire, c'est choisir l'un de nos modèles et vous lancer.
Nous avons longuement réfléchi à la conception de Workers AI, afin que le déploiement du modèle se déroule aussi facilement que possible.
Et si vous déployez des modèles en 2023, il y a de fortes chances que l'un d'entre eux soit un grand modèle de langage (LLM).
Vectorize pour... le stockage de vecteurs !
Pour construire un chatbot intégralement géré par IA, vous devez également pouvoir présenter une interface utilisateur à l'utilisateur final, analyser le corpus d'informations que vous souhaitez lui transmettre (par exemple, votre catalogue de produits), utiliser le modèle pour le convertir en données intégrées, puis stocker ces données quelque part. Jusqu'à aujourd'hui, nous proposions les produits nécessaires pour effectuer les deux premières opérations ; cependant, la dernière (le stockage des données intégrées) nécessite une solution unique : une base de données vectorielle.
Après avoir annoncé Workers, nous avions rapidement annoncé Workers KV ; il n'y a pas grand-chose que vous puissiez accomplir avec le traitement seul, sans disposer d'un accès aux données. Il en va de même pour l'IA : pour élaborer des scénarios d'utilisation pertinents de l'IA, vous devez permettre à l'IA d'accéder aux données. C'est alors qu'une base de données vectorielle entre en jeu, et c'est pour cette raison que nous sommes heureux d'annoncer aujourd'hui Vectorize, notre propre base de données vectorielle.
AI Gateway pour la mise en cache, la limitation du débit et la visibilité de vos déploiements d'IA
Chez Cloudflare, lorsque nous cherchons à améliorer quelque chose, la première étape consiste toujours à effectuer des mesures : si vous ne pouvez pas mesurer quelque chose, comment pouvez-vous espérer l'améliorer ? Lorsque nous avons entendu parler de clients qui peinaient à maîtriser les coûts de déploiement de l'IA, nous avons réfléchi à la manière dont nous allions aborder ce problème : d'abord en effectuant des mesures, puis en y apportant des améliorations.
AI Gateway vous aide à effectuer ces deux démarches !
Les capacités d'observation en temps réel de la solution permettent une gestion proactive, facilitant le contrôle, le débogage et la configuration précise des déploiements d'IA.Il est essentiel de l'utiliser pour la mise en cache, la limitation du débit et la surveillance des déploiements d'IA, afin d'optimiser les performances et de gérer efficacement les coûts.En mettant en cache les réponses d'IA fréquemment utilisées, AI Gateway réduit la latence et renforce la fiabilité du système ; la limitation du débit garantit, quant à elle, l'allocation efficace des ressources, atténuant les défis liés à l'envolée des coûts de l'IA.
Collaborer avec Meta pour intégrer Llama 2 à notre réseau mondial
Encore récemment, l'unique manière d'accéder à un grand modèle de langage (LLM) consistait à exécuter des appels à des modèles propriétaires. L'apprentissage des LLM représente un investissement considérable, en termes de temps, de traitement et de ressources financières, et n'est donc pas à la portée de la plupart des développeurs. Le lancement par Meta de Llama 2, un LLM open source, constitue une évolution majeure, en permettant aux développeurs d'exécuter et de déployer leurs propres LLM. À un détail près, bien sûr : cela nécessite toujours d'avoir accès à un GPU.
En proposant Llama 2 dans le catalogue de Workers AI, nous espérons permettre à tous les développeurs d'accéder à un LLM, sans configuration préalable.
L'existence d'un modèle en cours d'exécution n'est, bien entendu, qu'une des composantes d'une application basée sur l'IA.
Utiliser ONNX Runtime pour permettre aux développeurs d'évoluer avec fluidité du cloud vers la périphérie et les appareils
Bien que la périphérie du réseau soit l'emplacement optimal pour résoudre un grand nombre de ces problèmes, nous nous attendons à ce que les applications continuent d'être déployées ailleurs sur le spectre qu'offrent les appareils, la périphérie et le cloud centralisé.
