
Hier bei Cloudflare haben wir viel Erfahrung mit dem Betrieb von Servern im wilden Internet. Aber wir werden in der Beherrschung dieser schwarzen Kunst immer besser. In diesem Blog haben wir bereits Licht in mehrere dunkle Ecken der Internet-Protokolle gebracht, beispielsweise mit den grundlegenden Informationen zu FIN-WAIT-2 oder dem Tuning von Empfangspuffern.

Einem Thema wurde jedoch noch nicht genug Aufmerksamkeit geschenkt – SYN-Floods. Wir verwenden Linux und es stellt sich heraus, dass die Verarbeitung von SYN-Paketen unter Linux wirklich komplex ist. In diesem Beitrag werden wir etwas Licht in dieses Thema bringen.
Die Geschichte von zwei Warteschlangen
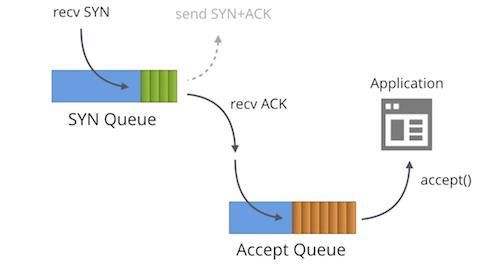
Zuerst müssen wir verstehen, dass jedes gebundene Socket im TCP-Zustand „LISTENING“ zwei separate Warteschlangen hat:
- Die SYN-Queue
- Die Accept-Queue
In der Literatur werden diese Warteschlangen oft mit anderen Namen wie „reqsk_queue“, „ACK Backlog“, „Listen Backlog“ oder sogar „TCP Backlog“ bezeichnet, aber ich werde mich an die oben genannten Namen halten, um Verwechslungen zu vermeiden.
Die SYN-Queue
Die SYN-Queue speichert eingehende SYN-Pakete [1] (speziell: struct inet_request_sock). Sie ist für das Senden von SYN+ACK-Paketen und den erneuten Versuch bei Timeout verantwortlich. Unter Linux ist die Anzahl der Wiederholungen folgendermaßen konfiguriert:
$ sysctl net.ipv4.tcp_synack_retries
net.ipv4.tcp_synack_retries = 5Die Dokumentation beschreibt diesen Umschalter:
tcp_synack_retries - INTEGER
Number of times SYNACKs for a passive TCP connection attempt
will be retransmitted. Should not be higher than 255. Default
value is 5, which corresponds to 31 seconds till the last
retransmission with the current initial RTO of 1second. With
this the final timeout for a passive TCP connection will
happen after 63 seconds.
Nach der Übertragung des SYN+ACK wartet die SYN-Queue auf ein ACK-Paket vom Client – das letzte Paket im Drei-Wege-Handshake. Alle empfangenen ACK-Pakete müssen zunächst mit der vollständig aufgebaute Verbindungstabelle und erst dann mit den Daten in der entsprechenden SYN-Queue abgeglichen werden. Bei Übereinstimmung mit der SYN-Queue entfernt der Kernel das Element aus der SYN-Queue, stellt glücklich eine vollwertige Verbindung her (speziell: struct inet_sock) und fügt diese der Accept-Queue hinzu.
Die Accept-Queue
Die Accept-Queue enthält vollständig hergestellte Verbindungen: bereit, von der Anwendung abgeholt zu werden. Wenn ein Prozess accept() aufruft, werden die Sockets aus der Warteschlange entfernt und an die Anwendung übergeben.
Dies ist eine etwas vereinfachte Beschreibung der Verarbeitung von SYN-Paketen unter Linux. Bei Socket-Umschaltern wie TCP_DEFER_ACCEPT[2] und TCP_FASTOPEN funktionieren die Dinge etwas anders.
