

Aux échelles opérationnelles de grande ampleur, l'adressage IP constitue un frein à l'innovation en matière de services orientés réseau et web. Lors de chaque modification architecturale, de même qu'aux premiers pas de la conception de nouveaux systèmes, le premier ensemble de questions que nous nous voyons contraints de nous poser est le suivant :
- Quel bloc d'adresses IP allons-nous ou pouvons-nous utiliser ?
- Disposons-nous de suffisamment d'adresses en IPv4 ? Dans le cas contraire, où et comment allons-nous en acquérir d'autres ?
- Comment allons-nous utiliser les adresses en IPv6 ? Ce schéma d’utilisation affectera-t-il d'autres usages de l'IPv6 ?
- Enfin, que devons-nous soigneusement prévoir en termes de plans, de contrôles, de temps et d'effectifs pour la migration ?
Marquer une pause dans le processus de développement afin de se préoccuper du sujet des adresses IP coûte du temps, de l'argent et des ressources. Ce constat peut paraître surprenant, compte tenu du caractère visionnaire et résilient de l'avènement du format IP, il y a plus de 40 ans. De par leur conception même, les adresses IP devraient former le dernier maillon de la chaîne d'éléments dont un réseau donné doit se soucier. Toutefois, si Internet a bien révélé quelque chose, il s'agit bien du fait que les fragilités de petite taille ou censément sans importance (souvent invisibles ou impossibles à déceler au moment de la conception) finissent toujours par apparaître à échelle suffisante.
L'une des choses dont nous sommes sûrs, toutefois, c'est que la « multiplication des adresses » ne devrait jamais être la réponse. En IPv4, ce type de raisonnement ne peut conduire qu'à leur raréfaction et à la flambée des prix du marché. Le format IPv6 se révèle absolument nécessaire, mais ne constitue qu'une partie de la solution. Ainsi, en IPv6, les bonnes pratiques stipulent que la plus petite attribution, uniquement réservée à l'usage personnel, est /56, c'est-à-dire 272 ou près de 4 722 000 000 000 000 000 000 adresses. Personnellement, je suis incapable d'appréhender un nombre aussi grand et de travailler autour. Et vous ?
Dans cet article de blog, nous expliquerons pourquoi l'adresse IP représente un problème pour les services web, ainsi que les causes sous-jacentes à ce problème, avant de décrire une solution innovante que nous nommons « agilité en matière d'adressage », en plus des leçons que nous avons apprises. La meilleure partie de cette approche peut constituer la variété de nouveaux systèmes et d'architectures permise par l'agilité en matière d'adressage. Vous trouverez l'intégralité des détails à ce sujet dans notre récent article publié dans l'ACM SIGCOMM 2021. À titre d'aperçu, voici un résumé des éléments que nous avons appris :

C'est vrai ! Il n'existe aucune limite au nombre de noms susceptibles d'apparaître sur une adresse donnée. L'adresse de n'importe quel nom peut changer à chaque nouvelle requête, et ce n'importe où. De même, les adresses peuvent être modifiées pour n'importe quelle raison, qu'il s'agisse de la fourniture d'un service, d'une politique, d'une évaluation de performances ou de tout autre cas restant encore à rencontrer…
Vous trouverez ci-dessous une explication des principes à l'œuvre derrière l'ensemble de ces réalisations, du cheminement de notre raisonnement en la matière et des raisons pour lesquelles ces leçons importent aux services HTTP et TLS de toutes tailles. Le résultat clé sur lequel nous bâtissons l'ensemble de notre réflexion est le suivant : à l'instar du système postal mondial, les adresses suivant la conception du protocole Internet (IP, Internet Protocol) n'ont jamais eu, ne devraient et ne devront jamais avoir besoin de représenter des noms. Pourtant, nous traitons parfois simplement ces dernières comme si c'était le cas. À la place, cette étude montre que tous les noms devraient partager l'ensemble de leurs adresses, un ensemble donné d'adresses, voire une seule adresse.
Le corset constitue une gaine, mais aussi un point d'étranglement
Des conventions remontant à plusieurs décennies relient artificiellement les adresses IP aux noms et aux ressources. Il s'agit là d'un constat compréhensible, car l'architecture et la partie logicielle qui soutiennent Internet sont issues d'une conception au sein de laquelle un ordinateur disposait d'un nom et (le plus souvent) d'une carte d'interface réseau. Il serait donc naturel que le réseau Internet évolue de telle façon qu'une adresse IP donnée soit liée à des noms et des processus logiciels.
Ces liaisons IP n'ont que peu d'impact sur les clients finaux et les opérateurs réseau, qui présentent de faibles besoins en matière de noms et encore plus faibles en termes de processus d'écoute. Toutefois, les conventions liées aux noms et aux processus créent de fortes limitations pour l'ensemble des fournisseurs d'hébergement, de distribution et de services liés au contenu. Une fois assignées à des noms, des interfaces et des ports, les adresses deviennent par nature statiques et toute modification de ces dernières nécessite des efforts, de la planification et de l'attention, si tant est qu'une telle modification soit même possible.
Le « corset », ou plutôt le « carcan », de l'adressage IP a permis le développement d'Internet, mais à l'instar du TCP pour les protocoles de transport et du HTTP pour les protocoles d'application, le protocole IP est devenu un frein à l'innovation. Cette idée est représentée par la figure ci-dessous, sur laquelle nous pouvons constater l'établissement de relations transitives entre des liaisons de communication (avec des noms) et des liaisons de connexion (avec des interfaces et des sockets) autrement distinctes.
