



想象一下这种情景:您身处机场,正在通过安检口。很多工作人员在扫描您的登机牌和护照,然后将您送到登机口。突然之间,一些工作人员开始休息。也许是安检口上方的天花板出现了漏水。也许是多个航班在下午 6 时起飞,一大批旅客同时出现。无论哪种情况,这种局部供需不平衡都可能导致排长队和不满的旅客——他们只是想尽快通过队伍并登上他们的航班。机场通过什么方式来处理这种情况?
有些机场可能什么都不做,只会让您排更长的队。一些机场可能会收费提供通过安检的快速通道。但大多数机场会告诉您去稍远一点的另一个安检口,以确保您能尽快通过并到达登机口。他们甚至可能会设置指示牌,告诉您每条排队线路的长度,以便您在尝试通过时可以更容易做出决策。
在 Cloudflare,我们也面临同样的问题。我们打造的网络分布于世界各地 300 个城市,旨在为我们的所有产品套件接收最终用户流量。在理想情况下,我们始终有足够的计算机和带宽在最接近的位置处理每个用户的流量。但世界并不总是理想的:有时我们会让一个数据中心下线以进行维护,或者与数据中心的连接中断,或者某些设备出现故障,等等。当这种情况发生时,我们可能没有足够的人员来为每个地方的每个人提供安检服务。这并不是因为我们没有建立足够的站点,而是因为我们的数据中心发生了一些问题,导致我们无法为每个人提供服务。
因此,我们打造了 Traffic Manager(流量管理器):这个工具用于在我们的整个全球网络中平衡供应和需求。这个博客文章介绍 Traffic Manager:它的来由,我们如何构建它,以及它现在的工作。
有 Traffic Manager 之前的情况
Traffic Manager 现在所做的工作过去是由网络工程师手动操作的:我们的网络正常运行,直到某个数据中心出现问题并影响到用户流量。
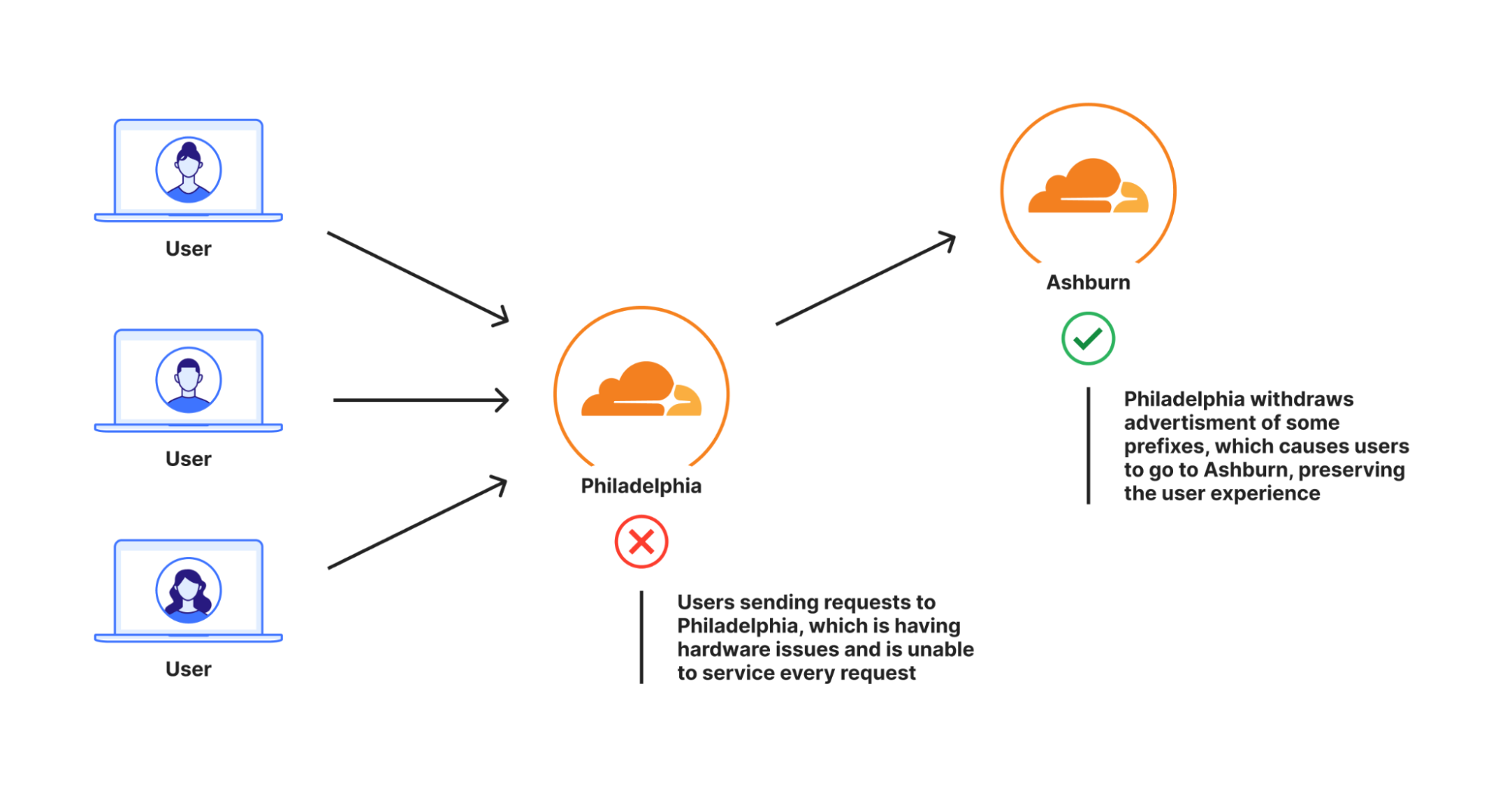
当出现此类事件时,用户请求会开始出现 499 或 500 错误,因为没有足够的机器来处理用户的请求负载。这将为我们的网络工程师触发一个页面,他们会删除该数据中心的一些 Anycast 路由。最终结果:通过不再在受影响的数据中心广告这些前缀,用户流量会转移到另一个数据中心。这就是 Anycast 的基本工作原理:用户流量会被引导到广告用户试图连接的前缀的数据中心,这是由边界网关协议决定的。如需了解 Anycast 是什么,请查看这篇参考文章。
根据问题的严重程度,工程师会移除数据中心的部分甚至全部路由。当数据中心再次能够吸收所有流量时,工程师将把数据中心的路由恢复,流量将自然返回数据中心。
您可以想象,每次我们的网络中任何硬件出现问题时,网络工程师都要进行这样的操作,这是一件具有挑战性的任务。这种做法不能规模化。
永远不要派人去做机器的工作
但是手动操作不仅会给我们的网络运营团队造成负担。这也会导致我们的客户体验不佳;我们的工程师需要花时间诊断和重新路由流量。为了解决这两个问题,我们希望打造一个服务,它可以立即自动检测用户是否无法到达 Cloudflare 数据中心,并从数据中心撤回路由,直到用户不再看到问题。一旦服务通知显示受影响的数据中心可以吸收流量,它就可以将路由恢复并重新连接该数据中心。这个服务被称为 Traffic Manager,因为它的工作就是管理进入 Cloudflare 网络的流量。
