


El 1 de abril de 2018, Cloudflare anunció el solucionador de DNS público 1.1.1.1. A lo largo de los años, hemos añadido distintas funcionalidades a la plataforma como la página para la resolución de problemas, la depuración de caché global, 0 TTL para zonas en Cloudflare, Upstream TLS y 1.1.1.1 for Families. En esta publicación, nos gustaría compartir algunos detalles y cambios que estamos implementando en segundo plano.
Cuando se inició el proyecto, elegimos Knot Resolver como solucionador de DNS. Empezamos a desarrollar todo un sistema a partir de esta implementación para que se adaptara al caso de uso de Cloudflare. Disponer de un solucionador de DNS recursivo maduro, así como de un validador de registros DNSSEC, era fantástico porque podíamos dedicar nuestro tiempo a otras tareas sin tener que preocuparnos por la implementación del protocolo DNS.
Knot Resolver es bastante flexible gracias a su sistema de plugins basado en el lenguaje de programación Lua. Pudimos ampliar rápidamente la funcionalidad básica para admitir diversas funciones del producto, como DoH/DoT, registro, mitigación de ataques basada en BPF, uso compartido de caché y anulación de la lógica de iteración. Sin embargo, a medida que aumentaba el tráfico, nos topamos con ciertas limitaciones.
Lecciones aprendidas
Antes de profundizar más, analicemos la visión de conjunto de una configuración simplificada de un centro de datos de Cloudflare, que podría ayudarnos a entender lo que veremos más adelante. En Cloudflare, todos los servidores son idénticos. La pila de software que se ejecuta en un servidor es exactamente la misma que en otro, solo que la configuración puede ser diferente. Esta decisión de arquitectura reduce considerablemente la complejidad del mantenimiento.

El solucionador se ejecuta como un proceso daemon, kresd, y no trabaja solo. Unimog realiza el equilibrio de carga de las solicitudes, en concreto las de DNS, que se dirigen a los servidores del centro de datos. Las solicitudes DoH se terminan en nuestro terminador TLS. Quicksilver puede distribuir configuraciones y otros pequeños conjuntos de datos a todo el mundo en cuestión de segundos. Toda esta ayuda permite al solucionador concentrarse en su propio objetivo, la resolución de consultas DNS, y despreocuparse de los detalles del protocolo de transporte. Ahora hablemos de tres áreas clave que queríamos mejorar: el bloqueo de E/S en los plugins, un uso más eficiente del espacio en caché y el aislamiento de plugins.
Callbacks que bloquean el event loop
Knot Resolver tiene un sistema de plugins muy flexible que permite ampliar su funcionalidad básica. Los plugins se denominan módulos y se basan en callbacks. En determinados momentos del procesamiento de solicitudes, estas callbacks se invocarán con el contexto de consulta actual. Esta acción concederá a un módulo la capacidad de inspeccionar, modificar e incluso generar solicitudes/respuestas. Por diseño, se supone que estas callbacks son sencillas con el fin de evitar bloquear el event loop subyacente. Esto es importante porque el servicio es monoproceso, y el event loop se encarga de servir muchas solicitudes al mismo tiempo. Por tanto, si una solicitud está siendo procesada por una callback, las demás solicitudes tendrán que esperar a ser procesadas hasta que la callback termine.
La configuración nos funcionó bastante bien hasta que necesitamos realizar operaciones bloqueantes, por ejemplo, para extraer datos de Quicksilver antes de responder al cliente.
Eficiencia de la caché
Como las solicitudes de un dominio pueden llegar a cualquier nodo de un centro de datos, sería excesivo resolver repetidamente una consulta cuando otro nodo ya tiene la respuesta. De manera intuitiva, la latencia podría mejorar si la caché se pudiera compartir entre los servidores, por lo que creamos un módulo de caché que realizaba la difusión múltiple de las entradas de caché recién añadidas. Los nodos del mismo centro de datos se podían suscribir a los eventos y actualizar su caché local.
La implementación por defecto de la caché en Knot Resolver es LMDB. Es rápida y fiable para implementaciones pequeñas y medianas. Pero en nuestro caso, la expiración de caché pronto se convirtió en un problema. La propia caché no realiza ningún seguimiento del tiempo de vida (TTL), popularidad, etc. Cuando está llena, simplemente borra todas las entradas y vuelve a empezar. Escenarios como la enumeración de zonas podrían llenar la caché con datos que es poco probable que se recuperen más tarde.
Además, nuestro módulo de caché multidifusión lo empeoró al amplificar los datos menos útiles a todos los nodos, y los llevó a la marca de agua alta de la caché al mismo tiempo. Fue entonces cuando observamos un pico de latencia porque todos los nodos abandonaron la caché y empezaron de nuevo más o menos al mismo tiempo.
Aislamiento de módulos
Al aumentar la lista de módulos Lua, la depuración de problemas era cada vez más difícil. La razón es que todos los módulos comparten un único estado Lua, por lo que un módulo que se comportara de manera errónea podría afectar a otro. Por ejemplo, cuando algo iba mal dentro del estado Lua, como tener demasiadas corrutinas o falta de memoria, teníamos suerte si el programa simplemente se bloqueaba, pero costaba leer los seguimientos de la pila resultantes. También es difícil parar forzosamente, o actualizar, un módulo en ejecución, ya que no solo tiene estado en el entorno de ejecución de Lua, sino también FFI, por lo que la seguridad de la memoria no está garantizada.
¡Hola, BigPineapple!