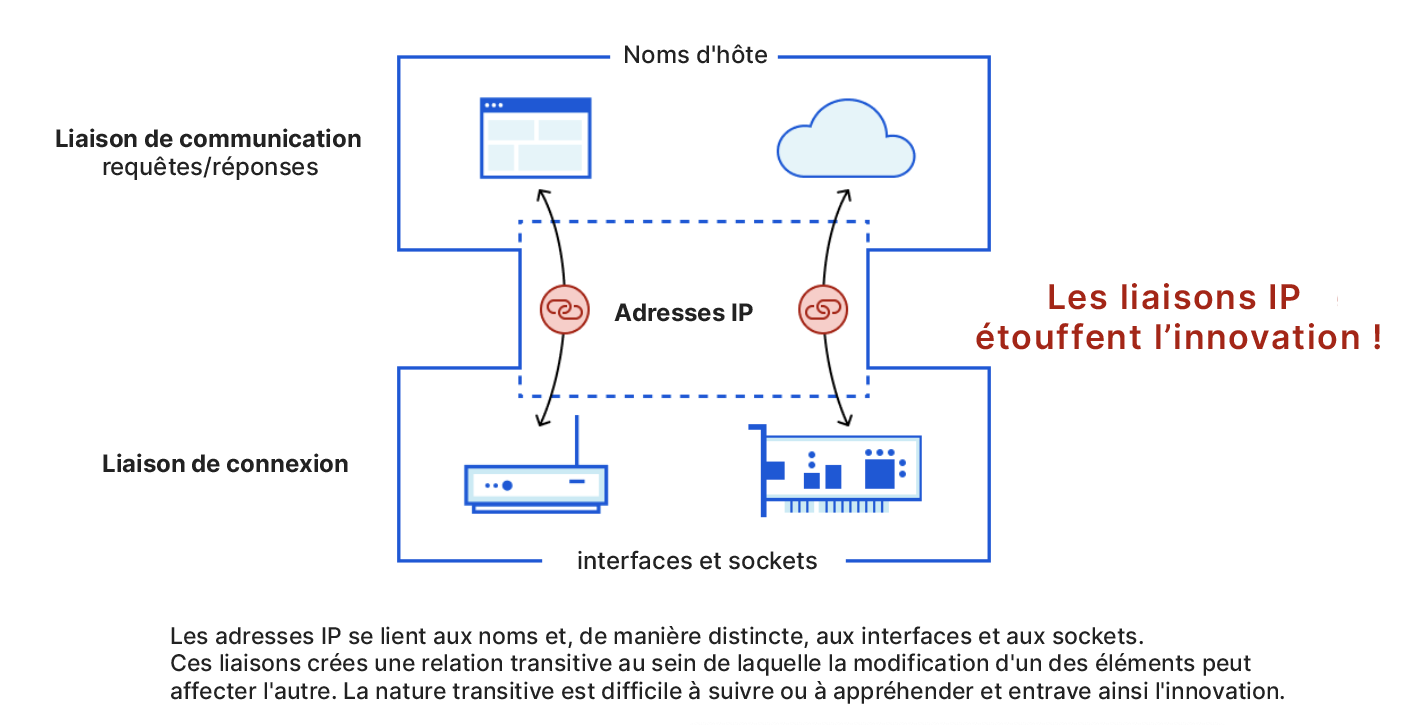
Le verrouillage transitif se révèle difficile à briser, car la modification d'un des deux éléments peut affecter l'autre. En outre, les fournisseurs de services utilisent souvent des adresses IP pour représenter des politiques et de niveaux de service qui existent par eux-mêmes, indépendamment des noms. En définitive, les liaisons IP constituent un nouvel élément à prendre en compte, malgré leur absence de finalité apparente.
Présentons la question autrement. Lorsque l'on réfléchit à de nouvelles conceptions, de nouvelles architectures ou simplement de meilleurs moyens d'allocation des ressources, les premières questions à se poser ne devraient pas être « Quelles adresses IP allons-nous utiliser ? » ou « Disposons-nous des adresses IP pour faire ceci ? ». Ce type de questionnement et les réponses associées à ce dernier freinent le développement et l'innovation.
Nous avons remarqué que les liaisons IP n'étaient pas seulement artificielles, mais qu'elles se révélaient également incorrectes, du point de vue des RFC et des normes originelles. En fait, la notion même d'adresse IP en tant qu'élément de représentation de tout autre chose que l'accessibilité va à l'encontre de sa conception initiale. Dans les RFC originales et les documents connexes, les architectes se montrent explicites : « Une distinction doit être faite entre les noms, les adresses et les itinéraires. Un nom désigne l'élément que l'on observe. L'adresse indique à quel endroit cet élément se situe. L'itinéraire montre de quelle manière se rendre à cet endroit. » Toute association IP d'informations, telles que le SNI ou l'hôte HTTP, au sein de protocoles de couche supérieure constitue une infraction claire au principe de superposition des couches.
Bien entendu, aucun de nos travaux n'existe de manière isolée. Ils mettent toutefois un point final à un long processus d'évolution visant à découpler les adresses IP de leur utilisation conventionnelle, une évolution qui consiste en définitive à nous jucher sur les épaules de géants, c'est-à-dire à développer l'étendue de nos connaissances.
Une évolution issue du passé…
En nous retournant sur les 20 dernières années, on constate effectivement que cette quête d'agilité en matière d'adressage a cours depuis un certain temps, temps pendant lequel Cloudflare s'est profondément investie.
La liaison un-pour-un remontant à plusieurs décennies entre le protocole IP et les interfaces par carte réseau a été brisée pour la première fois il y a quelques années lorsque le projet Maglev de Google a associé la stratégie Equal Cost MultiPath (ECMP) à un hachage constant afin de disséminer le trafic issu d'une adresse IP « virtuelle » entre plusieurs serveurs. À titre d'anecdote, conformément aux RFC originaux du protocole Internet, cette utilisation du protocole IP est proscrite et ne recèle absolument rien de virtuel.
De nombreux systèmes similaires ont depuis émergé sur GitHub, Facebook et partout ailleurs, dont notre propre solution Unimog. Plus récemment, Cloudflare a conçu une nouvelle architecture programmable de type sockets nommée bpf_sk_lookup, afin de découpler les adresses IP des sockets et des processus.
Mais qu'en est-il des noms ? La valeur de « l'hébergement virtuel » a été établie en 1997 lorsque le protocole HTTP 1.1 a défini le champ de l'hôte comme obligatoire. Il s'agissait de la première reconnaissance officielle du fait que plusieurs noms pouvaient coexister sur une même adresse IP, un constat nécessairement reproduit par le protocole TLS dans le champ Indication du nom du serveur. Des impératifs absolus sont nécessaires en la matière, car le nombre de noms possibles est supérieur au nombre d'adresses IP.
… révèle un avenir empreint d'agilité
En perspective, la question de Shakespeare « Qu'y a-t-il dans un nom ? » se révèle particulièrement avisée. Si le réseau Internet pouvait parler, il pourrait s'exprimer en ces termes : « Ce nom par lequel nous caractérisons toute autre adresse se révélerait tout aussi accessible. »
Si Shakespeare s'était demandé à la place « Qu'y a-t-il dans une adresse ? », le réseau lui répondrait certainement de la même façon « Cette adresse par laquelle nous caractérisons tout autre nom se révélerait tout aussi accessible, elle aussi. »
Une forte implication ressort de la vérité de ces réponses : le mappage entre les noms et les adresses s'effectue point à point (any-to-any). Si ce constat est vrai, alors n'importe quelle adresse peut être utilisée pour joindre un nom, tant que ce nom est joignable à une adresse.
