

This post is also available in 简体中文 and 繁體中文.
We've been relying on ML and AI for our core services like Web Application Firewall (WAF) since the early days of Cloudflare. Through this journey, we've learned many lessons about running AI deployments at scale, and all the tooling and processes necessary. We recently launched Workers AI to help abstract a lot of that away for inference, giving developers an easy way to leverage powerful models with just a few lines of code. In this post, we’re going to explore some of the lessons we’ve learned on the other side of the ML equation: training.
Cloudflare has extensive experience training models and using them to improve our products. A constantly-evolving ML model drives the WAF attack score that helps protect our customers from malicious payloads. Another evolving model powers our bot management product to catch and prevent bot attacks on our customers. Our customer support is augmented by data science. We build machine learning to identify threats with our global network. To top it all off, Cloudflare is delivering machine learning at unprecedented scale across our network.
Each of these products, along with many others, has elevated ML models — including experimentation, training, and deployment — to a crucial position within Cloudflare. To help our team continue to innovate efficiently, our MLOps effort has collaborated with Cloudflare’s data scientists to implement the following best practices.
Notebooks
Given a use case and data, the first step for many Data Scientist/AI Scientists is to set up an environment for exploring data, feature engineering, and model experiments. Jupyter Notebooks are a common tool to satisfy these requirements. These environments provide an easy remote Python environment that can be run in the browser or connected to a local code editor. To make notebooks scalable and open to collaboration, we deploy JupyterHub on Kubernetes. With JupyterHub, we can manage resources for teams of Data Scientists and ensure they get a suitable development environment. Each team can tailor their environment by pre-installing libraries and configuring user environments to meet the specific needs, or even individual projects.
This notebook space is always evolving as well. Open source projects include further features, such as:
- nbdev - a Python package to improve the notebook experience
- Kubeflow - the kubernetes native CNCF project for machine learning
- deployKF - ML Platforms on any Kubernetes cluster, with centralized configs, in-place upgrades, and support for leading ML & Data tools like Kubeflow, Airflow, and MLflow
GitOps
Our goal is to provide an easy-to-use platform for Data Scientists and AI Scientists to develop and test machine learning models quickly. Hence, we are adopting GitOps as our continuous delivery strategy and infrastructure management on MLOps Platform in Cloudflare. GitOps is a software development methodology that leverages Git, a distributed version control system, as the single source of truth for defining and managing infrastructure, application configurations, and deployment processes. It aims to automate and streamline the deployment and management of applications and infrastructure in a declarative and auditable manner. GitOps aligns well with the principles of automation and collaboration, which are crucial for machine learning (ML) workflows. GitOps leverages Git repositories as the source of truth for declarative infrastructure and application code.
A data scientist needs to define the desired state of infrastructure and applications. This usually takes a lot of custom work, but with ArgoCD and model templates, all it takes is a simple pull request to add new applications. Helm charts and Kustomize are both supported to allow for configuration for different environments and jobs. With ArgoCD, declarative GitOps will then start the Continuous Delivery process. ArgoCD will continuously check the desired state of the infrastructure and applications to ensure that they are synched with the Git repository.
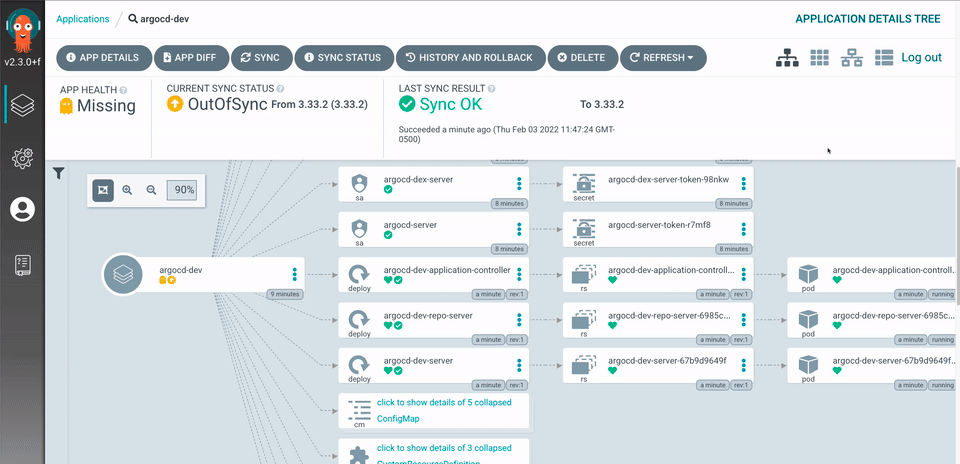
In the future, we plan to migrate our platform (including Jupyterhub) to Kubeflow, a machine learning workflow platform on Kubernetes that simplifies the development, deployment, and management of notebooks and end-to-end pipelines. This is best deployed using a new project, deployKF, which allows for distributed configuration management across multiple components available with Kubeflow, and others that extend beyond what is offered within Kubeflow.
Templates
Starting a project with the right tools and structure can be the difference between success and stagnation. Within Cloudflare, we've curated an array of model templates, which are production ready data science repositories with an example model. These model templates are deployed through production to continually ensure they are a stable foundation for future projects. To start a new project, all it takes is one Makefile command to build a new CICD project in the git project of the users’ choosing. These template utility packages are identical to those used in our Jupyter Notebooks and connections to R2 / S3 / GCS buckets, D1 / Postgres / Bigquery / Clickhouse databases. Data scientists can use these templates to instantly kickstart new projects with confidence. These templates are not yet publicly available, but our team plans to open source them in the future.