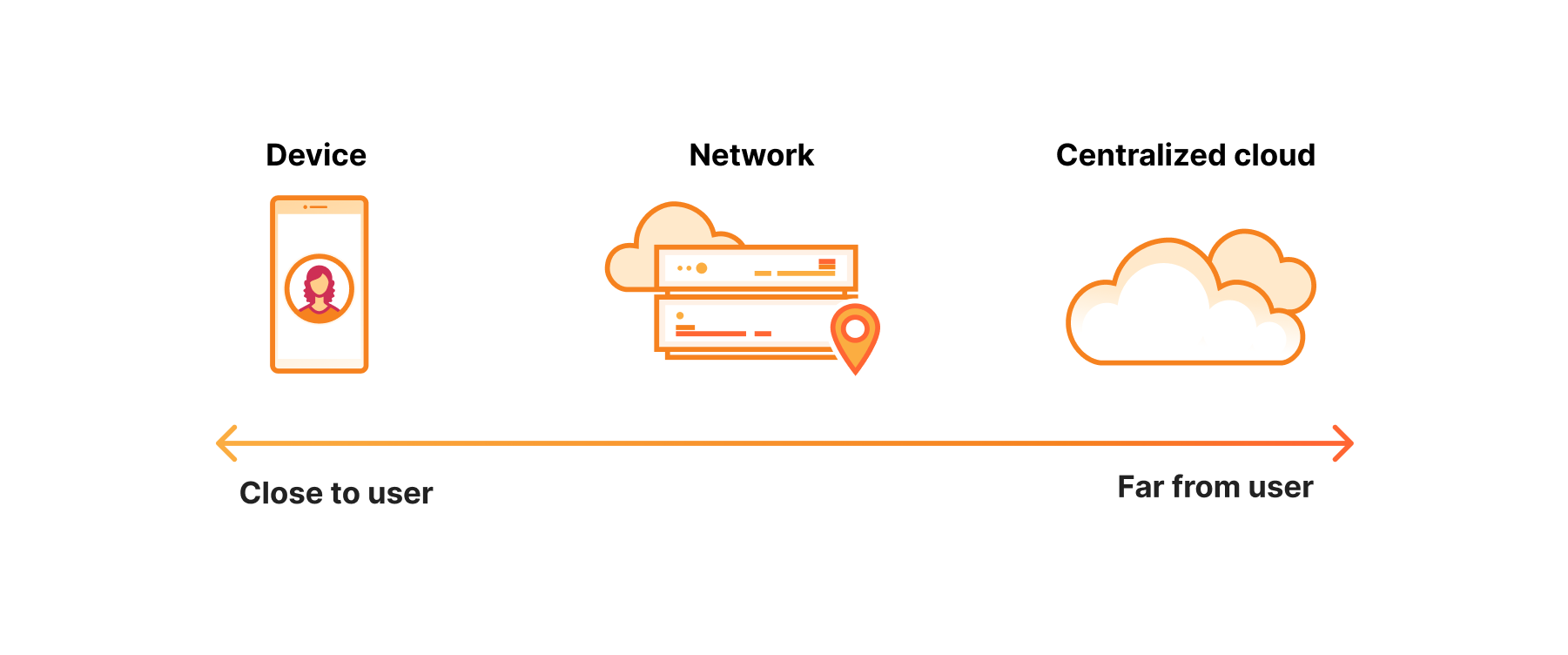
Prenons l'exemple des voitures autonomes : lorsque vous prenez des décisions où chaque milliseconde compte, ces décisions doivent être prises sur l'appareil. À l'inverse, si vous cherchez à exécuter des versions de modèles comportant des centaines de milliards de paramètres, le cloud centralisé sera mieux adapté à votre charge de travail.
La question qui se pose alors est la suivante : comment évoluer facilement entre ces différents emplacements ?
Depuis notre première version de Constellation (aujourd'hui appelé Workers AI), une technologie qui nous a particulièrement enthousiasmés est ONNX Runtime. ONNX Runtime crée un environnement standardisé pour l'exécution des modèles, permettant ainsi d'exécuter différents modèles dans différents emplacements.
Nous avons déjà expliqué que la périphérie est un emplacement idéal pour l'exécution de l'inférence elle-même, mais elle offre également une excellente couche de routage en contribuant à guider efficacement les charges de travail sur les trois emplacements, en fonction du scénario d'utilisation et des aspects que vous cherchez à optimiser – qu'il s'agisse de la latence, de la précision, du coût, de la conformité ou de la confidentialité.