考虑二阶后果
当网络工程师从路由器中移除一条路由时,他们可以尽可能猜测用户请求会转移到哪里,并尝试确保备用数据中心有足够的资源来处理请求—— 如果没有,他们可以在初始数据中心移除路由之前相应地调整那里的路由。为了实现这个过程的自动化,我们需要从直觉的世界转向数据的世界——准确地预测当一条路线被取消时,流量会转移到哪里,并将这些信息提供给 Traffic Manager,以便确保这样做不会使情况变得更糟。
认识 Traffic Predictor
尽管我们可以调整哪些数据中心广告路由,但我们无法影响每个数据中心接收的流量比例。每次我们增加一个新的数据中心,或者一个新的对等互连,流量的分布就会发生变化,由于我们的网络覆盖超过 300 个城市,拥有 12500 个对等互连,对于人类来说,跟踪或预测流量在我们的网络如何移动已经变得十分困难。Traffic Manager 需要一个拍档:Traffic Predictor
为了完成其工作,Traffic Predictor 在现实世界进行一系列持续的测试,以查看流量实际的移动情况。Traffic Predictor 依赖于一个测试系统,该系统模拟将数据中心从服务中移除,并测量如果该数据中心不再服务流量,流量会转移到哪里。为了帮助理解这个系统是如何工作的,让我们模拟移除新西兰基督城数据中心的一个子集:
首先,Traffic Predictor 获取通常连接到基督城数据中心的所有 IP 地址的列表。Traffic Predictor 将向最近发出请求的数十万个 IP 发送 ping 请求。
Traffic Predictor 记录每个 IP 是否响应,以及响应是否使用专门为 Traffic Predictor 配置的特殊 Anycast IP 范围返回到基督城数据中心。
一旦 Traffic Predictor 获得一个将响应发送到基督城数据中心的 IP 列表,它就会从基督城数据中心移除包含该特殊范围的路由,等待几分钟以便互联网路由表更新,然后再次运行测试。
这些响应不再被路由到基督城数据中心,而非它周围的其他数据中心。然后,Traffic Predictor 使用每个数据中心的响应情况,并将结果记录为基督城数据中心的故障转移。
这样一来,无需让基督城数据中心实际下线,我们就能模拟该数据中心下线的情况。
但是,Traffic Predictor 并不是就这样对任何数据中心执行这种操作。为了增加额外的韧性,Traffic Predictor 甚至计算第二层间接性:对于每个数据中心故障情景,Traffic Predictor 也计算周围数据中心的故障情景并创建发生故障时的策略。
使用上面的例子,当 Traffic Predictor 测试基督城时,它将运行一系列的测试,将包括基督城在内周围几个数据中心从服务中移除,以计算不同的故障情景。这确保即使发生了影响一个地区内多个数据中心的灾难性事件,我们仍然有能力服务用户流量。如果您认为这个数据模型很复杂,没错:计算所有这些故障路径和策略需要几天时间。
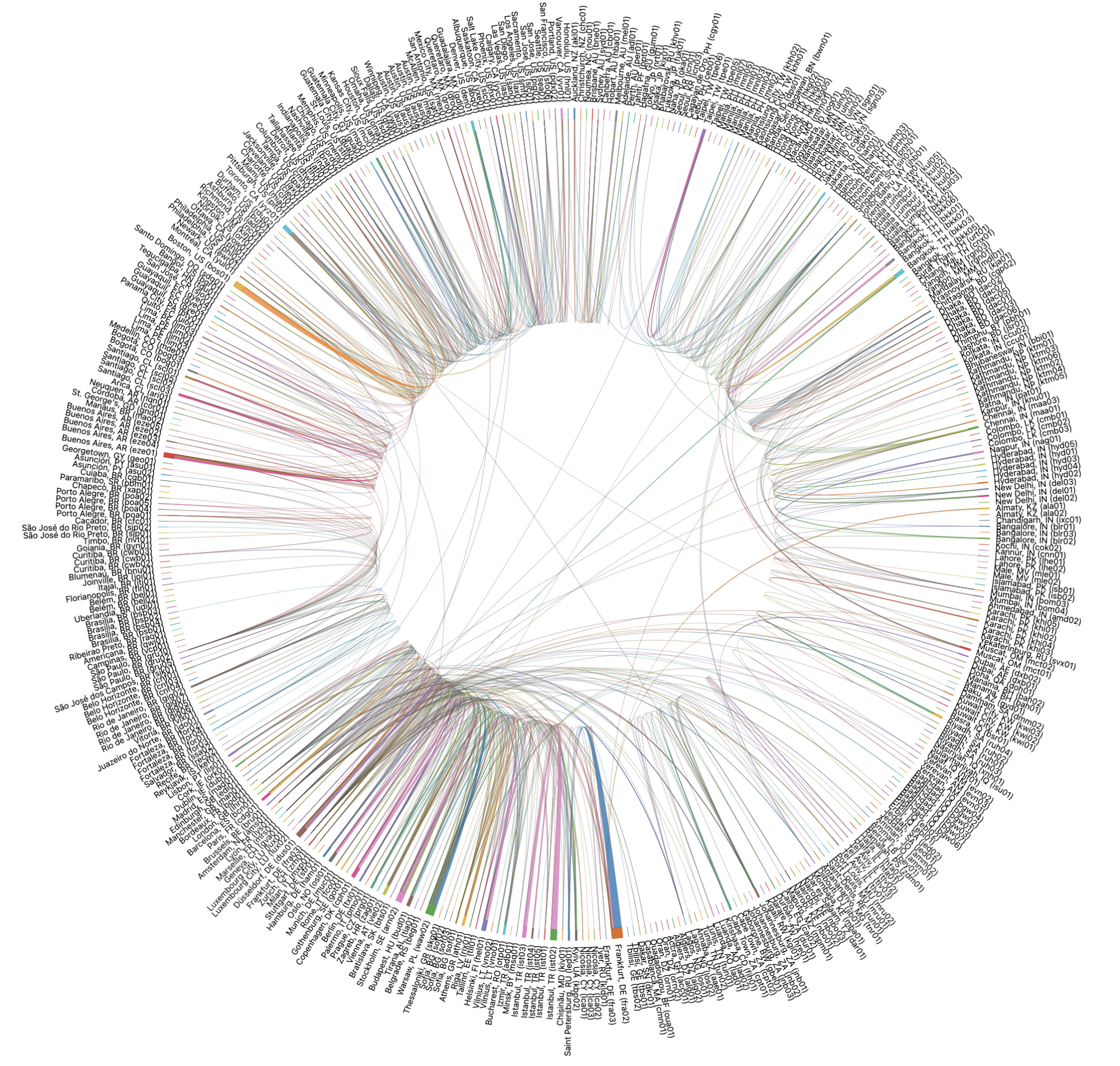
当我们将全球所有数据中心的故障路径和故障转移情景可视化时,看起来是这样的:
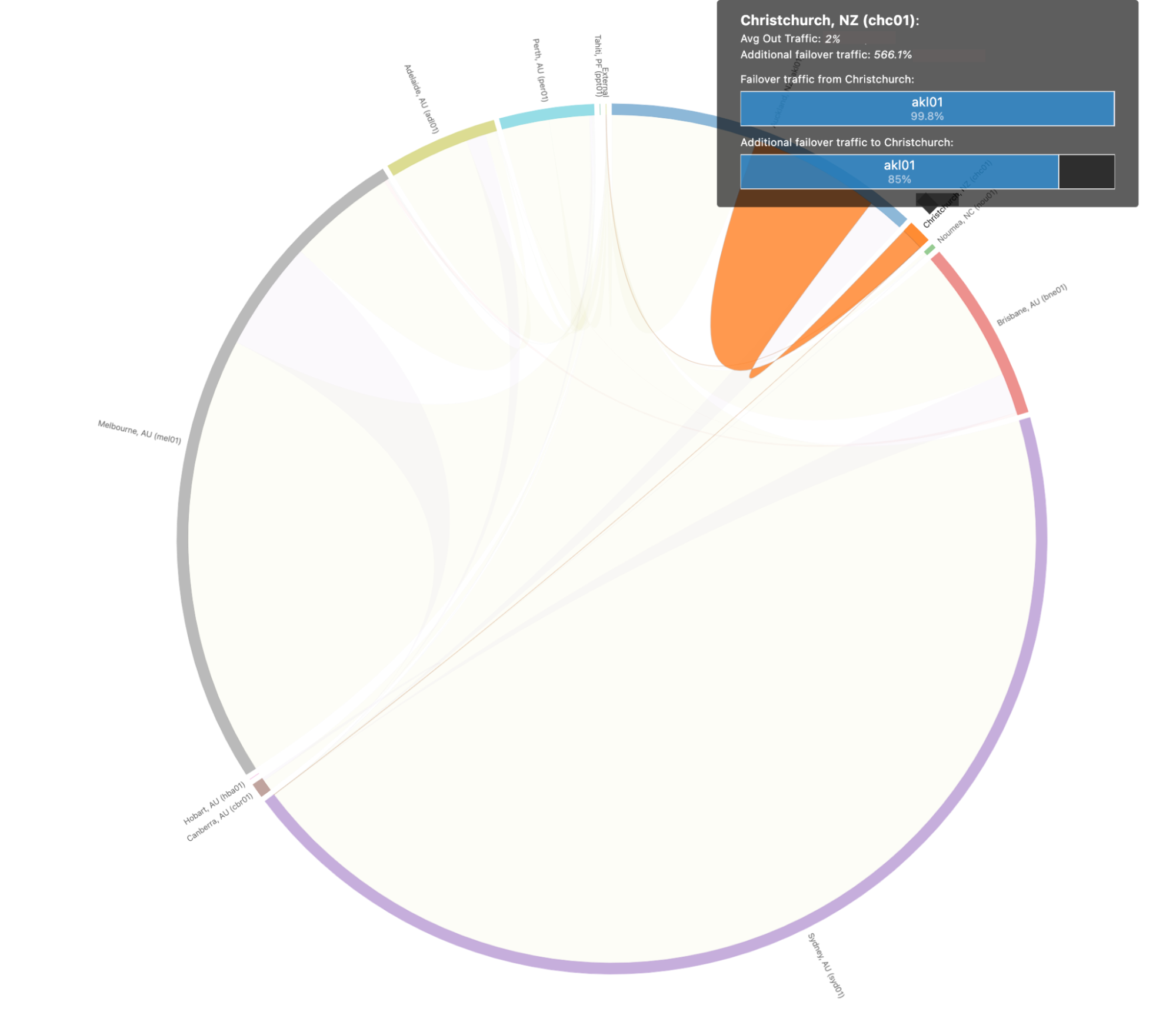