No encontramos ningún software existente que cumpliera nuestros requisitos un tanto especiales, así que al final empezamos nuestro propio desarrollo. El primer intento fue encapsular el núcleo de Knot Resolver con un servicio ligero escrito en Rust (edgedns modificado).
No fue fácil debido a la constante conversión entre los tipos de almacenamiento y C/FFI, y otras peculiaridades (por ejemplo, para buscar registros en la caché, la interfaz ABI espera que los registros devueltos sean inmutables hasta la siguiente llamada o el final de la transacción de lectura). Sin embargo, aprendimos mucho al intentar implementar este tipo de funcionalidad dividida en la que el host (el servicio) proporciona algunos recursos al huésped (la biblioteca principal del solucionador), y en cómo podríamos mejorar esa interfaz.
En las iteraciones posteriores, sustituimos toda la biblioteca recursiva por una nueva basada en un entorno de ejecución asíncrono. Añadimos un sistema de módulos rediseñado, reescribiendo el servicio en Rust con el tiempo conforme sustituíamos más y más componentes. Ese entorno de ejecución asíncrono era tokio, que ofrecía una interfaz de grupo de subprocesos para ejecutar tareas bloqueantes y no bloqueantes, así como un buen ecosistema para trabajar con otras librerías de Rust (crates).
Después, como los future combinators se volvieron tediosos, empezamos a convertirlo todo a la sintaxis async/await. Esto fue antes de la función async/await que se incorporó a Rust 1.39, lo que nos llevó a utilizar nightly (Rust beta) durante un tiempo, con algunas dificultades. Cuando la función async/await se estabilizó, nos permitió escribir nuestra rutina de procesamiento de solicitudes de forma ergonómica, similar a Go.
Todas las tareas se pueden ejecutar de forma simultánea, y algunas de las más difíciles de E/S se pueden dividir en grupos más pequeños, para beneficiarse de una gestión de subprocesos más eficiente. Como el entorno de ejecución ejecuta las tareas en un grupo de subprocesos, en lugar de en un único subproceso, también se beneficia del algoritmo "work stealing". De este modo, evitamos un problema que teníamos antes, en el que una sola solicitud que tardaba mucho tiempo en procesarse, bloqueaba todas las demás solicitudes en el event loop.
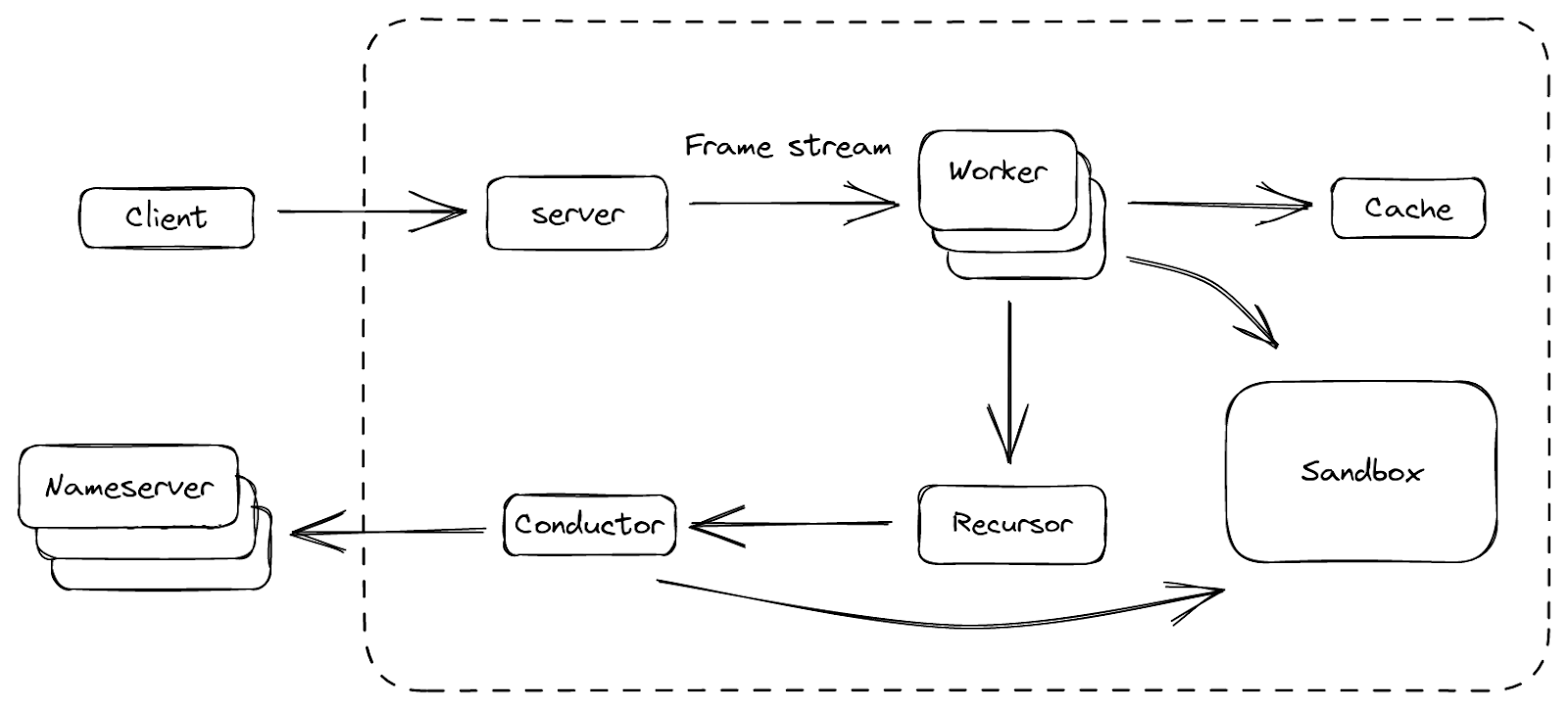
Finalmente, creamos una plataforma con la que estamos satisfechos, y se llama BigPineapple. La figura anterior muestra una visión general de sus componentes principales y del flujo de datos entre ellos. Dentro de BigPineapple, el módulo del servidor recibe las solicitudes entrantes del cliente, las valida y las transforma en flujos de tramas unificadas, que luego el módulo worker puede procesar. El módulo worker tiene un conjunto de workers, cuya tarea es averiguar la respuesta a la pregunta de la solicitud. Cada worker interactúa con el módulo de caché para comprobar si la respuesta está ahí y sigue siendo válida. De lo contrario, lleva al módulo recursor a iterar la consulta de forma recursiva. El recursor no realiza ninguna E/S, cuando necesita algo, delega la subtarea en el módulo conductor. A continuación, el conductor utiliza consultas salientes para obtener la información de los servidores DNS. A lo largo de todo el proceso, algunos módulos pueden interactuar con el módulo de espacio aislado para ampliar su funcionalidad ejecutando los plugins que contiene.