1. Training Template
Our model training template provides a solid foundation to build any model. This is configured to help extract, transform, and load data (ETL) from any data source. The template includes helper functions for feature engineering, tracking experiments with model metadata, and choose orchestration through a Directed Acyclic Graph (DAG) to productionalize the model pipeline. Each orchestration can be configured to use Airflow or Argo Workflows.
2. Batch Inference Template
Batch and micro-batch inference can make a significant impact on processing efficiency. Our batch inference model template to schedule models for consistent results, and can be configured to use Airflow or Argo Workflows.
3. Stream Inference Template
This template makes it easy for our team to deploy real-time inference. Tailored for Kubernetes as a microservice using FastAPI, this template allows our team to run inference using familiar Python in a container. This microservice already has built-in REST interactive documentation with Swagger and integration with Cloudflare Access authentication tokens in terraform.
4. Explainability Template
Our model template for explainability spins up dashboards to illuminate the model type and experiments. It is important to be able to understand key values such as a time window F1 score, the drift of features and data over time. Tools like Streamlit and Bokeh help to make this possible.
Orchestration
Organizing data science into a consistent pipeline involves a lot of data and several model versions. Enter Directed Acyclic Graphs (DAGs), a robust flow chart orchestration paradigm that weaves together the steps from data to model, and model to inference. There are many unique approaches to running DAG pipelines, but we have found that data science teams' preference comes first. Each team has different approaches based on their use cases and experience.
Apache Airflow - The Standard DAG Composer
Apache Airflow is the standard as a DAG (Directed Acyclic Graphs)-based orchestration approach. With a vast community and extensive plugin support, Airflow excels in handling diverse workflows. The flexibility to integrate with a multitude of systems and a web-based UI for task monitoring make it a popular choice for orchestrating complex sequences of tasks. Airflow can be used to run any data or machine learning workflow.
Argo Workflows - Kubernetes-native Brilliance
Built for Kubernetes, Argo Workflows embraces the container ecosystem for orchestrating workflows. It boasts an intuitive YAML-based workflow definition and excels in running microservices-based workflows. The integration with Kubernetes enables scalability, reliability, and native container support, making it an excellent fit for organizations deeply rooted in the Kubernetes ecosystem. Argo Workflows can also be used to run any data or machine learning workflow.
Kubeflow Pipelines - A Platform for Workflows
Kubeflow Pipelines is a more specific approach tailored for orchestrating machine learning workflows. “KFP” aims to address the unique demands of data preparation, model training, and deployment in the ML landscape. As an integrated component of the Kubeflow ecosystem, it streamlines ML workflows with a focus on collaboration, reusability, and versioning. Its compatibility with Kubernetes ensures seamless integration and efficient orchestration.
Temporal - The Stateful Workflow Enabler
Temporal takes a stance by emphasizing the orchestration of long-running, stateful workflows. This relative newcomer shines in managing resilient, event-driven applications, preserving workflow state and enabling efficient recovery from failures. The unique selling point lies in its ability to manage complex, stateful workflows, providing a durable and fault-tolerant orchestration solution.
In the orchestration landscape, the choice ultimately boils down to the team and use case. These are all open source projects, so the only limitation is support for different styles of work, which we find is worth the investment.
Hardware
Achieving optimal performance necessitates an understanding of workloads and the underlying use cases in order to provide teams with effective hardware. The goal is to enable data scientists and strike a balance between enablement and utilization. Each workload is different, and it is important to fine tune each use case for the capabilities of GPUs and CPUs to find the perfect tool for the job. For core datacenter workloads and edge inference, GPUs have leveled up the speed and efficiency that is core to our business. With observability and metrics consumed by Prometheus, metrics enable us to track orchestration to be optimized for performance, maximize hardware utilization, and operate within a Kubernetes-native experience.
Adoption
Adoption is often one of the most challenging steps in the MLops journey. Before jumping into building, it is important to understand the different teams and their approach to data science. At Cloudflare, this process began years ago, when each of the teams started their own machine learning solutions separately. As these solutions evolved, we ran into the common challenge of working across the company to prevent work from becoming isolated from other teams. In addition, there were other teams that had potential for machine learning but did not have data science expertise within their team. This presented an opportunity for MLops to step in — both to help streamline and standardize the ML processes being employed by each team, and to introduce potential new projects to data science teams to start the ideation and discovery process.
When able, we have found the most success when we can help get projects started and shape the pipelines for success. Providing components for shared use such as notebooks, orchestration, data versioning (DVC), feature engineering (Feast), and model versioning (MLflow) allow for teams to collaborate directly.
Looking forward
There is no doubt that data science is evolving our business and the businesses of our customers. We improve our own products with models, and have built AI infrastructure that can help us secure applications and applications built with AI. We can leverage the power of our network to deliver AI for us and our customers. We have partnered with machine learning giants to make it easier for the data science community to deliver real value from data.
The call to action is this: join the Cloudflare community in bringing modern software practices and tools to data science. Be on the lookout for more data science from Cloudflare. Help us securely leverage data to help build a better Internet.