对于人类来说,这可能有点复杂,所以让我们深入介绍一下基督城的上述情景,使它更清晰一些。查看基督城的故障转移路径时,我们看到如下图的样子:
在这个情景中,我们预测基督城 99.8% 的流量会转移到奥克兰数据中心,后者能够在灾难性的宕机事件发生时吸收基督城数据中心的所有流量。
Traffic Predictor 不仅允许我们看到发生故障时流量将转移到哪里,还允许我们预先配置 Traffic Manager 策略,以便将请求从发生故障的数据中心转移出来,以防止出现惊群效应:如果第一个数据中心出现问题,突然涌入的请求可能导致第二个数据中心发生故障。借助 Traffic Predictor,Traffic Manager 不仅在一个数据中心发生故障时将流量转移出去,还会主动将流量从其他数据中心转移出去,以确保服务的无缝延续。
将大锤换成手术刀
利用 Traffic Predictor,Traffic Manager 能够动态地广告和撤回前缀,同时确保每个数据中心都能处理所有流量。但是,有时以撤回前缀作为流量管理的手段可能有些过度。其中一个原因是,我们向数据中心添加或移除流量的唯一方式是通过从面向互联网的路由器广告路由。我们的每个路由都包含数千个 IP 地址,因此即使只删除一个,仍然代表了一大部分的流量。
具体而言,互联网应用将至少从一个 /24 子网向互联网广告前缀,但许多应用广告的前缀要大于 /24。这通常是为了防止路由泄露或路由劫持:许多提供商实际上会过滤掉比 /24 更具体的路由(有关更多信息,请查看这篇博客文章)。如果我们假设 Cloudflare 将受保护资产映射到 IP 地址的比例为 1:1,那么每个 /24 子网将能够为 256 个客户提供服务,这是 /24 子网中的 IP 地址数量。如果每个 IP 地址每秒发出一个请求,且需要每秒转移 1000 个请求 (RPS) 计算,我们将不得不从数据中心移出 4 个 /24 子网。
但实际上,Cloudflare 将单一 IP 地址映射到数十万个受保护资产。所以,对于 Cloudflare 来说,一个 /24 子网可能会接收到每秒 3000 个请求,但是如果我们需要移出 1000 个RPS,那么我们别无选择,只能移出一个 /24 子网。这还只是假设我们在 /24 级别进行路由广告。如果我们使用 /20 来进行广告,我们可以撤回的数量就会变得不那么精细了:如果网站到 IP 地址映射为 1:1 ,每个前缀每秒处理 4096 个请求,如果网站到 IP 地址的映射是多对一,那么处理的请求数就更多了。
虽然撤回前缀广告可为那些可能已看到 499 或 500 错误的用户改善体验——但可能有大部分用户并没有受到问题的影响,并仍然被从他们应该去的数据中心移走,那么他们的速度可能会下降,即便只有一点点。这种移出比必要更多的流量的概念被称为“搁浅容量”:理论上,数据中心能够为一个地区的更多用户提供服务,但由于 Traffic Manager 的工作方式,它无法做到这一点。
我们希望改进 Traffic Manager,使其只将绝对最少的用户从出现问题的数据中心移出,而不是搁浅更多的容量。为了做到这一点,我们需要转移一定比例的前缀,这样我们可以更加精细,只转移绝对需要移出的部分。为了解决这个问题,我们为我们的第四层负载均衡器 Unimog 构建了一个扩展,名为 Plurimog。