En fait, une version du format « plusieurs adresses pour un nom » est disponible depuis 1995 avec l'introduction de l'équilibrage de charge basé sur DNS. Alors pourquoi pas « toutes les adresses pour tous les noms » ou « n'importe quelle adresse à un moment donné pour l'ensemble des noms » ? Ou encore (comme nous allons bientôt le découvrir) « une adresse pour l'ensemble des noms » ! Mais discutons tout d'abord de la manière dont atteindre l'agilité en matière d'adressage.
Atteindre l'agilité en matière d'adressage : ignorer les noms et les politiques de mappage
La clé de l'agilité en matière d'adressage réside dans le DNS de référence, mais pas dans les mappages statiques « nom-IP » conservés au sein d'un enregistrement ou d'un tableau de correspondance quelconque. Considérez que, du point de vue de n'importe quel client, la liaison n'apparaît que « suite à une requête ». Pour l'ensemble des usages pratiques du mappage, la réponse à la requête représente le dernier moment possible où un nom peut être lié à une adresse au cours du cycle de vie d'une requête.
Ce constat conduit à l'observation suivante : les mappages de noms sont, en réalité, effectués au moment du retour de la réponse, pas au sein d'un enregistrement ou d'un fichier de zone quelconque. Il s'agit là d'une distinction subtile, mais importante. Les systèmes DNS d'aujourd'hui s'appuient sur un nom pour rechercher un ensemble d'adresses. Il leur arrive même parfois d'appliquer une politique pour décider quelles adresses spécifiques renvoyer. La figure ci-dessous illustre cette idée. Lorsqu'une requête arrive, une recherche révèle les adresses associées au nom, avant de renvoyer une ou plusieurs de ces adresses. Une politique (ou des filtres logiques) vient souvent s'ajouter à l'ensemble afin d'affiner la sélection des adresses, comme le niveau de service ou la couverture régionale (géolocalisation). Le détail important est le suivant : les adresses sont tout d'abord identifiées par un nom, les politiques ne s'appliquant qu'après l'identification.
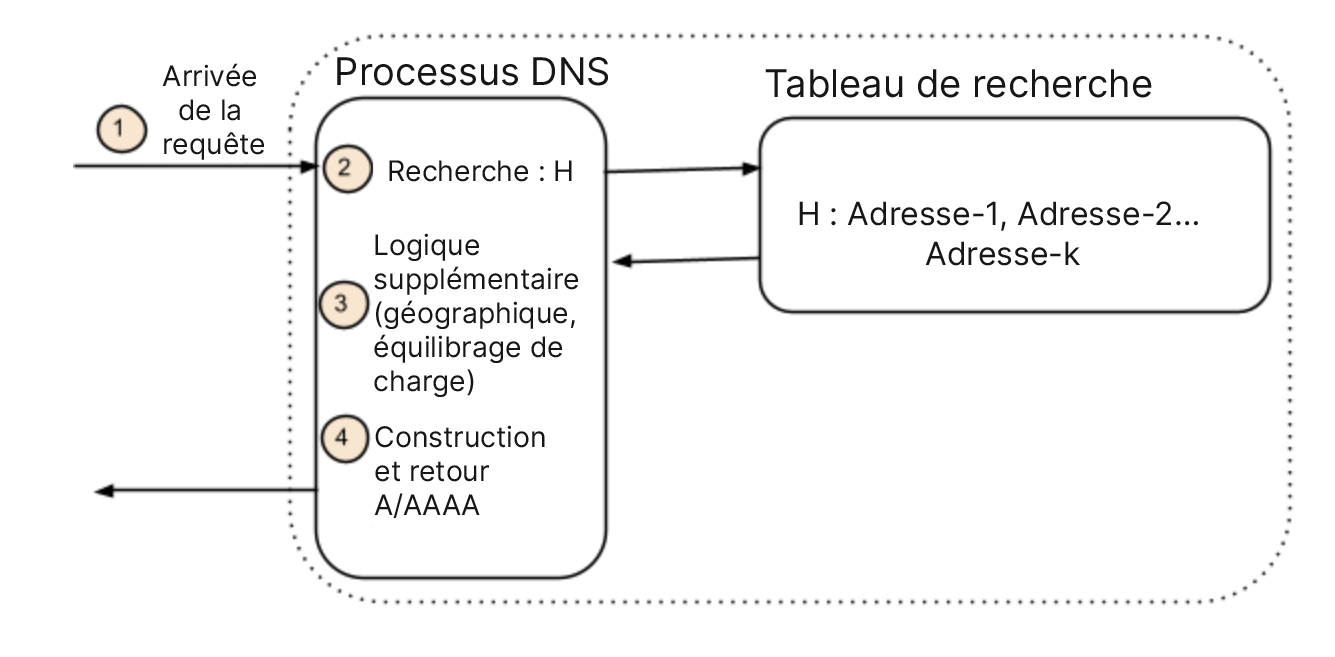
(a) DNS de référence conventionnel
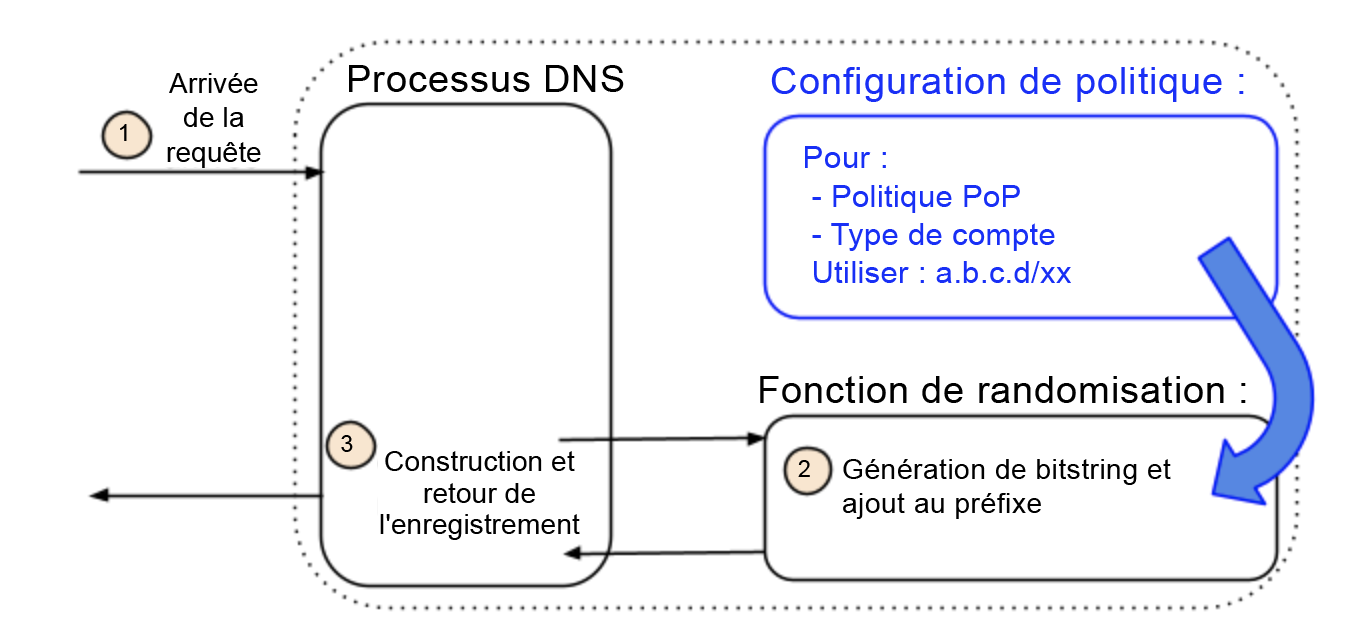
(b) agilité en matière d'adressage
L'agilité d'adressage s'atteint en inversant cette relation. Plutôt que de pré-assigner les adresses IP à un nom, notre architecture commence par une politique susceptible d'inclure un nom (ou, dans notre cas, de ne pas le faire). Une politique peut, par exemple, être représentée par divers attributs, comme l'emplacement et le type de compte, tout en ignorant le nom (comme nous l'avons fait pour notre déploiement). Les attributs identifient un ensemble d'adresses associées à cette politique. L'ensemble lui-même peut être isolé de cette politique ou comprendre des éléments partagés avec d'autres ensembles ou politiques. En outre, toutes les adresses de l'ensemble sont équivalentes. N'importe laquelle des adresses peut donc être renvoyée (ou sélectionnée au hasard) sans inspection du nom figurant dans la requête DNS.
Marquons une pause à présent, car ce cas de figure entraîne deux implications notables qui sortent du cadre des « réponses en fonction de la requête » :
i. Les adresses IP peuvent être, et sont, traitées et attribuées pendant l'exécution ou au moment de l'émission de la requête
ii. La durée de vie du mappage adresse IP-nom correspond au temps le plus long entre la durée de vie de la connexion qui s'ensuit et le TTL des caches en aval.
Ce résultat sans appel implique que la liaison elle-même est éphémère et peut être modifiée sans se soucier des considérations passées, comme les liaisons, les résolveurs, les clients ou les finalités. En outre, l'échelle ne constitue pas un problème, comme nous l'avons constaté après le déploiement de cette solution à la périphérie.