Größenbegrenzung von Warteschlangen
Die maximal zulässige Länge der Accept- und der SYN-Queue wird dem backlog-Parameter entnommen, den die Anwendung an den Syscall listen(2) übergibt. Dadurch werden beispielsweise die Größen von Accept- und SYN-Queues auf 1.024 festgelegt:
listen(sfd, 1024)
Hinweis: In Kerneln vor 4.3 wurde die Länge der SYN-Queue anders gezählt.
Diese Obergrenze der SYN-Queue wurde früher vom Umschalter net.ipv4.tcp_max_syn_backlog konfiguriert, aber das ist nicht mehr der Fall. Heute begrenzt net.core.somaxconn die Größe beider Warteschlangen. Auf unseren Servern haben wir sie auf 16k gesetzt:
$ sysctl net.core.somaxconn
net.core.somaxconn = 16384Perfekter Backlog-Wert
Jetzt, wo wir das alles wissen, könnten wir uns folgende Frage stellen: Was ist der ideale Wert für den backlog-Parameter?
Die Antwort lautet: Es kommt darauf an. Für die Mehrheit der trivialen TCP-Server spielt es keine Rolle. Beispielsweise unterstützte Golang vor Version 1.11 bekanntlich das Anpassen des Backlog-Werts nicht. Es gibt jedoch gute Gründe, diesen Wert zu erhöhen:
- Wenn die Menge der eintreffenden Verbindungen wirklich groß ist, benötigt die eingehende SYN-Queue selbst bei leistungsstarken Anwendungen möglicherweise eine größere Anzahl von Slots.
- Der backlog-Wert steuert die Größe der SYN-Queue. Dies kann effektiv als „laufende ACK-Pakete“ gelesen werden. Je größer die durchschnittliche Roundtrip-Zeit zum Client ist, desto mehr Slots werden genutzt. Wenn es viele Clients gibt, die weit vom Server entfernt sind, d. h. Hunderte von Millisekunden, ist es sinnvoll, den Backlog-Wert zu erhöhen.
- Die Option TCP_DEFER_ACCEPT bewirkt, dass Sockets länger im Zustand SYN-RECV bleiben und zu den Warteschlangenlimits beitragen.
Auch das Überschreiten des backlog ist schlecht:
- Jeder Slot in der SYN-Queue braucht etwas Speicher. Während einer SYN-Flood ist es nicht sinnvoll, Ressourcen für die Speicherung von Angriffspaketen zu verschwenden. Jeder struct inet_request_sock-Eintrag in die SYN-Queue belegt 256 Byte Arbeitsspeicher im Kernel 4.14.
Um unter Linux in die SYN-Queue zu schauen, können wir den Befehl ss verwenden und nach SYN-RECV-Sockets suchen. Zum Beispiel sehen wir auf einem der Server von Cloudflare 119 Slots, die in der tcp/80-SYN-Queue verwendet werden, und 78 bei tcp/443.
$ ss -n state syn-recv sport = :80 | wc -l
119
$ ss -n state syn-recv sport = :443 | wc -l
78Ähnliche Daten können mit unserem überzüchteten SystemTap-Skript resq.stp angezeigt werden.
Langsame Anwendung
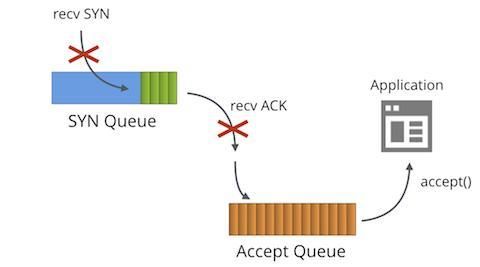
Was passiert, wenn die Anwendung mit dem Aufrufen von accept() nicht schnell genug Schritt halten kann?
Dann geschieht die Magie! Wenn die Accept-Queue voll wird (also eine Größe von backlog+1 erreicht), passiert Folgendes:
- Für die SYN-Queue eingehende SYN-Pakete werden verworfen.
- Für die SYN-Queue eingehende ACK-Pakete werden verworfen.