快速重温下 Unimog 和第四层负载平衡:我们的每一台机器都包含一个服务,用于确定该机器是否可以接受用户请求。如果该机器可以接受用户请求,那么它会将请求发送到我们的 HTTP 堆栈,后者将处理请求并将返回用户。如果该机器无法接受请求,则其会将请求发送到数据中心中可以接受请求的另一台机器。这些机器之所以能够做到这一点,是因为它们一直在进行通信,以了解彼此是否可以服务用户。
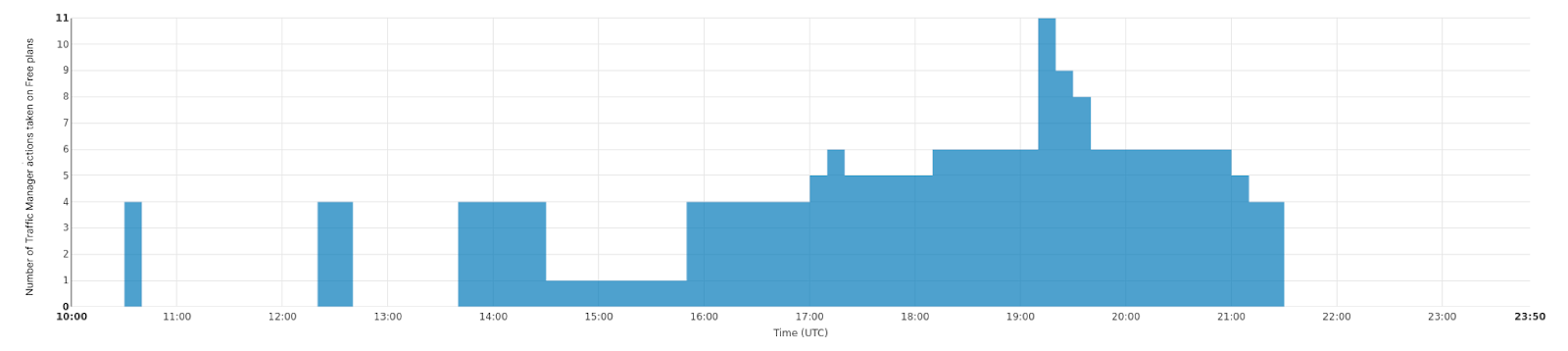
Plurimog 做同样的事情,但 Plurimog 是在数据中心和入网点之间进行通信,而不是在机器之间。如果一个请求进入费城数据中心,而它无法接受该请求,则 Plurimog 会将其转发到另一个可以接受该请求的数据中心,比如阿什本,并在那里解密并处理请求。因为 Plurimog 在第四层运行,它可以将单个 TCP 或 UDP 请求发送到其他地方,使得它可以非常精细:它可以非常容易地一定比例的流量发送到其他数据中心,意味着我们只需要转移出足够的流量,以确保每个人都可以尽快得到服务。看一下这在法兰克福数据中心是如何工作的,我们能够逐步将越来越多的流量转移出去,以便处理我们数据中心的问题。这张图表显示随着时间的推移,对免费流量采取将其转移出法兰克福数据中心的操作数量。
但即使在数据中心内部,我们也可以路由流量到其他部分,以防止流量离开数据中心。我们的大型数据中心,即多个共存入网点 (MCP),包含在数据中心内部的计算逻辑部分,它们彼此并不相同。这些 MCP 数据中心启用了另一个版本的 Unimog,称为 Duomog,它用于自动在计算逻辑部分之间转移流量。这使得 MCP 数据中心具备不牺牲客户性能的容错性,并允许 Traffic Manager 在一个数据中心内以及数据中心之间工作。
在评估要转移的请求部分时,Traffic Manager 执行以下操作:
Traffic Manager 确定需要从数据中心或数据中心的子部分移出的请求的比例,以便能够服务所有请求。
然后,Traffic Manager 计算每个目标的汇总空间指标,以查看每个故障转移数据中心可以接受多少请求。
然后,Traffic Manager 确定我们在每个计划中需要移出多少流量,并通过 Plurimog/Duomog 转移计划的一部分或全部,直到我们移出了足够的流量。我们首先转移 Free 计划客户,如果数据中心中没有更多 Free 客户,我们将转移 Pro 客户,然后如果需要,再转移 Business 客户。
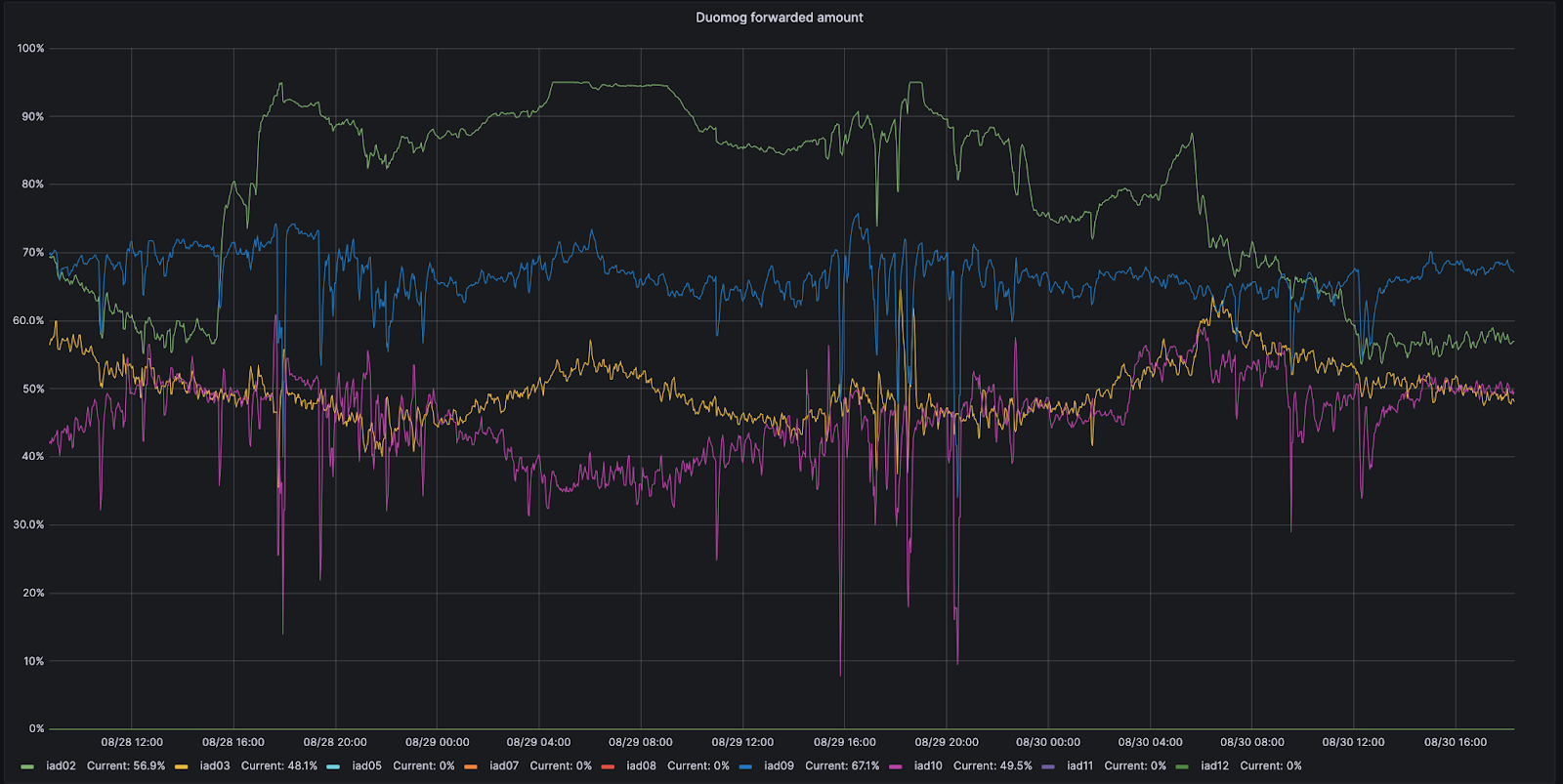
例如,让我们看一下弗吉尼亚州的阿什本,这是我们的其中一个 MCP。阿什本有九个不同的容量子区,每个子区都可以接受流量。在 8 月 28 日,其中一个子区 (IAD02) 出现了一个问题,导致它能够处理的流量减少。
在这段时间内,Duomog 将更多流量从 IAD02 转移到到阿什本内的其他子区,确保阿什本始终在线,在这个问题期间性能没有受到影响。然后,一旦 IAD02 再次能够接受流量,Duomog 就自动将流量转移回来。下面的时间序列图中可以看到这些操作的可视化,其中跟踪了 IAD02 内部在子区之间随时间转移的流量百分比(以绿色显示):
Traffic Manager 如何知道要转移多少流量?