Veamos algunos de ellos con más detalle, y cómo nos ayudaron a superar los problemas que teníamos antes.
Arquitectura de E/S actualizada
Un solucionador de DNS se puede ver como un agente entre un cliente y varios servidores DNS autoritativos. Recibe solicitudes del cliente, recaba datos de los servidores DNS de manera recursiva, luego compone las respuestas y las devuelve al cliente. Por tanto, tiene tráfico de entrada y de salida, que es gestionado por el servidor y el componente conductor, respectivamente.
El servidor escucha en una lista de interfaces que utilizan distintos protocolos de transporte. Estos se abstraen posteriormente en flujos de "tramas". Cada trama es una representación de alto nivel de un mensaje DNS, con algunos metadatos adicionales. Por debajo, puede ser un paquete UDP, un segmento de flujo TCP o la carga útil de una solicitud HTTP, pero todos se procesan de la misma manera. A continuación, la trama se convierte en una tarea asíncrona, que a su vez es recuperada por un conjunto de workers encargados de resolver estas tareas. Las tareas terminadas se convierten de nuevo en respuestas, y se devuelven al cliente.
Esta abstracción de "tramas" sobre los protocolos y sus codificaciones simplificó la lógica utilizada para regular las fuentes de tramas, como distribuir la carga uniformemente para evitar el colapso, y el control del ritmo para evitar la saturación del servidor. Una de las lecciones que hemos aprendido con las implementaciones anteriores es que, para un servicio abierto al público, el rendimiento máximo de la E/S importa menos que la capacidad de establecer el ritmo justo para los clientes. Esto se debe principalmente a que el tiempo y el coste del cálculo de cada solicitud recursiva es muy diferente (por ejemplo, un acierto de caché de un error de caché), y es difícil adivinarlo de antemano. Los errores de caché en el servicio recursivo no solo consumen los recursos de Cloudflare, sino también los recursos de los servidores DNS autoritativos consultados, por lo que debemos tenerlo en cuenta.
En el otro lado del servidor está el conductor, que gestiona todas las conexiones salientes. Es útil responder a algunas preguntas antes de llegar al canal ascendente: ¿Cuál es el servidor de nombres más rápido para conectarse en términos de latencia? ¿Qué hay que hacer si no se puede acceder a todos los servidores DNS? ¿Qué protocolo hay que utilizar para la conexión, ¿Hay alguna opción mejor? El conductor puede tomar estas decisiones haciendo un seguimiento de las métricas del servidor de destino, como reducción del tiempo de ida y vuelta (RTT), calidad del servicio (QoS), etc. Con esa información, también puede estimar, por ejemplo, la capacidad del canal ascendente, la pérdida de paquetes UDP, y tomar las medidas necesarias, por ejemplo, reintentar cuando cree que el paquete UDP anterior no llegó al servidor de destino.