IPv6 : des habits neufs pour le même empereur
Avant de parler de notre déploiement, occupons-nous tout d'abord du « secret de polichinelle » du moment : l'adressage IPv6. la première chose à préciser ici est que tous (tous !) les éléments discutés ici dans le contexte de l'adressage IPv4 s'appliquent également à l'IPv6. Comme dans le système postal mondial, les adresses restent des adresses, peu importe qu'elles soient situées au Canada, au Cambodge, au Cameroun, au Chili ou en Chine, et ce constat inclut leur nature relativement statique et inflexible.
Malgré cette équivalence, la question la plus évidente demeure : les raisons qui sous-tendent les recherches en matière d'agilité d'adressage sont-elles toutes satisfaites par le simple fait du passage au protocole IPv6 ? Aussi contre-intuitive qu'elle puisse être, cette réponse se solde inévitablement par un « Non ! » définitif et absolu. L'adressage IPv6 peut atténuer le phénomène d'épuisement des adresses, au moins pendant l'existence de toutes les personnes en vie à l'heure actuelle, mais l'abondance de préfixes et d'adresses en IPv6 complique le raisonnement autour des liens de ce protocole avec les noms et les ressources.
L'abondance d'adresses IP en IPv6 engendre aussi un risque d'inefficacité, car les opérateurs peuvent tirer avantage de la longueur du bit et de la grande taille des préfixes pour intégrer de la signification au sein des adresses IP. Il s'agit là d'une puissante fonctionnalité du protocole IPv6, mais cette dernière implique également qu'un grand nombre d'adresses sous un préfixe donné resteront inutilisées.
Pour être précis, Cloudflare constitue sans aucun doute l'un des plus grands défenseurs de l'IPv6, et ce pour de bonnes raisons, notamment l'assurance de longévité offerte par l'abondance d'adresses. Toutefois, le protocole IPv6 ne modifie que très peu la manière dont les adresses sont liées aux noms et aux ressources, tandis que l'agilité en matière d'adressage permet de garantir flexibilité et réactivité aux adresses pendant toute leur durée de vie.
Remarque en passant : l'agilité concerne tout le monde
Un dernier commentaire sur l'architecture et son caractère transférable : l'agilité en matière d'adressage est utilisable, et même souhaitable, pour n'importe quel service reposant sur un DNS de référence. Les autres fournisseurs de services orientés contenu sont des prétendants évidents en la matière, mais c'est également vrai pour de plus petits opérateurs. Les universités, les entreprises et les gouvernements ne constituent que quelques exemples des organisations susceptibles d'exécuter leurs propres services de référence. Tant que les opérateurs peuvent accepter les connexions sur les adresses IP renvoyées, nous sommes tous des bénéficiaires potentiels de l'agilité en matière d'adressage.
Des adresses randomisées en fonction d'une politique, à grande échelle
Nous travaillons depuis juin 2020 sur le concept d'agilité d'adressage en périphérie de réseau, avec le trafic de production, selon les modalités suivantes :
- Plus de 20 millions de noms d'hôte et de services.
- Tous les datacenters sont situés au Canada (afin de toucher un échantillon de population raisonnable et plusieurs fuseaux horaires).
- /20 (4 096 adresses) en IPv4 et /44 en IPv6.
- /24 (256 adresses) en IPv4 de janvier 2021 à juin 2021.
- Nous générons pour chaque requête une partie hôte aléatoire au sein du préfixe.
Après tout, le test d'agilité définitif est à son plus extrême lorsqu'une adresse aléatoire est générée pour chaque requête entrant sur nos serveurs. Nous avons ensuite décidé de tester véritablement cette idée. En juin 2021, nous avons procédé au sein de notre datacenter de Montréal (et très vite après dans celui de Toronto) au mappage de l'ensemble des zones (plus de 20 millions) vers une adresse unique.