尽管我们在上面的示例中使用了每秒请求数,但是在实际转移流量时,使用每秒请求数作为度量是不够准确的。这是因为不同的客户对我们的服务有不同的资源成本;一个主要从缓存中提供服务而禁用 WAF 的网站,与一个启用所有 WAF 规则而禁用缓存的网站相比,在 CPU 时间使用方面要便宜得多。因此,我们记录每个请求在 CPU 中占用的时间。然后,我们可以聚合每个计划的 CPU 时间,以找到每个计划的 CPU 时间使用情况。我们以毫秒为单位记录 CPU 时间,并取每秒的值,结果的单位是毫秒/秒。
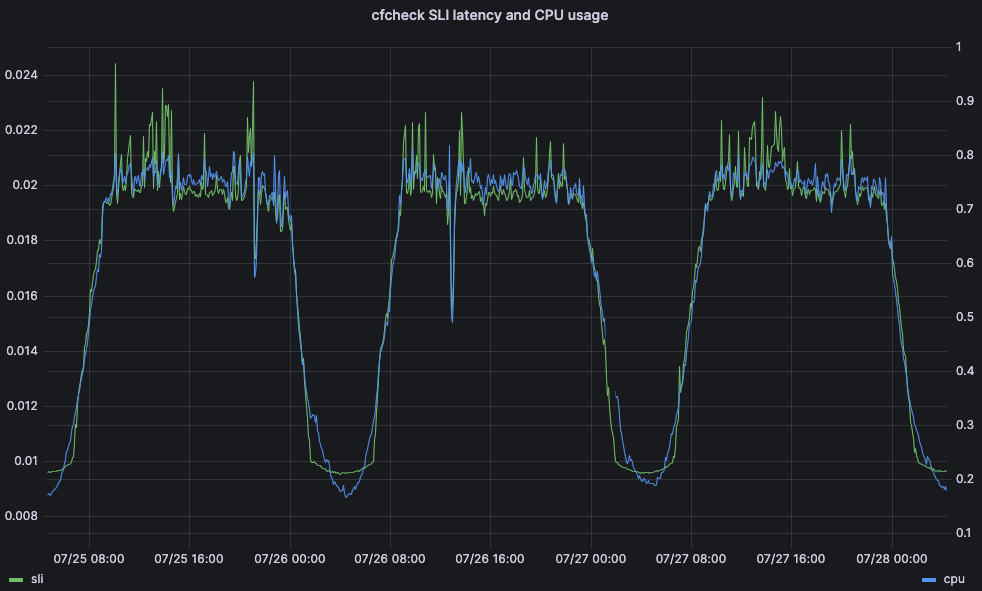
CPU 时间是一个重要的度量,因为它可能对延迟和客户性能产生影响。例如,考虑一下用户请求完全通过 Cloudflare 前线服务器所需的时间:我们称之为 cfcheck 延迟。如果这个数字变得过高,那么我们的客户会开始注意到,而且体验将变差。当 cfcheck 延迟变高时,通常是因为 CPU 利用率很高。下图显示了 95 百分位 cfcheck 延迟与同一数据中心中所有机器 CPU 利用率的关系,可以看到很强的相关性:
因此,让 Traffic Manager 查看数据中心的 CPU 时间是一种非常好的方式,以确保我们为客户提供最佳体验,而不会造成问题。
在获得每个计划的 CPU 时间之后,我们需要弄清楚有多少 CPU 时间可以转移到其他数据中心。为此,我们汇总所有服务器的 CPU 利用率,以获得整个数据中心的单一 CPU 利用率。如果数据中心中的部分服务器由于网络设备故障、电源故障等原因而出现故障,那么到达这些服务器的请求将由 Duomog 自动路由到数据中心的其他地方。随着服务器的数量减少,数据中心的整体 CPU 利用率将增加。Traffic Manager 为每个数据中心设置了三个阈值:最大阈值、目标阈值和可接受阈值。
最大阈值:性能开始下降的 CPU 水平,Traffic Manager 将在此水平采取行动
目标阈值:Traffic Manager 将尝试将 CPU 利用率降至这个水平以恢复最佳用户服务
可接受阈值:在此水平,数据中心可以接收从另一个数据中心转发的请求,或者撤销活动的转移
当数据中心超过最大阈值时,Traffic Manager 会取所有计划的总 CPU 时间与当前 CPU 利用率的比值,然后将其应用于目标 CPU 利用率以找到目标 CPU 时间。通过这样做,我们可以比较拥有 100 台服务器的数据中心和拥有 10 台服务器的数据中心,而无需担心每个数据中心中的服务器数量。这假设负载线性增加,对于我们的目的来说,这种假设已经足够。
目标比率等于当前比率:
因此:
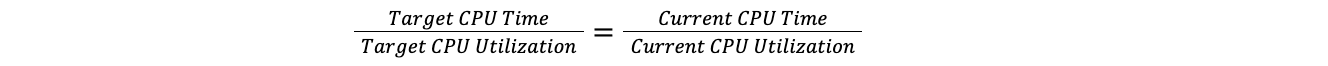
从当前 CPU 时间减去目标 CPU 时间,我们得到要转移的 CPU 时间:

例如,如果整个数据中心的当前 CPU 利用率为 90%,目标为 85%,并且所有计划的CPU时间为 18000,那么我们将有:

这意味着 Traffic Manager 将需要转移 1000 CPU 时间:
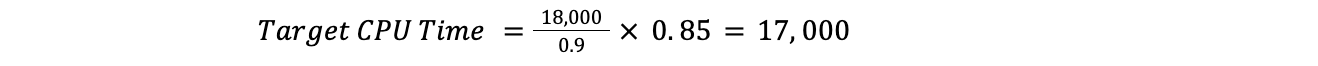
现在我们知道了需要转移的总 CPU 时间,我们可以遍历计划,直到达到所需的转移时间。
最大阈值是多少?