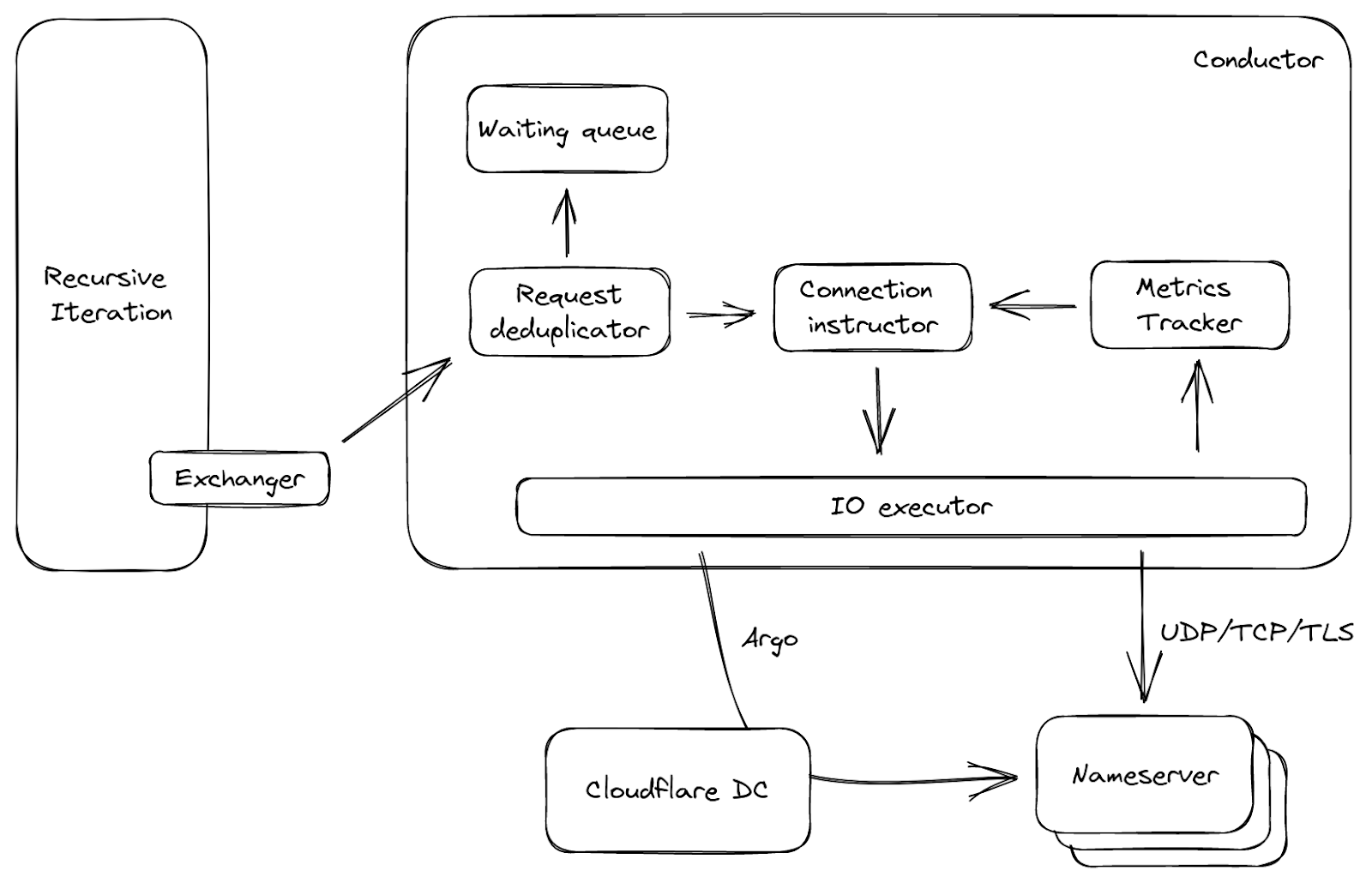
La figura 3 muestra un flujo de datos simplificado sobre el conductor. El intercambiador mencionado anteriormente llama al conductor, con solicitudes a servidores DNS autoritativos como entrada. Primero se duplicarán las solicitudes, es decir, en una ventana pequeña de tiempo, si llegan muchas solicitudes al conductor y solicitan lo mismo, solo se transmitirá una de ellas, mientras que las demás se pondrán en una cola de espera. Este proceso es habitual cuando expira una entrada de la caché, y puede reducir el tráfico innecesario de la red. A continuación, basándose en la solicitud y en las métricas ascendentes, el instructor de la conexión elige una conexión abierta si está disponible, o genera un conjunto de parámetros. Con estos parámetros, el ejecutor de E/S se puede conectar directamente al canal destino, o incluso tomar una ruta a través de otro centro de datos de Cloudflare utilizando ¡nuestra tecnología Argo Smart Routing!
La caché
El almacenamiento en caché en un servicio recursivo es fundamental, ya que un servidor puede devolver una respuesta almacenada en caché en menos de un milisegundo, si bien tardará cientos de milisegundos en responder a un error de caché. Como la memoria es un recurso limitado (y también un recurso compartido en la arquitectura de Cloudflare), el uso más eficiente del espacio para la caché era una de las áreas clave que queríamos mejorar. La nueva caché se implementa con una estructura de datos de reemplazo de caché (ARC), en lugar de un almacén clave-valor. Así se aprovecha bien el espacio en un solo nodo, ya que las entradas menos populares se eliminan progresivamente, y la estructura de datos es resistente a los análisis.