- Der TcpExtListenOverflows /
LINUX_MIB_LISTENOVERFLOWS-Zähler wird erhöht. - Der TcpExtListenDrops /
LINUX_MIB_LISTENDROPS-Zähler wird erhöht.
Es gibt eine starkes Grundprinzip für das Verwerfen eingehender Pakete: Es handelt sich um einen Push-Back-Mechanismus. Die andere Partei wird früher oder später die SYN- oder ACK-Pakete erneut senden, bis zu welchem Zeitpunkt sich die langsame Anwendung hoffentlich erholt hat.
Das ist ein wünschenswertes Verhalten für fast alle Server. Der Vollständigkeit halber: Es kann mit dem globalen Umschalter net.ipv4.tcp_abort_on_overflow angepasst werden. Fassen Sie ihn aber besser nicht an.
Wenn Ihr Server eine große Anzahl von eingehenden Verbindungen bewältigen muss und mit dem Durchsatz von accept() zu kämpfen hat, sollten Sie unseren Blogbeitrag Nginx-Tuning / Epoll-Arbeitsverteilung und die Fortsetzung mit nützlichen SystemTap-Skripten lesen.
Sie können die Überlaufstatistiken der Accept-Queue verfolgen, indem Sie die nstat-Zähler ansehen:
$ nstat -az TcpExtListenDrops
TcpExtListenDrops 49199 0.0Das ist ein globaler Zähler. Er ist nicht ideal – manchmal sahen wir ihn ansteigen, obwohl alle Anwendungen fehlerfrei aussahen! Der erste Schritt sollte immer sein, die Größen der Accept-Queue mit ss auszugeben:
$ ss -plnt sport = :6443|cat
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 1024 *:6443 *:*Die Spalte Recv-Q zeigt die Anzahl der Sockets in der Accept-Queue an, Send-Q den Backlog-Parameter. In diesem Fall sehen wir, dass es keine ausstehenden Sockets für accept() gibt, aber wir haben auch gesehen, dass der ListenDrops-Zähler immer noch steigt.
Es stellte sich heraus, dass unsere Anwendung für den Bruchteil einer Sekunde stecken geblieben war. Das reichte aus, um die Accept-Queue für einen sehr kurzen Zeitraum überlaufen zu lassen. Kurz darauf erholte sie sich wieder. Fälle wie dieser lassen sich schwer mit ss debuggen, weshalb wir einacceptq.stp-SystemTap-Skript geschrieben haben, um uns zu helfen. Es hakt sich in den Kernel ein und gibt die SYN-Pakete aus, die verworfen werden:
$ sudo stap -v acceptq.stp
time (us) acceptq qmax local addr remote_addr
1495634198449075 1025 1024 0.0.0.0:6443 10.0.1.92:28585
1495634198449253 1025 1024 0.0.0.0:6443 10.0.1.92:50500
1495634198450062 1025 1024 0.0.0.0:6443 10.0.1.92:65434
...Hier sehen Sie genau, welche SYN-Pakete von den ListenDrops betroffen waren. Mit diesem Skript ist es kinderleicht zu verstehen, welche Anwendung Verbindungen verwirft.

SYN-Flood
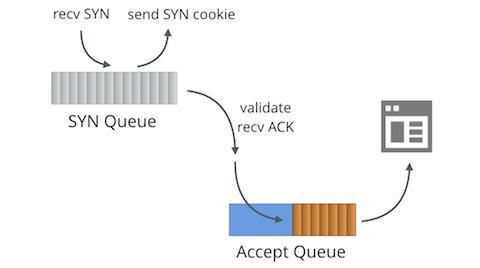
Wenn es möglich ist, dass die Accept-Queue überläuft, muss es auch möglich sein, dass die SYN-Queue überläuft. Was geschieht in diesem Fall?