我们经常遇到的一个问题是确定 Traffic Manager 应该在哪个点对一个数据中心开始采取行动——它应该观察什么指标,什么是可接受的水平?
如前所述,不同的服务在 CPU 利用率方面有不同的需求,并且在许多情况下,数据中心具有非常不同的利用率模式。
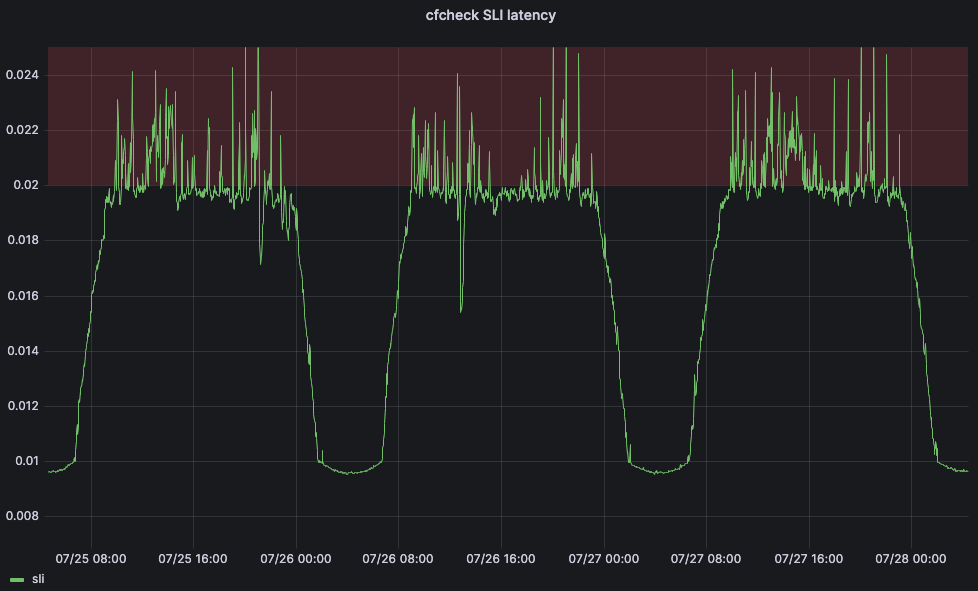
为了解决这个问题,我们求助于机器学习。我们创建了一项服务,其将根据面向客户的指标自动调整每个数据中心的最大阈值。对于我们的主要服务水平指标 (SLI),我们决定使用前面描述的 cfcheck 延迟度量。
但是我们还需要定义一个服务水平目标 (SLO),以便我们的机器学习应用能够调整阈值。我们将 SLO 设为 20 毫秒。将我们的 SLO 与 SLI 进行比较,我们的第 95 百分位 cfcheck 延迟不应该超过 20 毫秒,如果超过了,我们需要采取行动。下图显示随着时间的推移,第 95 百分位的 cfcheck 延迟,当 cfcheck 延迟进入红色区域时,客户开始变得不满:
如果当 CPU 利用率过高导致客户体验变差,那么 Traffic Manager 最大阈值的目标就是确保客户的性能不受影响,并在性能开始下降之前开始重定向流量。在预定的时间间隔内,Traffic Manager 服务将为每个数据中心获取一系列指标,并应用一系列机器学习算法。在清理数据的异常值后,我们应用一种简单的二次曲线拟合,我们目前正在测试一种线性回归算法。