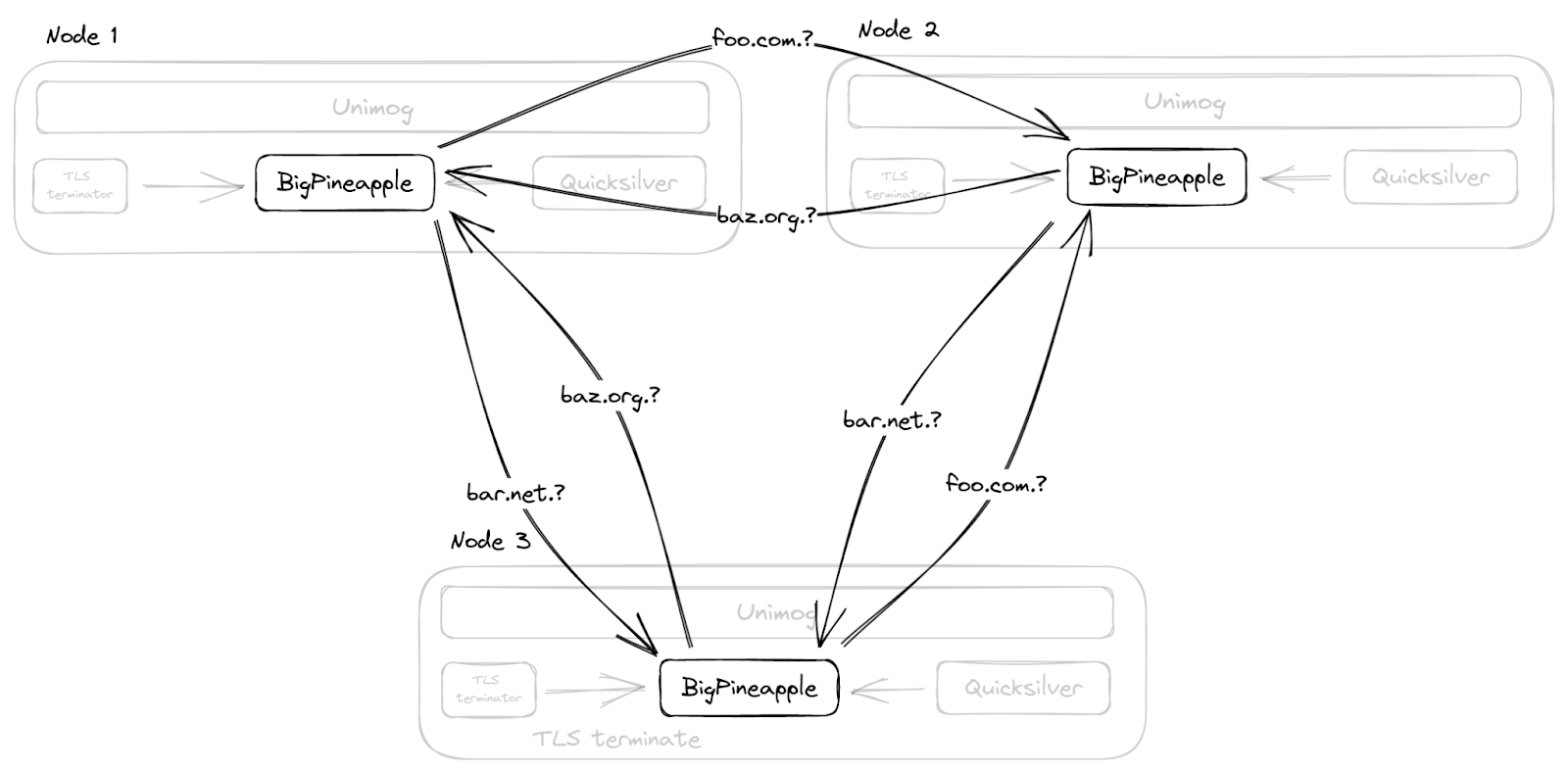
Además, en lugar de duplicar la caché en todo el centro de datos con multidifusión, como hacíamos antes, BigPineapple es consciente de sus nodos del mismo nivel en el mismo centro de datos, y retransmite las consultas de un nodo a otro si no encuentra una entrada en su propia caché. Para ello aplicamos una función hash coherente (consistent hashing) de las consultas a los nodos en buen estado de cada centro de datos. Así, por ejemplo, las consultas para el mismo dominio registrado pasan por el mismo subconjunto de nodos, lo que no solo aumenta la proporción de aciertos de la caché, sino que también ayuda a la caché de la infraestructura, que almacena información sobre el rendimiento y las funciones de los servidores DNS.
Biblioteca recursiva asíncrona
La biblioteca recursiva es el cerebro DNS de BigPineapple, ya que sabe cómo encontrar la respuesta a la pregunta de la consulta. Partiendo de la raíz, desglosa la consulta del cliente en subconsultas, y las utiliza para recopilar información de varios servidores DNS autoritativos en Internet de manera recursiva. El producto de este proceso es la respuesta. Gracias a la sintaxis async/await se puede abstraer como una función como esta:
async fn resolve(Request, Exchanger) → Result<Response>;
La función contiene toda la lógica necesaria para generar una respuesta a una solicitud dada, pero no realiza ninguna E/S por sí misma. En su lugar, pasamos un trait del intercambiador (interfaz Rust) que sabe cómo intercambiar mensajes DNS con los servidores DNS autoritativos de forma asíncrona. Normalmente se llama al intercambiador en varios await, por ejemplo, cuando se inicia una recursión, una de las primeras cosas que hace es buscar la delegación en caché más cercana para el dominio. Si no tiene la delegación final en caché, tiene que preguntar qué servidores DNS son responsables de este dominio y esperar la respuesta, antes de avanzar.
Gracias a este diseño, que desvincula la parte de "esperar algunas respuestas" de la lógica DNS recursiva, es mucho más fácil realizar pruebas proporcionando una implementación simulada del intercambiador. Además, hace que el código de iteración recursiva (y la lógica de validación DNSSEC en particular) sea mucho más legible, ya que se escribe secuencialmente en lugar de estar disperso en muchas callbacks.
Dato curioso: ¡escribir un solucionador de DNS recursivo desde cero no es divertido!
No solo por la complejidad de la validación DNSSEC, sino también por las "soluciones alternativas" necesarias para varios servidores, reenviadores, firewalls, etc. incompatibles con la RFC. Así que importamos Deckard a Rust para ayudar a probarlo. Además, cuando empezamos a migrar a esta nueva biblioteca recursiva asíncrona, primero la ejecutamos en modo "virtual". Procesamos muestras de consultas del mundo real del servicio de producción y comparamos las diferencias. Lo hicimos en el pasado con el servicio DNS autoritativo de Cloudflare. Es un poco más difícil para un servicio recursivo debido a que este tiene que buscar todos los datos en Internet, y los servidores DNS autoritativos a menudo dan respuestas diferentes para la misma consulta debido a la localización, el equilibrio de carga y demás, lo que da lugar a muchos falsos positivos.