Sur la période d'une année, chaque requête de domaine captée par la politique a reçu en réponse une adresse sélectionnée au hasard dans un ensemble ne comprenant que 4 096 adresses au départ, puis 256, puis une. En interne, nous nommons « Ao1 » l'ensemble d'adresses ne comprenant qu'une seule adresse, mais nous reviendrons à ce point par la suite.
La mesure du succès : « Circulez, il n'y a rien à voir »
Nos lecteurs se posent peut-être un certain nombre de questions silencieusement :
- Qu'est-ce que cette fonctionnalité a brisé sur Internet ?
- Quel effet cette fonctionnalité a-t-elle eu sur les systèmes Cloudflare ?
- Que pourrais-je constater si je me lançais dans l'aventure ?
La réponse courte à chaque question ci-dessus est la suivante : rien. Toutefois (et c'est important), la randomisation des adresses expose les faiblesses de conception des systèmes reposant sur Internet. Ces faiblesses se révèlent toujours, et pour chacune d'entre elles, car les concepteurs cherchent à attribuer du sens aux adresses IP, au-delà de la simple accessibilité. (Et chacune de ces faiblesses se voit déjouée par l'utilisation d'une adresse unique, comme l'ensemble « Ao1 ».)
Afin de mieux comprendre la nature de ce « rien », répondons aux questions ci-dessus, en commençant par le bas de la liste
Que pourrais-je constater si je me lançais dans l'aventure ?
La réponse est illustrée par l'exemple exposé dans la figure ci-dessous. Dans tous les datacenters compris dans le « Reste du monde », c'est-à-dire en dehors de notre secteur de déploiement, une requête de zone renvoie les mêmes adresses (comme celle du système Anycast mondial de Cloudflare). À l'inverse, chaque requête entrant dans un datacenter figurant au sein de la zone de déploiement reçoit une adresse aléatoire en réponse. Les commandes « dig » successives adressées à deux datacenters différents dans l'image ci-dessous illustrent ce phénomène.

Pour ceux qui s'interrogent sur le trafic de requêtes subséquent, oui, les serveurs sont configurés pour accepter les requêtes de connexion de n'importe lequel des plus de 20 millions de domaines, sur l'ensemble des adresses figurant dans le pool d'adresses.
Très bien, mais les systèmes environnants de Cloudflare ont certainement nécessité une modification, non ?
Non. Il s'agit d'une modification transparente et des plus simples à réaliser du pipeline de données du DNS de référence. Aucune modification des annonces de préfixe de routage n'a été nécessaire au niveau de BGP, de la protection contre les attaques DDoS, des équilibreurs de charge, du cache distribué, etc.