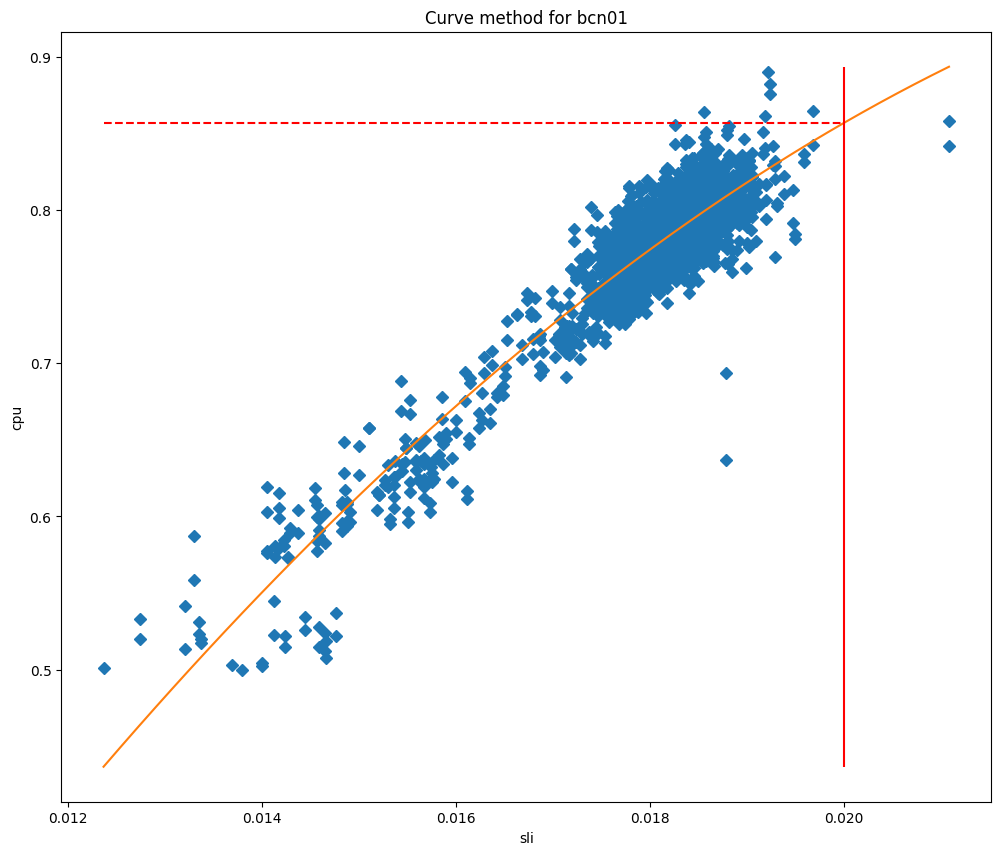
在拟合模型之后,我们可以使用它们来预测当 SLI 等于我们的 SLO 时的 CPU 使用情况,然后将其用作我们的最大阈值。如果我们根据 SLI 绘制 CPU 值,可以清楚地看到为什么这些方法对我们的数据中心如此有效,正如以下关于巴塞罗那的图表所示,它们是分别根据曲线拟合和线性回归拟合绘制的。
在这些图表中,垂直线是 SLO,这条线与拟合模型的交点代表将用作最大阈值的值。这个模型已经被证明非常准确,而且我们能够显著减少 SLO 违反情况。让我们看一下我们在里斯本开始部署这项服务时的情况:
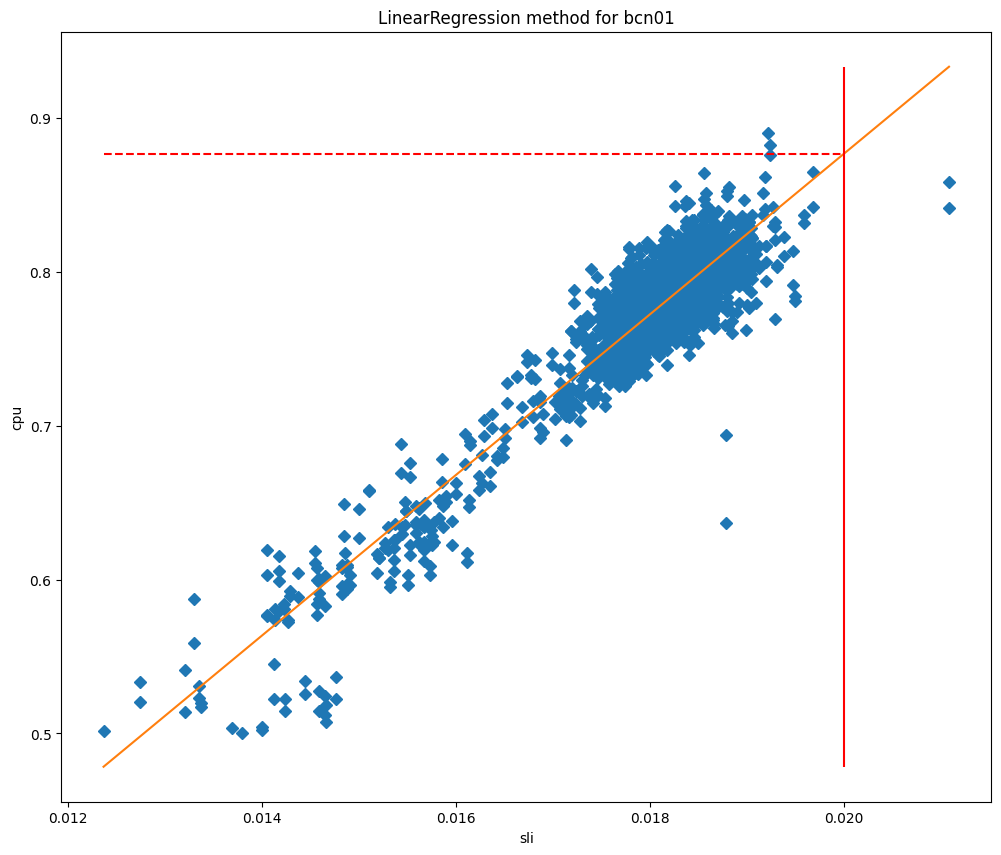
在更改之前,cfcheck 延迟持续出现峰值,但由于最大阈值是静态的,所以 Traffic Manager 没有采取行动。但是在 7 月 29 日之后,我们看到 cfcheck 延迟从未达到 SLO,因为我们在持续测量以确保客户永远不会受到 CPU 利用率增加的影响。
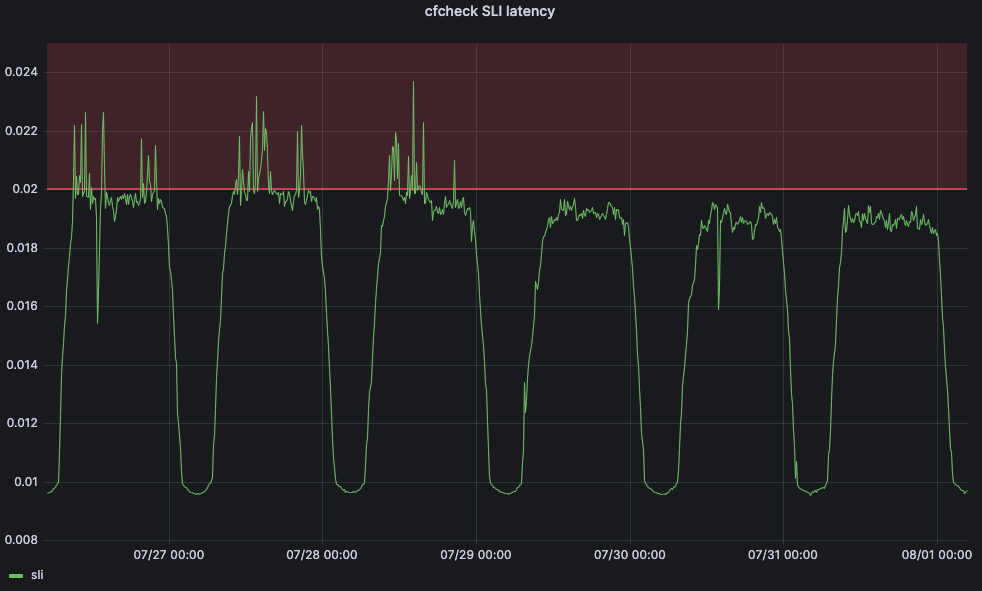
流量发送到哪里?