En diciembre de 2019, finalmente abrimos el servicio al público para probrarlo (ver el anuncio) y solucionar los problemas pendientes antes de migrar progresivamente los puntos finales de producción al nuevo servicio. Incluso después de todo el proceso, seguimos encontrando edge cases con la recursión DNS (y la validación DNSSEC en particular), pero ahora es más fácil solucionar y reproducir estos problemas gracias a la nueva arquitectura de la biblioteca.
Plugins en espacio aislado
Para nosotros es importante tener la posibilidad de ampliar sobre la marcha la funcionalidad básica del DNS, por eso BigPineapple ha rediseñado su sistema de plugins. Antes, los plugins Lua se ejecutaban en el mismo espacio de memoria que el propio servicio, y en general eran libres de hacer lo que quisieran. Este proceso es práctico, ya que podemos pasar libremente referencias de memoria entre el servicio y los módulos utilizando C/FFI, por ejemplo, para leer una respuesta directamente de la caché sin tener que copiarla antes a un búfer. Pero también es peligroso, ya que el módulo puede leer memoria sin inicializar, llamar a una ABI del host utilizando una firma de función incorrecta, bloquearse en un socket local u otras acciones no deseadas, además el servicio no tiene forma de restringir estos comportamientos.
Así que nos planteamos sustituir el entorno de ejecución Lua insertado por JavaScript, o módulos nativos, pero más o menos al mismo tiempo empezaron a aparecer entornos de ejecución integrados para WebAssembly (Wasm para abreviar). Dos buenas propiedades de los programas WebAssembly son que nos permiten escribirlos en el mismo lenguaje que el resto del servicio, y que se ejecutan en un espacio de memoria aislado. Así que empezamos a modelar la interfaz host/huésped en torno a las limitaciones de los módulos WebAssembly, para ver cómo funcionaba.
El entorno de ejecución Wasm de BigPineapple funciona actualmente con Wasmer. Probamos varios entornos de ejecución a lo largo del tiempo, como Wasmtime y WAVM al principio, y descubrimos que Wasmer era más sencillo de utilizar en nuestro caso. El entorno de ejecución permite que cada módulo se ejecute en su propia instancia, con una memoria aislada y una intercepción de señales, lo que naturalmente resolvía el problema de aislamiento de módulos que hemos descrito antes. Además, podemos tener varias instancias del mismo módulo ejecutándose al mismo tiempo. Si se controlan con cuidado, las aplicaciones se pueden intercambiar en caliente de una instancia a otra ¡sin perder ni una sola solicitud! Es genial porque las aplicaciones se pueden actualizar sobre la marcha sin reiniciar el servidor. Dado que los programas Wasm se distribuyen a través de Quicksilver, la funcionalidad de BigPineapple se puede cambiar con seguridad en todo el mundo ¡en pocos segundos!
Para entender mejor el espacio aislado de WebAssembly, primero hay que aclarar varios conceptos:
- Host: programa que ejecuta el entorno de ejecución Wasm. Similar a un kernel, tiene control total a través del entorno de ejecución sobre las aplicaciones huéspedes.
- Aplicación huésped: programa Wasm dentro del espacio aislado. Dentro de un entorno restringido, solo puede acceder a su propio espacio de memoria, que le proporciona el entorno de ejecución, y realizar las llamadas importadas del host. La llamamos "app" para abreviar.
- Llamada del host: funciones definidas en el host que el huésped puede importar. Comparable a las llamadas del sistema, es la única forma que tienen las aplicaciones huéspedes de acceder a los recursos fuera del espacio aislado.
- Entorno de ejecución huésped: biblioteca para que las aplicaciones huéspedes interactúen fácilmente con el host. Implementa algunas interfaces comunes, de modo que una aplicación se puede limitar a utilizar async, socket, log y tracing sin conocer los detalles subyacentes.
Ahora es el momento de analizar el espacio aislado, así que sigue leyendo. Primero empecemos por el lado del huésped, y veamos cómo es el ciclo de vida de una aplicación común. Con la ayuda del entorno de ejecución huésped, las aplicaciones huéspedes se pueden escribir de forma similar a los programas normales. Así, al igual que otros ejecutables, una aplicación comienza con una función de inicio como punto de entrada, a la que el host llama al inicializarse. También se le proporcionan argumentos como desde la línea de comandos. En este punto, la instancia normalmente realiza alguna inicialización y, lo que es más importante, registra las callbacks para diferentes fases de consulta. Esto se debe a que en un solucionador recursivo, una consulta tiene que pasar por varias fases antes de reunir suficiente información para producir una respuesta, p. ej., una búsqueda en caché, o hacer subconsultas para resolver una cadena de delegación para el dominio, por lo que poder vincularse a estas fases es necesario para que las aplicaciones sean útiles para diferentes casos de uso. La función de inicio también puede ejecutar algunas tareas en segundo plano para complementar las callbacks de las fases, y almacenar el estado global. Por ejemplo, informar de las métricas, obtener previamente datos compartidos de fuentes externas, etc. De nuevo, igual que escribimos un programa normal.
Pero, ¿de dónde proceden los argumentos del programa? ¿Cómo podría una aplicación huésped enviar registros y métricas? La respuesta es: funciones externas.