Das ist es, worum es bei SYN-Flood-Angriffen geht. In der Vergangenheit war die Überflutung der SYN-Queue mit gefälschten SYN-Paketen ein echtes Problem. Vor 1996 war es möglich, den Dienst fast jedes TCP-Servers mit sehr geringer Bandbreite erfolgreich zu lahmzulegen, nur indem man die SYN-Queues füllte.
Die Lösung sind SYN-Cookies. SYN-Cookies sind ein Konstrukt, das das zustandslose Generieren von SYN+ACK ermöglicht, ohne die eingehenden SYN zu speichern und Systemspeicher zu verschwenden. SYN-Cookies unterbrechen den legitimen Datenverkehr nicht. Wenn die Gegenpartei real ist, antwortet sie mit einem gültigen ACK-Paket einschließlich der reflektierten Sequenznummer, die kryptografisch verifiziert werden kann.
Standardmäßig werden SYN-Cookies bei Bedarf aktiviert – für Sockets mit einer gefüllten SYN-Queue. Linux aktualisiert einige Zähler für SYN-Cookies. Wenn ein SYN-Cookie gesendet wird:
- TcpExtTCPReqQFullDoCookies / LINUX_MIB_TCPREQQFULLDOCOOKIES wird erhöht.
- TcpExtSyncookiesSent / LINUX_MIB_SYNCOOKIESSENT wird erhöht.
- Früher hat Linux TcpExtListenDrops erhöht, Kernel 4.7 tut dies aber nicht mehr.
Wenn ein eingehendes ACK bei aktivierten SYN-Cookies in die SYN-Queue geht:
- TcpExtSyncookiesRecv / LINUX_MIB_SYNCOOKIESRECV wird nach erfolgreicher Krypto-Validierung erhöht.
- TcpExtSyncookiesFailed / LINUX_MIB_SYNCOOKIESFAILED wird erhöht, wenn die Krypto-Validierung scheitert.
Ein Sysctl net.ipv4.tcp_syncookies kann SYN-Cookies deaktivieren oder sie erzwingen. Die Standardeinstellung ist gut, ändern Sie sie nicht.
SYN-Cookies und TCP-Zeitstempel
Die Magie der SYN-Cookies funktioniert, ist aber nicht ohne Nachteile. Das Hauptproblem ist, dass nur sehr wenige Daten in einem SYN-Cookie gespeichert werden können. Insbesondere werden im ACK nur 32 Bit der Sequenznummer zurückgegeben. Diese Bit werden wie folgt verwendet:
+----------+--------+-------------------+
| 6 bits | 2 bits | 24 bits |
| t mod 32 | MSS | hash(ip, port, t) |
+----------+--------+-------------------+Da die MSS-Einstellung auf nur 4 verschiedene Werte verkürzt ist, kennt Linux keine optionalen TCP-Parameter der anderen Partei. Informationen zu Zeitstempeln, ECN, Selective ACK oder Window Scaling gehen verloren und können zu einer verminderten Leistung der TCP-Sitzung führen.
Glücklicherweise hat Linux einen Workaround. Wenn TCP-Zeitstempel aktiviert sind, kann der Kernel einen weiteren Slot mit 32 Bit im Zeitstempel-Feld wiederverwenden. Er enthält:
+-----------+-------+-------+--------+
| 26 bits | 1 bit | 1 bit | 4 bits |
| Timestamp | ECN | SACK | WScale |
+-----------+-------+-------+--------+TCP-Zeitstempel sollten standardmäßig aktiviert sein. Zur Überprüfung siehe sysctl:
$ sysctl net.ipv4.tcp_timestamps
net.ipv4.tcp_timestamps = 1In der Vergangenheit gab es viele Diskussionen über den Nutzen von TCP-Zeitstempeln.
- Früher haben Zeitstempel die Betriebszeit des Servers geleakt (ob das von Bedeutung ist, ist eine andere Diskussion). Dies wurde vor acht Monaten behoben.
- TCP-Zeitstempel nutzen eine nicht triviale Menge an Bandbreite – 12 Byte für jedes Paket.