在获得最大阈值后,我们需要找到第三个 CPU 利用率阈值——可接受阈值,这个阈值在计算需要转移多少流量时没有使用。当一个数据中心低于这个阈值时,它有未使用的容量,只要它本身不转发流量,就可以在需要时供其他数据中心使用。为了计算出每个数据中心能够接收多少数量,我们使用与上述相同的方法,将“目标”替换为“可接受”:
因此:
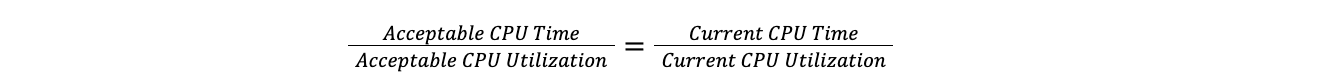
从可接受的 CPU 时间中减去当前 CPU 时间,我们得到数据中心可接受的 CPU 时间值:

为了找到发送流量的位置,Traffic Manager 将获取所有数据中心的可用 CPU时间,然后根据到需要转移流量的数据中心的延迟对它们进行排序。它会遍历每个数据中心,根据最大阈值使用所有可用容量,然后再移动到下一个数据中心。在查找要转移哪些计划时,我们从最低优先级的计划到最高优先级,但在寻找要发送它们的目的地时,我们以相反方向操作。
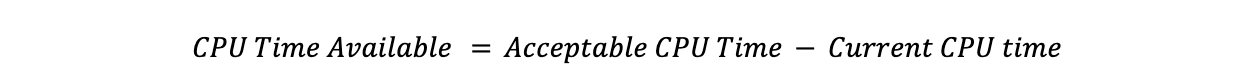
为了更清楚地说明这一点,让我们举一个例子:
我们需要从数据中心 A 转移 1000 个 CPU时间,我们有以下每个计划的使用量:Free:500 毫秒/秒,Pro:400 毫秒/,Business:200 毫秒/秒,Enterprise:1000 毫秒/秒。
我们将转移 100% 的 Free(500 毫秒/秒),100% 的 Pro(400 毫秒/秒),50% 的 Business(100 毫秒/秒),以及 0% 的 Enterprise。
附近的数据中心有以下可用的 CPU 时间:B:300 毫秒/秒,C:300 毫秒/秒,D:1000 毫秒/秒。
延迟为:A-B:100 毫秒,A-C:110 毫秒,A-D:120 毫秒。
从需要采取行动的最低延迟和最高优先级的计划开始,我们可将所有的 Business 计划 CPU 时间和一半的 Pro 计划 CPU 时间转移到数据中心 B。接下来我们会移动到数据中心 C,并能够转移剩下的 Pro 计划,以及 20% 的 Free 计划。剩下的 Pro 计划可以转发到数据中心 D。结果是以下操作:Business:50%→ B,Pro:50%→ B,50%→ C,Free:20%→ C,80%→ D。。
撤销操作
就像 Traffic Manager 不断保持数据中心不超过阈值一样,它也寻求将任何转发的流量恢复到正在转发流量的数据中心。
在上面,我们看到了 Traffic Manager 如何计算一个数据中心能够从另一个数据中心接收多少流量——它称之为可用 CPU 时间。当有活动的转移时,我们使用可用的CPU时间将流量带回数据中心——我们总是优先考虑恢复活动的转移,而不是接受来自另一个数据中心的流量。
将以上组合在一起,就能得到一个系统,它不断地测量每个数据中心的系统和客户健康指标,并分散流量,以确保每个请求都可以在我们网络当前状态下得到服务。当我们将所有这些在数据中心之间的转移放在地图上时,它看起来像这样,这是一个小时内 Traffic Manager 所有转移操作的地图。这张地图并没有显示我们全部的数据中心部署,但它确实显示了这段时间内正在发送或接收被转移流量的数据中心:
红色或黄色的数据中心正在承受负载,并将流量转移到其他数据中心,直到它们变为绿色,这意味着所有的指标都显示为健康。圆圈的大小表示从这些数据中心移出或移到到这些数据中心的请求数量。流量的转移方向由线条的移动方向指示。这在全球规模上难以看到,因此让我们放大到美国,看看在同一时间段内的实际情况:
图中可以看到多伦多、底特律、纽约和堪萨斯城由于硬件问题无法服务一些请求,因此它们会将这些请求发送到达拉斯、芝加哥和阿什本,直到用户和数据中心恢复平衡。一旦底特律等数据中心能够处理它们接收到的所有请求,而无需将流量发送出去,底特律将逐渐停止向芝加哥转发请求,直到数据中心的任何问题完全解决,此时它将不再转发任何东西。在以上整个过程中,最终用户都是在线的,底特律或任何其他发送流量的地点可能发生的任何物理问题都没有对最终用户造成影响。
网络顺畅,产品正常运行
因为 Traffic Manager 与用户体验息息相关,所以它是 Cloudflare 网络的基本组成部分:它让我们的产品保持在线,并确保它们尽可能地快速、可靠。它是我们的实时负载均衡器,通过只将必要的流量从出现问题的数据中心转移出去,帮助我们的产品保持快速运行。由于转移的流量减少了,我们的产品和服务保持快速运行。
但是 Traffic Manager 也可以帮助保持我们的产品在线和可靠,因为它允许我们的产品预测可能出现可靠性问题的地方,并预先将产品移动到其他地方。例如,Browser Isolation 直接与 Traffic Manager 协同工作,以帮助确保产品的正常运行时间。当您连接到一个 Cloudflare 数据中心以创建一个托管浏览器实例时,Browser Isolation 首先会询问 Traffic Manager:该数据中心是否有足够的容量在本地运行实例,如果有,就立即在那里创建实例。如果没有足够的可用容量,Traffic Manager 会告诉 Browser Isolation 哪个最近的数据中心有足够的可用容量,从而帮助 Browser Isolation 为用户提供尽可能最佳的体验。
网络顺畅,用户满意
Cloudflare 运营这个庞大的网络,服务我们所有不同的产品和客户情景。我们创建了一个具有韧性的网络:不但拥有 MCP 数据中心(设计为减少单一故障造成的影响),还不断因应内部和外部问题在我们的网络内部转移流量。
但那是我们的问题,您无需费心。
同样,当人类必须解决这些问题时,受影响的将是客户和最终用户。为了确保您始终在线,我们构建了一个智能的系统,它可以检测我们的硬件故障,并预先在我们的网络上平衡流量,以确保它在线并尽可能快速运行。这个系统的工作速度比任何人都快——不仅让我们的网络工程师能够在夜晚安睡——还为我们所有的客户提供了更好、更快的体验。
最后:如果这些工程挑战让您感到兴奋,欢迎考虑加入我们的流量工程团队。有关空缺职位信息,请查看招聘页面。