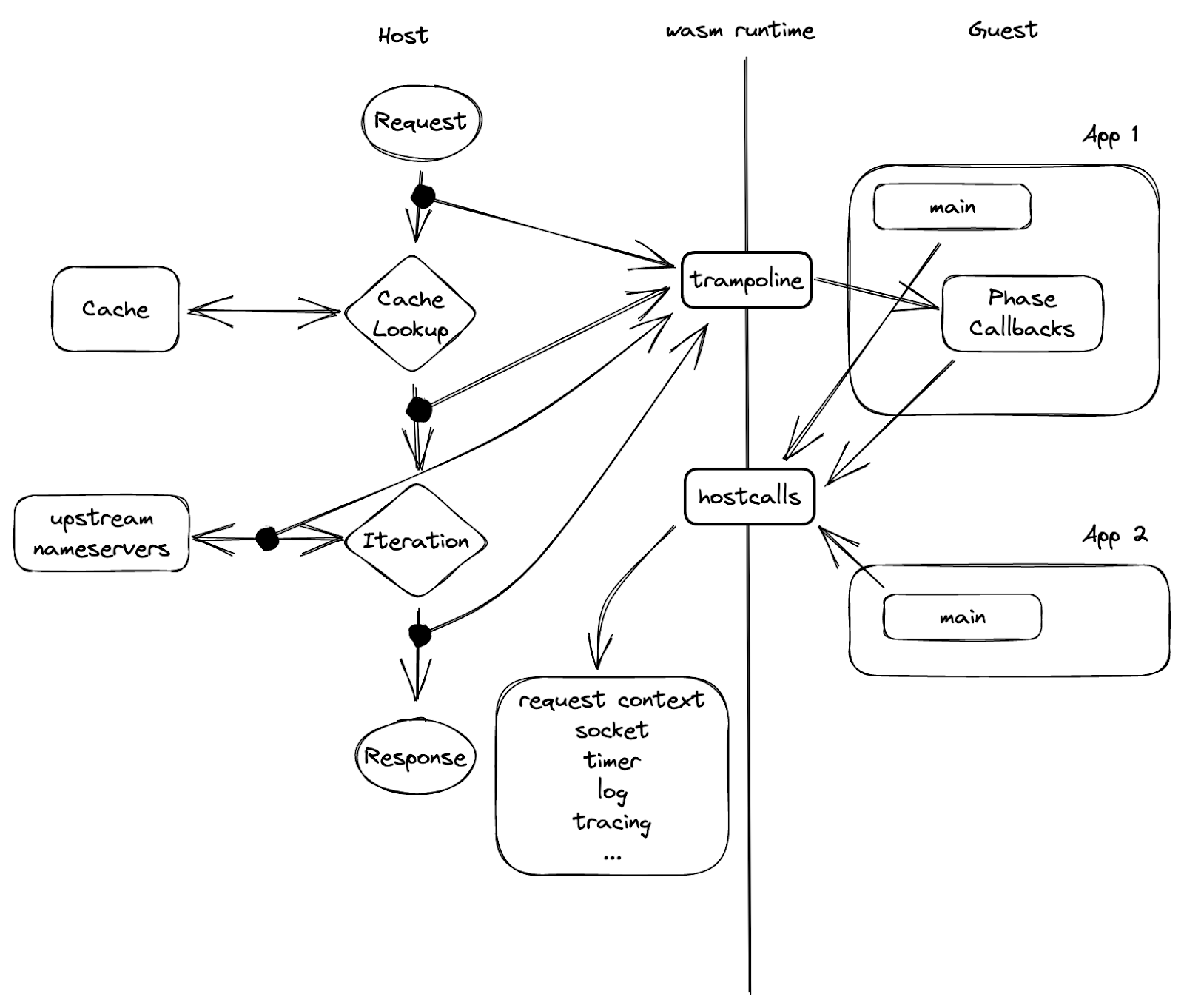
En la figura 5, podemos ver una barrera en el medio, que es el límite del espacio aislado, que separa al huésped del host. La única forma de que una parte pueda llegar a la otra, es a través de un conjunto de funciones exportadas previamente por el nodo del mismo nivel. Como en la imagen, el host exporta las "llamadas del host" y el huésped las importa y las realiza. Por su parte, los "trampolines" son funciones del huésped de las que el host tiene conocimiento.
Se llama trampolín porque se utiliza para invocar una función o un closure dentro de una instancia huésped que no se ha exportado. Las callbacks de fase son un ejemplo de por qué necesitamos una función trampolín. Cada callback devuelve un closure y, por tanto, no se puede exportar en la creación de instancias. Así que si una aplicación huésped quiere registrar una callback, realiza una llamada del host con la dirección de la callback "hostcall_register_callback(pre_cache, #30987)". Cuando hay que invocar la callback, el host no puede simplemente llamar a ese puntero, ya que apunta al espacio de memoria del huésped. En cambio, lo que puede hacer es aprovechar una de las funciones trampolín antes mencionadas y darle la dirección del closure de la callback: "trampoline_call(#30987)".
Sobrecarga de aislamiento
Como una moneda de dos caras, el nuevo espacio aislado conlleva una sobrecarga adicional. La portabilidad y el aislamiento que ofrece WebAssembly conllevan un coste extra. A continuación, enumeramos dos ejemplos.
En primer lugar, las aplicaciones huéspedes no pueden leer la memoria del host. La forma en que funciona es que el huésped proporciona una región de memoria mediante una llamada del host, y luego el host escribe los datos en el espacio de memoria del huésped. Este proceso incorpora una copia de memoria que no sería necesaria si estuviéramos fuera del espacio aislado. La mala noticia es que, en nuestro caso de uso, se supone que las aplicaciones huéspedes deben hacer algo en la consulta o en la respuesta, por lo que casi siempre necesitan leer datos del host en cada solicitud. La buena noticia, por otro lado, es que durante el ciclo de vida de una solicitud, los datos no cambiarán. Así que preasignamos una gran cantidad de memoria en el espacio de memoria del huésped justo después de que se instancie la aplicación huésped. La memoria asignada no se va a utilizar, sino que sirve para ocupar un hueco en el espacio de direcciones. Una vez que el host obtiene los detalles de las direcciones, asigna una región de memoria compartida con los datos comunes que necesita el huésped en el espacio de este. Cuando el código del huésped comienza a ejecutarse, solo tiene que acceder a los datos de la superposición de memoria compartida, y no es necesario copiarlos.