Un effet secondaire fascinant se dégage toutefois de l'ensemble. La randomisation est aux adresses IP ce qu'une bonne fonction de hachage est à une table de hachage : elle fait correspondre de manière équitable une entrée de taille arbitraire à un nombre fixe de sorties. L'effet peut être constaté en comparant les mesures de charge par adresse IP avant et après la randomisation, comme présentées sur les graphiques ci-dessous, aux données extraites de l'échantillon de 1 % des requêtes reçues dans un datacenter donné au cours d'une période de sept jours.
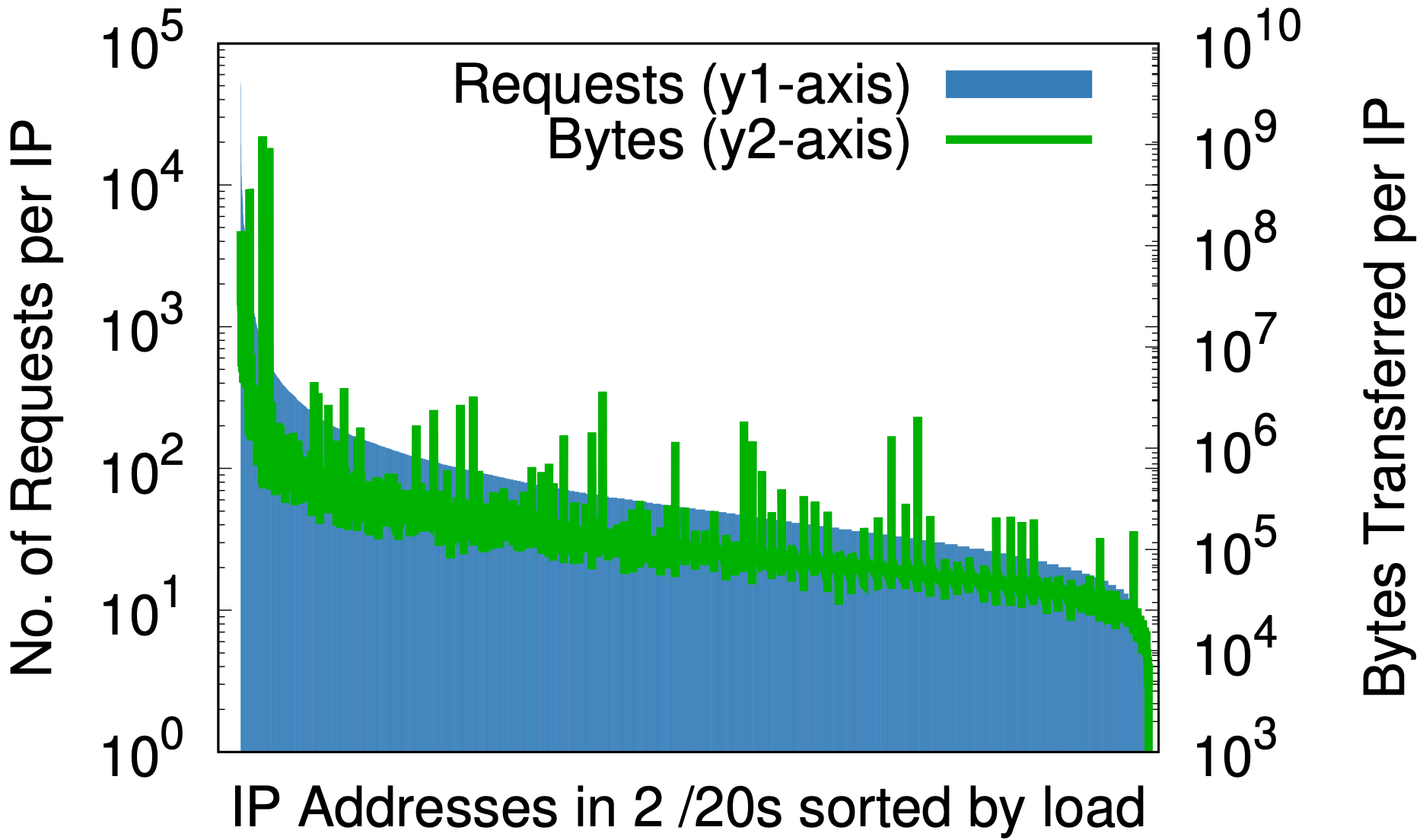
Avant l'agilité d'adressage
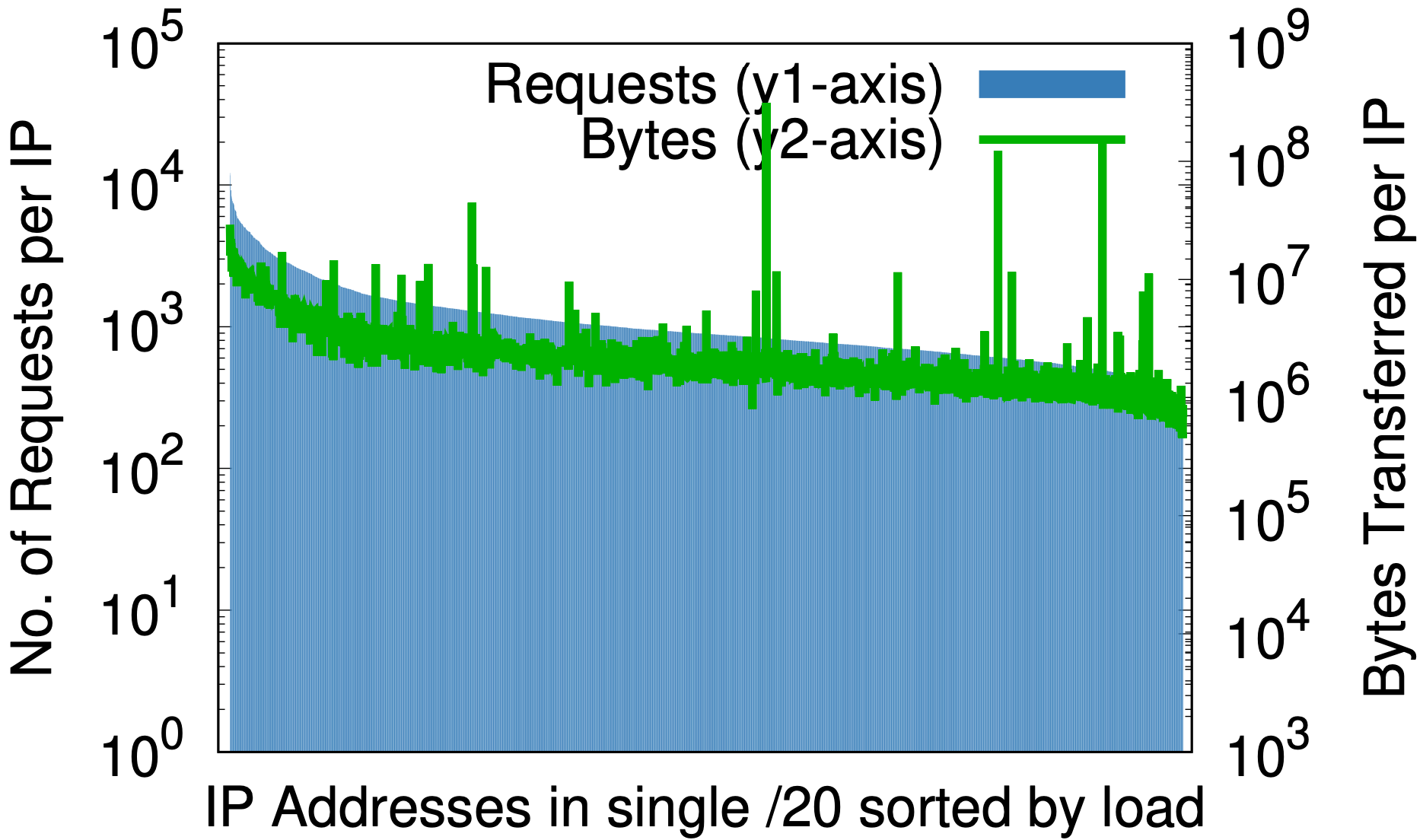
Randomisation sur masque /20
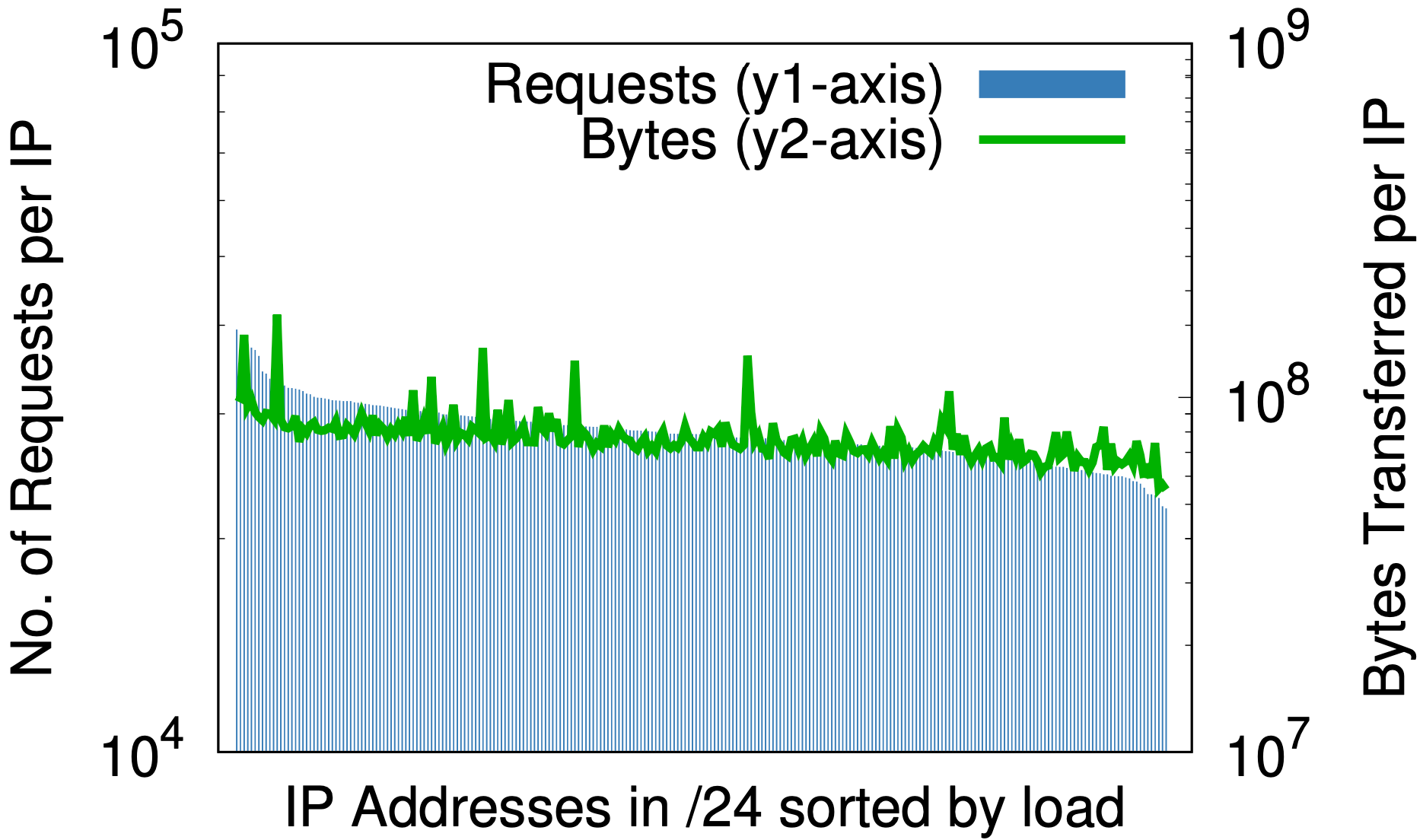
Randomisation sur masque /24
Avant la randomisation, et ce pour une petite partie de l'espace IP Cloudflare uniquement, (a) la différence entre le plus grand nombre et le plus petit nombre de requêtes par adresse IP (l'axe y1 à gauche) est de trois ordres de grandeur. Réciproquement, le nombre d'octets par adresse IP (l'axe y2 à droite) est lui de presque six ordres de grandeur. Après la randomisation, (b) pour l'ensemble des domaines situés sur un masque /20 unique qui occupaient précédemment plusieurs masques /20, ces valeurs sont respectivement réduites à deux et trois ordres de grandeur. En continuant cette analyse pour le masque /24 (c), la randomisation à chaque requête de plus de 20 millions de zones sur 256 adresses réduit les différences de charge à de petits facteurs constants.
Cette notion pourrait se montrer importante pour n'importe quel fournisseur de service de contenu susceptible de réfléchir au provisionnement des ressources en fonction de l'adresse IP. Les prédictions a priori de charge générées par un client peuvent se révéler difficiles. Les graphiques ci-dessus constituent la preuve que le meilleur moyen d'avancer consiste à associer l'ensemble des adresses à l'ensemble des noms.
Mais cette façon de faire doit certainement briser quelque chose dans le réseau Internet au sens large ?
Une fois encore, la réponse est non ! Enfin, plus précisément : « Non, la randomisation ne brise rien… mais elle peut révéler les faiblesses des systèmes et de leur conception ».
Tous les systèmes susceptibles d'être affectés par la randomisation de l'adresse semblent partager un prérequis : l'adresse IP véhicule du sens, au-delà de la simple accessibilité. L'agilité en matière d'adressage conserve, voire restaure, la sémantique des adresses IP et l'architecture Internet fondamentale, mais elle fera tomber les systèmes logiciels qui tentent d'introduire du sens dans ces dernières.
Découvrons quelques exemples montrant pourquoi ces valeurs n'ont aucune importance, puis poursuivons par une petite modification de l'agilité en matière d'adressage permettant de circonvenir les faiblesses (grâce à l'utilisation d'une adresse IP unique) :