Partenariat avec Hugging Face pour fournir des modèles optimisés, instantanément accessibles
Bien évidemment, la meilleure aide que nous puissions offrir aux développeurs consiste à les soutenir dans leur travail actuel ; c'est pourquoi nous nous associons à Hugging Face pour apporter l'inférence serverless aux modèles disponibles, là où les développeurs les explorent.
Partenariat avec Databricks pour créer des modèles d'IA
En collaboration avec Databricks, nous allons apporter la puissance de MLflow aux scientifiques et ingénieurs des données. MLflow est une plateforme open source qui permet de gérer l'intégralité du cycle de vie de l'apprentissage automatique ; ce partenariat permettra aux utilisateurs de déployer et de gérer plus facilement des modèles d'apprentissage automatique à grande échelle. Grâce à ce partenariat, les développeurs créant des solutions avec Cloudflare Workers AI pourront tirer parti de modèles compatibles avec MLflow, afin de facilement leur déploiement sur le réseau mondial de Cloudflare. Les développeurs peuvent utiliser MLflow pour la création de packages, la mise en œuvre, le déploiement et le suivi efficace des modèles, directement sur la plateforme pour développeurs serverless de Cloudflare.
Une solution d'IA qui ne tient pas votre directeur des systèmes d'information, votre directeur financier ou votre directeur juridique éveillé la nuit
Les choses évoluent rapidement dans le domaine de l'IA, et il est important de donner aux développeurs les outils dont ils ont besoin pour progresser ; toutefois, il est difficile d'avancer rapidement lorsque certaines considérations importantes doivent être prises en compte :qu'en est-il de la conformité, des coûts, de la protection de la vie privée ?
L'IA respectueuse de la conformité
Même si la plupart d'entre nous préfèrent ne pas y réfléchir, l'IA et la résidence des données sont de plus en plus réglementées par les gouvernements. À l'heure où les gouvernements exigent que les données soient traitées localement ou que les données de leurs résidents soient stockées dans le pays, les entreprises doivent réfléchir à ce sujet dans le contexte de l'endroit où elles exécutent leurs charges de travail d'inférence. En ce qui concerne la latence, la périphérie du réseau permet de bénéficier d'une étendue maximale. En matière de conformité, la puissance qu'offrent un réseau qui s'étend à 300 villes et une solution telle que notre produit Data Localization Suite est de fournir la granularité indispensable à la localisation précise des déploiements d'IA.
L'IA à petit prix
Lorsque nous échangeons avec nombre de nos amis et collègues qui expérimentent l'IA, un sentiment semble se dégager : l'IA est coûteuse. Il est facile de laisser les coûts vous échapper avant même d'avoir mis votre application en production ou d'en avoir extrait une quelconque valeur.L'objectif de notre plateforme d'IA est de rendre les coûts abordables, mais surtout, de vous facturer uniquement ce que vous consommez. Que vous utilisiez directement Workers AI ou notre solution AI Gateway, nous voulons vous fournir la visibilité et les outils nécessaires pour éviter que les dépenses liées à l'IA ne vous échappent.
Une IA respectueuse de la confidentialité
Si vous placez l'IA au cœur de vos expériences client et vos activités opérationnelles, vous voulez avoir l'assurance que toutes les données qui transitent par celle-ci sont en de bonnes mains. Comme cela a toujours été le cas avec Cloudflare, nous adoptons une approche privilégiant la protection de la confidentialité. Nous pouvons assurer à nos clients que nous n'utiliserons pas les données de clients transitant par Cloudflare pour l'inférence en vue de former de grands modèles de langage.
Non, mais vraiment - ce n'est que le commencement !
L'IA n'en est qu'à ses balbutiements, et nous pouvons nous attendre à vivre une sacrée aventure !Tandis que nous continuons à dévoiler les avantages qu'offre cette technologie, nous ne pouvons nous empêcher d'éprouver un sentiment d'admiration et d'émerveillement face aux infinies possibilités que nous réserve l'avenir. Qu'il s'agisse de révolutionner les soins de santé ou de transformer notre façon de travailler, l'IA est prête à changer la donne de manières que nous n'aurions jamais imaginées. Alors, attachez vos ceintures, car l'avenir de l'IA est plus prometteur que jamais – et nous sommes impatients de découvrir ce qui nous attend ensuite !
Ce message de clôture a beau avoir été généré par l'IA, le sentiment est sincère – ce n'est que le commencement, et nous sommes impatients de découvrir ce que vous allez développer.