Otro problema con el que nos topamos fue cuando quisimos añadir compatibilidad para un protocolo moderno, oDoH, en BigPineapple. Su función principal es desencriptar la consulta del cliente, resolverla y, a continuación, encriptar las respuestas antes de enviarlas de vuelta. Por diseño, esto no pertenece al propio DNS, y en su lugar se debería ampliar con una aplicación Wasm. Sin embargo, el conjunto de instrucciones WebAssembly no proporciona algunas primitivas criptográficas, como AES y SHA-2, lo que le impide beneficiarse del hardware del host. Se está trabajando para incorporar esta funcionalidad a Wasm con WASI-crypto. Hasta entonces, lo solucionamos simplemente delegando el cifrado de clave pública híbrida HPKE al host mediante llamadas de host, y ya hemos observado mejoras de rendimiento cuatro veces superiores en comparación con Wasm.
Asincronía en Wasm
¿Recuerdas el problema del que hablábamos antes de que las callbacks podían bloquear el event loop? Básicamente, el problema es cómo ejecutar el código de espacio aislado de forma asíncrona. No importa lo compleja que sea la callback de procesamiento de la solicitud, si puede ceder (yield), podemos poner un límite superior al tiempo que se le permite bloquear. Por suerte, el marco asíncrono de Rust es elegante y ligero, y nos da la oportunidad de utilizar un conjunto de llamadas de huéspedes para implementar los "futures".
En Rust, un future es un bloque de creación para cálculos asíncronos. Desde la perspectiva del usuario, para hacer un programa asíncrono, hay que ocuparse de dos cosas: implementar una función poll que dirija la transición de estado, y utilizar una función waker como callback para que se active cuando se vuelva a llamar a la función poll por algún acontecimiento externo (p. ej. pasa el tiempo, el socket se vuelve legible, etc.). Lo primero permite desarrollar el programa gradualmente, p. ej. leer datos almacenados en búfer de E/S y devolver un nuevo estado que indique el estado de la tarea: finalizada o cedida. Esto último es útil en caso de ceder la tarea, ya que hará que el futuro se base en poll cuando se cumplan las condiciones que la tarea estaba esperando, en lugar de estar ocupado repitiendo en bucle hasta que se complete.
Veamos cómo se implementa en nuestro espacio aislado. En un escenario en el que el huésped necesita hacer alguna E/S, tiene que hacerlo a través de las llamadas del host, ya que se encuentra dentro de un entorno restringido. Suponiendo que el host proporcione un conjunto de llamadas simplificadas del host que reflejen las operaciones básicas del socket (abrir, leer, escribir y cerrar), el huésped puede tener su función pseudopoll definida como se indica a continuación:
fn poll(&mut self, wake: fn()) -> Poll {
match hostcall_socket_read(self.sock, self.buffer) {
HostOk => Poll::Ready,
HostEof => Poll::Pending,
}
}
Aquí la llamada del host lee datos de un socket en un búfer, y dependiendo de su valor devuelto, la función puede pasar a uno de los estados que hemos mencionado antes: finalizado(Listo), o cedido(Pendiente). La magia ocurre dentro de la llamada del host. ¿Recuerdas en la figura 5, que es la única forma de acceder a los recursos? La aplicación huésped no es propietaria del socket, pero puede adquirir un "controlador" mediante "hostcall_socket_open", que a su vez creará un socket en el lado host y devolverá un "controlador". En teoría, el "controlador" puede ser cualquier cosa, pero en la práctica el uso de "controladores" de socket enteros se corresponde bien con descriptores de archivo en el lado host, o índices en un vector o bloque. Haciendo referencia al controlador devuelto, la aplicación huésped puede controlar el socket real de forma remota. Como el lado host es totalmente asíncrono, puede simplemente transmitir el estado del socket al huésped. Si te has dado cuenta de que arriba no se utiliza la función waker, ¡bien hecho! Eso se debe a que cuando se realiza la llamada del host no solo se inicia la apertura de un socket, sino que también se registra la función waker actual para llamarlo cuando se abra el socket (o de no hacerlo). Así, cuando el socket esté listo, se activará la tarea del host, encontrará la tarea huésped correspondiente de su contexto y la activará utilizando la función trampolín, como se muestra en la figura 5. Hay otros casos en los que una tarea huésped necesita esperar a otra tarea huésped, una exclusión mutua asíncrona, por ejemplo. Aquí el mecanismo es similar: utilizar llamadas al host para registrar activaciones.
Todos estos elementos complicados están encapsulados en nuestro entorno de ejecución asíncrono huésped con una API fácil de usar, para que las aplicaciones huéspedes tengan acceso a las funciones asíncronas normales sin tener que preocuparse de los detalles subyacentes.
Esto no acaba aquí
Esperamos que esta publicación del blog te haya dado una idea general de la innovadora plataforma en la que se basa el solucionador 1.1.1.1. que sigue evolucionando. A día de hoy, varios de nuestros productos, como 1.1.1.1 for Families, AS112 y Gateway DNS, son compatibles con aplicaciones huéspedes que se ejecutan en BigPineapple. Estamos deseando incorporar nuevas tecnologías. Si tienes alguna idea, háznoslo saber en la comunidad o a través del correo electrónico.