- Sie können Paketprüfsummen noch zufälliger machen, was bei bestimmter defekter Hardware hilfreich sein kann.
- Wie oben erwähnt, können TCP-Zeitstempel die Leistung von TCP-Verbindungen steigern, wenn SYN-Cookies aktiviert sind.
Derzeit haben wir bei Cloudflare TCP-Zeitstempel deaktiviert.
Zu guter Letzt funktionieren mit aktivierten SYN-Cookies einige coole Funktionen nicht – Dinge wie TCP_SAVED_SYN, TCP_DEFER_ACCEPT oder TCP_FAST_OPEN.
SYN-Floods in der Cloudflare-Größenordnung

SYN Cookies sind eine großartige Erfindung und lösen das Problem kleinerer SYN-Floods. Bei Cloudflare versuchen wir jedoch, sie nach Möglichkeit zu vermeiden. Während das Versenden von ein paar Tausend kryptografisch verifizierbaren SYN+ACK-Paketen pro Sekunde kein Problem ist, verzeichnen wir Angriffe von mehr als 200 Millionen Paketen pro Sekunde. In dieser Größenordnung würden unsere SYN+ACK-Antworten nur das Internet vermüllen und absolut keinen Nutzen bringen.
Stattdessen versuchen wir, die bösartigen SYN-Pakete auf der Firewall-Ebene zu löschen. Wir verwenden die p0f-SYN-Fingerabdrücke, die zu BPF kompiliert sind. Lesen Sie mehr in diesem Blogbeitrag, der den p0f-BPF-Compiler vorstellt. Für die Erkennung und Abwehr haben wir ein Automatisierungssystem entwickelt, das wir „Gatebot“ nennen. Wir haben es hier beschrieben: Wir stellen vor: Gatebot – der Bot, der uns ruhig schlafen lässt.
Eine Landschaft im Wandel
Weitere – leicht veraltete – Daten zu diesem Thema finden Sie in der ausgezeichneten Erklärung von Andreas Veithen aus dem Jahr 2015 und einem ausführlichen Artikel von Gerald W. Gordon aus dem Jahr 2013.
Das Landschaft der Verarbeitung von SYN-Paketen unter Linux entwickelt sich ständig weiter. Bis vor kurzem waren SYN-Cookies aufgrund einer altmodischen Sperre im Kernel langsam. Das wurde in 4.4 behoben. Jetzt können Sie sich darauf verlassen, dass der Kernel in der Lage ist, Millionen von SYN-Cookies pro Sekunde zu senden, was das SYN-Flood-Problem für die meisten Benutzer praktisch löst. Mit der richtigen Abstimmung ist es möglich, selbst die lästigsten SYN-Floods abzuwehren, ohne die Leistung legitimer Verbindungen zu beeinträchtigen.
Auch die Anwendungsleistung erhält große Aufmerksamkeit. Neue Ideen wie SO_ATTACH_REUSEPORT_EBPF führen eine ganz neue Ebene der Programmierbarkeit in den Netzwerkstack ein.
Es ist schön zu sehen, dass in der ansonsten stagnierenden Welt der Betriebssysteme der Netzwerkstack im Fokus von Innovationen und frischem Denken steht.
Vielen Dank an Binh Le für die Mithilfe an diesem Beitrag.
Der Umgang mit den Feinheiten von Linux und NGINX klingt interessant für Sie? Werden Sie Teil unseres weltberühmten Teams in London, Austin, San Francisco und unserem Elite-Büro in Warschau, Polen.
- Ich vereinfache: Technisch gesehen speichert die SYN-Queue noch nicht AUFGEBAUTE Verbindungen, nicht die SYN-Pakete an sich. Mit TCP_SAVE_SYN kommt es jedoch nah genug heran. ↩
- Wenn TCP_DEFER_ACCEPT neu für Sie ist, sehen Sie sich auf jeden Fall die FreeBSD-Version davon an: accf_http. ↩