- La coalescence de connexions HTTP (Connection Coalescing) permet à un client de réutiliser des connexions existantes afin de demander des ressources depuis des origines différentes. Les clients tels que Firefox, qui autorisent cette technique lorsque l'autorité URI correspond à la connexion, restent non affectés. Toutefois, les clients qui nécessitent un hôte URI pour résoudre la même adresse IP que celle de la connexion échoueront.
- Les services non TLS ou basés sur HTTP peuvent être affectés. Un bon exemple est le SSH, qui conserve un mappage nom d'hôte-adresse IP dans ses known_hosts. Bien que compréhensible, cette association se révèle obsolète et déjà dépassée, de nombreux enregistrements DNS renvoyant à l'heure actuelle plus d'une adresse IP.
- Les certificats TLS non SNI nécessitent une adresse IP dédiée. Les fournisseurs se voient contraints de facturer un supplément, car chaque adresse ne peut prendre en charge qu'un unique certificat sans SNI. Indépendamment des adresses IP, le plus gros problème ici réside dans l'utilisation du TLS sans SNI. Nous avons déployé de nombreux efforts pour comprendre l'approche non SNI, dans l'espoir de mettre un terme à ce triste héritage.
- Les protections contre les attaques DDoS qui s'appuient sur les adresses IP de destination peuvent se voir entravées, dans un premier temps. Nous considérons que l'agilité en matière d'adressage se montre avantageuse pour deux raisons. En premier lieu, la randomisation des adresses IP permet de répartir la charge hostile sur l'ensemble des adresses utilisées, en se comportant ainsi effectivement comme un équilibreur de charge de couche 3. Deuxièmement, les mesures d'atténuation DoS reposent souvent sur la modification des adresses IP, une capacité inhérente au concept d'agilité d'adressage.
Tous pour sur un et un pour tous
Nous avons commencé avec plus de 20 millions de zones associées à des adresses figurant au sein d'un ensemble regroupant des dizaines de milliers d'adresses, avant de les diffuser avec succès depuis un ensemble de 4 096 adresses au sein d'un masque /20, puis de 256 adresses au sein d'un masque /24. Cette tendance soulève sans conteste la question suivante :
Si la randomisation fonctionne sur n adresses, alors pourquoi ne pas randomiser sur une adresse uniquement ?
Et en effet, pourquoi pas ? Souvenez-vous du commentaire ci-dessus au sujet de la randomisation sur plusieurs adresses IP comme étant l'équivalent d'une fonction de hachage parfaite au sein d'un tableau de hachage. L'avantage des structures de hachage bien conçues réside dans leur capacité à préserver leurs propriétés quelle que soit la taille de la structure, même si cette taille est égale à 1. Une telle réduction constituerait un véritable test des fondations sur lesquelles s'appuie l'agilité d'adressage.
Et c'est ce que nous avons fait. À partir d'un ensemble d'adresses sur masque /20, puis sur masque /24, puis, depuis juin 2021, d'un ensemble composé d'une seule adresse en masque /32 et son équivalent en /128 (ensemble Ao1). Le processus ne se contente pas de fonctionner. Il fonctionne vraiment. Les inquiétudes concernant l'exposition par la randomisation sont résolues par l'ensemble Ao1. Ainsi, les services non TLS ou non HTTP disposent, par exemple, d'une adresse IP fiable (ou du moins non randomisée, jusqu'à modification de la politique du nom). De même, la coalescence de connexions HTTP devient possible dans pratiquement tous les cas et, oui, nous avons constaté des niveaux accrus de coalescence lors de l'utilisation de l'ensemble Ao1.
Mais pourquoi existe-t-il autant d'adresses sous le protocole IPv6 ?
L'un des arguments en défaveur de la liaison à une adresse IPv6 unique réside dans l'absence de nécessité en la matière, car l'épuisement de ces adresses se révèle pour le moins improbable. Il s'agit là d'une position antérieure au CIDR que nous considérons, au mieux, bénigne et au pire, irresponsable. Comme nous l'avons mentionné plus haut, le nombre même d'adresses IPv6 complique le raisonnement autour de ces dernières. Plutôt que de nous demander pour quelle raison utiliser une adresse IPv6 unique, nous devrions nous demander : « Pourquoi pas ? »
Une telle utilisation soulève-t-elle des implications en amont ? Oui, ainsi que des opportunités !
L'ensemble Ao1 révèle une somme d'implications totalement différentes de la randomisation des adresses IP. Et ces implications nous ouvrent sans doute une fenêtre sur l'avenir du routage Internet et de l'accessibilité, en amplifiant les effets que les actions apparemment anodines pourraient avoir.
Pourquoi ? Le nombre de noms à longueur variable possible dans l'univers excédera toujours le nombre d'adresses à longueur fixe. Ainsi, conformément au principe des tiroirs, les adresses IP uniques doivent être partagées par plusieurs noms et un contenu différent issu de parties sans lien entre elles.
Les possibles effets d'amont amplifiés par l'ensemble Ao1 valent la peine d'être évoqués et sont décrits ci-dessous. Jusqu'ici, toutefois, nous n'avons constaté aucun de ces derniers dans nos évaluations, pas plus qu'ils ne sont apparus dans les communications avec les réseaux d'amont.
- Les erreurs de routage en amont sont immédiates et absolues Si l'intégralité du trafic arrive sur une adresse (ou un préfixe) unique, les erreurs de routage en amont affectent l'ensemble du contenu de manière égale. (C'est la raison pour laquelle Cloudflare renvoie deux adresses situées sur des plages non contiguës.) On notera, toutefois, que c'est également le cas du blocage de menaces.
- Les protections anti-DoS situées en amont pourraient être déclenchées. Il reste concevable que la concentration de requêtes et de trafic sur une adresse unique puisse être perçue comme une attaque DoS et déclenche les protections existantes situées en amont.
Dans les deux cas, les actions sont atténuées par la capacité du concept d'agilité d'adressage à modifier les adresses rapidement et en bloc. La prévention se révèle également possible, mais elle nécessite une communication et un discours ouverts.
Un dernier effet d'amont demeure :
- L'épuisement des ports en NAT IPv4 pourrait se voir accéléré, mais le problème est résolu par l'IPv6 ! Du point de vue du client, le nombre admissible de connexions simultanées vers une adresse donnée est plafonné par la taille du champ Port du protocole de transport (65K environ dans TCP, par exemple).
Il s'agissait ainsi d'un problème en TCP sur Linux jusqu'à une époque récente. (Voir ce commit et la rubrique SO_BIND_ADDRESS_NO_PORT dans la page de manuel ip(7).) Le problème demeure en UDP. En QUIC, les identifiants de connexion peuvent prévenir l'épuisement des ports, mais ils doivent être utilisés. Jusqu'ici, toutefois, nous n'avons pas pu observer de preuve qu'il s'agisse bien d'un problème.
Toutefois (et c'est là son plus grand avantage), il ne s'agit à notre connaissance que du seul risque associé à l'utilisation d'adresses uniques et ce dernier se voit immédiatement résolu par la migration vers l'IPv6. (Nous conseillons donc aux FAI et aux administrateurs réseau de ne plus hésiter et de mettre en œuvre le protocole IPv6 !)
Nous n'en sommes encore qu'au début !
Nous concluons ainsi cet exposé tel que nous l'avons commencé. Sans limite au nombre de noms sur une unique adresse IP et grâce à la capacité de modifier l'adresse à chaque requête, pour quelque raison que ce soit, que pourriez-vous développer ?

Nous n'en sommes véritablement qu'au début ! La flexibilité et l'évolutivité proposées par l'agilité d'adressage nous permet d'imaginer, de concevoir et de développer de nouveaux systèmes et de nouvelles architectures. Nous prévoyons, entre autres, une solution de détection et d'atténuation des fuites d'itinéraire BGP pour les systèmes Anycast et des plates-formes de mesure.
Vous trouverez plus de détails techniques sur l'ensemble de ce qui précède, ainsi que des remerciements envers les très nombreuses personnes qui nous ont permis de rendre ce concept possible, dans cet article et cette courte discussion. Même face à ces nouvelles possibilités, de nombreux défis restent à relever et de nombreuses questions en suspens, comprenant, sans s'y limiter, les suivantes :
- Quelles politiques peuvent être raisonnablement exprimées ou mises en œuvre ?
- Existe-t-il une syntaxe abstraite ou une grammaire à l'aide desquelles les exprimer ?
- Pouvons-nous utiliser des méthodes formelles et des mesures de vérification pour prévenir les politiques erronées ou contradictoires ?
L'agilité d'adresse concerne tout le monde et s'avère même nécessaire pour que ces idées puissent connaître une réussite plus large. N'hésitez pas à nous faire part de vos idées à l'adresse suivante : [email protected].
Pour les étudiants inscrits à un programme de doctorat ou à un programme de recherche équivalent et à la recherche d'un stage pour 2022 aux États-Unis ou au Canada, ainsi que dans l'UE ou au Royaume-Uni, cliquez sur les liens correspondants.
Si vous souhaitez contribuer à d'autres projets tels que celui-ci ou aider Cloudflare à développer ses systèmes de gestion des adresses et du trafic, notre équipe d'ingénierie de l'adressage (Addressing Engineering) est à la recherche de personnel !